Document Review: AI als Compliance-Copilot
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ein mittelständisches Technologieunternehmen unterzeichnet etwa 300 Lieferantenverträge pro Jahr. Jeder Vertrag sollte gegen die Standardbedingungen des Unternehmens geprüft werden. Ungewöhnliche Haftungssprache sollte markiert werden. Nicht-standardmäßige Klauseln zur IP-Eigentumsschaft sollten erkannt werden. Zahlungsbedingungen, die vom 60-Tage-Standard des Unternehmens abweichen, sollten bemerkt werden, bevor jemand unterschreibt.
In der Praxis prüft das Legal-Team vielleicht 20 Prozent dieser Verträge vollständig. Die anderen 80 Prozent erhalten eine schnelle Durchsicht durch einen Operations Manager, der möglicherweise weiß oder nicht weiß, wonach er suchen soll. Einige dieser übersehenen Klauseln werden 18 Monate später zu Problemen, wenn sich die Lieferantenbeziehung verändert.
Das ist kein Kompetenzproblem des Legal-Teams. Es ist ein Volumen-Problem. Es gibt nicht genug Anwalts-Stunden, um jeden Vertrag gründlich zu prüfen, also ersetzt Triage die Gründlichkeit, und Ausnahmen schlüpfen durch.
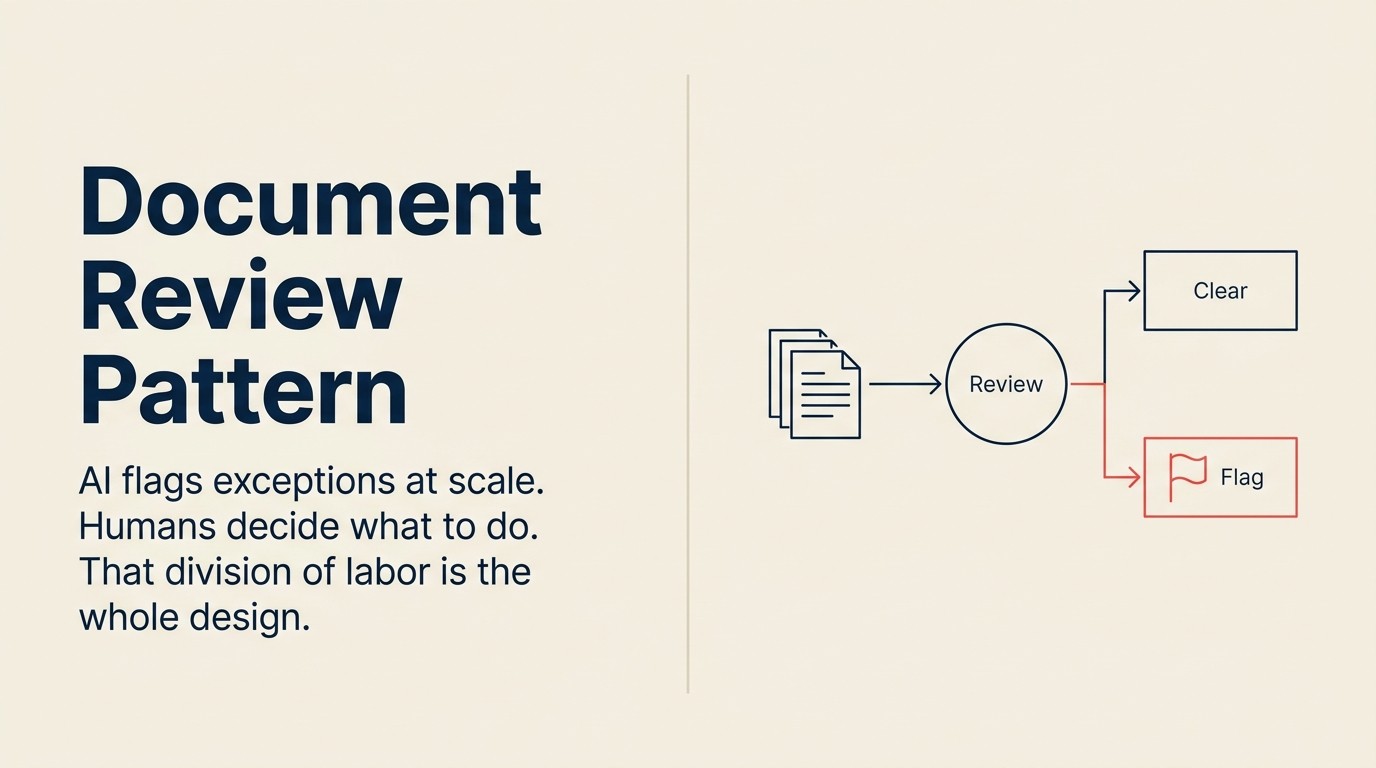
Document Review ist das AI-Pattern, das diese Mathematik verändert. Nicht indem es das rechtliche Urteil ersetzt (das ist der weiter unten behandelte Governance-Fehler), sondern indem es die Abdeckung skaliert. AI kann jeden Vertrag lesen. Es kann jede Klausel gegen Ihren Standard vergleichen. Es kann jede Abweichung markieren, egal wie klein. Dann entscheidet ein Mensch, welche Abweichungen wesentlich sind und was damit zu tun ist. Laut der ABA's Legal Technology Survey 2024 verdreifachte sich die AI-Adoption im Rechtsberuf von 11 auf 30 Prozent in nur einem Jahr, wobei Genauigkeitsbedenken die primäre Zurückhaltung bleiben. Das ist genau das Governance-Modell, das dieses Pattern adressiert.
