Autonomous Agent: Multi-Step-Ziele mit Tool Use
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Jedes andere Pattern behandelt eine einzelne, definierte Aufgabe. Der Autonomous Agent behandelt ein Ziel.
Dieser Unterschied ist alles.
Eine Aufgabe hat einen definierten Input und einen definierten Output. Dieses Meeting zusammenfassen. Diesen Lead bewerten. Diese E-Mail entwerfen. Der Weg ist klar. Ein Durchlauf durch die Capability-Kette, fertig.
Ein Ziel ist anders. "Diesen Account recherchieren und ein Meeting buchen" erfordert eine Reihe von Entscheidungen: welche Quellen zu lesen, welche Signale wichtig sind, wie das Outreach zu formulieren ist, was zu tun ist, wenn der Interessent die E-Mail zurückweist, wann aufzuhören ist. Der Agent kann den Weg nicht im Voraus kennen, weil der Weg davon abhängt, was er unterwegs antrifft.
Das macht autonome Agents mächtig. Und das ist genau das, was sie gefährlich macht, wenn das Ziel schlecht spezifiziert ist, die Tools falsch konfiguriert sind oder die Fehlerdetection schwach ist.
Dieser Artikel überhöht autonome Agents nicht. Er erklärt, was sie sind, wo sie funktionieren, was schiefläuft und wie man sie regiert, wenn man sich für ihren Einsatz entscheidet. OpenAIs praktischer Leitfaden zum Aufbau von Agents empfiehlt, mit einem einzelnen Agent zu beginnen und nur dann zu Multi-Agent-Systemen zu wechseln, wenn es nötig ist, wobei Use Cases mit komplexer Entscheidungsfindung, unstrukturierten Daten und schwer zu pflegenden Regeln Priorität haben.
Die Formel
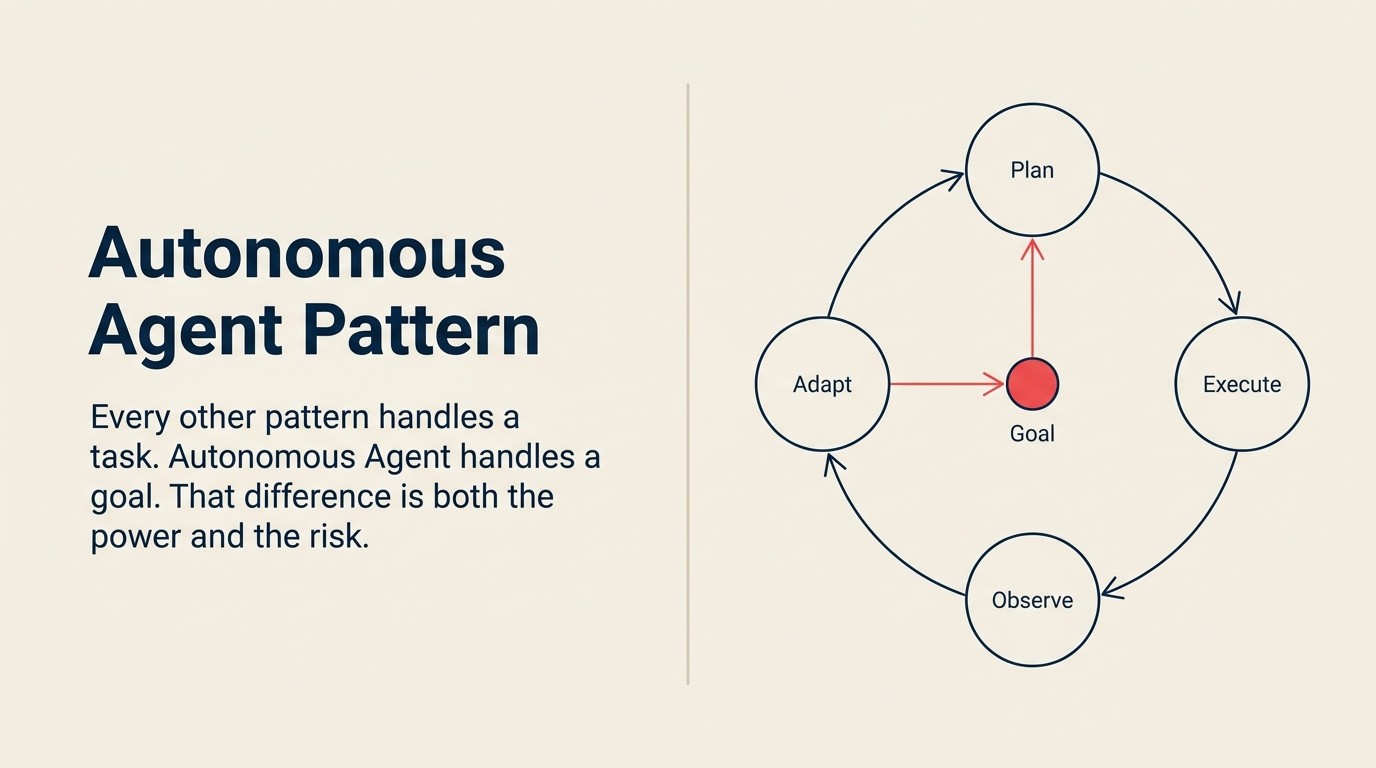
Autonomous Agent ist das einzige Pattern, das alle fünf ACE-Capabilities in einer Schleife verwendet:
Ingest (aktueller Zustand plus verfügbare Tools) → Analyze (Was weiß ich, was brauche ich?) → Predict (Welche Aktion bringt das Ziel am wahrscheinlichsten voran?) → Generate (Plan oder nächste Aktion) → Execute (Aktion ausführen, Zustand aktualisieren) → wiederholen bis Ziel erreicht oder maximale Schrittzahl erreicht
Jedes Element der Schleife trägt spezifische Bedeutung:
Ingest ist nicht nur das Lesen der initialen Aufgabe. Bei jeder Schleifeniteration nimmt der Agent den aktuellen Zustand der Welt auf. Was hat die letzte Aktion produziert? Welche Tools sind verfügbar? Was hat der Agent seit dem Start der Schleife gelernt? In einem Recherche-Agent enthält Ingest bei Iteration 3 den Inhalt der bereits gelesenen zwei Seiten, die Abfragen, die leere Ergebnisse zurückgaben, und die Tatsache, dass das Zielunternehmen vor 8 Monaten seinen Namen geändert hat.
