Risco de Alucinação por Padrão de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Alucinação é a palavra que encerra projetos de AI. Não porque sempre acontece, mas porque quando acontece no contexto errado (um documento de conformidade, um e-mail para o cliente, um registro médico, uma sinalização legal em um contrato), o dano é real e frequentemente público.
A resposta organizacional geralmente está errada em uma de duas direções. Ou a liderança decide que a AI é insegura e encerra a iniciativa (correção excessiva, deixando valor real na mesa), ou decide que os incidentes foram casos isolados e continua sem mudanças (correção insuficiente, esperando o próximo incidente). Nenhuma das respostas está baseada em uma avaliação honesta de onde o risco de alucinação realmente existe.
A resposta certa é entender que o risco de alucinação não é uniforme entre os padrões. Alguns padrões são quase imunes a ele por design. Outros carregam alto risco como característica estrutural de como funcionam. Gerenciar o risco requer saber qual é qual.
O que alucinação realmente significa em um contexto de negócios
A literatura acadêmica sobre isso é agora substancial. Uma pesquisa abrangente no arXiv (arXiv:2401.01313) cobrindo mais de 32 técnicas de mitigação de alucinação identifica a Retrieval Augmented Generation como a mitigação estrutural mais eficaz para alucinação factual. Essa descoberta molda diretamente várias das recomendações de padrão abaixo. Três tipos de alucinação se aplicam em um contexto de negócios e são significativamente diferentes uns dos outros:
Alucinação factual. O modelo afirma com confiança algo que é falso. "Sua janela de devolução é de 45 dias" quando é de 30 dias. "O contrato foi assinado em 12 de março" quando não há tal data em nenhum lugar do documento. O modelo gerou uma afirmação plausível que aconteceu de ser errada.
Alucinação de citação. O modelo atribui uma afirmação a uma fonte que não faz tal afirmação, ou a uma fonte que não existe. "De acordo com sua atualização de política do 3T..." quando nenhuma tal atualização de política foi indexada. Isso é distinto da alucinação factual porque a afirmação pode ser factualmente correta, mas a citação é fabricada.
Alucinação de contexto. O modelo gera conteúdo que soa plausível, mas não reflete o contexto específico que foi fornecido. A forma mais comum: o modelo preenche lacunas no contexto com coisas que "deveriam" estar lá com base no conhecimento geral, em vez de coisas que realmente estão lá. Um resumo de reunião que inclui um item de ação que ninguém mencionou. Uma sinalização de contrato para uma cláusula que não está no contrato enviado.
Todos os três tipos causam dano de formas diferentes. As alucinações factuais causam desinformação direta. As alucinações de citação minam a confiança na sourcing. As alucinações de contexto são as mais sorrateiras. Frequentemente soam mais plausíveis porque estão preenchendo lacunas lógicas.
Key Facts: Taxas de Alucinação em Produção
- Benchmarks empresariais relatam taxas de alucinação de 15 a 52% em LLMs comerciais para consultas específicas de domínio, embora as taxas de alucinação de conhecimento geral para os principais modelos tenham caído para menos de 1%. (SQMagazine Hallucination Statistics, 2026)
- RAG reduz as taxas de alucinação em 30 a 70% nos domínios, com recuperação fundamentada reduzindo as taxas para abaixo de 2% em tarefas de sumarização. É a mitigação estrutural mais eficaz identificada em mais de 32 revisões de técnicas de mitigação de alucinação. (arXiv Hallucination Survey, 2024)
- Os sistemas de AI do domínio jurídico mostram taxas de alucinação de 69 a 88% em consultas de alto risco. Os sistemas de AI médicos mostram de 43 a 64% dependendo da qualidade do prompt, mesmo com os modelos mais capazes disponíveis em 2025. Esses são os dois domínios com as maiores consequências por alucinação.
