Der Risikogradient über AI Patterns hinweg

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Jeder AI-Governance-Rahmen macht schließlich denselben Fehler: alle AI als gleich gefährlich zu behandeln.
Das Ergebnis ist vorhersehbar. Governance-Teams schreiben pauschale Richtlinien, die denselben Genehmigungsprozess, denselben Überprüfungszyklus und dasselbe Beschränkungsniveau auf einen Chatbot, der HR-Richtlinienfragen beantwortet, und auf einen Agent anwenden, der Rückerstattungen in Stripe ausstellen kann. Der HR-Chatbot stirbt in einem sechsmonatigen Überprüfungszyklus. Der Rückerstattungs-Agent wird mit schwachen Kontrollen ausgeliefert, weil niemand ihn vom Chatbot unterschieden hat.
Beide Ergebnisse sind schlecht. Risikoarme Patterns übermäßig zu kontrollieren tötet die Adoption und veranlasst AI-Teams, den Governance-Prozess zu umgehen. Hochrisiko-Patterns zu wenig zu kontrollieren verursacht die Vorfälle, die Schlagzeilen machen.
Die Lösung ist proportionale Governance: Passen Sie Ihre Kontrollen an das tatsächliche Risikoniveau jedes Patterns an, nicht an ein generisches Gefühl, dass "AI riskant ist." Das beginnt damit, zu verstehen, wo jedes Pattern auf dem Risikogradienten liegt. Das AI Risk Management Framework des NIST empfiehlt genau diesen Ansatz: AI-Risiken im Kontext regeln, kartieren, messen und managen, skaliert auf den spezifischen Anwendungsfall und seine potenziellen Konsequenzen. Wenn Sie mit den 10 Kern-Patterns noch vertraut werden, beginnen Sie zuerst mit Was ist ein AI Pattern.
Was Risiko in AI Patterns antreibt
Drei Faktoren bestimmen das Basisrisikoniveau eines Patterns.
Umkehrbarkeit von Execute-Aktionen. Patterns ohne Execute-Schritt tragen das niedrigste Risiko: wenn die AI falsch liegt, hat sich nichts in der externen Welt geändert. Der Mensch liest den Output und entscheidet, ob er handelt. Patterns mit Execute tragen Risiko proportional dazu, wie schwer es ist, die Aktion rückgängig zu machen. Ein CRM-Feld zu aktualisieren ist leicht reversibel. Eine E-Mail an einen Kunden zu senden ist schwerer reversibel (man kann eine Korrektur senden, aber nicht ungeschehen machen). Eine Rückerstattung ausstellen, eine Bestellung aufgeben oder eine Transaktion sperren sitzt bei den höchsten Reversibilitätskosten.
Gartners AI Risk Taxonomy 2025 stuft Irreversibilität als den einzigen höchsten Risiko-Multiplikator in AI-Governance-Rahmen ein, vor Datensensitivität und regulatorischer Exposition, weil irreversible Fehler schneller skalieren und sich einer Korrektur widersetzen, sobald die Execute-Schleife im großen Maßstab gelaufen ist.
Konfidenz-Kalibrierung von Predict-Outputs. Patterns, die auf Predict für Routing- oder Entscheidungsantrieb setzen, tragen Risiko proportional dazu, wie gut kalibriert die Konfidenz des Modells ist. Ein Lead-Scoring-Modell, das "82 % Konversionswahrscheinlichkeit" sagt, sollte bei 82 % bewerteten Leads ungefähr 18 % der Zeit falsch liegen. Wenn die Kalibrierung des Modells off ist (konsistent überkonzentriert oder unterkonzentriert), verschlechtert sich jede nachgelagerte Routing-Entscheidung auf Basis dieser Scores. Fehlkalibrierte Konfidenz ist unsichtbar, bis man Ergebnisse gegen Vorhersagen auditiert.
Platzierung des Menschen in der Schleife. Das Risiko ist niedriger, wenn ein menschliches Review-Gate zwischen Generate und Execute sitzt. Es ist höher, wenn Execute automatisch auf Basis eines Schwellenwerts oder einer Regel auslöst. Und es ist am höchsten, wenn Execute innerhalb einer Schleife sitzt und mehrmals pro Ziel läuft, wo frühe Fehler durch spätere Schritte verstärkt werden. Die Generate-vs.-Execute-Grenze ist die kritische Designentscheidung für jedes Pattern, das Execute beinhaltet.
