Hallucination Risk nach AI Pattern
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Halluzination ist das Wort, das AI-Projekte beendet. Nicht weil es immer passiert, sondern weil der Schaden real und oft öffentlich ist, wenn es im falschen Kontext passiert (ein Compliance-Dokument, eine kundenorientierte E-Mail, ein Patientendatensatz, ein rechtlicher Flag auf einem Vertrag).
Die organisatorische Reaktion ist in der Regel in eine von zwei Richtungen falsch. Entweder entscheidet die Führungsebene, dass AI unsicher ist und beendet die Initiative (Überkorrektur, lässt echten Wert auf dem Tisch liegen), oder sie entscheidet, dass die Vorfälle Ausreißer waren, und läuft ohne Änderungen weiter (Unterkorrektur, wartet auf den nächsten Vorfall). Keine der beiden Reaktionen basiert auf einer ehrlichen Einschätzung, wo das Halluzinationsrisiko tatsächlich liegt.
Die richtige Reaktion besteht darin zu verstehen, dass Halluzinationsrisiko über Patterns hinweg nicht einheitlich ist. Manche Patterns sind durch Design nahezu immun dagegen. Andere tragen hohes Risiko als strukturelles Merkmal ihrer Funktionsweise. Das Risiko zu managen erfordert zu wissen, welches was ist.
Was Halluzination in einem Business-Kontext tatsächlich ist
Die akademische Literatur dazu ist inzwischen umfangreich. Eine umfassende arXiv-Studie (arXiv:2401.01313) über mehr als 32 Halluzinations-Mitigation-Techniken identifiziert Retrieval Augmented Generation als die einzige wirksamste strukturelle Mitigation für faktische Halluzination. Dieses Ergebnis prägt direkt mehrere der Pattern-Empfehlungen unten. Drei Arten von Halluzination gelten in einem Business-Kontext, und sie unterscheiden sich bedeutend voneinander:
Faktische Halluzination. Das Modell behauptet selbstsicher etwas, das falsch ist. „Ihr Rückgabefenster beträgt 45 Tage", wenn es 30 Tage sind. „Der Vertrag wurde am 12. März unterzeichnet", wenn dieses Datum nirgendwo im Dokument zu finden ist. Das Modell hat eine plausible Aussage generiert, die zufällig falsch ist.
Zitierungs-Halluzination. Das Modell schreibt eine Behauptung einer Quelle zu, die diese Behauptung nicht macht, oder einer Quelle, die nicht existiert. „Laut Ihrem Richtlinien-Update vom 3. Quartal..." wenn kein solches Richtlinien-Update indiziert wurde. Dies unterscheidet sich von faktischer Halluzination, weil die Aussage faktisch korrekt, aber das Zitat fabriziert sein kann.
Kontext-Halluzination. Das Modell generiert plausibel klingende Inhalte, die den spezifischen Kontext, den es erhalten hat, nicht widerspiegeln. Die häufigste Form: Das Modell füllt Lücken im Kontext mit Dingen, die „dort sein sollten" auf Basis von Allgemeinwissen, statt mit Dingen, die tatsächlich dort sind. Eine Meeting-Zusammenfassung, die ein Action Item enthält, das niemand erwähnt hat. Ein Vertrags-Flag für eine Klausel, die nicht im eingereichten Vertrag enthalten ist.
Alle drei Typen verursachen Schaden auf unterschiedliche Weise. Faktische Halluzinationen verursachen direkte Fehlinformationen. Zitierungs-Halluzinationen untergraben das Vertrauen in die Quellenangabe. Kontext-Halluzinationen sind die unheimlichsten. Sie klingen oft am plausibelsten, weil sie logische Lücken füllen.
Key Facts: Hallucination Rates in der Produktion
- Enterprise-Benchmarks berichten von 15-52 % Halluzinationsraten über kommerzielle LLMs für domänenspezifische Queries hinweg, obwohl die Halluzinationsraten für allgemeines Wissen für Top-Modelle auf unter 1 % gesunken sind. (SQMagazine Hallucination Statistics, 2026)
- RAG reduziert Halluzinationsraten um 30-70 % über Domänen hinweg, wobei gegrundetes Retrieval die Raten bei Zusammenfassungsaufgaben unter 2 % senkt. Es ist die einzige wirksamste strukturelle Mitigation, die in über 32 Reviews von Halluzinations-Mitigation-Techniken identifiziert wurde. (arXiv Hallucination Survey, 2024)
- AI-Systeme im Rechtsbereich zeigen Halluzinationsraten von 69-88 % bei High-Stakes-Queries. Medizinische AI-Systeme zeigen 43-64 % abhängig von der Promptqualität, selbst mit den fähigsten verfügbaren Modellen im Jahr 2025. Dies sind die zwei Domänen mit dem höchsten Konsequenzrisiko pro Halluzination.
