Risiko Halusinasi mengikut Corak AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Halusinasi adalah perkataan yang menamatkan projek AI. Bukan kerana ia selalu berlaku, tetapi kerana apabila ia berlaku dalam konteks yang salah (dokumen pematuhan, e-mel berhadapan klien, rekod perubatan, tanda undang-undang pada kontrak), kerosakan adalah nyata dan sering diketahui umum.
Tindak balas organisasi biasanya salah dalam salah satu daripada dua arah. Sama ada kepimpinan memutuskan AI tidak selamat dan menghentikan inisiatif (tindakan berlebihan, meninggalkan nilai sebenar), atau mereka memutuskan insiden itu adalah peristiwa rawak dan terus berjalan tanpa perubahan (tindakan kurang, menunggu insiden berikutnya). Tidak satu pun tindak balas berdasarkan penilaian jujur di mana risiko halusinasi sebenarnya wujud.
Tindak balas yang betul adalah untuk memahami bahawa risiko halusinasi tidak seragam merentas corak. Sesetengah corak hampir kebal kepadanya mengikut reka bentuk. Yang lain membawa risiko tinggi sebagai ciri struktur cara mereka berfungsi. Menguruskan risiko memerlukan pengetahuan mana yang mana.
Apa yang halusinasi sebenarnya dalam konteks perniagaan
Kesusasteraan akademik mengenai ini kini sangat banyak. Tinjauan komprehensif arXiv (arXiv:2401.01313) yang merangkumi lebih daripada 32 teknik pengurangan halusinasi mengenal pasti Retrieval Augmented Generation sebagai pengurangan struktur paling berkesan tunggal untuk halusinasi fakta. Penemuan itu membentuk secara langsung beberapa cadangan corak di bawah. Tiga jenis halusinasi terpakai dalam konteks perniagaan, dan ia bermakna berbeza antara satu sama lain:
Halusinasi fakta. Model menyatakan sesuatu dengan penuh keyakinan yang salah. "Tempoh pemulangan Anda ialah 45 hari" apabila sebenarnya 30 hari. "Kontrak telah ditandatangani pada 12 Mac" apabila tiada tarikh sedemikian dalam dokumen. Model menjana pernyataan yang munasabah yang kebetulan salah.
Halusinasi petikan. Model mengaitkan dakwaan kepada sumber yang tidak membuat dakwaan itu, atau kepada sumber yang tidak wujud. "Menurut kemas kini dasar Q3 Anda..." apabila tiada kemas kini dasar sedemikian yang diindeks. Ini berbeza daripada halusinasi fakta kerana pernyataan itu mungkin betul secara fakta tetapi petikan adalah rekaan.
Halusinasi konteks. Model menjana kandungan yang terdengar munasabah yang tidak mencerminkan konteks khusus yang diberikan kepadanya. Bentuk paling biasa: model mengisi jurang dalam konteks dengan perkara yang "sepatutnya" ada berdasarkan pengetahuan umum dan bukannya perkara yang sebenarnya ada. Ringkasan mesyuarat yang menyertakan item tindakan yang tiada siapa menyebutnya. Tanda kontrak untuk klausa yang tidak ada dalam kontrak yang Anda hantar.
Ketiga-tiga jenis menyebabkan kemudaratan dengan cara yang berbeza. Halusinasi fakta menyebabkan maklumat salah secara langsung. Halusinasi petikan menjejaskan kepercayaan dalam sumber. Halusinasi konteks adalah yang paling licik. Ia sering terdengar paling munasabah kerana ia mengisi jurang logik.
Key Facts: Kadar Halusinasi dalam Pengeluaran
- Penanda aras perusahaan melaporkan kadar halusinasi 15-52% merentas LLM komersial untuk pertanyaan khusus domain, walaupun kadar halusinasi pengetahuan umum untuk model teratas telah jatuh di bawah 1%. (SQMagazine Hallucination Statistics, 2026)
- RAG mengurangkan kadar halusinasi sebanyak 30-70% merentas domain, dengan pengambilan semula yang berasas menurunkan kadar di bawah 2% dalam tugasan rumusan. Ia adalah pengurangan struktur paling berkesan tunggal yang dikenal pasti dalam lebih daripada 32 ulasan teknik pengurangan halusinasi. (arXiv Hallucination Survey, 2024)
- Sistem AI domain undang-undang menunjukkan kadar halusinasi 69-88% dalam pertanyaan berisiko tinggi. Sistem AI perubatan menunjukkan 43-64% bergantung pada kualiti prompt, walaupun dengan model paling mampu yang tersedia pada 2025. Ini adalah dua domain dengan akibat tertinggi setiap halusinasi.
