AIパターン別のハルシネーションリスク
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ハルシネーションはAIプロジェクトを終わらせる言葉です。常に発生するからではなく、間違ったコンテキスト(コンプライアンスドキュメント、クライアント向けのメール、医療記録、契約書の法的フラグ)で発生した時に、被害が現実であり、多くの場合公になるからです。
組織の対応は通常、2つの方向のどちらかで間違っています。リーダーシップがAIは安全でないと判断してイニシアティブを廃止する(過剰修正、本当の価値を諦める)か、インシデントは偶発的なものだと判断して変更なく続ける(不十分な修正、次のインシデントを待つ)かです。どちらの対応もハルシネーションリスクが実際にどこに存在するかの正直な評価に基づいていません。
正しい対応は、ハルシネーションリスクはパターン間で均一ではないことを理解することです。設計上ほぼ免疫のあるパターンもあります。他のパターンは動作の仕組みの構造的な特徴として高いリスクを持ちます。リスクを管理するには、どちらがどちらかを知ることが必要です。
ビジネスコンテキストでのハルシネーションとは何か
この分野の学術文献はかなりの量に達しています。32以上のハルシネーション緩和技術をカバーする包括的なarXiv調査(arXiv:2401.01313)は、Retrieval Augmented Generation(RAG)を事実ハルシネーションに対する最も効果的な単一の構造的緩和策として特定しています。この発見が以下のパターン推奨事項のいくつかを直接形成しています。ビジネスコンテキストでは3種類のハルシネーションが適用され、それぞれ意味のある違いがあります。
事実のハルシネーション。 モデルが偽りのことを自信を持って述べます。「返品期限は45日間です」が実際には30日の場合。「契約書は3月12日に署名されました」がドキュメントにそのような日付がない場合。モデルがたまたま間違っている尤もらしい文を生成しました。
引用のハルシネーション。 モデルがその主張をしていないソース、または存在しないソースに主張を帰属させます。「Q3のポリシーアップデートによると...」がそのようなポリシーアップデートがインデックスされていない場合。これは事実のハルシネーションとは異なります。なぜなら文は事実として正確かもしれませんが引用が捏造されているからです。
コンテキストのハルシネーション。 モデルが与えられた特定のコンテキストを反映しない尤もらしい内容を生成します。最も一般的な形: モデルは実際にそこにあるものではなく、一般的な知識に基づいて「あるはずの」もので文脈のギャップを埋めます。誰も言及しなかったアクションアイテムを含むミーティングサマリー。提出した契約書に存在しない条項への契約フラグ。
3種類すべてが異なる方法で害を引き起こします。事実のハルシネーションは直接的な誤情報を引き起こします。引用のハルシネーションはソースへの信頼を損ないます。コンテキストのハルシネーションは最も狡猾です。論理的なギャップを埋めているため、最も尤もらしく聞こえることが多いからです。
Key Facts: 本番環境でのハルシネーション率
- エンタープライズのベンチマークは、ドメイン固有のクエリに対して商用LLMで15〜52%のハルシネーション率を報告していますが、トップモデルの一般知識のハルシネーション率は1%未満に低下しています。(SQMagazine Hallucination Statistics, 2026)
- RAGはドメイン全体でハルシネーション率を30〜70%削減し、要約タスクでは2%未満まで低下させます。32以上のハルシネーション緩和技術のレビューで特定された最も効果的な単一の構造的緩和策です。(arXiv Hallucination Survey, 2024)
- 法律ドメインのAIシステムは高リスクなクエリで69〜88%のハルシネーション率を示します。医療AIシステムはプロンプトの質に応じて43〜64%を示します。2025年に利用可能な最も有能なモデルでも同様です。これらはハルシネーション1件あたりの影響が最も高い2つのドメインです。