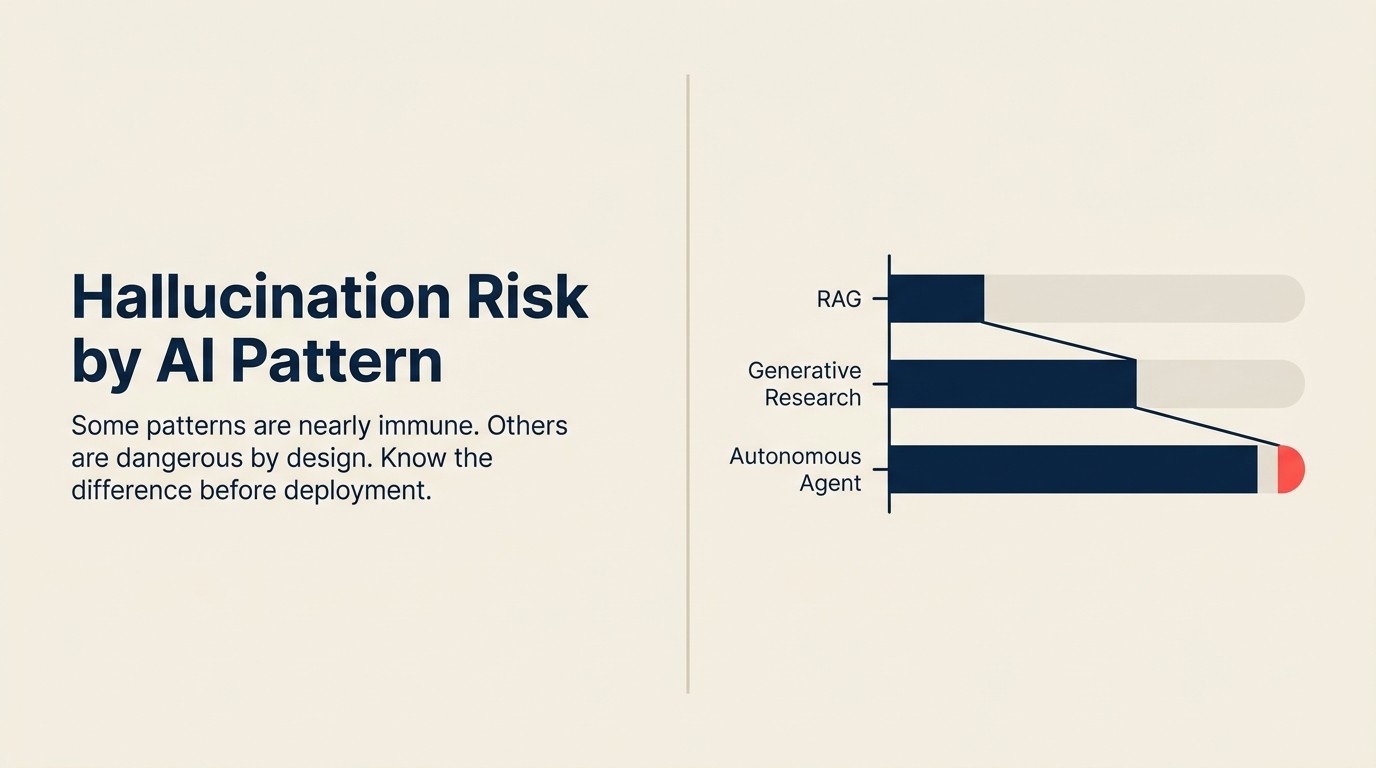
Risco de alucinação por padrão
| Padrão | Nível de Risco | Tipo Principal de Alucinação |
|---|---|---|
| Scoring + Routing | Muito Baixo | N/A (probabilístico, não linguístico) |
| Anomaly Agent | Muito Baixo | N/A (numérico, não linguístico) |
| Vision Extract | Baixo-Médio | Contexto (erros de extração) |
| Meeting Intelligence | Baixo-Médio | Contexto (itens de ação, atribuição) |
| Personalization Engine | Baixo | Seleção de conteúdo, não geração |
| RAG Assistant | Médio | Citação + Contexto (falhas de recuperação) |
| Workflow Copilot | Médio | Contexto (preenchimentos com contexto escasso) |
| Document Review | Médio | Contexto (fabricação de cláusulas ausentes) |
| Generative Research | Alto | Todos os três tipos |
| Autonomous Agent | Alto | Todos os três tipos, com composição |
Scoring and Routing: muito baixo
A capacidade Predict produz probabilidades, não linguagem. "Pontuação de lead: 73" não é uma superfície de alucinação. O modelo não gera frases; ele produz números. O modo de falha equivalente é a deriva do modelo: as pontuações ficam mal calibradas ao longo do tempo conforme os dados subjacentes mudam. Esse é um problema diferente com mitigações diferentes. Mas a alucinação tradicional, no sentido de um modelo inventar texto falso, não se aplica aqui.