Die Risk-Gradient-Doktrin
AI-Governance muss proportional zur Reversibilität und Autonomie des Execute-Schritts jedes Patterns sein, nicht einheitlich für alle AI-Systeme. Ein Pattern, das liest und generiert (Tier 1), benötigt Audit-Protokollierung und Nutzerschulung, keine Genehmigungsgates. Ein Pattern, das autonom in einer Schleife ausführt (Tier 4), benötigt Geltungsbereichsgrenzen, Rate-Limits, Rollback-Fähigkeit und menschliche Aufsicht beim Launch. Tier-4-Governance auf Tier-1-Patterns anzuwenden tötet die Adoption, ohne Risiko zu reduzieren. Tier-1-Governance auf Tier-4-Patterns anzuwenden ist die direkte Ursache der AI-Vorfälle, die Schlagzeilen machen.
Key Facts: AI-Risiko und Governance
- 80 % der Unternehmen haben riskantes oder unerwartetes Verhalten von AI Agents erlebt, wobei fast jeder Vorfall auf einen Execute-Schritt zurückzuführen war, der ohne ausreichende vorgelagerte Validierung ausgelöst wurde (McKinsey, 2025).
- Unternehmen, die einheitliche Governance über alle AI Patterns anwenden, geben 3-mal mehr für Compliance-Overhead aus als solche mit gestuften risikoproportionalen Kontrollen, bei gleichzeitig schlechteren Sicherheitsergebnissen (Deloitte AI Governance Report, 2025).
- AI-Vorfälle mit messbarem Geschäftsschaden sind 4,7-mal wahrscheinlicher, wenn autonome oder automatisierte Execute-Patterns beteiligt sind, als bei nur-lesenden Generate-Patterns (Forrester AI Incident Analysis, 2025).
Das Risikospektrum: vier Stufen

Tier 1: Nur-lesend, kein Execute
Patterns: RAG Assistant, Generative Research, Document Review
Diese Patterns Ingest, Analyze, Generate und halten dann inne. Nichts in der externen Welt ändert sich. Die Ausgabe ist ein Textartefakt (eine Antwort, ein Report, ein Set von Flags), das ein Mensch liest, bewertet und darauf handelt. Wenn die AI falsch liegt, erkennt der Mensch es, bevor irgendetwas festgeschrieben wird.
Der RAG Assistant produziert Antworten aus einer Wissensdatenbank. Wenn er falsche Passagen abruft und eine falsche Antwort generiert, liest der Mensch, der die Frage stellt, eine falsche Antwort. Das ist ein Problem. Aber es ist ein begrenztes Problem: Eine Person erhält falsche Informationen. Sie könnte danach handeln oder bemerken, dass es falsch ist, und nachprüfen.
Generative Research synthetisiert einen Report aus mehreren Quellen. Wenn er ein Zitat falsch zuordnet oder eine falsche Schlussfolgerung zieht, erhält der Leser einen fehlerhaften Report. Das Risiko skaliert damit, wie sehr der Leser dem Output ohne Überprüfung vertraut und danach handelt.
Document Review kennzeichnet Risiken in Verträgen oder Richtlinien. Wenn er eine nicht standardmäßige Klausel verpasst, erkennt das Rechtsteam sie möglicherweise nicht. Dieses Risiko ist real, aber es ist ein Auslassungsrisiko (verpasstes Flag), kein Begehungsrisiko (falsche Aktion durch die AI).
Basisrisiko: Niedrig. Die Schlüsselkontrolle ist Qualitätssicherung, keine Governance-Gates. Schulen Sie Nutzer darin, wichtige Outputs zu verifizieren, besonders bei hochwertigen Dokumenten in Document Review. Pflegen Sie Audit-Protokolle von Abfragen und Outputs.
Tier 2: Execute mit menschlicher Genehmigung
Patterns: Workflow Copilot, Meeting Intelligence, Vision Extract
Diese Patterns beinhalten Execute, aber mit einem menschlichen Genehmigungsgate, das in der Standardimplementierung zwischen Generate und Execute sitzt.
