Governance-Anforderungen nach AI Pattern
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
„Menschen sollten AI-Outputs überprüfen, bevor sie danach handeln." Wenn Ihre AI-Governance-Richtlinie diesen Satz enthält, enthält sie nichts. Dieser Satz beschreibt alles und regelt nichts.
Governance, die an spezifische Patterns gebunden ist, ist eine völlig andere Sache. „Für Autonomous Agent-Deployments in kundenorientierten Kontexten ist eine menschliche Genehmigung erforderlich, bevor ein Execute-Schritt einen Finanzdatensatz ändert oder externe Kommunikation versendet" ist handlungsorientiert. Sie können dagegen prüfen. Sie können jemanden darin schulen. Sie können es einem Regulierer zeigen und erklären, was es in der Praxis bedeutet.
Die meisten AI-Governance-Frameworks sind auf der falschen Abstraktionsebene geschrieben, weil sie so konzipiert wurden, dass sie die gesamte AI-Oberfläche einer Organisation abdecken. Diese Breite erzwingt Unschärfe. Dieser Artikel geht in die andere Richtung: spezifische Anforderungen für jedes der 10 Business AI Patterns, aufgebaut auf vier Governance-Dimensionen, die konsistent anwendbar sind. Die Generate vs. Execute Boundary ist das wichtigste Konzept, das Sie vor dem Lesen dieser Anforderungen verinnerlichen sollten.
Warum Governance musterspezifisch ist
Governance-Anforderungen folgen dem Risiko. Und Risiken in AI-Systemen entstehen fast ausschließlich aus zwei Quellen: was die Execute-Capability tut und in welchem Bereich sie operiert. Das NIST AI Risk Management Framework (AI RMF 1.0) kodifiziert dies mit vier Funktionen: GOVERN, MAP, MEASURE und MANAGE. Was dieser Artikel auf Pattern-Ebene tut, ist eine Implementierung der MAP- und MEASURE-Funktionen: Die AI-Risikooberfläche wird konkret, prüfbar und operativ statt theoretisch.
Ein RAG Assistant, der Richtliniendokumente liest und Mitarbeiterfragen beantwortet, hat einen geringen Governance-Bedarf. Das schlimmste realistische Ergebnis ist eine selbstsicher falsche Antwort zur Anspruchsberechtigung von Benefits. Ärgerlich. Korrigierbar. Kein Haftungsereignis.
Ein Autonomous Agent, der E-Mails an Kunden sendet, Finanzdatensätze in Ihrem ERP aktualisiert und im Namen Ihres CEO Meetings plant, hat ein völlig anderes Risikoprofil. Das schlimmste realistische Ergebnis ist eine irreversible Aktion, die im großen Maßstab auf einer halluzinierten Prämisse basiert. Das ist ein Haftungsereignis.
