Generative Research: Stunden des Lesens komprimieren
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Ein guter Analyst kann 30 Quellen zu einem kohärenten Briefing synthetisieren. Er weiß, welchen Quellen er vertrauen kann, welche er weniger gewichten soll, wie er die Spannung herausarbeitet, wenn zwei glaubwürdige Quellen voneinander abweichen, und wie er das Ergebnis für einen VP lesbar macht, der acht Minuten vor einem Board-Meeting hat.
Die meisten Teams können sich nicht genug Analysten leisten, um das gut, konsistent, für jeden Markt, Account und Wettbewerber zu tun, der sie interessiert. Die Account-Recherche vor einem Vertriebsgespräch wird übersprungen. Der Competitive-Intelligence-Bericht ist drei Wochen alt, wenn er genutzt wird. Die Due-Diligence eines potenziellen Akquisitionsziels ist oberflächlich, weil niemand Zeit hatte, tiefer zu gehen.
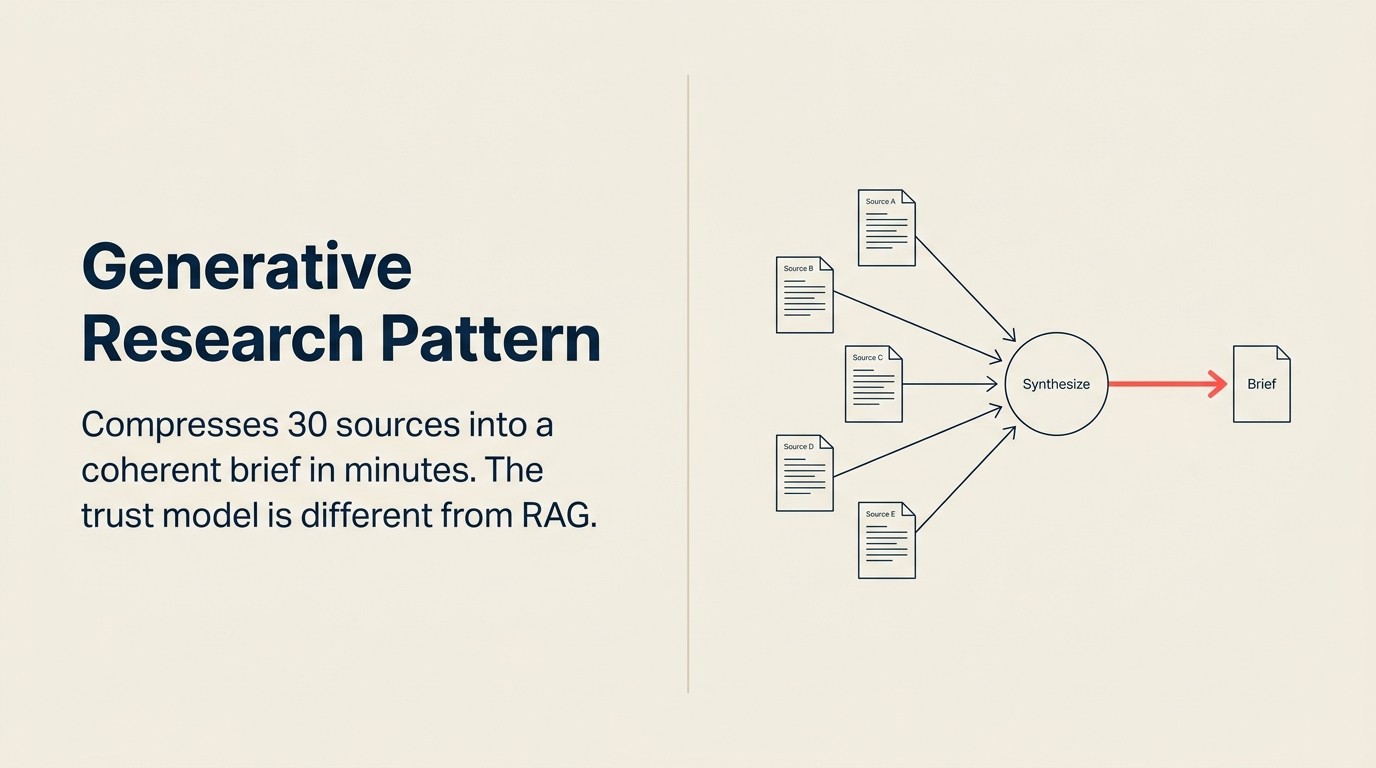
Generative Research ist das AI-Pattern, das diese Synthesearbeit auf Minuten komprimiert. Nicht dadurch, dass Analyse eliminiert wird, sondern durch Automatisierung des Lesens, der Querverweise und der ersten Strukturierung, die den Großteil der Zeit eines Analysten konsumiert. Das Urteil des Analysten zählt am Ende immer noch. Aber der Analyst beginnt mit einem 10-seitigen Briefing statt mit 30 Browser-Tabs.
