Scoring and Routing: AI-Triage im großen Maßstab
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
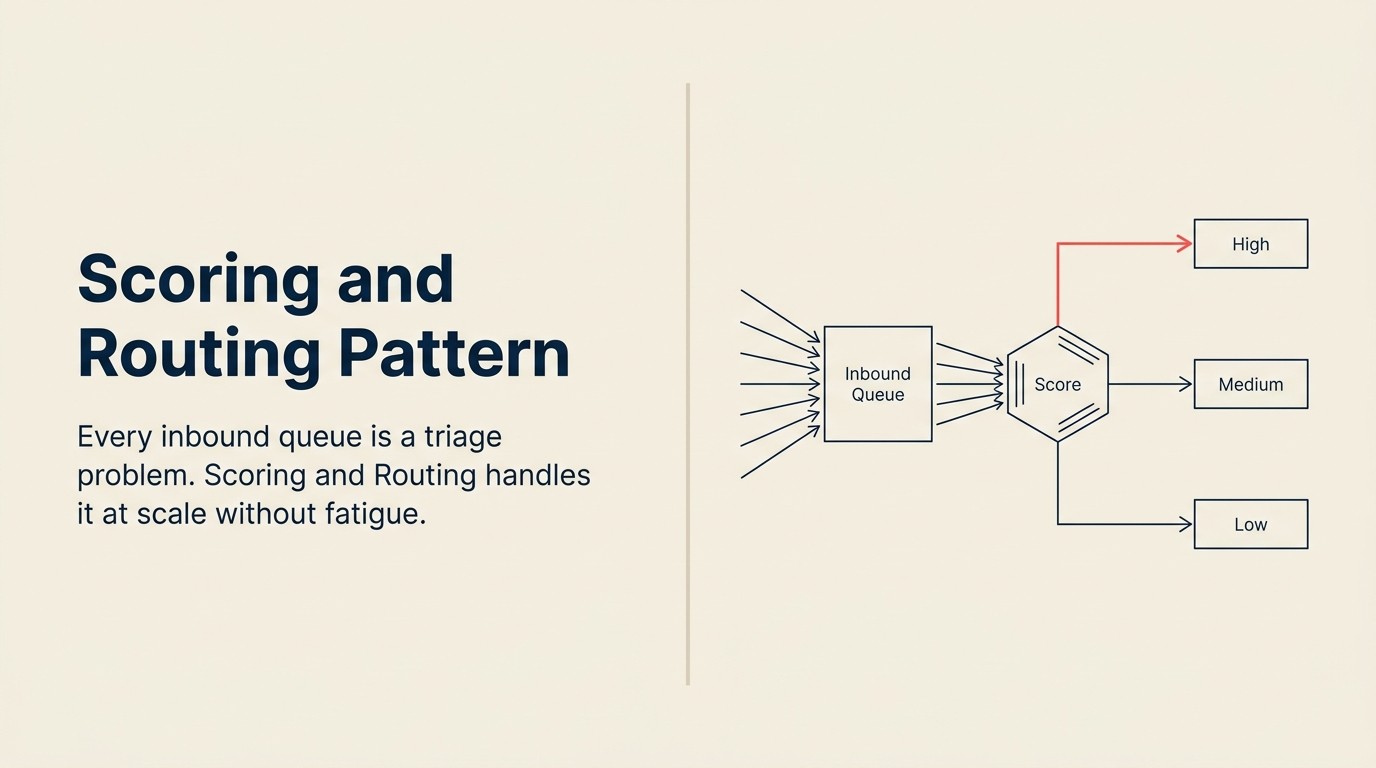
Jede eingehende Queue ist ein Triage-Problem.
Leads kommen von einer Webinar-Kampagne: 400 Kontakte, 40 davon mit echter Kaufabsicht und 360, die geklickt haben, weil der Titel interessant war. Support-Tickets häufen sich über Nacht an: 300 neue Anfragen, 12 davon dringende Enterprise-Probleme und 288 L1-Fragen, die bereits in Ihren Dokumenten beantwortet sind. Kreditanträge gehen ein: 1.200 diese Woche, einige kreditwürdig, einige nicht, einige, die sauber aussehen, aber Betrug sind.