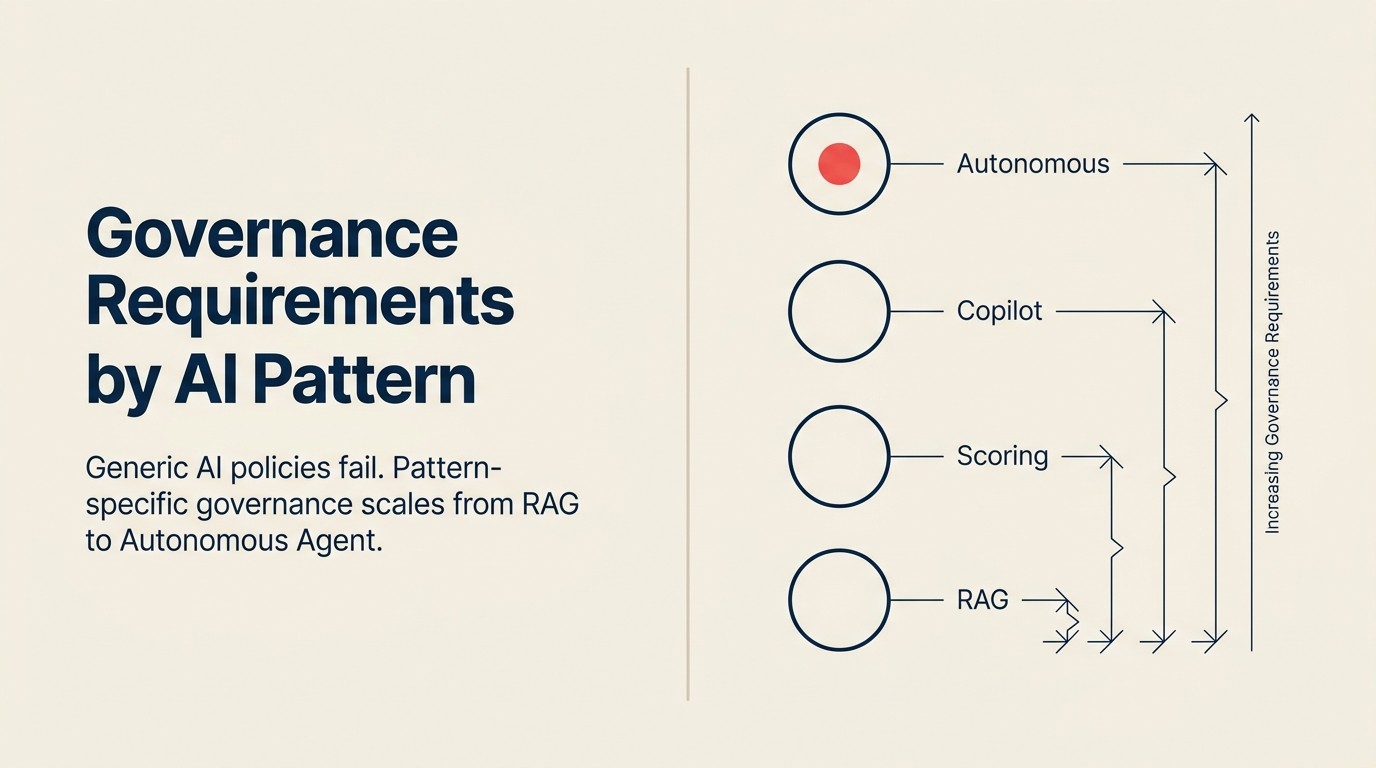
Der Risikogradient über Patterns hinweg entspricht fast perfekt der Execute-Intensität jedes Patterns. Patterns, die bei Analyze oder Generate angesiedelt sind, tragen eine begrenzte Governance-Last. Patterns, die wiederholt, autonom und im großen Maßstab Execute-Schritte ausführen, tragen eine erhebliche Last. Lesen Sie den Risikogradienten über AI Patterns hinweg für das vollständige Framework.
Key Facts: Enterprise AI Governance Gaps
- 83 % der Organisationen verwenden bereits AI-Tools, aber nur 25 % haben starke Governance-Frameworks implementiert. (Compliance Week, 2026)
- Der EU AI Act tritt am 2. August 2026 vollständig in Kraft, mit Bußgeldern von bis zu 35 Millionen Euro oder 7 % des globalen Umsatzes für Verstöße gegen verbotene AI-Praktiken. Verstöße gegen AI-Systeme mit hohem Risiko können mit bis zu 15 Millionen Euro oder 3 % des globalen Umsatzes geahndet werden.
- Der AI-Governance-Markt wird von 309 Millionen US-Dollar im Jahr 2025 auf 5,88 Milliarden US-Dollar bis 2035 wachsen, eine CAGR von 34 %, was die rasche Institutionalisierung von Governance-Anforderungen in Enterprise AI-Deployments widerspiegelt.
„Bis 2026 erwarten die Hälfte der Regierungen weltweit von Unternehmen die Einhaltung von AI-Gesetzen und Datenschutzanforderungen. Organisationen, die 2024 und 2025 Governance-Infrastruktur aufgebaut haben, verfügen jetzt über Audit Trails, HITL-Checkpoints und Override-Mechanismen, die für die Überprüfung durch Regulierungsbehörden bereit sind. Organisationen, die dies nicht getan haben, rüsten jetzt unter Compliance-Fristen nach." (Modulos AI Compliance Guide, 2026)
Die vier Governance-Dimensionen
Für jedes Pattern gliedert sich Governance in vier Dimensionen. Sie sind konsistent, sodass Sie Ihre AI-Governance-Richtlinie als Tabelle statt als Prosatext aufbauen können:
Audit Trail-Anforderungen. Welche Aufzeichnungen müssen in welcher Form und wie lange aufbewahrt werden? Audit Trails dienen zwei Zwecken: Debugging, wenn etwas schiefgeht, und Nachweis der Compliance, wenn jemand fragt. Beide Zwecke erfordern Spezifität darüber, welche Inputs und Outputs protokolliert wurden.
