Wenn AI Patterns im Maßstab teuer werden

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Das Pilot-Deployment sah erschwinglich aus. Sie haben 500 Dokumente verarbeitet, das System 60 Tage lang betrieben und 400 US-Dollar ausgegeben. Finance hat das Full Rollout genehmigt. Sechs Monate später verarbeiten Sie 50.000 Dokumente und die Rechnung beläuft sich auf 40.000 US-Dollar. Nicht 4.000 US-Dollar. Nicht 8.000 US-Dollar. 40.000 US-Dollar, weil die Dokumentkomplexität gestiegen ist, Sie einen zweiten LLM-Pass für die Qualitätskontrolle hinzugefügt haben und der Embeddings-Index beim Hinzufügen neuer Dokumenttypen neu aufgebaut werden musste.
AI Cost Overruns im Maßstab sind im Nachhinein fast immer vorhersehbar. Das Per-Inference-Preismodell, das Token-Skalierungsverhalten mit der Dokumentgröße, die Speicherkosten für Embeddings: nichts davon ist versteckt. Es wird vor dem Deployment nur nicht sorgfältig modelliert, weil Pilots bei geringem Volumen laufen und die Kosten bei geringem Volumen unsichtbar sind.
Dieser Artikel macht Kostenüberraschungen im Voraus vorhersehbar, Pattern für Pattern.
Warum AI-Kostenkurven sich von Software-Kostenkurven unterscheiden
Traditionelle Software-Kosten sind größtenteils fix: Lizenzgebühr, Implementierungskosten und ein relativ flacher Zuwachs pro Benutzer. Sie zahlen für Lizenzen, nicht für die Nutzung. Das Kostenmodell ist vorhersehbar und front-loaded.
AI-Pattern-Kosten sind verbrauchsbasiert auf eine Weise, die mit Ihrem Datenvolumen, der Dokumentkomplexität und den Query-Mustern interagiert. McKinseys Analyse der neuen Ökonomie der Unternehmenstechnologie in einer AI-Welt dokumentiert diesen Wandel: 79 % der IT-Ausgaben sind jetzt Betriebsausgaben statt Kapitalausgaben, und Token-basierte LLM-Nutzung ist ein wesentlicher Treiber der FinOps-Komplexität. Vier Dynamiken, die Software nicht hat:
Per-Inference-Pricing. Jeder Modellaufruf kostet Tokens. Token-Kosten skalieren mit Input-Länge und Output-Länge. Ein 10-seitiges Dokument kostet ungefähr 10-mal mehr zu verarbeiten als ein 1-seitiges Dokument. Bei geringem Volumen ist dies unsichtbar. Bei hohem Volumen ist es Ihr größter Kostenpunkt.
Speicherkosten für Embeddings und Indexes. RAG Assistant-Systeme speichern Vektor-Embeddings für jedes indizierte Dokument. Vektorspeicherung hat Kosten pro Dimension und pro Datensatz. Eine Wissensbasis mit 100.000 Dokumenten bei 1.536 Dimensionen pro Embedding erfordert erheblichen Speicher, und das erneute Embedding beim Aktualisieren von Dokumenten ist ein Compute-Ereignis, kein reines Storage-Update.
Retraining-Kosten, die mit der Geschäftskomplexität steigen. Scoring-Modelle, Anomalie-Baselines und Empfehlungsmaschinen benötigen periodisches Retraining, wenn sich Ihre Daten ändern. Frühe Retraining-Zyklen sind günstig, weil Sie relativ wenig Daten haben. Spätere Retraining-Zyklen sind teurer, weil Sie mehr Daten und komplexere Muster zu lernen haben.
Nicht-lineares Kostenverhalten bei komplexen Inputs. Ein 50-seitiger Vertrag kostet ungefähr 50-mal mehr pro LLM-Pass als ein 1-seitiger Vertrag. Ein Meeting mit 8 Teilnehmern kostet mehr für Zuordnung und Zusammenfassung als ein 2-Personen-Anruf. Die Pro-Einheits-Kosten am unteren Ende der Komplexitätsverteilung sehen viel besser aus als die durchschnittlichen Kosten beim Produktionsvolumen.
