Personalization Engine: Relevanz im großen Maßstab
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
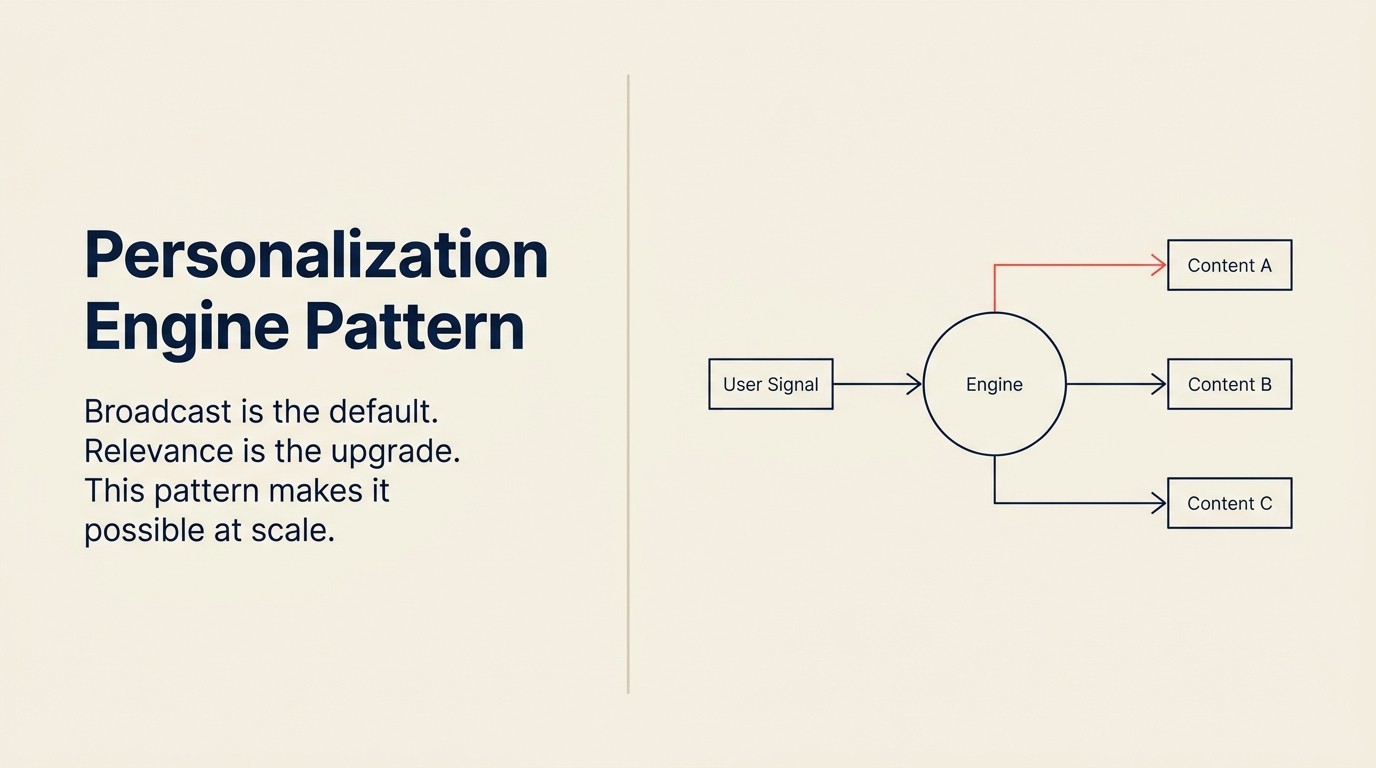
Broadcast ist der Standard. Relevanz ist das Upgrade.
Dieselbe E-Mail, die an 50.000 Menschen gesendet wird, erzielt eine Click-Through-Rate von 1 Prozent. Eine Version, die auf jedes Segment, jedes Verhalten, jeden Moment im Customer-Lifecycle abgestimmt ist, erzielt 5 bis 12 Prozent. Nicht weil der Text besser ist. Weil der richtige Content zur richtigen Person zum richtigen Zeitpunkt gelangt.
Personalization Engine ist das AI-Pattern, das Relevanz im großen Maßstab ermöglicht. Es ist in jeder großen E-Commerce-Plattform, jedem nennenswerten Marketing-Automation-Stack und einem wachsenden Anteil von B2B-Produkterlebnissen eingebaut. Aber die meisten Teams deployen es ohne die Mechanik zu verstehen, was dazu führt, dass Sie in einer Filterblase enden, die aufhört, neue Kategorien zu zeigen, oder einem "zu wissend"-Gefühl, das Nutzer unwohl macht und Abkopplung antreibt.