Human-in-the-Loop-Checkpoints. An welcher Stelle im Workflow muss ein Mensch überprüfen, bevor das System fortfährt? Nicht „Menschen sollten Outputs überprüfen." Ein spezifischer Schritt, eine spezifische Bedingung, ein spezifischer Entscheidungspunkt.
Override- und Rollback-Mechanismen. Wenn ein Mensch einer AI-Aktion widerspricht oder wenn sich ein Execute-Schritt als falsch herausstellt, was passiert dann? Jedes Pattern, das Execute-Schritte ausführen kann, benötigt einen definierten Rollback-Pfad.
Review- und Retraining-Häufigkeit. Wie oft wird das Pattern selbst auf Genauigkeit, Drift und anhaltende Relevanz überprüft? Ein Scoring+Routing-Modell, das auf den Leads des letzten Jahres trainiert wurde, kann in diesem Jahr aktiv irreführend sein. Jemand muss diese Überprüfung nach einem Zeitplan besitzen.
RAG Assistant Governance
Der RAG Assistant ist das am häufigsten deployed Pattern und trägt das geringste Execute-Risiko aller AI-Systeme, die mit Benutzern interagieren. Aber „geringes Risiko" bedeutet nicht „keine Governance".
Audit Trail: Queries und Responses protokollieren. Jede Response mit den verwendeten Quelldokumenten taggen. Einen Confidence Score oder Zitieranzahl angeben, wo verfügbar. Mindestaufbewahrung: 90 Tage für Debugging, länger für regulierte Branchen.
HITL-Checkpoints: Nicht erforderlich für Read-only-Anwendungsfälle, bei denen Benutzer verstehen, dass sie mit AI interagieren. Erforderlich, wenn RAG-Output in externer Kommunikation verwendet wird: kundenorientierte E-Mail-Entwürfe, regulatorische Einreichungen, Kundenangebote. Wenn der Output das Gebäude verlässt, überprüft zuerst ein Mensch.
Override-Mechanismus: Den Korrekturprozess für die Wissensbasis definieren. Wenn ein Benutzer eine falsche Antwort erkennt, wer kann das Quelldokument aktualisieren? Was ist die SLA für kritische Korrekturen?
Review-Rhythmus: Vierteljährliches Audit der Wissensbasis. Auf veraltete Dokumente, defekte Quelllinks und Themen prüfen, bei denen Benutzeranfragen unbeantwortet bleiben (ein Signal für Wissenslücken). Jährliche Überprüfung der Abrufqualität mit einem Testsatz.
Scoring + Routing Governance
Dieses Pattern trägt eine geringe direkte Governance-Last, aber eine erhebliche Compliance-Exposition, wenn es auf Menschen angewendet wird (Einstellung, Kreditvergabe, Versicherung, Strafjustiz). Wenn Scoring+Routing bestimmt, welche Menschen welche Behandlung erhalten, werden ECOA, DSGVO Artikel 22 und Titel VII alle relevant.
Audit Trail: Jede Scoring-Entscheidung mit den verwendeten Input-Features und dem erzeugten Score protokollieren. Dies ist nicht verhandelbar für jeden regulierten Anwendungsfall. „Unser Modell sagte 62" ist kein Governance-Datensatz. „Modell Version 3.1, Input-Features: Unternehmensgröße=Enterprise, Engagement=hoch, Demo=abgeschlossen, Score=62, weitergeleitet an: Enterprise-West Team" ist einer.
HITL-Checkpoints: Menschlicher Override für jede Routing-Entscheidung verfügbar. Sales Reps sollten Leads manuell neu zuweisen können. Support-Teams sollten Tickets manuell eskalieren können, unabhängig vom AI-Score. Die AI-Route ist ein Standard, keine Sperre.
Override-Mechanismus: Manueller Routing-Bypass für jeden Entscheidungspunkt. Sicherstellen, dass Bypass-Aktionen ebenfalls protokolliert werden. Muster manueller Overrides signalisieren oft Model Drift oder Datenqualitätsprobleme.
Review-Rhythmus: Monatliche Score-Verteilungsüberprüfung. Wenn sich der Median-Score verschiebt oder der High-Score-Bucket dünner wird, hat sich etwas in Ihren Daten oder Ihrem Markt verändert. Vierteljährliche Modellgenauigkeitsüberprüfung gegen zurückgehaltene Testdaten.
Vision Extract Governance
Dieses Pattern ersetzt menschliche Dateneingabe. Die Governance-Frage lautet: Was passiert, wenn es einen Fehler macht, und wer fängt ihn auf?