Die Aufgabe ist in jedem Fall dieselbe. Signal vom Rauschen trennen. Die richtigen Elemente priorisieren. Jedes an die richtige Person oder den richtigen Prozess weiterleiten. Schnell genug, dass die wirklich dringenden Dinge nicht drei Stunden in einer Queue sitzen, während ein Mensch alles manuell durchliest.
Manuelle Triage skaliert nicht. Schwellenwertbasierte Regeln ("alle Leads von Unternehmen mit 500+ Mitarbeitern an das Enterprise-Team weiterleiten") verpassen Kontext. Sie können den E-Mail-Thread nicht lesen, der mit dem Lead kam. Sie können nicht sehen, dass der Besucher 40 Minuten auf der Preisseite verbracht hat. Sie können nicht berücksichtigen, dass dieser Prospect zuvor nach sechs Monaten abgewandert ist.
Scoring and Routing ist das AI-Pattern, das das bewältigt. Es ist eines der wirtschaftlich wichtigsten Patterns in der Business AI, und es lohnt sich, es klar zu verstehen, einschließlich der Punkte, an denen es schiefgeht.
Die Formel: Ingest, Analyze, Predict, Execute
Ingest (eingehender Datensatz) erfasst den Rohwert: einen neuen Lead-Datensatz, ein eingereichtes Support-Ticket, eine Bewerbung, einen eingereichten Versicherungsanspruch. In den meisten Deployments ist der Ingest-Schritt nicht nur das Element selbst. Er zieht verwandten Kontext hinzu: die Browsing-Historie des Leads, den Tier und das Kontoalter des Kunden, den hochgeladenen Lebenslauf des Bewerbers zusammen mit der Stellenbeschreibung, den Device-Fingerprint und die Händlerhistorie der Transaktion.
Analyze (Merkmale extrahieren) transformiert den Rohwert in die Signale, die das Modell verwenden wird. Für einen Lead: Unternehmensgröße, Titelseniorität, besuchte Website-Seiten, E-Mail-Domain, Branche und vergangenes Engagement. Für ein Support-Ticket: Absichtsklassifikation (Abrechnung? Bug? Feature-Anfrage?), Stimmung, Kunden-Tier und ob es bekannten Incident-Mustern entspricht. Hier beginnt der Vorteil von AI. Menschliche Triage betrachtet 3 bis 5 Signale. Das Modell bewertet 20 bis 50 gleichzeitig, einschließlich Wechselwirkungen zwischen Signalen, die ein Mensch nicht prüfen würde.
Predict (bewerten) ist das Modell, das gelernte Muster auf die Merkmale anwendet. Die Ausgabe ist ein Score: eine Wahrscheinlichkeit oder Prioritätseinstufung. Für Leads: Wahrscheinlichkeit des Abschlusses innerhalb von 90 Tagen. Für Tickets: Wahrscheinlichkeit, dass eine Eskalation oder ein Spezialist benötigt wird. Für Betrug: Wahrscheinlichkeit, dass diese Transaktion nicht autorisiert ist. Der Predict-Schritt ist reines Muster-Matching gegen historische Ergebnisse, typischerweise implementiert mit logistischer Regression, Gradient-Boosted Trees oder feinabgestimmten LLMs für textreiche Eingaben.
Execute (weiterleiten oder zuweisen) nimmt den Score und handelt entsprechend. Den Lead dem Enterprise-Team zuweisen. Das Ticket in die Sicherheitswarteschlange verschieben. Die Transaktion ablehnen und einen Überprüfungs-Workflow auslösen. Eine Salesforce-Aufgabe erstellen. Eine Slack-Warnung an den zuständigen Rep senden. Execute ist der Punkt, an dem der Score zu einer Entscheidung mit Konsequenzen wird. Das ist auch der Punkt, an dem Governance am wichtigsten ist.
