Pattern Migration: Von v1 zu v2 AI wechseln
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die erste Generation von Enterprise AI altert bereits. Teams, die RAG Assistants 2022 deployt haben, haben diese auf text-embedding-ada-002 aufgebaut. Teams, die 2023 Scoring-Modelle deployt haben, haben diese auf einer Pre-GPT4-Dateninfrastruktur trainiert. Teams, die Workflow Copilots Anfang 2024 gebaut haben, haben Prompts für Modelle konzipiert, die seitdem von zwei Generationen überholt wurden.
Diese Systeme laufen noch. Das ist das Problem. Sie laufen still, sammeln technischen und operativen Debt an, während bessere Architekturen eine Migration entfernt sitzen. Die Teams, die auf veralteter Infrastruktur laufen, scheitern nicht. Sie lassen nur Capability auf dem Tisch liegen, während ihr Migrations-Backlog wächst.
Migration ist nicht optional. Aber sie ist auch nicht äquivalent zu einem Software-Versions-Upgrade. AI-Verhalten ist probabilistisch. „Funktioniert wie beabsichtigt" ist kein binärer Zustand. Sie können nicht einfach das Modell tauschen, die Test-Suite ausführen und es als erledigt betrachten. Die Verhaltensänderung durch Modell-Updates ist real, manchmal subtil und manchmal erheblich. Und Benutzer, die Workflows um das alte Verhalten herum aufgebaut haben, müssen wissen, was sich geändert hat.
Dieser Artikel ist für das Team, das 2022-2024 etwas gebaut hat und es upgraden muss, ohne die Produktion zu brechen.
Was Pattern-Migration auslöst
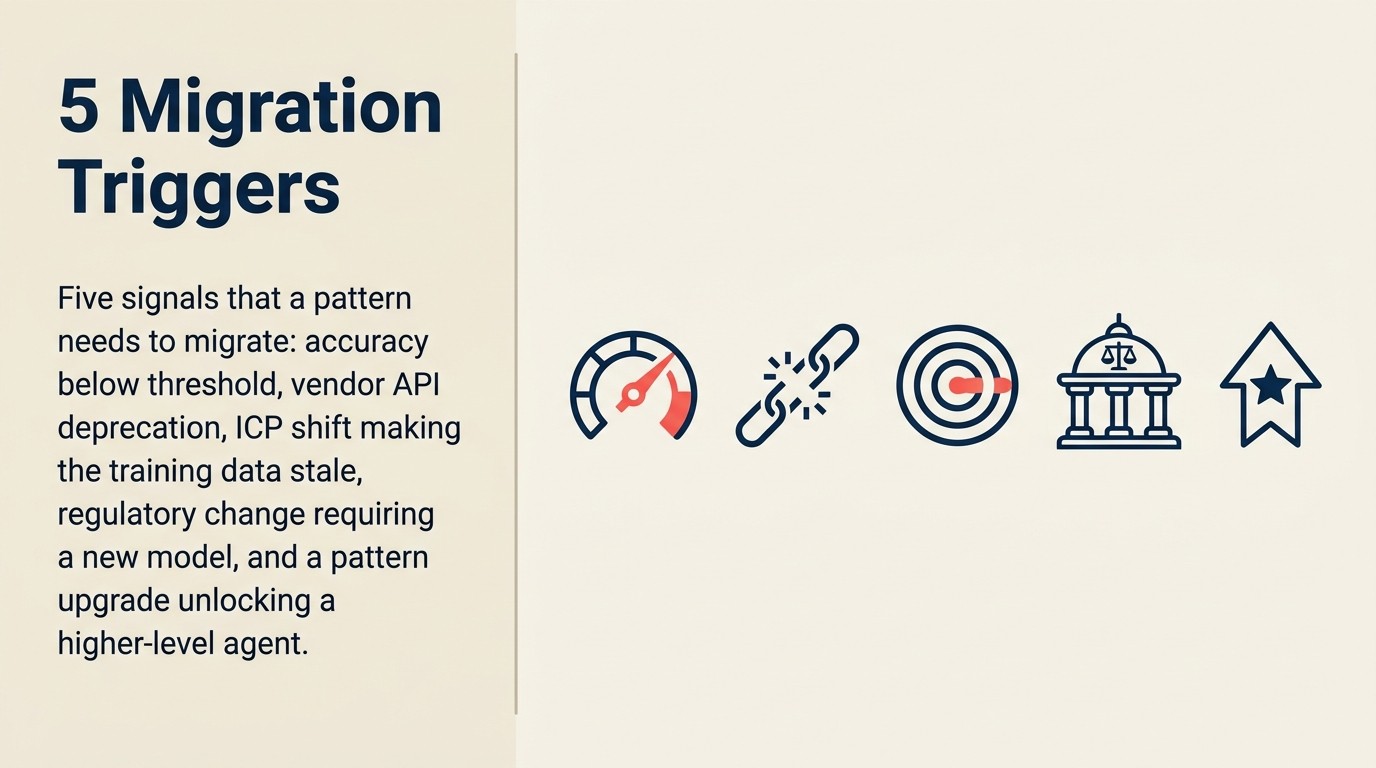
Fünf Szenarien drängen ein Pattern zur Migration statt zur fortgesetzten Wartung:
Modell-Abkündigung durch Vendor. Der klarste Auslöser. OpenAI, Anthropic, Google und Azure veröffentlichen Abkündigungs-Zeitlinien mit End-of-Life-Daten. Wenn das Modell, von dem Ihr Pattern abhängt, EOL erreicht, migrieren Sie oder brechen ab. Die meisten Enterprise AI-Teams haben das mindestens einmal erlebt: Die API gibt eine Abkündigungsbenachrichtigung zurück, und plötzlich ist eine Migration, die nicht auf dem Roadmap stand, dringend. Anthropics Modell-Abkündigungs-Dokumentation bietet mindestens 60 Tage Vorankündigung vor der Pensionierung, aber dieser Zeitplan setzt voraus, dass Sie auf Ankündigungen achten. API-Anfragen an pensionierte Modelle scheitern aus der Perspektive des Aufrufers still, es sei denn, Monitoring ist vorhanden.