Key Facts: AI-Kosten im Maßstab
- Agentische AI-Modelle benötigen zwischen 5 und 30-mal mehr Tokens pro Aufgabe als ein Standard-Generative-AI-Chatbot. Ein Autonomous Agent, der iterativ denkt und Tools aufruft, kann 10-20 LLM-Aufrufe pro einzelner Benutzeraufgabe auslösen. (Gartner, März 2026)
- Token-Preise sind in zwei Jahren um den Faktor 280 gefallen, aber die gesamten Enterprise AI-Ausgaben sind im gleichen Zeitraum um 320 % gestiegen, getrieben durch den Wechsel zu agentischen Workflows und RAG-Architekturen, die Kontextfenster um das 3-5-fache aufblähen. (Oplexa Inference Cost Crisis Analysis, 2026)
- 55 % der ML-Modelle in der Produktion benötigen ein Retraining innerhalb von 90 Tagen, was Retraining-Kosten zum anfänglichen Deployment-Budget hinzufügt, die die meisten Teams im ersten Jahr nie modellieren. (DataRobot, 2025)
Kostentreiber nach Pattern
RAG Assistant
Primärer Kostentreiber: Kontextfenstergröße während Retrieval und Generierung.
Eine einfache RAG-Query ruft 3-5 Dokumentfragmente ab und nutzt sie als Kontext für eine Antwort. Wenn jedes Fragment 500 Tokens umfasst, beträgt Ihr Kontextfenster für die Generierung 1.500-2.500 Tokens plus die Frage. Bei 0,01 US-Dollar/1.000 Tokens für ein Mid-Tier-Modell sind das etwa 0,02-0,03 US-Dollar pro Query.
Bei 10.000 Queries/Monat: 200-300 US-Dollar. Vertretbar.
Aber bei hohem Query-Volumen mit komplexen Fragen rufen RAG-Systeme oft mehr Fragmente ab (bessere Genauigkeit erfordert mehr Kontext) und nutzen längere Kontextfenster. Eine komplexe Richtlinienfrage kann 10 Fragmente à 1.000 Tokens abrufen: 0,10-0,15 US-Dollar pro Query. Bei 50.000 Queries/Monat sind das 5.000-7.500 US-Dollar/Monat allein für Query-Kosten, vor dem Speicher.
Die Index-Refresh-Kosten sind die zweite Überraschung. Wenn Ihre Wissensbasis 500.000 Dokumente umfasst und Sie monatlich 10 % aktualisieren, sind das 50.000 Re-Embeddings pro Monat. Bei 0,0001 US-Dollar pro Embedding (text-embedding-3-small-Preisgestaltung) sind das 5 US-Dollar/Monat. Bei text-embedding-3-large: 0,13 US-Dollar pro 1.000 Tokens, durchschnittliches Dokument 500 Wörter (~667 Tokens) = 0,087 US-Dollar pro Dokument. 50.000 Re-Embeddings = 4.350 US-Dollar/Monat allein für die Index-Wartung.
Scoring + Routing
Per-Inference-Kosten sind gering. Scoring-Modelle sind typischerweise kleiner, schneller und günstiger als Generierungsmodelle. Das wichtigste Kostenrisiko liegt in der Retraining-Häufigkeit und der Dateninfrastruktur.
Ein Scoring-Modell, das vierteljährliches Retraining benötigt, erfordert: Datenabruf und -bereinigung, Feature-Engineering-Compute, Modell-Training-Compute, Evaluierung und Deployment. Für ein internes Modell ist dies Engineering-Zeit. Für ein Vendor-managed-Modell ist es in der Regel eine Service-Gebühr. Die Kosten sind begrenzt und vorhersehbar, aber Teams budgetieren sie oft nicht im zweiten Jahr, weil sie nicht Teil der anfänglichen Deployment-Kosten waren.
Vision Extract
Pro-Seiten-Verarbeitungskosten skalieren linear mit dem Dokumentvolumen. Dies ist vorhersehbar. Das Kostenmodell ist transparent. Aber „wir werden 200 Dokumente pro Monat verarbeiten" im Pilot wird oft zu „wir müssen 2 Jahre historische Rechnungen nachverarbeiten" (ein einmaliger Verarbeitungspeak) plus „alle neuen Rechnungen plus alle historischen Dokumente, die wir jetzt für verbesserte Genauigkeit erneut verarbeiten."
Hochauflösende Bildverarbeitung kostet mehr als niedrig auflösende. Wenn Ihr Vendor nach Rechenzeit pro Bild abrechnet und Sie Ihre Scantechnik aufrüsten, steigen Ihre Kosten pro Dokument selbst beim gleichen Dokumentvolumen.
Meeting Intelligence
Zwei Kostentreiber, die beide mit dem Nutzungsvolumen skalieren:
Transkriptions-Kosten. Speech-to-Text-APIs preisen typischerweise pro Audiominute. Whisper-class-Transkription kostet 0,006-0,024 US-Dollar/Minute je nach Service-Tier. Ein 60-minütiger Sales-Anruf: 0,36-1,44 US-Dollar. Bei 500 Anrufen/Monat: 180-720 US-Dollar allein für Transkription. Bei 5.000 Anrufen/Monat (Enterprise-Maßstab): 1.800-7.200 US-Dollar/Monat.