Das Pattern funktioniert in Legal-, Finanz-, HR-, Beschaffungs- und Compliance-Kontexten, überall dort, wo Dokumente gegen einen bekannten Standard geprüft werden müssen. Und der Predict-Schritt in diesem Pattern tut etwas Spezifisches, das klar zu verstehen sich lohnt: Er prognostiziert keine Zukunft. Er vergleicht das aktuelle Dokument mit einer Vorlage und bewertet die Abweichung.
Die Formel: Ingest, Analyze, Predict, Generate
Ingest (Dokument) erfasst das Dokument in verarbeitbarer Form. Das könnte ein in ein Review-Tool hochgeladenes PDF-Vertrag sein, ein als E-Mail-Anhang erhaltenes Word-Dokument, ein in einem Lieferantenportal geteilter SOC-2-Bericht oder ein Batch von aus einem HR-System exportierten Mitarbeitervereinbarungen. Der Ingest-Schritt konvertiert das Dokument in eine strukturierte Darstellung, die das Modell parsen kann: sauberer Text mit Seitenmarkierungen, Abschnittsgrenzen und erhaltenen Formatierungshinweisen.
Analyze (Klauseln, Felder, Entitäten extrahieren) liest das Dokument und identifiziert seine Struktur. Für einen Vertrag bedeutet das das Lokalisieren: der Parteien, des Inkrafttretensdatums, des anwendbaren Rechts, jedes definierten Begriffs und jeder inhaltlichen Klausel (Freistellung, Haftungsbeschränkung, Zahlungsbedingungen, Kündigung, geistiges Eigentum, Datenverarbeitung). Das Modell beschriftet jedes extrahierte Element nach Typ. Das ist keine bloße Textextraktion. Es ist semantische Extraktion. Das Modell versteht, dass "Jede Partei kann diese Vereinbarung mit einer Frist von 30 Tagen schriftlich kündigen" eine Kündigungsklausel mit einer 30-Tage-Kündigungsfrist ist, nicht nur ein Satz, der das Wort "kündigen" enthält.
Predict (gegen Standard vergleichen, Abweichungen bewerten) ist der Schritt, der diesem Pattern seinen Namen gibt. Und es ist wichtig, präzise zu sein, was "Predict" hier bedeutet: Das ist keine Prognose zukünftiger Ergebnisse. Der Predict-Schritt vergleicht die extrahierte Klausel mit einer Referenzvorlage und erzeugt einen Abweichungs-Score. Im Wesentlichen fragt er: "Wie sehr weicht diese Klausel von unserem Standard ab, und ist diese Abweichung wesentlich?" Eine Zahlungsklausel, die "Netto 60" besagt, entspricht dem Standard des Unternehmens. Eine Zahlungsklausel, die "Netto 15 mit einer Verzugszinsegebühr von 2 Prozent ab Tag 5" besagt, weicht erheblich vom Standard ab. Predict bewertet diese Abweichung und klassifiziert sie: vorhanden vs. fehlend, Standard vs. Nicht-Standard, innerhalb des akzeptablen Bereichs vs. Ausnahme.
Generate (Flaggen-Liste, Redlines, Ausnahmen-Zusammenfassung) produziert das Review-Ergebnis. Das ist ein strukturiertes Dokument, das jede erkannte Ausnahme, die relevante extrahierte Klausel oder das Feld, die Abweichung vom Standard und eine Schweregrad-Bewertung auflistet. Für das Vertrags-Review könnte Generate auch eine Reihe von vorgeschlagenen Redlines produzieren: "Klausel 7.2 durch die Standard-Freistellungssprache des Unternehmens ersetzen." Das Ergebnis ist ein Review-Arbeitspaket für einen Menschen: keine Entscheidung, keine Rechtsauskunft, sondern eine vollständige, nachvollziehbare Flaggen-Liste, die ein Reviewer in 20 Minuten statt zwei Stunden durcharbeiten kann.