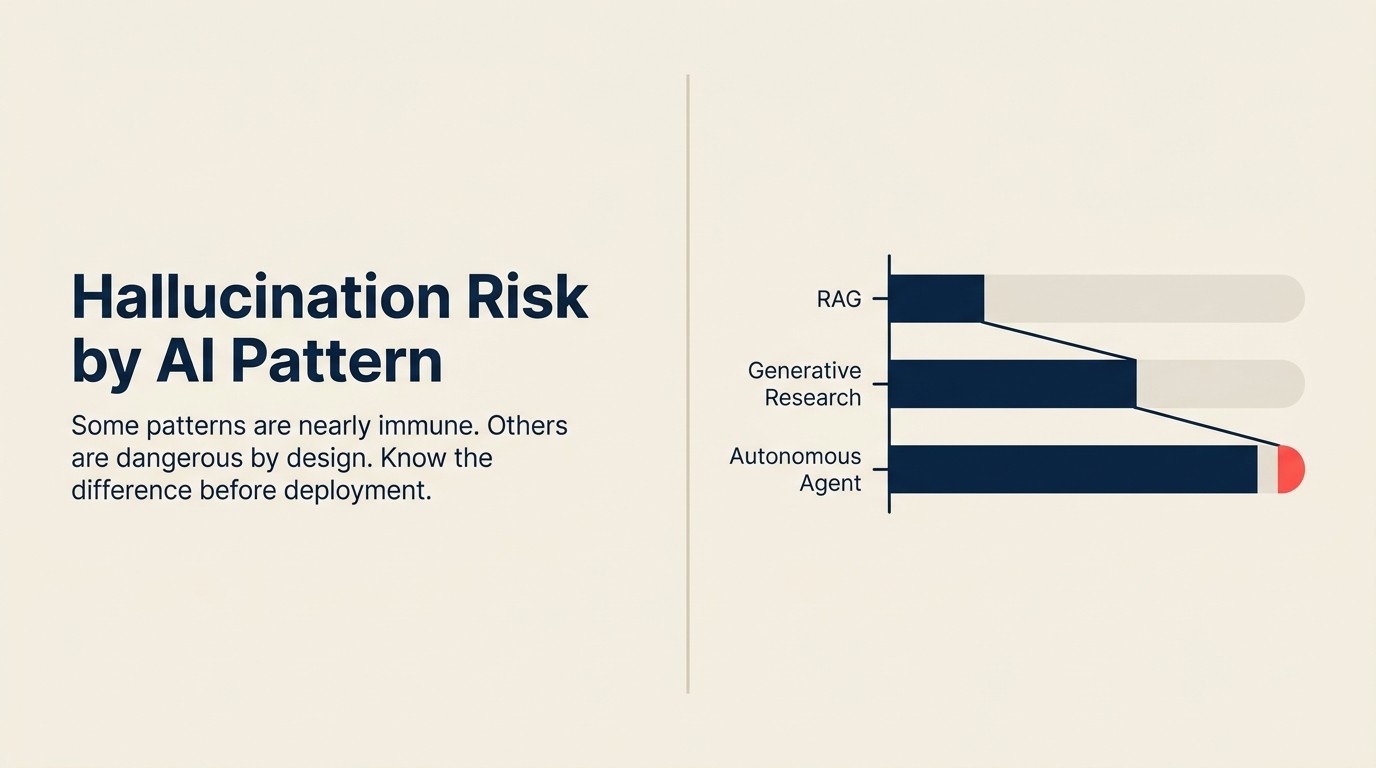
Risiko halusinasi mengikut corak
| Corak | Tahap Risiko | Jenis Halusinasi Utama |
|---|---|---|
| Scoring + Routing | Sangat Rendah | T/A (kebarangkalian, bukan bahasa) |
| Anomaly Agent | Sangat Rendah | T/A (berangka, bukan bahasa) |
| Vision Extract | Rendah-Sederhana | Konteks (ralat pengekstrakan) |
| Meeting Intelligence | Rendah-Sederhana | Konteks (item tindakan, atribusi) |
| Personalization Engine | Rendah | Pemilihan kandungan, bukan penjanaan |
| RAG Assistant | Sederhana | Petikan + Konteks (kegagalan pengambilan semula) |
| Workflow Copilot | Sederhana | Konteks (pengisian konteks jarang) |
| Document Review | Sederhana | Konteks (fabrikasi klausa yang tiada) |
| Generative Research | Tinggi | Ketiga-tiga jenis |
| Autonomous Agent | Tinggi | Ketiga-tiga jenis, bergabung |
Scoring and Routing: sangat rendah
Keupayaan Predict menghasilkan kebarangkalian, bukan bahasa. "Skor petunjuk: 73" bukan permukaan halusinasi. Model tidak menjana ayat; ia menghasilkan nombor. Mod kegagalan yang setara adalah hanyut model: skor menjadi tidak dikalibrasi dari masa ke masa apabila data asas beralih. Itu adalah masalah berbeza dengan pengurangan berbeza. Tetapi halusinasi tradisional, dalam erti kata model mencipta teks palsu, tidak terpakai di sini.