LLM-Zusammenfassungskosten. Lange Anrufe produzieren lange Transkripte. Ein 60-minütiges Anruf-Transkript umfasst ungefähr 8.000-12.000 Wörter (6.000-9.000 Tokens). Die Verarbeitung für Zusammenfassung, Action Items und CRM-Feldextraktion bei 0,01 US-Dollar/1.000 Tokens Input + 0,03 US-Dollar/1.000 Tokens Output: ungefähr 0,12-0,18 US-Dollar pro Anruf. Bei 5.000 Anrufen/Monat: 600-900 US-Dollar/Monat.
Die Kostenüberraschung tritt auf, wenn Teams Meeting Intelligence für alle Meetings deployen, nicht nur für kundenorientierte. Interne Standups, Planungsmeetings und All-Hands-Meetings produzieren keine nützlichen CRM-Daten, verursachen aber trotzdem Transkriptions- und Verarbeitungskosten. Eine einfache Scope-Richtlinie (Meeting Intelligence nur für externe Anrufe) reduziert die Kosten oft um 60-70 % ohne Wertverlust.
Anomaly Agent
Stream-Ingestion-Kosten bei hohem Datenvolumen sind das primäre Risiko. Wenn Ihr Anomaly Agent Transaktionsstreams bei 1 Million Ereignissen/Tag überwacht, sind Speicher- und Verarbeitungskosten erheblich, bevor Sie LLM-Aufrufe hinzufügen.
Bei rein statistischer Anomalieerkennung (kein LLM) sind die Kosten beherrschbar und skalieren vorhersehbar. Das Kostenrisiko tritt auf, wenn der Anomaly Agent LLM-Aufrufe für Kontextanreicherung verwendet („erkläre, warum diese Transaktion anomal ist, in natürlicher Sprache") oder für komplexe Multi-Signal-Korrelation. Bei hohem Alert-Volumen summieren sich diese LLM-Aufrufe.
Generative Research
LLM-Tokens für die Synthese skalieren mit der Länge des Quellmaterials. Ein Research-Brief, der 20 Quelldokumente à je 3.000 Wörter abruft, präsentiert dem Modell ungefähr 60.000 Wörter Kontext, bevor es irgendetwas generiert. Bei GPT-4-Preisgestaltung sind das 1,80-2,40 US-Dollar an Input-Tokens allein pro Forschungsaufgabe. Output-Generierung fügt weitere 0,30-0,60 US-Dollar hinzu. Pro Forschungsaufgabe: 2-3 US-Dollar.
Das klingt niedrig. Aber wenn Ihr Research-Operations-Team 100 Briefs/Monat generiert, sind das 200-300 US-Dollar/Monat allein in API-Kosten, vor den Infrastrukturkosten der Verwaltung der Research-Pipeline. Bei 1.000 Briefs/Monat skaliert dies auf 2.000-3.000 US-Dollar/Monat. Für einen großen Beratungsbetrieb mit 5.000+ Forschungsaufgaben/Monat nähern sich allein die LLM-Kosten 15.000-20.000 US-Dollar/Monat.
Der Kostenkontroll-Hebel: Scope-Begrenzung. Research, der 5 zielgerichtete Dokumente synthetisiert, kostet 75 % weniger als Research, der alles liest, was er finden kann. Research-Prompts mit expliziten Quelllimits („verwende die 10 relevantesten Quellen") produzieren vergleichbare Qualität wie unbegrenzte Quellensuche bei einem Bruchteil der Kosten.
Document Review
Vertragslänge ist der primäre Kostentreiber. Das Überprüfen eines 5-seitigen NDA kostet viel weniger als das Überprüfen eines 150-seitigen Enterprise-Software-Vertrags mit 40 Anhängen. Wenn sich Ihr Dokumentmix von kurzen Verträgen (Frühphasen-Startups) zu komplexen Enterprise-Verträgen (Wachstumsphase) verschiebt, steigen Ihre Pro-Dokument-Kosten erheblich ohne jede Volumenänderung.
Das zweite Risiko: mehrere Review-Durchläufe. Qualitätsbewusste Teams führen oft einen ersten Extraktionsdurchlauf, dann einen Klauselvergleichsdurchlauf und dann einen Zusammenfassungsgenerierungsdurchlauf durch. Jeder Durchlauf multipliziert die Basisdokumentkosten. Eine 3-Durchlauf-Review-Pipeline kostet das 3-fache einer Single-Pass-Pipeline. Definieren Sie Ihre erforderlichen Durchläufe im Voraus und budgetieren Sie dafür.