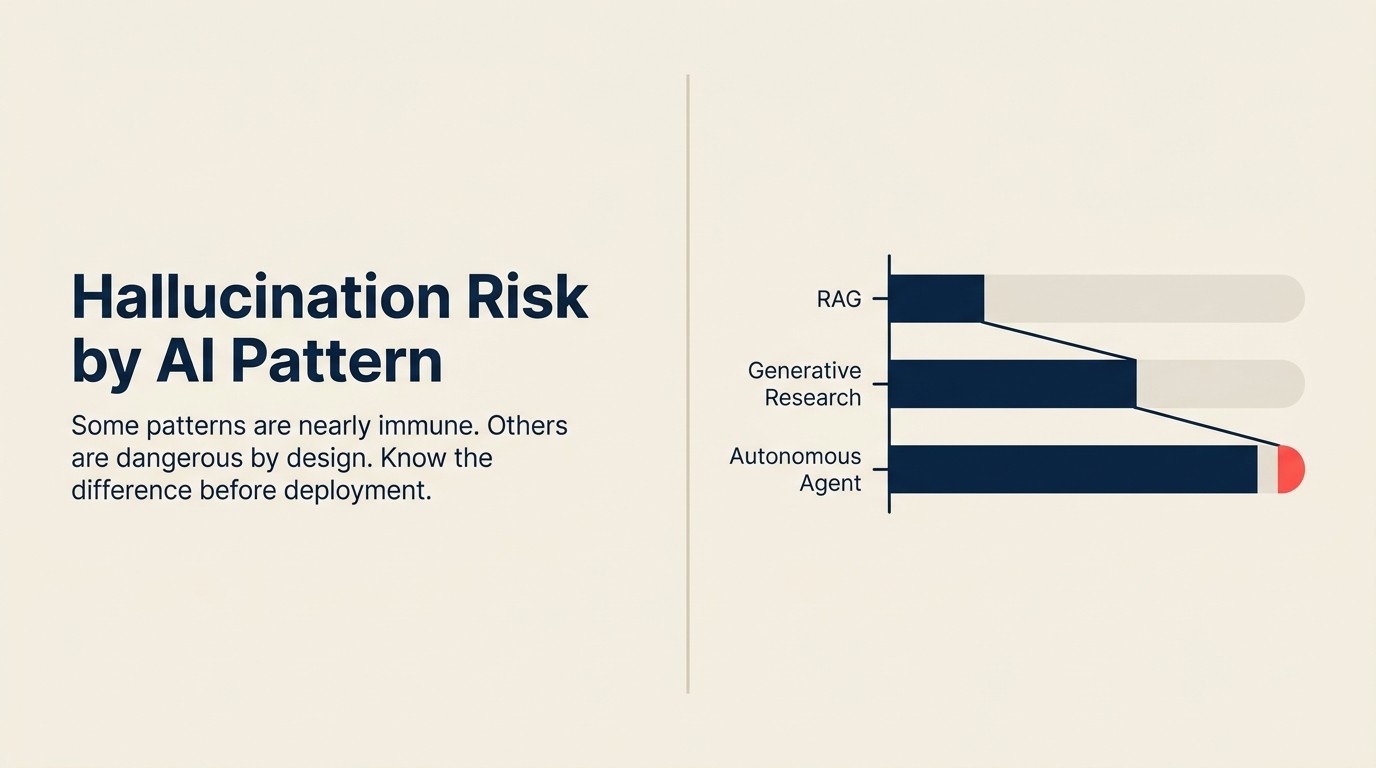
パターン別のハルシネーションリスク
| パターン | リスクレベル | 主なハルシネーションの種類 |
|---|---|---|
| Scoring + Routing | 非常に低い | N/A(確率的、言語ではない) |
| Anomaly Agent | 非常に低い | N/A(数値、言語ではない) |
| Vision Extract | 低〜中 | コンテキスト(抽出エラー) |
| Meeting Intelligence | 低〜中 | コンテキスト(アクションアイテム、帰属) |
| Personalization Engine | 低 | コンテンツ選択(生成ではない) |
| RAG Assistant | 中 | 引用+コンテキスト(検索失敗) |
| Workflow Copilot | 中 | コンテキスト(疎なコンテキストの補填) |
| Document Review | 中 | コンテキスト(欠落した条項の捏造) |
| Generative Research | 高 | 3種類すべて |
| Autonomous Agent | 高 | 3種類すべて、複合 |
Scoring and Routing: 非常に低い
Predictケイパビリティは言語ではなく確率を生成します。「Leadスコア: 73」はハルシネーションの表面ではありません。モデルは文を生成しません。数字を出力します。同等の失敗モードはモデルのドリフトです。基礎となるデータが変化するにつれてスコアが時間とともにキャリブレーションを失います。それは異なる緩和策を持つ別の問題です。しかし従来の意味でのハルシネーション、モデルが偽のテキストを生成するという意味では、ここでは適用されません。
Anomaly Agent: 非常に低い
Scoring+Routingと同じ推論です。このパターンは数値ストリームで動作します。「トランザクション異常フラグ: 信頼度99.2%」は確率的な出力であり、言語生成の出力ではありません。Anomaly Agentのエラーは偽陽性と偽陰性として現れ、ハルシネーションとしては現れません。
Vision Extract: 低〜中
Vision Extractのハルシネーションは抽出エラー、特に信頼度のキャリブレーション誤りにマッピングされます。ハルシネーションした文の同等物は、自信を持って間違っている抽出されたフィールド値です。請求書が12,470ドルを示しているのに「合計金額: 1,247ドル」など。これらのエラーは次の場合に最も頻繁に発生します。
- ドキュメントのフォーマットがモデルのトレーニングデータで表現されていない(新しいベンダーテンプレート)
- 画像の品質が低い(低解像度のスキャン、斜めの写真)
- フィールドが曖昧(同じドキュメントに2つの「日付」フィールド)
Vision Extractは物理的なドキュメントに制約されているため、リスクは低〜中です。モデルはページにないコンテンツを発明できません。そこにあるものを誤読または誤帰属するだけです。信頼度のキャリブレーションがガバナンスのレバーです。低信頼度の抽出を通過させるのではなく人間レビューのためにフラグを立てます。
Meeting Intelligence: 低〜中
文字起こし自体はほぼハルシネーション耐性があります。モデルは音声をテキストに変換しており、エラーは発明ではなく聞き誤りのように見えます。ハルシネーションリスクが入ってくるのはAnalyzeとGenerateのステージです。サマリー生成、アクションアイテムの抽出、話者の帰属です。
具体的なリスク。
- アクションアイテムの発明。 モデルがミーティングのコンテキストから「あるはずの」アクションアイテムを生成しますが、実際には述べられていません。「ジョンは金曜日までに契約書を送る」ジョンがそのような約束をしていない場合。
