Pattern-Abhängigkeiten und Voraussetzungen
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Der häufigste Grund, warum ein AI-Pattern nach dem Einsatz scheitert, ist eine fehlende Voraussetzung, die niemand überprüft hat.
Nicht das falsche Modell. Nicht der falsche Anbieter. Nicht das falsche Pattern. Eine Datenabhängigkeit, die niemand geprüft hat. Ein API-Zugriff, der vorausgesetzt, aber nicht bestätigt wurde. Eine Wissensbasis, die als Ordner mit Dokumenten existiert, aber keine Embedding-Pipeline, keine Aktualisierungsfrequenz und keinen Verantwortlichen hat.
Das Pattern wird gebaut. Die Integration wird abgeschlossen. Und dann, in der dritten Testwoche, fragt jemand, wo die historischen Ergebnisdaten für das Scoring-Modell sind, und stellt fest, dass sie nie in einem strukturierten Format gesammelt wurden. Oder die Audioaufnahmen für Meeting Intelligence existieren, sind aber in einem Anbietersystem gespeichert, das keine Export-API hat. Oder die Wissensbasis, aus der der RAG (Retrieval-Augmented Generation) Assistant antworten sollte, ist 18 Monate veraltet und bei zwei Produktlinien völlig falsch.
Diese Entdeckungen töten keine AI-Projekte. Sie verzögern sie um drei bis sechs Monate und verbrauchen das Vertrauen, das die Pilotphase aufbauen sollte. McKinseys Forschung zur Skalierung agentischer AI mit Datentransformationen zeigt, dass acht von zehn Unternehmen Datenbeschränkungen als primäres Hindernis für die Skalierung von AI nennen, nicht Modellqualität oder Anbieterauswahl.
Dieser Artikel kartiert die Abhängigkeiten nach Pattern, geht eine reale Einsatzsequenz durch und gibt Ihnen eine Voraussetzungs-Audit-Checkliste, die Sie vor jeder Implementierungsentscheidung ausführen sollten. Für das umfassendere Bild der Datenbereitschaft vor dem Start eines AI-Projekts ist Datenbereitschaft: Die Voraussetzung, die die meisten AI-Projekte überspringen der richtige Ausgangspunkt.
Arten von Abhängigkeiten
Drei Kategorien decken die Abhängigkeitslandschaft ab:
Datenabhängigkeiten: Welche Daten müssen vorhanden, korrekt strukturiert und zugänglich sein, bevor das Pattern betrieben werden kann? Dies ist die am häufigsten übersehene Kategorie. Teams setzen voraus, dass Daten vorhanden sind, weil sie gesammelt wurden. Aber Vorhandensein ist nicht dasselbe wie Zugänglichkeit, Struktur oder Qualität. Die 7 Datentypen, die Business-AI antreiben umreißt die vollständige Landschaft.
Infrastrukturabhängigkeiten: Welche Systeme, Pipelines, APIs und Rechenressourcen müssen vorhanden sein, damit das Pattern Eingaben verarbeiten, speichern und Ausgaben liefern kann? Engineering-Teams kalkulieren diese häufig, aber Business- und Programmverantwortliche unterschätzen sie oft. Eine Embedding-Pipeline für RAG, ein CRM-Webhook für Scoring and Routing und eine Audio-Verarbeitungspipeline für Meeting Intelligence sind jeweils nicht triviale Engineering-Investitionen.
Pattern-Abhängigkeiten: Einige Patterns erfordern, dass ein anderes Pattern zuerst betrieben wird, weil das nachgelagerte Pattern Daten verbraucht, die das vorgelagerte Pattern produziert. Meeting Intelligence produziert die strukturierten Gesprächsdaten, die Workflow Copilot für CRM-Nächste-Aktion-Vorschläge verwendet. Wenn Meeting Intelligence nicht läuft, hat der Workflow Copilot nichts, worauf er Vorschläge basieren kann.
Wichtige Fakten: Voraussetzungsfehler bei AI
- 85 % der gescheiterten AI-Projekte nennen schlechte Datenqualität als Hauptursache, laut RAND-Corporation-Analyse von über 2.400 Enterprise-AI-Initiativen.
- Gartners 2025-Forschung prognostiziert, dass 60 % der AI-Projekte ohne AI-bereite Daten vor dem Abschluss aufgegeben werden.