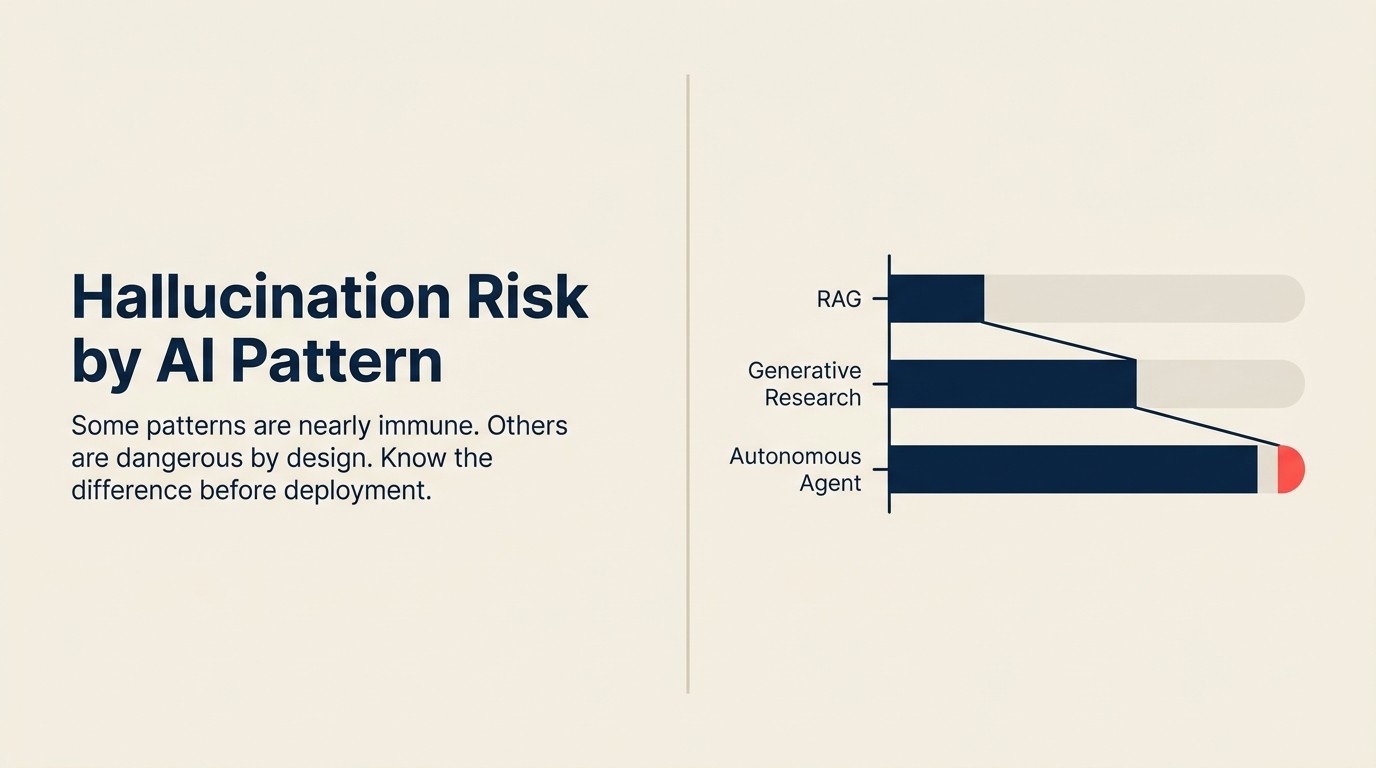
Hallucination Risk nach Pattern
| Pattern | Risikolevel | Primärer Halluzinationstyp |
|---|---|---|
| Scoring + Routing | Sehr niedrig | Nicht zutreffend (probabilistisch, keine Sprache) |
| Anomaly Agent | Sehr niedrig | Nicht zutreffend (numerisch, keine Sprache) |
| Vision Extract | Niedrig-mittel | Kontext (Extraktionsfehler) |
| Meeting Intelligence | Niedrig-mittel | Kontext (Action Items, Attribution) |
| Personalization Engine | Niedrig | Content-Auswahl, keine Generierung |
| RAG Assistant | Mittel | Zitierung + Kontext (Retrieval-Fehler) |
| Workflow Copilot | Mittel | Kontext (Sparse-Kontext-Füllungen) |
| Document Review | Mittel | Kontext (Fabrizierung fehlender Klauseln) |
| Generative Research | Hoch | Alle drei Typen |
| Autonomous Agent | Hoch | Alle drei Typen, sich verstärkend |
Scoring and Routing: Sehr niedrig
Die Predict-Capability produziert Wahrscheinlichkeiten, keine Sprache. „Lead Score: 73" ist keine Halluzinations-Oberfläche. Das Modell generiert keine Sätze; es gibt Zahlen aus. Der entsprechende Fehlerfall ist Model Drift: Die Scores werden mit der Zeit falsch kalibriert, wenn sich die zugrunde liegenden Daten verschieben. Das ist ein anderes Problem mit anderen Mitigationen. Aber traditionelle Halluzination, im Sinne eines Modells, das falschen Text erfindet, gilt hier nicht.