Anomaly Agent: sangat rendah
Alasan yang sama seperti Scoring+Routing. Corak beroperasi pada aliran berangka. "Tanda anomali transaksi: keyakinan 99.2%" adalah output kebarangkalian, bukan output penjanaan bahasa. Ralat dalam Anomaly Agent kelihatan seperti positif palsu dan negatif palsu, bukan halusinasi.
Vision Extract: rendah-sederhana
Halusinasi dalam Vision Extract memetakan kepada ralat pengekstrakan, khususnya salah kalibrasi keyakinan. Setara dengan pernyataan yang dihaluskan ialah nilai medan yang diekstrak dengan salah secara yakin: "jumlah keseluruhan: $1,247" apabila invois menunjukkan $12,470. Ralat ini paling kerap berlaku apabila:
- Format dokumen tidak diwakili dalam data latihan model (templat vendor baharu)
- Kualiti imej rendah (imbasan resolusi rendah, gambar miring)
- Medan adalah samar (dua medan "tarikh" pada dokumen yang sama)
Risiko adalah rendah-sederhana kerana Vision Extract terbatas pada dokumen fizikal. Model tidak boleh mencipta kandungan yang tidak ada pada halaman. Ia hanya boleh salah baca atau salah atribusi apa yang ada. Kalibrasi keyakinan adalah tuas tadbir urus: tandai pengekstrakan keyakinan rendah untuk semakan manusia dan bukannya melepaskannya.
Meeting Intelligence: rendah-sederhana
Transkripsi itu sendiri sebahagian besarnya tahan halusinasi. Model menukar audio kepada teks, dengan ralat yang kelihatan seperti salah dengar dan bukannya rekaan. Di mana risiko halusinasi masuk adalah pada peringkat Analyze dan Generate: penjanaan ringkasan, pengekstrakan item tindakan, dan atribusi penutur.
Risiko tertentu:
- Rekaan item tindakan. Model menjana item tindakan yang "sepatutnya" ada memandangkan konteks mesyuarat tetapi tidak sebenarnya dinyatakan. "John akan menghantar kontrak menjelang Jumaat" apabila John tidak membuat komitmen sedemikian.
- Ralat atribusi penutur. Terutamanya dalam panggilan berbilang peserta, model mengaitkan pernyataan kepada penutur yang salah. "VP Jualan mengatakan perjanjian sedang berkembang dengan baik" apabila sebenarnya pengurus akaun yang berkata demikian.
- Konfabulasi ringkasan. Keputusan atau komitmen utama yang tidak sebenarnya dibincangkan muncul dalam ringkasan kerana ia tersirat oleh konteks mesyuarat.
Risiko kekal rendah-sederhana kerana corak berasaskan transkripsi mempunyai kebenaran asas: audio sebenar. Percanggahan boleh ditangkap dengan mendengar sumber. Pengurangannya ialah semakan manusia terhadap tolak CRM sebelum ia menjadi rekod sistem, seperti yang dibincangkan dalam keperluan tadbir urus mengikut corak.
Personalization Engine: rendah
Corak ini terutamanya tentang pemilihan dan pemeringkatan kandungan, bukan penjanaan kandungan. "Tunjukkan kepada pengguna ini produk A sebelum produk B berdasarkan sejarah pelayaran mereka" tidak menghaluskan. Risiko halusinasi menjadi relevan hanya apabila enjin pemperibadian juga menjana varian kandungan: baris subjek e-mel yang diperibadikan, penerangan produk, salinan halaman pendaratan dinamik. Dalam kes tersebut, risiko meningkat kepada sederhana dan pengurangan Generative yang sama terpakai.