- Nur 12 % der Unternehmen haben Daten von ausreichender Qualität, um AI-Anwendungen ohne eine erhebliche Vorbereitungsphase zu unterstützen. (MIT Project NANDA, 2025)
Abhängigkeitskarte nach Pattern
| Pattern | Datenabhängigkeiten | Infrastrukturabhängigkeiten | Häufige Pattern-Abhängigkeiten |
|---|---|---|---|
| RAG Assistant | Gepflegte Wissensbasis (Richtlinien, SOPs, Produktdokumente, gelöste Tickets); in einer Vektordatenbank eingebettet | Vektordatenbank; Embedding-Pipeline; Dokumentenaufnahme- und Aktualisierungspipeline | Keine (läuft oft zuerst) |
| Scoring + Routing | Historische Datensätze mit beschrifteten Ergebnissen (geschlossen gewonnen/verloren, gelöst/eskaliert, eingestellt/abgelehnt); strukturierte Merkmalsfelder pro Datensatz | CRM oder Ticketsystem mit Webhook-Unterstützung; Modelltraining- und Neutrainingsinfrastruktur; Routing-Regelwerk | Keine (kann als erstes Pattern eingesetzt werden) |
| Vision Extract | Trainingsbilder oder annotierte Scan-Beispiele für den Zieldokumenttyp; Zugriff auf die Quelldokumente in digitaler oder physischer Form | Bildaufnahmepipeline; OCR- oder Vision-Modell-API; Ziel-System of Record mit Schreibzugriff | Keine (läuft oft eigenständig) |
| Meeting Intelligence | Audio- oder Videoaufnahmen mit ausreichender Qualität; Gesprächsmetadaten (Teilnehmer, Datum, Kontext) | Audio/Video-Speichersystem; Speech-to-Text-API; strukturierter Ausgabespeicher, der mit nachgelagerten Systemen verbunden ist | Keine (läuft oft zuerst in Sales/Support-Stacks) |
| Anomaly Agent | Mindestens 60-90 Tage Basisdaten für die überwachte Metrik; konsistente Datenerfassungsfrequenz | Echtzeit- oder nahezu echtzeitiger Datenstrom; Benachrichtigungs- und Alarmierungspipeline; Eskalationsrouting | Hängt häufig von Scoring + Routing für die Basisdatenerfassung ab |
| Generative Research | Zugängliche Quellen (Web, internes Corpus, Nachrichtenfeeds); Klarheit über Inhaltslizenzierung für interne Weiterverbreitung | Web-Zugriff oder interne Corpus-Such-API; Quellenzitiersystem | Keine, aber Ausgabequalität verbessert sich mit RAG Assistant für interne Quellen |
| Document Review | Beispieldokumente, die typische Fälle repräsentieren; Standard oder Vorlage zum Vergleich | Dokumentenparser; Vergleichsmodell; strukturiertes Ausgabeformat kompatibel mit nachgelagerten Systemen | Keine |