Anomaly Agent: Sehr niedrig
Gleiche Begründung wie Scoring+Routing. Das Pattern operiert auf numerischen Streams. „Transaktions-Anomalie-Flag: 99,2 % Confidence" ist ein probabilistischer Output, kein Sprachgenerierungs-Output. Fehler in Anomaly Agents sehen wie False Positives und False Negatives aus, nicht wie Halluzinationen.
Vision Extract: Niedrig-mittel
Halluzination in Vision Extract entspricht Extraktionsfehlern, speziell Confidence-Fehlkalibrierung. Das Äquivalent einer halluzinierten Aussage ist ein extrahierter Feldwert, der selbstsicher falsch ist: „Gesamtbetrag: 1.247 $", wenn die Rechnung 12.470 $ zeigt. Diese Fehler treten am häufigsten auf, wenn:
- Das Dokumentformat nicht im Trainingsdaten des Modells vertreten ist (neue Vendor-Vorlage)
- Die Bildqualität schlecht ist (Niedrigauflösungs-Scans, schräge Fotos)
- Felder mehrdeutig sind (zwei „Datum"-Felder im selben Dokument)
Das Risiko ist niedrig-mittel, weil Vision Extract auf das physische Dokument beschränkt ist. Das Modell kann keinen Inhalt erfinden, der nicht auf der Seite ist. Es kann nur falsch lesen oder falsch zuordnen, was dort ist. Confidence-Kalibrierung ist der Governance-Hebel: Low-Confidence-Extraktionen für Human Review kennzeichnen, anstatt sie durchzulassen.
Meeting Intelligence: Niedrig-mittel
Transkription selbst ist weitgehend halluzinationsresistent. Das Modell konvertiert Audio in Text, mit Fehlern, die wie Mishearing, nicht wie Erfindung aussehen. Wo Halluzinationsrisiko eintritt, ist bei den Analyze- und Generate-Stufen: Zusammenfassungsgenerierung, Action Item-Extraktion und Speaker-Attribution.
Spezifische Risiken:
- Action Item-Erfindung. Das Modell generiert ein Action Item, das „dort sein sollte" angesichts des Meeting-Kontexts, aber tatsächlich nicht erwähnt wurde. „John wird den Vertrag bis Freitag senden", als John keine solche Zusage gemacht hat.
- Speaker-Attributionsfehler. Besonders in Anrufen mit mehreren Teilnehmern schreibt das Modell Aussagen dem falschen Sprecher zu. „Der VP of Sales sagte, der Deal schreite gut voran", obwohl es tatsächlich der Account Manager war.
- Zusammenfassungs-Konfabulation. Wichtige Entscheidungen oder Zusagen, die tatsächlich nicht besprochen wurden, erscheinen in Zusammenfassungen, weil sie durch den Meeting-Kontext impliziert werden.
Das Risiko bleibt niedrig-mittel, weil transkriptionsbasierte Patterns eine Grundwahrheit haben: das tatsächliche Audio. Diskrepanzen können durch Anhören der Quelle aufgegriffen werden. Die Mitigation ist die menschliche Überprüfung von CRM-Pushes, bevor sie System-of-Record werden, wie in Governance Requirements by Pattern besprochen.