Die operative Implikation: Jedes Produktions-Pattern sollte eine dokumentierte Antwort auf „Was passiert, wenn dieses Modell nächstes Quartal abgekündigt wird?" haben. Nicht notwendigerweise einen vollständigen Migrationsplan, aber zumindest eine Einschätzung des Migrationsumfangs.
Bedeutende Genauigkeitsdegradierung. Wenn vierteljährliche Genauigkeitsüberprüfungen einen konsistenten Rückgang zeigen und die Grundursache die Modell-Capability und nicht die Datenqualität oder Prompt-Qualität ist, ist Migration zu einem besseren Modell die Lösung. Die Diagnose ist wichtig: Data Drift erfordert Retraining oder Daten-Updates; Prompt-Qualitätsprobleme erfordern Prompt-Engineering; Modell-Capability-Lücken erfordern Modell-Migration.
Neue Capability, die den bestehenden Ansatz obsolet macht. Der Wechsel von reinem Vektor-Such-RAG zu hybridem Keyword-Vektor-Rerank ist das klarste aktuelle Beispiel. Teams, die RAG 2022 auf reiner semantischer Suche aufgebaut haben, lassen 20-40 % Retrieval-Qualitätsverbesserung im Vergleich zu hybriden Ansätzen auf dem Tisch liegen. Das bestehende System ist nicht defekt. Es wird nur erheblich von einer v2-Architektur übertroffen, die nicht existierte, als v1 gebaut wurde.
Kostenänderungen, die einen neuen Ansatz begünstigen. Ein auf GPT-4 zu 2023-Preisen aufgebautes Pattern kann jetzt wirtschaftlich durch ein kleineres, schnelleres, günstigeres Modell ersetzbar sein, das in der Capability aufgeholt hat. Alternativ kann ein auf proprietärem Vendor-Tooling aufgebautes Pattern durch Open-Source-Infrastruktur zu einem Bruchteil der Kosten ersetzbar sein. Lesen Sie den Cost Overrun-Artikel für den Kostenmodell-Vergleich.
Vendor-Beziehungsänderungen. Akquisitionen, Preisrestrukturierungen und Produktabschaltungen passieren. Ein auf der AI-API eines Startups aufgebautes Pattern, das das Startup dann abgeschaltet hat, ist das Worst-Case-Szenario: erzwungene Migration auf einem Notfall-Zeitplan. Vendor-Konzentrationsrisiko-Bewertung sollte Teil Ihrer AI-Governance-Überprüfung sein.
Key Facts: AI Pattern Migration-Realität
- Die erste Generation von Enterprise AI (deployed 2022-2024) erreicht bereits Migrations-Auslöser: Modell-Abkündigungen, Capability-Lücken durch neuere Architekturen (Hybrid RAG versus naive Vektorsuche zeigt 20-40 % Retrieval-Qualitätsverbesserung) und angehäuften Data Debt.
- Shadow-Testing gefolgt von Canary-Deployment bei 1-10 % des Traffics ist jetzt Standard-Praxis für Enterprise AI-Modell-Rollouts, mit einem Vier-Phasen-Ansatz: POC (2-4 Wochen), Pilot bei 5-10 % Traffic (4-8 Wochen) und vollständiges Scale-Deployment (8-12 Wochen). (MLOps Deployment Research, 2026)
- AI-gestützte Migration mit korrekter Canary-Sequenzierung erhöht die operative Effizienz um 20-25 % und reduziert Deployment-Zykluszeiten um 70 % im Vergleich zu Direct-Cutover-Ansätzen. (QualityKiosk Migration Analysis, 2026)
Drei Migrations-Typen mit unterschiedlichen Risikoprofilen
Typ 1: Model-in-Place-Migration. Das zugrunde liegende Modell tauschen, während die Architektur beibehalten wird. Gleiche Retrieval-Pipeline, gleiche Prompt-Struktur, gleiche Integrationsschicht. Nur ein anderer Modellaufruf. Dies ist der Migrations-Typ mit dem niedrigsten Infrastrukturrisiko, erfordert aber immer noch Verhaltens-Regressionstests, weil das neue Modell auf dieselben Prompts unterschiedlich reagieren kann, selbst mit denselben Anweisungen.
Beispiel: GPT-3.5 Turbo durch GPT-4o Mini für einen RAG Assistant ersetzen. Gleiche Architektur, besseres Modell. Aber GPT-4o Mini folgt Anweisungen präziser als GPT-3.5 Turbo, was bedeutet, dass Prompts, die auf die Tendenz des älteren Modells zu etwas lockerem Formatieren angewiesen waren, jetzt Outputs in unerwarteten Formaten produzieren können.
