Rủi ro hallucination theo AI pattern
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hallucination là từ kết thúc các dự án AI. Không phải vì nó luôn xảy ra, mà vì khi nó xảy ra ở bối cảnh sai, tài liệu compliance, email đối khách hàng, hồ sơ y tế, flag pháp lý trên hợp đồng, thiệt hại là thực và thường công khai.
Phản ứng của tổ chức thường sai theo một trong hai hướng. Lãnh đạo quyết định AI không an toàn và hủy bỏ sáng kiến, điều chỉnh quá mức, bỏ lại giá trị thực trên bàn. Hoặc họ quyết định sự cố là ngẫu nhiên và tiếp tục chạy mà không thay đổi gì, điều chỉnh không đủ, chờ sự cố tiếp theo. Cả hai phản ứng đều không dựa trên đánh giá trung thực về nơi rủi ro hallucination thực sự tồn tại.
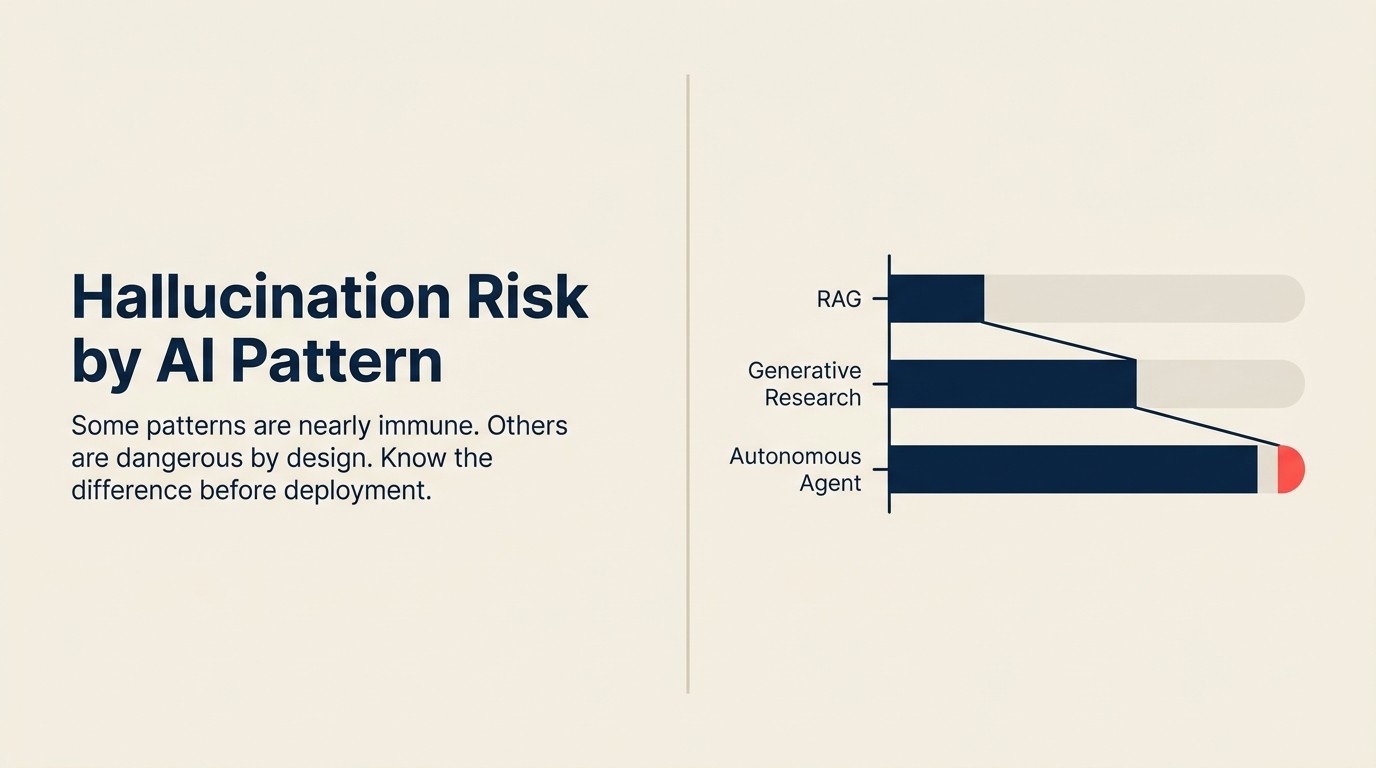
Phản ứng đúng là hiểu rằng rủi ro hallucination không đồng đều giữa các pattern. Một số pattern gần như miễn dịch theo thiết kế. Một số khác mang rủi ro cao như đặc tính cấu trúc của cách chúng vận hành. Quản lý rủi ro đòi hỏi phải biết cái nào là cái nào.