- 話者の帰属エラー。 特に複数参加者の通話で、モデルが文を間違った話者に帰属させます。「VP of Salesは商談が順調だと言った」が実際にはアカウントマネージャーが言った場合。
- サマリーの混同。 実際には議論されなかった重要な決定や約束が、ミーティングのコンテキストから暗示されるためサマリーに現れます。
文字起こしベースのパターンにはグランドトゥルースがあるためリスクは低〜中に留まります。実際の音声です。不一致はソースを聴くことでキャッチできます。緩和策はパターン別のガバナンス要件で議論されているように、CRMへのプッシュが記録となる前の人間レビューです。
Personalization Engine: 低
このパターンは主にコンテンツ選択とランク付けであり、コンテンツ生成ではありません。「閲覧履歴に基づいてこのユーザーに製品Bより製品Aを表示する」はハルシネーションしません。ハルシネーションリスクが関連するのは、Personalization Engineがコンテンツのバリアントも生成する場合のみです。パーソナライズされたメールの件名、製品説明、動的なランディングページのコピー。そのような場合、リスクは中に上昇し、Generativeと同じ緩和策が適用されます。
RAG Assistant: 中
RAGはナレッジベースに制約されており、制約のない生成と比較してハルシネーションリスクを大幅に制限します。しかし「制約されている」は「免疫がある」を意味しません。3つの失敗モード。
検索失敗。 システムが間違ったドキュメントを検索し、無関係なコンテンツに基づいて自信を持って回答します。「ドイツでの育児休業ポリシーは何ですか?」と尋ねて、システムが代わりに米国のポリシーを検索する場合、尤もらしく見える引用を伴って自信を持って間違った回答が返ってきます。
ギャップの補填。 検索されたドキュメントが質問に完全に答えていない場合、一部のモデルは「分かりません」と言う代わりに一般知識でギャップを埋めます。ユーザーは正確な検索コンテンツとハルシネーションした追加情報が混在した回答を受け取ります。
引用のハルシネーション。 モデルはナレッジベース内のドキュメントへの引用を生成しますが、そのドキュメントは実際には主張された文を述べていません。これはハルシネーションが検証済みに見えるため特に有害です。
RAGの緩和策はモデルの品質ではなく検索の品質です。検索が悪いより優れたモデルは依然として間違った回答を生成します。四半期ごとのナレッジベース監査、ユーザーへの信頼度スコアの表示、外部配布前の人間レビューが運用上のコントロールです。
Workflow Copilot: 中
Workflow Copilotのハルシネーションリスクは、モデルが疎または曖昧なコンテキストから下書きする時に最も高くなります。CRMレコードが「デモ完了」以外何も示していない状態でフォローアップメールを下書きするコパイロットは、欠落しているコンテキストを尤もらしいが発明した詳細で埋めます。「Q2のタイムラインについての議論のフォローアップです」Q2のタイムラインが議論されていない場合。
リスクはコパイロットの提案が受け取る人間レビューの量に比例してスケールします。担当者が読まずに提案を一括承認している場合、アウトバウンドコミュニケーションのハルシネーション率はコパイロットの生成エラー率であり、ゼロではありません。ガバナンスのレバーは提案承認の品質指標です。承認率だけでなく承認された提案の正確さを追跡します。
Document Review: 中
Document Reviewは特定の危険な方法でハルシネーションします。ドキュメントにない条項にフラグを立てるか、存在する条項を見落とします。ここでのコンテキストのハルシネーションは、モデルが見つかることを期待した(同様の契約書のトレーニングに基づく)が提出されたドキュメントには実際には存在しない条項の逸脱フラグを生成することを意味します。