Workflow Copilot
Kontextfensterverwaltung ist der wichtigste Kostenhebel. Ein Workflow Copilot, der die gesamte CRM-Datensatzhistorie, die letzten 10 E-Mail-Threads, die relevanten Account-Dokumente und den aktuellen Aufgabenkontext bei jedem Vorschlagsaufruf abruft, ist teuer. Jeder Vorschlagsaufruf könnte 8.000-15.000 Tokens Kontext selbst für einen einfachen E-Mail-Entwurf verwenden.
Bei 20 Vorschlagsanfragen/Benutzer/Tag × 50 Benutzer = 1.000 Aufrufe/Tag. Bei 0,15 US-Dollar/Aufruf (Durchschnitt über Kontext + Output): 150 US-Dollar/Tag, 4.500 US-Dollar/Monat. Bei 200 Benutzern: 18.000 US-Dollar/Monat.
Kontextkomprimierung (historischen Kontext zusammenfassen statt rohe Datensätze einzuschließen), Query-Routing (einfachere Anfragen gehen an günstigere Modelle) und Suggestion-Caching (ähnliche Anfragen verwenden vorherige Antworten wieder) können diese Kosten um 50-70 % reduzieren ohne merklichen Qualitätsverlust.
Personalization Engine
Das Kostenrisiko liegt hier bei der Real-Time-Inference im Maßstab. Das Bereitstellen personalisierter Empfehlungen erfordert einen Modellaufruf (oder eine Vektor-Ähnlichkeitssuche) für jede Benutzerinteraktion. Bei 100.000 täglich aktiven Benutzern, die jeweils 10 personalisierungsrelevante Entscheidungen treffen: 1 Million Inferenzaufrufe pro Tag.
Wenn jeder Aufruf ein kleines dediziertes Modell bei 0,001 US-Dollar/Aufruf verwendet: 1.000 US-Dollar/Tag, 30.000 US-Dollar/Monat. Wenn Sie auf ein qualitativ hochwertigeres LLM für bessere Empfehlungen aufrüsten: Kosten multiplizieren sich 10-20-fach. Die Engineering-Entscheidung zwischen Modellqualität und Inferenzkosten ist die wichtigste Kostenarchitekturentscheidung für dieses Pattern.
Caching reduziert die Kosten erheblich: Wenn 40 % der Benutzer ähnlich genug Profile haben, dass Sie gecachte Empfehlungen bereitstellen können, eliminieren Sie 40 % der Inferenzaufrufe.
Autonomous Agent: das höchste Kostenrisiko
Dies ist das Pattern, das am wahrscheinlichsten unerwartete Budget-Ereignisse produziert. Nennen Sie es klar: Ein Autonomous Agent ohne harte Iterations-Limits und Pro-Aufgabe-Budget-Caps ist eine Haftung, kein Werkzeug.
Hier ist, was passiert, wenn es schiefgeht:
Ein Produktions-Customer-Support-Autonomous-Agent erhält eine Aufgabe: „Löse Ticket #48291: Kunde sagt, er wurde doppelt abgerechnet." Der Agent beginnt seine Schleife. Er liest das Ticket (1 Aufruf). Er ruft die Zahlungshistorie ab (1 Aufruf). Er findet eine Mehrdeutigkeit und sucht nach verwandten Tickets (2 Aufrufe). Er entwirft eine Antwort (1 Aufruf). Er stellt fest, dass er eine Manager-Genehmigung benötigt und sucht nach der Eskalationsrichtlinie (1 Aufruf). Er findet die Richtlinie unklar und liest das vollständige Richtliniendokument (1 Aufruf). Er entscheidet, dass er 3 Monate Transaktionshistorie überprüfen muss (3 Aufrufe). Er vergleicht die Transaktionen und generiert eine Analyse (2 Aufrufe). An diesem Punkt: 12 Modellaufrufe für ein Support-Ticket.
Aber der Agent hat auch einen unerwarteten Zweig getroffen: Der Kunde hatte eine verwandte Beschwerde von vor 6 Monaten, die relevant erschien. Der Agent rief diesen Thread ab. 4 weitere Aufrufe. Dann entschied er, dass die Account-Geschichte des Kunden relevant war. 3 weitere Aufrufe. Dann entwarf er zwei Lösungsoptionen, überarbeitete jede auf Basis der Unternehmensrichtlinie und formatierte die endgültige Antwort. 6 weitere Aufrufe.
Gesamt: 25 Modellaufrufe für ein Support-Ticket, bei 0,05-0,15 US-Dollar pro Aufruf = 1,25-3,75 US-Dollar pro Ticket-Lösung, gegenüber den 0,10-0,20 US-Dollar, die Sie basierend auf Ihrem Pilot mit einfachen Tickets budgetiert haben.