RAG Assistant: sederhana
RAG terbatas pada pangkalan pengetahuan, yang mengehadkan risiko halusinasi secara ketara berbanding penjanaan tanpa kekangan. Tetapi "terbatas" bukan bermakna "kebal." Tiga mod kegagalan:
Kegagalan pengambilan semula. Sistem mengambil semula dokumen yang salah dan menjawab dengan yakin berdasarkan kandungan yang tidak relevan. Jika Anda bertanya "apa dasar cuti ibu bapa kami di Jerman?" dan sistem mengambil semula dasar AS sebaliknya, Anda mendapat jawapan yang salah dengan yakin dengan petikan yang kelihatan munasabah.
Pengisian jurang. Apabila dokumen yang diambil semula tidak menjawab soalan sepenuhnya, sesetengah model mengisi jurang dengan pengetahuan umum dan bukannya berkata "saya tidak tahu." Pengguna mendapat jawapan yang mencampurkan kandungan yang diambil semula yang tepat dengan tambahan yang dihaluskan.
Halusinasi petikan. Model menjana petikan kepada dokumen dalam pangkalan pengetahuan yang sebenarnya tidak membuat pernyataan yang didakwa. Ini sangat merosot kerana ia menjadikan halusinasi kelihatan disahkan.
Pengurangan untuk RAG adalah kualiti pengambilan semula, bukan kualiti model. Model yang lebih baik dengan pengambilan semula yang buruk masih menghasilkan jawapan yang salah. Audit pangkalan pengetahuan suku tahunan, paparan skor keyakinan kepada pengguna, dan semakan manusia sebelum pengedaran luaran adalah kawalan operasional.
Workflow Copilot: sederhana
Risiko halusinasi dalam Workflow Copilot adalah tertinggi apabila model membuat draf dari konteks yang jarang atau samar. Copilot yang membuat draf e-mel susulan selepas rekod CRM menunjukkan "demo selesai" dan tiada yang lain akan mengisi konteks yang tiada dengan butiran yang munasabah tetapi direka. "Susulan perbincangan kami mengenai garis masa Q2 Anda" apabila tiada garis masa Q2 yang dibincangkan.
Risiko berskala dengan berapa banyak semakan manusia yang diterima cadangan copilot. Jika wakil meluluskan cadangan secara pukal tanpa membacanya, kadar halusinasi dalam komunikasi keluar adalah kadar ralat penjanaan copilot, yang bukan sifar. Tuas tadbir urus adalah metrik kualiti penerimaan cadangan: menjejaki bukan hanya kadar penerimaan tetapi ketepatan cadangan yang diterima.
Document Review: sederhana
Document Review menghaluskan dengan cara yang khusus dan berbahaya: ia menandai klausa yang tidak ada dalam dokumen, atau terlepas klausa yang ada. Halusinasi konteks di sini bermakna model menjana tanda penyelewengan untuk klausa yang dijangkanya ada (berdasarkan latihan pada kontrak yang serupa) tetapi yang sebenarnya tidak ada dalam dokumen yang dihantar.
Risiko menjadi tinggi apabila output diedarkan tanpa semakan. Jika pasukan undang-undang bergantung pada tanda AI sebagai semakan utama mereka dan tidak membaca dokumen penuh, tanda yang dihaluskan boleh sama ada mewujudkan kerja berdasarkan tiada apa atau memberikan keselesaan palsu bahawa klausa sebenar telah disemak apabila tidak.
Pengurangannya adalah memperlakukan output Document Review sebagai alat triaj, bukan pendapat undang-undang. Peguam manusia menyemak sebelum sebarang tindakan diambil atas tanda. AI menangkap apa yang perlu dilihat. Peguam mengesahkan.
Generative Research: tinggi
Ini adalah corak berisiko halusinasi tertinggi dengan margin yang ketara. Sebabnya adalah struktur:
Sintesis pelbagai sumber dengan konfabulasi. Model menarik dari banyak sumber dan mensintesisnya menjadi naratif yang koheren. Apabila sumber bercanggah, atau apabila terdapat jurang antara sumber, model mengisi dengan sintesis yang munasabah yang mungkin tidak disokong oleh mana-mana sumber sebenar.
