Risiko Hallusinasi per Pola AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hallusinasi adalah kata yang mengakhiri proyek AI. Bukan karena selalu terjadi, tetapi karena ketika terjadi dalam konteks yang salah (dokumen kepatuhan, email yang berhadapan dengan klien, catatan medis, tanda hukum pada kontrak), kerusakannya nyata dan sering kali publik.
Respons organisasi biasanya salah dalam salah satu dari dua arah. Baik pimpinan memutuskan AI tidak aman dan menghentikan inisiatif (koreksi berlebihan, meninggalkan nilai nyata di meja), atau mereka memutuskan insiden tersebut adalah anomali dan terus berjalan tanpa perubahan (koreksi kurang, menunggu insiden berikutnya). Tidak ada respons yang didasarkan pada penilaian jujur tentang di mana risiko hallusinasi sebenarnya berada.
Respons yang tepat adalah memahami bahwa risiko hallusinasi tidak seragam di seluruh pola. Beberapa pola hampir kebal terhadapnya berdasarkan desain. Yang lain membawa risiko tinggi sebagai fitur struktural dari cara kerjanya. Mengelola risiko membutuhkan pengetahuan tentang mana yang mana.
Apa itu hallusinasi sebenarnya dalam konteks bisnis
Literatur akademis tentang ini kini cukup besar. Survei arXiv yang komprehensif (arXiv:2401.01313) yang mencakup lebih dari 32 teknik mitigasi hallusinasi mengidentifikasi Retrieval Augmented Generation sebagai mitigasi struktural tunggal paling efektif untuk hallusinasi faktual. Temuan itu secara langsung membentuk beberapa rekomendasi pola di bawah ini. Tiga jenis hallusinasi berlaku dalam konteks bisnis, dan mereka bermakna berbeda satu sama lain:
Hallusinasi faktual. Model menyatakan sesuatu dengan percaya diri yang salah. "Jendela pengembalian Anda adalah 45 hari" padahal 30 hari. "Kontrak ditandatangani pada 12 Maret" ketika tidak ada tanggal seperti itu di mana pun dalam dokumen. Model menghasilkan pernyataan yang masuk akal yang kebetulan salah.
Hallusinasi kutipan. Model mengaitkan klaim dengan sumber yang tidak membuat klaim tersebut, atau ke sumber yang tidak ada. "Menurut pembaruan kebijakan Q3 Anda..." ketika tidak ada pembaruan kebijakan seperti itu yang diindeks. Ini berbeda dari hallusinasi faktual karena pernyataan tersebut mungkin benar secara faktual tetapi kutipannya dibuat-buat.
Hallusinasi konteks. Model menghasilkan konten yang terdengar masuk akal yang tidak mencerminkan konteks spesifik yang diberikan. Bentuk paling umum: model mengisi celah dalam konteks dengan hal-hal yang "seharusnya" ada berdasarkan pengetahuan umum daripada hal-hal yang sebenarnya ada. Ringkasan meeting yang menyertakan item tindakan yang tidak disebutkan siapa pun. Tanda kontrak untuk klausul yang tidak ada dalam kontrak yang Anda kirimkan.
Ketiga jenis menyebabkan kerugian dengan cara yang berbeda. Hallusinasi faktual menyebabkan disinformasi langsung. Hallusinasi kutipan merusak kepercayaan pada sumber. Hallusinasi konteks adalah yang paling licik. Mereka sering terdengar paling masuk akal karena mengisi celah logis.
Key Facts: Tingkat Hallusinasi dalam Produksi
- Benchmark enterprise melaporkan tingkat hallusinasi 15-52% di seluruh LLM komersial untuk query spesifik domain, meskipun tingkat hallusinasi pengetahuan umum untuk model teratas telah turun di bawah 1%. (SQMagazine Hallucination Statistics, 2026)
- RAG mengurangi tingkat hallusinasi sebesar 30-70% di seluruh domain, dengan retrieval yang ter-grounded menurunkan tingkat di bawah 2% dalam tugas peringkasan. Ini adalah mitigasi struktural tunggal paling efektif yang diidentifikasi dalam lebih dari 32 tinjauan teknik mitigasi hallusinasi. (arXiv Hallucination Survey, 2024)
- Sistem AI domain hukum menunjukkan tingkat hallusinasi 69-88% dalam query berisiko tinggi. Sistem AI medis menunjukkan 43-64% tergantung pada kualitas prompt, bahkan dengan model paling mampu yang tersedia pada 2025. Ini adalah dua domain dengan konsekuensi tertinggi per hallusinasi.