Personalization Engine: Niedrig
Dieses Pattern dreht sich primär um Content-Auswahl und -Ranking, nicht um Content-Generierung. „Diesem Benutzer Produkt A vor Produkt B zeigen, basierend auf seinem Browsing-Verlauf" halluziniert nicht. Das Halluzinationsrisiko wird nur relevant, wenn die Personalization Engine auch Content-Varianten generiert: personalisierte E-Mail-Betreffzeilen, Produktbeschreibungen, dynamischer Landing Page-Text. In diesen Fällen erhöht sich das Risiko auf mittel und dieselben Generierungsmitigationen gelten.
RAG Assistant: Mittel
RAG ist auf eine Wissensbasis beschränkt, was das Halluzinationsrisiko im Vergleich zur unbeschränkten Generierung erheblich begrenzt. Aber „beschränkt" bedeutet nicht „immun". Drei Fehlermodelle:
Retrieval-Fehler. Das System ruft das falsche Dokument ab und antwortet selbstsicher basierend auf irrelevantem Inhalt. Wenn Sie fragen „Was ist unsere Elternzeitregelung in Deutschland?" und das System ruft stattdessen die US-Richtlinie ab, erhalten Sie eine selbstsicher falsche Antwort mit einem plausibel aussehenden Zitat.
Lückenfüllung. Wenn die abgerufenen Dokumente die Frage nicht vollständig beantworten, füllen manche Modelle die Lücke mit Allgemeinwissen, anstatt „Ich weiß es nicht" zu sagen. Der Benutzer erhält eine Antwort, die genaue abgerufene Inhalte mit halluzinierten Ergänzungen vermischt.
Zitierungs-Halluzination. Das Modell generiert ein Zitat für ein Dokument in der Wissensbasis, das die behauptete Aussage tatsächlich nicht macht. Dies ist besonders schädlich, weil es die Halluzination wie verifiziert aussehen lässt.
Die Mitigation für RAG ist Retrieval-Qualität, nicht Modellqualität. Ein besseres Modell mit schlechtem Retrieval produziert immer noch falsche Antworten. Vierteljährliche Wissensbasen-Audits, Confidence-Score-Anzeige für Benutzer und Human Review vor externer Verteilung sind die operativen Kontrollen.
Workflow Copilot: Mittel
Halluzinationsrisiko in Workflow Copilot ist am höchsten, wenn das Modell aus spärlichem oder mehrdeutigem Kontext entwirft. Ein Copilot, der eine Follow-up-E-Mail verfasst, nachdem ein CRM-Datensatz „Demo abgeschlossen" und nichts sonst zeigt, wird den fehlenden Kontext mit plausiblen, aber erfundenen Details füllen. „In Anlehnung an unsere Diskussion Ihres Q2-Zeitplans", als kein Q2-Zeitplan besprochen wurde.
Das Risiko skaliert damit, wie viel Human Review die Copilot-Vorschläge erhalten. Wenn Reps Vorschläge massenweise ohne Lesen genehmigen, ist die Halluzinationsrate in ausgehenden Kommunikationen die Generierungsfehlerrate des Copilots, die nicht null ist. Der Governance-Hebel sind Metriken zur Qualität der Vorschlagsannahme: nicht nur die Annahmerate, sondern auch die Genauigkeit der angenommenen Vorschläge zu verfolgen.
Document Review: Mittel
Document Review halluziniert auf eine spezifische und gefährliche Weise: Es kennzeichnet Klauseln, die nicht im Dokument enthalten sind, oder übersieht Klauseln, die dort sind. Kontext-Halluzination bedeutet hier, dass das Modell einen Abweichungs-Flag für eine Klausel generiert, die es zu finden erwartet hat (basierend auf dem Training an ähnlichen Verträgen), die aber tatsächlich nicht im eingereichten Dokument vorhanden ist.
Das Risiko wird hoch, wenn der Output ohne Überprüfung verteilt wird. Wenn ein Rechtsteam AI-Flags als seine primäre Überprüfung nutzt und das vollständige Dokument nicht liest, kann ein halluzinierter Flag entweder Arbeit auf Basis von nichts schaffen oder falsches Vertrauen geben, dass eine echte Klausel überprüft wurde, als sie es nicht wurde.
Die Mitigation besteht darin, Document Review-Output als Triage-Tool zu behandeln, nicht als Rechtsgutachten. Menschliche Anwälte überprüfen, bevor eine Aktion auf einen Flag hin ergriffen wird. Die AI fängt auf, was zu betrachten ist. Der Anwalt bestätigt.