Dieser Artikel deckt das vollständige Pattern ab: Formel, reale Beispiele in fünf Deployment-Kontexten, Fehlerquellen, Datenschutzarchitektur und ROI-Signale.
Die Formel
Ingest (Nutzerverhaltenssignale) → Analyze (Nutzerprofil aufbauen oder aktualisieren) → Predict (Präferenzen, nächste beste Aktion, relevanter Content) → Generate (personalisierter Content, Angebot oder Erlebnis) → Execute (zum richtigen Zeitpunkt ausliefern)
Jeder Schritt in einem E-Mail-Personalisierungsbeispiel:
Ingest: Ein Nutzer öffnet Ihr Produkt, klickt auf die Preisseite und bricht dann ohne Konversion ab. Er hat Ihre letzten drei E-Mails geöffnet. Er hat einen Link zu Enterprise-Sicherheits-Features angeklickt und 90 Sekunden auf dieser Seite verbracht. Das sind Verhaltenssignale. Der Ingest-Schritt erfasst sie in Echtzeit und verknüpft sie mit dem Profil des Nutzers.
Analyze: Das System aktualisiert das Profil des Nutzers. Diese Person hat wiederholtes Interesse an Sicherheits-Features gezeigt, hat sich mit Enterprise-Tier-Inhalten engagiert und scheint basierend auf Seitenbesuchsmustern in einem Evaluierungszyklus zu sein. Rollen-Schätzung: IT- oder Sicherheitsleiter. Kaufphase: Überlegung.
Predict: Angesichts dieses Profils ist der nächste beste Content eine Fallstudie über Enterprise-Kunden in regulierten Branchen, die den Sicherheitsstack implementiert haben. Kein generisches Newsletter. Kein SMB-Onboarding-Guide. Dieser spezifische Content, für diese Person, in diesem Moment.
Generate: Das System erstellt eine E-Mail mit einer personalisierten Betreffzeile, einem Einleitungssatz, der Enterprise-Sicherheit referenziert ohne aufdringlich zu sein, der Fallstudie als primärem Call-to-Action und sekundärem Content, der den Interessensignalen entspricht.
Execute: Die E-Mail wird zu dem Zeitpunkt gesendet, den das Modell als den wahrscheinlichsten Öffnungszeitpunkt für diesen Nutzer prognostiziert (historisch Dienstagmorgen, 9 Uhr). Das CRM protokolliert die Interaktion. Die Feedback-Schleife beginnt: Hat der Nutzer geöffnet, geklickt, konvertiert?
Die Feedback-Schleife ist nicht optional. Sie ist das, was das Pattern im Laufe der Zeit verbessert. Eine Personalization Engine ohne Signal-to-Outcome-Feedback-Schleife ist statische Segmentierung mit extra Schritten. Das Modell muss wissen, ob seine Prognosen richtig waren, um besser zu werden. Siehe Predict: Wie AI Geschäftsergebnisse prognostiziert dafür, wie die Prognose-Ebene im Detail funktioniert.
Key Facts: Geschäftliche Auswirkung von Personalization Engine
- Unternehmen, die bei Personalisierung hervorragende Leistungen erbringen, generieren damit 40 Prozent mehr Umsatz als langsamer wachsende Wettbewerber, wobei der Abstand durch Closed-Loop-Feedback zwischen Verhaltenssignalen und Content-Entscheidungen angetrieben wird (McKinsey Personalization at Scale, 2021)
- Personalisierte E-Mail-Kampagnen, die Verhaltenssignale und rollenbasierte Segmentierung verwenden, erreichen Click-Through-Raten von 5-12 Prozent gegenüber 1 Prozent für Broadcast-E-Mails an dasselbe Publikum (Salesforce Email Benchmark Report, 2025)
- B2B-Produktteams, die rollenspezifische Onboarding-Personalisierung einsetzen, sehen eine 25-40-prozentige Verbesserung der 30-Tage-Feature-Aktivierungsraten im Vergleich zu generischen Onboarding-Flows, weil das richtige Feature in dem Moment sichtbar gemacht wird, in dem die Rolle des Nutzers es relevant macht (Amplitude Product Analytics, 2025)
Die Real-Time-Relevance-Schleife
Der Kernmechanismus der Personalization Engine ist eine geschlossene Feedback-Schleife: Verhaltenssignale aktualisieren das Nutzerprofil, das aktualisierte Profil treibt eine neue Prognose an, die Prognose generiert personalisierten Content, der Content wird ausgeliefert, und die Reaktion des Nutzers (klicken, überspringen, konvertieren, ignorieren) wird zum nächsten Verhaltenssignal. Diese Schleife ist das, was Personalization Engine von Segmentierung unterscheidet. Segmentierung weist Nutzer statischen Gruppen zu und hält diese Zuweisung aufrecht, bis jemand sie manuell aktualisiert. Personalization Engine aktualisiert das Profil kontinuierlich, sodass die Prognose widerspiegelt, wer der Nutzer heute ist, nicht wer er bei der Anmeldung war. Ein Modell ohne geschlossene Feedback-Schleife ist statische Segmentierung mit AI-Etikettierung. Ein Modell mit geschlossener Schleife verbessert die Prognosegenauigkeit mit jeder Interaktion.