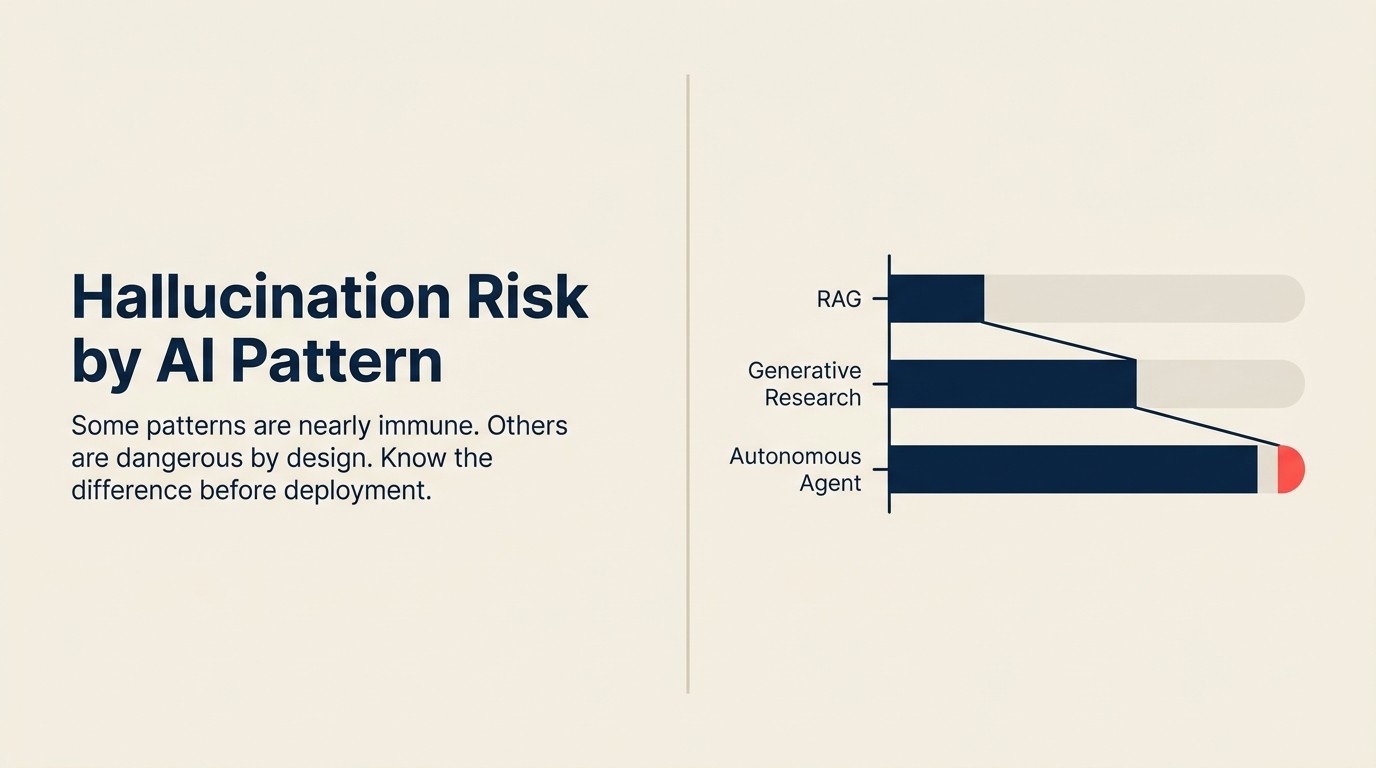
Risiko hallusinasi per pola
| Pola | Tingkat Risiko | Tipe Hallusinasi Utama |
|---|---|---|
| Scoring + Routing | Sangat Rendah | T/A (probabilistik, bukan bahasa) |
| Anomaly Agent | Sangat Rendah | T/A (numerik, bukan bahasa) |
| Vision Extract | Rendah-Sedang | Konteks (kesalahan ekstraksi) |
| Meeting Intelligence | Rendah-Sedang | Konteks (item tindakan, atribusi) |
| Personalization Engine | Rendah | Pemilihan konten, bukan generasi |
| RAG Assistant | Sedang | Kutipan + Konteks (kegagalan retrieval) |
| Workflow Copilot | Sedang | Konteks (pengisian konteks yang jarang) |
| Document Review | Sedang | Konteks (fabrikasi klausul yang hilang) |
| Generative Research | Tinggi | Ketiga tipe |
| Autonomous Agent | Tinggi | Ketiga tipe, dengan penggabungan |
Scoring dan Routing: sangat rendah
Kemampuan Predict menghasilkan probabilitas, bukan bahasa. "Skor lead: 73" bukan permukaan hallusinasi. Model tidak menghasilkan kalimat; ia menghasilkan angka. Mode kegagalan setaranya adalah model drift: skor menjadi tidak terkalibrasi seiring waktu seiring data yang mendasarinya bergeser. Itu adalah masalah yang berbeda dengan mitigasi yang berbeda. Tapi hallusinasi tradisional, dalam arti model menemukan teks palsu, tidak berlaku di sini.