Key Facts: AI-Adoption und Auswirkung bei Document Review
- AI-Adoption im Rechtsberuf verdreifachte sich von 11 auf 30 Prozent in nur einem Jahr, wobei Genauigkeitsbedenken die primäre Zurückhaltung bleiben (ABA Legal Technology Survey, 2024)
- AI Document Review reduziert die Kosten pro Vertrag von 300-800 Euro in Anwaltszeit auf 20-80 Euro pro Vertrag einschließlich AI-Verarbeitungs- und Ops-Review-Zeit, eine 80-90-prozentige Kostenreduktion (Thomson Reuters Legal AI Benchmark, 2024)
- Organisationen, die AI Document Review einsetzen, wechseln von einer 20-40-prozentigen gründlichen Vertragsprüfung zu 95-100 Prozent AI-First-Pass-Abdeckung, mit einer 85-95-prozentigen Erkennungsrate bei trainierten Abweichungstypen gegenüber 70-80 Prozent bei manueller Stichprobennahme (Gartner Legal Ops Report, 2025)
Die Template-Comparison-Methode
Document Review liefert Wert durch einen präzisen Vergleichsmechanismus: Der Predict-Schritt misst den Abweichungsabstand zwischen einer extrahierten Klausel und einem Referenzstandard und klassifiziert dann diese Abweichung nach Schweregrad. Das erfordert drei Inputs: die extrahierte Klausel aus dem eingereichten Dokument, den Referenzstandard des Unternehmens für diesen Klauseltyp und einen kalibrierten Schweregrad-Schwellenwert, der wesentliche Abweichungen von akzeptablen Variationen unterscheidet. Ohne einen klar definierten Referenzstandard hat der Predict-Schritt keine Baseline, gegen die er vergleichen kann, und der Output wird zu allgemeinen Kommentaren statt zu spezifischen Abweichungs-Flags. Die Template-Comparison-Methode macht den Referenzstandard genauso wichtig wie das AI-Modell. Teams sollten genauso viel Aufwand in die Definition und Pflege ihrer Klauselbibliothek investieren wie in die Auswahl und Konfiguration des Review-Tools.
Was "Predict" in diesem Pattern bedeutet
Eines der häufigsten Missverständnisse, wenn Teams Document Review zum ersten Mal kennenlernen, ist die Erwartung, dass der Predict-Schritt Ergebnisse prognostiziert: "Wird dieser Vertrag ein Problem?" Das wird er nicht zuverlässig tun, und dafür ist das Pattern nicht konzipiert.
Predict in Document Review ist vergleichsbasiert. Das Modell fragt: Stimmt diese Klausel mit einem Referenzstandard überein oder weicht sie davon ab? Schließt diese Versicherungspolice diese Abdeckungsanforderung ein oder aus? Erfüllt oder scheitert dieser Lieferanten-SOC-2-Bericht an dieser Kontrollanforderung? Das ist eine Klassifizierungsaufgabe, keine Prognoseaufgabe.
Der Referenzstandard ist der Schlüssel-Input für den Predict-Schritt. Ohne einen definierten Standard (Ihre bevorzugten Vertragsbedingungen, Ihre Compliance-Checkliste, Ihre erforderlichen Versicherungsdeckungsniveaus) gibt es nichts, gegen das verglichen werden kann, und der Predict-Schritt hat keinen Referenzpunkt. Teams, die Document Review deployen, ohne den Vergleichsstandard zu definieren, erhalten keine nützlichen Outputs. Für das vollständige Bild davon, wie Predict als ACE-Capability funktioniert, siehe Predict: Wie AI Geschäftsergebnisse prognostiziert.
Fünf reale Beispiele im Detail
1. NDA-Review
Das Operations-Team eines Startups erhält monatlich 40 NDAs von Lieferanten, potenziellen Mitarbeitern und Partnerschaftsgesprächen. Jede NDA sollte auf Folgendes geprüft werden: gegenseitige vs. einseitige Vertraulichkeit (einseitige NDAs, bei denen das Startup die einzige offenbarende Partei ist, sind ein Red Flag), Gerichtsbarkeit (der Standard des Unternehmens ist Delaware; alles andere erfordert rechtliche Überprüfung), Fortbestandsklausel (wie lange gilt die Vertraulichkeitspflicht nach der Kündigung?) und Ausnahmen für allgemein bekannte Informationen.
Das Modell nimmt jede NDA auf. Analyze extrahiert jede der Zielklauseln. Predict vergleicht: Ist sie gegenseitig? Ist die Gerichtsbarkeit Delaware? Liegt der Fortbestandszeitraum im Standardbereich? Erscheint die Standard-Ausschlussliste (allgemein bekannte Informationen, unabhängig entwickelt, von einem Dritten erhalten)?
Generate produziert eine einseitige Flaggen-Zusammenfassung pro NDA: grün (keine Ausnahmen), gelb (geringfügige Abweichungen) oder rot (erhebliche Ausnahmen). Das Operations-Team leitet grüne NDAs direkt zur Ausführung, gelbe NDAs zu einer schnellen rechtlichen Stichprobenprüfung und rote NDAs zur vollständigen rechtlichen Überprüfung weiter.
Vor diesem System ging jede NDA an Legal. Danach werden 60-70 Prozent direkt weitergeleitet, und die Legal-Zeit konzentriert sich auf die, die sie wirklich brauchen.