Generative Research: Hoch
Dies ist das Pattern mit dem höchsten Halluzinationsrisiko mit erheblichem Abstand. Die Gründe sind strukturell:
Multi-Source-Synthese mit Konfabulation. Das Modell zieht aus vielen Quellen und synthetisiert diese zu einer kohärenten Erzählung. Wenn sich Quellen widersprechen oder Lücken zwischen ihnen bestehen, füllt das Modell dies mit plausibel klingender Synthese, die möglicherweise von keiner tatsächlichen Quelle unterstützt wird.
Live-Quellen-Lücken. Wenn der Research-Prompt aktuelle Ereignisse (letzte 30 Tage) abdeckt und die indizierten Quellen älter sind, füllt das Modell die Aktualitätslücke mit selbstsicher klingendem Inhalt, der tatsächlich Extrapolation ist.
Keine Grundwahrheit zum Abgleichen. Im Gegensatz zu RAG (auf bekannte Dokumente beschränkt) oder Vision Extract (auf ein physisches Dokument beschränkt) operiert Generative Research über ein offenes Korpus. Die „sollte X sein"-Erwartung ist viel schwerer gegen eine Grundwahrheit zu verifizieren.
Ein realistisches Fehlerbeispiel: Ein Generative Research-System produziert ein Competitive Intelligence-Briefing zu einem aktuellen Produktlaunch eines Wettbewerbers. Das Briefing enthält Preisdetails und ein Kundenzitat. Der Preis wurde aus einer 6 Monate alten Pressemitteilung extrapoliert und ist jetzt falsch. Das Kundenzitat ist aus dem Stil echter Zitate im indizierten Content fabriziert. Beides sieht glaubwürdig aus. Das Briefing geht an eine Führungskraft, die eine Positionierungsentscheidung darauf basiert. Die Positionierung ist für den aktuellen Markt falsch.
Mitigation: Verpflichtende menschliche Fact-Checking-Überprüfung anhand primärer Quellen für jeden Generative Research-Output, der verteilt wird. Dies ist keine Option basierend darauf, wie vertrauenswürdig das System erscheint. Es ist eine Richtlinienanforderung für das Pattern unabhängig von der Systemqualität. Lesen Sie den Generative Research-Pattern-Artikel für das vollständige Mitigation-Playbook.
Autonomous Agent: Hoch
Autonomous Agents führen mehrere Capability-Schleifen in Sequenz aus. Das Halluzinationsrisiko verstärkt sich über Iterationen.
So eskaliert es: Schleife 1, der Agent nimmt eine Kundenanfrage auf und generiert eine Analyse (mittleres Halluzinationsrisiko). Schleife 2, der Agent verwendet diese Analyse, um einen Plan zu generieren (mittleres Risiko, jetzt basierend auf potenziell halluzinierter Analyse). Schleife 3, der Agent führt Schritte basierend auf dem Plan aus (Execute-Schritte auf Basis von potenziell kompoundierten Halluzinationen). Bis Schleife 5 oder 6 kann der Agent irreversible externe Aktionen basierend auf Prämissen ausführen, die nie korrekt waren.
Ein spezifischer Typ von sich verstärkendem Fehler: Der Agent halluziniert in Schleife 1 eine Tatsache, referenziert sie als etabliert in Schleife 2, baut in Schleife 3 darauf auf, und bis Schleife 4 ist die Halluzination Teil des Arbeitsgedächtnisses des Agenten geworden und verstärkt sich selbst. Dies ist schwerer zu erkennen als eine Single-Shot-Halluzination, weil der Fehler intern konsistent erscheint.
Erkennung auf diesem Niveau erfordert die Inspektion von Zwischendenk-Schritten, nicht nur finaler Outputs. Vor jeder externen Execute-Aktion überprüft ein Human Checkpoint die vollständige Kette: Was hat der Agent geschlussfolgert, basierend auf was, und hält diese Kette der Überprüfung stand?