| Workflow Copilot | Nutzerkontextdaten in Echtzeit (aktueller Datensatz, letzte Aktivität); System of Record des Nutzers | Tiefe Integration in das primäre Arbeitstool des Nutzers (CRM, IDE, Marketingplattform); Low-Latency-Inferenzendpunkt | Hängt häufig von Meeting Intelligence oder Scoring + Routing für umfangreichen Kontext ab |
| Personalization Engine | Nutzerverhaltensdaten (mindestens 5-10 Interaktionen pro Nutzer für nützliche Personalisierung); Produktkatalog oder Inhaltsbibliothek | Echtzeit-Ereigniserfassung; Profildatenspeicher; Content-Delivery-System mit Unterstützung für dynamisches Rendering | Keine eigenständig; funktioniert besser mit Anomaly Agent für Churn-Signal-Integration |
| Autonomous Agent | Alle Tools, die der Agent verwenden muss, müssen über getestete APIs zugänglich sein; Rollback- oder Rückgängig-Funktion für jeden irreversiblen Aktionstyp | Tool-Registry mit getesteten Schemas; Durchsetzung der maximalen Schrittzahl; Audit-Log-System; Eskalationspfad | Hängt vom spezifischen Ziel ab; häufig von Scoring + Routing für Triage und von RAG für Wissensaccess |
"Unternehmensprogramme, die 50-70 % ihrer AI-Projektzeitlinie für Datenbereitschaft einplanen, einschließlich Extraktion, Normalisierung, Governance-Metadaten und Qualitätsprüfungen, erreichen eine 3-mal höhere Produktionseinsatzrate als Programme, die mit der Modellarbeit beginnen, bevor das Datenfundament bestätigt ist." (Integrate.io Data Transformation Report, 2026)
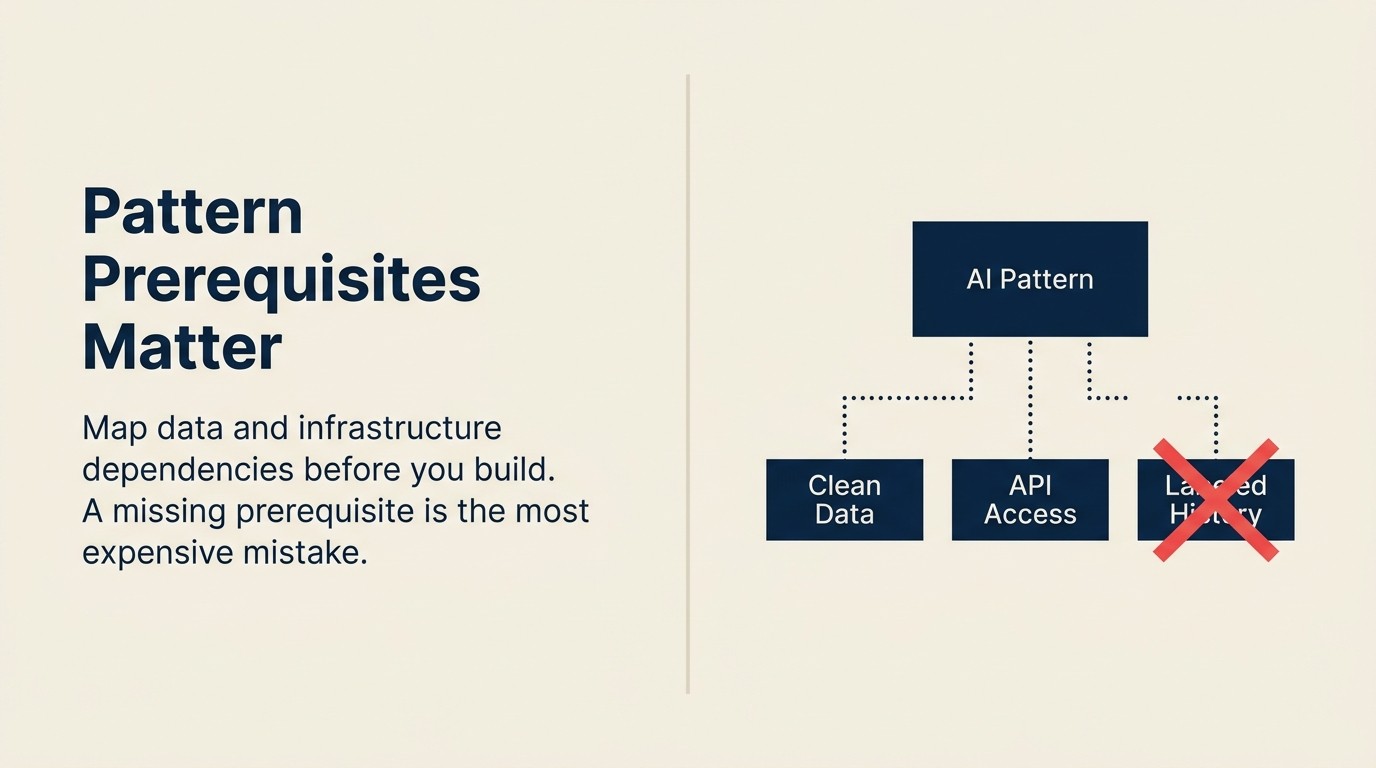
Die Pattern Dependency Map
Die Pattern Dependency Map ist eine Voraussetzungs-Audit-Struktur, die jedes AI-Pattern vor der Implementierung entlang drei Achsen kategorisiert: Datenabhängigkeiten (welche strukturierten Daten müssen vorhanden und zugänglich sein), Infrastrukturabhängigkeiten (welche Pipelines, APIs und Rechenressourcen müssen vorhanden sein) und Pattern-Abhängigkeiten (welche vorgelagerten Patterns müssen Daten produzieren, bevor dieses sinnvoll getestet werden kann). Die Ausführung der Map vor jeder Bauentscheidung eliminiert die drei- bis sechsmonatigen Verzögerungen, die das Vertrauen aus der Pilotphase zerstören, wenn fehlende Voraussetzungen mitten in der Integration auftauchen.