2. Lieferanten-MSA-Review
Ein Beschaffungsteam verwaltet 80 aktive Lieferantenverträge und bearbeitet 25 neue Lieferanten-MSAs pro Quartal. Die Review-Checkliste umfasst: Zahlungsbedingungen (60-Tage-Standard), IP-Eigentumsschaft (das Unternehmen muss alle im Rahmen der Vereinbarung entwickelten Arbeitsergebnisse besitzen), Datenverarbeitungszusatz (erforderlich für alle Lieferanten mit Zugang zu personenbezogenen Daten), Haftungsbeschränkung (begrenzt auf 12 Monate des Vertragswerts) und automatische Verlängerungsklauseln (müssen eine 90-tägige Kündigungsfrist haben).
Das Modell extrahiert jede Klauselkategorie aus der eingereichten MSA. Predict vergleicht gegen die Standard-Klauselbibliothek. Häufige gefundene Abweichungen: Lieferanten, die ihre eigenen Standardbedingungen mit Zahlung bei Netto 30 einreichen (Abweichung), IP-Eigentumsklauseln, die vorhandenes Lieferanten-IP ausklammern, ohne eine klare Definition dessen, was das beinhaltet (Zweideutigkeits-Flag), und automatische Verlängerungsbestimmungen, die eine Kündigungsfrist von mehr als 120 Tagen erfordern (Abweichung vom 90-Tage-Standard).
Generate produziert eine Abweichungstabelle mit Klauseltext, Unternehmensstandard und einem vorgeschlagenen Redline für jede Abweichung. Das Legal-Team überprüft die Abweichungstabelle (was 30 Minuten dauert) statt die vollständige MSA von Grund auf.
Tools in diesem Bereich: Ironclad, ContractPodAi, Luminance und Kira Systems sind die wichtigsten spezifisch entwickelten Vertrags-Review-Plattformen. Allgemeine Ansätze mit LLMs und strukturierten Extraktions-Prompts werden auch von kleineren Teams häufig verwendet.
3. Versicherungspolice-Vergleich
Ein Risk Manager muss verifizieren, dass die neuen Allgemein-Haftpflicht-, E&O- und Cyber-Versicherungspolicen des Unternehmens die in der Versicherungsrichtlinien-Checkliste des Unternehmens angegebenen Mindestabdeckungsanforderungen erfüllen. Die Checkliste legt fest: Mindestdeckungsbeträge pro Schadensfall und aggregiert, erforderliche Zusätze, Anforderungen an die Trägerbewertung und verbotene Ausschlüsse.
Das Modell nimmt jedes Policen-Dokument auf (oft dichte, 40-80-seitige PDFs mit Querverweisen zwischen Abschnitten). Analyze extrahiert die Deckungslimits, Zusätze, Ausschlüsse und Trägerinformationen. Predict vergleicht jeden extrahierten Wert gegen die Checklisten-Anforderungen: Erfüllt das Limit pro Schadensfall der Cyber-Police das Minimum von 5 Millionen US-Dollar? Schließt es den erforderlichen Betriebsunterbrechungs-Zusatz ein? Enthält der Ausschlussabschnitt einen der verbotenen Ausschlusstypen?
Generate produziert eine Abdeckungs-Compliance-Matrix: jede Anforderung, die Police-Bestimmung und einen Bestanden/Nicht bestanden/Flag-Status. Lücken werden mit der spezifischen Klauselsprache hervorgehoben, die die Lücke erzeugt.
4. Security-Lieferanten-SOC-2-Review
Ein Information-Security-Team überprüft jährlich 35 SOC-2-Type-II-Berichte von Cloud-Lieferanten. Jeder Bericht sollte gegen die Lieferantensicherheitsanforderungen des Unternehmens geprüft werden: abgedeckte spezifische Kontrollkategorien (Verfügbarkeit, Vertraulichkeit, Verarbeitungsintegrität), uneingeschränktes vs. eingeschränktes Prüfungsurteil, spezifische vom Unternehmen geforderte Kontrollen und der Berichtszeitraum (muss innerhalb von 12 Monaten aktuell sein).
Manuelle SOC-2-Review dauert 3-4 Stunden pro Bericht und erfordert einen Analysten mit spezifischen Kenntnissen der SOC-2-Struktur und Kontrollsprache. Das Modell nimmt jeden SOC-2-Bericht auf und extrahiert: abgedeckte Trust-Service-Kategorien, Prüfungsunternehmen und Urteilstyp, Berichtszeitraum und ob spezifische erforderliche Kontrollen (Verschlüsselung im Ruhezustand, Zugriffskontrollen, Incident-Response-Verfahren) in den getesteten Kontrollen erscheinen.
Predict markiert: Berichte mit eingeschränkten Urteilen (erfordert vollständige Sicherheitsteam-Review), fehlende erforderliche Kontrollkategorien und Berichte mit einem Enddatum des Zeitraums, das älter als 12 Monate ist. Generate produziert eine Lieferantensicherheits-Review-Zusammenfassung mit Bestanden/Nicht-bestanden-Status und den spezifischen Flags, die Follow-up erfordern.