Workflow Copilot entwirft eine E-Mail oder eine CRM-Aktualisierung. Der Mensch überprüft den Entwurf und klickt auf Senden. Execute löst nur nach menschlicher Genehmigung aus. Das Risiko liegt darin, was passiert, wenn das Genehmigungsgate entfernt wird (was das Erste ist, was Teams tun, wenn sie entscheiden, dass die AI "gut genug zum Vertrauen" ist). Das Gate zu entfernen verwandelt ein Tier-2-Pattern in etwas Ähnliches zu Tier 3.
Meeting Intelligence generiert Call-Zusammenfassungen und CRM-Notizen, oft mit einem Rep-Überprüfungsschritt, bevor sie übertragen werden. In manchen Implementierungen ist die Übertragung ins CRM automatisch. Wenn sie automatisch ist, wird eine schlechte Zusammenfassung zu einem schlechten CRM-Datensatz, was Pipeline-Reporting, Forecast-Genauigkeit und Coaching-Qualität beeinflusst. Das ist ein mittel-riskantes Ergebnis.
Vision Extract überträgt strukturierte Datensätze in ein System of Record. In den meisten Implementierungen prüft ein Mensch stichprobenartig eine Stichprobe von Datensätzen, bevor sie festgeschrieben werden. Wenn die Stichprobenprüfung entfernt wird (oft aus Kostengründen), werden Extraktionsfehler zu Datenbankfehlern.
Basisrisiko: Mittel-niedrig. Die Kern-Governance-Kontrolle ist die Aufrechterhaltung des menschlichen Review-Gates und das Auditing dessen, was passiert, wenn Sie es entfernen. Definieren Sie die Ausnahmebehandlung: Was tut das System mit Datensätzen, die es nicht mit Sicherheit extrahieren kann? Zur manuellen Prüfung weiterleiten, nicht automatisch mit niedrigem Konfidenzwert festschreiben.
Tier 3: Execute mit Regeln (keine per-Aktion menschliche Genehmigung)
Patterns: Scoring plus Routing, Anomaly Agent, Personalization Engine
Diese Patterns Execute automatisch auf Basis von Schwellenwerten, Regeln oder Modell-Outputs. Es gibt keinen Menschen, der jede einzelne Aktion genehmigt. Ein Lead bewertet sich über 80 und wird automatisch an das Enterprise-Team weitergeleitet. Eine Transaktion wird als anomal bewertet und automatisch gekennzeichnet oder gesperrt. Die Verhaltenshistorie eines Nutzers löst eine personalisierte Produktempfehlung aus. Aktionen erfolgen in Menge, kontinuierlich, ohne einen Menschen in der Schleife für jede einzelne.
Die Governance-Herausforderung: Die Kontrollen sind vorgelagert (Modellkalibrierung, Schwellenwert-Einstellungen, Ausnahme-Queues), nicht am Punkt der Aktion. Wenn das Lead-Scoring-Modell falsch kalibriert ist, wird 20 % Ihrer Revenue-Pipeline an das falsche Team geleitet, und Sie sehen es erst, wenn Sie Ergebnisse auditieren. Wenn die Baseline des Anomaly Agents falsch ist, sperren Sie entweder legitime Kunden oder verpassen echten Betrug. Keiner dieser Fehler ist in Echtzeit sichtbar ohne Monitoring.
Basisrisiko: Mittel-hoch. Governance-Anforderungen: definierte Konfidenz-Schwellenwerte mit menschlichen Review-Queues für Randfälle, regelmäßige Modellaudits, die Vorhersagen mit Ergebnissen vergleichen, Rollback-Verfahren für Regeländerungen und dokumentierte Ausnahmebehandlung für Elemente unter dem Konfidenz-Schwellenwert. Einen Schwellenwert setzen und vergessen ist keine Option. Überprüfen Sie Schwellenwerte vierteljährlich auf Basis von Ergebnisdaten.