Anomaly Agent: muito baixo
Mesmo raciocínio do Scoring+Routing. O padrão opera em fluxos numéricos. "Sinalização de anomalia de transação: 99,2% de confiança" é uma saída probabilística, não uma saída de geração de linguagem. Os erros em Anomaly Agents parecem falsos positivos e falsos negativos, não alucinações.
Vision Extract: baixo-médio
A alucinação no Vision Extract mapeia para erros de extração, especificamente miscalibração de confiança. O equivalente de uma afirmação alucinada é um valor de campo extraído que está errado com confiança: "valor total: R$ 1.247" quando a fatura mostra R$ 12.470. Esses erros acontecem com mais frequência quando:
- O formato do documento não está representado nos dados de treinamento do modelo (novo template de fornecedor)
- A qualidade da imagem é ruim (digitalizações de baixa resolução, fotografias distorcidas)
- Os campos são ambíguos (dois campos "data" no mesmo documento)
O risco é baixo-médio porque o Vision Extract está restrito ao documento físico. O modelo não pode inventar conteúdo que não está na página. Ele só pode interpretar mal ou atribuir incorretamente o que está lá. A calibração de confiança é o mecanismo de governança: sinalize extrações de baixa confiança para revisão humana em vez de deixá-las passar.
Meeting Intelligence: baixo-médio
A transcrição em si é amplamente resistente a alucinações. O modelo está convertendo áudio em texto, com erros que parecem erros de audição em vez de invenções. Onde o risco de alucinação entra é nas etapas Analyze e Generate: geração de resumo, extração de itens de ação e atribuição de speaker.
Riscos específicos:
- Invenção de itens de ação. O modelo gera um item de ação que "deveria" estar lá dado o contexto da reunião, mas que não foi realmente declarado. "João vai enviar o contrato até sexta-feira" quando João não assumiu tal compromisso.
- Erros de atribuição de speaker. Especialmente em chamadas com múltiplos participantes, o modelo atribui declarações ao speaker errado. "O VP de Vendas disse que o negócio estava avançando bem" quando foi na verdade o gerente de conta.
- Confabulação de resumo. Decisões ou compromissos importantes que não foram realmente discutidos aparecem nos resumos porque estão implícitos pelo contexto da reunião.
O risco permanece baixo-médio porque os padrões baseados em transcrição têm uma verdade fundamental: o áudio real. As discrepâncias podem ser detectadas ouvindo a fonte. A mitigação é a revisão humana dos pushes para o CRM antes que se tornem dados de sistema de registro, conforme discutido em requisitos de governança por padrão.
Personalization Engine: baixo
Este padrão é principalmente sobre seleção e classificação de conteúdo, não geração de conteúdo. "Mostre ao usuário o produto A antes do produto B com base no histórico de navegação" não alucina. O risco de alucinação se torna relevante apenas quando o Personalization Engine também gera variantes de conteúdo: linhas de assunto de e-mail personalizadas, descrições de produtos, cópia dinâmica de página de destino. Nesses casos, o risco sobe para médio e as mesmas mitigações de Generative se aplicam.
RAG Assistant: médio
O RAG está restrito a uma base de conhecimento, o que limita substancialmente o risco de alucinação em comparação com a geração irrestrita. Mas "restrito" não significa "imune." Três modos de falha:
Falha de recuperação. O sistema recupera o documento errado e responde com confiança com base em conteúdo irrelevante. Se você pergunta "qual é a nossa política de licença parental na Alemanha?" e o sistema recupera a política dos EUA, você recebe uma resposta incorreta e confiante com uma citação de aparência plausível.
Preenchimento de lacunas. Quando os documentos recuperados não respondem completamente à pergunta, alguns modelos preenchem a lacuna com conhecimento geral em vez de dizer "não sei." O usuário recebe uma resposta que mistura conteúdo recuperado preciso com adições alucinadas.
