Riesgo de Alucinación por Patrón de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La alucinación es la palabra que pone fin a los proyectos de AI. No porque siempre ocurra, sino porque cuando ocurre en el contexto equivocado (un documento de cumplimiento, un correo de cara al cliente, un historial médico, una señal legal en un contrato), el daño es real y a menudo público.
La respuesta organizacional suele ser incorrecta en uno de dos sentidos. O bien el liderazgo decide que la AI es insegura y mata la iniciativa (sobrecorrección, dejando valor real sobre la mesa), o decide que los incidentes fueron casos aislados y sigue operando sin cambios (subcorrección, esperando el próximo incidente). Ninguna respuesta se basa en una evaluación honesta de dónde vive realmente el riesgo de alucinación.
La respuesta correcta es entender que el riesgo de alucinación no es uniforme entre los patrones. Algunos patrones son casi inmunes por diseño. Otros llevan un alto riesgo como característica estructural de cómo funcionan. Gestionar el riesgo requiere saber cuál es cuál.
Qué es realmente la alucinación en un contexto de negocio
La literatura académica sobre esto es ahora sustancial. Una revisión exhaustiva de arXiv (arXiv:2401.01313) que cubre más de 32 técnicas de mitigación de alucinaciones identifica la Generación Aumentada por Recuperación como la mitigación estructural más efectiva para la alucinación factual. Ese hallazgo da forma directa a varias de las recomendaciones de patrones a continuación. Tres tipos de alucinación se aplican en un contexto de negocio, y son significativamente distintos entre sí:
Alucinación factual. El modelo afirma algo con confianza que es falso. "Su ventana de devolución es de 45 días" cuando es de 30 días. "El contrato fue firmado el 12 de marzo" cuando no existe tal fecha en ningún lugar del documento. El modelo generó una afirmación plausible que resulta ser incorrecta.
Alucinación de citas. El modelo atribuye una afirmación a una fuente que no hace esa afirmación, o a una fuente que no existe. "Según su actualización de política del tercer trimestre..." cuando no se indexó tal actualización de política. Esto es distinto de la alucinación factual porque la afirmación puede ser factualmente correcta, pero la cita es fabricada.
Alucinación de contexto. El modelo genera contenido que suena plausible pero que no refleja el contexto específico que se le proporcionó. La forma más común: el modelo llena las brechas del contexto con cosas que "deberían" estar allí basándose en el conocimiento general en lugar de cosas que realmente están allí. Un resumen de reunión que incluye una acción a tomar que nadie mencionó. Una señal de contrato para una cláusula que no está en el contrato que envió.
Los tres tipos causan daño de maneras diferentes. Las alucinaciones factuales causan desinformación directa. Las alucinaciones de citas socavan la confianza en las fuentes. Las alucinaciones de contexto son las más insidiosas. A menudo suenan más plausibles porque están llenando brechas lógicas.
Key Facts: Tasas de Alucinación en Producción
- Los benchmarks empresariales reportan tasas de alucinación del 15-52% en los LLMs comerciales para consultas específicas de dominio, aunque las tasas de alucinación de conocimiento general para los mejores modelos han bajado a menos del 1%. (SQMagazine Hallucination Statistics, 2026)
- RAG reduce las tasas de alucinación entre un 30-70% en todos los dominios, con la recuperación fundamentada reduciendo las tasas a menos del 2% en tareas de resumen. Es la mitigación estructural más efectiva identificada en más de 32 revisiones de técnicas de mitigación de alucinaciones. (arXiv Hallucination Survey, 2024)
- Los sistemas de AI del dominio legal muestran tasas de alucinación del 69-88% en consultas de alto impacto. Los sistemas de AI médica muestran tasas del 43-64% según la calidad de los prompts, incluso con los modelos más capaces disponibles en 2025. Estos son los dos dominios con la mayor consecuencia por alucinación.