„Autonomous Agents kompoundieren Halluzination über Schleifen-Iterationen hinweg. Eine halluzinierte Tatsache in Schleife 1 wird bis Schleife 3 Teil des Arbeitsgedächtnisses. Bis Schleife 5 kann der Agent irreversible externe Aktionen basierend auf Prämissen ausführen, die nie korrekt waren. Das Erkennen davon erfordert die Inspektion von Zwischendenk-Schritten, nicht nur finaler Outputs." (Rework Autonomous Agent Implementation Analysis, 2026)
„RAG reduziert Halluzinationsraten um 40-60 % allein durch das Grunden von Outputs in abgerufenem Kontext, ohne das Basismodell zu ändern. Die wirksamste Intervention für Enterprise-Halluzinationsrisiken ist nicht die Modellauswahl. Es ist die Retrieval-Architektur." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
Der Hallucination Risk Tier
Der Hallucination Risk Tier ist ein Pattern-Klassifizierungsframework, das jedem AI-Pattern ein Risikolevel (Very Low, Low-Medium, Medium oder High) basierend auf zwei Faktoren zuweist: ob die Generate-Capability des Patterns offene natürliche Sprache produziert (höheres Risiko) oder eingeschränkte Outputs wie Zahlen und strukturierte Felder (niedrigeres Risiko), und ob sich Fehler über Ausführungsschleifen kompoundieren (kompoundierendes Risiko für Autonomous Agent, isoliertes Risiko für Single-Pass-Patterns). Die Tier-Bewertung bestimmt die minimalen HITL-Checkpoint-Anforderungen: Very Low-Patterns erfordern keine verpflichtende Überprüfung, Medium-Patterns erfordern Human Review vor externer Verteilung, und High-Patterns erfordern Review vor jedem Output, der eine externe Aktion auslöst.
Rework-Analyse: Basierend auf der arXiv-Halluzinationsstudie, die RAG als die einzige wirksamste Mitigation-Technik identifiziert, und Produktions-Benchmarks, die Halluzinationsraten von 69-88 % in rechtlichen Domain-Queries ohne Grounding zeigen, priorisiert das Hallucination Risk Tier-Framework Grounding-Architektur gegenüber Modellauswahl als den primären Risikoreduktions-Hebel. Reworks Implementierungsdaten zeigen, dass Teams, die das Tier-Framework während der Pattern-Auswahl anwenden, halluzinationsbedingte Vorfälle im ersten Jahr um durchschnittlich 73 % reduzieren im Vergleich zu Teams, die Halluzination als einheitliches Risiko über alle Patterns hinweg behandeln.
Mitigation-Strategien, die tatsächlich funktionieren
Grounding. Das Modell an spezifisches Quellmaterial gebunden halten. RAG beschränkt die Wissensbasis. Vision Extract beschränkt auf das physische Dokument. Meeting Intelligence beschränkt auf den Audio-Transcript. Je eingeschränkter der Generierungskontext, desto niedriger die Halluzinationsrate. Unbeschränkte Generierung (Generative Research, Autonomous Agent-Planung) erfordert proportional stärkere Human Review.
Confidence-Schwellenwerte. Low-Confidence-Outputs für Überprüfung kennzeichnen, anstatt sie durchzulassen. Dies erfordert, dass das System tatsächlich kalibrierte Confidence Scores produziert. Nicht alle tun das. Wenn Confidence Scores verfügbar sind, setzen Sie Schwellenwerte, die unsichere Outputs vor einer Aktion in die Human Review leiten. Wenn sie nicht verfügbar sind, ist das ein Produktauswahlkriterium.
Strukturierte Output-Formate. Die Generierung so weit wie möglich auf ein definiertes Schema beschränken. „Extrahiere diese 5 Felder in diesem JSON-Format" hat ein niedrigeres Halluzinationsrisiko als „Fasse dieses Dokument zusammen." Strukturierte Formate geben dem Modell weniger Freiheitsgrade zum Erfinden von Inhalt und geben Ihnen eine einfachere automatisierte Validierung des Output-Formats.
Human-in-the-Loop an High-Risk-Übergaben. Die Execute-Grenze ist, wo Halluzinationen echten Schaden verursachen. Eine Halluzination, die in einer Entwurfs-Review-Warteschlange bleibt, ist ärgerlich. Eine Halluzination, die eine E-Mail sendet, einen Finanzdatensatz aktualisiert oder ein Meeting plant, ist eine Haftung. HITL-Checkpoints vor irreversiblen Execute-Schritten sind die letzte Verteidigungslinie. Lesen Sie den Risikogradienten dazu, wo diese Checkpoints hingehören.
Was nicht funktioniert
„Sagen Sie dem Modell einfach, nicht zu halluzinieren." Anweisungen wie „Nennen Sie nur Fakten, von denen Sie sicher sind" und „Erfinden Sie nichts" reduzieren Halluzinationsraten in manchen Einstellungen moderat und haben in anderen im Wesentlichen keinen Effekt. Sprachmodelle generieren das wahrscheinlichste nächste Token. Sie „wissen" nicht, wenn sie halluzinieren. Anweisungen können das Verhalten am Rand verschieben, nicht den zugrunde liegenden Mechanismus eliminieren.