Analyze bestimmt, was der Agent weiß und was er noch braucht, um das Ziel zu erreichen. Es ist eine fortlaufende Gap-Analyse: Hier ist, was ich habe, hier ist, was ich brauche, hier ist, was noch fehlt. Hier entscheidet der Agent, ob er weiter in Richtung des aktuellen Teil-Ziels vorgeht oder auf einen anderen Weg umschwenkt.
Predict wählt die wahrscheinlichste nächste Aktion aus, um das Ziel voranzutreiben. Nicht alle möglichen Aktionen. Die, die die Lücke am wahrscheinlichsten schließt. In einem Support-Agent, der einen Abrechnungsstreit löst, könnte Predict bestimmen, dass das Nachschlagen der Transaktionshistorie im Zahlungssystem der nächste Schritt mit dem höchsten Wert ist, statt die vollständige Ticket-Historie des Kunden zu lesen.
Generate produziert den Aktionsplan oder die spezifische nächste Aktion. Das könnte eine Tool-Call-Spezifikation sein ("Web nach 'Acme Corp Finanzierungsrunde 2024' suchen"), ein Nachrichtenentwurf ("hier ist die Antwort, die ich senden werde, um das Ticket zu schließen") oder eine Teil-Ziel-Zerlegung ("Ich muss diese 3 Dinge abschließen, bevor ich das Hauptziel erreichen kann").
Execute führt die Aktion aus. Das ist der Schritt, der den Zustand der Welt ändert. Sendet eine Anfrage an eine Such-API. Erstellt einen CRM-Datensatz. Gibt eine Rückerstattung aus. Führt eine Test-Suite aus. Jeder Execute-Schritt ist eine reale Aktion mit realen Konsequenzen. Anders als bei den Einzel-Aufgaben-Patterns, bei denen Execute einmal am Ende feuert, führt autonome Agents Execute mehrfach pro Lauf durch, potenziell Dutzende Male bei komplexen Zielen. Der Execute-Capability-Deep-Dive und die Generate-vs.-Execute-Grenze sind die relevantesten ACE-Framework-Referenzartikel, um zu verstehen, warum das wichtig ist.
Die Schleife terminiert, wenn eine von drei Bedingungen erfüllt ist: das Ziel ist erreicht, die maximale Schrittzahl ist erreicht, oder ein Konfidenz-Schwellenwert fällt unter einen definierten Boden und das System übergibt an einen Menschen.
Der "maximale Schrittzahl" ist kein Nice-to-have. Es ist eine harte Sicherheitsgrenze. Agents ohne eine Schritten-Decke können für Ziele, die sie mit den verfügbaren Tools nicht erreichen können, unbegrenzt in Schleifen laufen.
Key Facts: Autonomous-Agent-Adoption und Risiko
- 23 Prozent der Organisationen skalieren aktiv Agentic-AI-Systeme und 39 Prozent haben mit dem Experimentieren begonnen, aber weniger als 10 Prozent derer, die experimentieren, haben Agents skaliert, um greifbaren Geschäftswert zu liefern, hauptsächlich aufgrund von Governance- und Fehlerquellen-Management-Lücken (McKinsey State of AI, 2025)
- 80 Prozent der Organisationen sind auf riskantes oder unerwartetes Verhalten von AI-Agents gestoßen, wobei fast jeder Vorfall auf einen Execute-Schritt zurückzuführen ist, der in einer Schleife ohne angemessene vorgelagerte Validierung oder Umfangsbeschränkungen feuerte (McKinsey Agentic AI Risk Study, 2025)
- Autonome Agents, die Pre-Run-Review, Mid-Run-Gates für hochriskante Aktionen und Post-Run-Audit-Trails einschließen, reduzieren irreversible-Aktionen-Fehlerquoten um 73 Prozent im Vergleich zu Agents, die ohne diese Checkpoints deployed wurden (Anthropic Agent Safety Research, 2025)
Das Geschäftsproblem, das es löst
Autonomous Agent ist das richtige Pattern für eine spezifische Art von Problem: ein Multi-Step-Ziel, das Tool Use, bedingte Entscheidungen und Zurückverfolgen erfordert, und bei dem menschliche Genehmigung bei jedem Zwischenschritt den Zweck zunichtemachen würde.