Das Pattern bringt eine Vertrauensfrage mit sich, die sein verwandtes Pattern, der RAG Assistant, nicht hat. RAG retrievet aus einer bekannten, kontrollierten Wissensbasis. Generative Research durchforstet Live-, externe oder domänenübergreifende Quellen. Dieser Unterschied verändert, wie Verifizierung aussieht und wo Fehlerquellen sich konzentrieren.
Die Formel: Ingest, Analyze, Generate
Ingest (Multi-Source-Corpus) zieht das rohe Quellmaterial. Die Quellen hängen vom Use Case ab. Für Competitive Intelligence: Pressemitteilungen, G2- und Capterra-Bewertungen, LinkedIn-Stellenanzeigen, Konferenzaufzeichnungen, Earnings-Call-Transkripte, Fachpresse-Artikel. Für Account-Recherche: aktuelle Nachrichten des Zielunternehmens, LinkedIn-Profile der Führungskräfte, Branchenanalystenberichte, aktuelle Finanzierungsankündigungen, Wettbewerbererwähnungen. Für Executive-Trend-Synthesen: Earnings-Call-Transkripte von 10-20 öffentlichen Unternehmen im Sektor, Gartner- oder Forrester-Auszüge, Artikel auf Board-Niveau. Der Ingest-Layer übernimmt die Sammlung und erste Normalisierung: Konvertierung von PDFs, Webseiten, Transkripten und strukturierten Daten in lesbare Textfragmente.
Analyze (Synthetisieren) ist der anspruchsvollste Schritt in diesem Pattern. Das Modell fasst nicht jede Quelle unabhängig zusammen. Es liest alle Quellen gleichzeitig, identifiziert, worüber mehrere Quellen übereinstimmen (hochkonfidente Signale), hebt Stellen hervor, an denen Quellen in Konflikt stehen (Bereiche der Unsicherheit), extrahiert Named Entities und Schlüsselfakten und baut eine kohärente Interpretation dessen auf, was die Belege kollektiv aussagen. Diese Quell-übergreifende Synthese ist das, was Generative Research von einfacher Dokumentenzusammenfassung unterscheidet. Jede Quelle separat zusammenzufassen ist nicht das Pattern. Der Wert liegt in der Syntheseschicht. Siehe Analyze: Wie AI das Gesammelte versteht für die vollständige Capability-Definition.
Generate (Bericht, Briefing oder strukturierter Output) produziert das Ergebnis. Das könnte eine Wettbewerbsanalyse sein, die als abschnittsweises Briefing mit Zitaten formatiert ist, eine Account-Recherchekarte für einen CRM-Eintrag, ein Executive-Memo mit Stichpunkten und empfohlener Maßnahme oder eine Marktsizing-Tabelle mit Quellfußnoten. Der Generate-Schritt formatiert die synthetisierte Erkenntnis in das Ausgabeformat, das der Anfragende benötigt.
Dieses Pattern endet bei Generate. Es gibt keinen Execute-Schritt in der Basisformel. Das Ergebnis ist ein Entwurf, den ein Mensch überprüfen muss, bevor er irgendwo weitergeht. Für die meisten Generative-Research-Use-Cases ist diese menschliche Überprüfung nicht optional. Sie ist der Governance-Mechanismus, der das Pattern sicher für die Verteilung macht.
Key Facts: Auswirkung von Generative Research
- McKinsey schätzt, dass generative AI 60-70 Prozent der Zeit der Mitarbeiter, die derzeit für Wissensarbeitsaktivitäten aufgewendet wird, automatisieren kann, wobei Forschungssynthese als eine der Wissensarbeitsaktivitäten mit dem höchsten Wert genannt wird (McKinsey, 2023)
- Vertriebsreps schließen Pre-Call-Recherche bei 40-60 Prozent der Gespräche ohne AI-Unterstützung ab; mit AI-generierten Account-Briefings steigen die Pre-Call-Recherche-Abschlussraten auf 85-95 Prozent (Forrester B2B Sales AI Benchmark, 2025)
- AI-gestützte Competitive-Intelligence-Briefings synthetisieren 20-50 Quellen in 2-4 Stunden gegenüber 6-8 Stunden pro Analyst pro Wettbewerber bei manueller Recherche, eine 3-5-fache Quellabdeckungsverbesserung bei 85-90-prozentiger Zeitreduktion (Gartner Competitive Intelligence Report, 2025)
Das Multi-Source-Synthesis-Pattern
Der Kernwert von Generative Research ist nicht die Zusammenfassung einzelner Quellen. Es ist die Quell-übergreifende Synthese: herausfinden, worüber mehrere Quellen übereinstimmen (hochkonfidente Signale), hervorheben, wo Quellen in Konflikt stehen (Bereiche der Unsicherheit), und schlussfolgern, was die kombinierten Belege über das hinaus implizieren, was eine einzelne Quelle explizit aussagt. Ein Generative-Research-Deployment, das jede Quelle separat zusammenfasst und die Zusammenfassungen nebeneinander präsentiert, nutzt dieses Pattern nicht. Das Pattern erfordert einen Analyze-Schritt, der alle Quellen gleichzeitig liest und eine einheitliche Interpretation produziert. Diese Syntheseschicht ist es, was 30 Quellen zu einem kohärenten Briefing komprimiert, und sie unterscheidet Generative Research von einer Reihe zusammengefügter Zusammenfassungen.