Rework-Analyse: Basierend auf McKinseys Erkenntnis, dass acht von zehn Unternehmen Datenbeschränkungen als primäres AI-Skalierungshindernis nennen, und auf bestätigenden Daten der RAND Corporation (85 % der gescheiterten AI-Projekte nennen Datenqualität als Grundursache), stellt die Pattern Dependency Map die einzelne Investition mit dem höchsten Ertrag in jedem AI-Projekt dar. Reworks Implementierungserfahrung zeigt, dass Teams, die ein formales Voraussetzungs-Audit vor dem Baubeginn abschließen, ihre Time-to-Production um durchschnittlich 11 Wochen verkürzen, verglichen mit Teams, die Abhängigkeiten während des Integrationstests entdecken.
Der kritische Pfad: Einsatzsequenz des AI Sales Operator
Ein Unternehmen möchte einen AI Sales Operator einsetzen, der Meeting Intelligence, Scoring and Routing, RAG Assistant und Workflow Copilot kombiniert. Hier ist die abhängigkeitsgesteuerte Reihenfolge:
Phase 1 (parallel, Wochen 1-4)
Diese parallel ausführen, da keine von der anderen abhängt:
Scoring-and-Routing-Setup: Exportieren Sie historische CRM-Datensätze mit Ergebnis-Labels (geschlossen gewonnen/geschlossen verloren, qualifiziert/disqualifiziert). Mindestens 6 Monate beschrifteter Daten, idealerweise 12. Trainieren Sie das anfängliche Scoring-Modell. Konfigurieren Sie das Routing-Regelwerk. Testen Sie auf einem Holdout-Set, bevor Sie live gehen.
Meeting-Intelligence-Setup: Bestätigen Sie den Audio-Speicherzugriff und die Formatkompatibilität. Richten Sie die Speech-to-Text-Pipeline ein. Definieren Sie das strukturierte Ausgabe-Schema: welche Felder (Aktionspunkte, Einwände, Phasensignal, Stimmung) fließen in welche nachgelagerten Systeme. Testen Sie mit 20 aufgezeichneten Gesprächen vor dem Produktivbetrieb.
Phase 2 (sequenziell, Wochen 5-8)
Diese hängen von Phase-1-Ausgaben ab:
RAG-Assistant-Setup: Erfordert eine gepflegte Wissensbasis. Überprüfen Sie vorhandene Dokumentation. Identifizieren Sie, was aktuell vs. veraltet ist. Weisen Sie für jede Dokumentkategorie einen Verantwortlichen zu. Bauen Sie die Embedding-Pipeline. Chunken und embedden Sie die Wissensbasis. Richten Sie eine Aktualisierungsfrequenz ein (wöchentlich für sich schnell ändernde Dokumente, monatlich für stabile Richtlinien).
Workflow-Copilot-Integration: Erfordert, dass Meeting Intelligence strukturierte Ausgaben produziert (damit es Gesprächskontext hat, auf den es reagieren kann) und erfordert, dass Scoring and Routing läuft (damit das Prioritätssignal den Copilot speist). Die Copilot-Konfiguration kann in Phase 1 als Build-Aufgabe beginnen, kann aber erst sinnvoll getestet werden, wenn die vorgelagerten Patterns Daten produzieren.
Phase 3 (Wochen 9-12)
Vollständige Stack-Tests. Führen Sie alle vier Patterns zusammen mit einer Pilotgruppe von 10-15 Vertriebsmitarbeitern aus. Messen Sie separat: Produziert Meeting Intelligence genaue Zusammenfassungen? Leitet Scoring and Routing korrekt weiter? Zeigt der RAG Assistant relevante Dokumente an? Wird der Workflow Copilot von Vertriebsmitarbeitern angenommen oder ignoriert? Beheben Sie auf Pattern-Ebene, bevor Sie den Stack anpassen.
Diese Sequenzierung ist nicht optional. Teams, die versuchen, alle vier Patterns gleichzeitig zu bauen, entdecken beim Integrationstest, dass die vorgelagerten Patterns nicht bereit waren, und die nachgelagerten müssen überarbeitet werden.
