Generative Research: Memampatkan Jam-Jam Membaca
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Analis yang baik dapat menyintesis 30 sumber menjadi brief yang koheren. Mereka tahu sumber mana yang harus dipercaya, mana yang harus diberi bobot ringan, cara menampilkan ketegangan ketika dua sumber yang kredibel tidak setuju, dan cara membuat output dapat dibaca untuk VP yang memiliki delapan menit sebelum rapat board.
Sebagian besar tim tidak mampu memiliki cukup analis untuk melakukan ini dengan baik, secara konsisten, di setiap pasar, akun, dan pesaing yang mereka pedulikan. Riset akun sebelum panggilan penjualan terlewatkan. Laporan competitive intelligence sudah usang tiga minggu ketika digunakan. Uji tuntas pada target akuisisi yang potensial dangkal karena tidak ada yang punya waktu untuk mendalami lebih jauh.
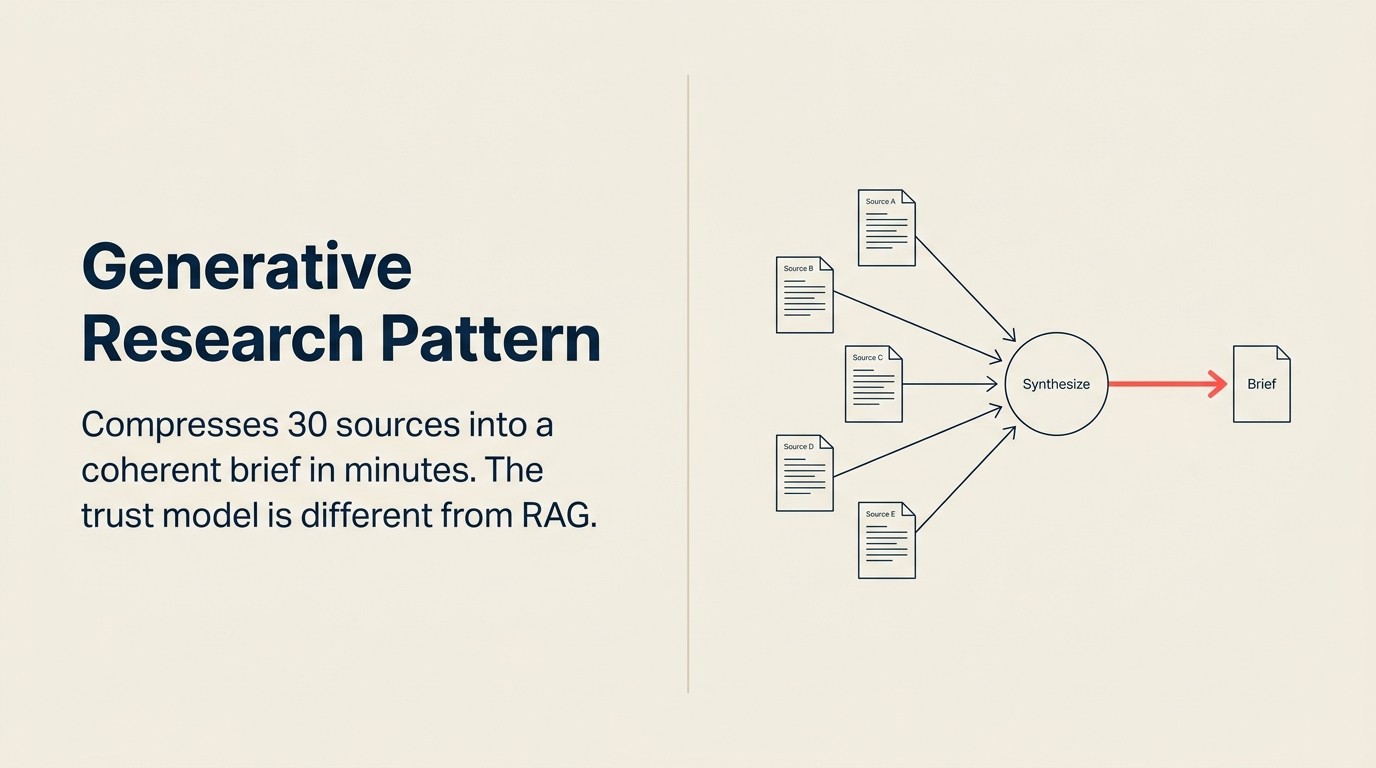
Generative Research adalah AI pattern yang memampatkan pekerjaan sintesis ini menjadi menit-menit. Bukan dengan menghilangkan analisis, tetapi dengan mengotomatisasi pembacaan, referensi silang, dan penataan awal yang menghabiskan sebagian besar waktu analis. Penilaian analis masih penting di akhir. Tetapi analis memulai dari brief 10 halaman alih-alih dari 30 tab browser.