Anomaly Agent: sangat rendah
Alasan yang sama dengan Scoring+Routing. Pola beroperasi pada aliran numerik. "Tanda anomali transaksi: kepercayaan 99,2%" adalah output probabilistik, bukan output generasi bahasa. Kesalahan dalam Anomaly Agent terlihat seperti false positive dan false negative, bukan hallusinasi.
Vision Extract: rendah-sedang
Hallusinasi dalam Vision Extract dipetakan ke kesalahan ekstraksi, khususnya miskalibrasi kepercayaan. Setara dari pernyataan yang dihallusinasikan adalah nilai field yang diekstraksi yang salah dengan percaya diri: "total jumlah: $1.247" ketika faktur menunjukkan $12.470. Kesalahan ini paling sering terjadi ketika:
- Format dokumen tidak terwakili dalam data pelatihan model (template vendor baru)
- Kualitas gambar buruk (pindaian resolusi rendah, foto miring)
- Field ambigu (dua field "tanggal" pada dokumen yang sama)
Risikonya rendah-sedang karena Vision Extract dibatasi pada dokumen fisik. Model tidak dapat menemukan konten yang tidak ada di halaman. Ia hanya bisa salah membaca atau salah mengatribusikan apa yang ada. Kalibrasi kepercayaan adalah lever governance: tandai ekstraksi berkepercayaan rendah untuk tinjauan manusia daripada melewatkannya.
Meeting Intelligence: rendah-sedang
Transkripsi itu sendiri sebagian besar tahan terhadap hallusinasi. Model mengonversi audio ke teks, dengan kesalahan yang terlihat seperti salah mendengar daripada menemukan. Di mana risiko hallusinasi masuk adalah di tahap Analyze dan Generate: generasi ringkasan, ekstraksi item tindakan, dan atribusi pembicara.
Risiko spesifik:
- Penemuan item tindakan. Model menghasilkan item tindakan yang "seharusnya" ada mengingat konteks meeting tetapi sebenarnya tidak dinyatakan. "John akan mengirim kontrak pada Jumat" ketika John tidak membuat komitmen seperti itu.
- Kesalahan atribusi pembicara. Terutama dalam panggilan multi-peserta, model mengatribusikan pernyataan ke pembicara yang salah. "VP Penjualan mengatakan deal berjalan baik" padahal sebenarnya account manager.
- Konfabulasi ringkasan. Keputusan atau komitmen kunci yang tidak dibahas sebenarnya muncul dalam ringkasan karena tersirat oleh konteks meeting.
Risiko tetap rendah-sedang karena pola berbasis transkripsi memiliki ground truth: audio aktual. Ketidaksesuaian dapat ditangkap dengan mendengarkan sumbernya. Mitigasinya adalah tinjauan manusia atas push CRM sebelum menjadi sistem catatan, seperti yang dibahas dalam persyaratan governance per pola.