Generative Research vs. RAG Assistant: die entscheidende Unterscheidung
Diese beiden Patterns werden in der Praxis am häufigsten verwechselt.
RAG Assistant retrievet Antworten aus einer kontrollierten, bekannten internen Wissensbasis. Sie wissen, was in der Wissensbasis ist (Ihre Produktdokumentation, vergangene Support-Tickets, HR-Richtlinien). Das Retrieval ist begrenzt. Die Antworten zitieren Quellen, die in Ihrem System existieren. Die Fehlerquelle ist das Retrieven des falschen Dokuments oder das Veralten der Wissensbasis. Keine Fabrikation aus dem offenen Web.
Generative Research synthetisiert aus einem Corpus, der oft extern, live oder domänenübergreifend ist. Die Quellen sind nicht in Ihrem System vorindiziert. Sie werden zum Anfragezeitpunkt aus Websuchen, API-Feeds, hochgeladenen Dokumenten oder Drittanbieterdatenbanken gezogen. Die Synthese kann Informationen hervorbringen, die keine einzelne Quelle explizit aussagt: Das Modell schlussfolgert aus der Kombination. Diese Schlussfolgerungsfähigkeit ist sowohl der Wert als auch das Risiko.
Die praktische Implikation: RAG-Outputs können verifiziert werden, indem die zitierte Quelle überprüft wird. Generative-Research-Outputs erfordern das Stichprobenchecken sowohl der zitierten Quelle (sagt die Quelle tatsächlich, was ihr zugeschrieben wird?) als auch der Syntheselogik (hält die Schlussfolgerung stand?). Unterschiedlicher Verifizierungsprozess, unterschiedliche Governance-Anforderung.
Fünf reale Beispiele im Detail
1. Competitive-Intelligence-Reporting
Ein VP of Product benötigt ein vierteljährliches Wettbewerbs-Update zu drei direkten Wettbewerbern. Jeder Wettbewerber hat eine Website, ein G2-Profil, ein aktives LinkedIn, aktuelle Pressemitteilungen und eine Handvoll Bewertungserwähnungen auf Reddit und Capterra. Das manuelle Lesen und Synthetisieren all dessen kostet einen Produktanalysten 6-8 Stunden pro Wettbewerber.
Ingest zieht aus all diesen Quellen: zum Abfrufzeitpunkt gescrapte Webseiten, nach Datum gefilterte G2-Bewertungen, LinkedIn-Posts und Stellenanzeigen, Pressemitteilungen und Nachrichtenerwähnungen. Analyze querverweist die Quellen: Welche Features erwähnen Reviewer in G2-Bewertungen konsistent, die nicht auf der eigenen Website des Unternehmens stehen? Was signalisiert die Stellenanzeige für "Head of Enterprise Sales" über ihre strategische Ausrichtung? Wo weichen zwei Quellen voneinander ab (eine Bewertung nennt die UX ausgezeichnet; eine andere markiert sie als Schwachpunkt)?
Generate produziert ein strukturiertes Briefing: Produktupdates im Quartal, Positionierungsverschiebungen, Preissignale aus Bewertungen, Talentsignale aus Stellenanzeigen und Schlüsselzitate aus Drittquellen. Das Ergebnis ist als einseitige Zusammenfassung mit ausklappbaren Abschnitten für jede Quellkategorie formatiert.
Die menschliche Überprüfung prüft: Kommen die zitierten Aussagen tatsächlich aus den zitierten Quellen? Halten die inferrierten strategischen Schlussfolgerungen unter Prüfung stand?
Tools, die das unterstützen: Perplexity API, Tavily für Web-Search-Grounding, Claude und GPT-4 mit Suchtools sowie speziell entwickelte Competitive-Intelligence-Plattformen wie Crayon, Klue und Battlecards.
2. Account-Recherche-Briefing vor einem Vertriebsgespräch
Eine Vertriebsdirektorin hat in 90 Minuten ein Gespräch mit einem VP of Operations bei einem Fertigungsunternehmen, mit dem sie noch nie gesprochen hat. Sie muss wissen: Was passiert bei diesem Unternehmen, was ihre jüngsten Herausforderungen sind, wer die Stakeholder sind und wie der Branchenkontext aussieht.