アウトプットがレビューなしに配布される場合、リスクは高くなります。法律チームがAIフラグをプライマリレビューとして信頼し、全文書を読まない場合、ハルシネーションしたフラグは何もない場所に基づく作業を生み出すか、実際の条項が確認されたという誤った安心感を提供する可能性があります。
緩和策はDocument Reviewのアウトプットを法的意見ではなくトリアージツールとして扱うことです。フラグに基づくアクションが実行される前に人間の弁護士がレビューします。AIが何を見るべきかをキャッチします。弁護士が確認します。
Generative Research: 高
これは大差でハルシネーションの最も高リスクなパターンです。理由は構造的です。
混同を伴う複数ソースの統合。 モデルは多くのソースから引き出してそれらを一貫したナラティブに統合しています。ソースが矛盾する場合、またはそれらの間にギャップがある場合、モデルはどの実際のソースでも支持されないかもしれない尤もらしい統合で埋めます。
ライブソースのギャップ。 調査プロンプトが最近の出来事(直近30日)をカバーし、インデックスされたソースが古い場合、モデルは実際には外挿である自信に満ちたように聞こえるコンテンツで最近性のギャップを埋めます。
キャッチするためのグランドトゥルースがない。 RAG(既知のドキュメントに制約)やVision Extract(物理的なドキュメントに制約)とは異なり、Generative Researchはオープンなコーパスにまたがって動作します。「Xであるはず」という期待はグランドトゥルースに対して確認するのがはるかに難しいです。
現実的な失敗の例: Generative Researchシステムが競合他社の最近の製品ローンチについての競合インテリジェンスブリーフを生成します。ブリーフには価格の詳細と顧客の引用が含まれています。価格は6カ月前のプレスリリースから外挿され、現在は間違っています。顧客の引用はインデックスされたコンテンツの実際の引用のスタイルから捏造されています。両方が信頼できるように見えます。ブリーフはそれに基づいてポジショニングの決定を行うエグゼクティブに届きます。ポジショニングは現在の市場に対して間違っています。
緩和策: 配布されるあらゆるGenerative Researchのアウトプットに対して、プライマリソースに対する必須の人間によるファクトチェック。これはシステムが信頼できるように見えるかどうかに基づいて任意ではありません。システムの品質に関係なく、パターンのポリシー要件です。完全な緩和策についてはGenerative Researchパターン記事をご覧ください。
Autonomous Agent: 高
Autonomous Agentは複数のケイパビリティループを順番に実行します。ハルシネーションリスクは繰り返しをまたいで複合します。
エスカレーションの仕方: ループ1でエージェントは顧客リクエストを取り込んで分析を生成します(中程度のハルシネーションリスク)。ループ2でエージェントはその分析を使って計画を生成します(中程度のリスク、現在は潜在的にハルシネーションした分析に基づいている)。ループ3でエージェントは計画に基づいてステップを実行します(潜在的に複合したハルシネーションに基づくExecuteステップ)。ループ5または6までに、エージェントは正確ではなかった前提に基づいて取り消し不可能な外部アクションを実行しているかもしれません。
特定のタイプの複合エラー: エージェントがループ1でファクトをハルシネーションし、ループ2でそれを確立されたものとして参照し、ループ3でそれを基に構築し、ループ4までにハルシネーションがエージェントの作業コンテキストの一部になり、自己強化しています。これは単一ショットのハルシネーションよりもキャッチが難しいです。なぜならエラーが内部的に一貫しているように見えるからです。
このレベルでの検出は最終的なアウトプットだけでなく、中間の推論ステップの検査を必要とします。外部のExecuteアクションの前に、人間のチェックポイントが全チェーンをレビューします。エージェントは何を結論づけたか、何に基づいて、そのチェーンは精査に耐えるか?