Das Geschäftsproblem, das es löst
Generische Kommunikation verschwendet Lieferbudget und erodiert Vertrauen. Wenn ein Kunde Ihr Produkt seit zwei Jahren nutzt und immer noch "Willkommen auf der Plattform, hier ist, wie Sie beginnen" erhält, fällt das auf. Wenn ein Interessent einen Enterprise-Preisleitfaden herunterlädt und dann eine E-Mail erhält, die Ihren kostenlosen Plan bewirbt, fällt das auf. Die Diskrepanz zwischen dem, was der Nutzer Ihnen durch sein Verhalten mitgeteilt hat, und dem, was Sie in Ihrer Antwort sagen, signalisiert, dass Sie nicht aufpassen.
Personalization Engine löst das im großen Maßstab. Ohne AI erfordert Personalisierung manuelle Segmentierung, Campaign-Kopien für jedes Segment und manuell verwaltete Logik. Dieser Ansatz stößt bei 4 oder 5 Segmenten an seine Grenze, bevor er operational nicht mehr handhabbar wird. Mit AI können Sie über Hunderte von Dimensionen gleichzeitig personalisieren, das Profil in Echtzeit aktualisieren, wenn Signale eintreffen, und das Modell bestimmen lassen, welcher Content am relevantesten ist, ohne explizite Regeln für jeden Fall zu schreiben.
Das Upgrade sind nicht nur Performance-Metriken. Es ist das Erlebnis. Nutzer, die relevanten Content erhalten, vertrauen der Marke mehr. Nutzer, die irrelevanten Content erhalten, kündigen das Abonnement, churnen oder fangen einfach an, Sie auszublenden.
Fünf reale Beispiele im Detail
E-Commerce-Produktempfehlungen
Ingest: Browser-Verlauf, Kaufhistorie, In-den-Warenkorb-legen ohne Kauf, Suchanfragen, Preisbereich der angeklickten Artikel, Kategorienstverteilung vergangener Bestellungen.
Profil-Logik: Das System baut ein Präferenzmodell pro Nutzer auf. Dieser Nutzer kauft im mittleren Preissegment, einkauft hauptsächlich in Laufausrüstung und hat denselben Schuh zweimal im Warenkorb verlassen, der aktuell nicht vorrätig ist.
Was personalisiert wird: Das Homepage-Produktraster, der E-Mail-"Könnte Ihnen auch gefallen"-Abschnitt und das "Häufig zusammen gekauft"-Modul auf Produktseiten.
Execute: Die Homepage rendert pro Nutzer unterschiedliche Produkt-Feeds. Der nicht vorrätige Schuh löst eine "Wieder verfügbar"-Benachrichtigung aus. Die E-Mail-Sendung wählt aus einem Pool von 200 Produkten und zeigt die 4 für das Profil dieses Nutzers relevantesten.
Die Feedback-Schleife ist hier eng. Klicken, kaufen oder ignorieren, jede Reaktion aktualisiert das Modell innerhalb von Stunden.
Dynamischer Content in E-Mail-Kampagnen
Ingest: CRM-Daten (Rolle, Unternehmensgröße, Branche), vergangenes E-Mail-Engagement (welche Themen der Nutzer angeklickt hat, welche er ignoriert hat), Produktnutzungsdaten (welche Features er aktiviert hat) und Funnel-Phase.
Profil-Logik: Zwei Nutzer erhalten dieselbe Kampagne. Nutzer A ist VP of Sales bei einem 500-Personen-Tech-Unternehmen, hat zwei Artikel über Pipeline-Forecasting angeklickt und ist ein aktiver Tagesnutzer. Nutzer B ist Marketing Manager bei einem 50-Personen-Startup, hat geöffnet aber nie geklickt und zuletzt vor 12 Tagen eingeloggt.
Was personalisiert wird: Die Betreffzeile, der einleitende Absatz, der primäre Artikel-Link und der Call-to-Action. Nutzer A erhält Pipeline-Effizienz-Content und eine Aufforderung, ein Demo zu buchen. Nutzer B erhält ein Re-Engagement-Stück und eine Aufforderung, mit einem schnellen Gewinn im Produkt zu beginnen.