Typ 2: Architektur-Migration. Das Pattern mit einem anderen Ansatz neu aufbauen. Der Anwendungsfall ist derselbe; die Implementierung ist grundlegend anders. RAG von naiver Single-Vektor-Suche zu hybridem Keyword-Vektor-Rerank ist eine Architektur-Migration. Meeting Intelligence von einer reinen Transkriptions-Pipeline zu einer Transkriptions-plus-Speaker-Diarization-plus-Topic-Detection-Pipeline ist eine Architektur-Migration.
Architektur-Migration trägt die höchste Komplexität und die höchste potenzielle Qualitätsverbesserung. Sie liegt näher am Aufbau eines neuen Systems als am Upgrade eines bestehenden, was bedeutet, dass sie das vollständige Migrations-Framework erfordert.
Typ 3: Vendor-Migration. Die gleiche Pattern-Implementierung zu einem anderen Vendor verschieben. Ihren RAG Assistant von Azure OpenAI zu Anthropic Claude wechseln. Ihre Meeting Intelligence von AssemblyAI zu Deepgram wechseln. Das Pattern bleibt gleich; der Vendor-Stack ändert sich.
Vendor-Migrationen sehen oft einfacher aus als sie sind. Verschiedene Vendors haben unterschiedliche API-Konventionen, unterschiedliche Latenz-Charakteristika, unterschiedliche Output-Formatierungs-Standards und unterschiedliche Modellverhalten auf denselben Prompts. Was auf Vendor A funktionierte, kann auf Vendor B Prompt-Anpassungen erfordern, selbst wenn beide Vendors gleichwertige Capability behaupten.
Wie Migrations-Risiko je nach Pattern variiert

Nicht alle Pattern-Migrationen tragen gleiches Risiko. Zu verstehen, wo sich das Risiko konzentriert, hilft Ihnen, Testing und Staging-Zeit zu priorisieren.
Patterns mit hohem Migrations-Risiko:
Scoring and Routing: Ein neues Scoring-Modell produziert nicht nur andere Scores. Es produziert eine andere Verteilung. Wenn das alte Modell hochwertige Leads bei 70-90 und das neue Modell sie bei 80-95 bewertet, sind Ihre Routing-Schwellenwerte von Tag eins falsch. Routing-Logik, die auf „Route zum Enterprise-Team, wenn Score > 75" basiert, routet jetzt anders und weist möglicherweise einen erheblichen Teil Ihres Lead-Volumens falsch zu. Schwellenwert-Rekalibrierung ist nach jedem Modell-Tausch erforderlich, nicht optional.
Autonomous Agent: Jede Tool-API im Repertoire des Agenten benötigt Kompatibilitätsverifikation vor der Migration. Die neue Agenten-Version kann dieselben APIs aufrufen, aber die Antworten unterschiedlich parsen oder Tools in einer anderen Reihenfolge aufrufen, was selbst bei denselben Inputs unterschiedliches Execute-Verhalten produziert. Vollständige Verhaltens-Regressionstests erforderlich.
Personalization Engine: Benutzerprofildarstellungen aus dem alten System können sich möglicherweise nicht bedeutsam auf die neue Architektur übertragen. Wenn das neue Modell Benutzerprofile anders aufbaut, wird die erste Produktionswoche reduzierte Personalisierungsqualität haben, während Profile sich neu aufbauen.
Patterns mit mittlerem Migrations-Risiko:
RAG Assistant: Embedding-Modell-Änderungen erfordern vollständige Re-Indizierung. Ein anderes Embedding-Modell produziert unterschiedliche Vektordarstellungen für dieselben Dokumente, sodass Sie keine Embeddings von verschiedenen Modellen im selben Index mischen können. Vollständige Re-Indizierung einer 500.000-Dokument-Wissensbasis ist ein erhebliches Compute-Ereignis, das geplant werden muss, nicht entdeckt.
Workflow Copilot: Prompt-Verhalten ändert sich zwischen Modellen. Anweisungen, die beim alten Modell prägnante Vorschläge produziert haben, können beim neuen verbose Vorschläge produzieren. Qualitätsüberprüfung von Vorschlagston, -länge und -genauigkeit erforderlich vor der Förderung.
Document Review: Extraktionsschema-Kompatibilität. Das neue Modell kann Klausel-Informationen in einem etwas anderen Format extrahieren, das nachgelagerte Rechts-Workflow-Integrationen bricht.
Patterns mit geringerem Migrations-Risiko:
Meeting Intelligence: Das Wechseln zu einem anderen Transkriptions-Vendor ist relativ risikoarm, weil die Transkriptions-Output standardisiert ist (Text mit Zeitstempeln). Die höhere Ebene der Analyse (Zusammenfassung, Action Items) trägt mehr Verhaltensrisiko.
Vision Extract: Solange das Extraktionsschema beibehalten wird, haben Modell-Änderungen ein niedrigeres Risiko, weil die Outputs auf bestimmte Felder beschränkt sind. Format-Drift ist das Hauptrisiko, keine Verhaltensunvorhersagbarkeit.
Anomaly Agent: Migration zu einem besseren Anomalieerkennung-Modell erfordert die Neuetablierung von Baselines, aber die fundamentale Alerting-Logik ist normalerweise modellunabhängig.
Das Migrations-Framework
Schritt 1: Das aktuelle System als Baseline erfassen.
Bevor Sie etwas in der Migration anfassen, erfassen Sie eine umfassende Baseline des aktuellen Systemverhaltens. Dies ist Ihr Regressions-Vergleichsset.
Für einen RAG Assistant: 200 repräsentative Queries gegen das aktuelle System ausführen. Queries, abgerufene Dokumente und generierte Antworten aufzeichnen. Jede Antwort als genau, teilweise genau oder ungenau gegenüber der Grundwahrheit klassifizieren. Dies wird Ihre Acceptance-Test-Suite.