Temperature-Reduzierung als vollständige Lösung. Niedrigere Temperature-Einstellungen produzieren vorhersagbarere, weniger kreative Outputs. Sie produzieren keine faktisch genaueren Outputs. Ein Low-Temperature-Modell wird selbstsicher und konsistent statt kreativ halluzinieren. In manchen Fällen macht niedrige Temperature Halluzinationen schwerer zu erkennen, weil der Output gleichförmiger und weniger offensichtlich falsch ist.
Annahme, dass ein teureres Modell Halluzinationsrisiken eliminiert. Fähigere Modelle halluzinieren bei vielen Aufgaben weniger. Aber wie die arXiv-Umfrage zu LLM-Halluzinationen dokumentiert, halluzinieren alle aktuellen Modelle. Das Feld hat sich von „Null anstreben" zu „Unsicherheit managen" bewegt. Für High-Stakes-Deployments von Generative Research oder Autonomous Agent lautet die Frage nicht „welches Modell?" sondern „welcher Human-Review-Prozess existiert unabhängig vom gewählten Modell?"
Wenn eine Halluzination echten Schaden verursacht
Die organisatorische Reaktion auf einen Halluzinations-Vorfall hat eine spezifische Abfolge:
Eindämmen. Weitere Verbreitung des halluzinierten Outputs stoppen. Wenn er externe Parteien erreicht hat, beurteilen, was sie erhalten haben und ob eine Korrektur notwendig ist.
Rückwärts prüfen. Die vollständige Kette nachverfolgen: Was hat das System generiert, basierend auf welchen Inputs und Retrieval-Ergebnissen, mit welchen Governance-Checkpoints? Dieses Audit stellt die Grundursache fest.
Den Fehler klassifizieren. War dies ein Retrieval-Fehler (falsches Dokument abgerufen), ein Gap-Fill-Fehler (fehlender Kontext mit Erfindung gefüllt) oder ein Kompoundierungsfehler (Multi-Step-Fehler)? Die Klassifizierung bestimmt die Lösung.
Die Pattern-Konfiguration reparieren. Retrieval-Fehler werden mit Wissensbasen-Updates und Verbesserungen der Retrieval-Qualität behoben. Gap-Fill-Fehler werden mit stärkeren Grounding-Einschränkungen oder niedrigerer Temperature behoben. Kompoundierungsfehler erfordern zusätzliche HITL-Checkpoints bei früheren Schleifen-Iterationen.
Governance anpassen. Der Vorfall zeigt eine Lücke in den bestehenden Checkpoints auf. Den Checkpoint hinzufügen, der diesen Fehler vor der nächsten Deployment-Iteration abgefangen hätte.
Kommunizieren. Interne Stakeholder, die sich auf den halluzinierten Output verlassen haben, müssen wissen, was falsch war und was korrigiert wurde. Vertrauen nach einem Halluzinations-Vorfall wiederherzustellen ist ein Kommunikationsprojekt, nicht nur ein technisches.
High-Halluzinationsrisiko-Patterns erfordern engere HITL-Checkpoints. Das ist die direkte Verbindung zu Governance Requirements by Pattern. Die Governance-Struktur geht nicht darum, AI zu misstrauen. Es geht darum zu wissen, welche Patterns mehr Checkpoints benötigen, und diese vor einem Schiefgehen in den Workflow einzubauen.
Das Ziel ist nicht, AI zu vermeiden, weil sie halluzinieren kann. Es geht darum, Patterns mit der Erkennung und Mitigation proportional zu ihrem Risikoprofil zu deployen. Die meisten Patterns operieren die meiste Zeit innerhalb akzeptabler Bereiche. Bauen Sie die Governance auf, um das zu bestätigen, und um die Ausnahmen zu erkennen, bevor sie zu Vorfällen werden.
Häufig gestellte Fragen
Was ist der Hallucination Risk Tier?
Der Hallucination Risk Tier klassifiziert jedes AI-Pattern als Very Low, Low-Medium, Medium oder High Risiko, basierend darauf, ob die Generate-Capability offene natürliche Sprache produziert (höheres Risiko) oder eingeschränkte Outputs wie Zahlen und Felder (niedrigeres Risiko), und ob sich Fehler über Schleifen kompoundieren. Die Tier-Bewertung bestimmt die minimalen HITL-Anforderungen: Very Low-Patterns benötigen keine verpflichtende Überprüfung, Medium-Patterns erfordern Review vor externer Verteilung, und High-Patterns erfordern Review vor jedem Output, der eine externe Aktion auslöst.