Execute: Dieselbe Campaign-Infrastruktur, zwei verschiedene E-Mail-Erlebnisse, die zum Sendezeitpunkt aufgebaut werden.
Der Unterschied zur einfachen Segmentierung: Das System nutzt keine statischen Segmente. Es baut ein Echtzeit-Profil pro Nutzer auf und trifft Content-Entscheidungen pro Sendung. Das Modell verbessert sich mit jeder Sendung basierend auf dem, was funktioniert hat.
In-Produkt-Onboarding-Nudges
Ingest: Berufsbezeichnung aus dem Anmeldeformular, Unternehmensgröße, in den ersten 7 Tagen aktivierte Features, in der App besuchte Seiten und eingereichte Support-Tickets (indirekte Signale darüber, wo der Nutzer feststeckt).
Profil-Logik: Ein Nutzer, der sich als Account Executive angemeldet hat und die CRM-Integration aktiviert hat, aber seinen E-Mail-Kalender noch nicht verbunden hat, vermisst einen hochwertvollen Workflow. Das System merkt das.
Was personalisiert wird: Die In-Produkt-Tooltip-Sequenz, die in der Onboarding-Seitenleiste angezeigten Checklisten-Punkte und die an Tag 3 ausgelöste E-Mail-Nachverfolgung.
Execute: An Tag 3 erhält der Nutzer statt der generischen Onboarding-E-Mail eine einzige fokussierte E-Mail: "Sie haben Ihr CRM verbunden. So fügen Sie die Kalender-Synchronisierung in 90 Sekunden hinzu," mit einem Deep-Link direkt zu den Kalendereinstellungen.
B2B-Produktteams unterschätzen, wie viel Wert in diesem Pattern steckt. Generische Onboarding-Flows lassen erhebliche Aktivierungsraten ungenutzt. Rollenspezifische Flows, aufgebaut aus Verhaltenssignalen, konvertieren mit deutlich höheren Raten.
B2B-Preisgestaltungs-Personalisierung
Ingest: Account-Größe (aus CRM), Branchenvertikale, Produktnutzungs-Tier (welche Features der Account am häufigsten nutzt), Expansionssignale (hinzugefügte Nutzer, beantragte Sitze, eingereichte Feature-Requests) und NPS-Score.
Profil-Logik: Ein 200-Sitze-Account im Finanzdienstleistungsbereich ist auf dem Starter-Plan, nutzt die API aber intensiv. Drei Teammitglieder haben Feature-Requests für erweitertes Audit-Logging eingereicht. Dieser Account ist expansionsbereit.
Was personalisiert wird: Der In-App-Upgrade-Prompt zeigt eine Nachricht speziell über Audit-Logging- und Compliance-Features. Die E-Mail vom Customer-Success-Manager ist vorab mit dem Expansionsfall gefüllt, der für das Nutzungsmuster dieses Accounts spezifisch ist.
Execute: Der Upgrade-Prompt löst nach dem 500. API-Call in einem Abrechnungszyklus aus. Die CSM-E-Mail steht vor dem Senden zur Überprüfung in der Queue (menschliches Genehmigungs-Gate für kundenseitige Kommunikation).
Hier weicht B2B-Personalisierung von Consumer-Personalisierung ab. Der Execute-Schritt für Preiskommunikation sollte einen Menschen in der Schleife halten. Die AI baut die Relevanz auf. Der Mensch besitzt die Beziehung.
LMS-Lernpfad-Empfehlungen
Ingest: Rolle und Abteilung aus dem HR-System, bisherige Kursabschlüsse, Quiz-Ergebnisse nach Themenbereich, Zeit bis zum Abschluss pro Modul (Proxy für Engagement) und selbst berichtete Kompetenzlücken aus der Erstbewertung.
Profil-Logik: Ein neu beförderte Manager hat zwei Leadership-Kurse abgeschlossen und bei Kommunikationsmodulen gut abgeschnitten, hat aber das Konfliktlösungsmodul übersprungen. Das Modell markiert Konfliktlösung als die nächste Empfehlung mit der höchsten Priorität.
Was personalisiert wird: Das "Für Sie empfohlen"-Karussell auf der LMS-Homepage, die wöchentliche Learning-Digest-E-Mail und die Coaching-Plan-Inputs des Managers.
Execute: Der Lernplan aktualisiert sich jeden Montag automatisch. Die E-Mail-Digest-Erstellung listet die 3-Item-Empfehlungsliste jedes Nutzers dynamisch auf.