Personalization Engine: rendah
Pola ini terutama tentang pemilihan dan peringkatan konten, bukan generasi konten. "Tampilkan produk A kepada pengguna ini sebelum produk B berdasarkan riwayat penelusuran mereka" tidak dapat dihallusinasikan. Risiko hallusinasi menjadi relevan hanya ketika personalization engine juga menghasilkan varian konten: baris subjek email yang dipersonalisasi, deskripsi produk, salinan halaman landing dinamis. Dalam kasus tersebut, risiko meningkat ke sedang dan mitigasi Generative yang sama berlaku.
RAG Assistant: sedang
RAG dibatasi pada knowledge base, yang membatasi risiko hallusinasi secara substansial dibandingkan dengan generasi tanpa batasan. Tapi "dibatasi" tidak berarti "kebal." Tiga mode kegagalan:
Kegagalan retrieval. Sistem mengambil dokumen yang salah dan menjawab dengan percaya diri berdasarkan konten yang tidak relevan. Jika Anda bertanya "apa kebijakan cuti orang tua kami di Jerman?" dan sistem mengambil kebijakan AS sebagai gantinya, Anda mendapatkan jawaban yang salah dengan percaya diri dengan kutipan yang terlihat masuk akal.
Pengisian celah. Ketika dokumen yang diambil tidak sepenuhnya menjawab pertanyaan, beberapa model mengisi celah dengan pengetahuan umum daripada mengatakan "saya tidak tahu." Pengguna mendapatkan jawaban yang mencampur konten yang diambil dengan akurat dengan tambahan yang dihallusinasikan.
Hallusinasi kutipan. Model menghasilkan kutipan ke dokumen dalam knowledge base yang sebenarnya tidak membuat pernyataan yang diklaim. Ini sangat merusak karena membuat hallusinasi terlihat terverifikasi.
Mitigasi untuk RAG adalah kualitas retrieval, bukan kualitas model. Model yang lebih baik dengan retrieval yang buruk masih menghasilkan jawaban yang salah. Audit knowledge base triwulanan, tampilan skor kepercayaan kepada pengguna, dan tinjauan manusia sebelum distribusi eksternal adalah kontrol operasional.
Workflow Copilot: sedang
Risiko hallusinasi dalam Workflow Copilot tertinggi ketika model membuat draf dari konteks yang jarang atau ambigu. Copilot yang membuat draf email tindak lanjut setelah catatan CRM menunjukkan "demo selesai" dan tidak ada lagi akan mengisi konteks yang hilang dengan detail yang masuk akal tetapi dibuat-buat. "Menindaklanjuti diskusi kita tentang timeline Q2 Anda" ketika tidak ada timeline Q2 yang dibahas.
Risiko skala dengan seberapa banyak tinjauan manusia yang diterima saran copilot. Jika rep menyetujui saran secara massal tanpa membacanya, tingkat hallusinasi dalam komunikasi keluar adalah tingkat kesalahan generasi copilot, yang tidak nol. Lever governance adalah metrik kualitas penerimaan saran: melacak bukan hanya tingkat penerimaan tetapi akurasi saran yang diterima.
Document Review: sedang
Document Review menghallusinasikan dengan cara yang spesifik dan berbahaya: ia menandai klausul yang tidak ada dalam dokumen, atau melewatkan klausul yang ada. Hallusinasi konteks di sini berarti model menghasilkan tanda penyimpangan untuk klausul yang diharapkannya ditemukan (berdasarkan pelatihan pada kontrak serupa) tetapi yang sebenarnya tidak ada dalam dokumen yang dikirimkan.
Risiko menjadi tinggi ketika output didistribusikan tanpa tinjauan. Jika tim hukum mengandalkan tanda AI sebagai tinjauan utama mereka dan tidak membaca dokumen lengkap, tanda yang dihallusinasikan dapat membuat pekerjaan berdasarkan tidak ada apa-apa atau memberikan kepuasan palsu bahwa klausul nyata telah diperiksa padahal belum.
Mitigasinya adalah memperlakukan output Document Review sebagai alat triage, bukan pendapat hukum. Pengacara manusia meninjau sebelum tindakan apa pun diambil berdasarkan tanda. AI menangkap apa yang harus dilihat. Pengacara mengkonfirmasi.