Pattern ini hadir dengan pertanyaan kepercayaan yang tidak dimiliki oleh pattern saudaranya, RAG Assistant. RAG mengambil dari knowledge base yang diketahui dan terkontrol. Generative Research menjelajahi sumber langsung, eksternal, atau lintas domain. Perbedaan tersebut mengubah tampilan verifikasi dan tempat failure modes berkerumun.
Formulanya: Ingest, Analyze, Generate
Ingest (korpus multi-sumber) menarik materi sumber mentah. Sumbernya tergantung pada kasus penggunaan. Untuk competitive intelligence: siaran pers, ulasan G2 dan Capterra, posting pekerjaan LinkedIn, rekaman konferensi, transkrip earnings call, artikel pers perdagangan. Untuk riset akun: berita terbaru perusahaan target, profil LinkedIn kepemimpinan, laporan analis industri, pengumuman pendanaan terbaru, sebutan pesaing. Untuk sintesis tren eksekutif: transkrip earnings call dari 10-20 perusahaan publik di sektor tersebut, kutipan Gartner atau Forrester, artikel berita tingkat board. Lapisan Ingest melakukan pengumpulan dan normalisasi awal: mengonversi PDF, halaman web, transkrip, dan data terstruktur menjadi potongan teks yang dapat dibaca.
Analyze (sintesis) adalah langkah yang paling menuntut dalam pattern ini. Model tidak hanya merangkum setiap sumber secara independen. Ia membaca semua sumber secara bersamaan, mengidentifikasi apa yang disepakati beberapa sumber (sinyal kepercayaan tinggi), menampilkan di mana sumber-sumber bertentangan (area ketidakpastian), mengekstrak entitas yang disebutkan dan fakta kunci, dan membangun interpretasi yang koheren tentang apa yang secara kolektif dikatakan oleh bukti tersebut. Sintesis lintas-sumber ini adalah tempat Generative Research berbeda dari rangkuman dokumen sederhana. Merangkum setiap sumber secara terpisah bukan pattern ini. Nilainya ada di lapisan sintesis. Lihat Analyze: cara AI memahami apa yang Anda kumpulkan untuk definisi kemampuan lengkap.
Generate (laporan, brief, atau output terstruktur) menghasilkan deliverable. Ini mungkin analisis kompetitif yang diformat sebagai brief bagian per bagian dengan kutipan, kartu riset akun yang diformat untuk sisipan CRM, memo eksekutif dengan poin-poin dan tindakan yang direkomendasikan, atau tabel ukuran pasar dengan catatan kaki sumber. Langkah Generate memformat wawasan yang disintesis ke dalam format output yang dibutuhkan pemohon.
Perhatikan bahwa pattern ini berakhir pada Generate. Tidak ada langkah Execute dalam formula dasar. Outputnya adalah draf untuk ditinjau manusia sebelum pergi ke mana pun. Untuk sebagian besar kasus penggunaan Generative Research, tinjauan manusia tersebut tidak opsional. Ini adalah mekanisme tata kelola yang membuat pattern aman untuk didistribusikan.
Key Facts: Dampak Generative Research
- McKinsey memperkirakan AI generatif dapat mengotomatisasi 60-70% waktu karyawan yang saat ini dihabiskan untuk aktivitas knowledge work, dengan sintesis riset dikutip sebagai salah satu aktivitas knowledge work bernilai tertinggi yang dapat dikompresi (McKinsey, 2023)
- Sales rep menyelesaikan riset pra-panggilan pada 40-60% panggilan tanpa bantuan AI; dengan brief akun yang dihasilkan AI, tingkat penyelesaian riset pra-panggilan meningkat menjadi 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- Brief competitive intelligence berbasis AI menyintesis 20-50 sumber dalam 2-4 jam versus 6-8 jam per analis per pesaing menggunakan riset manual, peningkatan cakupan sumber 3-5x pada pengurangan waktu 85-90% (Gartner Competitive Intelligence Report, 2025)
The Multi-Source Synthesis Pattern
Nilai inti Generative Research bukan rangkuman sumber individual. Ini adalah sintesis lintas-sumber: menemukan apa yang disepakati beberapa sumber (sinyal kepercayaan tinggi), menampilkan di mana sumber-sumber bertentangan (area ketidakpastian), dan menyimpulkan apa yang diimplikasikan oleh bukti gabungan di luar apa yang secara eksplisit dinyatakan oleh sumber tunggal mana pun. Deployment Generative Research yang merangkum setiap sumber secara independen dan menyajikan rangkuman secara berdampingan tidak menggunakan pattern ini. Pattern ini memerlukan langkah Analyze yang membaca semua sumber secara bersamaan dan menghasilkan interpretasi terpadu. Lapisan sintesis itulah yang memampatkan 30 sumber menjadi brief yang koheren, dan inilah yang memisahkan Generative Research dari kumpulan rangkuman yang disambung bersama.