5. Medizinische Chart-Review auf Dokumentationsvollständigkeit
Eine Arztpraxis muss verifizieren, dass Patientenakten Dokumentationsstandards für Abrechnung und Versorgungskontinuität erfüllen. Akten müssen enthalten: eine Problemliste, eine Medikationsabgleich-Notiz, dokumentierte Einwilligung nach Aufklärung für Eingriffe und einen von dem behandelnden Arzt unterzeichneten Versorgungsplan. Fehlende Dokumentation erzeugt Abrechnungsrisiken und Versorgungskontinuitätslücken.
Das Modell nimmt jede Akte auf (oft ein strukturiertes PDF aus dem EHR-Export). Analyze extrahiert: ob jedes erforderliche Dokumentationselement vorhanden ist, wer jeden Abschnitt unterzeichnet hat und ob Daten innerhalb der erforderlichen Zeitrahmen liegen. Predict bewertet jede Akte auf Vollständigkeit gegen den Dokumentationsstandard.
Generate produziert einen Dokumentationsvollständigkeitsbericht pro Akte: welche Elemente vorhanden sind, welche fehlen und welche vor der Abrechnungseinreichung eine zusätzliche Unterschrift oder Datumsprüfung erfordern. Der Praxismanager überprüft Flags statt jede Akte erneut zu lesen.
Fehlerquellen: Was Document Review zum Scheitern bringt
| Fehlerquelle | Grundursache | Maßnahme |
|---|---|---|
| Neuartige Klauseltypen | Ein Klauseltyp, den das Modell im Training nicht gesehen hat, wird als bekannter Typ falsch klassifiziert oder vollständig ignoriert | Ein "nicht klassifizierte Klausel"-Flag in den Output einbauen. Jedes Klauselsegment, das keinem bekannten Typ zugeordnet werden kann, sollte explizit für die menschliche Überprüfung sichtbar gemacht werden. |
| Querverweisfehler | Klausel in Abschnitt 3 modifiziert Klausel in Abschnitt 12 wesentlich; das Modell überprüft jede isoliert | Einen Querverweis-Prüfungsdurchlauf während Analyze einbauen: wenn Klausel A eine andere Sektion referenziert, beide extrahieren und als Verbundklausel behandeln. Das ist die technisch anspruchsvollste Fehlerquelle. |
| False-Flag-Fatigue | Modell markiert jede geringfügige Abweichung unabhängig von der Wesentlichkeit; Reviewer beginnen, Flags zu ignorieren | Schweregradbewertung kalibrieren. Nicht alle Abweichungen sind gleich wesentlich. Dreistufiges Flagging einbauen: Rot (wesentliche Abweichung, die eine rechtliche Entscheidung erfordert), Gelb (Abweichung innerhalb akzeptablen Bereichs, Review empfohlen), Grün (keine Ausnahme). |
| Konfidenz-Übertreibung | Modell meldet "Standardfreistellungssprache", wenn die Klausel subtile Änderungen hat, die nicht in seinem Training-Set sind | Per-Klausel-Konfidenz-Scores im Output verlangen. Jede Klausel mit Konfidenz unter 80 Prozent für menschliche Überprüfung sichtbar machen, unabhängig vom Flag-Status. |
| Standard-Dokument-Drift | Die Standardvertragsbedingungen des Unternehmens wurden vor sechs Monaten aktualisiert; das Modell vergleicht immer noch gegen den alten Standard | Den Referenzstandard als versioniertes Dokument behandeln. Vergleichsstandard überprüfen und aktualisieren, wann immer sich Vorlagen ändern. |
| Kontext-Kollaps | Definierter Begriff in Abschnitt 1 ändert die Bedeutung einer Klausel in Abschnitt 14; Modell interpretiert Abschnitt 14 ohne die Definition | Definierte Begriffe aus Abschnitt 1 in den Analysekontext für jede Klausel injizieren. Das ist eine Prompt-Engineering-Anforderung, kein Datenproblem. |
False-Flag-Fatigue ist in Legal Operations besonders schädlich, weil sie das ursprüngliche Problem, das gelöst werden sollte, imitiert. Ein Vertrags-Review-Prozess, der 80 Prozent der Verträge als Rechtliches-Review-Bedarf markiert, ist nur manuelles Review mit extra Schritten. Gut kalibrierte kommerzielle Document-Review-Tools zielen auf eine 25-35-prozentige Rate von Verträgen ab, die für menschliches Follow-on markiert werden, und konzentrieren die Legal-Aufmerksamkeit auf die wirklich wesentlichen Ausnahmen statt Volumen zu erzeugen (Ironclad Customer Benchmark Report, 2025).
Querverweisfehler verdient ein spezifisches Beispiel, weil es die Fehlerquelle mit den höchsten Kosten ist. Ein Vertrag könnte eine Freistellungsklausel in Abschnitt 7 haben, die isoliert betrachtet standard aussieht. Aber Abschnitt 2 definiert "Schäden" auf eine Weise, die den Umfang dessen, was "Schäden" in Abschnitt 7 bedeutet, dramatisch erweitert. Ein Modell, das Abschnitt 7 liest ohne die Abschnitt-2-Definition anzuwenden, produziert eine falsche "Standard-Klausel"-Bewertung. Die einzige Maßnahme ist der Aufbau eines Querverweis-Analyseschritts. Aber viele kommerzielle Tools tun das nicht gut. Siehe Halluzinationsrisiko nach AI-Pattern für die vollständige Fehlerquellen-Karte.