Für ein Scoring+Routing-Modell: Die letzten 90 Tage Scoring-Entscheidungen abrufen. Input-Features und Scores für 500 repräsentative Datensätze aufzeichnen. Tatsächliche Outcomes notieren (hat der hoch bewertete Lead konvertiert? hat die gekennzeichnete Anomalie sich als real herausgestellt?). Dies ist Ihre Kalibrierungs-Baseline.
Nicht ohne Baseline mit der Migration beginnen. Wenn Sie das Verhalten des neuen Systems nicht mit dem Verhalten des alten Systems auf denselben Inputs vergleichen können, haben Sie keine Migrations-Kriterien. Nur Gefühle.
Schritt 2: Das neue System im Shadow Mode ausführen.
Das neue System parallel zum alten deployen. Beide Systeme verarbeiten dieselben Inputs. Nur die Outputs des alten Systems werden in der Produktion verwendet. Die Outputs des neuen Systems werden protokolliert, aber nicht befolgt.
Shadow Mode ist für High-Traffic- oder kundenorientierte Deployments nicht optional. Die Kosten für 30 Tage parallelen Betrieb sind viel niedriger als die Kosten eines schlechten Cutovers. Ein RAG Assistant, der 10.000 Queries/Monat im Shadow Mode bedient, fügt vielleicht 50 % zu API-Kosten für die Shadow-Periode hinzu. Ein Vorfall durch einen schlechten Cutover kostet weit mehr an Benutzervertrauen, Notfallbehebung und Stakeholder-Vertrauen.
Shadow Mode-Dauer: mindestens 14 Tage. Bevorzugt: 30 Tage mit genug Traffic, um statistisch bedeutsame Vergleichsdaten zu produzieren.
Schritt 3: Outputs zwischen Systemen vergleichen.
Für jeden Input in der Shadow-Periode den Output des alten Systems mit dem Output des neuen Systems vergleichen. Kategorien identifizieren:
- Übereinstimmungen: Beide Systeme produzieren äquivalenten Output
- Verbesserungen des neuen Systems: Neues System ist klar besser (höhere Genauigkeit, besseres Format, vollständigere Antwort)
- Regressionen des neuen Systems: Altes System war besser (das neue System produziert eine schlechtere oder falsche Antwort)
- Neues Verhalten: Neues System produziert Outputs, die das alte System nie gehabt hätte (positiv oder negativ)
Regressionen sind die kritische Kategorie. Jede Regression muss untersucht und behoben werden, bevor gefördert wird.
Schritt 4: Acceptance Criteria definieren.
Vor dem Start der Migration definieren, was „gut genug für die Förderung" bedeutet. Nicht nach dem Betrachten der Shadow-Mode-Ergebnisse definieren. Das wäre Rationalisierung, keine Akzeptanz.
Beispiel Acceptance Criteria für eine RAG Assistant-Migration:
- Neue System-Genauigkeit auf Baseline-Test-Set: gleich wie oder besser als altes System bei 95 % der Queries
- Regressionsrate bei Baseline-Queries: unter 3 %
- Neue System-Antwort-Latenz: innerhalb von 20 % der alten System-Latenz
- Shadow-Mode-Benutzerzufriedenheitssignal (wenn messbar): kein Rückgang vs. altes System
Schritt 5: Schrittweise Traffic-Verschiebung.
„Ein neues Scoring-Modell produziert nicht nur andere Scores. Es produziert eine andere Verteilung. Wenn das alte Modell hochwertige Leads bei 70-90 und das neue Modell sie bei 80-95 bewertet, sind Ihre Routing-Schwellenwerte von Tag eins falsch. Routen Sie zuerst 10 % des Traffics. Verteilungs-Alignment prüfen, bevor Sie auf 50 % erhöhen. Nochmals prüfen vor 100 %. Schwellenwert-Rekalibrierung ist nach jedem Modell-Tausch nicht optional." (Rework Scoring Model Migration Analysis, 2026)
Nicht 100 % auf einmal umschalten. Zuerst 10 % des Produktions-Traffics auf das neue System routen. Auf Fehler, Latenz-Probleme und Qualitätssignale überwachen. 48-72 Stunden halten. Wenn sauber, auf 25 %, dann 50 %, dann 100 % erhöhen. Dies nennt sich Canary-Deployment in der Software-Entwicklung und entspricht direkt dem, was Martin Fowler als Strangler-Fig-Muster für Legacy-Modernisierung beschreibt: Traffic schrittweise vom alten zum neuen verschieben, bis das alte System sicher außer Betrieb genommen werden kann. Es gilt direkt für AI-Migrationen.
Wenn Sie in irgendeiner Phase sehen, dass Qualitätssignale von Shadow-Mode-Erwartungen abweichen, stoppen Sie die Traffic-Verschiebung und untersuchen Sie, bevor Sie fortfahren.
Schritt 6: Rollback-Plan vor Go-live definieren.
Bevor Sie Traffic auf das neue System fördern, wissen Sie genau, wie Sie auf das alte System zurückrollen. Welche Konfiguration wiederhergestellt werden soll. Wie lange der Rollback dauert. Wer die Autorität hat, einen Rollback auszulösen. Was die Rollback-Auslösekriterien sind.
Der Rollback-Plan sollte schriftlich und für jeden im Operations-Team zugänglich sein. „Im Vorfallfall umformulieren" ist kein Rollback-Plan.