Generative Research vs. RAG Assistant: perbedaan kritis
Dua pattern ini adalah yang paling sering tertukar dalam praktik.
RAG Assistant mengambil jawaban dari knowledge base internal yang terkontrol dan diketahui. Anda tahu apa yang ada di knowledge base (dokumen produk Anda, tiket support masa lalu, kebijakan HR). Retrieval dibatasi. Jawaban mengutip sumber yang ada di sistem Anda. Failure mode adalah mengambil dokumen yang salah atau knowledge base yang kedaluwarsa. Bukan fabrikasi dari web terbuka.
Generative Research menyintesis dari korpus yang sering eksternal, langsung, atau lintas domain. Sumber-sumber tidak diindeks sebelumnya di sistem Anda. Mereka ditarik pada waktu query dari pencarian web, umpan API, dokumen yang diunggah, atau database pihak ketiga. Sintesis dapat menampilkan informasi yang tidak dinyatakan secara eksplisit oleh sumber tunggal mana pun: model menyimpulkan dari kombinasi tersebut. Kemampuan inferensi tersebut adalah nilai sekaligus risikonya.
Implikasi praktis: output RAG dapat diverifikasi dengan memeriksa sumber yang dikutip. Output Generative Research memerlukan spot-checking baik sumber yang dikutip (apakah sumber benar-benar mengatakan apa yang dikaitkan?) maupun logika sintesis (apakah inferensi bertahan?). Proses verifikasi yang berbeda, persyaratan tata kelola yang berbeda.
Lima contoh nyata secara mendalam
1. Pelaporan competitive intelligence
VP of Product membutuhkan pembaruan kompetitif kuartalan tentang tiga pesaing langsung. Setiap pesaing memiliki situs web, profil G2, LinkedIn aktif, siaran pers terbaru, dan sejumlah sebutan ulasan di Reddit dan Capterra. Membaca dan menyintesis semua itu secara manual membutuhkan analis produk 6-8 jam per pesaing.
Ingest menarik dari semua sumber ini: halaman web yang di-scrape pada waktu pengambilan, ulasan G2 yang difilter berdasarkan tanggal, posting dan daftar pekerjaan LinkedIn, siaran pers, dan sebutan berita. Analyze merujuk silang sumber-sumber: fitur apa yang secara konsisten disebutkan reviewer dalam ulasan G2 yang tidak ada di situs web perusahaan sendiri? Apa yang diisyaratkan posting pekerjaan untuk "Head of Enterprise Sales" tentang arah strategis mereka? Di mana dua sumber tidak setuju (satu ulasan menyebut UX sangat baik; ulasan lain menandainya sebagai kelemahan)?
Generate menghasilkan brief terstruktur: pembaruan produk dalam kuartal, perubahan positioning, sinyal penetapan harga dari ulasan, sinyal bakat dari daftar pekerjaan, dan kutipan utama dari sumber pihak ketiga. Output diformat sebagai ringkasan satu halaman dengan bagian yang dapat diperluas untuk setiap kategori sumber.
Tinjauan manusia memeriksa: apakah kutipan yang dikutip benar-benar berasal dari sumber yang dikutip? Apakah kesimpulan strategis yang disimpulkan bertahan di bawah pengawasan?
Alat yang mendukung ini: Perplexity API, Tavily untuk grounding pencarian web, Claude dan GPT-4 dengan alat pencarian, dan platform competitive intelligence yang dibuat khusus seperti Crayon, Klue, dan Battlecards.
2. Brief riset akun sebelum panggilan penjualan
Sales director memiliki panggilan dalam 90 menit dengan VP of Operations di perusahaan manufaktur yang belum pernah ia ajak bicara sebelumnya. Ia perlu mengetahui: apa yang terjadi di perusahaan ini, apa tantangan terbaru mereka, siapa para pemangku kepentingan, dan apa konteks industrinya.