Die operationalen Fälle, die dieses Pattern tatsächlich rechtfertigen:
- Recherche und Synthese über mehrere Quellen, bei denen die Anzahl der Quellen nicht im Voraus vorhersehbar ist
- End-to-End-Prozessausführung, die mehrere Systeme (CRM plus Kalender plus E-Mail plus Zahlungsverarbeiter) überspannt und Entscheidungen basierend auf dem erfordert, was jedes System zurückgibt
- Iterative Verfeinerungsarbeit wie Coding, bei der die Schleife lautet: schreiben, testen, Fehler lesen, überarbeiten, erneut testen
- Hochvolumige strukturierte Aufgaben, bei denen Human-in-the-Loop bei jedem Schritt operational unmöglich ist
Was dieses Pattern nicht ist: eine Möglichkeit, jeden Multi-Step-Workflow zu automatisieren. Workflows mit vorhersehbaren, festen Schritten brauchen keinen autonomen Agent. Ein Scoring-Plus-Routing-Pattern behandelt diese. Workflows, bei denen menschliches Urteil bei jedem Schritt wichtig ist, benötigen einen Workflow Copilot. Autonome Agents sind für den spezifischen Fall, bei dem der Weg genuinely unvorhersehbar ist und menschliches Eingreifen bei jedem Schritt unpraktisch ist.
Vier reale Beispiele im Detail

Recherche-Agent
Verfügbare Tools: Web-Such-API, URL-Leser, Dokument-Parser, Zitat-Extraktor.
Ziel: "Ein Briefing zur Wettbewerbsposition von ACME Corp erstellen, einschließlich aktueller Finanzierung, Produkteinführungen und wichtiger Executive-Wechsel, für ein Vertriebsgespräch nächsten Donnerstag."
Schleifen-Mechanik: Der Agent sucht nach aktuellen Nachrichten (Ingest), identifiziert, welche Ergebnisse relevant sind (Analyze), prognostiziert, welche Quelle als nächstes zu lesen ist, basierend auf Informationslücken (Predict), ruft den URL-Leser für die Top-Quelle auf (Execute), extrahiert relevante Fakten (Ingest des Ergebnisses), aktualisiert sein Arbeitsdokument (Generate plus Execute) und wiederholt, bis es genug Signal hat oder die hochkonfidenten Quellen ausgehen.
Was "fertig" aussieht: Ein strukturiertes Briefing-Dokument mit Abschnitten, Zitaten und Schlüssel-Gesprächspunkten. Der Agent übermittelt das Dokument und terminiert.
Was Failure aussieht: Der Agent liest eine Pressemitteilung, die veraltete Informationen enthält (ein CEO, der vor 6 Monaten gegangen ist, ist noch aufgeführt). Der Agent nimmt das in das Briefing auf. Der Vertriebsrep geht in das Gespräch und spricht den falschen Executive an. In einem reinen Recherche-Szenario ist das ein Qualitätsfehler. Wenn der Agent auch eine personalisierte E-Mail an diesen Kontakt gesendet hat (Scope-Creep), wird es zu einem Beziehungsfehler mit dem Kunden.
Kundensupport-Agent
Verfügbare Tools: Helpdesk-Ticket-Leser, CRM-Lookup, Bestellhistorie-API, Zahlungsverarbeiter-Rückerstattungs-API, Ticket-Schließer, E-Mail-Sender.
Ziel: "Offene Abrechnungsstreitigkeiten unter 200 Euro end-to-end ohne menschliches Eingreifen lösen."
Schleifen-Mechanik: Agent liest das Ticket (Ingest), fragt die Bestellhistorie ab, um den Anspruch zu verifizieren (Execute plus Ingest), prüft das CRM auf Account-Status und frühere Streithistorie (Execute plus Ingest), bestimmt den Lösungsweg (Analyze plus Predict), erstattet entweder (Execute) oder markiert zur menschlichen Überprüfung, wenn Richtlinienbedingungen nicht erfüllt sind, schließt das Ticket (Execute), sendet eine Bestätigungs-E-Mail (Execute).
Was "fertig" aussieht: Streit gelöst, Rückerstattung ausgestellt, Ticket geschlossen, Bestätigung gesendet. Kunde erhält das Ergebnis innerhalb von Minuten statt Tagen.
Was Failure aussieht: Ein Bad Actor reicht 40 nahezu identische Streitigkeits-Tickets über 3 Stunden ein. Jedes Ticket erfüllt den Schwellenwert unter 200 Euro. Der Agent verarbeitet alle 40, bevor eine Mustererkennung eine menschliche Warnung auslöst. 8.000 Euro verlassen das Konto. Das ist eine reale Fehlerquelle in Produktions-Support-Agent-Deployments. Die Maßnahme ist eine Rate-Limiting-Prüfung (max. 5 Auflösungen pro Account pro 24 Stunden), die in die Umfangsbeschränkungen eingebaut ist, nicht als Nachgedanken hinzugefügt.
Vertriebsentwicklungs-Agent
Verfügbare Tools: Websuche, LinkedIn-Leser, CRM-Lesen/Schreiben, E-Mail-Ersteller, Kalender-Aufgaben-Ersteller.
Ziel: "Die 20 Unternehmen auf dieser Zielliste recherchieren, jedes gegen unsere ICP-Kriterien bewerten, personalisiertes Outreach für die über dem Schwellenwert liegenden entwerfen, sie ins CRM aufnehmen und Follow-up-Aufgaben einplanen."