Tier 4: Execute in Schleifen, hohe Autonomie
Pattern: Autonomous Agent
Der Autonomous Agent nutzt alle fünf Fähigkeiten in einer Schleife und verfolgt ein Ziel über mehrere Schritte und mehrere Systeme hinweg. Jede Schleifeniteration kann Execute-Aktionen beinhalten. Ein Fehler in einem frühen Schritt (falsches Analyze, falsch kalibriertes Predict) pflanzt sich durch jeden nachfolgenden Execute-Schritt in der Schleife fort. Und die Schleife läuft wieder und wieder, bis das Ziel erreicht ist oder der Agent entscheidet, dass er nicht fortfahren kann.
Das ist kategorisch anders als die anderen Stufen. Der Workflow Copilot führt einmal aus, mit einem menschlichen Review des Entwurfs. Der Autonomous Agent führt möglicherweise 15-mal aus, während er eine Research-und-Outreach-Aufgabe abschließt, ohne dass ein Mensch Schritte 2 bis 14 überprüft.
Die Szenarien, die echten Schaden verursachen: Ein Agent, der Prospects recherchiert und im großen Maßstab Outreach-E-Mails sendet, die Account-Zuordnung falsch versteht und unangemessene Nachrichten an das falsche Unternehmen sendet. Ein Agent, der Rückerstattungsanfragen verwaltet und Rückerstattungen auf Basis einer fehlerhaften Matching-Regel ausstellt. Ein Agent, der Kalenderzeiten bucht und CRM-Aufgaben erstellt, durch eine 300-Kontakt-Liste läuft, die Kalenderintegration falsch versteht und Lärm über den gesamten Teamplan verbreitet. McKinsey berichtet, dass 80 % der Unternehmen riskantes Verhalten von AI Agents erlebt haben, und die obigen Muster sind genau die Fehlerarten, die in diesen Vorfällen auftauchen.
Basisrisiko: Hoch. Erforderliche Governance: explizite Geltungsbereichsgrenzen (welche Systeme kann der Agent berühren, welche Aktionen kann er vornehmen), Rate-Limits auf Execute-Aktionen (nicht mehr als X E-Mails pro Stunde, nicht mehr als Y USD in Rückerstattungen pro Tag ohne menschliche Überprüfung), Rollback-Fähigkeit für ausgeführte Aktionen und Mensch-in-der-Schleife beim ersten Produktionslauf vor dem Skalieren. Das Rate-Limit ist die am häufigsten übersehene Kontrolle: Es verwandelt einen potenziellen Massenfehler in einen begrenzten, korrigierbaren.