Bei 10.000 komplexen Tickets/Monat betragen die tatsächlichen Kosten 12.500-37.500 US-Dollar/Monat gegenüber budgetierten 1.000-2.000 US-Dollar/Monat. Das passiert.
Die Kostenkontrollanforderung: harte Iterations-Limits (maximal 10 Modellaufrufe pro Aufgabe), Pro-Aufgabe-Token-Budgets und automatischer Handoff an menschlichen Agenten, wenn Limits erreicht werden. Das sind keine operativen Annehmlichkeiten. Das sind finanzielle Kontrollen.
„Ein Autonomous Agent ohne harte Iterations-Limits ist kein Produktivitätswerkzeug. Es ist eine finanzielle Haftung. Gartners März 2026-Analyse bestätigt, dass agentische Modelle 5-30-mal mehr Tokens pro Aufgabe benötigen als Standard-Chatbots. Ein Agent, der bei komplexen Support-Tickets das obere Ende dieses Bereichs erreicht, kostet 3-4 US-Dollar pro Lösung zu Enterprise-Token-Preisen, gegenüber budgetierten 0,10-0,20 US-Dollar." (Rework Autonomous Agent Cost Analysis, 2026)
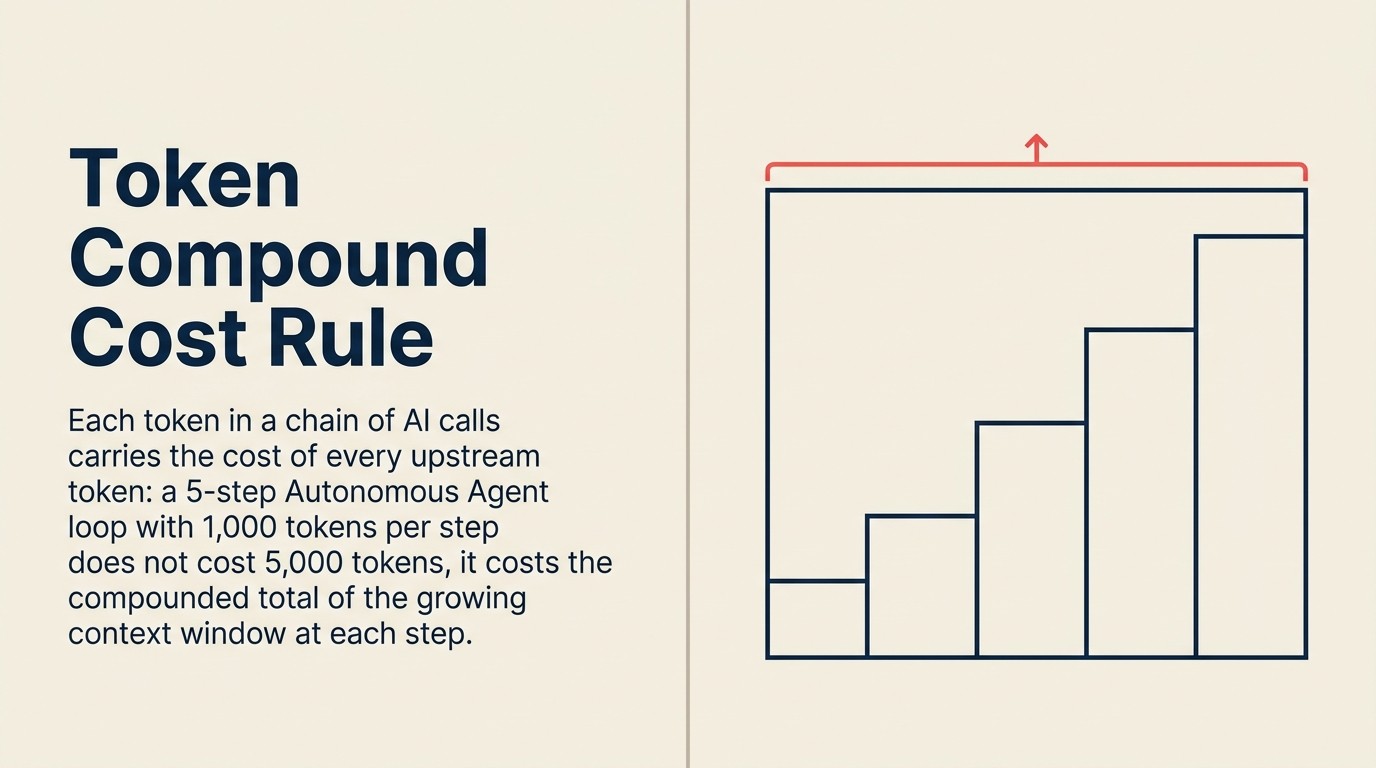
Die Token Compound Cost Rule
Die Token Compound Cost Rule besagt, dass die gesamten Enterprise AI-Ausgaben mit der Anzahl der LLM-Aufrufe pro Benutzeraufgabe, der durchschnittlichen Kontextfenstergröße pro Aufruf und der Retraining-Häufigkeit pro Pattern skalieren, nicht mit dem Per-Token-Preis. Dies erklärt, warum die gesamten Enterprise AI-Ausgaben um 320 % gestiegen sind, während die individuellen Token-Preise um den Faktor 280 gefallen sind: Der Wechsel zu agentischen Workflows (10-20 Aufrufe pro Aufgabe), RAG-Architekturen (3-5-fache Kontextfenster-Aufblähung) und Always-on-Monitoring-Agenten erzeugt kompoundierende Aufrufvolumina, die Per-Token-Preisreduktionen überwältigen. Die praktische Implikation der Regel lautet: Kostenkontrolle im Maßstab erfordert das Begrenzen von Aufrufen pro Aufgabe, das Cachen von wiederholtem Kontext und das Beschränken des Deployments auf die wertvollsten Workflows, statt auf weitere Token-Preissenkungen zu warten.