Audit Trail: Alle extrahierten Datensätze mit dem Quellbild, dem Extraktions-Confidence Score und den extrahierten Feldwerten protokollieren. Quellbilder für die Dauer des geschäftlichen Lebens des Datensatzes speichern.
HITL-Checkpoints: Erforderlich für Low-Confidence-Extraktionen. Definieren Sie Ihren Confidence-Schwellenwert (typischerweise wird alles unter 85 % Genauigkeit bei kritischen Feldern in eine Human Review Queue geleitet). Auch erforderlich für jede Extraktion, die in einer Finanztransaktion ohne zusätzliche Verifizierung verwendet wird.
Override-Mechanismus: Manueller Feldkorrektur-Workflow mit Audit Log. Jede menschliche Korrektur sollte protokolliert werden. Dies ist Ihr Trainingssignal für die Modellverbesserung.
Review-Rhythmus: Monatliche Genauigkeitsstichprobe bei einem Sample von High-Confidence-Extraktionen. Sie suchen nach systematischen Fehlern, die über dem Confidence-Schwellenwert liegen. Hinzufügungen von Dokumenttypen oder Formatänderungen von Vendors sollten eine sofortige Stichprobe auslösen.
Meeting Intelligence Governance
Das Meeting Intelligence Pattern hat zwei unterschiedliche Governance-Bedenken, die die meisten Deployments unterschätzen: Einwilligung und CRM-Datenqualität. Ein vollständiges Beispiel für Governance in einem AI Sales Ops-Kontext finden Sie unter AI Sales Ops Governance und Audit Trails.
Einwilligungsanforderungen: Aufnahme-Einwilligung ist nicht einheitlich. In Einpartei-Einwilligungsstaaten (einschließlich der meisten US-Bundesstaaten) ist die Aufnahme erlaubt, wenn eine Partei zustimmt. In Zweipartei-Bundesstaaten (Kalifornien, Florida, andere) ist die Zustimmung aller Parteien erforderlich. Die DSGVO erweitert die Einwilligungsanforderungen auf EU-Staatsangehörige, unabhängig davon, von wo sie anrufen. Wenn Ihre Reps Meeting Intelligence bei jedem Anruf mit einem europäischen Teilnehmer verwenden, benötigen Sie eine dokumentierte Einwilligung. Das Speichern von Aufnahmen ohne Einwilligung ist eine Haftung, nicht nur ein Compliance-Kontrollkästchen.
Audit Trail: Aufnahmespeicherung mit einem Aufbewahrungsplan, der Ihrer Branche entspricht (typischerweise 1-3 Jahre für Sales-Anrufe, möglicherweise länger für Finanzdienstleistungen oder Gesundheitswesen). CRM-Push-Logs: Wann hat die AI was in welchen Datensatz geschrieben?
HITL-Checkpoints: Menschliche Überprüfung von CRM-Pushes, bevor diese System-of-Record-Daten werden. Der Meeting Intelligence-Output sollte zuerst in einen Staging-Bereich eintreten, nicht direkt in Live-CRM-Felder schreiben. Eine fünfminütige Überprüfung durch einen Rep vor der Genehmigung des Pushes fängt die meisten Fehler ab, ohne die Zeitersparnis zu zerstören.
Override-Mechanismus: Korrektur-Workflow für CRM-Einträge. Fehlerhafte, von der AI geschriebene Notizen sollten mit einem Zeitstempel korrigiert werden können, der zeigt, dass die Korrektur menschlich initiiert wurde.
Review-Rhythmus: Monatliche Stichprobe der CRM-Datenqualität für AI-geschriebene Datensätze. Sind Action Items korrekt? Sind Speaker-Attributionen korrekt? Fassen Zusammenfassungen die richtigen Zusagen auf?
Anomaly Agent Governance
Die primäre Governance-Frage hier sind die Kosten von False Positives: Handeln auf der Grundlage einer Anomalie, die sich als normale Geschäftsvariation herausstellt.
Audit Trail: Alle Alerts mit den Signaldaten, die den Alert ausgelöst haben, dem Confidence-Level des Modells und der Disposition protokollieren (überprüft, verworfen, eskaliert). Dieser Audit Trail ist sowohl für Debugging als auch für False-Positive-Analysen unerlässlich.
HITL-Checkpoints: Menschliche Überprüfung erforderlich, bevor ein Execute-Schritt bei einer gekennzeichneten Anomalie durchgeführt wird. Der Anomaly Agent sollte alarmieren und in die Warteschlange stellen, nicht alarmieren und handeln. Wenn Ihr Pattern einen automatischen Block hat (Betrugsprävention), sollte der Schwellenwert für automatische Aktionen extrem hoch sein, und alle automatischen Aktionen sollten im Nachhinein überprüft werden.