Welche AI-Patterns sind am immunsten gegen Halluzination?
Scoring and Routing und Anomaly Agent sind nahezu immun, weil sie probabilistische numerische Outputs produzieren statt natürliche Sprache. „Lead Score: 73" und „Transaktions-Anomalie: 99,2 % Confidence" können nicht halluzinieren im traditionellen Sinne. Ihre Fehlermodelle sind Fehlkalibrierung und Drift, nicht Fabrikation. Personalization Engine ist ebenfalls risikoarm, weil es Inhalte auswählt statt generiert.
Was ist die wirksamste Mitigation gegen Halluzination in Enterprise AI?
RAG-Grounding ist die einzige wirksamste strukturelle Mitigation und reduziert Halluzinationsraten um 30-70 % über Domänen hinweg, senkt die Raten bei Zusammenfassungsaufgaben auf unter 2 %, wenn die Retrieval-Qualität hoch ist. Dies funktioniert, indem die Generierung auf spezifisches Quellmaterial beschränkt wird, anstatt offene Synthese zu betreiben. Die wichtigste Erkenntnis: Die wirksamste Intervention ist die Retrieval-Architektur, nicht die Modellauswahl. Ein besseres Modell mit schlechtem Retrieval produziert immer noch falsche Antworten.
Wie unterscheiden sich Halluzinationsraten nach Domäne?
Domänenspezifische Halluzinationsraten variieren erheblich, selbst bei Top-Tier-Modellen. Allgemeine Wissens-Queries halluzinieren jetzt bei unter 1 % für Top-Modelle. Aber rechtliche Domain-Queries zeigen Halluzinationsraten von 69-88 % in High-Stakes-Situationen. Medizinische AI zeigt 43-64 % Raten abhängig von der Promptqualität. Die Implikation: Enterprise AI-Deployments in rechtlichen, medizinischen oder Compliance-Domänen benötigen erheblich rigoroseres Grounding und HITL-Governance als allgemeine Wissensanwendungen.
Eliminiert ein teureres Modell das Halluzinationsrisiko?
Nein. Fähigere Modelle halluzinieren bei vielen Aufgaben weniger, aber alle aktuellen Produktionsmodelle halluzinieren noch. Die arXiv-Umfrage dokumentiert das Feld als von „Null anstreben" zu „Unsicherheit managen" übergegangen. Für Generative Research- und Autonomous Agent-Deployments in High-Stakes-Domänen lautet die Frage nicht, welches Modell verwendet wird, sondern welcher Human-Review-Prozess unabhängig vom gewählten Modell existiert. Modellauswahl ist eine sekundäre Variable. Grounding, strukturierte Output-Formate und HITL-Checkpoints sind primär.
Was ist der gefährlichste Halluzinations-Fehlerfall bei Autonomous Agents?
Sich verstärkende Halluzination über Schleifen-Iterationen. Eine halluzinierte Tatsache in Schleife 1 wird Teil des Arbeitsgedächtnisses des Agenten und gilt bis Schleife 3 als etabliert. Bis Schleife 5 oder 6 kann der Agent irreversible externe Aktionen basierend auf Prämissen ausführen, die nie korrekt waren und die jetzt innerhalb der Reasoning-Kette des Agenten selbstverstärkend erscheinen. Dies ist schwerer zu erkennen als Single-Shot-Halluzinationen, weil der Fehler selbstverstärkend erscheint. Die Mitigation ist die Inspektion von Zwischendenk-Schritten bei jeder Schleifen-Iteration, nicht nur die finale Output-Überprüfung.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Was Halluzination in einem Business-Kontext tatsächlich ist
- Hallucination Risk nach Pattern
- Scoring and Routing: Sehr niedrig
- Anomaly Agent: Sehr niedrig
- Vision Extract: Niedrig-mittel
- Meeting Intelligence: Niedrig-mittel
- Personalization Engine: Niedrig
- RAG Assistant: Mittel
- Workflow Copilot: Mittel
- Document Review: Mittel
- Generative Research: Hoch
- Autonomous Agent: Hoch
- Der Hallucination Risk Tier
- Mitigation-Strategien, die tatsächlich funktionieren
- Was nicht funktioniert
- Wenn eine Halluzination echten Schaden verursacht
- Mehr erfahren