Ingest zieht: aktuelle Pressemitteilungen und Nachrichtenberichterstattung des Unternehmens (letzte 90 Tage), das LinkedIn-Profil des Interessenten und aktuelle Aktivitäten, aktuelle öffentliche Kommentare von CEO und CFO, Branchennachrichten aus Fertigungs-Fachmedien und vorhandene CRM-Daten und vergangene E-Mail-Threads.
Analyze hebt hervor: eine kürzliche Übernahme, die die Supply-Chain-Prioritäten verändert hat, ein LinkedIn-Post des Interessenten, der operative Komplexität als Herausforderung erwähnt, ein Earnings-Call-Zitat des CEO über "operative Effizienz" als Priorität für 2026 und ein Muster in jüngsten Einstellungen, das darauf hindeutet, dass sie ein Datenteam aufbauen.
Generate produziert ein zweiseitiges Pre-Call-Briefing: wichtiger Unternehmenskontext (2 Stichpunkte), jüngste Entwicklungen (3 Stichpunkte), Kontakthintergrund (2 Stichpunkte), wahrscheinliche Prioritäten basierend auf Belegen (3 Stichpunkte mit Quellen) und vorgeschlagene Eröffnungsfragen, die mit den Erkenntnissen verknüpft sind. Der Rep überprüft das in 8 Minuten, passt die Eröffnungsfrage basierend auf seinem eigenen Wissen an und nutzt das Briefing als Kontext statt als Skript.
Dieses Pattern ist in Salesforce Einsteins "Account Summaries", HubSpots AI-Research-Features eingebaut und ist der Kern von speziell entwickelten Tools wie Apollo.ios AI-Recherche und Warmly. Für die vollständige vertriebsspezifische Version dieses Use Cases, siehe AI Account Research vor dem ersten Kontakt.
3. Executive-Branchen-Trend-Synthese
Ein CFO bei einem Healthcare-Technologieunternehmen möchte ein 20-minütiges Briefing vor einem Board-Meeting zu "Wie AI Healthcare-Revenue-Cycles beeinflusst." Diese Synthese erfordert normalerweise das Lesen von 6-8 Analystenberichten, 3 Earnings-Call-Transkripten von relevanten öffentlichen Unternehmen und einem Dutzend Fachpresse-Artikeln.
Ingest zieht aus Gartner-Auszügen (falls verfügbar), HIMSS-Konferenzberichterstattung, Earnings-Call-Transkripten von Health-IT-Unternehmen (Veeva, Epic-Partner, Waystar), Fachpresse von Healthcare IT News und Health Data Management sowie VC-Investitionsankündigungen in dem Bereich.
Analyze identifiziert die Konsensthemen (Automatisierung der Claims-Abrechnung wird konsistent in 7 von 10 Quellen hervorgehoben), die aufkommenden Debatten (welche AI-Anbieter tatsächlich liefern vs. versprechen) und die wichtigsten zitierten Unternehmen. Es prüft auch auf widersprüchliche Signale (eine Quelle prognostiziert 30 Prozent Reduktion der Admin-Kosten; ein anderer Analystenreport bezeichnet das als "optimistisch").
Generate produziert ein zweiseitiges Briefing: drei Konsensthemen mit Belegen, zwei Bereiche aktiver Meinungsverschiedenheit explizit markiert, fünf beobachtenswerte Unternehmen und ein Abschnitt "Fragen, die Sie wahrscheinlich erhalten" mit vorgeschlagenen Antworten. Der CFO kann das als informierten Kommentar präsentieren, nicht als AI-generierten Text.
4. Marktsizing mit zitierten Quellen
Der Head of Business Development eines Startups benötigt eine grobe Marktsizing-Schätzung für ein neues Segment vor einem Fundraising-Meeting. Die TAM/SAM/SOM-Analyse muss vertretbar sein: keine magische Zahl, sondern eine nachvollziehbare Schätzung mit Quellen, die ein VC überprüfen kann.
Ingest zieht: Branchenanalysten-Berichte, staatliche statistische Datenbanken (BLS, Census), Earnings Calls öffentlicher Unternehmen, die das Segment erwähnen, und aktuelle Startup-Finanzierungsrunden in dem Bereich mit ihren implizierten Marktannahmen.
Analyze querverweist die Sizing-Schätzungen aus mehreren Quellen: ein Analyst sagt 12 Milliarden US-Dollar TAM, das S-1 eines Wettbewerbers impliziert 9 Milliarden, ein Gartner-Report von 2024 sagte 8 Milliarden wachsend mit 14 Prozent. Es identifiziert die methodologischen Unterschiede (einer zählt nur Software; ein anderer schließt Dienstleistungen ein). Es hebt die Bandbreite vertretbarer Schätzungen und die Annahmen hervor, die jede antreiben.
Generate produziert ein Marktsizing-Memo: Methodologie-Abschnitt, drei Szenarien (konservativ/Basis/optimistisch), Quellenzitate pro Zahl und ein einzeiliger "Wie man das verteidigt"-Hinweis für das Fundraising-Meeting.