Override-Mechanismus: Flag-Unterdrückung für bekannte False-Positive-Muster. Wenn die Zahlungen eines Vendors aufgrund ihres Abrechnungszyklus immer anomal erscheinen, sollte dieses Muster an der Quelle unterdrückt werden, anstatt es jeden Monat manuell zu überprüfen.
Review-Rhythmus: False-Positive-Rate wird monatlich überprüft. Wenn Ihre False-Positive-Rate über 15 % liegt, frisst der Governance-Overhead den Wert auf. Liegt sie unter 1 %, verpassen Sie möglicherweise echte Anomalien. Der operative Sweet Spot hängt vom Bereich und den Aktionskosten ab.
Generative Research, Document Review und Workflow Copilot
Diese drei Patterns teilen ein gemeinsames Governance-Profil: Das primäre Risiko besteht darin, KI-generierten Text als autoritativ zu verteilen, ohne angemessene Überprüfung.
Generative Research: Jeder Output, der außerhalb des unmittelbaren Teams verteilt wird, erfordert menschliches Fact-Checking anhand primärer Quellen. Der Audit Trail protokolliert Query, zugegriffene Quellen und wer den Output für die Verteilung genehmigt hat. Review-Rhythmus: Monatliche Stichprobe der Ausgabegenauigkeit, insbesondere für Hochrisiko-Anwendungsfälle (Investor Briefs, regulatorische Einreichungen, Kundenlieferungen).
Document Review: Der AI-Output ist ein Flagging-System, kein Rechtsgutachten. Anwälte überprüfen, bevor sie auf eine Kennzeichnung reagieren. Der Audit Trail erfasst welches Dokument, welche Klauseln gekennzeichnet wurden und wie die Disposition des menschlichen Anwalts war. Keine automatisierte Vertragshandlung ohne menschliche Unterzeichnung.
Workflow Copilot: Governance konzentriert sich auf Datenlecks. Welche Daten sieht der Copilot? Wenn er auf das CRM zugreift, kann er auf Datensätze außerhalb des normalen Territoriums eines Reps zugreifen? Datenzugriffsgrenzen für den Copilot müssen definiert und geprüft werden, nicht vorausgesetzt.
Autonomous Agent Governance
Dies ist der kritischste Governance-Abschnitt im Framework und derjenige, den die meisten Implementierungen unterschätzen, bis etwas schiefgeht.
Autonomous Agents durchlaufen alle fünf Capabilities in einer Schleife: Ingest, Analyze, Predict, Generate, Execute, dann wiederholen. Jeder Execute-Schritt hat Konsequenzen. Fehler summieren sich über Iterationen. Ein halluzinierter Zwischenschritt in Schleifeniteration 3 kann eine Sequenz falscher Aktionen in den Iterationen 4 bis 8 antreiben, bevor ein Mensch die Ergebnisse sieht.
Audit Trail: Jeder Tool-Aufruf wird mit Input-Parametern, Output und Entscheidungsbegründung protokolliert (der Generate-Schritt, der die Execute-Entscheidung getrieben hat). Nicht nur „Agent hat E-Mail gesendet", sondern „Agent hat Meeting-Bestätigungsanfrage erhalten, Terminierungsfenster via Kalenderabfrage ermittelt, E-Mail-Entwurf generiert, an externen Kontakt gesendet." Vollständige Provenienz von Absicht bis Aktion.
HITL-Checkpoints (verpflichtend):
- Vor jedem Execute-Schritt, der externe Kommunikation sendet
- Vor jedem Execute-Schritt, der einen Finanzdatensatz ändert
- Vor jedem Execute-Schritt, der einen Datensatz modifiziert, der jemandem außerhalb des Teams des Aufgabenurhebers gehört
- Vor jeder Sequenz von 3 oder mehr Execute-Schritten in einer einzelnen Aufgabe
Dies sind keine Empfehlungen. Sie sind die Mindestanforderung für ein kundenorientiertes Autonomous Agent-Deployment. Jedes Deployment ohne diese Checkpoints setzt darauf, dass der Agent sich nicht in eine irreversible Aktion halluziniert. Diese Wette wird schließlich verloren werden. EU AI Act, Artikel 14 schreibt vor, dass AI-Systeme mit hohem Risiko so gestaltet sein müssen, dass natürliche Personen „Anomalien erkennen und beheben, sich des Automatisierungsbias bewusst sein, den Output des Systems korrekt interpretieren und entscheiden können, das System nicht zu verwenden." Diese Anforderungen entsprechen direkt diesen Checkpoints für jeden Agenten, der in Beschäftigung, Finanzdienstleistungen oder kundenorientierten Kontexten operiert.