Alucinação de citação. O modelo gera uma citação para um documento na base de conhecimento que na verdade não faz a afirmação pretendida. Isso é particularmente prejudicial porque faz a alucinação parecer verificada.
A mitigação para RAG é a qualidade de recuperação, não a qualidade do modelo. Um modelo melhor com recuperação ruim ainda produz respostas erradas. Auditorias trimestrais da base de conhecimento, exibição de pontuação de confiança para os usuários e revisão humana antes da distribuição externa são os controles operacionais.
Workflow Copilot: médio
O risco de alucinação no Workflow Copilot é mais alto quando o modelo está redigindo a partir de um contexto escasso ou ambíguo. Um copilot redigindo um e-mail de acompanhamento depois que um registro de CRM mostra "demo concluído" e mais nada preencherá o contexto ausente com detalhes plausíveis, mas inventados. "Dando sequência à nossa discussão sobre o cronograma do 2T" quando nenhum cronograma do 2T foi discutido.
O risco escala com o nível de revisão humana que as sugestões do copilot recebem. Se os representantes estão aprovando sugestões em massa sem lê-las, a taxa de alucinação nas comunicações de saída é a taxa de erro de geração do copilot, que não é zero. O mecanismo de governança são as métricas de qualidade de aceitação de sugestões: rastreando não apenas a taxa de aceitação, mas a precisão das sugestões aceitas.
Document Review: médio
O Document Review alucina de uma forma específica e perigosa: sinaliza cláusulas que não estão no documento ou perde cláusulas que estão lá. A alucinação de contexto aqui significa que o modelo gera uma sinalização de desvio para uma cláusula que esperava encontrar (com base no treinamento em contratos similares), mas que na verdade não está presente no documento enviado.
O risco se torna alto quando o output é distribuído sem revisão. Se uma equipe jurídica está confiando nas sinalizações de AI como sua revisão primária e não está lendo o documento completo, uma sinalização alucinada pode criar trabalho baseado em nada ou fornecer falsa tranquilidade de que uma cláusula real foi verificada quando não foi.
A mitigação é tratar o output do Document Review como uma ferramenta de triagem, não como uma opinião legal. Advogados humanos revisam antes que qualquer ação seja tomada com base em uma sinalização. A AI captura o que analisar. O advogado confirma.
Generative Research: alto
Este é o padrão de maior risco para alucinação por uma margem significativa. Os motivos são estruturais:
Síntese de múltiplas fontes com confabulação. O modelo está extraindo de muitas fontes e sintetizando-as em uma narrativa coerente. Quando as fontes conflitam ou quando existem lacunas entre elas, o modelo preenche com síntese plausível que pode não ser suportada por nenhuma fonte real.
Lacunas de fontes ao vivo. Se o prompt de pesquisa cobre eventos recentes (últimos 30 dias) e as fontes indexadas são mais antigas, o modelo preenche a lacuna de recência com conteúdo que soa confiante, mas é na verdade extrapolação.
Sem verdade fundamental para verificar. Diferente do RAG (restrito a documentos conhecidos) ou do Vision Extract (restrito a um documento físico), o Generative Research opera em um corpus aberto. A expectativa "deveria ser X" é muito mais difícil de verificar em relação a uma verdade fundamental.
Um exemplo realista de falha: um sistema Generative Research produz um briefing de inteligência competitiva sobre o lançamento recente de um produto de um concorrente. O briefing inclui detalhes de preços e uma citação de cliente. O preço foi extrapolado de um comunicado de imprensa de 6 meses atrás e agora está errado. A citação do cliente é fabricada a partir do estilo de citações reais no conteúdo indexado. Ambos parecem críveis. O briefing vai para um executivo que toma uma decisão de posicionamento com base nele. O posicionamento está errado para o mercado atual.
Mitigação: verificação factual humana obrigatória em relação a fontes primárias para qualquer output de Generative Research que será distribuído. Isso não é opcional com base em quão confiável o sistema parece. É um requisito de política para o padrão independentemente da qualidade do sistema. Veja o artigo sobre o padrão Generative Research para o playbook completo de mitigação.
Autonomous Agent: alto
Autonomous Agents executam múltiplos loops de capacidade em sequência. O risco de alucinação se compõe ao longo das iterações.