「Autonomous Agentはループの繰り返しをまたいでハルシネーションを複合します。ループ1でハルシネーションされたファクトはループ3までに作業コンテキストの一部になります。ループ5までに、エージェントは正確ではなかった前提に基づいて取り消し不可能な外部アクションを実行しているかもしれません。これを検出するには最終的なアウトプットだけでなく中間の推論ステップの検査が必要です。」(Rework Autonomous Agent Implementation Analysis, 2026)
「RAGはベースモデルを変えることなく、検索されたコンテキストにアウトプットを接地するだけでハルシネーション率を40〜60%削減します。エンタープライズのハルシネーションリスクに対する最も効果的な介入はモデルの選択ではありません。検索アーキテクチャです。」(arXiv Comprehensive Survey on LLM Hallucinations, 2024)
ハルシネーションリスクティア
ハルシネーションリスクティアは、各AIパターンにリスクレベル(非常に低い、低〜中、中、高)を割り当てるパターン分類フレームワークであり、2つの要素に基づいています。パターンのGenerateケイパビリティがオープンエンドの自然言語(高リスク)を生成するか、数字や構造化フィールドのような制約されたアウトプット(低リスク)を生成するか、そしてエラーが実行ループをまたいで複合するか(Autonomous Agentの複合リスク、単一パスパターンの独立リスク)です。ティア評価は最小限のHITLチェックポイント要件を決定します。非常に低いパターンには必須レビューは不要で、中程度のパターンは外部配布前の人間レビューが必要で、高リスクのパターンは外部アクションを促すすべてのアウトプット前のレビューが必要です。
Rework Analysis: arXivのハルシネーション調査でRAGが単一最も効果的な緩和技術であるという発見と、グラウンディングなしの法律ドメインクエリで69〜88%のハルシネーション率を示す本番ベンチマークに基づき、ハルシネーションリスクティアフレームワークはプライマリなリスク削減レバーとしてモデル選択よりもグラウンディングアーキテクチャを優先します。Reworkの実装データは、ティアフレームワークをパターン選択中に適用するチームが、すべてのパターンにわたってハルシネーションを均一なリスクとして扱うチームと比較して最初の1年間でハルシネーション関連のインシデントを平均73%削減することを示しています。
実際に機能する緩和戦略
グラウンディング。 モデルを特定のソース材料に結び付けます。RAGはナレッジベースに制約します。Vision Extractは物理的なドキュメントに制約します。Meeting Intelligenceは音声文字起こしに制約します。生成コンテキストが制約されるほどハルシネーション率は低くなります。制約のない生成(Generative Research、Autonomous Agentの計画)は比例してより強い人間レビューが必要です。
信頼度の閾値。 低信頼度のアウトプットを通過させるのではなくレビューのためにフラグを立てます。これはシステムが実際にキャリブレーションされた信頼度スコアを生成することを必要とします。すべてのシステムがそうするわけではありません。信頼度スコアが利用可能な場合、不確かなアウトプットをアクションの前に人間レビューにルーティングする閾値を設定します。利用できない場合、それは製品選択の基準です。
構造化された出力フォーマット。 可能な限り定義されたスキーマに生成を制約します。「このJSONフォーマットでこれら5つのフィールドを抽出する」は「このドキュメントを要約する」よりハルシネーションリスクが低いです。構造化フォーマットはモデルがコンテンツを発明する自由度を減らし、出力フォーマットの自動検証を容易にします。