Ingest menarik: siaran pers dan liputan berita terbaru perusahaan (90 hari terakhir), profil LinkedIn dan aktivitas terbaru prospek, komentar publik terbaru CEO dan CFO, berita industri dari outlet perdagangan manufaktur, dan data CRM yang ada serta utas email masa lalu.
Analyze menampilkan: akuisisi baru-baru ini yang mengubah prioritas rantai pasokan mereka, posting LinkedIn dari prospek yang menyebutkan kompleksitas operasional sebagai tantangan, kutipan earnings call dari CEO tentang "efisiensi operasional" sebagai prioritas 2026, dan pola dalam perekrutan terbaru yang menunjukkan mereka membangun tim data.
Generate menghasilkan brief pra-panggilan dua halaman: konteks perusahaan utama (2 poin), perkembangan terbaru (3 poin), latar belakang kontak (2 poin), kemungkinan prioritas berdasarkan bukti (3 poin dengan sumber), dan pertanyaan pembuka yang disarankan terkait dengan intelijen. Rep meninjau dalam 8 menit, menyesuaikan pertanyaan pembuka berdasarkan pengetahuannya sendiri, dan menggunakan brief sebagai konteks, bukan sebagai naskah.
Pattern ini dibangun ke dalam "account summaries" Salesforce Einstein, fitur riset AI HubSpot, dan merupakan inti dari alat yang dibuat khusus seperti riset AI Apollo.io dan Warmly. Untuk versi kasus penggunaan khusus penjualan secara lengkap, lihat riset akun AI sebelum kontak pertama.
3. Sintesis tren industri eksekutif
CFO di perusahaan teknologi kesehatan menginginkan brief 20 menit sebelum rapat board tentang "di mana AI mempengaruhi siklus pendapatan kesehatan." Sintesis tersebut biasanya memerlukan membaca 6-8 laporan analis, 3 transkrip earnings call dari perusahaan publik yang relevan, dan selusin artikel pers perdagangan.
Ingest menarik dari kutipan Gartner (jika tersedia), liputan konferensi HIMSS, transkrip earnings call dari perusahaan health IT (Veeva, mitra Epic, Waystar), pers perdagangan dari Healthcare IT News dan Health Data Management, dan pengumuman investasi VC di ruang tersebut.
Analyze mengidentifikasi tema konsensus (otomatisasi adjudikasi klaim secara konsisten ditandai di 7 dari 10 sumber), perdebatan yang muncul (vendor AI mana yang benar-benar memberikan vs. berjanji), dan perusahaan kunci yang dikutip. Ia juga memeriksa sinyal yang bertentangan (satu sumber memproyeksikan pengurangan biaya admin 30%; laporan analis lain menyebut itu "optimistis").
Generate menghasilkan brief dua halaman: tiga tren konsensus dengan bukti, dua area ketidaksepakatan aktif yang ditandai secara eksplisit, lima perusahaan yang layak diperhatikan, dan bagian "pertanyaan yang kemungkinan akan Anda hadapi" dengan respons yang disarankan. CFO dapat menyampaikan ini sebagai komentar yang terinformasi, bukan sebagai teks yang dihasilkan AI.
4. Ukuran pasar dengan sumber yang dikutip
Head of Business Development startup membutuhkan ukuran pasar kasar untuk segmen baru sebelum rapat penggalangan dana. Analisis TAM/SAM/SOM perlu dapat dipertahankan: bukan angka ajaib, tetapi perkiraan yang dapat dilacak dengan sumber yang dapat diperiksa VC.
Ingest menarik: laporan analis industri, database statistik pemerintah (BLS, Census), earnings call perusahaan publik yang menyebutkan segmen tersebut, dan putaran pendanaan startup terbaru di ruang tersebut dengan asumsi pasar yang tersirat.
Analyze merujuk silang perkiraan ukuran dari beberapa sumber: satu analis mengatakan TAM $12M, S-1 pesaing mengimplikasikan $9M, laporan Gartner 2024 mengatakan $8M tumbuh pada 14%. Ia mengidentifikasi perbedaan metodologis (satu menghitung hanya perangkat lunak; yang lain menyertakan layanan). Ia menampilkan rentang perkiraan yang dapat dipertahankan dan asumsi yang mendorong masing-masing.