"Scoring-Modelle, die ohne ergebnis-beschriftete historische Daten eingesetzt werden, produzieren Scores, die nicht mit tatsächlichen Ergebnissen korrelieren. Hoch bewertete Leads scheitern beim Abschluss mit der erwarteten Rate. Das Scoring sieht aktiv aus, ist aber Rauschen. Die Grundursache sind Merkmalsdaten und Ergebnisdaten, die in separaten Systemen existieren und vor dem Modelltraining nie zusammengeführt wurden." (Folio3 AI Enterprise Pattern Analysis, 2026)
Häufige Voraussetzungsfehler nach Pattern
RAG Assistant ohne gepflegte Wissensbasis eingesetzt. Symptom: Der Assistant gibt selbstsichere Antworten, die 18 Monate veraltet sind. Nutzer vertrauen der Antwort, handeln danach, stellen fest, dass sie falsch ist. Die Grundursache ist eine einmal aufgebaute und nie aktualisierte Wissensbasis. Nach drei Monaten hat sich die Produktdokumentation geändert, Richtlinien wurden aktualisiert, und der RAG Assistant zitiert veralteten Inhalt. Lösung: Die Wissensbasis muss einem Verantwortlichen zugewiesen sein, bevor der RAG Assistant eingesetzt wird. Jede Dokumentkategorie hat einen namentlich genannten Verantwortlichen für Aktualisierungen. Die Embedding-Aktualisierungsfrequenz wird durch einen geplanten Job durchgesetzt, nicht durch manuelle Eingriffe.
Scoring and Routing ohne beschriftete historische Ergebnisdaten eingesetzt. Symptom: Das Scoring-Modell gibt Scores aus, die nicht mit tatsächlichen Ergebnissen korrelieren. Hoch bewertete Leads schließen nicht ab. Niedrig bewertete Leads konvertieren. Das Scoring sieht aktiv aus, ist aber im Wesentlichen Rauschen. Die Grundursache ist entweder keine historischen Ergebnisdaten oder Ergebnisdaten, die in einem System existieren, und Merkmalsdaten, die in einem anderen existieren, nie zusammengeführt. Lösung: Vor dem Training jedes Scoring-Modells validieren, dass der historische Datensatz konsistente Ergebnis-Labels hat und dass die für das Scoring verwendeten Merkmalsfelder in über 80 % der Datensätze ausgefüllt sind.
Anomaly Agent ohne Basisperiode eingesetzt. Symptom: Der Agent feuert Alarme auf alles oder nichts. Das Modell hat keine Basis zum Vergleich, also behandelt es entweder alle Variation als anomal oder lernt eine Basis aus zu wenig Daten, die die reale Verteilung nicht repräsentiert. Lösung: 60 bis 90 Tage Basisdaten sammeln, bevor die Anomalieerkennung aktiviert wird. Das Modell im Shadow-Modus während der Basisdatenerfassung betreiben: protokollieren, was es markiert hätte, mit tatsächlichen Ergebnissen vergleichen, Schwellenwert vor dem Live-Gang kalibrieren.
Autonomous Agent ohne getestete Tool-APIs eingesetzt. Symptom: Der Agent läuft, ruft ein Tool auf, empfängt ein unerwartetes Antwortformat und schleift entweder unendlich oder nimmt eine unbeabsichtigte Aktion basierend auf fehlerhaftem Parsing vor. Die Grundursache sind Tool-Schemas, die beschrieben, aber nicht auf API-Ebene getestet wurden. Lösung: Jedes Tool, auf das der Agent Zugriff hat, isoliert testen, bevor der Agent eingesetzt wird. Überprüfen, dass das Antwortformat den Erwartungen des Agenten entspricht. Fehler-Zweige für jeden Fehlerfall eines Tools erstellen, bevor der erste Produktionslauf stattfindet.
Datenbereitsschafts-Audit-Checkliste
Führen Sie diese vor der Genehmigung jeder Pattern-Implementierung aus:
Datenverfügbarkeit
- Die erforderlichen Daten sind vorhanden und für das System zugänglich, das Sie bauen
- Zugriffsberechtigungen sind bestätigt (nicht vom Organigramm vorausgesetzt)
- Datenvolumen ist ausreichend (Mindestanzahl von Datensätzen für Training, Embedding oder Basisdaten)
Datenqualität
- Ergebnis-Labels existieren und sind genau für Patterns, die sie erfordern (Scoring, Anomalie)
- Schlüsselfelder haben eine Ausfüllrate von über 80 % (nicht größtenteils leer oder null)
- Keine systematischen Verzerrungen im Trainingsset, die Modellausgaben verzerren würden
Das NIST AI Risk Management Framework identifiziert Genauigkeit, Vollständigkeit, Konsistenz, Gültigkeit, Eindeutigkeit und Aktualität der Daten als die sechs primären Dimensionen, die bestimmen, ob AI-Systeme vertrauenswürdige Ausgaben produzieren. Jedes Element in dieser Checkliste entspricht einer oder mehreren dieser Dimensionen.