Alle 10 Patterns auf dem Gradienten
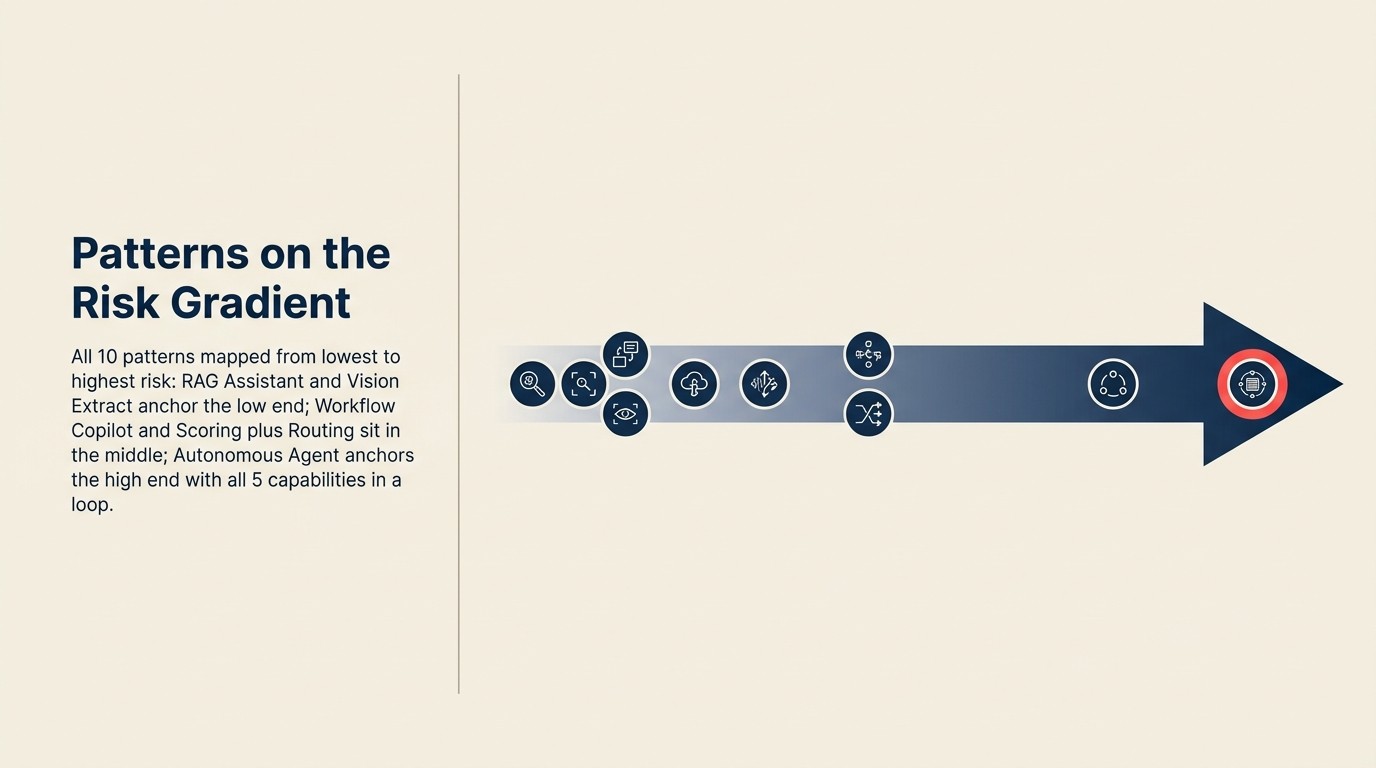
| Pattern | Risikostufe | Execute? | Menschliches Gate? | Primäres Risiko |
|---|---|---|---|---|
| RAG Assistant | Tier 1 (Niedrig) | Nein | Nicht anwendbar | Falsche oder veraltete Antwort |
| Generative Research | Tier 1 (Niedrig) | Nein | Nicht anwendbar | Fehlerhafte Synthese, falsch zugeordnete Quellen |
| Document Review | Tier 1 (Niedrig) | Nein | Nicht anwendbar | Verpasste Flags (Auslassungsrisiko) |
| Workflow Copilot | Tier 2 (Mittel-niedrig) | Ja, menschlich kontrolliert | Überprüfung vor Execute | Gate-Entfernung; schlechte Entwürfe festgeschrieben |
| Meeting Intelligence | Tier 2 (Mittel-niedrig) | Ja, oft menschlich kontrolliert | Überprüfung vor Übertragung | Ungenaue Notizen im System of Record |
| Vision Extract | Tier 2 (Mittel-niedrig) | Ja, menschlich kontrolliert | Stichprobe vor Festschreibung | Extraktionsfehler in der Datenbank |
| Scoring plus Routing | Tier 3 (Mittel-hoch) | Ja, automatisch | Schwellenwerte plus Ausnahme-Queue | Falsch kalibriertes Modell-Routing im großen Maßstab |
| Anomaly Agent | Tier 3 (Mittel-hoch) | Ja, automatisch | Schwellenwerte plus Ausnahme-Queue | Falsche Baseline; Falsch-Positive oder verpasste Warnungen |
| Personalization Engine | Tier 3 (Mittel-hoch) | Ja, automatisch | Schwellenwerte plus Monitoring | Diskriminierende Personalisierung; Preisexposition |
| Autonomous Agent | Tier 4 (Hoch) | Ja, in Schleife | Rate-Limits plus initiale Aufsicht | Sich summierende Fehler über Execute-Schritte |
Wie Domain-Kontext das Risiko multipliziert
Die obige Stufe stellt das Basisrisiko dar. Domain-Kontext ist ein Multiplikator.
Ein Vision-Extract-Pattern, das Visitenkarten in ein CRM verarbeitet, ist Tier-2-Basisrisiko. Ein falsches Feld (Telefonnummer um eine Stelle versetzt, Unternehmensname falsch geschrieben) ist ein lästiges Datenqualitätsproblem. Behebbar.