Scope-Limits: Definieren Sie eine explizite Allowlist von Tools, auf die der Agent zugreifen kann. Ein Agent, der Meetings planen muss, benötigt keinen Zugriff auf Ihr Abrechnungssystem. Ein Agent, der Account-Research betreibt, benötigt keinen Send-Zugriff auf Ihren E-Mail-Client. Scope-Limits sind Ihre primäre Verteidigung gegen unerwartetes Execute-Verhalten.
Override-Mechanismus: Task-Stop- und Rollback-Fähigkeit. Der Betreiber muss die Fähigkeit haben, eine laufende Agent-Aufgabe mitten in der Ausführung anzuhalten und alle bisher durchgeführten Execute-Schritte rückgängig zu machen. Wenn Ihre Plattform Task-Halt und Rollback nicht unterstützt, ist Ihre Governance-Haltung unabhängig von den von Ihnen geschriebenen Richtlinien schwach.
Review-Rhythmus: Wöchentlich während des Erstdeployments (erste 60 Tage). Monatlich nach etablierter Baseline. Vollständiges Audit aller Execute-Aktionen vierteljährlich, speziell die Überprüfung von Fällen, in denen der Agent Aufgaben auf unerwartete Weise abgeschlossen hat.
| Pattern | Execute-Intensität | Primäre Compliance-Anforderung | Mindest-HITL-Anforderung | Audit Trail-Aufbewahrung |
|---|---|---|---|---|
| RAG Assistant | Keine (Read-only) | Selbstsicher falsche Antworten | Nur für externe Verteilung erforderlich | 90 Tage |
| Scoring + Routing | Leicht (Routing-Entscheidungen) | Algorithmischer Bias bei HR/Kreditvergabe | Menschlicher Override für jede Routing-Entscheidung verfügbar | 12 Monate (reguliert) |
| Vision Extract | Mittel (Dateneingabe-Ersatz) | Genauigkeit von Finanzdatensätzen | Low-Confidence-Extraktionen in Human Review Queue | Dauer des Geschäftslebens des Datensatzes |
| Meeting Intelligence | Leicht (CRM-Push) | Aufnahme-Einwilligung nach Jurisdiktion | Menschliche Überprüfung bevor CRM-Staging live geht | 1-3 Jahre (branchenabhängig) |
| Anomaly Agent | Mittel (Alert + Block) | False-Positive-Aktionskosten | Menschliche Überprüfung vor Execute-Aktion bei gekennzeichnetem Element | 12 Monate |
| Generative Research | Keine (generiert Text) | Halluzinierte Zitate extern verteilt | Menschliches Fact-Checking vor externer Verteilung | 90 Tage |
| Document Review | Keine (kennzeichnet, ändert nicht) | Rechtsgutachten-Haftung wenn als solches behandelt | Anwalts-Review vor Handlung bei einer Kennzeichnung | Vertragslaufzeit |
| Workflow Copilot | Leicht (schlägt vor, Mensch genehmigt) | Datenzugriffsgrenzen-Leck | Menschliche Genehmigung vor dem Senden | 90 Tage |
| Autonomous Agent | Hoch (Multi-Step Execute-Schleife) | Irreversible Aktionen im großen Maßstab auf halluzinierten Prämissen | Vor externer Kommunikation, Finanzänderungen, 3+ Execute-Schritten | Vollständige Provenienz, 2+ Jahre |
Der Per-Pattern Governance Footprint
Der Per-Pattern Governance Footprint ist ein strukturiertes Richtlinienformat, das für jedes aktive AI Pattern-Deployment genau vier Dinge spezifiziert: die Audit Trail-Spezifikation (Format, protokollierte Felder und Aufbewahrungszeitraum), die Human-in-the-Loop-Checkpoints (spezifischer Schritt, Auslösebedingung, wer genehmigt), den Override- und Rollback-Mechanismus (wer kann overriden, wie, mit welchem Datensatz) und die Review- und Retraining-Häufigkeit (wer überprüft, wonach gesucht wird, nach welchem Zeitplan). Das Framework basiert auf dem Prinzip, dass Governance-Anforderungen der Execute-Intensität folgen: Patterns bei den Analyze- und Generate-Schritten tragen begrenzte Governance-Last, während Patterns, die wiederholt, autonom oder im großen Maßstab Execute-Schritte ausführen, eine erhebliche Last tragen, die ihrer Konsequenzoberfläche entspricht.