Datenaktualität
- Daten sind aktuell genug, um relevant zu sein (veraltete Daten sind für einige Patterns schlimmer als keine Daten)
- Eine Aktualisierungsfrequenz ist definiert und hat einen Verantwortlichen, wird nicht vorausgesetzt
- Alte Daten jenseits eines nützlichen Horizonts werden ausgeschlossen oder heruntergewichtet
Infrastrukturbereitschaft
- Aufnahmepipeline ist gebaut und getestet
- Speicher und Rechenressourcen sind bereitgestellt
- API-Endpunkte sind mit korrekten Berechtigungen zugänglich bestätigt
- Latenzanforderungen werden durch die Infrastrukturkonfiguration erfüllt
Governance
- Datennutzung ist durch Nutzungsbedingungen oder Nutzerzustimmung abgedeckt
- PII-Behandlung ist definiert und entspricht der geltenden Regulierung
- Prüfpfad ist für alle Execute-Pfad-Ausgaben vorhanden
Wenn ein Kontrollkästchen nicht angekreuzt ist, ist das Pattern nicht bereit für den Einsatz. Das fehlende Element ist eine Voraussetzung, kein nettes Extra.
Infrastrukturvoraussetzungen, die Teams verpassen
Embedding-Pipeline für RAG. Das ist nicht "laden Sie Ihre Dokumente in das Tool hoch." Es ist eine geplante Pipeline, die: neue oder aktualisierte Dokumente liest, sie nach Abschnitt aufteilt, Embeddings mit derselben Modellversion wie der Abruf-Endpunkt generiert, in die Vektordatenbank schreibt und gelöschte oder überholte Dokumente durch Entfernen ihrer Embeddings behandelt. Diese Pipeline ist eine Engineering-Investition. Sie als "der Anbieter kümmert sich darum" einzustufen bedeutet normalerweise, dass sie nicht tatsächlich läuft, weshalb die Wissensbasis veraltet.
CRM-Webhooks für Scoring and Routing. Das Scoring-Modell muss immer dann ausgeführt werden, wenn sich ein relevanter Datensatz ändert. Das erfordert CRM-Webhooks, die so konfiguriert sind, dass sie bei den richtigen Ereignissen feuern (Lead erstellt, Deal-Phase aktualisiert, Kontaktinformationen geändert). Viele CRM-Implementierungen haben verfügbare, aber nicht konfigurierte Webhooks. Das ist eine Drei-Tage-Engineering-Aufgabe, die das gesamte Scoring-Pattern blockiert, wenn sie versäumt wird.
Audio-Verarbeitungspipeline für Meeting Intelligence. Aufnahmen müssen: mit ausreichender Qualität aufgenommen werden (mindestens 16 kHz Mono), zugänglich gespeichert werden, dem richtigen Teilnehmer und Deal-Metadaten zugeordnet sein, und in einem angemessenen Zeitfenster nach dem Ende des Gesprächs verarbeitet werden. Wenn Aufnahmen in einem Anbietersystem gespeichert sind, das keine Export-API hat, oder wenn die Qualität für eine genaue Transkription zu niedrig ist, kann das Pattern nicht ausgeführt werden. Das ist eine physische Infrastruktureinschränkung, die keine Modellqualität lösen kann.