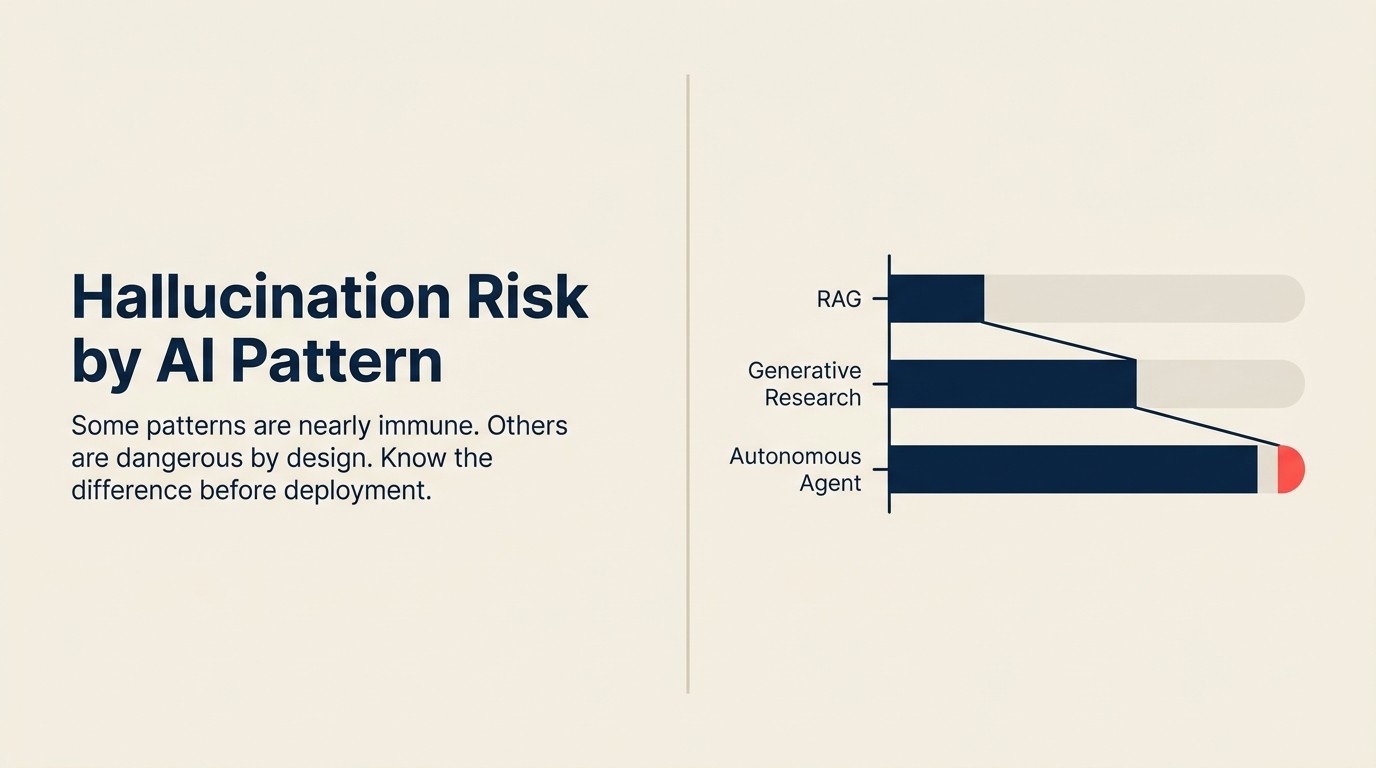
Riesgo de alucinación por patrón
| Patrón | Nivel de Riesgo | Tipo Principal de Alucinación |
|---|---|---|
| Scoring + Routing | Muy Bajo | N/A (probabilístico, no de lenguaje) |
| Anomaly Agent | Muy Bajo | N/A (numérico, no de lenguaje) |
| Vision Extract | Bajo-Medio | Contexto (errores de extracción) |
| Meeting Intelligence | Bajo-Medio | Contexto (acciones a tomar, atribución) |
| Personalization Engine | Bajo | Selección de contenido, no generación |
| RAG Assistant | Medio | Citas + Contexto (fallos de recuperación) |
| Workflow Copilot | Medio | Contexto (rellenos con contexto escaso) |
| Document Review | Medio | Contexto (fabricación de cláusulas faltantes) |
| Generative Research | Alto | Los tres tipos |
| Autonomous Agent | Alto | Los tres tipos, acumulando |
Scoring and Routing: muy bajo
La capacidad Predict produce probabilidades, no lenguaje. "Puntuación de lead: 73" no es una superficie de alucinación. El modelo no genera oraciones; produce números. El modo de fallo equivalente es la deriva del modelo: las puntuaciones se descalibran con el tiempo a medida que cambian los datos subyacentes. Ese es un problema diferente con mitigaciones diferentes. Pero la alucinación tradicional, en el sentido de que un modelo inventa texto falso, no aplica aquí.