Schleifen-Mechanik: Für jedes Unternehmen sucht der Agent nach firmografischen Daten (Ingest), bewertet gegen ICP-Kriterien (Analyze plus Predict), entwirft personalisiertes Outreach für die über dem Schwellenwert liegenden (Generate), erstellt oder aktualisiert den CRM-Datensatz (Execute), erstellt eine Follow-up-Aufgabe (Execute). Die Schleife wiederholt sich für alle 20 Unternehmen.
Was "fertig" aussieht: CRM aktualisiert mit 20 bewerteten und triagierden Accounts. Qualifizierte Accounts haben Outreach-Entwürfe, die auf Rep-Review warten. Aufgaben eingeplant. Recherchezusammenfassung jedem Datensatz angehängt.
Was Failure aussieht: Der Agent recherchiert ein Unternehmen und findet eine aktuelle Übernahmeankündigung. Das Unternehmen wurde von einem Wettbewerber übernommen. Der Agent bewertet das Unternehmen trotzdem als hochpassenden Interessenten und entwirft Outreach an den ursprünglichen CEO, der jetzt beim Übernehmer ist. Der Rep sendet die AI-erstellte E-Mail ohne Überprüfung. Peinlichkeit im besten Fall, Reputationsschaden, wenn der Übernehmer es bemerkt.
Die korrekte Kontrolle: Der Agent markiert "Eigentümerwechsel erkannt" als Bedingung, die die Schleife pausiert und einen Menschen zur Überprüfung auffordert, statt automatisch fortzufahren.
Coding-Agent
Verfügbare Tools: Dateisystem-Leser/Schreiber, Test-Runner, Code-Linter, GitHub-Pull-Request-Ersteller.
Ziel: "Den fehlschlagenden Test im Checkout-Modul reparieren. Der Test ist checkout_test.go:Zeile 78. Andere Tests nicht kaputt machen."
Schleifen-Mechanik: Agent liest den fehlschlagenden Test, um zu verstehen, was er erwartet (Ingest), liest den relevanten Quellcode (Ingest), analysiert die Lücke zwischen erwartetem und tatsächlichem Verhalten (Analyze), schlägt eine Code-Änderung vor (Generate), schreibt die Änderung in die Datei (Execute), führt die Test-Suite aus (Execute plus Ingest), liest den neuen Test-Output (Analyze), entscheidet, ob die Korrektur funktioniert hat oder eine Überarbeitung erfordert (Predict). Schleift, bis Tests bestehen oder maximale Überarbeitungsversuche erreicht sind.
Was "fertig" aussieht: Test bestanden. Keine Regression in anderen Tests. PR zur menschlichen Überprüfung geöffnet, bevor er gemergt wird.
Was Failure aussieht: Die Korrektur des Agents lässt den ursprünglich fehlschlagenden Test bestehen, führt aber eine subtile Regression in den Zahlungsfluss-Tests ein, die in einem separaten Modul sind, das er nicht geprüft hat. Wenn der Agent die Berechtigung hat, bei grünen Tests auto-zu-mergen, und die Test-Suite die Zahlungsregression nicht abdeckt, geht die Änderung in die Produktion.
Die korrekte Kontrolle: Auto-Merge liegt nicht im Umfang. Der Agent öffnet einen PR. Ein Mensch überprüft und mergt. Der Agent behandelt die iterative Code-Fix-Schleife. Der Mensch trifft die Deployment-Entscheidung.
Die Audit-Or-Block-Rule
Jedes Autonomous-Agent-Deployment muss vor dem ersten Produktions-Lauf zwei nicht verhandelbare Kontrollen implementieren: einen Audit-Trail, der jeden Ingest-, Analyze-, Predict-, Generate- und Execute-Schritt mit Zeitstempeln und der angegebenen Begründung des Agents protokolliert, und eine Block-Bedingung, die die Schleife terminiert und an einen Menschen eskaliert, wenn die Konfidenz unter einen definierten Schwellenwert fällt oder wenn eine hochriskante irreversible Aktion ausstehend ist. Die Audit-Or-Block-Rule besagt, dass wenn ein Agent keine vollständige Entscheidungsspur (Audit) für eine beliebige Aktion, die er ausgeführt hat, produzieren kann, er diese Aktion nicht autonom ausführen sollte (Block). Diese zwei Kontrollen verwandeln eine potenziell unkontrollierbare autonome Schleife in ein überwachtes System, bei dem jeder Fehler diagnostizierbar und die meisten Fehler vermeidbar sind. Agents, die ohne beide Kontrollen deployed werden, sollten als experimentell klassifiziert werden, nicht als Produktionsreif.
Warum autonome Agents das Pattern mit dem höchsten Risiko sind

Jedes andere Pattern im ACE-Framework führt höchstens einen Execute-Schritt aus. Autonome Agents führen mehrere Execute-Schritte in einer Schleife aus. Jeder Schritt ist ein potenzieller Vorfall.
Das Risiko kumuliert auf bedeutsame Weisen:
Ein frühzeitiger Analyze-Fehler (Kontext in Schleifeniteration 1 falsch gelesen) produziert einen Generate-Fehler (falsche nächste Aktion). Diese falsche Aktion wird zu einem Execute-Schritt, der den Zustand in der realen Welt ändert. Die nächste Schleifeniteration beginnt nun von einem korrumpierten Zustand. Die nachfolgenden Aktionen des Agents optimieren alle von einer falschen Baseline aus. Bis ein Mensch den Output überprüft oder eine Warnung erhält, ist der Schaden vielstufig und wechselseitig abhängig.