Generate menghasilkan memo ukuran pasar: bagian metodologi, tiga skenario (konservatif/dasar/optimistis), kutipan sumber per angka, dan satu paragraf catatan "cara mempertahankan ini" untuk rapat penggalangan dana.
5. Riset meja uji tuntas M&A
Tim strategi pembeli membutuhkan pandangan awal tentang perusahaan target sebelum keterlibatan formal. Mereka menginginkan intelijen sumber publik saja, sebelum menandatangani NDA. Ini adalah riset meja, bukan uji tuntas penuh, tetapi perlu menyeluruh.
Ingest menarik: situs web dan dokumentasi produk target, semua liputan pers publik, data LinkedIn tentang jumlah karyawan dan trajektori pertumbuhan (proxy untuk kinerja keuangan), ulasan Glassdoor untuk sinyal budaya, Crunchbase untuk riwayat pendanaan dan nama investor, G2 untuk sentimen pelanggan, dan pengajuan paten jika relevan.
Analyze menyintesis: perkiraan kisaran pendapatan dari sinyal pendanaan + pertumbuhan, kualitas tim dan sinyal churn dari LinkedIn dan Glassdoor, penilaian diferensiasi produk dari materi dan ulasan publik, positioning kompetitif dalam konteks akuisisi lain di ruang tersebut.
Generate menghasilkan memo uji tuntas dalam format yang digunakan tim strategi: ikhtisar bisnis, perkiraan keuangan dengan tingkat kepercayaan, penilaian tim, penilaian produk, tanda risiko, dan pertanyaan terbuka untuk proses uji tuntas formal.
Failure modes: apa yang merusak Generative Research
| Failure mode | Akar penyebab | Mitigasi |
|---|---|---|
| Confabulation | Model mengisi kesenjangan antara sumber nyata dengan klaim yang terdengar masuk akal yang tidak didukung oleh sumber mana pun | Memerlukan kutipan per klaim. Spot-check 3-5 kutipan per brief sebelum mendistribusikan. Jangan pernah mengedarkan tanpa reviewer manusia yang ditunjuk yang telah memeriksa sumber. |
| Keterlambatan mata uang sumber | Indeks pencarian web 2-3 hari di belakang; sintesis dokumen internal hanya segar seperti jalannya indeks terakhir | Sertakan timestamp crawl atau indeks dalam output. Tandai klaim yang sensitif terhadap waktu dengan tanggal sumbernya. Untuk intelijen kompetitif atau pasar langsung, verifikasi klaim utama secara langsung. |
| Sumber yang bertentangan disajikan sebagai terpadu | Model memilih satu interpretasi ketika sumber-sumber tidak setuju, tanpa menandai ketidaksesuaian | Prompt untuk penampilan konflik eksplisit: "Jika sumber tidak setuju tentang topik ini, tandai ketidaksesuaian tersebut dan kutip kedua sisi." Perlakukan brief apa pun yang menyajikan segalanya sebagai konsensus dengan kecurigaan. |
| Citation laundering | Model mengutip sumber nyata yang kredibel untuk klaim yang sebenarnya tidak dibuat sumber tersebut | Spot-check kutipan: bukan hanya bahwa sumber ada, tetapi bahwa bagian yang dikutip mendukung klaim yang dikaitkan. Ini adalah failure mode yang paling berbahaya karena terlihat otoritatif. |
| Scope drift | Prompt yang terlalu terbuka menghasilkan output 40 halaman yang komprehensif tetapi tidak dapat digunakan | Tentukan ruang lingkup dengan tepat: rentang waktu, jenis sumber, format output, dan batas kata. Prompt yang lebih sempit menghasilkan output yang lebih berguna daripada yang luas. |
| Bias sumber tunggal | Satu sumber dominan berkualitas tinggi menguasai sintesis; output mencerminkan satu perspektif, bukan pandangan multi-sumber | Periksa distribusi sumber dalam output. Jika 80% kutipan menunjuk ke satu sumber, sintesis tidak melakukan tugasnya. |
Citation laundering adalah failure mode yang paling berbahaya karena menghasilkan output yang terlihat otoritatif. Brief yang mengutip laporan Gartner nyata untuk klaim yang sebenarnya tidak dibuat laporan tersebut akan lolos tinjauan biasa dan gagal di bawah pengawasan. Evaluasi Stanford HAI 2024 tentang LLM terkemuka pada akurasi kutipan menemukan bahwa 23% kutipan yang dihasilkan otomatis dalam tugas sintesis panjang baik mengutip sumber yang tidak berisi klaim yang dikaitkan atau sedikit salah mewakili posisi sumber. Ini tidak membuat Generative Research tidak dapat digunakan. Ini membuat tinjauan manusia 15 menit tidak dapat dinegosiasikan.