Hallucination thực sự là gì trong bối cảnh kinh doanh
Tài liệu học thuật về vấn đề này hiện khá dày. Khảo sát arXiv toàn diện (arXiv:2401.01313) phân tích hơn 32 kỹ thuật giảm thiểu hallucination và xác định Retrieval Augmented Generation là biện pháp giảm thiểu cấu trúc hiệu quả nhất cho hallucination thực tế. Phát hiện đó định hình trực tiếp nhiều khuyến nghị theo pattern bên dưới. Có ba loại hallucination xuất hiện trong bối cảnh kinh doanh, và chúng gây hại theo những cách rất khác nhau:
Hallucination thực tế. Model khẳng định điều gì đó sai một cách tự tin. "Thời hạn hoàn trả của bạn là 45 ngày" khi thực tế là 30 ngày. "Hợp đồng ký ngày 12 tháng 3" khi tài liệu không có ngày đó. Model tạo ra câu nghe có lý nhưng sai.
Hallucination citation. Model gán phát biểu cho nguồn không đưa ra phát biểu đó, hoặc cho nguồn không tồn tại. "Theo bản cập nhật chính sách Q3 của bạn..." khi không có bản cập nhật nào như vậy được index. Khác với hallucination thực tế ở chỗ: nội dung có thể đúng, nhưng citation là bịa.
Hallucination ngữ cảnh. Model tạo ra nội dung nghe hợp lý nhưng không phản ánh ngữ cảnh cụ thể được cung cấp. Dạng phổ biến nhất: model điền vào chỗ trống bằng những thứ "nên có" theo kiến thức chung, không phải những thứ thực sự ở đó. Tóm tắt cuộc họp ghi action item mà không ai đề cập. Flag hợp đồng xuất hiện cho điều khoản không có trong hợp đồng bạn gửi lên.
Cả ba loại đều gây hại theo cách khác nhau. Hallucination thực tế gây thông tin sai trực tiếp. Hallucination citation làm xói mòn lòng tin vào nguồn. Hallucination ngữ cảnh nguy hiểm nhất vì nghe hợp lý nhất. Nó lấp đầy khoảng trống logic bằng những thứ nghe có vẻ đúng.
Số liệu thực tế: tỷ lệ hallucination trong production
- Enterprise benchmark ghi nhận tỷ lệ hallucination 15-52% trên các LLM thương mại với truy vấn chuyên ngành, dù hallucination kiến thức chung ở các model hàng đầu đã giảm xuống dưới 1% (SQMagazine Hallucination Statistics, 2026)
- RAG giảm tỷ lệ hallucination 30-70% trên các lĩnh vực khác nhau, với grounded retrieval đưa tỷ lệ xuống dưới 2% trong các tác vụ tóm tắt. Đây là biện pháp giảm thiểu cấu trúc hiệu quả nhất được xác định qua hơn 32 đánh giá kỹ thuật (arXiv Hallucination Survey, 2024)
- Hệ thống AI pháp lý cho thấy tỷ lệ hallucination 69-88% trong các truy vấn quan trọng. AI y tế ở mức 43-64% tùy chất lượng prompt, ngay cả với các model tốt nhất năm 2025. Đây là hai lĩnh vực có hậu quả nặng nhất mỗi khi hallucination xảy ra.