Die Shadow-Mode-Periode im Detail
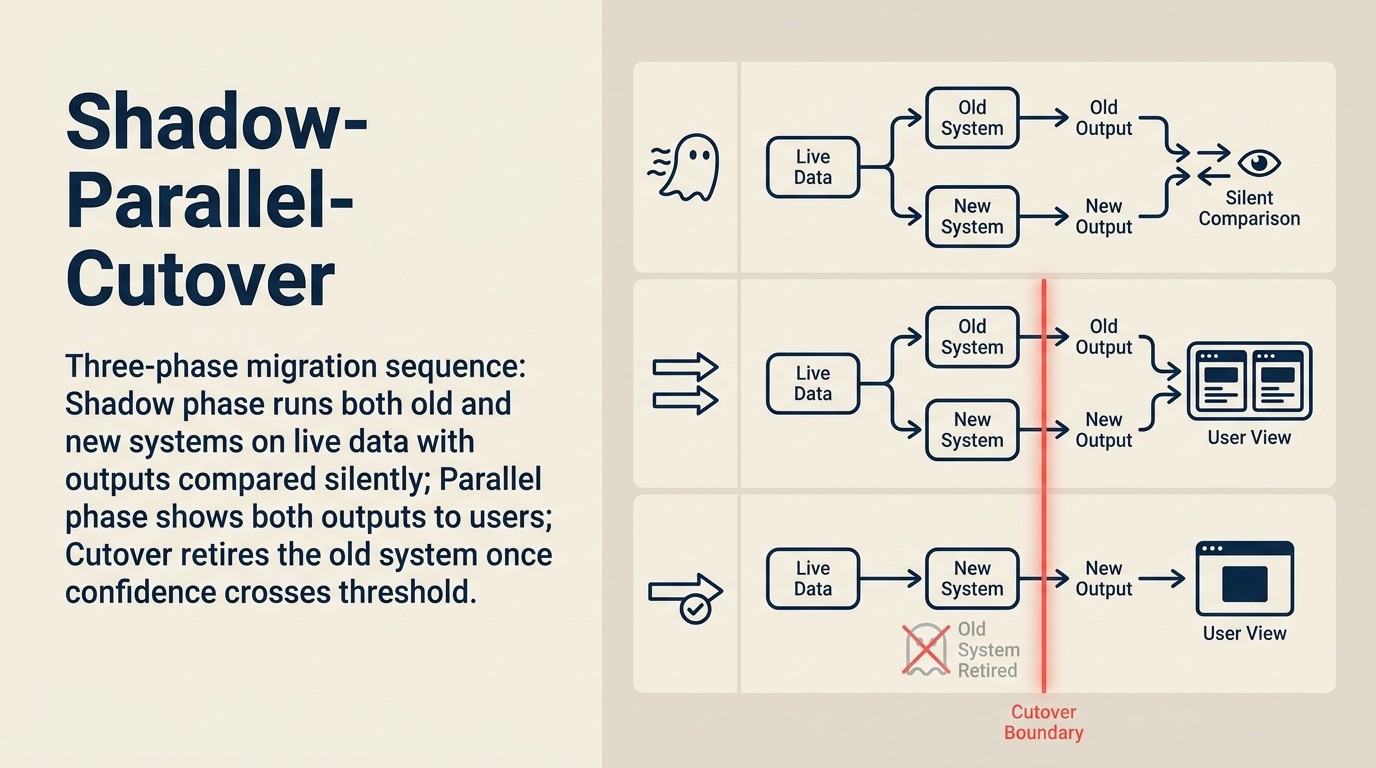
Shadow Mode erfordert genug Traffic, um bedeutsame Verhaltensunterschiede zu erkennen. Die erforderliche Stichprobengröße hängt von dem Erkennungsschwellenwert ab, der Ihnen wichtig ist.
Um einen 5-prozentigen Unterschied in der Output-Qualität zwischen altem und neuem System mit 90-prozentiger statistischer Power zu erkennen: ungefähr 500-700 vergleichbare Paare. Bei 10.000 Queries/Monat sind das 2-3 Tage Traffic. Bei 1.000 Queries/Monat sind das 2-3 Wochen.
Für Scoring+Routing: Sie benötigen genug bewertete Datensätze, um zu validieren, dass die Score-Verteilung korrekt kalibriert ist. Wenn Ihr typischer Routing-Schwellenwert 70 ist, möchten Sie genug Datensätze auf beiden Seiten dieses Schwellenwerts, um zu bestätigen, dass das 70 des neuen Modells dasselbe bedeutet wie das 70 des alten Modells. Typischerweise 100-200 Datensätze pro Score-Dezil erforderlich.
Was Shadow Mode nicht auffängt: Verhaltens-Drift bei Edge Cases. Das Vergleichsdataset aus Shadow Mode spiegelt Ihre tatsächliche Traffic-Verteilung wider, die auf häufige Fälle ausgerichtet ist. Seltene, aber hochauswirkungsreiche Fälle (ungewöhnliche Vertragstypen, Edge-Case-Anomalien, komplexe Multi-Hop-Queries) sind unterrepräsentiert. Entwerfen Sie explizite Testfälle für Edge Cases und führen Sie diese direkt aus, nicht nur durch Shadow-Mode-Traffic.