Dasselbe Vision-Extract-Pattern, das Patienten-Aufnahmeformulare liest und ein medizinisches Aufzeichnungssystem aktualisiert, ist ein Tier-4-Governance-Problem. Ein falscher Feldwert (falsche Medikation, falsche Allergie, falsche Dosierung) in einem Patientendatensatz kann klinische Entscheidungen beeinflussen. Gleiche Fähigkeitsformel, andere Domäne, andere Risikostufe.
Ein Scoring-plus-Routing-Pattern, das eingehende Vertriebsleads leitet, ist Tier-3-Basisrisiko. Ein falsch kalibriertes Modell leitet manche Leads an das falsche Team. Revenue-Impact, lästig, auditierbar.
Dasselbe Scoring-plus-Routing-Pattern, angewandt auf Kreditanträge, ist in regulierten Märkten ein Tier-4-Governance-Problem. ECOA, der Fair Housing Act und GDPR Artikel 22 verlangen Erklärbarkeit und menschliche Überprüfungsrechte für AI-gesteuerte Entscheidungen, die den Zugang zu Kredit betreffen. Regulatorische Exposition wandelt ein technisches Tier-3-Problem in ein rechtliches Tier-4-Problem um.
Passen Sie die Stufe jedes Patterns nach oben an, wenn: der Output regulierte Entscheidungen betrifft (Kredit, Beschäftigung, Wohnen, Gesundheitswesen), die Daten sensible persönliche Informationen umfassen, die Execute-Aktion finanziell oder rechtlich folgenreich ist oder das Ausmaß automatisierter Aktionen Fehler schwer erkennbar macht, bevor sie sich summieren. Der Artikel zur Messung von AI-Pattern-ROI in "Mehr erfahren" behandelt, wie man quantifiziert, wann der risikobereinigte Return das Deployment rechtfertigt.
Häufige Risikounterschätzungen nach Pattern
Scoring plus Routing fühlt sich sicher an, weil es "nur Dinge weiterleitet." Routing-Entscheidungen in großem Maßstab sind Revenue-Entscheidungen. Wenn Ihr Lead-Scoring-Modell falsch liegt, welche Leads hochprioritär sind, arbeiten Ihre besten Reps an den falschen Accounts. Wenn Ihr Support-Ticket-Router Dringlichkeit falsch klassifiziert, warten Enterprise-Kunden in der Standard-Queue. Das sind keine abstrakten Risiken. Sie sind messbar: Prüfen Sie Ihre Rep-Aktivitätsverteilung, SLA-Verletzungsraten und Routing-Genauigkeit monatlich.
Personalization Engine wirkt harmlos, weil sie nur "relevante Inhalte zeigt." Personalisierte Preisgestaltung (verschiedenen Nutzern unterschiedliche Preise zeigen) kann in mehreren Jurisdiktionen rechtliche Exposition unter Verbraucherschutzgesetzen schaffen, besonders wenn die Personalisierung mit geschützten Merkmalen korreliert. Personalisierte Stellenanzeigen, die bestimmte demografische Gruppen auf Basis von Verhaltens-Targeting ausschließen, waren Gegenstand von EEOC- und EU-Untersuchungen. "Wir personalisieren nur Inhalte" ist keine Governance-Antwort.
Workflow Copilot scheint risikoarm, weil ein Mensch alles überprüft. Bis der Mensch aufhört zu überprüfen. Das Review-Gate ist die gesamte Governance-Struktur für dieses Pattern. Wenn Teams entscheiden, dass die AI "gut genug" ist, und den Überprüfungsschritt entfernen, haben sie gerade ein automatisiertes Execute ohne Tier-3-Governance-Kontrollen deployed. Der Übergang sollte bewusst und dokumentiert sein, keine stille Prozessänderung.
Governance-Anforderungen nach Stufe

Tier 1: Audit-Protokolle von Abfragen und Outputs. Qualitätsüberprüfungsprozess (periodische Stichprobenprüfung von Outputs durch einen menschlichen Prüfer). Nutzerschulung zu Verifikationserwartungen (hochwichtige Anwendungen erfordern unabhängige Verifikation). Keine Genehmigungsgates für den Standardgebrauch erforderlich.