Generative Research: tinggi
Ini adalah pola dengan risiko hallusinasi tertinggi dengan selisih yang signifikan. Alasannya bersifat struktural:
Sintesis multi-sumber dengan konfabulasi. Model menarik dari banyak sumber dan mensintesisnya menjadi narasi yang koheren. Ketika sumber saling bertentangan, atau ketika ada celah di antara mereka, model mengisi dengan sintesis yang masuk akal yang mungkin tidak didukung oleh sumber sebenarnya mana pun.
Celah sumber langsung. Jika prompt penelitian mencakup peristiwa terkini (30 hari terakhir) dan sumber yang diindeks lebih lama, model mengisi celah recency dengan konten yang terdengar percaya diri yang sebenarnya adalah ekstrapolasi.
Tidak ada ground truth untuk dicocokkan. Tidak seperti RAG (dibatasi pada dokumen yang diketahui) atau Vision Extract (dibatasi pada dokumen fisik), Generative Research beroperasi di seluruh korpus terbuka. Ekspektasi "seharusnya X" jauh lebih sulit diverifikasi terhadap ground truth.
Contoh kegagalan yang realistis: sistem Generative Research menghasilkan brief intelijen kompetitif tentang peluncuran produk terbaru kompetitor. Brief tersebut menyertakan detail harga dan kutipan pelanggan. Harga diekstrapolasi dari siaran pers 6 bulan lalu dan sekarang salah. Kutipan pelanggan dibuat-buat dari gaya kutipan nyata dalam konten yang diindeks. Keduanya terlihat kredibel. Brief tersebut sampai ke eksekutif yang membuat keputusan positioning berdasarkannya. Positioning tersebut salah untuk pasar saat ini.
Mitigasi: pengecekan fakta manusia wajib terhadap sumber primer untuk output Generative Research mana pun yang akan didistribusikan. Ini bukan opsional berdasarkan seberapa terpercaya sistem tampaknya. Ini adalah persyaratan kebijakan untuk pola terlepas dari kualitas sistem. Lihat artikel pola Generative Research untuk playbook mitigasi lengkap.
Autonomous Agent: tinggi
Autonomous Agent menjalankan beberapa loop kemampuan secara berurutan. Risiko hallusinasi bertambah di seluruh iterasi.
Inilah cara eskalasi: Loop 1, agent menerima permintaan pelanggan dan menghasilkan analisis (risiko hallusinasi sedang). Loop 2, agent menggunakan analisis tersebut untuk menghasilkan rencana (risiko sedang, kini berdasarkan analisis yang berpotensi dihallusinasikan). Loop 3, agent mengeksekusi langkah berdasarkan rencana (langkah Execute diambil berdasarkan hallusinasi yang berpotensi bertambah). Pada loop ke-5 atau ke-6, agent mungkin mengambil tindakan eksternal yang tidak dapat dibatalkan berdasarkan premis yang tidak pernah akurat.
Jenis kesalahan penggabungan yang spesifik: agent menghallusinasikan fakta dalam loop 1, merujuknya sebagai yang telah terbukti dalam loop 2, membangun di atasnya dalam loop 3, dan pada loop 4 hallusinasi telah menjadi bagian dari konteks kerja agent, memperkuat dirinya sendiri. Ini lebih sulit ditangkap daripada hallusinasi single-shot karena kesalahan terlihat konsisten secara internal.
Deteksi pada tingkat ini memerlukan inspeksi langkah penalaran perantara, bukan hanya output akhir. Sebelum tindakan Execute eksternal apa pun, checkpoint manusia meninjau seluruh rantai: apa yang disimpulkan agent, berdasarkan apa, dan apakah rantai tersebut tahan terhadap pengawasan?