Die Governance-Grenze: Flaggen-Liste, keine Rechtsauskunft
Dieser Punkt ist so wichtig, dass er sowohl im Governance-Abschnitt dieses Artikels als auch im Fazit erscheint, weil es der häufigste Governance-Fehler ist, den Teams machen.
Der Output von Document Review ist eine Flaggen-Liste. Er ist keine Rechtsauskunft.
AI Document Review sagt Ihnen, was von Ihrem Standard abweicht. Er sagt Ihnen nicht, ob diese Abweichung rechtlich bedeutsam ist, ob ein Gericht sie durchsetzen würde, ob sie ein akzeptables Geschäftsrisiko in dieser spezifischen Beziehung darstellt oder welche Verhandlungsposition einzunehmen ist.
Das sind rechtliche Urteile. Sie erfordern einen Anwalt. Die AI beschleunigt die Arbeit, zu identifizieren, was rechtliches Urteil erfordert. Sie ersetzt das Urteil selbst nicht.
Der Governance-Fehler: Ein Beschaffungs-Operations-Team beginnt, Document-Review-Outputs zu nutzen, um Unterzeichnungs-/Nicht-Unterzeichnungs-Entscheidungen zu treffen, ohne Abweichungen an Legal weiterzuleiten. Das funktioniert bei 90 Prozent der Verträge, bei denen die Abweichungen tatsächlich geringfügig sind. Es scheitert kostspielig bei den 10 Prozent, bei denen eine Abweichung, die routine erschien, wesentliche rechtliche Konsequenzen hat.
Das richtige Betriebsmodell:
- AI Document Review läuft bei jedem Vertrag
- Output geht an einen definierten Reviewer (Legal, Ops, Compliance, je nach Vertragstyp und Risikoniveau)
- Der Reviewer trifft die Entscheidung über jedes Flag, nicht die AI
- Hochrisiko-Flags (Rot-Tier) gehen für rechtliches Urteil an einen Anwalt
- Niedrigrisiko-Flags (Grün-Tier) können ohne rechtliche Beteiligung von Ops genehmigt werden
- Die Grenze zwischen "Ops kann entscheiden" und "Legal muss entscheiden" ist explizit definiert und wird jährlich überprüft
Audit-Trails sind hier ebenfalls wichtig. Regulierte Branchen (Finanzdienstleistungen, Gesundheitswesen, öffentliche Unternehmen) müssen möglicherweise nachweisen, dass Vertrags-Review-Entscheidungen von qualifizierten Menschen mit Zugang zu vollständigen Informationen getroffen wurden. Eine Flaggen-Liste mit menschlicher Unterzeichnung erfüllt diese Anforderung. Ein reines AI-Review tut es nicht. Die DSGVO und ähnliche Datenschutzbestimmungen verlangen dokumentierte Entscheidungsprozesse für jede automatisierte Verarbeitung personenbezogener Daten, und Lieferantenverträge enthalten routinemäßig solche Daten.
Wann Document Review funktioniert (und wann nicht)
Funktioniert gut wenn:
- Sie einen klaren, dokumentierten Standard haben, gegen den verglichen werden kann. "Ist diese NDA gegenseitig?" ist ein definierter Vergleich. "Ist dieser Vertrag fair?" ist es nicht.
- Dokumente einer vorhersehbaren Struktur folgen. Standard-Handelsvereinbarungen (NDAs, MSAs, Arbeitsverträge, Versicherungspolicen) haben genug strukturelle Konsistenz, dass Klauselextraktion zuverlässig ist. Ungewöhnliche oder stark angepasste Dokumenttypen erfordern mehr Konfiguration.
- Das Pattern routinemäßige Abweichungserkennung ist, keine Ausnahmeanalyse. Document Review ist ausgezeichnet darin, die 80 Prozent der Abweichungen zu finden, die klar außerhalb des Standards liegen. Es ist weniger zuverlässig bei den nuancierten 20 Prozent, die kontextuelles Urteil erfordern.
vs. RAG Assistant: RAG Assistant beantwortet Fragen zu Dokumenten. "Was ist die Kündigungsfrist in diesem Vertrag?" ist eine RAG-Frage. Document Review führt strukturierte Compliance-Analyse gegen einen definierten Referenzwert durch. "Erfüllt die Kündigungsklausel unsere Standardanforderungen?" ist Document Review. Beide können der Reihe nach auf dasselbe Dokument angewendet werden.
vs. Generative Research: Generative Research synthetisiert über viele Quellen hinweg, um neue Erkenntnisse zu produzieren. Document Review prüft ein spezifisches Dokument gegen einen bekannten Standard. Unterschiedliche Inputs, unterschiedliche Outputs. Sie können kombiniert werden (Generative Research, um den Vergleichsstandard aus Markt-Benchmarks aufzubauen; Document Review, um diesen Standard auf eingehende Verträge anzuwenden), aber sie sind keine Alternativen.
vs. Vision Extract: Vision Extract ist oft der Schritt vor Document Review. Vision Extract extrahiert Felder und Text aus einem Bild oder PDF und erstellt den strukturierten Text, den das Document-Review-Modell analysieren kann. Für Verträge, die als gescannte PDFs eingehen (in manchen Branchen üblich), läuft Vision Extract zuerst, dann analysiert Document Review den extrahierten Text.