Rework-Analyse: Basierend auf Gartners Ergebnis, dass agentische Modelle 5-30-mal mehr Tokens pro Aufgabe benötigen, und Oplexas Ergebnis, dass Enterprise AI-Ausgaben um 320 % gestiegen sind trotz 280-facher Token-Preissenkungen, identifiziert die Token Compound Cost Rule drei Kostenmultiplikatoren, die Pilot-Budgets systematisch übersehen: Aufrufvolumen-Kompoundierung durch autonome Schleifen, Kontextfenster-Aufblähung durch RAG und History-Retrieval sowie Retraining-Häufigkeitskosten, die mit der Datenkomplexität skalieren. Reworks Implementierungsdaten zeigen, dass Teams, die alle drei Multiplikatoren vor der Deployment-Genehmigung modellieren, durchschnittliche Produktions-Cost-Overruns von 23 % haben. Teams, die nur den Per-Token-Preis modellieren, haben durchschnittliche Overruns von 287 %.
Die vier häufigsten Cost Overrun-Szenarien
Szenario 1: Der Embedding-Index, der ohne Bereinigung wächst. Ein RAG-System wird mit einer sauberen 10.000-Dokument-Wissensbasis deployed. Niemand entfernt alte Dokumente, wenn Richtlinien aktualisiert oder Produkte eingestellt werden. Zwei Jahre später hat der Index 80.000 Dokumente (die meisten davon veraltet), die Retrieval-Qualität verschlechtert sich, weil das Modell veralteten Inhalt abruft, und die Re-Indizierung zur Behebung kostet mehr als das ursprüngliche Deployment. Budget von Anfang an für Index-Wartung. So werden aus RAG-Systemen auch Tech Debt. Lesen Sie Wenn AI Patterns zu Tech Debt werden für den vollständigen Kostenverlauf.
Szenario 2: Autonomous Agent ohne Iterations-Limits. Oben beschrieben. Dies ist ein begrenztes Risiko mit einer vollständigen Lösung: Budget-Caps und Iterations-Limits, definiert vor dem Deployment. Jeder Autonomous Agent-Deployment-Vorschlag, der diese nicht als nicht-verhandelbare Anforderungen enthält, sollte zurückgesendet werden.
Szenario 3: Meeting Intelligence verarbeitet jedes interne Meeting. Der am einfachsten zu vermeidende Cost Overrun. 70 % der Meetings in den meisten Organisationen sind intern. Meeting Intelligence liefert null CRM-Wert für interne Meetings. Beschränken Sie das Deployment auf kundenorientierte Anrufe, bevor die Rechnung eintrifft.
Szenario 4: Generative Research mit zu breitem Scope. Research-Prompts, die „alles Relevante zu X recherchieren" sagen, produzieren vollständige Ergebnisse, aber vollständige Kosten. Definieren Sie maximale Quellanzahlen, maximale Dokumenttiefe und Themenumfang in Ihren Research-Prompt-Vorlagen. „Recherchiere die letzten 6 Monate der Wettbewerbsaktivität von Wettbewerber X mit den 10 relevantesten Quellen" produziert 85 % des Wertes von „recherchiere alles über Wettbewerber X" bei 20 % der Kosten.