Tier 2: Menschliche Review-Gates als explizite Richtlinie aufrechterhalten. Dokumentieren, welche Workflows automatisches Festschreiben vs. Review-Pflicht haben. Stichprobenraten für automatisch festgeschriebene Datensätze. Ausnahme-Routing für Outputs mit niedrigem Konfidenzwert.
Tier 3: Modellgenauigkeitsmonitoring mit periodischen Ergebnisaudits (Vorhersagen mit tatsächlichen Ergebnissen vergleichen). Konfidenz-Schwellenwerte mit Ausnahme-Queues für Elemente unter dem Schwellenwert. Vierteljährliche Schwellenwertüberprüfung auf Basis von Ergebnisdaten. Dokumentation von Routing-Regeln und Eskalationspfaden. Alert bei Model-Drift.
Tier 4: Explizite Geltungsbereichsgrenzen, auf Systemebene dokumentiert und durchgesetzt (nicht nur als Richtlinie). Rate-Limits auf Execute-Aktionen. Rollback-Fähigkeit zum Rückgängigmachen ausgeführter Aktionen. Menschliche Aufsicht für den ersten Produktionslauf erforderlich. Gestaffeltes Rollout (mit risikoarmen Accounts oder Anwendungen beginnen, bevor skaliert wird). Incident-Response-Plan für den Fall, dass der Agent im großen Maßstab eine falsche Aktion vornimmt.
Aufbau Ihres Risikoregisters
Ein Risikoregister für aktive AI Patterns muss nicht komplex sein. Für jedes Pattern in Produktion dokumentieren Sie:
- Pattern-Name und spezifischer Anwendungsfall (z. B. "Scoring plus Routing für eingehende Lead-Zuweisung")
- Risikostufe (1-4)
- Domain-Multiplikatoren (regulierte Daten? Finanzielle Konsequenz? Sensible persönliche Daten?)
- Eigentümer (wer ist verantwortlich für das Monitoring von Genauigkeit und Governance dieses Patterns?)
- Überprüfungsfrequenz (Tier 1: jährlich; Tier 2: vierteljährlich; Tier 3: monatlich; Tier 4: wöchentlich bis stabil)
- Aktuelle Kontrollen (was ist tatsächlich vorhanden)
- Bekannte Lücken (was vorhanden sein sollte, aber nicht ist)
Das Register ist ein lebendes Dokument. Wenn Sie Patterns hinzufügen, Domänen anpassen oder Konfigurationen ändern, aktualisieren Sie es. Der Punkt ist nicht Perfektion: Es geht darum, dass jemand die Risikoposition jedes Patterns besitzt und sie planmäßig überprüft.
Rework Analysis: Der Governance-Fehler, den wir am häufigsten sehen, ist, dass Unternehmen eine AI-Richtlinie schreiben, die einheitlich auf alle AI-Systeme angewendet wird. Die Richtlinie wird auf das gefährlichste Pattern in der Produktion kalibriert (oft ein Autonomous Agent oder ein automatisiertes Routing-System) und auf alles angewendet. Das Ergebnis: risikoarme RAG Assistants werden in sechsmonatigen Sicherheitsreviews blockiert, während die eigentlichen Hochrisiko-Autonomous-Agents, die ausgeliefert werden, nur eine Checkbox-Überprüfung haben. Gestufte Governance, die dem tatsächlichen Execute-Risiko jedes Patterns entspricht, kostet weniger und kontrolliert mehr. Das obige Vier-Stufen-Modell gibt Risiko- und Compliance-Teams das Vokabular, um proportionale Regeln statt pauschaler zu schreiben.
Häufig gestellte Fragen
Was ist der Risikogradient über AI Patterns hinweg?
Der Risikogradient stuft AI Patterns von Tier 1 (nur-lesend, kein Execute) bis Tier 4 (autonome Schleifen mit wiederholten Execute-Schritten) ein. Tier-1-Patterns wie RAG Assistant und Generative Research tragen geringes Risiko, weil die AI Textausgaben produziert, auf die ein Mensch handelt. Tier-4-Patterns wie Autonomous Agent tragen hohes Risiko, weil Execute mehrmals pro Ziel ohne menschliche Überprüfung auslöst und Fehler sich über Schritte summieren.
Was macht ein AI Pattern hochriskant?