5. M&A-Due-Diligence-Desk-Research
Das Strategie-Team eines Erwerbers benötigt eine vorläufige Einschätzung eines Zielunternehmens vor dem formellen Engagement. Sie wollen nur Public-Source-Intelligence, bevor sie eine NDA unterzeichnet haben. Das ist Desk-Research, keine vollständige Due Diligence, aber sie muss gründlich sein.
Ingest zieht: Website und Produktdokumentation des Ziels, alle öffentlichen Presseberichte, LinkedIn-Daten zu Mitarbeiterzahl und Wachstumstrend (ein Proxy für finanzielle Performance), Glassdoor-Bewertungen für Kultursignale, Crunchbase für Finanzierungsgeschichte und Investorennamen, G2 für Kundenstimmung und Patentanmeldungen, falls relevant.
Analyze synthetisiert: Umsatzbereichsschätzung aus Finanzierung plus Wachstumssignale, Team-Qualitäts- und Fluktuation-Signale aus LinkedIn und Glassdoor, Produktdifferenzierungsbewertung aus öffentlichen Materialien und Bewertungen, Wettbewerbspositionierung im Kontext anderer Übernahmen in dem Bereich.
Generate produziert ein Due-Diligence-Memo in dem vom Strategie-Team verwendeten Format: Geschäftsübersicht, Finanzschiätzungen mit Konfidenzlevels, Team-Bewertung, Produkt-Bewertung, Risiko-Flags und offene Fragen für den formellen Due-Diligence-Prozess.
Fehlerquellen: Was Generative Research zum Scheitern bringt
| Fehlerquelle | Grundursache | Maßnahme |
|---|---|---|
| Konfabulation | Modell füllt Lücken zwischen realen Quellen mit plausibel klingenden Behauptungen, die keine Quelle tatsächlich unterstützt | Zitate pro Behauptung verlangen. 3-5 Zitate pro Briefing vor der Verteilung stichprobenchecken. Nie ohne einen namentlich genannten menschlichen Reviewer, der die Quellen geprüft hat, verteilen. |
| Quellaktualitäts-Verzögerung | Web-Search-Index ist 2-3 Tage hinterher; interne Dokumentensynthese ist nur so aktuell wie der letzte Index-Lauf | Crawl- oder Index-Zeitstempel in den Output einschließen. Zeitkritische Behauptungen mit ihrem Quelldatum markieren. Für Live-Wettbewerbs- oder Marktinformationen Schlüsselbehauptungen direkt verifizieren. |
| Widerstreitende Quellen als einheitlich dargestellt | Modell wählt eine Interpretation, wenn Quellen nicht übereinstimmen, ohne die Meinungsverschiedenheit zu markieren | Explizites Konflikt-Hervorheben im Prompt verlangen: "Wenn Quellen zu diesem Thema nicht übereinstimmen, markieren Sie die Meinungsverschiedenheit und zitieren Sie beide Seiten." Jedes Briefing, das alles als Konsens präsentiert, mit Misstrauen behandeln. |
| Citation Laundering | Modell zitiert eine reale, glaubwürdige Quelle für eine Behauptung, die diese Quelle tatsächlich nicht macht | Zitate stichprobenchecken: nicht nur dass die Quelle existiert, sondern dass die zitierte Passage die zugeschriebene Behauptung unterstützt. Das ist die hinterhältigste Fehlerquelle, weil sie autoritativ aussieht. |
| Scope-Drift | Offene Prompts produzieren 40-seitige Outputs, die umfassend, aber nicht nutzbar sind | Scope präzise definieren: Zeitraum, Quellentypen, Ausgabeformat und Wortlimit. Engere Prompts produzieren nützlichere Outputs als breite. |
| Single-Source-Bias | Eine dominante, hochqualitative Quelle überwältigt die Synthese; der Output spiegelt eine Perspektive wider, nicht eine Multi-Source-Sicht | Quellenverteilung im Output prüfen. Wenn 80 Prozent der Zitate auf eine Quelle verweisen, macht die Synthese nicht ihren Job. |
Citation Laundering ist die hinterhältigste Fehlerquelle, weil sie Outputs produziert, die autoritativ aussehen. Ein Briefing, das einen realen Gartner-Bericht für eine Behauptung zitiert, die dieser Bericht tatsächlich nicht macht, übersteht eine oberflächliche Überprüfung und scheitert unter Prüfung. Die Bewertung von führenden LLMs zur Zitiergenauigkeit durch Stanford HAI aus dem Jahr 2024 ergab, dass 23 Prozent der automatisch generierten Zitate in Langform-Synthese-Aufgaben entweder eine Quelle zitierten, die die zugeschriebene Behauptung nicht enthielt, oder die Position der Quelle leicht falsch darstellten. Das macht Generative Research nicht unbrauchbar. Es macht die 15-minütige menschliche Überprüfung nicht verhandelbar.