Ein Kostenmodell vor dem Deployment aufbauen
Für jedes Pattern-Deployment, diese Inputs vor der Genehmigung modellieren:
| Input | Woher es kommt |
|---|---|
| Durchschnittliche Input-Token-Anzahl pro Aufruf | 20-30 repräsentative Samples messen |
| Durchschnittliche Output-Token-Anzahl pro Aufruf | Aus dem Prompt-Design schätzen |
| Erwartetes Aufrufvolumen (monatlich) | Aktuelles Workflow-Volumen als Baseline |
| Modell-Preisgestaltung (pro 1.000 Tokens) | Vendor-Preisliste |
| Speicherkosten (Embeddings, Aufnahmen, Indexes) | Vendor-Speicherpreisgestaltung |
| Retraining-Häufigkeit und -Kosten | Architekturentscheidung |
Drei Szenarien aufbauen: konservativ (aktuelles Volumen), moderat (2x aktuelles Volumen in Jahr 1) und aggressiv (5x Volumen bei Peak). Wenn das aggressive Szenario inakzeptable Kosten produziert, die Kostenkontrollelemente vor dem Deployment entwerfen, nicht danach.
Warum Pre-Deployment-Schätzungen in der Regel zu niedrig sind: Samples kommen aus den einfachsten, repräsentativsten Fällen. Die Produktion umfasst alle Edge Cases, langen Dokumente, komplexen Queries und unerwarteten Nutzungsmuster, die Pilots herausfiltern. Fügen Sie Ihrer zentralen Schätzung einen Puffer von 50-100 % hinzu.
Überwachung auf Kosten-Anomalien
Wenden Sie das Anomaly Agent-Konzept auf Ihre eigenen AI-Kostendaten an. Richten Sie Kosten-pro-Transaktion-Dashboards für jedes deployed Pattern ein. Definieren Sie normale Kostenbereiche basierend auf Ihren ersten 60 Produktionstagen. Setzen Sie Alerts, wenn Kosten-pro-Transaktion mehr als 30 % über die Baseline steigen.
Frühwarnzeichen:
- Durchschnittliche Kontextfenstergröße steigt (Zeichen für Prompt-Scope-Creep oder Änderungen der Input-Größe)
- Iterations-Anzahl pro Autonomous Agent-Aufgabe steigt (Zeichen für Aufgabenkomplexitäts-Creep oder Model Drift)
- Index-Refresh-Häufigkeit steigt (Zeichen für Wissensbasen-Wachstum ohne Bereinigung)
- Fehlerraten steigen neben den Kosten (Zeichen dafür, dass das Modell kämpft und zu Retry-Kosten führt)
Wenn ein Pattern prohibitiv teuer wird
Das Entscheidungsrahmen:
Zuerst optimieren. Kontextkomprimierung, Caching, Modell-Downgrade für einfachere Aufgaben, Batch-Verarbeitung statt Echtzeit. Ein typischer Optimierungsdurchgang spart 30-50 % der Kosten ohne Qualitätseinbußen.
Scope danach reduzieren. Die höchstwertigen Anwendungsfälle innerhalb des Patterns definieren und das Deployment darauf beschränken. Meeting Intelligence nur für Enterprise-Accounts. Generative Research nur für Tier-1-Accounts. Das ist kein Versagen. Das ist rationale Kostenallokation.
Durch ein günstigeres Pattern ersetzen, wenn Optimierung und Scope-Reduzierung nicht funktionieren. Ein Autonomous Agent, der Task-Routing betreibt, könnte durch ein Scoring and Routing-Modell bei 5 % der Kosten ersetzbar sein, wenn die Aufgabenkomplexität keine Multi-Step-Autonomie erfordert. Pattern-Auswahl ist immer revidierbar. Der Artikel Buy vs. Build-Entscheidung nach Pattern zeigt, wo Vendor-Lösungen im Vergleich zu Custom Builds Kosten reduzieren.
Lesen Sie Wenn AI Patterns zu Tech Debt werden für den langfristigen Kostenverlauf von Patterns, die nicht für Wartbarkeit konzipiert wurden, und ROI jedes AI Patterns messen dazu, wie Kosten in Relation zum Wert verfolgt werden. Das Ziel ist nicht das günstigste Deployment. Es ist das höchstwertige Deployment zu Kosten, die das Unternehmen im Maßstab aufrechterhalten kann.
Häufig gestellte Fragen
Was ist die Token Compound Cost Rule?