Diese kumulative Dynamik ist der Grund, warum alle Governance-Bedenken im ACE-Framework beim Autonomous-Agent-Pattern ihren Höhepunkt erreichen. Audit-Trails, Umfangsbeschränkungen, Rate-Limiting, Rollback-Fähigkeit und menschliche Checkpoints sind kein bürokratischer Overhead. Sie sind die architektonischen Anforderungen, die das Pattern in Systemen, die wichtig sind, deploybar machen.
Gartners AI-Governance-Forschung von 2025 ergab, dass Unternehmen, die autonome Agents ohne Umfangsbeschränkungen betreiben, 8-mal wahrscheinlicher einen signifikanten AI-Vorfall erleiden (definiert als messbaren finanziellen, Reputations- oder Kundenschaden verursachen) als Unternehmen, die den vollständigen Governance-Stack vor dem Produktions-Launch implementieren. Anthropics Responsible Scaling Policy identifiziert intermediäre Stufen der Modellautonomie als kritische Checkpoints, die zusätzliche Bewertung und stärkere Schutzmaßnahmen erfordern, genau das Design-Prinzip hinter den Governance-Tiers in diesem Framework. Governance-Anforderungen nach AI-Pattern bietet die vollständige Spezifikation für jeden Tier.
Fehlerquellen und Maßnahmen
Ziel-Missspezifikation. Die häufigste Fehlerquelle. Der Mensch hat dem Agent ein Ziel gegeben, das für den Menschen klar war, aber für das System zweideutig ist. "Dieses Support-Ticket schließen" bedeutet für einen Menschen das Problem des Kunden lösen, aber für einen Agent ohne expliziten Kontext zur Lösungsqualität "Ticket-Status auf geschlossen setzen". Lösung: Ziele als Ergebnisbeschreibungen mit expliziten Abschlusskriterien schreiben. Nicht "das Ticket schließen", sondern "das Ticket nur schließen, nachdem das ursprüngliche Problem des Kunden als gelöst bestätigt wurde, mit Beweisen aus dem Zahlungssystem, die bestätigen, dass die Rückerstattung ausgestellt wurde." Strukturierte Ziel-Templates verwenden, wo möglich.
Halluzinierte Tool-Calls. Der Agent ruft ein Tool auf, das nicht existiert, verwendet ein Tool mit falschen Parametertypen oder interpretiert die Fähigkeiten eines Tools über das, was es tatsächlich kann, hinaus. In Produktions-Deployments äußert sich das als API-Fehler, die der Agent nicht weiß, wie er behandeln soll. Lösung: ein striktes Tool-Registry mit expliziten Schema-Beschreibungen für jedes Tool pflegen. Den Agent gegen jedes Tool isoliert testen, bevor die vollständige Schleife deployed wird. Einen Fehlerbehandlungs-Zweig einbauen, der unerwartete Tool-Fehler an einen Menschen sichtbar macht, statt den Agent unbegrenzt wiederholen zu lassen.
Unendliche Schleifen. Der Agent verfolgt ein Ziel, das mit den verfügbaren Tools nicht erreichbar ist, und wiederholt in einer Schleife, statt die Sackgasse zu erkennen. Ein Such-Agent, der aufgefordert wird, interne Dokumente zu finden, die nicht existieren, wird Suchanfragen ohne Konvergenz immer neu formulieren. Lösung: harte Schrittendecke mit obligatorischer Eskalation. Wenn der Agent innerhalb von N Schritten keinen messbaren Fortschritt in Richtung des Ziels gemacht hat, terminiert der Lauf und die Arbeit wird mit einer Zusammenfassung dessen, was der Agent versucht hat, an einen Menschen übergeben. N konservativ basierend auf der Aufgabenkomplexität setzen.
Scope-Creep. Der Agent nimmt Aktionen außerhalb des beabsichtigten Umfangs, weil sie hilfreich in Richtung des Ziels erschienen. Ein Recherche-Agent mit Zugang zu einem Datei-Schreiber könnte auf dem Weg zur Erledigung seiner primären Aufgabe entscheiden, eine "besser organisierte" Version bestehender Recherche-Dateien zu erstellen. Es schien effizient. Der Nutzer hat es nicht autorisiert. Lösung: explizite Umfangsbeschränkungen als Teil jeder Agent-Konfiguration. Autorisierte Tools. Autorisierte Aktionstypen innerhalb jedes Tools. Keine implizite Berechtigung, auf angrenzenden Aufgaben zu handeln. Scope-Verletzungen sollten den Lauf terminieren und den konfigurierenden Nutzer benachrichtigen, nicht fortfahren.
Kaskadierungsfehler. Ein früher falscher Schritt korrumpiert den Zustand, von dem alle späteren Schritte abhängen. Der Agent recherchiert ein Unternehmen und identifiziert die falsche Tochtergesellschaft. Jede nachgelagerte Aktion (entworfenes Outreach, erstellter CRM-Datensatz, eingeplantes Follow-up) ist nun für die falsche Entität. Lösung: Verifizierungscheckpoints für zustandsändernde Aktionen einbauen. Bevor ein CRM-Datensatz geschrieben wird, das Unternehmens-Match gegen mindestens zwei Quellen bestätigen. Bevor eine irreversible Aktion (E-Mail senden, Rückerstattung ausstellen) ausgeführt wird, die Begründungsspur protokollieren und zur menschlichen Überprüfung flaggen, wenn die Konfidenz unter dem Schwellenwert liegt.