Key Facts: Geschäftlicher Impact von Scoring and Routing
- McKinsey schätzt, dass AI in Vertrieb und Marketing 0,8 bis 1,2 Billionen USD an inkrementeller Produktivität freisetzen könnte, wobei Unternehmen, die in AI investieren, Umsatzsteigerungen von 3 bis 15 % und ROI-Steigerungen im Vertrieb von 10 bis 20 % sehen (McKinsey, 2023).
- B2B-Unternehmen mit KI-gestütztem Lead Scoring sehen eine 2- bis 3-fache Konversionsratenverbesserung in ihrer am höchsten bewerteten Lead-Klasse im Vergleich zu manuell triageten Queues, in ausgereiften Deployments mit 12+ Monaten Ergebnisdaten (Forrester B2B Sales AI Report, 2025).
- Versicherungsunternehmen mit dem Scoring-and-Routing-Pattern berichten 30 bis 40 % Reduktion der Schadensbearbeitungskosten bei Routineansprüchen durch Schnellbearbeitung sauberer Ansprüche und Weiterleitung komplexer an Spezialisten (Deloitte Insurance AI Study, 2024).
Fünf echte Beispiele im Detail
1. Lead Scoring und Rep-Zuweisung
Der kanonische Anwendungsfall. Eine Marketingkampagne generiert 300 eingehende Leads. Das Modell nimmt jeden Lead-Datensatz plus Verhaltensdaten aus Ihrer Site-Analytics und E-Mail-Engagement-Plattform auf. Es analysiert Merkmale wie Titel (VP of Sales bewertet höher als Sales Intern), Unternehmensgröße, Branchenfit, besuchte Seiten (Preisseite mehr als zweimal besucht ist ein starkes Signal), E-Mail innerhalb von zwei Stunden geöffnet und frühere CRM-Historie bei einem wiederkehrenden Prospect.
Der Predict-Schritt weist jedem Lead einen Score von 0 bis 100 zu, der die geschätzte Konversionswahrscheinlichkeit darstellt. Der Execute-Schritt leitet Leads über 75 an Ihre Senior Reps mit Same-Day-SLA weiter, Leads zwischen 40 und 75 an SDRs zur Qualifikation und Leads unter 40 in eine automatisierte Nurture-Sequenz.
Tools hier sind Salesforce Einstein Lead Scoring, HubSpots Predictive Lead Scoring und in Rework das KI-gestützte Scoring im Vertriebs-Workflow. Ein gut kalibriertes System verlagert typischerweise 20 bis 30 % mehr Pipeline zu hochkonvertierenden Leads ohne Personalaufstockung.
2. Support-Ticket-Priorisierung und Team-Routing
Ein B2B-SaaS-Unternehmen erhält täglich 600 Support-Tickets. Das Modell nimmt den Text jedes Tickets zusammen mit den Account-Daten des einreichenden Kunden auf: ARR, Vertragstier, Nutzungsmuster, frühere Ticket-Historie und Tage bis zur Verlängerung. Analyze klassifiziert Absicht (Abrechnungsproblem, technischer Bug, Feature-Anfrage, Sicherheitsbedenken), erkennt Stimmung und prüft auf Eskalationsrisiko-Indikatoren.
Predict bewertet Dringlichkeit: High-ARR-Kunden mit Abrechnungsproblemen drei Wochen vor der Verlängerung erhalten die höchste Bewertung. Execute leitet hochdringliche Tickets an Named Account Manager weiter, technische Probleme an den richtigen Engineering-Tier und niedrigdringliche Feature-Anfragen in die Backlog-Queue.
3. Lebenslauf-Screening und Recruiter-Zuweisung
Ein Unternehmen schreibt 12 offene Stellen aus und erhält innerhalb von zwei Wochen 1.800 Bewerbungen. Das Modell nimmt jeden Lebenslauf und die Stellenbeschreibung auf. Analyze extrahiert relevante Signale: Jahre in relevanten Funktionen, genannte spezifische Fähigkeiten, frühere Arbeitgeber, Bildungsniveau. Es vergleicht jeden Lebenslauf mit dem Zielprofil für diese Stelle.