高リスクの引き渡し時のHuman-in-the-loop。 Executeの境界がハルシネーションが実際の損害を引き起こす場所です。ドラフトレビューキューに残るハルシネーションは迷惑です。メールを送信するか、財務記録を更新するか、ミーティングをスケジュールするハルシネーションは負債です。取り消し不可能なExecuteステップの前のHITLチェックポイントが最後の防衛ラインです。これらのチェックポイントが属する場所についてはリスクグラデーションをご覧ください。
機能しないもの
「モデルにハルシネーションしないよう伝えるだけ」。 「確信していることだけを述べる」「でたらめを言わない」のような指示は、一部の設定でハルシネーション率を控えめに削減し、他の設定ではほぼ効果がありません。言語モデルは最も確率の高い次のトークンを生成します。ハルシネーションしていることを「知り」ません。指示は動作をわずかに変えることができますが、基礎となるメカニズムを排除することはできません。
完全な解決策としての温度の低下。 低温度設定はより予測可能で創造性の低いアウトプットを生成します。より事実に忠実なアウトプットは生成しません。低温度モデルは創造的にではなく自信を持って一貫してハルシネーションします。場合によっては、低温度はアウトプットがより均一で明らかに間違っていないためハルシネーションをキャッチしにくくします。
より高価なモデルがハルシネーションリスクを排除するという前提。 より有能なモデルは多くのタスクでハルシネーションが少ないです。しかしarXivのLLMハルシネーションに関する包括的調査が文書化しているように、現在のすべてのモデルはハルシネーションします。この分野は「ゼロを目指す」から「不確実性を管理する」に移行しました。高リスクのGenerative ResearchまたはAutonomous Agentの導入に対して、問題は「どのモデルか?」ではありません。「どのモデルを使用するかに関係なく、どのような人間レビューのプロセスが存在するか?」です。
ハルシネーションが実際の損害を引き起こした場合
ハルシネーションのインシデントに対する組織の対応には特定の順序があります。
封じ込め。 ハルシネーションされたアウトプットのさらなる伝播を止めます。外部の関係者に届いた場合、彼らが何を受け取ったか、修正が必要かどうかを評価します。
後方への監査。 全チェーンをトレースします。システムは何を生成したか、どの入力と検索結果に基づいて、どのガバナンスチェックポイントが設置されていたか? この監査が根本原因を確立します。
失敗の分類。 これは検索失敗(間違ったドキュメントが検索された)、ギャップ補填失敗(欠落しているコンテキストが発明で埋められた)、複合失敗(多段階のエラー)のどれか? 分類が修正を決定します。
パターン設定の修正。 検索失敗はナレッジベースの更新と検索品質の改善で修正します。ギャップ補填失敗はより強いグラウンディング制約または低温度で修正します。複合失敗は以前のループの繰り返しでの追加HITLチェックポイントを必要とします。
ガバナンスの調整。 インシデントは既存のチェックポイントのギャップを明らかにします。次の導入イテレーションの前にこの失敗をキャッチしたであろうチェックポイントを追加します。
コミュニケーション。 ハルシネーションされたアウトプットに依存した内部ステークホルダーは、何が間違っていたか、何が修正されたかを知る必要があります。ハルシネーションのインシデント後の信頼の回復は、技術的なプロジェクトだけでなくコミュニケーションのプロジェクトです。
高ハルシネーションリスクのパターンはより厳格なHITLチェックポイントを必要とします。これがパターン別のガバナンス要件への直接的なつながりです。ガバナンス構造はAIを信頼しないことについてではありません。どのパターンがより多くのチェックポイントを必要とするかを知り、何かがうまくいく前にそれらをワークフローに組み込むことです。
目標はハルシネーションの可能性があるためAIを避けることではありません。リスクプロファイルに比例した検出と緩和を持つパターンを導入することです。ほとんどのパターンは、ほとんどの時間、許容可能な範囲内で動作しています。それを確認し、例外がインシデントになる前にキャッチするガバナンスを構築してください。
よくある質問
ハルシネーションリスクティアとは何ですか?