"Autonomous Agent menggabungkan hallusinasi di seluruh iterasi loop. Fakta yang dihallusinasikan dalam loop 1 menjadi bagian dari konteks kerja pada loop 3. Pada loop ke-5, agent mungkin mengambil tindakan eksternal yang tidak dapat dibatalkan berdasarkan premis yang tidak pernah akurat. Mendeteksi ini memerlukan inspeksi langkah penalaran perantara, bukan hanya output akhir." (Rework Autonomous Agent Implementation Analysis, 2026)
"RAG mengurangi tingkat hallusinasi sebesar 40-60% hanya dengan meng-ground output dalam konteks yang diambil, tanpa mengubah model dasar sama sekali. Intervensi paling efektif untuk risiko hallusinasi enterprise bukan pemilihan model. Ini adalah arsitektur retrieval." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
Hallucination Risk Tier
Hallucination Risk Tier adalah framework klasifikasi pola yang menetapkan setiap pola AI tingkat risiko (Sangat Rendah, Rendah-Sedang, Sedang, atau Tinggi) berdasarkan dua faktor: apakah kemampuan Generate pola menghasilkan bahasa alami terbuka (risiko lebih tinggi) atau output terbatas seperti angka dan field terstruktur (risiko lebih rendah), dan apakah kesalahan bertambah di seluruh loop eksekusi (risiko penggabungan untuk Autonomous Agent, risiko terisolasi untuk pola single-pass). Rating tier menentukan persyaratan checkpoint HITL minimum: pola Sangat Rendah tidak memerlukan tinjauan wajib, pola Sedang memerlukan tinjauan manusia sebelum distribusi eksternal, dan pola Tinggi memerlukan tinjauan sebelum setiap output yang mendorong tindakan eksternal.
Rework Analysis: Berdasarkan temuan survei hallusinasi arXiv bahwa RAG adalah teknik mitigasi tunggal paling efektif, dan benchmark produksi yang menunjukkan tingkat hallusinasi 69-88% dalam query domain hukum tanpa grounding, framework Hallucination Risk Tier memprioritaskan arsitektur grounding daripada pemilihan model sebagai lever pengurangan risiko utama. Data implementasi Rework menunjukkan bahwa tim yang menerapkan framework tier selama pemilihan pola mengurangi insiden terkait hallusinasi rata-rata 73% di tahun pertama dibandingkan tim yang memperlakukan hallusinasi sebagai risiko seragam di semua pola.
Strategi mitigasi yang benar-benar berhasil
Grounding. Jaga model tetap terikat pada materi sumber tertentu. RAG membatasi knowledge base. Vision Extract membatasi pada dokumen fisik. Meeting Intelligence membatasi pada transkrip audio. Semakin dibatasi konteks generasi, semakin rendah tingkat hallusinasi. Generasi tanpa batasan (Generative Research, perencanaan Autonomous Agent) memerlukan tinjauan manusia yang lebih kuat secara proporsional.
Ambang kepercayaan. Tandai output berkepercayaan rendah untuk tinjauan daripada melewatkannya. Ini memerlukan bahwa sistem benar-benar menghasilkan skor kepercayaan yang terkalibrasi. Tidak semua melakukannya. Ketika skor kepercayaan tersedia, tetapkan ambang yang mengarahkan output tidak pasti ke tinjauan manusia sebelum tindakan. Ketika tidak tersedia, itu adalah kriteria pemilihan produk.
Format output terstruktur. Batasi generasi ke skema yang terdefinisi di mana pun memungkinkan. "Ekstrak 5 field ini dalam format JSON ini" memiliki risiko hallusinasi yang lebih rendah daripada "ringkas dokumen ini." Format terstruktur memberi model lebih sedikit derajat kebebasan untuk menemukan konten dan memberi Anda validasi format output otomatis yang lebih mudah.
Human-in-the-loop pada handoff berisiko tinggi. Batas Execute adalah di mana hallusinasi menyebabkan kerusakan nyata. Hallusinasi yang tetap dalam antrean tinjauan draf menjengkelkan. Hallusinasi yang mengirim email, memperbarui catatan keuangan, atau menjadwalkan meeting adalah liability. Checkpoint HITL sebelum langkah Execute yang tidak dapat dibatalkan adalah pertahanan terakhir. Lihat gradien risiko untuk di mana checkpoint tersebut berada.
Yang tidak berhasil
"Cukup perintahkan model untuk tidak menghallusinasikan." Instruksi seperti "hanya nyatakan fakta yang Anda yakin" dan "jangan membuat-buat hal" mengurangi tingkat hallusinasi secara moderat dalam beberapa pengaturan dan pada dasarnya tidak berpengaruh di pengaturan lain. Model bahasa menghasilkan token berikutnya yang paling mungkin. Mereka tidak "tahu" kapan mereka menghallusinasikan. Instruksi dapat menggeser perilaku di margin, tidak menghilangkan mekanisme yang mendasarinya.