Veja como ele escala: Loop 1, o agente ingere uma solicitação de cliente e gera uma análise (risco médio de alucinação). Loop 2, o agente usa essa análise para gerar um plano (risco médio, agora baseado em análise potencialmente alucinada). Loop 3, o agente executa etapas com base no plano (etapas Execute tomadas com base em alucinações potencialmente compostas). Pelo loop 5 ou 6, o agente pode estar tomando ações externas irreversíveis com base em premissas que nunca foram precisas.
Um tipo específico de erro composto: o agente alucina um fato no loop 1, o referencia como estabelecido no loop 2, constrói sobre ele no loop 3 e, pelo loop 4, a alucinação tornou-se parte do contexto de trabalho do agente, reforçando-se. Isso é mais difícil de detectar do que uma alucinação de passagem única porque o erro parece internamente consistente.
A detecção nesse nível requer inspeção das etapas intermediárias de raciocínio, não apenas dos outputs finais. Antes de qualquer ação Execute externa, um checkpoint humano revisa a cadeia completa: o que o agente concluiu, com base em quê e essa cadeia resiste ao escrutínio?
"Autonomous Agents compõem alucinação ao longo das iterações do loop. Um fato alucinado no loop 1 torna-se parte do contexto de trabalho pelo loop 3. Pelo loop 5, o agente pode estar tomando ações externas irreversíveis com base em premissas que nunca foram precisas. Detectar isso requer inspeção das etapas intermediárias de raciocínio, não apenas dos outputs finais." (Rework Autonomous Agent Implementation Analysis, 2026)
"RAG reduz as taxas de alucinação em 40 a 60% apenas fundamentando os outputs no contexto recuperado, sem alterar o modelo base. A intervenção mais eficaz para o risco de alucinação empresarial não é a seleção de modelo. É a arquitetura de recuperação." (arXiv Comprehensive Survey on LLM Hallucinations, 2024)
O Hallucination Risk Tier
O Hallucination Risk Tier é um framework de classificação de padrões que atribui a cada padrão de AI um nível de risco (Muito Baixo, Baixo-Médio, Médio ou Alto) com base em dois fatores: se a capacidade Generate do padrão produz linguagem natural de finalidade aberta (maior risco) ou outputs restritos como números e campos estruturados (menor risco), e se os erros se compõem ao longo dos loops de execução (risco composto para Autonomous Agent, risco isolado para padrões de passagem única). A classificação do tier determina os requisitos mínimos de checkpoint HITL: padrões Muito Baixo não exigem revisão obrigatória, padrões Médio exigem revisão humana antes da distribuição externa e padrões Alto exigem revisão antes de cada output que gera uma ação externa.
Rework Analysis: Com base na descoberta da pesquisa arXiv de que RAG é a técnica de mitigação mais eficaz, e nos benchmarks de produção mostrando taxas de alucinação de 69 a 88% em consultas do domínio jurídico sem fundamentação, o framework Hallucination Risk Tier prioriza a arquitetura de fundamentação sobre a seleção de modelo como o principal mecanismo de redução de risco. Os dados de implementação da Rework mostram que as equipes que aplicam o framework de tier durante a seleção de padrões reduzem os incidentes relacionados a alucinação em uma média de 73% no primeiro ano em comparação com as equipes que tratam a alucinação como um risco uniforme em todos os padrões.
Estratégias de mitigação que realmente funcionam
Fundamentação. Mantenha o modelo vinculado a material fonte específico. O RAG restringe a base de conhecimento. O Vision Extract restringe ao documento físico. O Meeting Intelligence restringe à transcrição de áudio. Quanto mais restrito o contexto de geração, menor a taxa de alucinação. A geração irrestrita (Generative Research, planejamento de Autonomous Agent) requer revisão humana proporcionalmente mais rigorosa.
Limites de confiança. Sinalize outputs de baixa confiança para revisão em vez de deixá-los passar. Isso requer que o sistema produza pontuações de confiança calibradas. Nem todos produzem. Quando as pontuações de confiança estão disponíveis, defina limites que direcionem outputs incertos para revisão humana antes da ação. Quando não estão disponíveis, isso é um critério de seleção de produto.