Predict gibt einen Eignungsscore pro Bewerber pro Stelle aus. Execute bringt das Top-Quartil dem Recruiter für diese Stelle zur Prüfung, leitet Grenzkandidaten an einen leichteren Screening-Schritt weiter und sendet dem unteren Tier eine automatisierte Antwort. Hinweis: Hier ist auch das Bias-Risiko am höchsten. Weiter unten behandelt.
4. Versicherungsanspruch: Schnellbearbeitung vs. menschliche Prüfung
Ein Versicherer verarbeitet monatlich 5.000 Ansprüche. Einfache Ansprüche (leichte Auffahrunfälle mit Fotodokumentation und klarer Haftung) können innerhalb von 48 Stunden ausgezahlt werden, wenn das Modell ihnen einen "Schnellbearbeitung"-Score gibt. Komplexe Ansprüche brauchen menschliche Sachbearbeiter.
Das Modell nimmt Schadensformulardaten, angehängte Fotos, Fahrzeughistorie, Versicherungsnehmerhistorie und Drittparteidatensätze auf. Analyze extrahiert Komplexitätsindikatoren: Ist die Haftung klar? Gibt es Verletzungen? Entspricht der geltend gemachte Betrag vergleichbaren Vorfallsdaten?
Predict bewertet jeden Anspruch auf zwei Dimensionen: Schnellbearbeitungswahrscheinlichkeit und Betrugswahrscheinlichkeit. Execute leitet Schnellbearbeitungs-, Niedrig-Betrug-Ansprüche zur automatisierten Zahlung, mittlere Komplexitätsansprüche zu Sachbearbeitern und Hoch-Betrug-Wahrscheinlichkeits-Ansprüche an die Sonderermittlungsabteilung weiter.
5. Betrugserkennung im Zahlungsverkehr
Stripe Radar ist eines der weltweit am häufigsten eingesetzten Scoring-Systeme, auch wenn die meisten Betreiber es als "Betrugsverhinderung" statt als "AI" bezeichnen. Für jede Kartentransaktion nimmt Stripes Modell Kartenmetadaten, Device-Fingerprint, Transaktionsbetrag, Händlerkategorie, geografische Daten und Verhaltenssignale auf.
Analyze extrahiert Merkmale. Predict weist einen Betrugswert zu: 99,5 % (fast sicher Betrug) oder 0,2 % (fast sicher legitim). Execute handelt entsprechend: genehmigen, zur 3D-Secure-Überprüfung senden oder vollständig sperren.
Der Execute-Schritt hier hat extrem hohe Einsätze und erfolgt in Millisekunden. Deshalb ist die Score-Schwellenwert-Kalibrierung kritisch. Ein zu aggressiv gesetzter Schwellenwert sperrt legitime Transaktionen. Zu permissiv und Betrugsverluste steigen.
Der Score-Then-Execute-Loop
Scoring and Routing funktioniert in zwei unterschiedlichen Phasen, die nicht zusammengefasst werden dürfen: eine Bewertungsphase, in der jedes eingehende Element eine Prioritätseinstufung auf Basis extrahierter Merkmale und historischer Ergebnismuster erhält, und eine Execute-Phase, in der diese Einstufung eine Routing-Entscheidung antreibt. Das Zusammenfassen der beiden Phasen, also direktes Routing aus regelbasierten Schwellenwerten ohne Modell-Scoring, verpasst die Kontextsignale, die einen Low-Intent-Enterprise-Lead von einem High-Intent-SMB-Lead unterscheiden. Direktes Routing aus rohem Modellkonfidenzwert ohne Schwellenwert-Validierung produziert Routing-Instabilität.