ハルシネーションリスクティアは、各AIパターンに非常に低い、低〜中、中、高のリスクを分類します。Generateケイパビリティがオープンエンドの自然言語(高リスク)を生成するか、数字やフィールドのような制約されたアウトプット(低リスク)を生成するか、エラーがループをまたいで複合するかに基づきます。ティア評価は最小限のHITL要件を決定します。非常に低いパターンは必須レビューが不要で、中程度のパターンは外部配布前のレビューが必要で、高リスクのパターンは外部アクションを促すすべてのアウトプット前のレビューが必要です。
どのAIパターンがハルシネーションに最も免疫がありますか?
Scoring and RoutingとAnomaly Agentは、自然言語ではなく確率的な数値アウトプットを生成するためほぼ免疫があります。「Leadスコア: 73」と「トランザクション異常: 信頼度99.2%」は従来の意味でハルシネーションできません。それらの失敗モードはキャリブレーション誤りとドリフトであり、捏造ではありません。Personalization Engineもコンテンツを生成するのではなく選択するため低リスクです。
エンタープライズAIのハルシネーションに対する最も効果的な緩和策は何ですか?
RAGグラウンディングが最も効果的な単一の構造的緩和策であり、ドメイン全体でハルシネーション率を30〜70%削減し、検索品質が高い場合は要約タスクで2%未満まで低下させます。これは生成をオープンエンドの統合ではなく特定のソース材料に制約することで機能します。重要な洞察は、最も効果的な介入がモデル選択ではなく検索アーキテクチャだということです。検索が悪いより優れたモデルは依然として間違った回答を生成します。
ドメインによってハルシネーション率はどう異なりますか?
ドメイン固有のハルシネーション率は、トップクラスのモデルでも大幅に異なります。一般知識のクエリはトップモデルで1%未満のハルシネーション率です。しかし法律ドメインのクエリは高リスクな状況で69〜88%のハルシネーション率を示します。医療AIはプロンプトの品質に応じて43〜64%の率を示します。示唆: 法律、医療、またはコンプライアンスドメインのエンタープライズAI導入は、一般知識アプリケーションよりも大幅に厳格なグラウンディングとHITLガバナンスが必要です。
より高価なモデルを使用するとハルシネーションリスクがなくなりますか?
いいえ。より有能なモデルは多くのタスクでハルシネーションが少ないですが、現在のすべての本番モデルはまだハルシネーションします。arXivの包括的調査は、この分野が「ゼロを目指す」から「不確実性を管理する」に移行したことを文書化しています。高リスクドメインでのGenerative ResearchとAutonomous Agentの導入に対して、問題はどのモデルを使用するかではなく、どのモデルを選択するかに関係なくどのような人間レビュープロセスが存在するかです。モデル選択は二次的な変数です。グラウンディング、構造化された出力フォーマット、HITLチェックポイントがプライマリです。
Autonomous Agentにとって最も危険なハルシネーションの失敗モードは何ですか?
ループの繰り返しをまたいだ複合ハルシネーション。ループ1でハルシネーションされたファクトはエージェントの作業コンテキストの一部になり、ループ3までに確立されたものとして扱われます。ループ5または6までに、エージェントは正確ではなく現在はエージェントの推論チェーン内で自己強化しているように見える前提に基づいて取り消し不可能な外部アクションを実行しているかもしれません。これはエラーが自己強化的に見えるため単一ショットのハルシネーションよりもキャッチが難しいです。緩和策は最終的なアウトプットのレビューだけでなく、すべてのループの繰り返しでの中間推論ステップの検査です。
関連リンク

Co-Founder, Rework.com
On this page
- ビジネスコンテキストでのハルシネーションとは何か
- パターン別のハルシネーションリスク
- Scoring and Routing: 非常に低い
- Anomaly Agent: 非常に低い
- Vision Extract: 低〜中
- Meeting Intelligence: 低〜中
- Personalization Engine: 低
- RAG Assistant: 中
- Workflow Copilot: 中
- Document Review: 中
- Generative Research: 高
- Autonomous Agent: 高
- ハルシネーションリスクティア
- 実際に機能する緩和戦略
- 機能しないもの
- ハルシネーションが実際の損害を引き起こした場合
- 関連リンク