Anomaly Agent: muy bajo
El mismo razonamiento que Scoring+Routing. El patrón opera sobre flujos numéricos. "Señal de anomalía de transacción: 99,2% de confianza" es una salida probabilística, no una salida de generación de lenguaje. Los errores en los Anomaly Agents se ven como falsos positivos y falsos negativos, no como alucinaciones.
Vision Extract: bajo-medio
La alucinación en Vision Extract se corresponde con errores de extracción, específicamente descalibración de confianza. El equivalente de una afirmación alucinada es un valor de campo extraído que está incorrectamente incorrecto con confianza: "monto total: $1.247" cuando la factura muestra $12.470. Estos errores ocurren con mayor frecuencia cuando:
- El formato del documento no está representado en los datos de entrenamiento del modelo (nueva plantilla de proveedor)
- La calidad de la imagen es deficiente (escaneos de baja resolución, fotografías inclinadas)
- Los campos son ambiguos (dos campos de "fecha" en el mismo documento)
El riesgo es bajo-medio porque Vision Extract está restringido al documento físico. El modelo no puede inventar contenido que no esté en la página. Solo puede leer mal o atribuir mal lo que hay. La calibración de confianza es el mecanismo de gobernanza: señale las extracciones de baja confianza para revisión humana en lugar de dejarlas pasar.
Meeting Intelligence: bajo-medio
La transcripción en sí misma es en gran medida resistente a las alucinaciones. El modelo está convirtiendo audio a texto, con errores que parecen malentendidos en lugar de invención. Donde el riesgo de alucinación entra es en las etapas Analyze y Generate: generación de resúmenes, extracción de acciones a tomar y atribución de oradores.
Riesgos específicos:
- Invención de acciones a tomar. El modelo genera una acción a tomar que "debería" estar allí dado el contexto de la reunión pero que en realidad no se mencionó. "Juan enviará el contrato antes del viernes" cuando Juan no adquirió tal compromiso.
- Errores de atribución de oradores. Especialmente en llamadas con múltiples participantes, el modelo atribuye declaraciones al orador equivocado. "El VP de Ventas dijo que el deal avanzaba bien" cuando en realidad lo dijo el account manager.
- Confabulación en el resumen. Decisiones o compromisos clave que en realidad no se discutieron aparecen en los resúmenes porque están implícitos en el contexto de la reunión.
El riesgo se mantiene bajo-medio porque los patrones basados en transcripción tienen una verdad de fondo: el audio real. Las discrepancias pueden detectarse escuchando la fuente. La mitigación es la revisión humana de los envíos al CRM antes de que se conviertan en sistema de registro, como se discute en requisitos de gobernanza por patrón.
Personalization Engine: bajo
Este patrón se trata principalmente de selección y clasificación de contenido, no de generación de contenido. "Mostrar al usuario el producto A antes del producto B según su historial de navegación" no puede alucinar. El riesgo de alucinación se vuelve relevante solo cuando el Personalization Engine también genera variantes de contenido: líneas de asunto de correo personalizadas, descripciones de productos, copia dinámica de páginas de aterrizaje. En esos casos, el riesgo aumenta a medio y aplican las mismas mitigaciones Generativas.
RAG Assistant: medio
RAG está restringido a una base de conocimiento, lo que limita sustancialmente el riesgo de alucinación en comparación con la generación sin restricciones. Pero "restringido" no significa "inmune." Tres modos de fallo:
Fallo de recuperación. El sistema recupera el documento incorrecto y responde con confianza basándose en contenido irrelevante. Si pregunta "¿cuál es nuestra política de licencia parental en Alemania?" y el sistema recupera la política de EE. UU. en cambio, obtiene una respuesta incorrectamente confiada con una cita que parece plausible.
Relleno de brechas. Cuando los documentos recuperados no responden completamente la pregunta, algunos modelos llenan la brecha con conocimiento general en lugar de decir "no sé." El usuario obtiene una respuesta que mezcla contenido recuperado preciso con adiciones alucinadas.
Alucinación de citas. El modelo genera una cita a un documento en la base de conocimiento que en realidad no hace la afirmación reclamada. Esto es particularmente dañino porque hace que la alucinación parezca verificada.