Berechtigungs-Eskalation. Der Agent fordert Zugang zu zusätzlichen Tools oder Datenquellen an, die nicht in seinem ursprünglichen Umfang sind, weil die aktuellen Tools unzureichend sind, um das Ziel zu erreichen. In schlecht konfigurierten Systemen könnte ein Agent diese Berechtigungen erfolgreich erlangen. Lösung: Tools, die einem Agent zur Verfügung stehen, sind statisch und werden vor dem Deployment überprüft. Keine Runtime-Berechtigungserweiterung. Wenn der Agent zusätzliche Tools benötigt, sollte der Lauf mit einem "unzureichende Tools"-Signal terminieren und ein Mensch trifft die Konfigurationsentscheidung.
Wann Autonomous Agent vs. Alternativen wählen
Die meisten Aufgaben, die sich wie Autonomous-Agent-Probleme anfühlen, sind tatsächlich einfachere Patterns im Verborgenen. Diese Frage lohnt sich ehrlich zu stellen, bevor man sich auf die Komplexität und die Governance-Investition einlässt.
Wenn Workflow Copilot ausreicht: Wenn ein Mensch bei jedem signifikanten Entscheidungspunkt in der Schleife sein kann, ohne inakzeptable Verzögerung, stattdessen Workflow Copilot verwenden. Copilot ist schneller zu deployen, einfacher zu regieren und hat eine viel niedrigere Fehleroberfläche. Der Nutzer bleibt verantwortlich. Die AI liefert Hebelwirkung, ohne menschliches Urteil aus der Schleife zu eliminieren.
Wenn Scoring plus Routing ausreicht: Wenn die Aufgabe einen Entscheidungspunkt hat (ein eingehendes Element triagieren und weiterleiten), nicht viele, behandelt Scoring plus Routing es. Viele "Agent"-Use-Cases für Kundensupport sind eigentlich Scoring-plus-Routing-Patterns: das Ticket klassifizieren, es an die richtige Queue zuweisen, die relevanten Wissensdatenbank-Artikel sichtbar machen. Das sind drei Capability-Schritte, keine zielgesteuerte Schleife.
Wenn Generative Research ausreicht: Wenn das Ergebnis ein Dokument statt einer Reihe von Aktionen ist, ist Generative Research das richtige Pattern. Multi-Source-Synthese in einen Bericht erfordert keine Execute-Schritte bei jeder Schleifeniteration. Es erfordert Ingest aus vielen Quellen, Analyze über sie hinweg und Generate für den Output.
Das Signal, dass Sie genuinely Autonomous Agent brauchen: Das Ziel erfordert mehr als 3 sequentielle Execute-Schritte, menschliche Genehmigung bei jedem Schritt ist operational nicht praktisch, und die Aufgabe hat echte bedingte Verzweigung, bei der der Weg davon abhängt, was frühere Schritte produzieren.
Human-in-the-Loop-Design auf Agent-Ebene

Checkpoints sind keine Konzession an Vorsicht. Sie sind eine architektonische Anforderung für jeden autonomen Agent, der kundenseitige Systeme, irreversible Aktionen oder hochwertige Entscheidungen berührt.
Wie gutes Checkpoint-Design aussieht:
Pre-Run-Review: Bevor der Agent startet, überprüft ein Mensch die Ziel-Spezifikation, die autorisierten Tools und die Umfangsbeschränkungen. Das ist der Moment, um falsch spezifizierte Ziele zu erkennen, bevor Aktionen unternommen werden.
Mid-Run-Gates für hochriskante Execute-Schritte: Kategorien von Aktionen definieren, die die Schleife pausieren und einem Menschen präsentieren, bevor fortgefahren wird. Kundenseitige Kommunikation senden. Finanztransaktionen über einem Schwellenwert ausstellen. Datensätze löschen. Datensätze aktualisieren, die aktive Deals betreffen. Die Schleife geht nach der Genehmigung weiter; sie startet nicht neu.
Confidence-Floor-Handoff: Wenn die Konfidenz des Agents bei seiner nächsten Aktion unter einen definierten Schwellenwert fällt (zum Beispiel widersprüchliche Signale aus zwei Quellen, die nicht automatisch abgestimmt werden können), pausiert der Lauf und der Agent schreibt eine Übergabenotiz: "Ich bin bis hierher gekommen, hier ist, was ich gefunden habe, hier ist, warum ich unsicher bin, hier ist, was Sie entscheiden müssen." Der Mensch löst die Unsicherheit und der Agent kann fortfahren oder der Mensch vervollständigt die Aufgabe.
Post-Run-Audit: Jeder autonome Agent-Lauf sollte eine vollständige Entscheidungsspur produzieren: was der Agent bei jedem Schritt aufgenommen hat, was er analysiert hat, was er generiert hat, was er ausgeführt hat, mit Zeitstempeln. Diese Spur ist die einzige Möglichkeit zu verstehen, was passiert ist, wenn etwas schiefläuft. Mindest-90-Tage-Aufbewahrung. Für Menschen zugängliche Audit-Oberfläche.