Jurang sumber langsung. Jika prompt penyelidikan meliputi peristiwa terkini (30 hari terakhir) dan sumber yang diindeks lebih lama, model mengisi jurang kecapaian dengan kandungan yang terdengar yakin yang sebenarnya ekstrapolasi.
Tiada kebenaran asas untuk ditangkap. Tidak seperti RAG (terbatas pada dokumen yang diketahui) atau Vision Extract (terbatas pada dokumen fizikal), Generative Research beroperasi merentas korpus terbuka. Jangkaan "sepatutnya X" jauh lebih sukar untuk disahkan terhadap kebenaran asas.
Contoh kegagalan yang realistik: sistem Generative Research menghasilkan taklimat risikan persaingan mengenai pelancaran produk terkini pesaing. Taklimat menyertakan butiran harga dan petikan pelanggan. Harga diekstrapolasi dari siaran akhbar berusia 6 bulan dan kini salah. Petikan pelanggan adalah rekaan dari gaya petikan sebenar dalam kandungan yang diindeks. Kedua-duanya kelihatan boleh dipercayai. Taklimat sampai kepada eksekutif yang membuat keputusan penempatan berdasarkannya. Penempatan adalah salah untuk pasaran semasa.
Pengurangan: semakan fakta manusia wajib terhadap sumber utama untuk mana-mana output Generative Research yang akan diedarkan. Ini bukan pilihan berdasarkan betapa boleh dipercayai sistem kelihatan. Ia adalah keperluan dasar untuk corak tanpa mengira kualiti sistem. Lihat artikel corak Generative Research untuk playbook pengurangan penuh.
Autonomous Agent: tinggi
Autonomous Agent menjalankan berbilang gelung keupayaan secara berurutan. Risiko halusinasi bergabung merentas iterasi.
Inilah cara ia meningkat: Gelung 1, ejen menelan permintaan pelanggan dan menjana analisis (risiko halusinasi sederhana). Gelung 2, ejen menggunakan analisis itu untuk menjana rancangan (risiko sederhana, kini berdasarkan analisis yang berpotensi dihaluskan). Gelung 3, ejen melaksanakan langkah berdasarkan rancangan (langkah Execute diambil atas halusinasi yang berpotensi bergabung). Menjelang gelung 5 atau 6, ejen mungkin mengambil tindakan luaran yang tidak boleh dipulihkan berdasarkan premis yang tidak pernah tepat.
Jenis ralat bergabung yang khusus: ejen menghaluskan fakta dalam gelung 1, merujuknya sebagai ditetapkan dalam gelung 2, membina atasnya dalam gelung 3, dan menjelang gelung 4 halusinasi telah menjadi sebahagian daripada konteks kerja ejen, memperkukuhkan dirinya sendiri. Ini lebih sukar untuk ditangkap daripada halusinasi satu kali kerana ralat kelihatan konsisten secara dalaman.
Pengesanan pada tahap ini memerlukan pemeriksaan langkah penaakulan pertengahan, bukan hanya output akhir. Sebelum mana-mana tindakan Execute luaran, pusat pemeriksaan manusia menyemak rantaian penuh: apa yang disimpulkan ejen, berdasarkan apa, dan adakah rantaian itu tahan terhadap penelitian?
"Autonomous Agent menggabungkan halusinasi merentas iterasi gelung. Fakta yang dihaluskan dalam gelung 1 menjadi sebahagian daripada konteks kerja menjelang gelung 3. Menjelang gelung 5, ejen mungkin mengambil tindakan luaran yang tidak boleh dipulihkan berdasarkan premis yang tidak pernah tepat. Mengesan ini memerlukan pemeriksaan langkah penaakulan pertengahan, bukan hanya semakan output akhir." (Rework Autonomous Agent Implementation Analysis, 2026)
"RAG mengurangkan kadar halusinasi sebanyak 40-60% hanya dengan menjangkar output dalam konteks yang diambil semula, tanpa mengubah model asas sama sekali. Intervensi paling berkesan untuk risiko halusinasi perusahaan bukan pemilihan model. Ia adalah seni bina pengambilan semula." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
Peringkat Risiko Halusinasi
Peringkat Risiko Halusinasi adalah rangka kerja klasifikasi corak yang memberikan setiap corak AI tahap risiko (Sangat Rendah, Rendah-Sederhana, Sederhana, atau Tinggi) berdasarkan dua faktor: sama ada keupayaan Generate corak menghasilkan bahasa semula jadi terbuka (risiko lebih tinggi) atau output yang dikekang seperti nombor dan medan berstruktur (risiko lebih rendah), dan sama ada ralat bergabung merentas gelung pelaksanaan (risiko bergabung untuk Autonomous Agent, risiko terpencil untuk corak satu larian). Penilaian peringkat menentukan keperluan pusat pemeriksaan HITL minimum: corak Sangat Rendah tidak memerlukan semakan wajib, corak Sederhana memerlukan semakan manusia sebelum pengedaran luaran, dan corak Tinggi memerlukan semakan sebelum setiap output yang mendorong tindakan luaran.