Drei Faktoren treiben AI-Pattern-Risiko: Irreversibilität von Execute-Aktionen (wie schwer es ist, rückgängig zu machen, was die AI tat), Konfidenz-Kalibrierung von Predict-Outputs (ob Scores die tatsächliche Wahrscheinlichkeit genau widerspiegeln) und Platzierung des Menschen in der Schleife (ob ein Mensch Outputs überprüft, bevor Execute auslöst). Forresters AI Incident Analysis 2025 ergab, dass AI-Vorfälle mit Execute-Patterns 4,7-mal wahrscheinlicher messbaren Geschäftsschaden verursachen als Vorfälle mit nur-lesenden Generate-Patterns.
Wie sollte Governance über AI-Pattern-Risikostufen skaliert werden?
Tier-1-Patterns benötigen Audit-Protokollierung und Nutzerschulung zu Verifikationserwartungen. Tier-2-Patterns benötigen aufrecht erhaltene menschliche Review-Gates und Ausnahme-Routing für Outputs mit niedrigem Konfidenzwert. Tier-3-Patterns benötigen Modellgenauigkeitsmonitoring, Konfidenz-Schwellenwerte mit Ausnahme-Queues und vierteljährliche Ergebnisaudits. Tier-4-Patterns benötigen Geltungsbereichsgrenzen, Rate-Limits auf Execute-Aktionen, Rollback-Fähigkeit und menschliche Aufsicht während initialer Produktionsläufe.
Warum ist das Workflow-Copilot-Pattern risikoärmer als Scoring plus Routing?
Workflow Copilot beinhaltet ein explizites menschliches Genehmigungsgate zwischen Generate und Execute: Die AI entwirft, der Mensch genehmigt, bevor etwas gesendet oder festgeschrieben wird. Scoring plus Routing Execute automatisch im großen Maßstab auf Basis von Modell-Scores, ohne per-Aktion menschliche Überprüfung. Das Risiko bei Workflow Copilot skaliert mit Gate-Entfernung. Das Risiko bei Scoring plus Routing skaliert mit Modell-Fehlkalibrierung, die unsichtbar ist, bis Ergebnisse auditiert werden.
Was ist die Risk-Gradient-Doktrin?
Die Risk-Gradient-Doktrin besagt, dass AI-Governance proportional zur Reversibilität und Autonomie des Execute-Schritts jedes Patterns sein muss, nicht einheitlich für alle AI-Systeme. Dieselben Kontrollen auf einen nur-lesenden RAG Assistant und einen Autonomous Agent anzuwenden überregelt gleichzeitig risikoarme Systeme und unterregelt hochriskante. Gestufte Governance, die dem tatsächlichen Execute-Profil jedes Patterns entspricht, kostet weniger und kontrolliert mehr als pauschale AI-Richtlinien.
Beeinflusst Domain-Kontext die Risikostufe eines Patterns?
Ja. Domain-Kontext ist ein Multiplikator auf das Basisrisiko. Vision Extract, das Visitenkarten verarbeitet, ist Tier-2-Basisrisiko. Dasselbe Pattern, das medizinische Datensätze mit Allergie- oder Medikationsdaten aktualisiert, ist ein Tier-4-Governance-Problem, weil Fehler klinische Entscheidungen direkt beeinflussen. Ebenso ist Scoring plus Routing für Lead-Zuweisung Tier 3, aber dasselbe Pattern auf Kreditentscheidungen angewendet löst regulatorische Pflichten unter ECOA und GDPR Artikel 22 aus, die es auf Tier 4 pushen.
Mehr erfahren

Co-Founder, Rework.com
On this page
- Was Risiko in AI Patterns antreibt
- Die Risk-Gradient-Doktrin
- Das Risikospektrum: vier Stufen
- Tier 1: Nur-lesend, kein Execute
- Tier 2: Execute mit menschlicher Genehmigung
- Tier 3: Execute mit Regeln (keine per-Aktion menschliche Genehmigung)
- Tier 4: Execute in Schleifen, hohe Autonomie
- Alle 10 Patterns auf dem Gradienten
- Wie Domain-Kontext das Risiko multipliziert
- Häufige Risikounterschätzungen nach Pattern
- Governance-Anforderungen nach Stufe
- Aufbau Ihres Risikoregisters
- Mehr erfahren