Die Token Compound Cost Rule besagt, dass die gesamten Enterprise AI-Ausgaben mit drei Multiplikatoren skalieren, die sich kompoundieren: der Anzahl der LLM-Aufrufe pro Benutzeraufgabe (agentische Workflows lösen 10-20 Aufrufe aus statt 1-2 für einfache Queries), der durchschnittlichen Kontextfenstergröße pro Aufruf (RAG-Architekturen blähen den Kontext um das 3-5-fache auf) und der Retraining-Häufigkeit pro Pattern (55 % der Modelle benötigen Retraining innerhalb von 90 Tagen). Per-Token-Preisreduktionen kompensieren das kompoundierende Aufrufvolumen nicht. Enterprise AI-Ausgaben stiegen um 320 %, während Per-Token-Preise um den Faktor 280 fielen, genau wegen dieser Multiplikatoren.
Warum sehen AI-Pilot-Kosten so anders aus als Produktionskosten?
Pilots filtern alle Edge Cases, langen Dokumente, komplexen Queries und ungewöhnlichen Nutzungsmuster heraus, die die Produktion einschließt. Ein Pilot, der 500 repräsentative Dokumente bei durchschnittlicher Komplexität verarbeitet, übersieht die 15 % der Produktionsdokumente, die lang, nicht-standardmäßig oder für mehrere Verarbeitungsdurchläufe erforderlich sind. Fügen Sie Ihrer Pilot-Kostenschätzung für die Produktionsplanung einen Puffer von 50-100 % hinzu. Für Autonomous Agents insbesondere fügen Sie auch einen Iterations-Zahl-Puffer hinzu.
Was ist die wirksamste Kostenkontrolle für Autonomous Agents?
Harte Iterations-Limits (maximale LLM-Aufrufe pro Aufgabe) und Pro-Aufgabe-Token-Budget-Caps. Ein Autonomous Agent ohne diese finanziellen Kontrollen ist ein offenes Kostenengagement. Gartners Analyse zeigt, dass Agenten 5-30-mal mehr Tokens pro Aufgabe benötigen als Standard-Chatbots, wobei komplexe Aufgaben das obere Ende dieses Bereichs erreichen. Ein 10-Aufruf-Maximum pro Aufgabe und automatischen Handoff an menschliche Agenten zu setzen, wenn Limits erreicht werden, ist keine operative Bequemlichkeit. Es ist eine finanzielle Kontrolle.
Wie wirkt sich der Meeting Intelligence-Deployment-Scope auf die Kosten aus?
Das Deployen von Meeting Intelligence für alle Meetings statt nur für kundenorientierte Meetings fügt typischerweise 60-70 % zu Transkriptions- und Verarbeitungskosten ohne zusätzlichen CRM-Wert hinzu. Interne Meetings (Standups, Planung, All-Hands) produzieren keine nützlichen Deal-Daten, verursachen aber trotzdem Pro-Minuten-Transkriptionskosten und Pro-Anruf-Zusammenfassungskosten. Die Beschränkung auf externe Anrufe vor dem Launch ist die einfachste Kostenoptimierung im Meeting Intelligence-Pattern.
Wann sollte eine Organisation ein günstigeres Modell einem besseren Modell vorziehen?
Wenn die Query-Komplexität die Fähigkeiten des besseren Modells nicht erfordert. Model Routing, das einfachere Anfragen an günstigere Modelle und komplexe Anfragen an Premium-Modelle leitet, reduziert Enterprise AI-Kosten um 30-50 % ohne Qualitätsverlust bei einfachen Aufgaben. Für Workflow Copilot können Kurzkontext-Vorschläge (E-Mail-Ton-Prüfung, einfache Feldvervollständigung) auf kleineren Modellen bei einem Bruchteil der Kosten von Full-Context-GPT-4-class-Inferenz ausgeführt werden. Model Routing in die Architektur vor dem Deployment einbauen, nicht als Kostenreduktions-Retrofit.
Auf welchen Kostentrend sollten Unternehmen sich bis 2030 vorbereiten?
Gartner prognostiziert, dass Inferenzkosten bis 2030 um über 90 % fallen werden. Aber die aktuelle Preisgestaltung wird durch Risikokapital und Hyperscaler-Cross-Subventionen subventioniert und schafft einen künstlich niedrigen Boden, der sich vor dem langfristigen Rückgang normalisieren könnte. Organisationen, die Kostenmodelle für Zeithorizonte von 3+ Jahren aufbauen, sollten für eine Periode der Preisvolatilität planen, anstatt einen linearen Kostenrückgang vorauszusetzen.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Warum AI-Kostenkurven sich von Software-Kostenkurven unterscheiden
- Kostentreiber nach Pattern
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: das höchste Kostenrisiko
- Die Token Compound Cost Rule
- Die vier häufigsten Cost Overrun-Szenarien
- Ein Kostenmodell vor dem Deployment aufbauen
- Überwachung auf Kosten-Anomalien
- Wenn ein Pattern prohibitiv teuer wird
- Mehr erfahren