Konfabulation verdient direkte Aufmerksamkeit, weil sie die Fehlerquelle ist, die den größten Vertrauensschaden erzeugt. Ein Generative-Research-Briefing, das eine zuversichtlich zitierte Behauptung enthält, die die zitierte Quelle tatsächlich nicht macht, wird, wenn entdeckt, das Vertrauen in das gesamte Briefing und in das Pattern allgemein zerstören. OpenAIs Forschung zu GPT-4 erkennt das direkt an: Selbst hochfähige Modelle können plausibel klingende, aber ungenaue Inhalte produzieren, weshalb die Zitierverifizierung unabhängig von der Modellqualität eine menschliche Verantwortung bleibt. Die Maßnahme ist nicht, das Pattern zu vermeiden. Es ist, Verifizierung als Workflow-Schritt vor der Verteilung einzubauen. Siehe Halluzinationsrisiko nach AI-Pattern dafür, wie das sich mit Fehlerquellen in anderen Generate-intensiven Patterns vergleicht.
Das Vertrauensmodell: Verifizierung ist nicht optional
Das RAG-Assistant-Pattern profitiert von einem relativ begrenzten Vertrauensmodell. Die Wissensbasis gehört Ihnen. Die Quellen sind bekannt. Wenn eine Antwort falsch ist, ist die Quelle falsch, und Sie können die Quelle korrigieren.
Generative Research schöpft aus externen, Live- und domänenübergreifenden Quellen. Die Synthese kann Schlussfolgerungen produzieren, die keine einzelne Quelle explizit unterstützt. Das ist der Wert. Aber deshalb muss das Vertrauensmodell explizit sein.
Bevor ein Generative-Research-Output verteilt wird, sollte ein namentlich genannter menschlicher Reviewer:
- Den Output als vollständiges Dokument lesen, nicht nur die Zusammenfassung
- 3-5 Zitate stichprobenchecken und verifizieren, dass die Quelle existiert und die zugeschriebene Behauptung tatsächlich in der Quelle steht
- Konsensbehauptungen markieren, die angesichts ihrer Belege übertrieben erscheinen
- Jeden Abschnitt markieren, in dem Quellen in Konflikt standen (sofern nicht bereits von der AI markiert)
- Seinen Namen als überprüfender Analyst zum Dokument hinzufügen
Diese Überprüfung dauert 15-30 Minuten für ein gut formatiertes Briefing. Sie ist nicht dasselbe wie die ursprüngliche 6-8-stündige Recherchearbeit. Das ist der Produktivitätsgewinn. Aber die 15-minütige Überprüfung ist nicht optional.
Die häufige Fehlerquelle: Teams deployen Generative Research und hören nach den ersten sechs Monaten auf, Stichproben zu machen, weil Outputs "in Ordnung erscheinen." Dann erreicht ein Briefing mit einer fabrizierten Statistik eine Board-Präsentation. Die Lösung ist, den Stichprobencheck als dokumentierten Workflow-Schritt zu verankern, nicht als optionale Überprüfung.
Wann Generative Research funktioniert (und wann nicht)
Funktioniert gut wenn:
- Die Frage einen definierten Scope hat. "Was hat Wettbewerber X in Q1 2026 angekündigt?" ist eingegrenzt. "Erzähl mir alles über Wettbewerber X" ist es nicht.
- Quellen verfügbar und zugänglich sind. Für öffentliche Unternehmen, Marktforschung und Competitive Intelligence sind öffentliche Quellen normalerweise reichhaltig. Für Privatunternehmen oder aufkommende Märkte sinkt die Quellqualität.
- Das Ergebnis vor der Verteilung überprüft wird. Das ist kein Vertrauensproblem hinsichtlich der Technologie. Es ist eine Workflow-Anforderung für jeden Recherche-Output, der Entscheidungen beeinflusst.
- Das Bedürfnis nach Synthese besteht, nicht nach einer spezifischen Faktenabfrage. Wenn Sie "Was ist Acme Corps ARR?" benötigen, ist das eine Faktenabfrage, bei der eine einzelne autoritative Quelle besser ist als Synthese. Wenn Sie "Was können wir aus öffentlichen Signalen über Acme Corps Wachstumstrend schlussfolgern?" benötigen, ist das Synthese.
vs. RAG Assistant: RAG ist Ihre interne Wissensbasis, die bekannte Fragen beantwortet. Generative Research ist Synthese aus externen oder domänenübergreifenden Quellen, die neue Erkenntnisse produziert. Sie werden oft zusammen genutzt: Generative Research, um Intelligence-Briefings aus externen Quellen aufzubauen, RAG Assistant, um "Was haben wir über diesen Account gelernt?" aus vergangenen Briefings und Gesprächsnotizen zu beantworten.