Rework-Analyse: Basierend auf Compliance Weeks Ergebnis, dass 83 % der Unternehmen AI verwenden, aber nur 25 % starke Governance-Frameworks haben, und dem vollen Enforcement des EU AI Acts auf AI-Systeme mit hohem Risiko im August 2026, stellt der Per-Pattern Governance Footprint die minimal viable Governance-Struktur für jede Organisation dar, die AI in Beschäftigung, Finanzen, Gesundheitswesen oder kundenorientierten Kontexten betreibt. Reworks Governance-Implementierungsdaten zeigen, dass Teams, die den Per-Pattern Governance Footprint vor dem Deployment jedes Patterns definieren, ihre Compliance-Audit-Vorbereitungszeit um durchschnittlich 8 Wochen reduzieren im Vergleich zu Teams, die Governance retrospektiv nach Anforderung durch Regulierungsbehörden oder Vorfällen dokumentieren.
Die Governance-Richtlinie aus diesem Framework aufbauen
Eine musterspezifische Governance-Richtlinie hat diese Struktur:
Pattern-Inventar. Alle aktiven AI Pattern-Deployments in der Organisation auflisten, das Team, das sie besitzt, und die Execute-Aktionen, die sie ausführen können.
Risikoklassifizierung. Anhand der vier obigen Dimensionen jedes Deployment auf einer Skala von 1-5 klassifizieren. Autonomous Agent-Deployments mit Kundenkontakt erhalten 5. Read-only RAG Assistants erhalten 1.
Anforderungstabelle. Für jedes Deployment: Audit Trail-Spezifikation (Format, Felder, Aufbewahrung), HITL-Checkpoints (spezifischer Schritt, spezifische Auslösebedingung), Override-Mechanismus (wer kann overriden, wie, mit welchem Datensatz) und Review-Rhythmus (wer überprüft, wonach gesucht wird, wann).
Eigentümerzuweisung. Jedes Pattern-Deployment hat einen benannten operativen Eigentümer, der für den Review-Rhythmus und die Reaktion auf Vorfälle verantwortlich ist.
Incident Response-Verfahren. Wenn ein Pattern einen Output produziert, der Schaden verursacht (falsche Aktion durchgeführt, Daten durchgesickert, Halluzination extern verteilt), wer wird benachrichtigt, wer untersucht, und was sind die Entscheidungspunkte für Aussetzung vs. fortgesetzten Betrieb mit zusätzlichen Kontrollen?
Dies ist keine Compliance-Übung. Es ist das Betriebsverfahren, das es Ihnen ermöglicht, High-Autonomy-Patterns sicher zu betreiben. Ohne es ist jedes Autonomous Agent-Deployment einen Vorfall davon entfernt, dauerhaft abgeschaltet zu werden.
Das Ziel von Governance ist nicht, die AI-Adoption zu verlangsamen. Es ist, die Adoption dauerhaft zu machen. Die OECD-AI-Prinzipien, die von 42 Ländern übernommen wurden und eine grundlegende Referenz für den EU AI Act und das NIST-Framework sind, beschreiben Rechenschaftspflicht als Kernprinzip: AI-Akteure sind für das ordnungsgemäße Funktionieren von AI-Systemen und die Einhaltung geltender Normen verantwortlich. Musterspezifische Governance ist der Weg, wie diese Rechenschaftspflicht operativ statt aspirationell wird. Beginnen Sie mit Hallucination Risk by Pattern für die spezifischen Fehlermodelle, die Governance entwerfen soll zu fangen, und Measuring ROI by Pattern für die Audit-Trail-Daten, die in Ihre ROI-Analyse einfließen.
Häufig gestellte Fragen
Warum benötigen AI Patterns musterspezifische Governance statt einer einzigen Richtlinie?
Weil Governance-Anforderungen der Execute-Intensität folgen und die Execute-Intensität über Patterns hinweg erheblich variiert. Ein RAG Assistant, der Mitarbeiterfragen beantwortet, trägt fast kein Execute-Risiko. Ein Autonomous Agent, der E-Mails sendet, Finanzdatensätze aktualisiert und Meetings plant, trägt erhebliches Irreversibilitätsrisiko. Eine einzige Richtlinie, die beide abdeckt, regelt entweder den RAG Assistant zu eng (verlangsamt die Adoption) oder den Autonomous Agent zu locker (schafft Vorfallrisiko).