Fehlerarten: was tatsächlich schiefgeht
| Fehlerart | Grundursache | Behebung |
|---|---|---|
| Trainingsdaten-Bias | Modell auf historisch verzerrten Ergebnissen trainiert (vergangene Reps abgeschlossen nur aus Mid-Market; Enterprise-Leads unfair deprioritisiert) | Score-Verteilungen über Segmente auditieren. Auf demografische Korrelationen in Kandidaten- oder Kundendaten prüfen. |
| Schwellenwert-Fehlkalibrierung | Ein 70-Punkte-Schwellenwert, der 60 % der hochabsichtlichen Leads an Junior-Reps sendet, weil der Grenzwert nicht gegen tatsächliche Win-Rates validiert wurde | Schwellenwerte gegen Ergebnisse validieren. Schwellenwert-Setzung als vierteljährliches Business-Review-Element behandeln, nicht als einmalige Einrichtung. |
| Feature-Veralterung | Auf Q1-Daten trainiertes Modell verpasst eine in Q3 eingeführte neue Produktlinie | Automatische Neutrainings-Zeitpläne einrichten, die an Produkt-/Segmentänderungen geknüpft sind. Score-Verteilungs-Drift im Zeitverlauf verfolgen. |
| Feedback-Loop-Fehler | Niemand überwacht, ob weitergeleitete Leads tatsächlich abgeschlossen wurden | Ergebnis-Tracking von Anfang an in den Workflow einbauen. Das Modell braucht beschriftete historische Daten, um kalibriert zu bleiben. |
| Score-Inflation ohne Aktion | Scoring läuft, aber Reps ignorieren die Queue-Reihenfolge | Score im Workflow-Interface sichtbar machen (CRM, Support-Tool). Teamleistungsmetriken an Scoring-Compliance koppeln. |
| Stille Routing-Fehler | Execute sendet Elemente still in die falsche Queue (niemand bemerkt es wochenlang) | Jede Routing-Entscheidung protokollieren. Ausnahmen-Report aufbauen, der Abweichungen zwischen bewertetem Tier und Ergebnis-Tier aufzeigt. |
Die beiden wirkungsstärksten Fehlerarten (Schwellenwert-Fehlkalibrierung und Feedback-Loop-Fehler) sind auch die am wenigsten aufregenden zu beheben. Sie erfordern keine neuen Modelle. Sie erfordern betriebliche Disziplin: regelmäßige Überprüfungen, wer wohin geleitet wurde und ob diese Routing-Entscheidung Früchte trug.
Gartners AI-Operations-Report 2025 ergab, dass 68 % der AI-Scoring-Systeme, die hinter ihren anfänglichen Benchmarks zurückbleiben, die Degradation auf Feedback-Loop-Fehler zurückführen. Das Modell wurde nie auf neuen Ergebnissen neu trainiert, also bewertet es weiterhin 2025 Leads gegen Muster, die aus 2022 gewonnenen Deals gelernt wurden.
Schwellenwert-Kalibrierung: der am häufigsten übersehene Hebel
Die meisten Betreiber, die ein Scoring-System deployen, verbringen 90 % ihrer Aufmerksamkeit auf die Modellauswahl und 10 % auf die Schwellenwert-Setzung. Das Rendite-Investitions-Verhältnis ist rückwärts.
Die Aufgabe des Modells ist die Einstufung von Elementen. Die Aufgabe des Schwellenwerts ist die operative Bedeutung dieser Einstufung. Ein Lead-Scoring-Modell könnte 300 Leads von 1 bis 300 genau einstufen. Aber wenn Sie den "hohe Priorität"-Schwellenwert bei 60 von 100 setzen und 200 Ihrer 300 Leads über 60 bewerten, sind Ihre Senior Reps überwältigt und die Segmentierung ist bedeutungslos.
Schwellenwert-Kalibrierung erfordert drei Eingaben: die Score-Verteilung historischer Daten, Ihre operative Kapazität auf jedem Routing-Tier und Ihre Ergebnisdaten (welcher Score-Bereich korreliert tatsächlich mit Abschlüssen?). Mit diesen drei können Sie Schwellenwerte setzen, die der operativen Realität entsprechen.