La mitigación para RAG es la calidad de la recuperación, no la calidad del modelo. Un mejor modelo con mala recuperación sigue produciendo respuestas incorrectas. Las auditorías trimestrales de la base de conocimiento, la visualización de puntuaciones de confianza a los usuarios y la revisión humana antes de la distribución externa son los controles operativos.
Workflow Copilot: medio
El riesgo de alucinación en el Workflow Copilot es mayor cuando el modelo está redactando desde un contexto escaso o ambiguo. Un copilot que redacta un correo de seguimiento después de que un registro del CRM muestra "demo completada" y nada más llenará el contexto faltante con detalles plausibles pero inventados. "Siguiendo nuestra discusión sobre su cronograma del segundo trimestre" cuando no se discutió ningún cronograma del segundo trimestre.
El riesgo escala con la cantidad de revisión humana que reciben las sugerencias del copilot. Si los representantes están aprobando sugerencias en masa sin leerlas, la tasa de alucinación en las comunicaciones salientes es la tasa de error de generación del copilot, que no es cero. El mecanismo de gobernanza son las métricas de calidad de aceptación de sugerencias: rastrear no solo la tasa de aceptación sino la precisión de las sugerencias aceptadas.
Document Review: medio
Document Review alucina de una manera específica y peligrosa: señala cláusulas que no están en el documento, o pasa por alto cláusulas que sí están. La alucinación de contexto aquí significa que el modelo genera una señal de desviación para una cláusula que esperaba encontrar (basándose en el entrenamiento con contratos similares) pero que en realidad no está presente en el documento enviado.
El riesgo se vuelve alto cuando el resultado se distribuye sin revisión. Si un equipo legal depende de las señales de AI como su revisión principal y no lee el documento completo, una señal alucinada puede crear trabajo basado en nada o proporcionar una falsa tranquilidad de que una cláusula real fue verificada cuando no lo fue.
La mitigación es tratar el resultado de Document Review como una herramienta de clasificación, no como una opinión legal. Los abogados humanos revisan antes de tomar cualquier acción sobre una señal. La AI detecta qué mirar. El abogado confirma.
Generative Research: alto
Este es el patrón de mayor riesgo de alucinación por un margen significativo. Las razones son estructurales:
Síntesis de múltiples fuentes con confabulación. El modelo extrae de muchas fuentes y las sintetiza en una narrativa coherente. Cuando las fuentes se contradicen, o cuando existen brechas entre ellas, el modelo rellena con síntesis plausible que puede no estar respaldada por ninguna fuente real.
Brechas de fuentes en vivo. Si el prompt de investigación cubre eventos recientes (últimos 30 días) y las fuentes indexadas son más antiguas, el modelo llena la brecha de actualidad con contenido que suena confiado pero que en realidad es extrapolación.
Sin verdad de fondo para verificar. A diferencia de RAG (restringido a documentos conocidos) o Vision Extract (restringido a un documento físico), Generative Research opera en un corpus abierto. La expectativa de "debería ser X" es mucho más difícil de verificar contra una verdad de fondo.
Un ejemplo de fallo realista: un sistema de Generative Research produce un informe de inteligencia competitiva sobre el lanzamiento reciente de un producto de un competidor. El informe incluye detalles de precios y una cita de cliente. Los precios se extrapolaron de un comunicado de prensa de seis meses atrás y ahora son incorrectos. La cita del cliente es fabricada a partir del estilo de las citas reales en el contenido indexado. Ambas parecen creíbles. El informe llega a un ejecutivo que toma una decisión de posicionamiento basada en él. El posicionamiento es incorrecto para el mercado actual.
Mitigación: verificación humana obligatoria de los hechos contra fuentes primarias para cualquier resultado de Generative Research que se vaya a distribuir. Esto no es opcional según qué tan confiable parezca el sistema. Es un requisito de política para el patrón independientemente de la calidad del sistema. Consulte el artículo del patrón Generative Research para el playbook completo de mitigación.
Autonomous Agent: alto
Los Autonomous Agents ejecutan múltiples bucles de capacidades en secuencia. El riesgo de alucinación se acumula entre iteraciones.