Was ist der Per-Pattern Governance Footprint?
Der Per-Pattern Governance Footprint spezifiziert vier Dinge für jedes aktive AI Pattern: die Audit Trail-Spezifikation (Format, Felder, Aufbewahrung), Human-in-the-Loop-Checkpoints (spezifischer Schritt und Auslösebedingung), Override- und Rollback-Mechanismus (wer kann overriden, wie, mit welchem Datensatz) und Review- und Retraining-Häufigkeit. Er transformiert generische Governance-Aussagen in operative Verfahren, die geprüft, geschult und Regulierungsbehörden gezeigt werden können.
Welche EU AI Act-Anforderungen gelten für Autonomous Agent-Deployments?
Artikel 14 schreibt vor, dass AI-Systeme mit hohem Risiko es Menschen ermöglichen müssen, Anomalien zu erkennen und zu beheben, sich des Automatisierungsbias bewusst zu sein, System-Outputs korrekt zu interpretieren und zu entscheiden, das System nicht zu verwenden. Dies entspricht direkt vier Autonomous Agent-Governance-Anforderungen: Task-Halt- und Rollback-Fähigkeit, False-Positive-Protokollierung und Review-Rhythmus, vollständige Provenienz-Audit-Trails von Absicht bis Aktion und menschliche Genehmigung vor irreversiblen Execute-Schritten. EU AI Act-Verstöße können mit bis zu 35 Millionen Euro oder 7 % des globalen Umsatzes für verbotene Praktiken geahndet werden.
Wie oft sollten AI Patterns auf Model Drift überprüft werden?
Scoring and Routing-Modelle sollten monatlich auf Score-Verteilungsänderungen und vierteljährlich auf Genauigkeit gegen zurückgehaltene Testdaten überprüft werden. Anomaly Agents sollten ihre False-Positive-Rate monatlich überprüfen. RAG Assistants benötigen vierteljährliche Wissensbasen-Audits. Autonomous Agents sollten in den ersten 60 Tagen wöchentlich, dann monatlich, mit einem vollständigen vierteljährlichen Audit aller Execute-Aktionen überprüft werden. Model Drift ist die häufigste Governance-Lücke in Deployments im zweiten Jahr, weil Teams Review-Rhythmen in Startpläne einbauen und sie dann deprioritisieren, wenn sich andere Arbeit ansammelt.
Was ist der kritischste Governance-Fehlerfall bei Autonomous Agents?
Deployment ohne Task-Halt- und Rollback-Fähigkeit. Autonomous Agents durchlaufen alle fünf ACE-Capabilities in einer Schleife, was bedeutet, dass jeder Execute-Schritt auf dem vorherigen aufbaut. Ein halluzinierter Zwischenschritt in Schleifeniteration 3 kann eine Sequenz falscher Aktionen in den Iterationen 4-8 antreiben, bevor ein Mensch die Ergebnisse sieht. Ohne die Möglichkeit, den Agenten mitten in der Ausführung anzuhalten und bereits durchgeführte Execute-Schritte rückgängig zu machen, ist die Governance-Haltung theoretisch statt operativ. Wenn Ihre Agentenplattform Task-Halt und Rollback nicht unterstützt, ist dies eine Blockieranforderung vor dem Deployment.
Wie schaffen Scoring and Routing Patterns Compliance-Risiken in HR-Kontexten?
Wenn Scoring and Routing bestimmt, welche Kandidaten in einem Einstellungsprozess vorankommen, gelten EEOC Titel VII, DSGVO Artikel 22 und aufkommende staatliche AI-Vorurteils-Gesetze. Das Modell darf keine geschützten Merkmale als Features verwenden (oder Features, die als Proxies für geschützte Merkmale dienen). Audit Trails müssen jede Scoring-Entscheidung mit den verwendeten Input-Features protokollieren. Menschlicher Override muss für jede Routing-Entscheidung verfügbar sein.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Warum Governance musterspezifisch ist
- Die vier Governance-Dimensionen
- RAG Assistant Governance
- Scoring + Routing Governance
- Vision Extract Governance
- Meeting Intelligence Governance
- Anomaly Agent Governance
- Generative Research, Document Review und Workflow Copilot
- Autonomous Agent Governance
- Der Per-Pattern Governance Footprint
- Die Governance-Richtlinie aus diesem Framework aufbauen
- Mehr erfahren