vs. Document Review: Document Review nimmt ein spezifisches Dokument und prüft es gegen einen bekannten Standard oder eine Vorlage. Generative Research nimmt viele Dokumente und synthetisiert einen neuen Output aus ihnen. Die Unterscheidung: ein Dokument vs. viele Quellen; Compliance-Check vs. Erkenntnissynthese.
vs. Meeting Intelligence: Meeting Intelligence verarbeitet Ihre eigenen Gesprächsaufzeichnungen. Generative Research schöpft aus externem Material. Sie können kombiniert werden: Meeting Intelligence erfasst Ihre eigenen Kundengespräche, Generative Research synthetisiert externen Marktkontext, und ein Stratege kombiniert beides für eine vollständige Account-Sicht.
ROI-Signale: Wirkung messen
| Kennzahl | Manuelle Baseline | Mit Generative Research | Typische Verbesserung |
|---|---|---|---|
| Analysenstunden pro Briefing | 4-8 Stunden für ein vollständiges Wettbewerbs-Briefing | 30-60 Minuten (AI plus Überprüfung) | 85-90 Prozent Zeitreduktion |
| Zeit von Anfrage bis Lieferung | 1-3 Tage (Backlog plus Schreibzeit) | 2-4 Stunden (Same-Day-Lieferung) | 80-90 Prozent Zykluszeitreduktion |
| Quellabdeckung pro Briefing | 5-10 Quellen (praktisches Limit für einen Analysten) | 20-50 Quellen (AI-Syntheselimit ist breiter) | 3-5-fache Abdeckungsverbesserung |
| Briefing-Frequenz | 1 umfassendes Briefing pro Monat pro Thema | Wöchentliche Briefings werden machbar | 4-6-fache Kadenz-Verbesserung |
| Pre-Call-Recherche-Abschlussrate | 40-60 Prozent der Vertriebsgespräche haben irgendeine Pre-Call-Recherche | 85-95 Prozent mit automatisierter Account-Briefing-Generierung | 40-50 Prozent Verbesserung |
Die Pre-Call-Recherche-Abschlussrate ist oft die am leichtesten nachverfolgbare Kennzahl und verbindet sich direkt mit Pipeline-Ergebnissen. Wenn Reps mit einem Briefing in Gespräche gehen, verbessert sich die Gesprächsqualität. McKinseys Forschung zu AI im B2B-Vertrieb zeigt, dass Account-Recherche und Pre-Call-Vorbereitung zu den spannendsten AI-Use-Cases für Vertriebsleiter gehören, genau weil der Produktivitätsgewinn messbar und unmittelbar ist. Nicht weil das Briefing perfekt ist, sondern weil das Vorhandensein von Kontext die Eröffnung von "Erzählen Sie mir von Ihrem Unternehmen" zu "Ich habe gesehen, dass Sie gerade ein neues Büro in Austin eröffnet haben. Hängt das mit dem Expansionsprogramm zusammen, das Sie in Ihrem Earnings Call erwähnt haben?" verschiebt.
Rework Analysis: Die Generative-Research-Deployments, die Erfolg haben, haben eine Gemeinsamkeit: einen namentlich genannten Reviewer, der den 15-minütigen Stichprobencheck besitzt, bevor jedes Briefing verteilt wird. Nicht die AI macht ein Recherche-Briefing vertrauenswürdig. Es ist der Name des Reviewers auf dem Dokument. Teams, die diesen Schritt zugunsten der Geschwindigkeit überspringen, verteilen schließlich ein Briefing mit einer fabrizierten Statistik an ein Board, einen Kunden oder einen Investor. Sobald das passiert, kollabiert das Vertrauen in das gesamte Programm, nicht nur in das spezifische Briefing. Die Aufgabe des Reviewers ist nicht, die Recherche zu wiederholen. Es ist, 3-5 Zitate zu verifizieren und jede Behauptung zu markieren, die angesichts ihrer Belege überzuversichtlich erscheint. Das dauert 15-30 Minuten für ein 10-seitiges Briefing. Es verwandelt einen potenziell gefährlichen Output in ein vertrauenswürdiges Dokument. Keine andere Governance-Kontrolle liefert mehr ROI bei niedrigeren Kosten.
Häufig gestellte Fragen
Was ist das Generative-Research-AI-Pattern?
Generative Research ist ein AI-Pattern, das mehrere Quellen zu einem kohärenten Recherche-Output synthetisiert. Die Formel lautet: Ingest (Multi-Source-Corpus), Analyze (Quell-übergreifende Synthese, die Konsensignale, Konflikte und Schlussfolgerungen identifiziert), Generate (strukturierter Bericht, Briefing oder Analyse). Es unterscheidet sich von RAG Assistant dadurch, dass es aus externen, Live- oder domänenübergreifenden Quellen statt aus einer kontrollierten internen Wissensbasis schöpft und neue Schlussfolgerungen aus der Kombination der Quellen produziert.