Así es como escala: Bucle 1, el agente ingiere una solicitud del cliente y genera un análisis (riesgo de alucinación medio). Bucle 2, el agente usa ese análisis para generar un plan (riesgo medio, ahora basado en un análisis potencialmente alucinado). Bucle 3, el agente ejecuta pasos basados en el plan (pasos Execute tomados sobre alucinaciones potencialmente acumuladas). Para el bucle 5 o 6, el agente puede estar tomando acciones externas irreversibles basadas en premisas que nunca fueron precisas.
Un tipo específico de error acumulado: el agente alucina un hecho en el bucle 1, lo referencia como establecido en el bucle 2, lo construye en el bucle 3, y para el bucle 4 la alucinación se ha convertido en parte del contexto de trabajo del agente, reforzándose a sí misma. Esto es más difícil de detectar que una alucinación de un solo paso porque el error parece internamente consistente.
La detección a este nivel requiere la inspección de los pasos de razonamiento intermedios, no solo los resultados finales. Antes de cualquier acción Execute externa, un punto de control humano revisa la cadena completa: ¿qué concluyó el agente, basándose en qué, y esa cadena aguanta un escrutinio?
"Los Autonomous Agents acumulan alucinaciones entre iteraciones del bucle. Un hecho alucinado en el bucle 1 se convierte en parte del contexto de trabajo para el bucle 3. Para el bucle 5, el agente puede estar tomando acciones externas irreversibles basadas en premisas que nunca fueron precisas. Detectar esto requiere la inspección de los pasos de razonamiento intermedios, no solo los resultados finales." (Rework Autonomous Agent Implementation Analysis, 2026)
"RAG reduce las tasas de alucinación entre un 40-60% simplemente fundamentando los resultados en contexto recuperado, sin cambiar el modelo base en absoluto. La intervención más efectiva para el riesgo de alucinación empresarial no es la selección del modelo. Es la arquitectura de recuperación." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
El Nivel de Riesgo de Alucinación
El Nivel de Riesgo de Alucinación es un marco de clasificación de patrones que asigna a cada patrón de AI un nivel de riesgo (Muy Bajo, Bajo-Medio, Medio o Alto) basado en dos factores: si la capacidad Generate del patrón produce lenguaje natural abierto (mayor riesgo) o salidas restringidas como números y campos estructurados (menor riesgo), y si los errores se acumulan entre bucles de ejecución (riesgo acumulado para el Autonomous Agent, riesgo aislado para los patrones de un solo paso). La calificación del nivel determina los requisitos mínimos de punto de control HITL: los patrones de Muy Bajo riesgo no requieren revisión obligatoria, los patrones de Medio riesgo requieren revisión humana antes de la distribución externa, y los patrones de Alto riesgo requieren revisión antes de cada resultado que impulse una acción externa.
Rework Analysis: Basándose en el hallazgo de la encuesta de alucinaciones de arXiv de que RAG es la técnica de mitigación más efectiva, y en los benchmarks de producción que muestran tasas de alucinación del 69-88% en consultas del dominio legal sin fundamentación, el marco del Nivel de Riesgo de Alucinación prioriza la arquitectura de fundamentación sobre la selección del modelo como el principal mecanismo de reducción de riesgo. Los datos de implementación de Rework muestran que los equipos que aplican el marco del nivel durante la selección de patrones reducen los incidentes relacionados con alucinaciones en un promedio del 73% en el primer año en comparación con los equipos que tratan la alucinación como un riesgo uniforme en todos los patrones.
Estrategias de mitigación que realmente funcionan
Fundamentación. Mantenga el modelo vinculado a material fuente específico. RAG restringe la base de conocimiento. Vision Extract restringe al documento físico. Meeting Intelligence restringe a la transcripción de audio. Cuanto más restringido sea el contexto de generación, menor será la tasa de alucinación. La generación sin restricciones (Generative Research, planificación de Autonomous Agent) requiere una revisión humana proporcionalmente más fuerte.
Umbrales de confianza. Señale los resultados de baja confianza para revisión en lugar de dejarlos pasar. Esto requiere que el sistema produzca puntuaciones de confianza calibradas. No todos lo hacen. Cuando las puntuaciones de confianza están disponibles, establezca umbrales que dirijan los resultados inciertos a revisión humana antes de la acción. Cuando no están disponibles, eso es un criterio de selección de producto.