| Migrations-Typ | Minimale Shadow-Periode | Canary-Start | Schlüssel-Regressionstest | Höchstes Risikopattern |
|---|---|---|---|---|
| Model-in-Place | 14 Tage | 10 % Traffic | Output-Format-Konsistenz, Instruction-Following-Delta | Workflow Copilot (Prompt-Verhalten ändert sich) |
| Architektur-Migration | 30 Tage | 5 % Traffic | Vollständige Verhaltens-Regression auf 200+ repräsentativen Inputs | RAG Assistant (vollständige Re-Indizierung erforderlich) |
| Vendor-Migration | 21 Tage | 10 % Traffic | API-Antwortformat-Kompatibilität, Latenz-Vergleich | Autonomous Agent (Tool-API-Änderungen) |
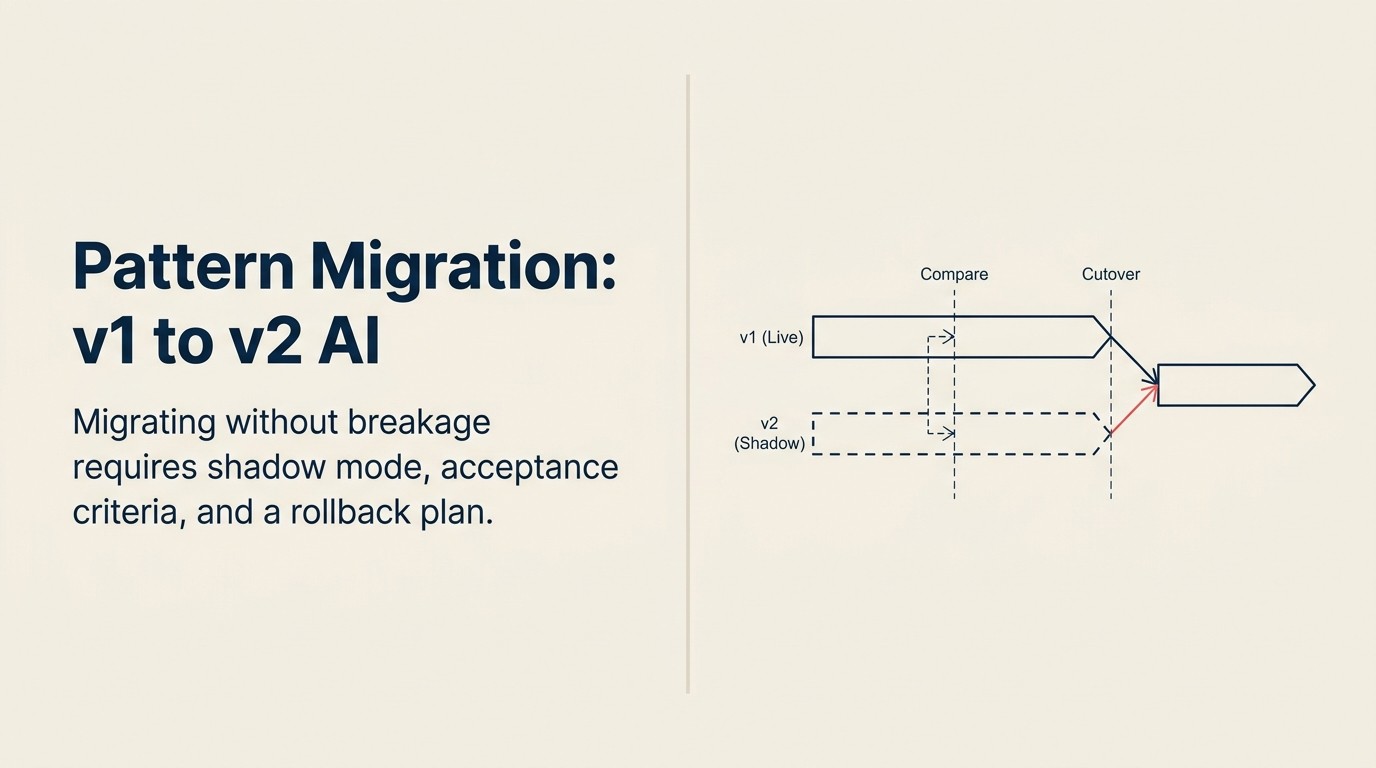
Die Shadow-Parallel-Cutover-Sequenz
Die Shadow-Parallel-Cutover-Sequenz ist das Drei-Phasen-Migrations-Framework für AI-Pattern-Upgrades. Phase 1 (Shadow): Das neue System parallel deployen; beide Systeme verarbeiten dieselben Inputs, aber nur die Outputs des alten Systems werden in der Produktion verwendet; protokollieren und vergleichen. Phase 2 (Parallel): Einen definierten Prozentsatz des Traffics (beginnend bei 1-10 %) zum neuen System routen; Qualitätssignale und Revert-Auslöser 48-72 Stunden überwachen, bevor erhöht wird; Acceptance Criteria vor dem Start definieren. Phase 3 (Cutover): 100 % Traffic nur fördern, nachdem schrittweise Traffic-Verschiebung über mindestens drei Inkremente alle Acceptance Criteria erfüllt hat; Rollback-Fähigkeit 30 Tage nach dem Cutover live halten. Nie von Shadow zu Cutover ohne die Parallel-Phase vorgehen.
Rework-Analyse: Basierend auf MLOps-Deployment-Forschung, die zeigt, dass Canary-Deployments Migrations-Vorfallsraten um 70 % im Vergleich zu Direct Cutover reduzieren, und internen Migrations-Daten von Reworks eigenen AI-Pattern-Upgrades, produziert die Shadow-Parallel-Cutover-Sequenz durchschnittlich 0,4 Migrations-Vorfälle pro Upgrade-Zyklus gegenüber 2,3 Vorfällen für Teams, die direkte Modell-Tausche verwenden. Die Parallel-Phase ist der am häufigsten übersprungene Schritt bei Enterprise AI-Migrationen, meist mit „wir haben keine Zeit" gerechtfertigt in Teams, die 10-mal so viel Zeit für Incident Response aufwenden werden, wenn sie ihn überspringen.