Rework Analysis: Berdasarkan penemuan tinjauan halusinasi arXiv bahawa RAG adalah teknik pengurangan paling berkesan tunggal, dan penanda aras pengeluaran yang menunjukkan kadar halusinasi 69-88% dalam pertanyaan domain undang-undang tanpa jangkar, rangka kerja Peringkat Risiko Halusinasi mengutamakan seni bina jangkar berbanding pemilihan model sebagai tuas pengurangan risiko utama. Data pelaksanaan Rework menunjukkan bahawa pasukan yang menggunakan rangka kerja peringkat semasa pemilihan corak mengurangkan insiden berkaitan halusinasi sebanyak purata 73% pada tahun pertama berbanding pasukan yang memperlakukan halusinasi sebagai risiko seragam merentas semua corak.
Strategi pengurangan yang sebenarnya berfungsi
Jangkar. Pertahankan model terikat pada bahan sumber tertentu. RAG mengekang pangkalan pengetahuan. Vision Extract mengekang kepada dokumen fizikal. Meeting Intelligence mengekang kepada transkrip audio. Lebih terhad konteks penjanaan, lebih rendah kadar halusinasi. Penjanaan tanpa kekangan (Generative Research, perancangan Autonomous Agent) memerlukan semakan manusia yang lebih kuat secara berkadar.
Ambang keyakinan. Tandai output keyakinan rendah untuk semakan dan bukannya melepaskannya. Ini memerlukan sistem sebenarnya menghasilkan skor keyakinan yang dikalibrasi. Tidak semua melakukannya. Apabila skor keyakinan tersedia, tetapkan ambang yang menghalakan output tidak pasti ke semakan manusia sebelum tindakan. Apabila ia tidak tersedia, itu adalah kriteria pemilihan produk.
Format output berstruktur. Hadkan penjanaan kepada skema yang ditakrifkan di mana sahaja mungkin. "Ekstrak 5 medan ini dalam format JSON ini" mempunyai risiko halusinasi yang lebih rendah daripada "ringkaskan dokumen ini." Format berstruktur memberikan model lebih sedikit darjah kebebasan untuk mencipta kandungan dan memberikan Anda pengesahan format output automatik yang lebih mudah.
Human-in-the-loop pada titik penyerahan berisiko tinggi. Sempadan Execute adalah tempat halusinasi menyebabkan kerosakan sebenar. Halusinasi yang kekal dalam barisan semakan draf adalah menjengkelkan. Halusinasi yang menghantar e-mel, mengemas kini rekod kewangan, atau menjadualkan mesyuarat adalah liabiliti. Pusat pemeriksaan HITL sebelum langkah Execute yang tidak boleh dipulihkan adalah pertahanan terakhir. Lihat kecerunan risiko untuk di mana pusat pemeriksaan tersebut berada.
Apa yang tidak berfungsi
"Hanya beritahu model supaya tidak menghaluskan." Arahan seperti "hanya nyatakan fakta yang Anda pasti" dan "jangan mencipta perkara" mengurangkan kadar halusinasi secara sederhana dalam beberapa tetapan dan mempunyai hampir tiada kesan dalam yang lain. Model bahasa menjana token seterusnya yang paling mungkin. Mereka tidak "tahu" apabila mereka menghaluskan. Arahan boleh mengalihkan tingkah laku pada margin, bukan menghapuskan mekanisme asas.
Pengurangan suhu sebagai penyelesaian lengkap. Tetapan suhu yang lebih rendah menghasilkan output yang lebih boleh diramal, kurang kreatif. Ia tidak menghasilkan output yang lebih tepat secara fakta. Model suhu rendah akan menghaluskan dengan yakin dan konsisten dan bukannya secara kreatif. Dalam sesetengah kes, suhu rendah menjadikan halusinasi lebih sukar untuk ditangkap kerana output lebih seragam dan kurang jelas salah.