| Voraussetzungsfehlertyp | Am meisten betroffene Patterns | Typischer Entdeckungszeitpunkt | Durchschn. verursachte Verzögerung |
|---|---|---|---|
| Keine beschrifteten Ergebnisdaten | Scoring + Routing, Anomaly Agent | Woche 3-4 des Tests | 8-12 Wochen |
| Wissensbasis nie aktualisiert | RAG Assistant | Woche 3 des Pilots (wenn Nutzer falsche Antwort entdeckt) | 4-6 Wochen |
| Audio ohne Export-API gespeichert | Meeting Intelligence | Vorab-Vendor-Audit (wenn durchgeführt) oder Woche 1 der Integration | 6-10 Wochen |
| Tool-APIs nicht getestet | Autonomous Agent | Erster Produktionslauf | 2-4 Wochen plus Incident Recovery |
| CRM-Webhooks nicht konfiguriert | Scoring + Routing, Workflow Copilot | Integrationstest, Woche 2 | 1-3 Wochen |
Sequenzierung für ressourcenbeschränkte Teams
Wenn Sie nicht alle Patterns gleichzeitig bauen können, sequenzieren Sie für maximalen frühen Wert und minimale Voraussetzungsschuld:
Beginnen Sie mit abhängigkeitsfreien Patterns, die eigenständigen Wert haben. RAG Assistant (wenn Sie eine Wissensbasis haben) und Scoring and Routing (wenn Sie beschriftete historische Daten haben) können beide unabhängig eingesetzt werden und liefern sofortigen Wert. Sie generieren auch keine Ausgaben, auf die andere Patterns angewiesen sind, daher entsteht kein technischer Schulden für nachgelagerte Implementierungen. Wie man diese Entscheidungen über einen mehrjährigen Plan hinweg sequenziert, erklärt Sequenzierung von AI-Patterns in einer Roadmap.
Sammeln Sie jetzt die Daten, die Sie später benötigen werden. Wenn Sie planen, Meeting Intelligence in sechs Monaten hinzuzufügen, beginnen Sie heute, Gesprächsaufnahmen im richtigen Format zu speichern. Wenn Sie einen Anomaly Agent hinzufügen wollen, beginnen Sie von einem definierten Basisdatum an, konsistente Metriken zu sammeln. Die Datenerfassungskosten sind gering. Die Entdeckung, dass Sie 90 Tage Daten benötigen und nur 12 haben, ist hoch.
Setzen Sie den Workflow Copilot ein, nachdem seine vorgelagerten Abhängigkeiten laufen. Ein Copilot, der vor Meeting Intelligence und Scoring and Routing gebaut wird, produziert generische statt kontextreiche Vorschläge. Warten Sie, bis die vorgelagerten Patterns Daten produzieren, bevor Sie in die Copilot-Schicht investieren.
Voraussetzungen im Laufe der Zeit aktualisieren
Patterns, die in Jahr 1 funktionieren, können in Jahr 2 degradieren, wenn ihre Voraussetzungen nicht gepflegt werden:
- Wissensbasen werden veraltet, wenn sich Produkte und Richtlinien ändern
- Scoring-Modelle driften, wenn sich die Marktzusammensetzung ändert (mehr Enterprise-Kunden als beim Modelltraining, andere Abschlussraten, andere Vertriebszyklen)
- Anomalieerkenntnis-Basisdaten, die in einem Quartal aufgebaut wurden, können für ein anderes saisonales Muster falsch sein
McKinseys Forschung zur Wegkartierung zum daten- und AI-gesteuerten Unternehmen empfiehlt, ein einziges Datenfundament für Analytik und AI aufzubauen, das überall genutzt wird, statt separate Pipelines pro System. Dieser Ansatz ist das Infrastrukturäquivalent zur Definition Ihres Voraussetzungspflegekalenders, bevor Sie ihn benötigen.
Erstellen Sie einen Pflegekalender für die Voraussetzungen jedes Patterns:
- RAG-Wissensbasis: mindestens vierteljährlich überprüfen und aktualisieren; größere Produktänderungen lösen sofortige Aktualisierung aus
- Scoring-Modell: alle 6 Monate gegen frische Ergebnisdaten neu trainieren; Modelldrift-Metriken monatlich überwachen
- Anomalieerkenntnis-Basis: neu kalibrieren, wann immer eine wesentliche Geschäftsänderung eintritt (neue Produktlinie, neuer Markt, größere Teamveränderung)
Das Voraussetzungs-Audit beim Einsatz ist kein einmaliges Ereignis. Es ist der Ausgangspunkt für einen laufenden Pflegerhythmus.
Häufig gestellte Fragen
Was ist die am häufigsten versäumte AI-Implementierungsvoraussetzung?
Datenverfügbarkeit wird vorausgesetzt, aber Datenzugänglichkeit und -qualität werden nicht bestätigt. Ein Datensatz, der in einem CRM existiert, ist nicht dasselbe wie ein Datensatz, dessen Ergebnis-Label genau ist, dessen Merkmalsfelder ausgefüllt sind und dessen Format mit dem Modell kompatibel ist, das ihn verarbeiten muss. Die RAND Corporation stellte fest, dass 85 % der gescheiterten AI-Projekte Datenqualität als Grundursache nennen.