Was ist das Multi-Source-Synthesis-Pattern?
Das Multi-Source-Synthesis-Pattern ist die definierende Fähigkeit von Generative Research: mehrere Quellen gleichzeitig zu lesen, um herauszufinden, worüber sie kollektiv übereinstimmen, Stellen hervorzuheben, wo sie in Konflikt stehen, und zu schlussfolgern, was die kombinierten Belege über das hinaus implizieren, was eine einzelne Quelle aussagt. Ein Deployment, das jede Quelle unabhängig zusammenfasst, nutzt dieses Pattern nicht. Die Syntheseschicht ist das, was 30 Quellen zu einem kohärenten Briefing komprimiert und Generative Research von einer Reihe zusammengefügter Dokumentzusammenfassungen unterscheidet.
Wie unterscheidet sich Generative Research von einem RAG Assistant?
RAG Assistant retrievet Antworten aus einer kontrollierten internen Wissensbasis, die Sie besitzen. Generative Research synthetisiert aus externen, Live- oder domänenübergreifenden Quellen zum Anfragezeitpunkt. Die Vertrauensmodelle sind unterschiedlich: RAG-Outputs können verifiziert werden, indem die zitierte interne Quelle überprüft wird. Generative-Research-Outputs erfordern das Verifizieren, dass die zitierte externe Quelle die zugeschriebene Behauptung tatsächlich unterstützt und dass die synthetisierte Schlussfolgerung unter Prüfung standhält. Die 15-minütige menschliche Überprüfung vor der Verteilung ist eine Governance-Anforderung für Generative Research, die für RAG weniger kritisch ist.
Was ist Citation Laundering bei AI-Recherche?
Citation Laundering tritt auf, wenn ein AI-Modell eine reale, glaubwürdige Quelle für eine Behauptung zitiert, die diese Quelle tatsächlich nicht macht. Die 2024-Bewertung von Stanford HAI ergab, dass 23 Prozent der AI-generierten Zitate in Langform-Synthese-Aufgaben entweder eine Quelle zitierten, die die zugeschriebene Behauptung nicht enthielt, oder die Position der Quelle falsch darstellten. Das produziert Outputs, die autoritativ aussehen und eine oberflächliche Überprüfung überstehen, aber unter Prüfung scheitern. Die Maßnahme ist, 3-5 Zitate pro Briefing vor der Verteilung stichprobenzuprüfen.
Welchen ROI sollten Sie von Generative Research erwarten?
Analysenstunden pro Wettbewerbs-Briefing sinken von 4-8 Stunden auf 30-60 Minuten (85-90 Prozent Zeitreduktion). Quellabdeckung pro Briefing verbessert sich von 5-10 auf 20-50 Quellen (3-5-fache Verbesserung). Pre-Call-Recherche-Abschlussraten für Vertriebsreps steigen von 40-60 auf 85-95 Prozent. Briefing-Kadenz verbessert sich 4-6-fach (wöchentliche Briefings werden machbar, wo monatlich das frühere Limit war). Die Pre-Call-Recherche-Abschlussrate ist die am leichtesten nachverfolgbare Kennzahl und verbindet sich direkt mit Pipeline-Ergebnissen.
Was sind die häufigsten Generative-Research-Fehlerquellen?
Die sechs Hauptfehlerquellen sind Konfabulation (plausibel klingende Behauptungen, die von keiner Quelle unterstützt werden), Citation Laundering (echte Quelle für eine Behauptung zitiert, die die Quelle nicht macht), Quellaktualitäts-Verzögerung (Index ist Tage hinterher), widerstreitende Quellen als einheitlicher Konsens dargestellt, Scope-Drift (zu breiter Prompt produziert einen nicht nutzbaren Output) und Single-Source-Bias (eine dominante Quelle überwältigt die Synthese). Citation Laundering ist die hinterhältigste, weil sie autoritativ aussieht. Konfabulation ist am schädlichsten für das Vertrauen, wenn sie entdeckt wird.
Weitere Ressourcen

Co-Founder, Rework.com
On this page
- Die Formel: Ingest, Analyze, Generate
- Das Multi-Source-Synthesis-Pattern
- Generative Research vs. RAG Assistant: die entscheidende Unterscheidung
- Fünf reale Beispiele im Detail
- 1. Competitive-Intelligence-Reporting
- 2. Account-Recherche-Briefing vor einem Vertriebsgespräch
- 3. Executive-Branchen-Trend-Synthese
- 4. Marktsizing mit zitierten Quellen
- 5. M&A-Due-Diligence-Desk-Research
- Fehlerquellen: Was Generative Research zum Scheitern bringt
- Das Vertrauensmodell: Verifizierung ist nicht optional
- Wann Generative Research funktioniert (und wann nicht)
- ROI-Signale: Wirkung messen
- Weitere Ressourcen