Confabulation layak mendapat perhatian langsung karena ini adalah failure mode yang menciptakan kerusakan kepercayaan terbesar. Brief Generative Research yang berisi satu klaim yang dikutip dengan percaya diri yang tidak benar-benar dibuat oleh sumber yang dikutip akan, ketika ditemukan, menghancurkan kepercayaan pada seluruh brief dan pada pattern secara lebih luas. Riset OpenAI tentang GPT-4 mengakui ini secara langsung: bahkan model dengan kemampuan tinggi dapat menghasilkan konten yang terdengar masuk akal tetapi tidak akurat, itulah mengapa verifikasi kutipan tetap menjadi tanggung jawab manusia terlepas dari kualitas model. Mitigasinya bukan untuk menghindari pattern. Ini adalah membangun verifikasi ke dalam workflow sebelum distribusi. Lihat risiko halusinasi berdasarkan AI pattern untuk bagaimana ini dibandingkan dengan failure modes dalam pattern berat-Generate lainnya.
Trust model: verifikasi tidak opsional
RAG Assistant pattern mendapat manfaat dari trust model yang relatif terkandung. Knowledge base-nya milik Anda. Sumber-sumbernya diketahui. Jika jawaban salah, sumbernya salah, dan Anda dapat memperbaiki sumbernya.
Generative Research menggambar dari sumber eksternal, langsung, dan lintas domain. Sintesis dapat menghasilkan inferensi yang tidak didukung secara eksplisit oleh sumber individual mana pun. Itulah nilainya. Tetapi itu juga mengapa trust model harus eksplisit.
Sebelum output Generative Research apa pun didistribusikan, reviewer manusia yang ditunjuk harus:
- Membaca output sebagai dokumen penuh, bukan hanya ringkasannya
- Spot-check 3-5 kutipan, memverifikasi bahwa sumber ada dan bahwa klaim yang dikaitkan benar-benar ada dalam sumber
- Menandai klaim konsensus apa pun yang terasa dilebih-lebihkan mengingat dasar buktinya
- Menandai setiap bagian di mana sumber-sumber bertentangan (jika belum ditandai oleh AI)
- Menambahkan nama mereka ke dokumen sebagai analis peninjau
Tinjauan ini membutuhkan 15-30 menit untuk brief yang diformat dengan baik. Ini bukan sama dengan pekerjaan riset 6-8 jam asli. Itulah keuntungan produktivitas. Tetapi tinjauan 15 menit tidak opsional.
Kegagalan umum: tim menerapkan Generative Research dan berhenti melakukan spot-check setelah enam bulan pertama karena output "tampak baik-baik saja." Kemudian brief dengan statistik yang difabrikasi mencapai presentasi board. Perbaikannya adalah menjadikan spot-check sebagai langkah workflow yang terdokumentasi, bukan tinjauan opsional.
Kapan Generative Research bekerja (dan kapan tidak)
Bekerja dengan baik ketika:
- Pertanyaannya memiliki ruang lingkup yang ditentukan. "Apa yang diumumkan Pesaing X pada Q1 2026?" memiliki ruang lingkup. "Ceritakan semua tentang Pesaing X" tidak.
- Sumber tersedia dan dapat diakses. Untuk perusahaan publik, riset pasar, dan competitive intelligence, sumber publik biasanya kaya. Untuk perusahaan swasta atau pasar yang baru muncul, kualitas sumber menurun.
- Output akan ditinjau sebelum distribusi. Ini bukan masalah kepercayaan tentang teknologi. Ini adalah persyaratan workflow untuk output riset apa pun yang menginformasikan keputusan.