Die Feedback-Schleife hier sind Lernergebnis-Daten: Hat sich der Performance-Review-Score des Mitarbeiters in Bereichen verbessert, in denen die AI Entwicklung empfohlen hat? Das ist ein Long-Cycle-Signal, aber es ist das Signal, das validiert, ob die Personalisierung auf Ergebnis-Ebene funktioniert, nicht nur auf Engagement-Ebene.
Wann Personalization Engine gut funktioniert
Drei Bedingungen machen das Pattern effektiv:
Ausreichend Verhaltenssignal pro Nutzer. Das Modell braucht etwas, womit es arbeiten kann. Wenn Nutzer mit Ihrem Produkt selten interagieren oder minimale Verhaltensspuren hinterlassen, ist das Profil dünn. Dünne Profile produzieren generische Empfehlungen. Die meisten E-Commerce-Plattformen benötigen 5-10 Interaktionen, bevor Personalisierung Broadcast übertrifft. B2B-Tools mit komplexen, seltenen Workflows benötigen explizite Signal-Sammlung (Rolle, Absicht, Ziel), um spärliche Verhaltensdaten zu kompensieren.
Personalisierungsoberfläche, die variieren kann. Der E-Mail-Körper, der Produkt-Feed, der Onboarding-Flow oder die Preisseite müssen tatsächlich Variation unterstützen. Wenn Ihre technische Infrastruktur jedem Besucher eine statische Seite liefert, wird Personalisierung auf der Content-Ebene durch Infrastruktur blockiert, nicht durch AI-Fähigkeiten. Prüfen Sie die Oberfläche, bevor Sie sich auf das Pattern festlegen.
Geschlossene Feedback-Schleife. Sie müssen messen, ob die Personalisierung funktioniert hat. Klick, Kauf, Aktivierung, Konversion, Bindung. Wenn Sie die personalisierte Intervention nicht mit einem Outcome-Signal verbinden können, können Sie das Modell nicht trainieren, um sich zu verbessern. Sie betreiben Personalisierung blind.
Fehlerquellen
Cold Start. Neue Nutzer ohne Signal erhalten ohnehin generischen Output. Das ist unvermeidbar, aber handhabbar. Die Maßnahme ist explizite Signal-Sammlung bei der Anmeldung: nach Rolle, Use Case und Zielen fragen. Diese deklarierten Signale nutzen, um das Profil zu bootstrappen, bevor sich Verhaltensdaten ansammeln. Explizite Signale veralten im Laufe der Zeit (Menschen wechseln Rollen, Unternehmen wachsen), daher sollte das System neueren Verhaltenssignalen gegenüber veralteten deklarierten mehr Gewicht geben, wenn das Profil reift.
Filterblase. Das Modell zeigt, was der Nutzer bereits als interessant markiert hat, was bedeutet, dass er aufhört, Dinge außerhalb seiner bestehenden Muster zu sehen.
Netflix-Forschung ergab, dass 80 Prozent der auf der Plattform angesehenen Inhalte durch deren Empfehlungs-Engine entdeckt werden, aber in Jahren, in denen die Diversitätsquote nicht aktiv aufrechterhalten wurde, sank das Nutzerengagement mit neuen Titeln innerhalb von 6 Monaten um 23 Prozent, da Nutzer in immer enger werdende Empfehlungsschleifen fielen (Netflix Technology Blog, 2022). Dieselbe Dynamik zeigt sich in B2B-Kontexten: Nutzer, deren Onboarding-Personalisierung nur Features zeigt, mit denen sie bereits interagiert haben, verpassen benachbarte Features, die zusätzlichen Wert liefern würden. Das ist am wichtigsten in Content-Plattformen und Marktplätzen, wo Entdeckung ein Kernwert ist. Maßnahme: Eine "Diversitätsquote" in die Empfehlungslogik injizieren, einen Anteil von Empfehlungen, die bewusst aus benachbarten Kategorien statt aus bestätigten Präferenzen ziehen. 10 bis 20 Prozent Diversität ist typischerweise ausreichend, um Entdeckung aufrechtzuerhalten, ohne Relevanz zu untergraben.
Datenschutz-Wahrnehmung. Nutzer, die die Personalisierung als "zu wissend" empfinden, koppeln sich ab oder fühlen sich überwacht. Das ist von der Datenschutzrechts-Compliance (DSGVO, CCPA) unterschieden. Eine Empfehlung, die technisch legal ist, kann sich trotzdem invasiv anfühlen. Die Grenze liegt normalerweise beim Kombinieren von Offline- und Online-Signalen auf Weisen, die überraschend wirken. Maßnahme: Personalisierung auf das verankern, was Nutzer innerhalb Ihres Produkts getan oder womit sie sich explizit engagiert haben. Der Kauf von Drittanbieterdaten zur Personalisierung eines Erlebnisses überschreitet für viele Nutzer eine Grenze, auch wenn es legal ist.