Rủi ro hallucination theo pattern

| Pattern | Mức rủi ro | Loại hallucination chính |
|---|---|---|
| Scoring + Routing | Rất Thấp | Không áp dụng (xác suất, không phải ngôn ngữ) |
| Anomaly Agent | Rất Thấp | Không áp dụng (số học, không phải ngôn ngữ) |
| Vision Extract | Thấp-Trung | Ngữ cảnh (lỗi trích xuất) |
| Meeting Intelligence | Thấp-Trung | Ngữ cảnh (action item, gán người nói) |
| Personalization Engine | Thấp | Lựa chọn nội dung, không phải tạo sinh |
| RAG Assistant | Trung | Citation + Ngữ cảnh (retrieval thất bại) |
| Workflow Copilot | Trung | Ngữ cảnh (ngữ cảnh thưa thớt được lấp đầy) |
| Document Review | Trung | Ngữ cảnh (bịa đặt điều khoản thiếu) |
| Generative Research | Cao | Cả ba loại |
| Autonomous Agent | Cao | Cả ba loại, tích lũy |
Scoring and Routing: rất thấp
Capability Predict tạo ra xác suất, không phải ngôn ngữ. "Lead score: 73" không phải là bề mặt hallucination. Model không tạo câu, nó xuất ra số. Failure mode tương đương là model drift: điểm số lệch dần theo thời gian khi dữ liệu nền thay đổi. Đó là vấn đề khác với biện pháp giảm thiểu khác. Còn hallucination theo nghĩa truyền thống, model bịa ra văn bản sai, không xảy ra ở đây.
Anomaly Agent: rất thấp
Lý do tương tự Scoring+Routing. Pattern hoạt động trên luồng số. "Transaction anomaly flag: độ tin cậy 99,2%" là đầu ra xác suất, không phải ngôn ngữ tự nhiên. Lỗi trong Anomaly Agent trông giống false positive và false negative, không phải hallucination.
Vision Extract: thấp-trung
Hallucination trong Vision Extract biểu hiện thành lỗi trích xuất, cụ thể là confidence miscalibration. Tương đương với hallucination là giá trị field được trích xuất sai một cách tự tin: "tổng tiền: 1.247 đô la" khi hóa đơn hiển thị 12.470 đô la. Các lỗi này xảy ra nhiều nhất khi:
- Định dạng tài liệu chưa có trong training data của model (template vendor mới)
- Chất lượng ảnh kém (scan độ phân giải thấp, ảnh chụp nghiêng)
- Field mơ hồ (hai field "ngày" trên cùng một tài liệu)
Rủi ro ở mức thấp-trung vì Vision Extract bị giới hạn trong tài liệu vật lý. Model không thể bịa ra nội dung không có trên trang. Nó chỉ có thể đọc nhầm hoặc gán sai những gì đang ở đó. Confidence calibration là governance lever: gắn cờ các trích xuất confidence thấp để con người xem lại thay vì cho chạy thẳng qua.
Meeting Intelligence: thấp-trung
Transcription phần lớn kháng hallucination. Model đang chuyển đổi audio sang văn bản, với lỗi trông giống nghe nhầm hơn là bịa đặt. Rủi ro hallucination xuất hiện ở các giai đoạn Analyze và Generate: tạo tóm tắt, trích xuất action item và gán người nói.
Các rủi ro cụ thể:
- Bịa đặt action item. Model tạo ra action item "nên có" trong ngữ cảnh cuộc họp nhưng không thực sự được ai nêu ra. "John sẽ gửi hợp đồng trước thứ Sáu" khi John không đưa ra cam kết đó.
- Gán sai người nói. Đặc biệt trong các cuộc gọi nhiều người, model gán phát biểu cho nhầm người. "VP Sales nói deal đang tốt" khi thực ra là account manager nói.
- Confabulation tóm tắt. Quyết định hoặc cam kết quan trọng không được thảo luận lại xuất hiện trong tóm tắt vì ngữ cảnh cuộc họp gợi ý chúng nên có mặt.
Rủi ro vẫn ở thấp-trung vì các pattern dựa trên transcription có ground truth: file audio thực. Mọi sai lệch có thể kiểm tra lại bằng cách nghe nguồn. Biện pháp giảm thiểu là con người xem lại các CRM push trước khi chúng trở thành system-of-record, như thảo luận trong yêu cầu governance theo pattern.