Überprüfen Sie Schwellenwerte mindestens vierteljährlich. Marktveränderungen, Kampagnen-Mix-Änderungen und Produkterweiterungen verschieben die Score-Verteilung unter Ihnen.
Wann Scoring plus Routing funktioniert und wann nicht
Funktioniert gut, wenn:
- Sie beschriftete historische Ergebnisse haben. Das Modell lernt aus vergangenen Daten: welche Leads abgeschlossen wurden, welche Ansprüche betrügerisch waren, welche Bewerber eingestellt wurden und geblieben sind. Keine beschriftete Historie bedeutet keine sinnvollen Vorhersagen.
- Sie Volumen haben. Scoring and Routing zahlt sich aus, wenn das Triage-Problem real ist.
- Die Routing-Entscheidung einer klaren, ausführbaren Aktion entspricht. "An Enterprise-Team weiterleiten" ist ausführbar. "Diesen Lead vorsichtiger behandeln" ist es nicht.
Alternativen erwägen, wenn:
vs. Anomaly Agent: Scoring and Routing weist Priorität innerhalb bekannter Kategorien zu. Anomaly Agent kennzeichnet Elemente, die zu keiner erwarteten Kategorie gehören (das unbekannte Unbekannte). Wenn Sie neuartige Betrugsmuster erkennen müssen, die keinem vergangenen Betrug ähneln, ist Anomaly Agent das richtige Tool.
vs. Workflow Copilot: Scoring handelt ohne den Nutzer. Copilot assistiert dem Nutzer bei seiner Arbeit. Wenn Ihr Prozess ein Urteil erfordert, das nicht algorithmisch delegiert werden kann (ein komplexer Enterprise-Vertriebsanruf, eine nuancierte Verhandlung), assistiert Copilot dem Menschen statt seine Triage-Entscheidung zu ersetzen.
vs. Autonomous Agent: Scoring and Routing trifft eine Entscheidung an einem Punkt in einem Workflow. Ein Autonomous Agent führt eine mehrstufige Schleife aus und trifft mehrere Entscheidungen, um ein Ziel zu erfüllen.
ROI-Signale: Messung der Wirksamkeit
| Metrik | Was sie misst | Plausibler Benchmark |
|---|---|---|
| Speed-to-First-Contact | Zeit von der Lead-Einreichung bis zur ersten Rep-Kontaktaufnahme | 50 bis 70 % Reduktion vs. manuelle Queue |
| Rep-Auslastung nach Tier | Anteil der Enterprise-Rep-Zeit an Enterprise-bewerteten Leads | Baseline: ~40 %. Mit Scoring: 65 bis 80 % |
| Win-Rate: bewertet vs. nicht bewertet | Konversionsraten-Vergleich über Hoch-/Mittel-/Niedrig-Score-Bänder | High-Band sollte in ausgereiften Deployments 2 bis 3-mal höhere Win-Rate als Low-Band haben |
| Ticket-Lösungszeit nach Routing-Pfad | AI-geleitet vs. manuell sortierte Tickets | 20 bis 35 % Reduktion der Time-to-Resolution für AI-geleitete |
| False-Positive-Rate | Elemente in Priority-Queue, die keine Priorität verdienten | Vierteljährlich verfolgen; Ziel: <15 % False Positives im Enterprise-Tier |
| Score-Verteilungs-Drift | Ob die Score-Verteilung des Modells sich im Zeitverlauf verschiebt | Flag setzen, wenn der mittlere Score sich um mehr als 10 Punkte im Quartalsvergleich verändert |
Der Win-Rate-Vergleich zwischen bewerteten und nicht bewerteten Leads ist Ihr stärkster Nachweis. Wenn Leads im Top-Score-Band bei 28 % abschließen und Leads im Bottom-Score-Band bei 7 %, verdient das Modell seinen Einsatz. Wenn diese Zahlen ähnlich sind, unterscheidet das Modell nicht nützlich, und Sie haben ein Trainingsdaten- oder Feature-Problem.