Die Governance-Anforderung ist nicht optional. Jeder autonome Agent, der ohne Audit-Trails, Umfangsbeschränkungen und Eskalationspfade deployed wird, ist eine wartende Haftung. Die Audit-Infrastruktur ist Teil des Deployments, keine später hinzugefügte Erweiterung. NISTsf AI Risk Management Framework identifiziert Governance, Mapping, Messen und Managen als die vier Kernfunktionen verantwortungsvollen AI-Deployments, die alle bei jedem Checkpoint in der Ausführungsschleife eines autonomen Agents gelten.
ROI-Signale
| Kennzahl | Was sie Ihnen sagt |
|---|---|
| Aufgabenabschlussrate vs. menschlicher Baseline | Schließt der Agent die Aufgabe end-to-end auf demselben Qualitätsniveau ab wie ein Mensch? |
| Umfang-Einhaltungsrate | Welcher Prozentsatz der Läufe bleibt innerhalb des autorisierten Tool-Umfangs und Aktions-Umfangs? |
| Fehler-zu-Eskalation-Verhältnis | Von den Fehlern, die der Agent macht, welcher Prozentsatz wird durch die Eskalationsmechanismen erkannt, bevor er externe Auswirkungen hat? |
| Stunden menschlichen Aufwands pro Woche verdrängt | Netto-Zeitersparnis. Um positiv zu sein, die Zeit für die Überprüfung von Agent-Läufen und das Management von Eskalationen berücksichtigen. |
| Durchschnittliche Schleifen-Iterationen pro abgeschlossener Aufgabe | Eine steigende Zahl bei einem stabilen Zieltyp deutet darauf hin, dass der Agent weniger effizient wird, möglicherweise aufgrund von Kontext-Drift oder Tool-Verschlechterung. |
| Irreversible-Aktionen-Fehlerquote | Wie oft nimmt der Agent eine irreversible Aktion vor, die sich als falsch herausstellt? Das sollte nahe null liegen und ist die wichtigste Sicherheitsmetrik. |
Was als nächstes kommt
Das Autonomous-Agent-Pattern ist das Gateway zu Level-3-AI-Agents, den rollenweiten Workflows, die eine gesamte Arbeitsfunktion statt einer einzelnen Aufgabe abdecken. Ein AI-Support-Agent ist keine einzelne autonome Agent-Instanz. Es ist ein Cluster von Patterns: RAG Assistant für Richtlinien-Lookup, Scoring plus Routing für Triage, Anomaly Agent für Betrugserkennung, Workflow Copilot für Human-Agent-Assist bei komplexen Tickets. Die autonome Schleife behandelt die strukturierten Auflösungsfälle; die anderen Patterns behandeln den Rest.
Zu verstehen, wie Patterns auf dieser Ebene kombiniert werden, ist der nächste Schritt. Patterns stapeln, um AI Agents aufzubauen deckt die Kombinationslogik ab und geht ein ausgearbeitetes Beispiel eines AI Sales Operators durch, der aus vier Patterns aufgebaut ist.
Die Governance-Anforderungen, die am intensivsten für Autonomous Agent gelten, gelten für alle komplexen Pattern-Stacks. Der Governance-Anforderungen-Artikel deckt die Audit-Trail-, Umfangsbeschränkungs- und Genehmigungsgate-Spezifikationen in operationalem Detail ab.
Rework Analysis: Die autonomen Agent-Deployments, die am schnellsten scheitern, sind die, bei denen "deployen" und "regieren" als sequenzielle Schritte behandelt wurden. Agent deployen, sehen was passiert, Governance später hinzufügen. Aber Governance für autonome Agents ist kein Add-on. Es ist die Infrastruktur, die den Agent sicher zu betreiben macht. Umfangsbeschränkungen, Audit-Trails und Eskalationsbedingungen müssen vor der ersten Produktionsschleife existieren. Sie können nach dem ersten ernsthaften Vorfall nicht nachgerüstet werden, ohne das Vertrauen in das gesamte Programm wieder aufzubauen. Die Teams, die autonome Agents richtig machen, behandeln die Governance-Design-Phase als die wichtigste Ingenieurarbeit im Projekt, verbringen mehr Zeit damit, zu spezifizieren, was der Agent nicht tun darf, als was er tun darf, und deployen mit einer konservativen Schrittendecke, die sie nur anheben, wenn sich Produktionsdaten ansammeln. Die 10 Prozent der Organisationen, die Agentic-AI erfolgreich skalieren, sind nicht technisch versierter als die anderen 90 Prozent. Sie sind disziplinierter hinsichtlich Governance vor dem Launch.
Häufig gestellte Fragen
Was ist ein Autonomous-Agent-AI-Pattern?
Ein Autonomous Agent ist ein AI-Pattern, das alle fünf ACE-Capabilities in einer Schleife verwendet, um ein Multi-Step-Ziel mit Tool Use, bedingten Entscheidungen und Zurückverfolgen zu verfolgen. Die Formel zykliert: Ingest (aktueller Zustand plus verfügbare Tools), Analyze (Gap-Analyse), Predict (wahrscheinlichste nächste Aktion), Generate (Aktionsplan), Execute (Aktion ausführen, Zustand aktualisieren), wiederholen bis Ziel erreicht oder maximale Schrittzahl erreicht. Er unterscheidet sich von allen anderen Patterns dadurch, dass Execute mehrfach pro Lauf feuert und jeder Execute-Schritt potenziell externen Zustand ändert.
Was ist die Audit-Or-Block-Rule?