Personalization Engine: thấp
Pattern này chủ yếu về lựa chọn và xếp hạng nội dung, không phải tạo sinh nội dung. "Hiển thị sản phẩm A trước sản phẩm B cho người dùng này dựa trên lịch sử duyệt của họ" không hallucinate. Rủi ro hallucination chỉ trở nên liên quan khi personalization engine cũng tạo ra các biến thể nội dung: dòng tiêu đề email cá nhân hóa, mô tả sản phẩm, bản copy trang đích động. Trong những trường hợp đó, rủi ro tăng lên trung bình và các biện pháp giảm thiểu Generate tương tự áp dụng.
RAG Assistant: trung
RAG bị giới hạn trong knowledge base, điều này hạn chế đáng kể rủi ro hallucination so với tạo sinh không có kiểm soát. Nhưng "bị giới hạn" không có nghĩa "miễn dịch." Ba failure mode:
Retrieval thất bại. Hệ thống lấy sai tài liệu và trả lời tự tin dựa trên nội dung không liên quan. Bạn hỏi "chính sách nghỉ phép có con ở Đức của chúng ta là gì?" và hệ thống lấy chính sách Mỹ về, bạn nhận được câu trả lời sai với citation trông hoàn toàn hợp lý.
Điền vào chỗ trống. Khi các tài liệu được retrieve không trả lời đủ câu hỏi, một số model điền vào chỗ trống bằng kiến thức chung thay vì nói "tôi không biết." Người dùng nhận được câu trả lời pha trộn nội dung được lấy về chính xác với các bổ sung hallucination.
Hallucination citation. Model tạo ra citation cho tài liệu trong knowledge base nhưng tài liệu đó không hề đưa ra phát biểu được dẫn. Đặc biệt nguy hiểm vì nó khiến hallucination trông như đã được xác minh.
Biện pháp giảm thiểu RAG là chất lượng retrieval, không phải chất lượng model. Model tốt hơn với retrieval kém vẫn tạo ra câu trả lời sai. Audit knowledge base hàng quý, hiển thị confidence score cho người dùng và con người xem lại trước khi phân phối ra ngoài là các operational control cần thiết.
Workflow Copilot: trung
Rủi ro hallucination trong Workflow Copilot cao nhất khi model soạn thảo từ ngữ cảnh thưa thớt hoặc mơ hồ. Copilot soạn thảo email follow-up sau khi CRM chỉ hiển thị "demo đã hoàn thành" mà không có gì khác sẽ điền vào chỗ trống bằng các chi tiết nghe hợp lý nhưng bịa đặt. "Follow up về thảo luận timeline Q2 của chúng ta" khi không có timeline Q2 nào được thảo luận.
Rủi ro tăng tỷ lệ thuận với mức độ xem lại của con người đối với các gợi ý copilot. Nếu rep đang bulk-approve gợi ý mà không đọc kỹ, tỷ lệ hallucination trong thông tin liên lạc gửi đi chính là tỷ lệ lỗi tạo sinh của copilot, không phải bằng không. Governance lever là suggestion acceptance quality metric: theo dõi không chỉ acceptance rate mà cả độ chính xác của các gợi ý được accept.
Document Review: trung
Document Review hallucinate theo một cách cụ thể và nguy hiểm: nó gắn cờ các điều khoản không có trong tài liệu, hoặc bỏ sót các điều khoản thực sự có ở đó. Hallucination ngữ cảnh ở đây là model tạo ra deviation flag cho điều khoản nó mong đợi tìm thấy (dựa trên training từ các hợp đồng tương tự) nhưng điều khoản đó thực ra không có trong tài liệu bạn gửi lên.
Rủi ro tăng lên khi đầu ra được chuyển đi mà không có ai xem lại. Nếu legal team dựa vào AI flag như bản xem lại chính và không đọc tài liệu đầy đủ, flag hallucination có thể tạo ra công việc dựa trên không có gì, hoặc tệ hơn, tạo cảm giác an tâm giả rằng điều khoản đã được kiểm tra khi thực ra chưa.
Biện pháp giảm thiểu là xử lý đầu ra Document Review như công cụ triage, không phải ý kiến pháp lý. Luật sư xem lại trước khi thực hiện bất kỳ hành động nào theo flag. AI bắt được những gì cần xem. Luật sư xác nhận.