- Kebutuhannya adalah untuk sintesis, bukan untuk pencarian faktual spesifik. Jika Anda membutuhkan "berapa ARR Acme Corp?", itu adalah pencarian faktual di mana satu sumber otoritatif lebih baik dari sintesis. Jika Anda membutuhkan "apa yang dapat kita simpulkan tentang trajektori pertumbuhan Acme Corp dari sinyal publik?", itu adalah sintesis.
vs. RAG Assistant: RAG adalah knowledge base internal Anda yang menjawab pertanyaan yang diketahui. Generative Research adalah sintesis dari sumber eksternal atau lintas domain yang menghasilkan wawasan baru. Keduanya sering digunakan bersama: Generative Research untuk membangun brief intelijen dari sumber eksternal, RAG Assistant untuk menjawab "apa yang telah kita pelajari tentang akun ini?" dari brief dan catatan panggilan masa lalu.
vs. Document Review: Document Review mengambil dokumen tertentu dan memeriksa terhadap standar atau template yang diketahui. Generative Research mengambil banyak dokumen dan menyintesis output baru dari mereka. Perbedaannya: satu dokumen vs. banyak sumber; pemeriksaan kepatuhan vs. sintesis wawasan.
vs. Meeting Intelligence: Meeting Intelligence memproses rekaman percakapan Anda sendiri. Generative Research menggambar dari materi eksternal. Mereka dapat dipasangkan: Meeting Intelligence menangkap percakapan pelanggan Anda sendiri, Generative Research menyintesis konteks pasar eksternal, dan seorang ahli strategi menggabungkan keduanya untuk pandangan akun yang lengkap.
ROI signals: mengukur dampak
| Metrik | Baseline manual | Dengan Generative Research | Peningkatan tipikal |
|---|---|---|---|
| Jam analis per brief | 4-8 jam untuk brief kompetitif penuh | 30-60 menit (AI + tinjauan) | Pengurangan waktu 85-90% |
| Waktu dari permintaan ke deliverable | 1-3 hari (backlog + waktu penulisan) | 2-4 jam (penyelesaian hari yang sama) | Pengurangan waktu siklus 80-90% |
| Cakupan sumber per brief | 5-10 sumber (batas praktis untuk satu analis) | 20-50 sumber (batas sintesis AI lebih luas) | Peningkatan cakupan 3-5x |
| Frekuensi brief | 1 brief komprehensif per bulan per topik | Brief mingguan menjadi layak | Peningkatan kadence 4-6x |
| Tingkat penyelesaian riset pra-panggilan | 40-60% panggilan penjualan memiliki riset pra-panggilan apa pun | 85-95% dengan pembuatan brief akun otomatis | Peningkatan 40-50% |
Tingkat penyelesaian riset pra-panggilan sering kali merupakan metrik yang paling mudah dilacak, dan ini terhubung langsung ke hasil Pipeline. Ketika rep memasuki panggilan dengan brief, kualitas panggilan meningkat. Riset McKinsey tentang AI dalam penjualan B2B menemukan bahwa riset akun dan persiapan pra-panggilan adalah salah satu kasus penggunaan AI dengan antusias tertinggi bagi pemimpin penjualan, justru karena keuntungan produktivitas dapat diukur dan langsung. Bukan karena brief sempurna, tetapi karena memiliki konteks menggeser pembukaan dari "ceritakan tentang perusahaan Anda" menjadi "Saya melihat Anda baru saja membuka kantor baru di Austin. Apakah itu terkait dengan dorongan ekspansi yang Anda sebutkan dalam earnings call Anda?"
Rework Analysis: Deployment Generative Research yang berhasil memiliki satu kesamaan: seorang reviewer yang ditunjuk yang memiliki spot-check 15 menit sebelum setiap brief didistribusikan. Bukan AI yang membuat brief riset dapat dipercaya. Ini adalah nama reviewer pada dokumen. Tim yang melewati langkah ini demi kecepatan akhirnya mengedarkan brief dengan statistik yang difabrikasi ke board, klien, atau investor. Begitu itu terjadi, kepercayaan pada seluruh program runtuh, bukan hanya pada brief tertentu. Pekerjaan reviewer bukan untuk mengulangi riset. Ini adalah memverifikasi 3-5 kutipan dan menandai klaim apa pun yang terasa terlalu percaya diri mengingat dasar buktinya. Itu membutuhkan 15-30 menit untuk brief 10 halaman. Ini mengubah output yang berpotensi berbahaya menjadi deliverable yang dapat dipercaya. Tidak ada kontrol tata kelola lain yang memberikan lebih banyak ROI dengan biaya lebih rendah.
Pertanyaan yang Sering Diajukan
Apa itu Generative Research AI pattern?
Generative Research adalah AI pattern yang menyintesis beberapa sumber menjadi output riset yang koheren. Formulanya adalah: Ingest (korpus multi-sumber), Analyze (sintesis lintas-sumber yang mengidentifikasi sinyal konsensus, konflik, dan inferensi), Generate (laporan terstruktur, brief, atau analisis). Ini berbeda dari RAG Assistant karena menggambar dari sumber eksternal, langsung, atau lintas domain daripada knowledge base internal yang terkontrol, dan menghasilkan inferensi baru dari kombinasi sumber.