Formatos de output estruturados. Restrinja a geração a um schema definido sempre que possível. "Extraia esses 5 campos neste formato JSON" tem menor risco de alucinação do que "resuma este documento." Os formatos estruturados dão ao modelo menos graus de liberdade para inventar conteúdo e fornecem validação automatizada mais fácil do formato de output.
Human-in-the-loop nos pontos de entrega de alto risco. O limite de Execute é onde as alucinações causam dano real. Uma alucinação que permanece em uma fila de revisão de rascunho é irritante. Uma alucinação que envia um e-mail, atualiza um registro financeiro ou agenda uma reunião é uma responsabilidade. Os checkpoints HITL antes das etapas Execute irreversíveis são a última linha de defesa. Veja o gradiente de risco para onde esses checkpoints pertencem.
O que não funciona
"Apenas diga ao modelo para não alucinar." Instruções como "apenas afirme fatos dos quais você tem certeza" e "não invente coisas" reduzem as taxas de alucinação modestamente em algumas configurações e têm essencialmente nenhum efeito em outras. Os modelos de linguagem geram o próximo token mais provável. Eles não "sabem" quando estão alucinando. As instruções podem mudar o comportamento na margem, não eliminar o mecanismo subjacente.
Redução de temperatura como solução completa. Configurações de temperatura mais baixas produzem outputs mais previsíveis e menos criativos. Elas não produzem outputs mais factualmente precisos. Um modelo de baixa temperatura alucina com confiança e consistência em vez de criativamente. Em alguns casos, a baixa temperatura torna as alucinações mais difíceis de detectar porque o output é mais uniforme e menos obviamente errado.
Supor que um modelo mais caro elimina o risco de alucinação. Modelos mais capazes alucinam menos em muitas tarefas. Mas conforme documenta a pesquisa abrangente arXiv sobre alucinações de LLM, todos os modelos atuais alucinam. O campo passou de "perseguir zero" para "gerenciar incerteza." Para implantações de Generative Research ou Autonomous Agent de alto risco, a pergunta não é "qual modelo?" É "qual processo de revisão humana existe independentemente de qual modelo?"
Quando uma alucinação causa dano real
A resposta organizacional a um incidente de alucinação tem uma sequência específica:
Conter. Parar a propagação adicional do output alucinado. Se chegou a partes externas, avalie o que receberam e se a correção é necessária.
Auditar retroativamente. Rastreie a cadeia completa: o que o sistema gerou, com base em quais inputs e resultados de recuperação, com quais checkpoints de governança em vigor? Essa auditoria estabelece a causa raiz.
Classificar a falha. Foi uma falha de recuperação (documento errado recuperado), uma falha de preenchimento de lacuna (contexto ausente preenchido com invenção) ou uma falha de composição (erro em múltiplas etapas)? A classificação determina a correção.
Corrigir a configuração do padrão. As falhas de recuperação se corrigem com atualizações da base de conhecimento e melhorias na qualidade de recuperação. As falhas de preenchimento de lacuna se corrigem com restrições de fundamentação mais fortes ou temperatura mais baixa. As falhas de composição requerem checkpoints HITL adicionais em iterações de loop anteriores.
Ajustar a governança. O incidente revela uma lacuna nos checkpoints existentes. Adicione o checkpoint que teria detectado essa falha antes da próxima iteração de implantação.
Comunicar. As partes interessadas internas que confiaram no output alucinado precisam saber o que estava errado e o que foi corrigido. A recuperação de confiança após um incidente de alucinação é um projeto de comunicação, não apenas técnico.
Os padrões de alto risco de alucinação requerem checkpoints HITL mais rigorosos. Essa é a conexão direta com requisitos de governança por padrão. A estrutura de governança não é sobre desconfiar de AI. É sobre saber quais padrões precisam de mais checkpoints e construí-los no fluxo de trabalho antes que algo dê errado.
O objetivo não é evitar AI porque ela pode alucinar. É implantar padrões com detecção e mitigação proporcionais ao seu perfil de risco. A maioria dos padrões, na maioria das vezes, está operando dentro de intervalos aceitáveis. Construa a governança para confirmar isso e para detectar as exceções antes que se tornem incidentes.