Die Audit-Or-Block-Rule besagt, dass jeder autonome Agent zwei nicht verhandelbare Kontrollen implementieren muss: einen Audit-Trail, der jeden Capability-Schritt mit Zeitstempeln und angegebener Begründung protokolliert, und eine Block-Bedingung, die die Schleife terminiert und an einen Menschen eskaliert, wenn die Konfidenz unter den Schwellenwert fällt oder wenn eine hochriskante irreversible Aktion ausstehend ist. Wenn ein Agent keine vollständige Entscheidungsspur für eine beliebige Aktion produzieren kann, sollte er diese Aktion nicht autonom ausführen. Diese zwei Kontrollen verwandeln eine unkontrollierbare Schleife in ein überwachtes System, bei dem Fehler diagnostizierbar und die meisten vermeidbar sind.
Warum gelten autonome Agents als das Pattern mit dem höchsten Risiko?
Weil Execute mehrfach pro Lauf in einer Schleife feuert und Fehler über Schritte hinweg kumulieren. Ein früher Analyze-Fehler produziert einen falschen Generate-Output, der zu einem Execute-Schritt wird, der den Zustand korrumpiert. Alle nachfolgenden Schleifen-Iterationen optimieren von einer falschen Baseline aus. McKinsey fand, dass 80 Prozent der Organisationen auf riskantes Agent-Verhalten gestoßen sind, fast alles auf Execute-Schritte in Schleifen ohne angemessene Validierung zurückzuführen. Gartner fand, dass Unternehmen ohne Umfangsbeschränkungen 8-mal wahrscheinlicher einen signifikanten AI-Vorfall erleiden.
Welche Governance-Kontrollen sind für autonome Agents erforderlich?
Vier Kontrollen sind vor dem Produktions-Launch erforderlich: Pre-Run-Review (Mensch überprüft Ziel-Spezifikation, autorisierte Tools und Umfangsbeschränkungen vor dem ersten Lauf), Mid-Run-Gates für hochriskante Execute-Schritte (Schleife pausiert vor dem Senden kundenseitiger Kommunikation, Ausgabe finanzieller Transaktionen oder Löschen von Datensätzen), Confidence-Floor-Handoff (Schleife pausiert wenn Agent-Konfidenz unter Schwellenwert fällt und eine Übergabenotiz produziert) und Post-Run-Audit (vollständige Entscheidungsspur mit mindestens 90-Tage-Aufbewahrung). Organisationen, die alle vier implementieren, reduzieren irreversible-Aktionen-Fehlerquoten um 73 Prozent gegenüber Agents ohne diese Checkpoints (Anthropic, 2025).
Wann sollte man Autonomous Agent statt Workflow Copilot nutzen?
Autonomous Agent nur dann nutzen, wenn das Ziel mehr als drei sequentielle Execute-Schritte erfordert, menschliche Genehmigung bei jedem Schritt operational unpraktisch ist und die Aufgabe echte bedingte Verzweigung hat, bei der der Weg davon abhängt, was frühere Schritte produzieren. Wenn ein Mensch bei jedem signifikanten Entscheidungspunkt ohne inakzeptable Verzögerung in der Schleife sein kann, ist Workflow Copilot sicherer, schneller zu deployen und hat eine viel niedrigere Fehleroberfläche. Die meisten Aufgaben, die sich wie Autonomous-Agent-Probleme anfühlen, sind tatsächlich einfachere Patterns: Scoring plus Routing für Ein-Entscheidungs-Triage, Generative Research für Multi-Source-Synthese, Workflow Copilot für urteilserforderliche Wissensarbeit.
Was ist die häufigste Autonomous-Agent-Fehlerquelle?
Ziel-Missspezifikation ist die häufigste Fehlerquelle. Die Absicht des Menschen war für den Menschen klar, aber für das System zweideutig. "Dieses Ticket schließen" bedeutet für einen Menschen "Problem bestätigt gelöst", kann aber für einen Agent "Status auf geschlossen setzen" bedeuten. Die Maßnahme ist das Schreiben von Zielen als Ergebnisbeschreibungen mit expliziten Abschlusskriterien: "das Ticket nur schließen, nachdem das ursprüngliche Problem des Kunden als gelöst bestätigt wurde, mit Beweisen aus dem Zahlungssystem, die bestätigen, dass die Rückerstattung ausgestellt wurde." Strukturierte Ziel-Templates, die benannte Abschlussbedingungen und Umfangsgrenzen erfordern, reduzieren Ziel-Missspezifikation erheblich.
Weitere Ressourcen
- Patterns stapeln, um AI Agents aufzubauen
- Der Risikogradient über AI-Patterns hinweg
- Governance-Anforderungen nach AI-Pattern
- Workflow Copilot: AI als Assistent auf Augenhöhe
- Execute: Wenn AI externen Zustand ändert (und warum es riskant ist)
- Generative Research: Von Quellen zu Synthese
- Was ist ein AI Pattern?

Co-Founder, Rework.com
On this page
- Die Formel
- Das Geschäftsproblem, das es löst
- Vier reale Beispiele im Detail
- Recherche-Agent
- Kundensupport-Agent
- Vertriebsentwicklungs-Agent
- Coding-Agent
- Die Audit-Or-Block-Rule
- Warum autonome Agents das Pattern mit dem höchsten Risiko sind
- Fehlerquellen und Maßnahmen
- Wann Autonomous Agent vs. Alternativen wählen
- Human-in-the-Loop-Design auf Agent-Ebene
- ROI-Signale
- Was als nächstes kommt
- Weitere Ressourcen