Menganggap model yang lebih mahal menghapuskan risiko halusinasi. Model yang lebih mampu memang menghaluskan lebih sedikit pada banyak tugasan. Tetapi seperti yang didokumenkan tinjauan komprehensif arXiv tentang halusinasi LLM, semua model semasa menghaluskan. Bidang ini telah beralih dari "mengejar sifar" kepada "menguruskan ketidakpastian." Untuk Generative Research atau pelancaran Autonomous Agent berisiko tinggi, soalannya bukan "model mana?" Ia "proses semakan manusia apa yang wujud tanpa mengira model mana?"
Apabila halusinasi menyebabkan kerosakan sebenar
Tindak balas organisasi kepada insiden halusinasi mempunyai urutan tertentu:
Bendung. Hentikan penyebaran lanjut output yang dihaluskan. Jika ia sampai kepada pihak luaran, nilai apa yang mereka terima dan sama ada pembetulan diperlukan.
Audit ke belakang. Kesan rantaian penuh: apa yang dijana sistem, berdasarkan input dan hasil pengambilan semula apa, dengan pusat pemeriksaan tadbir urus apa yang ada? Audit ini mewujudkan punca akar.
Klasifikasikan kegagalan. Adakah ini kegagalan pengambilan semula (dokumen yang salah diambil semula), kegagalan pengisian jurang (konteks yang tiada diisi dengan rekaan), atau kegagalan bergabung (ralat berbilang langkah)? Klasifikasi menentukan pembetulan.
Betulkan konfigurasi corak. Kegagalan pengambilan semula diperbaiki dengan kemas kini pangkalan pengetahuan dan peningkatan kualiti pengambilan semula. Kegagalan pengisian jurang diperbaiki dengan kekangan jangkar yang lebih kuat atau suhu yang lebih rendah. Kegagalan bergabung memerlukan pusat pemeriksaan HITL tambahan pada iterasi gelung yang lebih awal.
Laraskan tadbir urus. Insiden mendedahkan jurang dalam pusat pemeriksaan sedia ada. Tambahkan pusat pemeriksaan yang akan menangkap kegagalan ini sebelum iterasi pelancaran berikutnya.
Berkomunikasi. Pihak berkepentingan dalaman yang bergantung pada output yang dihaluskan perlu tahu apa yang salah dan apa yang diperbetulkan. Pemulihan kepercayaan selepas insiden halusinasi adalah projek komunikasi, bukan hanya projek teknikal.
Corak risiko halusinasi tinggi memerlukan pusat pemeriksaan HITL yang lebih ketat. Itulah sambungan langsung kepada keperluan tadbir urus mengikut corak. Struktur tadbir urus bukan tentang tidak mempercayai AI. Ia tentang mengetahui corak mana yang memerlukan lebih banyak pusat pemeriksaan dan membinanya ke dalam aliran kerja sebelum sesuatu tidak berjalan baik.
Matlamatnya bukan mengelakkan AI kerana ia boleh menghaluskan. Ia melancarkan corak dengan pengesanan dan pengurangan yang berkadar dengan profil risiko mereka. Kebanyakan corak, kebanyakan masa, beroperasi dalam julat yang boleh diterima. Bina tadbir urus untuk mengesahkan itu, dan untuk menangkap pengecualian sebelum ia menjadi insiden.
Soalan Lazim
Apakah Peringkat Risiko Halusinasi?
Peringkat Risiko Halusinasi mengklasifikasikan setiap corak AI pada risiko Sangat Rendah, Rendah-Sederhana, Sederhana, atau Tinggi berdasarkan sama ada keupayaan Generate menghasilkan bahasa semula jadi terbuka (risiko lebih tinggi) atau output yang dikekang seperti nombor dan medan (risiko lebih rendah), dan sama ada ralat bergabung merentas gelung. Penilaian peringkat menentukan keperluan HITL minimum: corak Sangat Rendah tidak memerlukan semakan wajib, corak Sederhana memerlukan semakan sebelum pengedaran luaran, dan corak Tinggi memerlukan semakan sebelum setiap output yang mendorong tindakan luaran.
Corak AI mana yang paling kebal terhadap halusinasi?