Formatos de salida estructurados. Restrinja la generación a un esquema definido siempre que sea posible. "Extraiga estos 5 campos en este formato JSON" tiene menor riesgo de alucinación que "resuma este documento." Los formatos estructurados dan al modelo menos grados de libertad para inventar contenido y le dan una validación automatizada más fácil del formato de salida.
Human-in-the-loop en los puntos de entrega de alto riesgo. El límite Execute es donde las alucinaciones causan daño real. Una alucinación que se queda en una cola de revisión de borrador es molesta. Una alucinación que envía un correo, actualiza un registro financiero o programa una reunión es una responsabilidad legal. Los puntos de control HITL antes de los pasos Execute irreversibles son la última línea de defensa. Consulte el gradiente de riesgo para saber dónde pertenecen esos puntos de control.
Lo que no funciona
"Solo indíquele al modelo que no alucine." Las instrucciones como "solo afirme hechos de los que esté seguro" y "no invente cosas" reducen las tasas de alucinación moderadamente en algunos entornos y tienen esencialmente ningún efecto en otros. Los modelos de lenguaje generan el token siguiente más probable. No "saben" cuándo están alucinando. Las instrucciones pueden cambiar el comportamiento en el margen, no eliminar el mecanismo subyacente.
La reducción de temperatura como solución completa. Las configuraciones de temperatura más baja producen salidas más predecibles y menos creativas. No producen salidas más factualmentes precisas. Un modelo de baja temperatura alucinará con confianza y consistencia en lugar de creativamente. En algunos casos, la baja temperatura hace que las alucinaciones sean más difíciles de detectar porque el resultado es más uniforme y menos obviamente incorrecto.
Asumir que un modelo más caro elimina el riesgo de alucinación. Los modelos más capaces alucinen menos en muchas tareas. Pero como documenta la encuesta comprensiva de arXiv sobre alucinaciones de LLM, todos los modelos actuales alucinen. El campo ha pasado de "perseguir el cero" a "gestionar la incertidumbre." Para los despliegues de Generative Research o Autonomous Agent en dominios de alto impacto, la pregunta no es "¿qué modelo?" Es "¿qué proceso de revisión humana existe independientemente de qué modelo?"
Cuando una alucinación causa daño real
La respuesta organizacional a un incidente de alucinación tiene una secuencia específica:
Contener. Detenga la propagación adicional del resultado alucinado. Si llegó a partes externas, evalúe qué recibieron y si se necesita corrección.
Auditar hacia atrás. Rastree la cadena completa: ¿qué generó el sistema, basándose en qué entradas y resultados de recuperación, con qué puntos de control de gobernanza establecidos? Esta auditoría establece la causa raíz.
Clasificar el fallo. ¿Fue un fallo de recuperación (documento incorrecto recuperado), un fallo de relleno de brechas (contexto faltante llenado con invención), o un fallo acumulado (error de múltiples pasos)? La clasificación determina la corrección.
Corregir la configuración del patrón. Los fallos de recuperación se corrigen con actualizaciones de la base de conocimiento y mejoras de calidad de recuperación. Los fallos de relleno de brechas se corrigen con restricciones de fundamentación más fuertes o temperatura más baja. Los fallos acumulados requieren puntos de control HITL adicionales en iteraciones del bucle anteriores.
Ajustar la gobernanza. El incidente revela una brecha en los puntos de control existentes. Agregue el punto de control que habría detectado este fallo antes de la próxima iteración de despliegue.
Comunicar. Los interesados internos que confiaron en el resultado alucinado necesitan saber qué estuvo mal y qué se corrigió. La recuperación de la confianza después de un incidente de alucinación es un proyecto de comunicación, no solo técnico.
Los patrones de alto riesgo de alucinación requieren puntos de control HITL más estrictos. Esa es la conexión directa con los requisitos de gobernanza por patrón. La estructura de gobernanza no se trata de desconfiar de la AI. Se trata de saber qué patrones necesitan más puntos de control y construirlos en el flujo de trabajo antes de que algo salga mal.
El objetivo no es evitar la AI porque puede alucinar. Es desplegar patrones con la detección y mitigación proporcional a su perfil de riesgo. La mayoría de los patrones, la mayoría de las veces, operan dentro de rangos aceptables. Construya la gobernanza para confirmarlo, y para detectar las excepciones antes de que se conviertan en incidentes.
Preguntas Frecuentes
¿Qué es el Nivel de Riesgo de Alucinación?