Signal-Verfall. Die Kaufhistorie eines Kunden von vor 18 Monaten ist kein zuverlässiges Signal mehr, wenn er die Rolle gewechselt, das Unternehmen gewechselt oder ein Projekt abgeschlossen hat, das das ursprüngliche Kaufmuster erzeugt hat. Das Modell optimiert weiterhin für einen Nutzer, der nicht mehr existiert. Maßnahme: Signale zeitlich gewichten, sodass neueres Verhalten einen höheren Einfluss hat als älteres. Einen Verfall-Schwellenwert setzen: Signale, die älter als 12 Monate sind, tragen mit reduziertem Gewicht bei; Signale, die älter als 24 Monate sind, werden archiviert und vom aktiven Profilaufbau ausgeschlossen. Der Risikogradient über AI-Patterns erklärt, warum dieses Pattern bei Tier-3-Risiko liegt, wenn Personalisierung automatisierte Entscheidungen im großen Maßstab treibt.
Wann Personalization Engine vs. Alternativen wählen
Vs. RAG Assistant: RAG antwortet auf explizite Abfragen. Der Nutzer stellt eine Frage; das System retrievet relevante Inhalte und antwortet. Personalization Engine ist proaktiv. Es passt die Umgebung an, bevor der Nutzer fragt. RAG nutzen, wenn Nutzer spezifische, ausdrückbare Fragen haben. Personalization Engine nutzen, wenn Sie gestalten möchten, was Nutzer begegnen, bevor sie eine Abfrage formulieren.
Vs. Workflow Copilot: Workflow Copilot unterstützt den Nutzer während aktiver Arbeit und schlägt nächste Aktionen innerhalb einer Aufgabe vor. Personalization Engine passt die Umgebung um den Nutzer herum an und ändert, welche Inhalte, Produkte oder Optionen sichtbar sind, bevor der Nutzer mit etwas Spezifischem beginnt. Die Unterscheidung ist innerhalb-der-Aufgabe vs. rund-um-die-Aufgabe.
Vs. Scoring + Routing: Scoring and Routing triagiert eingehende Elemente und leitet sie an den richtigen Menschen oder die richtige Queue weiter. Es bestimmt, wohin etwas geht. Personalization Engine stimmt ab, was der Nutzer sieht, nicht wohin er geht. Beide können dieselben Verhaltens- und Profilsignale verwenden, produzieren aber unterschiedliche Outputs: eine Routing-Entscheidung vs. eine Content-Auswahl.
Datenschutz- und Einwilligungsarchitektur
Drei Signal-Kategorien erfordern in den meisten regulatorischen Rahmenbedingungen (DSGVO, CCPA, PIPEDA) explizite Nutzereinwilligung:
- Cross-Site-Tracking (Cookies, die Nutzern domänenübergreifend folgen)
- Sensible Kategoriendaten (Gesundheit, Finanzen, politisch, Standort mit Präzision)
- Kombination von Identifikatoren, um ein Profil zu erstellen, das Online-Verhalten mit Offline-Identität verknüpft
Für Cookie-lose Umgebungen erfordern Verhaltenssignale innerhalb Ihres Produkts (Klicks, Feature-Nutzung, Zeit auf der Seite, In-Produkt-Suchabfragen) keine Drittanbieter-Einwilligungsmechanismen. Sie sind First-Party-Signale von Nutzern, die ein Konto haben und Ihren Nutzungsbedingungen zugestimmt haben.
Praktische Architektur für einwilligungssichere Personalisierung:
- First-Party-Verhaltenssignale: keine zusätzliche Einwilligung über Ihre Nutzungsbedingungen hinaus erforderlich
- Marketing-E-Mail-Personalisierung mit deklarierten Attributen (Rolle, Unternehmen): durch E-Mail-Opt-in-Einwilligung abgedeckt
- Kanalübergreifende Personalisierung, die Produktdaten mit Werbeplattformen kombiniert: erfordert explizite Einwilligung mit granularen Opt-in-Optionen, kein verstecktes Kontrollkästchen
Umgang mit Opt-out ohne Erlebnis-Verschlechterung: Wenn ein Nutzer aus der Personalisierung austritt, ein gut gestaltetes Standard-Erlebnis bereitstellen, kein defektes. Einen soliden Standard-Feed kuratieren. Nutzer, die es vorziehen, nicht verfolgt zu werden, nicht bestrafen, indem eine offensichtlich minderwertige Version des Produkts gezeigt wird.