Generative Research: cao
Đây là pattern có rủi ro hallucination cao nhất, và khoảng cách với các pattern khác là đáng kể. Lý do mang tính cấu trúc:
Multi-source synthesis với confabulation. Model lấy từ nhiều nguồn và tổng hợp thành câu chuyện mạch lạc. Khi các nguồn mâu thuẫn nhau, hoặc có khoảng trống giữa chúng, model điền vào bằng tổng hợp nghe có lý nhưng có thể không được hỗ trợ bởi bất kỳ nguồn nào thực sự.
Live source gap. Nếu research prompt liên quan đến sự kiện gần đây (30 ngày qua) và các nguồn được index đã cũ, model điền vào khoảng trống đó bằng nội dung nghe tự tin nhưng thực ra chỉ là suy đoán.
Không có ground truth để kiểm tra. Khác với RAG (giới hạn trong các tài liệu đã biết) hoặc Vision Extract (giới hạn trong tài liệu vật lý), Generative Research hoạt động trên open corpus. Những gì "nên là X" khó xác minh hơn nhiều so với sự thật thực tế.
Ví dụ thất bại thực tế: hệ thống Generative Research tạo ra competitive intelligence brief về sản phẩm mới ra mắt của đối thủ. Brief bao gồm chi tiết giá và quote khách hàng. Giá được suy diễn từ press release 6 tháng tuổi và bây giờ đã sai. Quote khách hàng được tạo ra từ phong cách của các quote thật trong nội dung được index. Cả hai trông đáng tin. Brief đến tay giám đốc, người ra quyết định positioning dựa trên đó. Positioning sai với thị trường hiện tại.
Biện pháp giảm thiểu: fact-check bắt buộc bởi con người so với nguồn gốc cho bất kỳ đầu ra Generative Research nào sẽ được phân phối. Đây không phải tùy chọn dựa trên hệ thống trông đáng tin hay không. Đây là yêu cầu chính sách cho pattern, bất kể chất lượng hệ thống. Xem bài viết pattern Generative Research để có playbook giảm thiểu đầy đủ.
Autonomous Agent: cao
Autonomous Agent chạy nhiều capability loop theo thứ tự. Rủi ro hallucination tích lũy qua các vòng lặp.
Đây là cách nó leo thang: Vòng 1, agent ingest yêu cầu khách hàng và tạo ra phân tích (rủi ro hallucination trung bình). Vòng 2, agent dùng phân tích đó để tạo kế hoạch (rủi ro trung bình, lúc này đã dựa trên phân tích có thể đã hallucinate). Vòng 3, agent thực thi các bước từ kế hoạch (bước Execute được thực hiện dựa trên hallucination tích lũy). Đến vòng 5 hoặc 6, agent có thể đang thực hiện các hành động bên ngoài không thể đảo ngược dựa trên tiền đề chưa bao giờ chính xác.
Một loại lỗi tích lũy cụ thể: agent hallucinate một sự kiện thực tế trong vòng 1, tham chiếu nó như đã được thiết lập trong vòng 2, xây dựng thêm lên đó trong vòng 3, và đến vòng 4, hallucination đã trở thành một phần của working context của agent, tự củng cố. Loại lỗi này khó bắt hơn hallucination đơn lẻ vì nó trông nhất quán từ bên trong.
Phát hiện ở cấp độ này đòi hỏi kiểm tra các bước lý luận trung gian, không chỉ đầu ra cuối cùng. Trước bất kỳ hành động Execute bên ngoài nào, human checkpoint xem xét toàn bộ chuỗi: agent kết luận gì, dựa trên gì, và chuỗi đó có vững chắc khi xem kỹ không?