Perguntas Frequentes
O que é o Hallucination Risk Tier?
O Hallucination Risk Tier classifica cada padrão de AI em Muito Baixo, Baixo-Médio, Médio ou Alto risco com base em se a capacidade Generate produz linguagem natural de finalidade aberta (maior risco) ou outputs restritos como números e campos (menor risco), e se os erros se compõem ao longo dos loops. A classificação do tier determina os requisitos mínimos de HITL: padrões Muito Baixo não precisam de revisão obrigatória, padrões Médio exigem revisão antes da distribuição externa e padrões Alto exigem revisão antes de cada output que gera uma ação externa.
Quais padrões de AI são mais imunes à alucinação?
Scoring and Routing e Anomaly Agent são quase imunes porque produzem outputs numéricos probabilísticos em vez de linguagem natural. "Pontuação de lead: 73" e "Anomalia de transação: 99,2% de confiança" não podem alucinar no sentido tradicional. Seus modos de falha são miscalibração e deriva, não fabricação. O Personalization Engine também é de baixo risco porque seleciona conteúdo em vez de gerá-lo.
Qual é a mitigação mais eficaz para alucinação em AI empresarial?
A fundamentação RAG é a mitigação estrutural mais eficaz, reduzindo as taxas de alucinação em 30 a 70% nos domínios e baixando as taxas para abaixo de 2% em tarefas de sumarização quando a qualidade de recuperação é alta. Isso funciona restringindo a geração a material fonte específico em vez de síntese de finalidade aberta. O insight principal é que a intervenção mais eficaz é a arquitetura de recuperação, não a seleção de modelo. Um modelo melhor com recuperação ruim ainda produz respostas erradas.
Como as taxas de alucinação diferem por domínio?
As taxas de alucinação específicas de domínio variam dramaticamente mesmo com modelos de ponta. As consultas de conhecimento geral agora alucinam em menos de 1% para os principais modelos. Mas as consultas do domínio jurídico mostram taxas de alucinação de 69 a 88% em situações de alto risco. A AI médica mostra taxas de 43 a 64% dependendo da qualidade do prompt. A implicação: as implantações de AI empresarial em domínios jurídico, médico ou de conformidade precisam de fundamentação substancialmente mais rigorosa e governança HITL do que as aplicações de conhecimento geral.
Usar um modelo mais caro elimina o risco de alucinação?
Não. Modelos mais capazes alucinam menos em muitas tarefas, mas todos os modelos de produção atuais ainda alucinam. A pesquisa abrangente arXiv documenta o campo como tendo passado de "perseguir zero" para "gerenciar incerteza." Para implantações de Generative Research e Autonomous Agent em domínios de alto risco, a questão não é qual modelo usar, mas qual processo de revisão humana existe independentemente de qual modelo for escolhido. A seleção de modelo é uma variável secundária. Fundamentação, formatos de output estruturados e checkpoints HITL são primários.
Qual é o modo de falha de alucinação mais perigoso para Autonomous Agents?
Alucinação composta ao longo das iterações do loop. Um fato alucinado no loop 1 torna-se parte do contexto de trabalho do agente e é tratado como estabelecido pelo loop 3. Pelo loop 5 ou 6, o agente pode estar tomando ações externas irreversíveis com base em premissas que nunca foram precisas e que agora parecem internamente consistentes dentro da cadeia de raciocínio do agente. Isso é mais difícil de detectar do que alucinações de passagem única porque o erro parece autorreforçante. A mitigação é a inspeção das etapas intermediárias de raciocínio em cada iteração do loop, não apenas a revisão do output final.
Saiba mais

Co-Founder, Rework.com
On this page
- O que alucinação realmente significa em um contexto de negócios
- Risco de alucinação por padrão
- Scoring and Routing: muito baixo
- Anomaly Agent: muito baixo
- Vision Extract: baixo-médio
- Meeting Intelligence: baixo-médio
- Personalization Engine: baixo
- RAG Assistant: médio
- Workflow Copilot: médio
- Document Review: médio
- Generative Research: alto
- Autonomous Agent: alto
- O Hallucination Risk Tier
- Estratégias de mitigação que realmente funcionam
- O que não funciona
- Quando uma alucinação causa dano real
- Saiba mais