ROI-Signale
| Kennzahl | Was sie Ihnen sagt |
|---|---|
| Konversionsrate nach Personalisierungskohorte | Personalisiert vs. Broadcast, gleiches Produkt, gleicher Zeitraum. Das ist die Kern-Business-Argumentation. |
| E-Mail-Click-Through: personalisiert vs. Broadcast | Direkter Vergleich derselben Kampagne mit und ohne Personalisierung. |
| Umsatz pro Nutzer nach Personalisierungs-Tier | Zahlt sich die Investition des Modells in tiefe Personalisierung in Umsatz pro Account aus? |
| Feature-Adoption für angestoßene vs. nicht-angestoßene Nutzer | Für In-Produkt-Personalisierung: Treibt das Zeigen einer Feature-Empfehlung die Aktivierung? |
| Feedback-Schleifen-Latenz | Wie lange dauert es, bis ein Outcome-Signal das Modell erreicht und die nächste Empfehlung beeinflusst? Kürzer ist besser. |
| Empfehlungs-Diversitäts-Score | Welcher Prozentsatz der Empfehlungen kommt aus Kategorien, mit denen der Nutzer bisher nicht interagiert hat? Verfolgt das Filterblase-Risiko. |
Was als nächstes kommt
Personalization Engine ist oft das erste AI-Pattern, das kundenseitige Teams deployen. Aber es steht selten allein. McKinseys Technologie-Blueprint für Personalisierung identifiziert, dass das vollständige Pattern die Orchestrierung von vier Capabilities erfordert: Datensammlung, AI-gestützte Entscheidungsfindung, Content-Design und Distribution, die jeweils direkt der Ingest-Analyze-Generate-Execute-Kette im ACE-Framework entsprechen.
Für verhaltensbasierte Anomalieerkennung (der Nutzer, der plötzlich Muster ändert, die auf Churn oder Betrug hinweisen), ist das Anomaly-Agent-Pattern das Komplement. Personalization Engine mit Anomaly Agent kombinieren und Sie haben ein System, das nicht nur den richtigen Content für jeden Nutzer zeigt, sondern auch erkennt, wenn das Verhalten eines Nutzers auf eine Weise wechselt, die eine andere Intervention erfordert: ein Health-Check-Anruf von Customer Success oder ein Flag für das Betrugs-Team.
Wenn Sie mehrere Patterns zu einem Rollen-Level-AI-System kombinieren möchten, deckt der Artikel Patterns stapeln, um AI Agents aufzubauen ab, wie Patterns sich addieren. Ein AI Marketer zum Beispiel kombiniert Personalization Engine mit Generative Research, Meeting Intelligence und Predict, wobei jedes eine andere Phase des Kampagnenzyklus übernimmt.
Rework Analysis: Die Personalization-Engine-Fehlerquelle, die wir am häufigsten sehen, ist ein System ohne geschlossene Feedback-Schleife. Das Modell führt seine ersten Prognosen beim Start basierend auf Rolle und deklarierten Präferenzen durch, und dann verbindet niemand Outcome-Daten zurück mit dem Modell. Sechs Monate später basieren die Empfehlungen immer noch auf Anmeldedaten von Nutzern, die seitdem die Rolle gewechselt, verschiedene Features aktiviert und mehrere Phasen ihres Customer-Lifecycle durchlaufen haben. Das Modell personalisiert für Nutzer, die nicht mehr existieren. Die Schleife zu schließen ist kein technischer Nachgedanke: Es erfordert das Definieren, auf welchem Outcome-Signal das Modell trainiert (Klick, Aktivierung, Bindung, Umsatz), das Aufbauen der Pipeline, die dieses Signal zurück zum Modell leitet, und das Festlegen einer Retraining-Kadenz. Teams, die das beim Start tun, sehen den von McKinsey gemessenen 40-prozentigen Umsatzanstieg. Teams, die es überspringen, sehen Personalisierung, die marginal besser als Broadcast abschneidet, und ein Budget-Gespräch sechs Monate später.
Häufig gestellte Fragen
Was ist ein Personalization-Engine-AI-Pattern?
Personalization Engine ist ein AI-Pattern, das verschiedenen Nutzern auf Basis von Verhaltenssignalen unterschiedliche Inhalte, Angebote oder Erlebnisse liefert. Die Formel lautet: Ingest (Nutzerverhaltenssignale), Analyze (Nutzerprofil aufbauen oder aktualisieren), Predict (Präferenzen, nächste beste Aktion oder relevanter Content), Generate (personalisierter Content oder Angebot), Execute (zum richtigen Zeitpunkt ausliefern). Es unterscheidet sich von Segmentierung dadurch, dass es Nutzerprofile kontinuierlich aktualisiert und Content-Entscheidungen pro Nutzer statt pro Segment trifft.
Was ist die Real-Time-Relevance-Schleife?