Governance-Anforderungen
Scoring and Routing berührt die wirtschaftlichen Ergebnisse von Menschen: Kommissionen von Sales Reps, Stellenangebote für Kandidaten, Genehmigungen oder Ablehnungen für Kunden. Das ist kein Grund, es zu vermeiden. Es ist ein Grund, es gut zu regeln.
Das Modell vierteljährlich auditieren. Score-Verteilungen über demografische, geografische und firmenografische Segmente prüfen. Wenn Ihr Lead-Scoring-Modell systematisch niedrigere Scores für Leads aus bestimmten Regionen oder Branchen ohne Geschäftsgrund gibt, haben Sie ein Bias-Problem.
Menschliche Übersteuerung klar definieren. Jeder Rep sollte einen niedrig bewerteten Lead, den er für hochabsichtlich hält, kennzeichnen können. Jeder Recruiter sollte einen Lebenslauf manuell in die nächste Runde bewegen können.
Neutrainings-Rhythmus. Für die meisten Geschäftsanwendungen ist vierteljährliches Neutraining ein vernünftiger Standard. Monatlich, wenn sich Ihr Markt schnell verändert. Jährlich ist fast immer zu langsam.
Dokumentation für regulierte Branchen. In Finanzdienstleistungen, Kreditvergabe, Versicherungen und bei der Einstellung können automatisierte Scoring-Entscheidungen unter ECOA, GDPR Artikel 22 oder staatlichen KI-Gesetzen Erklärbarkeit erfordern. "Das Modell hat es gesagt" ist keine vertretbare Erklärung für eine nachteilige Kreditentscheidung.
Anbieter- und Tool-Landschaft
| Anwendungsfall | Wichtige Tools |
|---|---|
| Lead Scoring | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Support-Ticket-Routing | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Kandidaten-Screening | Eightfold, HireVue, Paradox, Greenhouse AI |
| Betrugserkennung | Stripe Radar, Kount, Featurespace, Sardine |
| Versicherungsansprüche | Shift Technology, Tractable, Cape Analytics |
| Individuelle Scoring-Infrastruktur | Pinecone (Vektor-Embeddings), Tecton (Feature Stores), AWS SageMaker, Azure ML |
Rework Analysis: Die meisten Teams, die Lead Scoring deployen, machen das Modell richtig und die Betriebsprozesse falsch. Das Modell bewertet Leads genau. Aber die Schwellenwerte wurden einmal beim Launch gesetzt, die Ergebnisdaten wurden nie zurückgespeist, und das Team hat nie auditiert, ob hochbewertete Leads tatsächlich höhere Abschlussraten zeigen als niedrigbewertete. Sechs Monate später vertrauen Reps der Queue-Reihenfolge nicht mehr und arbeiten ihre eigene Pipeline. Der ROI des Modells löst sich auf, nicht weil AI versagt hat, sondern weil der Feedback-Loop nie aufgebaut wurde. Scoring and Routing erfordert zwei organisatorische Verpflichtungen, nicht eine: ein Scoring-System und eine vierteljährliche Ergebnisüberprüfung, die es kalibriert hält.
Häufig gestellte Fragen
Was ist das Scoring-and-Routing-AI-Pattern?
Scoring and Routing ist ein AI-Pattern, das eingehende Elemente (Leads, Tickets, Bewerbungen, Ansprüche) mit einer vierstufigen Formel automatisch priorisiert und zuweist: eingehende Datensätze und Kontext Ingest, Merkmale Analyze, Prioritätsscore Predict und Routing-Entscheidung Execute. Das Pattern bewältigt Triage in Volumina, die manuelle Überprüfung nicht aufrechterhalten kann.
Wie funktioniert AI Lead Scoring?