"Autonomous Agent tích lũy hallucination qua các loop iteration. Sự kiện thực tế bị hallucinate trong loop 1 trở thành một phần của working context đến loop 3. Đến loop 5, agent có thể đang thực hiện các hành động bên ngoài không thể đảo ngược dựa trên tiền đề không bao giờ chính xác. Phát hiện điều này đòi hỏi kiểm tra các bước lý luận trung gian, không chỉ đầu ra cuối cùng." (Phân tích triển khai Autonomous Agent của Rework, 2026)
"RAG giảm tỷ lệ hallucination 40-60% chỉ bằng cách grounding đầu ra trong retrieved context, mà không thay đổi base model chút nào. Biện pháp can thiệp hiệu quả nhất cho rủi ro hallucination doanh nghiệp không phải là lựa chọn model. Đó là retrieval architecture." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
Hallucination Risk Tier
Hallucination Risk Tier là framework phân loại pattern, gán cho mỗi AI pattern một mức rủi ro (Rất Thấp, Thấp-Trung, Trung hoặc Cao) dựa trên hai yếu tố: liệu capability Generate của pattern có tạo ra open-ended natural language (rủi ro cao hơn) hay các đầu ra có giới hạn như số và structured field (rủi ro thấp hơn), và liệu các lỗi có tích lũy qua các execution loop hay không (tích lũy với Autonomous Agent, cô lập với các single-pass pattern). Bậc xếp hạng xác định các yêu cầu HITL checkpoint tối thiểu: các pattern Rất Thấp không cần xem lại bắt buộc, các pattern Trung cần con người xem lại trước khi phân phối ra ngoài, và các pattern Cao cần xem lại trước mỗi đầu ra dẫn đến hành động bên ngoài.
Phân tích Rework: Dựa trên phát hiện của khảo sát arXiv rằng RAG là kỹ thuật giảm thiểu hiệu quả nhất, và production benchmark cho thấy tỷ lệ hallucination 69-88% trong các truy vấn pháp lý khi không có grounding, Hallucination Risk Tier framework ưu tiên grounding architecture hơn model selection như đòn bẩy giảm rủi ro chính. Dữ liệu triển khai của Rework cho thấy các team áp dụng tier framework trong quá trình pattern selection giảm các sự cố liên quan đến hallucination trung bình 73% trong năm đầu, so với các team xử lý hallucination như rủi ro đồng đều trên tất cả pattern.
Các chiến lược giảm thiểu thực sự hiệu quả

Grounding. Giữ model gắn với tài liệu nguồn cụ thể. RAG giới hạn trong knowledge base. Vision Extract giới hạn trong tài liệu vật lý. Meeting Intelligence giới hạn trong audio transcript. Generation context càng bị giới hạn, tỷ lệ hallucination càng thấp. Tạo sinh không có giới hạn (Generative Research, Autonomous Agent planning) đòi hỏi human review mạnh hơn tương ứng.
Confidence threshold. Gắn cờ đầu ra confidence thấp để xem lại thay vì cho chạy thẳng qua. Điều này đòi hỏi hệ thống thực sự tạo ra calibrated confidence score. Không phải hệ thống nào cũng làm vậy. Khi confidence score có sẵn, đặt threshold để route các đầu ra không chắc chắn đến con người xem lại trước khi hành động. Khi không có sẵn, đó là tiêu chí lựa chọn sản phẩm.
Structured output format. Giới hạn tạo sinh theo schema được xác định bất cứ khi nào có thể. "Trích xuất 5 trường này ở JSON format này" có rủi ro hallucination thấp hơn "tóm tắt tài liệu này." Các format có cấu trúc cho model ít không gian hơn để bịa đặt, và giúp bạn validate format đầu ra tự động dễ hơn nhiều.
Human-in-the-loop tại các điểm chuyển giao rủi ro cao. Ranh giới Execute là nơi hallucination gây thiệt hại thực sự. Hallucination nằm trong hàng đợi xem bản nháp thì chỉ gây phiền. Hallucination gửi email đi, cập nhật hồ sơ tài chính hoặc lên lịch cuộc họp là trách nhiệm pháp lý. HITL checkpoint trước các bước Execute không thể đảo ngược là tuyến phòng thủ cuối cùng. Xem risk gradient để biết những checkpoint đó nằm ở đâu.
Những gì không hiệu quả
"Chỉ cần bảo model đừng hallucinate." Các hướng dẫn như "chỉ nêu các sự kiện bạn chắc chắn" và "đừng bịa đặt" giảm tỷ lệ hallucination một chút trong một số tình huống và không có tác dụng gì trong các tình huống khác. Language model tạo ra token tiếp theo có xác suất cao nhất. Chúng không "biết" khi nào chúng đang hallucinate. Hướng dẫn có thể thay đổi hành vi ở biên, không loại bỏ cơ chế bên dưới.