Die Real-Time-Relevance-Schleife ist der Kernmechanismus der Personalization Engine: Verhaltenssignale aktualisieren das Nutzerprofil, das aktualisierte Profil treibt eine neue Prognose an, die Prognose generiert personalisierten Content, der Content wird ausgeliefert, und die Reaktion des Nutzers wird zum nächsten Verhaltenssignal. Diese geschlossene Schleife unterscheidet Personalization Engine von statischer Segmentierung. Ein Modell ohne geschlossene Schleife ist statische Segmentierung mit AI-Etikettierung. Ein Modell mit geschlossener Schleife verbessert die Prognosegenauigkeit mit jeder Interaktion.
Welche Umsatzauswirkung liefert Personalisierung?
Unternehmen, die bei Personalisierung hervorragende Leistungen erbringen, generieren damit 40 Prozent mehr Umsatz als langsamer wachsende Wettbewerber, angetrieben durch Closed-Loop-Feedback (McKinsey, 2021). Personalisierte E-Mail-Kampagnen mit Verhaltenssignalen erreichen Click-Through-Raten von 5-12 Prozent gegenüber 1 Prozent für Broadcast-E-Mails (Salesforce, 2025). B2B-Produktteams mit rollenspezifischer Onboarding-Personalisierung sehen eine 25-40-prozentige Verbesserung der 30-Tage-Feature-Aktivierungsraten gegenüber generischen Flows (Amplitude, 2025).
Was ist das Filterblase-Problem bei der Personalisierung?
Filterblase tritt auf, wenn das Empfehlungsmodell nur Content aus Kategorien zeigt, mit denen der Nutzer zuvor interagiert hat, sodass er aufhört, neue Optionen zu entdecken. Netflix fand heraus, dass das Engagement mit neuen Titeln innerhalb von 6 Monaten um 23 Prozent sank, als die Diversitätsquote nicht aktiv aufrechterhalten wurde. Die Maßnahme ist eine Diversitätsquote: 10-20 Prozent der Empfehlungen aus benachbarten Kategorien statt aus bestätigten Präferenzen, die Entdeckung aufrechterhalten, ohne Relevanz zu untergraben.
Welche Datenschutzanforderungen gelten für Personalization Engine?
Drei Signal-Kategorien erfordern unter DSGVO, CCPA und PIPEDA explizite Nutzereinwilligung: Cross-Site-Tracking (Cookies, die Nutzern domänenübergreifend folgen), sensible Kategoriendaten (Gesundheit, Finanzen, politisch, Standort mit Präzision) und Kombination von Identifikatoren zur Verknüpfung von Online-Verhalten mit Offline-Identität. First-Party-Verhaltenssignale innerhalb Ihres eigenen Produkts erfordern keine zusätzliche Einwilligung über die Nutzungsbedingungen hinaus. Marketing-E-Mail-Personalisierung mit deklarierten Attributen ist durch E-Mail-Opt-in-Einwilligung abgedeckt. Kanalübergreifende Personalisierung, die Produktdaten mit Werbeplattformen kombiniert, erfordert explizites, granulares Opt-in.
Wann sollten Sie Personalization Engine statt Workflow Copilot nutzen?
Personalization Engine passt die Umgebung um den Nutzer herum an und ändert, welche Inhalte, Produkte oder Optionen sichtbar sind, bevor der Nutzer mit einer spezifischen Aufgabe beginnt. Workflow Copilot unterstützt den Nutzer innerhalb einer aktiven Aufgabe und schlägt nächste Aktionen innerhalb von bereits laufender Arbeit vor. Die Unterscheidung ist rund-um-die-Aufgabe vs. innerhalb-der-Aufgabe. Personalization Engine für Content-Feeds, E-Mail-Kampagnen, Produktempfehlungen und Onboarding-Flows nutzen. Workflow Copilot für Verfassen, Coding, Reporting und CRM-Arbeit nutzen, bei denen der Nutzer am Aktionspunkt Unterstützung benötigt.
Weitere Ressourcen

Co-Founder, Rework.com
On this page
- Die Formel
- Die Real-Time-Relevance-Schleife
- Das Geschäftsproblem, das es löst
- Fünf reale Beispiele im Detail
- E-Commerce-Produktempfehlungen
- Dynamischer Content in E-Mail-Kampagnen
- In-Produkt-Onboarding-Nudges
- B2B-Preisgestaltungs-Personalisierung
- LMS-Lernpfad-Empfehlungen
- Wann Personalization Engine gut funktioniert
- Fehlerquellen
- Wann Personalization Engine vs. Alternativen wählen
- Datenschutz- und Einwilligungsarchitektur
- ROI-Signale
- Was als nächstes kommt
- Weitere Ressourcen