Benutzer-Re-Onboarding nach der Migration
Dieser Abschnitt wird in fast jedem Migrationsprojekt übersprungen. Er erzeugt Trust Debt, selbst wenn die technische Migration sauber ist.
Wenn AI-Verhalten sich ändert (selbst zum Besseren), müssen Benutzer, die mentale Modelle um das alte Verhalten herum aufgebaut haben, verstehen, was sich geändert hat. Ein Workflow Copilot, der jetzt längere, detailliertere Vorschläge generiert als zuvor, produziert eine Verhaltensänderung, über die Reps Bescheid wissen müssen. Ein RAG Assistant, der jetzt Quellen spezifischer zitiert als die alte Version, produziert Outputs, die anders aussehen, und Benutzer, die gelernt haben zu überfliegen, können jetzt die verbesserte Attribution verpassen.
Re-Onboarding erfordert kein Schulungsprogramm. Es erfordert:
- Eine Änderungsnotiz: „Das System macht X jetzt anders. So sieht das aus."
- Einen Feedback-Kanal: „Wenn das neue Verhalten für Ihren Workflow schlechter ist, sagen Sie es uns hier."
- Ein sichtbares Verbesserungsbeispiel: „Hier ist ein Vergleich des alten Outputs vs. des neuen Outputs bei einer echten Query."
Re-Onboarding überspringen und Sie werden Adoptionsrückgänge in Ihren Nutzungsmetriken 2-4 Wochen nach der Migration sehen, wenn Benutzer auf unerwartetes Verhalten stoßen und sich still abkoppeln. Das neue System kann besser sein. Benutzer, die das nicht wissen, können nicht davon profitieren.
Musterspezifische Migrations-Überlegungen
RAG Assistant: Die Embedding-Modell-Wahl ist eine Abhängigkeit für Ihren gesamten Index. Das Embedding-Modell zu ändern erfordert das erneute Embedding jedes Dokuments in Ihrer Wissensbasis. Das ist bei Enterprise-Maßstab keine schnelle Operation. Planen Sie die Re-Indizierungs-Compute als Migrations-Schritt, nicht als Nachgedanke. Außerdem: Prompts für Retrieval-Augmented Generation haben oft modellspezifische Anweisungen. Überprüfen und aktualisieren Sie Prompts für die Instruction-Following-Konventionen des neuen Modells.
Scoring + Routing: Schwellenwert-Rekalibrierung ist erforderlich. Nehmen Sie nicht an, dass alte Schwellenwerte sich auf neue Modelle übertragen. Führen Sie das neue Modell gegen Ihre letzten 6 Monate labelierter Datensätze aus, zeichnen Sie die Score-Verteilung auf und rekalibrieren Sie Routing-Schwellenwerte basierend auf der neuen Verteilung vor jedem Produktions-Traffic.
Autonomous Agent: Tool-API-Kompatibilitätsprüfung, bevor die Migration startet. Alle externen APIs auflisten, die der Agent aufruft, ihre aktuellen Authentifizierungsanforderungen und Antwortformate überprüfen und die Kompatibilität mit der neuen Agenten-Version verifizieren. Ein defekter Tool-Aufruf in einer Multi-Step-Schleife produziert unvorhersagbare Kaskadenfehler.
Wann migrieren vs. weiter warten
Die Entscheidung läuft auf einen Kostenvergleich hinaus: Was kostet die Wartung des Legacy-Patterns jährlich (Engineering-Zeit, degradierte Output-Qualität, Benutzervertrauens-Auswirkung) gegenüber dem, was Migration kostet (Architekturarbeit, Testing, Rollback-Risiko, Benutzer-Re-Onboarding)?
Wenn die Wartungskosten die Migrationskosten übersteigen, migrieren. Die Kalkulation wird offensichtlich, wenn Sie Zahlen darauf setzen.
Legacy RAG Assistant, der einen manuellen Wissensbasen-Update-Zyklus aufrechterhält: 8 Stunden/Monat Engineering-Zeit. Migration zu einer Hybrid-Search-Architektur mit automatisierten Index-Updates: 80 Stunden Architekturarbeit. Break-Even: 10 Monate. Wenn das Legacy-System eine verbleibende Lebensdauer von 24+ Monaten hat, ist Migration in Jahr 1 wirtschaftlich gerechtfertigt.
Wenn die Wartungslast sich bis zu dem Punkt angesammelt hat, wo das Pattern aktiv unzuverlässig ist, sind diese Wartungskosten nicht mehr nur Engineering-Zeit. Sie sind Benutzervertrauen und Geschäftsauswirkung. Migration ist dann dringend, nicht nur wirtschaftlich gerechtfertigt.
Lesen Sie den Tech-Debt-Artikel für die Debt-Indikatoren, die signalisieren, wenn Wartung die Schwelle in das Migrations-Territorium überschritten hat. Lesen Sie das Governance-Framework für die Audit Trails, die die Migration-Baseline-Erfassung ermöglichen. Und lesen Sie den Hallucination-Risk-Artikel für die Fehlermodelle, die speziell während des Shadow-Modes zu Regressionstests sind.