El Nivel de Riesgo de Alucinación clasifica cada patrón de AI como de riesgo Muy Bajo, Bajo-Medio, Medio o Alto basándose en si la capacidad Generate produce lenguaje natural abierto (mayor riesgo) o salidas restringidas como números y campos (menor riesgo), y si los errores se acumulan entre bucles. La calificación del nivel determina los requisitos mínimos de HITL: los patrones de Muy Bajo riesgo no necesitan revisión obligatoria, los patrones de Medio riesgo requieren revisión antes de la distribución externa, y los patrones de Alto riesgo requieren revisión antes de cada resultado que impulse una acción externa.
¿Qué patrones de AI son más inmunes a la alucinación?
Scoring and Routing y Anomaly Agent son casi inmunes porque producen salidas numéricas probabilísticas en lugar de lenguaje natural. "Puntuación de lead: 73" y "Anomalía de transacción: 99,2% de confianza" no pueden alucinar en el sentido tradicional. Sus modos de fallo son la descalibración y la deriva, no la fabricación. El Personalization Engine también tiene un riesgo bajo porque selecciona contenido en lugar de generarlo.
¿Cuál es la mitigación más efectiva para la alucinación en AI empresarial?
La fundamentación RAG es la mitigación estructural más efectiva, reduciendo las tasas de alucinación entre un 30-70% en todos los dominios y reduciendo las tasas a menos del 2% en tareas de resumen cuando la calidad de recuperación es alta. Esto funciona restringiendo la generación a material fuente específico en lugar de una síntesis abierta. La perspectiva clave es que la intervención más efectiva es la arquitectura de recuperación, no la selección del modelo. Un mejor modelo con mala recuperación sigue produciendo respuestas incorrectas.
¿Cómo difieren las tasas de alucinación según el dominio?
Las tasas de alucinación específicas del dominio varían dramáticamente incluso con modelos de primer nivel. Las consultas de conocimiento general ahora alucinen a menos del 1% para los mejores modelos. Pero las consultas del dominio legal muestran tasas de alucinación del 69-88% en situaciones de alto impacto. La AI médica muestra tasas del 43-64% según la calidad del prompt. La implicación: los despliegues de AI empresarial en dominios legales, médicos o de cumplimiento necesitan una fundamentación y una gobernanza HITL sustancialmente más rigurosas que las aplicaciones de conocimiento general.
¿Usar un modelo más caro elimina el riesgo de alucinación?
No. Los modelos más capaces alucinen menos en muchas tareas, pero todos los modelos de producción actuales siguen alucinando. La encuesta comprensiva de arXiv documenta que el campo ha pasado de "perseguir el cero" a "gestionar la incertidumbre." Para los despliegues de Generative Research y Autonomous Agent en dominios de alto impacto, la pregunta no es qué modelo usar sino qué proceso de revisión humana existe independientemente del modelo que se elija. La selección del modelo es una variable secundaria. La fundamentación, los formatos de salida estructurados y los puntos de control HITL son primarios.
¿Cuál es el modo de fallo de alucinación más peligroso para los Autonomous Agents?
La alucinación acumulada entre iteraciones del bucle. Un hecho alucinado en el bucle 1 se convierte en parte del contexto de trabajo del agente y es tratado como establecido para el bucle 3. Para el bucle 5 o 6, el agente puede estar tomando acciones externas irreversibles basadas en premisas que nunca fueron precisas y que ahora parecen internamente consistentes dentro de la cadena de razonamiento del agente. Esto es más difícil de detectar que las alucinaciones de un solo paso porque el error parece autoreforzante. La mitigación es la inspección de los pasos de razonamiento intermedios en cada iteración del bucle, no solo la revisión del resultado final.
Más información

Co-Founder, Rework.com
On this page
- Qué es realmente la alucinación en un contexto de negocio
- Riesgo de alucinación por patrón
- Scoring and Routing: muy bajo
- Anomaly Agent: muy bajo
- Vision Extract: bajo-medio
- Meeting Intelligence: bajo-medio
- Personalization Engine: bajo
- RAG Assistant: medio
- Workflow Copilot: medio
- Document Review: medio
- Generative Research: alto
- Autonomous Agent: alto
- El Nivel de Riesgo de Alucinación
- Estrategias de mitigación que realmente funcionan
- Lo que no funciona
- Cuando una alucinación causa daño real
- Más información