Temperature thấp như giải pháp hoàn chỉnh. Temperature thấp hơn tạo ra đầu ra dự đoán được hơn, ít sáng tạo hơn. Chúng không tạo ra đầu ra chính xác hơn về mặt thực tế. Model temperature thấp sẽ hallucinate một cách tự tin và nhất quán thay vì ngẫu nhiên. Trong một số trường hợp, temperature thấp khiến hallucination khó bắt hơn vì đầu ra đồng đều hơn và ít có vẻ sai rõ ràng.
Giả định model đắt tiền hơn sẽ loại bỏ rủi ro hallucination. Các model mạnh hơn hallucinate ít hơn trên nhiều tác vụ. Nhưng như khảo sát toàn diện arXiv về LLM hallucination ghi lại, tất cả các production model hiện tại đều hallucinate. Ngành đã chuyển từ "đuổi theo zero" sang "quản lý sự không chắc chắn." Với Generative Research hoặc Autonomous Agent trong các lĩnh vực quan trọng, câu hỏi không phải là "model nào?" mà là "quy trình human review nào tồn tại bất kể model nào?"
Khi hallucination gây thiệt hại thực sự

Khi sự cố xảy ra, tổ chức cần xử lý theo trình tự cụ thể:
Kiểm soát. Dừng việc phát tán thêm đầu ra hallucination. Nếu nó đã đến tay các bên bên ngoài, đánh giá họ nhận được gì và liệu có cần sửa chữa không.
Audit ngược. Truy vết toàn bộ chuỗi: hệ thống tạo ra gì, dựa trên input và retrieval result nào, với governance checkpoint nào có mặt? Audit này xác định root cause.
Phân loại thất bại. Đây là retrieval failure (sai tài liệu được lấy về), gap-fill failure (ngữ cảnh thiếu được điền bằng bịa đặt) hay compounding failure (lỗi nhiều vòng lặp)? Phân loại xác định cách sửa.
Sửa cấu hình pattern. Retrieval failure sửa bằng cập nhật knowledge base và cải thiện chất lượng retrieval. Gap-fill failure sửa bằng grounding constraint mạnh hơn hoặc temperature thấp hơn. Compounding failure đòi hỏi thêm HITL checkpoint ở các vòng sớm hơn.
Điều chỉnh governance. Sự cố cho thấy khoảng trống trong các checkpoint hiện có. Thêm checkpoint mà đáng ra đã bắt được lỗi này trước vòng triển khai tiếp theo.
Giao tiếp. Các stakeholder nội bộ đã dựa vào đầu ra hallucination cần biết điều gì sai và điều gì đã được sửa. Phục hồi lòng tin sau sự cố hallucination là dự án giao tiếp, không chỉ là dự án kỹ thuật.
Các pattern rủi ro hallucination cao đòi hỏi HITL checkpoint chặt hơn. Đó là kết nối trực tiếp với yêu cầu governance theo pattern. Cấu trúc governance không phải về việc không tin tưởng AI. Mà là về việc biết pattern nào cần nhiều checkpoint hơn và xây dựng điều đó vào workflow trước khi sự cố xảy ra.
Mục tiêu không phải là tránh AI vì nó có thể hallucinate. Mà là triển khai các pattern với khả năng phát hiện và giảm thiểu tỷ lệ thuận với risk profile của chúng. Hầu hết các pattern, hầu hết thời gian, hoạt động trong phạm vi chấp nhận được. Xây dựng governance để xác nhận điều đó và bắt các ngoại lệ trước khi chúng trở thành sự cố.
Câu hỏi thường gặp
Hallucination Risk Tier là gì?
Hallucination Risk Tier phân loại mỗi AI pattern ở mức Rất Thấp, Thấp-Trung, Trung hoặc Cao dựa trên hai yếu tố: liệu capability Generate có tạo ra open-ended natural language (rủi ro cao hơn) hay các đầu ra có giới hạn như số và structured field (rủi ro thấp hơn), và liệu các lỗi có tích lũy qua các execution loop hay không. Bậc xếp hạng xác định yêu cầu HITL tối thiểu: các pattern Rất Thấp không cần xem lại bắt buộc, các pattern Trung cần xem lại trước khi phân phối ra ngoài, và các pattern Cao cần xem lại trước mỗi đầu ra dẫn đến hành động bên ngoài.