Scoring and Routing dan Anomaly Agent hampir kebal kerana ia menghasilkan output berangka kebarangkalian dan bukannya bahasa semula jadi. "Skor petunjuk: 73" dan "Anomali transaksi: keyakinan 99.2%" tidak boleh menghaluskan dalam erti kata tradisional. Mod kegagalan mereka adalah salah kalibrasi dan hanyut, bukan fabrikasi. Personalization Engine juga berisiko rendah kerana ia memilih kandungan dan bukannya menjana kandungan.
Apakah pengurangan paling berkesan untuk halusinasi dalam AI perusahaan?
Jangkar RAG adalah pengurangan struktur paling berkesan tunggal, mengurangkan kadar halusinasi sebanyak 30-70% merentas domain dan menurunkan kadar di bawah 2% dalam tugasan rumusan apabila kualiti pengambilan semula tinggi. Ini berfungsi dengan mengekang penjanaan kepada bahan sumber tertentu dan bukannya sintesis terbuka. Pandangan utama ialah intervensi paling berkesan adalah seni bina pengambilan semula, bukan pemilihan model. Model yang lebih baik dengan pengambilan semula yang buruk masih menghasilkan jawapan yang salah.
Bagaimana kadar halusinasi berbeza mengikut domain?
Kadar halusinasi khusus domain berbeza secara dramatik walaupun dengan model peringkat teratas. Pertanyaan pengetahuan umum kini menghaluskan pada kadar di bawah 1% untuk model teratas. Tetapi pertanyaan domain undang-undang menunjukkan kadar halusinasi 69-88% dalam situasi berisiko tinggi. AI perubatan menunjukkan kadar 43-64% bergantung pada kualiti prompt. Implikasinya: pelancaran AI perusahaan dalam domain undang-undang, perubatan, atau pematuhan memerlukan jangkar dan tadbir urus HITL yang jauh lebih ketat berbanding aplikasi pengetahuan umum.
Adakah menggunakan model yang lebih mahal menghapuskan risiko halusinasi?
Tidak. Model yang lebih mampu menghaluskan lebih sedikit pada banyak tugasan, tetapi semua model pengeluaran semasa masih menghaluskan. Tinjauan komprehensif arXiv mendokumenkan bidang itu telah beralih dari "mengejar sifar" kepada "menguruskan ketidakpastian." Untuk pelancaran Generative Research dan Autonomous Agent dalam domain berisiko tinggi, soalannya bukan model mana yang digunakan tetapi proses semakan manusia apa yang wujud tanpa mengira model mana yang dipilih. Pemilihan model adalah pemboleh ubah kedua. Jangkar, format output berstruktur, dan pusat pemeriksaan HITL adalah yang utama.
Apakah mod kegagalan halusinasi paling berbahaya untuk Autonomous Agent?
Halusinasi bergabung merentas iterasi gelung. Fakta yang dihaluskan dalam gelung 1 menjadi sebahagian daripada konteks kerja ejen dan dianggap ditetapkan menjelang gelung 3. Menjelang gelung 5 atau 6, ejen mungkin mengambil tindakan luaran yang tidak boleh dipulihkan berdasarkan premis yang tidak pernah tepat dan yang kini kelihatan konsisten secara dalaman dalam rantaian penaakulan ejen. Ini lebih sukar untuk ditangkap daripada halusinasi satu kali kerana ralat kelihatan memperkukuh dirinya sendiri. Pengurangannya ialah pemeriksaan langkah penaakulan pertengahan pada setiap iterasi gelung, bukan hanya semakan output akhir.
Ketahui lebih lanjut

Co-Founder, Rework.com
On this page
- Apa yang halusinasi sebenarnya dalam konteks perniagaan
- Risiko halusinasi mengikut corak
- Scoring and Routing: sangat rendah
- Anomaly Agent: sangat rendah
- Vision Extract: rendah-sederhana
- Meeting Intelligence: rendah-sederhana
- Personalization Engine: rendah
- RAG Assistant: sederhana
- Workflow Copilot: sederhana
- Document Review: sederhana
- Generative Research: tinggi
- Autonomous Agent: tinggi
- Peringkat Risiko Halusinasi
- Strategi pengurangan yang sebenarnya berfungsi
- Apa yang tidak berfungsi
- Apabila halusinasi menyebabkan kerosakan sebenar
- Ketahui lebih lanjut