AI Lead Scoring nimmt jeden Lead-Datensatz plus Verhaltensdaten auf, extrahiert Merkmale (Unternehmensgröße, Titelseniorität, Branche, frühere CRM-Historie) und wendet ein trainiertes Modell an, um einen Wahrscheinlichkeitsscore zuzuweisen. Das Modell hat aus historischen Ergebnissen gelernt: welche vergangenen Leads mit ähnlichen Profilen tatsächlich abgeschlossen wurden. Der Score treibt das Routing an: Hohe Scores gehen an Senior Reps mit Same-Day-SLA, mittlere an SDRs zur Qualifikation, niedrige in automatisierte Nurture-Sequenzen.
Was sind die häufigsten Fehlerarten bei Scoring and Routing?
Die zwei wirkungsstärksten Fehler sind Schwellenwert-Fehlkalibrierung und Feedback-Loop-Fehler. Schwellenwert-Fehlkalibrierung sendet den falschen Anteil von Leads an jeden Routing-Tier. Feedback-Loop-Fehler tritt auf, wenn Ergebnisdaten (wer abgeschlossen hat, wer abgewandert ist, welche Ansprüche betrügerisch waren) nicht zurückgespeist werden, um das Modell neu zu trainieren. Gartner ergab, dass 68 % der unterdurchschnittlichen Scoring-Systeme die Degradation auf Feedback-Loop-Fehler zurückführen.
Was ist der Score-Then-Execute-Loop?
Der Score-Then-Execute-Loop ist die Zwei-Phasen-Struktur des Scoring-and-Routing-Patterns: zuerst eine Bewertungsphase, in der jedes Element eine Prioritätseinstufung erhält, dann eine Execute-Phase, in der validierte Schwellenwerte diese Einstufung in eine Routing-Entscheidung übersetzen. Das Zusammenfassen der beiden Phasen verpasst die Kontextsignale, die einen hochabsichtlichen Lead von einem niedrigabsichtlichen unterscheiden.
Wann Scoring plus Routing vs. Anomaly Agent nutzen?
Nutzen Sie Scoring and Routing, wenn Sie Elemente innerhalb bekannter Kategorien triagieren müssen. Nutzen Sie Anomaly Agent, wenn Sie Elemente erkennen müssen, die zu keiner erwarteten Kategorie gehören, wie neuartige Betrugsmuster, die keinem vergangenen Betrug ähneln. Scoring and Routing würde neuartigen Betrug als mittleres Risiko bewerten, weil er wie eine normale Transaktion aussieht. Anomaly Agent kennzeichnet ihn speziell, weil er von der statistischen Baseline abweicht.
Welchen ROI sollte man von Scoring and Routing erwarten?
Ausgereifte Deployments mit 12+ Monaten Ergebnisdaten sehen 2- bis 3-fache Konversionsratenverbesserung im höchsten Score-Band. Vertriebsteams sehen 50 bis 70 % Reduktion der Speed-to-First-Contact. Support-Ticket-Routing reduziert typischerweise die Time-to-Resolution um 20 bis 35 %. Versicherungsunternehmen berichten 30 bis 40 % Reduktion der Schadensbearbeitungskosten. Das Erreichen dieser Benchmarks erfordert sowohl ein kalibriertes Scoring-System als auch eine vierteljährliche Ergebnisüberprüfung.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Die Formel: Ingest, Analyze, Predict, Execute
- Fünf echte Beispiele im Detail
- 1. Lead Scoring und Rep-Zuweisung
- 2. Support-Ticket-Priorisierung und Team-Routing
- 3. Lebenslauf-Screening und Recruiter-Zuweisung
- 4. Versicherungsanspruch: Schnellbearbeitung vs. menschliche Prüfung
- 5. Betrugserkennung im Zahlungsverkehr
- Der Score-Then-Execute-Loop
- Fehlerarten: was tatsächlich schiefgeht
- Schwellenwert-Kalibrierung: der am häufigsten übersehene Hebel
- Wann Scoring plus Routing funktioniert und wann nicht
- ROI-Signale: Messung der Wirksamkeit
- Governance-Anforderungen
- Anbieter- und Tool-Landschaft
- Mehr erfahren