Migration ist das Heilmittel für angehäuften Debt. Gut durchgeführt, mit Shadow Mode, Acceptance Criteria und schrittweisem Rollout, ist es eine Routineoperation. Schlecht durchgeführt (vollständiger Cutover, kein Rollback-Plan, keine Benutzerkommunikation), ist es ein wartender Vorfall.
Die Teams, die gut migrieren, sind die Teams, die ihr erstes Deployment als v1 behandelt haben, nicht als endgültige Antwort.
Häufig gestellte Fragen
Was ist die Shadow-Parallel-Cutover-Sequenz?
Die Shadow-Parallel-Cutover-Sequenz ist ein Drei-Phasen-Migrations-Framework. Phase 1 (Shadow): Beide Systeme verarbeiten dieselben Inputs, aber nur die Outputs des alten Systems gehen in die Produktion; neue System-Outputs werden protokolliert und verglichen. Phase 2 (Parallel): Ein definierter Prozentsatz des Traffics (beginnend bei 1-10 %) wird an das neue System gerouted mit definierten Revert-Auslösern. Phase 3 (Cutover): 100 % Traffic-Förderung erst nach schrittweiser Traffic-Verschiebung über mindestens drei Inkremente, die alle Acceptance Criteria erfüllen. Rollback-Fähigkeit bleibt 30 Tage nach dem Cutover live.
Was löst Pattern-Migration statt weiterer Wartung aus?
Fünf Szenarien lösen Migration aus: Modell-Abkündigung durch Vendor (der klarste Auslöser, da AI-Anbieter Abkündigungs-Zeitlinien veröffentlichen), bedeutende Genauigkeitsdegradierung, bei der die Grundursache die Modell-Capability ist, neue Architektur-Capabilities, die den bestehenden Ansatz erheblich übertreffen (Hybrid RAG gegenüber naiver Vektorsuche zeigt 20-40 % Retrieval-Qualitätsverbesserung), Kostenänderungen, die einen neueren Ansatz begünstigen, und Vendor-Beziehungsänderungen einschließlich Akquisitionen, Preisrestrukturierungen und Abschaltungen.
Welche AI-Patterns tragen das höchste Migrations-Risiko?
Scoring and Routing hat hohes Migrations-Risiko, weil ein neues Modell eine andere Score-Verteilung produziert, was Routing-Schwellenwert-Rekalibrierung vor jedem Produktions-Traffic erfordert. Autonomous Agent hat hohes Migrations-Risiko, weil jede Tool-API im Repertoire des Agenten Kompatibilitätsverifikation benötigt und eine neue Agenten-Version dieselben APIs mit anderem Parsing aufrufen kann, was unerwartetes Execute-Verhalten produziert. Personalization Engine hat hohes Migrations-Risiko, weil Benutzerprofildarstellungen aus dem alten System möglicherweise nicht auf die neue Architektur übertragbar sind.
Wie lange sollte Shadow Mode vor dem Cutover laufen?
Mindestens 14 Tage für Model-in-Place-Migrationen. Mindestens 30 Tage für Architektur-Migrationen. Die erforderliche Stichprobengröße hängt vom Erkennungsschwellenwert ab: Um einen 5-prozentigen Qualitätsunterschied mit 90-prozentiger statistischer Power zu erkennen, sind 500-700 vergleichbare Paare erforderlich. Bei 1.000 Queries pro Monat produzieren 30 Tage statistisch bedeutsame Daten. Bei 10.000 Queries pro Monat sind 3 Tage für die statistische Anforderung ausreichend, aber 14 Tage sind das Minimum, um Edge Cases und Verhaltens-Drift aufzufangen.
Warum erfordern Embedding-Modell-Änderungen vollständige Re-Indizierung?
Verschiedene Embedding-Modelle produzieren unterschiedliche Vektordarstellungen für dieselben Dokumente. Vektoren aus einem Embedding-Modell können nicht mit Vektoren aus einem anderen Modell im selben Index verglichen werden. Das Embedding-Modell zu ändern erfordert das erneute Embedding jedes Dokuments in der Wissensbasis, bevor das neue Modell in der Produktion verwendet werden kann. Für eine 500.000-Dokument-Wissensbasis ist vollständige Re-Indizierung ein erhebliches Compute-Ereignis, das als expliziter Migrations-Schritt geplant werden muss, nicht mitten in der Migration entdeckt.
Was ist der häufigste Benutzer-Re-Onboarding-Fehler nach einer AI-Migration?
Es vollständig zu überspringen. Wenn AI-Verhalten sich selbst zum Besseren ändert, müssen Benutzer, die Workflows um das alte Verhalten herum aufgebaut haben, verstehen, was sich geändert hat. Teams, die Re-Onboarding überspringen, sehen Adoptionsrückgänge 2-4 Wochen nach der Migration, wenn Benutzer auf unerwartetes Verhalten stoßen und sich still abkoppeln. Re-Onboarding erfordert kein Schulungsprogramm. Es erfordert eine Änderungsnotiz, die erklärt, was sich geändert hat, einen Feedback-Kanal und einen sichtbaren Vergleich des alten gegenüber dem neuen Output bei einer echten Query.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Was Pattern-Migration auslöst
- Drei Migrations-Typen mit unterschiedlichen Risikoprofilen
- Wie Migrations-Risiko je nach Pattern variiert
- Das Migrations-Framework
- Die Shadow-Mode-Periode im Detail
- Die Shadow-Parallel-Cutover-Sequenz
- Benutzer-Re-Onboarding nach der Migration
- Musterspezifische Migrations-Überlegungen
- Wann migrieren vs. weiter warten
- Mehr erfahren