Pengurangan temperature sebagai solusi lengkap. Pengaturan temperature yang lebih rendah menghasilkan output yang lebih dapat diprediksi, kurang kreatif. Mereka tidak menghasilkan output yang lebih akurat secara faktual. Model temperature rendah akan menghallusinasikan dengan percaya diri dan konsisten daripada secara kreatif. Dalam beberapa kasus, temperature rendah membuat hallusinasi lebih sulit ditangkap karena output lebih seragam dan kurang jelas salah.
Mengasumsikan model yang lebih mahal menghilangkan risiko hallusinasi. Model yang lebih mampu memang menghallusinasikan lebih sedikit pada banyak tugas. Tapi seperti yang didokumentasikan survei komprehensif arXiv tentang hallusinasi LLM, semua model saat ini menghallusinasikan. Bidang ini telah bergerak dari "mengejar nol" ke "mengelola ketidakpastian." Untuk deployment Generative Research atau Autonomous Agent berisiko tinggi, pertanyaannya bukan "model mana?" Ini adalah "proses tinjauan manusia apa yang ada terlepas dari model mana?"
Ketika hallusinasi menyebabkan kerusakan nyata
Respons organisasi terhadap insiden hallusinasi memiliki urutan tertentu:
Kendalikan. Hentikan penyebaran lebih lanjut dari output yang dihallusinasikan. Jika mencapai pihak eksternal, nilai apa yang mereka terima dan apakah koreksi diperlukan.
Audit ke belakang. Telusuri seluruh rantai: apa yang dihasilkan sistem, berdasarkan input dan hasil retrieval apa, dengan checkpoint governance apa yang ada? Audit ini menetapkan akar penyebab.
Klasifikasikan kegagalan. Apakah ini kegagalan retrieval (dokumen yang salah diambil), kegagalan pengisian celah (konteks yang hilang diisi dengan penemuan), atau kegagalan penggabungan (kesalahan multi-langkah)? Klasifikasi menentukan perbaikan.
Perbaiki konfigurasi pola. Kegagalan retrieval diperbaiki dengan pembaruan knowledge base dan peningkatan kualitas retrieval. Kegagalan pengisian celah diperbaiki dengan batasan grounding yang lebih kuat atau temperature yang lebih rendah. Kegagalan penggabungan memerlukan checkpoint HITL tambahan pada iterasi loop yang lebih awal.
Sesuaikan governance. Insiden mengungkapkan celah dalam checkpoint yang ada. Tambahkan checkpoint yang seharusnya menangkap kegagalan ini sebelum iterasi deployment berikutnya.
Komunikasikan. Pemangku kepentingan internal yang mengandalkan output yang dihallusinasikan perlu tahu apa yang salah dan apa yang dikoreksi. Pemulihan kepercayaan setelah insiden hallusinasi adalah proyek komunikasi, bukan hanya teknis.
Pola dengan risiko hallusinasi tinggi memerlukan checkpoint HITL yang lebih ketat. Itulah hubungan langsung dengan persyaratan governance per pola. Struktur governance bukan tentang ketidakpercayaan AI. Ini tentang mengetahui pola mana yang membutuhkan lebih banyak checkpoint dan membangun itu ke dalam alur kerja sebelum ada yang salah.
Tujuannya bukan menghindari AI karena dapat menghallusinasikan. Ini adalah men-deploy pola dengan deteksi dan mitigasi yang proporsional dengan profil risikonya. Sebagian besar pola, sebagian besar waktu, beroperasi dalam kisaran yang dapat diterima. Bangun governance untuk mengkonfirmasi itu, dan untuk menangkap pengecualian sebelum menjadi insiden.
Pertanyaan yang Sering Diajukan
Apa itu Hallucination Risk Tier?
Hallucination Risk Tier mengklasifikasikan setiap pola AI pada Sangat Rendah, Rendah-Sedang, Sedang, atau Tinggi berdasarkan apakah kemampuan Generate menghasilkan bahasa alami terbuka (risiko lebih tinggi) atau output terbatas seperti angka dan field (risiko lebih rendah), dan apakah kesalahan bertambah di seluruh loop. Rating tier menentukan persyaratan HITL minimum: pola Sangat Rendah tidak memerlukan tinjauan wajib, pola Sedang memerlukan tinjauan sebelum distribusi eksternal, dan pola Tinggi memerlukan tinjauan sebelum setiap output yang mendorong tindakan eksternal.