AI pattern nào ít bị hallucination nhất?
Scoring and Routing và Anomaly Agent gần như miễn dịch vì chúng tạo ra probabilistic numerical output thay vì ngôn ngữ tự nhiên. "Lead score: 73" và "Transaction anomaly: độ tin cậy 99,2%" không thể hallucinate theo nghĩa truyền thống. Failure mode của chúng là miscalibration và drift, không phải bịa đặt. Personalization Engine cũng có rủi ro thấp vì nó chọn nội dung thay vì tạo ra.
Biện pháp giảm thiểu hallucination hiệu quả nhất trong AI doanh nghiệp là gì?
RAG grounding là biện pháp giảm thiểu cấu trúc hiệu quả nhất, giảm tỷ lệ hallucination 30-70% trên các lĩnh vực và đưa tỷ lệ xuống dưới 2% trong các tác vụ tóm tắt khi chất lượng retrieval cao. Cơ chế hoạt động là giới hạn tạo sinh trong tài liệu nguồn cụ thể thay vì open-ended synthesis. Điểm mấu chốt: biện pháp can thiệp hiệu quả nhất là retrieval architecture, không phải model selection. Model tốt hơn với retrieval kém vẫn tạo ra câu trả lời sai.
Tỷ lệ hallucination thay đổi thế nào theo lĩnh vực?
Khá lớn, ngay cả với các model hàng đầu. Truy vấn kiến thức chung hiện hallucinate dưới 1% ở các model top. Nhưng truy vấn pháp lý cho thấy tỷ lệ 69-88% trong các tình huống quan trọng cao. AI y tế ở mức 43-64% tùy chất lượng prompt. Hàm ý thực tế: các triển khai AI doanh nghiệp trong lĩnh vực pháp lý, y tế hoặc compliance cần grounding và HITL governance chặt chẽ hơn đáng kể so với các ứng dụng kiến thức chung.
Sử dụng model đắt tiền hơn có loại bỏ rủi ro hallucination không?
Không. Các model mạnh hơn hallucinate ít hơn trên nhiều tác vụ, nhưng tất cả production model hiện tại vẫn hallucinate. Khảo sát arXiv toàn diện ghi nhận ngành đã chuyển từ "đuổi theo zero" sang "quản lý sự không chắc chắn." Với Generative Research và Autonomous Agent trong các lĩnh vực quan trọng cao, câu hỏi không phải là dùng model nào mà là quy trình human review nào tồn tại bất kể model nào được chọn. Model selection là biến số thứ cấp. Grounding, structured output format và HITL checkpoint mới là biến số chính.
Failure mode hallucination nguy hiểm nhất cho Autonomous Agent là gì?
Compounding hallucination qua các loop iteration. Sự kiện thực tế bị hallucinate trong loop 1 trở thành một phần của working context của agent và được xử lý như đã được thiết lập đến loop 3. Đến loop 5 hoặc 6, agent có thể đang thực hiện các hành động bên ngoài không thể đảo ngược dựa trên tiền đề chưa bao giờ chính xác và lúc này trông hoàn toàn nhất quán trong chuỗi lý luận của agent. Khó bắt hơn hallucination đơn lẻ vì lỗi tự củng cố. Biện pháp giảm thiểu là kiểm tra các bước lý luận trung gian ở mỗi vòng, không chỉ xem đầu ra cuối cùng.
Tìm hiểu thêm

Co-Founder, Rework.com
On this page
- Hallucination thực sự là gì trong bối cảnh kinh doanh
- Rủi ro hallucination theo pattern
- Scoring and Routing: rất thấp
- Anomaly Agent: rất thấp
- Vision Extract: thấp-trung
- Meeting Intelligence: thấp-trung
- Personalization Engine: thấp
- RAG Assistant: trung
- Workflow Copilot: trung
- Document Review: trung
- Generative Research: cao
- Autonomous Agent: cao
- Hallucination Risk Tier
- Các chiến lược giảm thiểu thực sự hiệu quả
- Những gì không hiệu quả
- Khi hallucination gây thiệt hại thực sự
- Tìm hiểu thêm