Apa itu The Multi-Source Synthesis Pattern?
The Multi-Source Synthesis Pattern adalah kemampuan yang mendefinisikan Generative Research: membaca beberapa sumber secara bersamaan untuk menemukan apa yang mereka sepakati secara kolektif, menampilkan di mana mereka bertentangan, dan menyimpulkan apa yang diimplikasikan oleh bukti gabungan di luar apa yang dinyatakan oleh sumber tunggal mana pun. Deployment yang merangkum setiap sumber secara independen tidak menggunakan pattern ini. Lapisan sintesis adalah yang memampatkan 30 sumber menjadi brief yang koheren dan membedakan Generative Research dari kumpulan ringkasan dokumen yang disambung bersama.
Bagaimana Generative Research berbeda dari RAG Assistant?
RAG Assistant mengambil jawaban dari knowledge base internal yang terkontrol yang Anda miliki. Generative Research menyintesis dari sumber eksternal, langsung, atau lintas domain pada waktu query. Trust model-nya berbeda: output RAG dapat diverifikasi dengan memeriksa sumber internal yang dikutip. Output Generative Research memerlukan verifikasi bahwa sumber eksternal yang dikutip benar-benar mendukung klaim yang dikaitkan dan bahwa inferensi yang disintesis bertahan di bawah pengawasan. Tinjauan manusia 15 menit sebelum distribusi adalah persyaratan tata kelola untuk Generative Research yang kurang kritis untuk RAG.
Apa itu citation laundering dalam riset AI?
Citation laundering terjadi ketika model AI mengutip sumber nyata yang kredibel untuk klaim yang sebenarnya tidak dibuat sumber tersebut. Evaluasi Stanford HAI 2024 menemukan 23% kutipan yang dihasilkan AI dalam tugas sintesis panjang baik mengutip sumber yang tidak berisi klaim yang dikaitkan atau salah mewakili posisi sumber tersebut. Ini menghasilkan output yang terlihat otoritatif dan lolos tinjauan biasa tetapi gagal di bawah pengawasan. Mitigasinya adalah spot-checking 3-5 kutipan per brief sebelum distribusi.
ROI apa yang harus Anda harapkan dari Generative Research?
Jam analis per brief kompetitif turun dari 4-8 jam menjadi 30-60 menit (pengurangan waktu 85-90%). Cakupan sumber per brief meningkat dari 5-10 sumber menjadi 20-50 sumber (peningkatan 3-5x). Tingkat penyelesaian riset pra-panggilan untuk sales rep meningkat dari 40-60% menjadi 85-95%. Kadence briefing meningkat 4-6x (brief mingguan menjadi layak di mana bulanan adalah batas sebelumnya). Tingkat penyelesaian riset pra-panggilan adalah metrik yang paling dapat dilacak dan terhubung langsung ke hasil Pipeline.
Apa failure mode Generative Research yang paling umum?
Enam failure mode utama adalah confabulation (klaim yang terdengar masuk akal tidak didukung oleh sumber mana pun), citation laundering (sumber nyata dikutip untuk klaim yang tidak dibuat sumber tersebut), keterlambatan mata uang sumber (indeks beberapa hari di belakang), sumber yang bertentangan disajikan sebagai konsensus terpadu, scope drift (prompt yang terlalu luas menghasilkan output yang tidak dapat digunakan), dan bias sumber tunggal (satu sumber dominan menguasai sintesis). Citation laundering adalah yang paling berbahaya karena terlihat otoritatif. Confabulation adalah yang paling merusak kepercayaan ketika ditemukan.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Formulanya: Ingest, Analyze, Generate
- The Multi-Source Synthesis Pattern
- Generative Research vs. RAG Assistant: perbedaan kritis
- Lima contoh nyata secara mendalam
- 1. Pelaporan competitive intelligence
- 2. Brief riset akun sebelum panggilan penjualan
- 3. Sintesis tren industri eksekutif
- 4. Ukuran pasar dengan sumber yang dikutip
- 5. Riset meja uji tuntas M&A
- Failure modes: apa yang merusak Generative Research
- Trust model: verifikasi tidak opsional
- Kapan Generative Research bekerja (dan kapan tidak)
- ROI signals: mengukur dampak
- Pelajari lebih lanjut