ROI-Signale: Wirkung messen
| Kennzahl | Manuelle Baseline | Mit Document Review | Typische Verbesserung |
|---|---|---|---|
| Review-Zeit pro Dokument | 2-4 Stunden (Anwalt) oder 45-90 Minuten (Ops, weniger gründlich) | 15-30 Minuten (Überprüfung der AI-Flaggen-Liste) | 75-85 Prozent Zeitreduktion |
| Dokument-Abdeckungsrate | 20-40 Prozent der Verträge gründlich überprüft | 95-100 Prozent AI-geprüft; 40-60 Prozent mit menschlichem Follow-on | Von Stichproben zu vollständiger Abdeckung |
| Ausnahme-Erkennungsrate | 70-80 Prozent der wesentlichen Abweichungen durch menschliche Überprüfung erkannt | 85-95 Prozent AI-Erkennungsrate für trainierte Abweichungstypen | 10-20 Prozent Verbesserung der Erkennungsrate |
| Kosten pro Vertrags-Review | 300-800 Euro (Anwaltszeit zu Marktpreisen) | 20-80 Euro (AI-Verarbeitungs- plus Ops-Review-Zeit) | 80-90 Prozent Kostenreduktion pro Vertrag |
| Legal-Team-Zeitumverteilung | 60-70 Prozent der Legal-Zeit für routinemäßiges Vertrags-Review | 20-30 Prozent für routinemäßiges Review; 70-80 Prozent für komplexe/wesentliche Arbeit | Legal-Team-Kapazität für höherwertige Arbeit |
Die Abdeckungsrate-Kennzahl ist oft die bedeutsamste. Der Wechsel von "20 Prozent der Verträge überprüft" zu "100 Prozent von AI überprüft und markierte Verträge von Menschen überprüft" verändert das Risikoprofil wesentlich. McKinseys Analyse von AI in Unternehmensfunktionen identifiziert Legal und Compliance als Bereiche, in denen AI überproportionalen Wert liefert, genau weil Abdeckung, nicht Geschwindigkeit, die bindende Einschränkung ist. Die Verträge, die bisher überhaupt nicht überprüft wurden, haben jetzt zumindest eine First-Pass-Abdeckung.
Rework Analysis: Der teuerste Document-Review-Governance-Fehler ist, die Flaggen-Liste das rechtliche Urteil ersetzen zu lassen. AI Document Review ist ausgezeichnet darin, Abdeckung zu skalieren: Es liest jeden Vertrag, vergleicht jede Klausel und hebt jede Abweichung hervor. Was es nicht kann, ist zu entscheiden, ob eine spezifische Abweichung im Kontext einer spezifischen Lieferantenbeziehung ein akzeptables Geschäftsrisiko darstellt. Das Urteil erfordert einen Anwalt. Die Teams, die keine Probleme bekommen, nutzen AI Document Review, um das "Wir haben es nicht erkannt, weil wir es nicht gelesen haben"-Problem zu eliminieren, und leiten jeden wesentlichen Flag an einen Anwalt weiter. Die Teams, die in Probleme geraten, nutzen AI Document Review, um die Anwaltsbeteiligung vollständig zu eliminieren, stellen fest, dass 10 Prozent der Abweichungen Kontext erfordern, den die AI nicht liefern kann, und enden damit, Klauseln zu bekämpfen, die sie in einem 10-minütigen Legal-Review hätten erkennen können.
Häufig gestellte Fragen
Was ist das Document-Review-AI-Pattern?
Document Review ist ein AI-Pattern, das spezifische Dokumente gegen einen definierten Referenzstandard prüft, um Abweichungen, fehlende Elemente oder Compliance-Lücken zu markieren. Die Formel lautet: Ingest (Dokument), Analyze (Klauseln und Entitäten extrahieren), Predict (extrahierte Klauseln mit Referenzstandard vergleichen und Abweichungen bewerten), Generate (Flaggen-Liste, Redlines oder Compliance-Zusammenfassung). Es skaliert die Review-Abdeckung von Stichproben auf vollständige Abdeckung, ohne die Anwaltszeit proportional zu skalieren.
Was ist die Template-Comparison-Methode?