Wie lange dauert ein Voraussetzungs-Audit typischerweise?
Ein gründliches Voraussetzungs-Audit über alle drei Abhängigkeitskategorien (Daten, Infrastruktur, Pattern-Abhängigkeiten) dauert 2-3 Wochen für ein einzelnes Pattern und 4-6 Wochen für einen Multi-Pattern-Stack. Diese Investition eliminiert die 8-12-Wochen-Verzögerungen, die auftreten, wenn fehlende Voraussetzungen während des Integrationstests auftauchen. Erfolgreiche Programme planen 50-70 % ihrer AI-Projektzeitlinie für Datenbereitschaftsarbeit ein.
Haben alle AI-Patterns dieselben Voraussetzungen?
Nein. RAG Assistant, Document Review und Vision Extract haben keine vorgelagerten Pattern-Abhängigkeiten und können zuerst eingesetzt werden. Meeting Intelligence, Scoring and Routing und Generative Research haben ebenfalls keine Pattern-Abhängigkeiten, aber spezifische Datenanforderungen. Workflow Copilot und Anomaly Agent hängen häufig von vorgelagerten Patterns ab, um kontextreiche Ausgaben zu produzieren. Autonomous Agent hat die strengsten Infrastrukturvoraussetzungen und erfordert, dass jede Tool-API vor dem Einsatz getestet wird.
Was passiert, wenn man ein Scoring-Modell ohne beschriftete historische Daten einsetzt?
Das Scoring-Modell produziert Scores, die nicht mit tatsächlichen Ergebnissen korrelieren. Hoch bewertete Leads schließen nicht mit der prognostizierten Rate ab. Niedrig bewertete Leads konvertieren mit Raten, die das Modell mit geringer Wahrscheinlichkeit eingestuft hat. Das Modell sieht aktiv aus, funktioniert aber als Rauschen. Lösung: Vor dem Training validieren, dass der historische Datensatz konsistente Ergebnis-Labels hat und dass Merkmalsfelder in über 80 % der Datensätze ausgefüllt sind.
Wie oft sollten AI-Pattern-Voraussetzungen nach dem ersten Einsatz neu überprüft werden?
RAG-Wissensbasen sollten mindestens vierteljährlich überprüft werden, mit sofortigen Aktualisierungen bei größeren Produkt- oder Richtlinienänderungen. Scoring-Modelle sollten alle sechs Monate gegen frische Ergebnisdaten neu trainiert werden, mit monatlicher Drift-Überwachung. Anomalieerkenntnis-Baisdaten müssen neu kalibriert werden, wenn eine wesentliche Geschäftsänderung eintritt (neue Produktlinie, neuer Markt, größere Teamumstrukturierung). Voraussetzungen sind keine einmalige Prüfung.
Was ist die Pattern Dependency Map?
Die Pattern Dependency Map ist eine Voraussetzungs-Audit-Struktur, die jedes AI-Pattern vor der Implementierung entlang drei Achsen kategorisiert: Datenabhängigkeiten, Infrastrukturabhängigkeiten und Pattern-Abhängigkeiten (vorgelagerte Patterns, die zuerst laufen müssen). Die Ausführung der Map vor Bauentscheidungen eliminiert die drei- bis sechsmonatigen Verzögerungen, die auftreten, wenn fehlende Voraussetzungen mitten in der Integration auftauchen.
Mehr erfahren
- Pattern-Stacking: Wie AI-Patterns zu AI-Agenten werden
- Datenbereitschaft nach AI-Pattern
- Datenbereitschaft: Die Voraussetzung, die die meisten AI-Projekte überspringen
- Sequenzierung von AI-Patterns in einer mehrjährigen Roadmap
- Anti-Patterns: AI-Kombinationen, die scheitern
- Buy-vs.-Build-Entscheidung für jedes AI-Pattern

Co-Founder, Rework.com
On this page
- Arten von Abhängigkeiten
- Abhängigkeitskarte nach Pattern
- Die Pattern Dependency Map
- Der kritische Pfad: Einsatzsequenz des AI Sales Operator
- Häufige Voraussetzungsfehler nach Pattern
- Datenbereitsschafts-Audit-Checkliste
- Infrastrukturvoraussetzungen, die Teams verpassen
- Sequenzierung für ressourcenbeschränkte Teams
- Voraussetzungen im Laufe der Zeit aktualisieren
- Mehr erfahren