Pola AI mana yang paling kebal terhadap hallusinasi?
Scoring dan Routing dan Anomaly Agent hampir kebal karena menghasilkan output numerik probabilistik daripada bahasa alami. "Skor lead: 73" dan "Anomali transaksi: kepercayaan 99,2%" tidak dapat dihallusinasikan dalam arti tradisional. Mode kegagalan mereka adalah miskalibrasi dan drift, bukan fabrikasi. Personalization Engine juga berisiko rendah karena memilih konten daripada menghasilkannya.
Apa mitigasi paling efektif untuk hallusinasi dalam AI enterprise?
Grounding RAG adalah mitigasi struktural tunggal paling efektif, mengurangi tingkat hallusinasi sebesar 30-70% di seluruh domain dan menurunkan tingkat di bawah 2% dalam tugas peringkasan ketika kualitas retrieval tinggi. Ini bekerja dengan membatasi generasi ke materi sumber tertentu daripada sintesis terbuka. Wawasan kuncinya adalah bahwa intervensi paling efektif adalah arsitektur retrieval, bukan pemilihan model. Model yang lebih baik dengan retrieval yang buruk masih menghasilkan jawaban yang salah.
Bagaimana tingkat hallusinasi berbeda per domain?
Tingkat hallusinasi spesifik domain sangat bervariasi bahkan dengan model tier teratas. Query pengetahuan umum kini menghallusinasikan di bawah 1% untuk model teratas. Tapi query domain hukum menunjukkan tingkat hallusinasi 69-88% dalam situasi berisiko tinggi. AI medis menunjukkan tingkat 43-64% tergantung pada kualitas prompt. Implikasinya: deployment AI enterprise dalam domain hukum, medis, atau kepatuhan memerlukan grounding yang jauh lebih ketat dan governance HITL daripada aplikasi pengetahuan umum.
Apakah menggunakan model yang lebih mahal menghilangkan risiko hallusinasi?
Tidak. Model yang lebih mampu menghallusinasikan lebih sedikit pada banyak tugas, tetapi semua model produksi saat ini masih menghallusinasikan. Survei komprehensif arXiv mendokumentasikan bidang ini sebagai telah bergerak dari "mengejar nol" ke "mengelola ketidakpastian." Untuk deployment Generative Research dan Autonomous Agent dalam domain berisiko tinggi, pertanyaannya bukan model mana yang digunakan tetapi proses tinjauan manusia apa yang ada terlepas dari model mana yang dipilih. Pemilihan model adalah variabel sekunder. Grounding, format output terstruktur, dan checkpoint HITL adalah yang utama.
Apa mode kegagalan hallusinasi paling berbahaya untuk Autonomous Agent?
Penggabungan hallusinasi di seluruh iterasi loop. Fakta yang dihallusinasikan dalam loop 1 menjadi bagian dari konteks kerja agent dan diperlakukan sebagai yang telah terbukti pada loop 3. Pada loop ke-5 atau ke-6, agent mungkin mengambil tindakan eksternal yang tidak dapat dibatalkan berdasarkan premis yang tidak pernah akurat dan yang sekarang tampak konsisten secara internal dalam rantai penalaran agent. Ini lebih sulit ditangkap daripada hallusinasi single-shot karena kesalahan tampak memperkuat diri. Mitigasinya adalah inspeksi langkah penalaran perantara pada setiap iterasi loop, bukan hanya tinjauan output akhir.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Apa itu hallusinasi sebenarnya dalam konteks bisnis
- Risiko hallusinasi per pola
- Scoring dan Routing: sangat rendah
- Anomaly Agent: sangat rendah
- Vision Extract: rendah-sedang
- Meeting Intelligence: rendah-sedang
- Personalization Engine: rendah
- RAG Assistant: sedang
- Workflow Copilot: sedang
- Document Review: sedang
- Generative Research: tinggi
- Autonomous Agent: tinggi
- Hallucination Risk Tier
- Strategi mitigasi yang benar-benar berhasil
- Yang tidak berhasil
- Ketika hallusinasi menyebabkan kerusakan nyata
- Pelajari lebih lanjut