Die Template-Comparison-Methode ist der Kernmechanismus des Predict-Schritts des Document-Review-Patterns. Sie misst den Abweichungsabstand zwischen einer extrahierten Klausel und dem Referenzstandard des Unternehmens für diesen Klauseltyp und klassifiziert dann die Abweichung nach Schweregrad. Die Methode erfordert drei Inputs: die extrahierte Klausel, die Referenzstandard-Klausel und einen kalibrierten Schweregrad-Schwellenwert. Ohne einen klar definierten Referenzstandard produziert der Predict-Schritt allgemeine Kommentare statt spezifische Abweichungs-Flags. Der Referenzstandard verdient genauso viel Investition wie das AI-Tool selbst.
Was ist der Unterschied zwischen Document Review und RAG Assistant?
RAG Assistant beantwortet Fragen zu Dokumenten. "Was ist die Kündigungsfrist in diesem Vertrag?" ist eine RAG-Frage. Document Review führt strukturierte Compliance-Analyse gegen einen definierten Referenzwert durch. "Erfüllt die Kündigungsklausel unsere Standard-30-Tage-Anforderung?" ist Document Review. Beide können der Reihe nach auf dasselbe Dokument angewendet werden und werden in Legal-Operations-Workflows häufig kombiniert.
Welchen ROI können Sie von AI Document Review erwarten?
AI Document Review reduziert die Kosten pro Vertrag von 300-800 Euro in Anwaltszeit auf 20-80 Euro pro Vertrag (80-90 Prozent Kostenreduktion). Die Abdeckungsrate verbessert sich von 20-40 Prozent gründlich überprüfter Verträge auf 95-100 Prozent AI-First-Pass-Abdeckung. Die Ausnahme-Erkennung verbessert sich von 70-80 Prozent für manuelle Stichprobennahme auf 85-95 Prozent für trainierte Abweichungstypen. Die Legal-Team-Zeit wird von 60-70 Prozent für routinemäßiges Review auf 20-30 Prozent umverteilt, was 70-80 Prozent für komplexe und wesentliche Arbeit freimacht.
Kann AI in Document Review rechtliche Entscheidungen treffen?
Nein. Der Output von Document Review ist eine Flaggen-Liste, keine Rechtsauskunft. AI sagt Ihnen, was von Ihrem Standard abweicht. Er bestimmt nicht, ob eine Abweichung rechtlich bedeutsam ist, ob ein Gericht sie durchsetzen würde, ob sie ein akzeptables Geschäftsrisiko darstellt oder welche Verhandlungsposition einzunehmen ist. Das sind rechtliche Urteile, die einen Anwalt erfordern. Das korrekte Betriebsmodell leitet wesentliche Flags (Rot-Tier) für rechtliches Urteil an einen Anwalt weiter. Operations-Teams können geringfügige Flags (Grün-Tier) ohne Anwaltsbeteiligung handhaben, aber nur wenn die Grenze zwischen "Ops kann entscheiden" und "Legal muss entscheiden" explizit definiert wurde.
Was sind die häufigsten Document-Review-Fehlerquellen?
Die sechs Hauptfehlerquellen sind: neuartige Klauseltypen (falsch klassifiziert oder ignoriert, weil sie nicht in den Trainingsdaten waren), Querverweisfehler (Klausel A modifiziert Klausel B, aber beide werden isoliert überprüft), False-Flag-Fatigue (zu viele Flags mit geringer Wesentlichkeit führen dazu, dass Reviewer die Queue ignorieren), Konfidenz-Übertreibung (Modell meldet "Standard-Sprache" für eine subtil modifizierte Klausel), Standard-Dokument-Drift (Referenzstandard wurde aktualisiert, aber Modell vergleicht immer noch gegen alte Version) und Kontext-Kollaps (definierte Begriffe aus Abschnitt 1 werden bei der Analyse von Klauseln in Abschnitt 14 nicht angewendet). Querverweisfehler haben die höchsten rechtlichen Kosten, weil sie falsche "Standard-Klausel"-Bewertungen für Klauseln produzieren, deren Umfang durch andere Abschnitte erweitert wurde.
Weitere Ressourcen
- Vision Extract: Bilder in strukturierte Daten verwandeln
- RAG Assistant: Das Retrieval-Augmented-Generation-Pattern
- Halluzinationsrisiko nach AI-Pattern
- Governance-Anforderungen nach AI-Pattern
- Das ACE-Framework: Eine Periodentafel für Business AI
- Warum 10 Patterns 90 Prozent der Business-AI-Anwendungen abdecken
- AI-Pattern-ROI messen

Co-Founder, Rework.com
On this page
- Die Formel: Ingest, Analyze, Predict, Generate
- Die Template-Comparison-Methode
- Was "Predict" in diesem Pattern bedeutet
- Fünf reale Beispiele im Detail
- 1. NDA-Review
- 2. Lieferanten-MSA-Review
- 3. Versicherungspolice-Vergleich
- 4. Security-Lieferanten-SOC-2-Review
- 5. Medizinische Chart-Review auf Dokumentationsvollständigkeit
- Fehlerquellen: Was Document Review zum Scheitern bringt
- Die Governance-Grenze: Flaggen-Liste, keine Rechtsauskunft
- Wann Document Review funktioniert (und wann nicht)
- ROI-Signale: Wirkung messen
- Weitere Ressourcen