Generative Research: Nén Hàng Giờ Đọc Tài Liệu
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Một analyst giỏi tổng hợp được 30 nguồn thành brief mạch lạc. Họ biết nguồn nào đáng tin, nguồn nào cần xem nhẹ, cách bộc lộ mâu thuẫn khi hai nguồn tin cậy bất đồng nhau, và cách trình bày đầu ra để VP đọc được trong 8 phút trước board meeting.
Vấn đề là hầu hết các team không đủ người làm việc này tốt, đều đặn, trên toàn bộ danh sách thị trường, tài khoản và đối thủ. Account research trước cuộc gọi sales bị bỏ qua. Báo cáo competitive intelligence cũ 3 tuần khi đến tay người dùng. Due diligence cho mục tiêu M&A tiềm năng còn sơ sài vì không ai có thời gian đi sâu hơn.
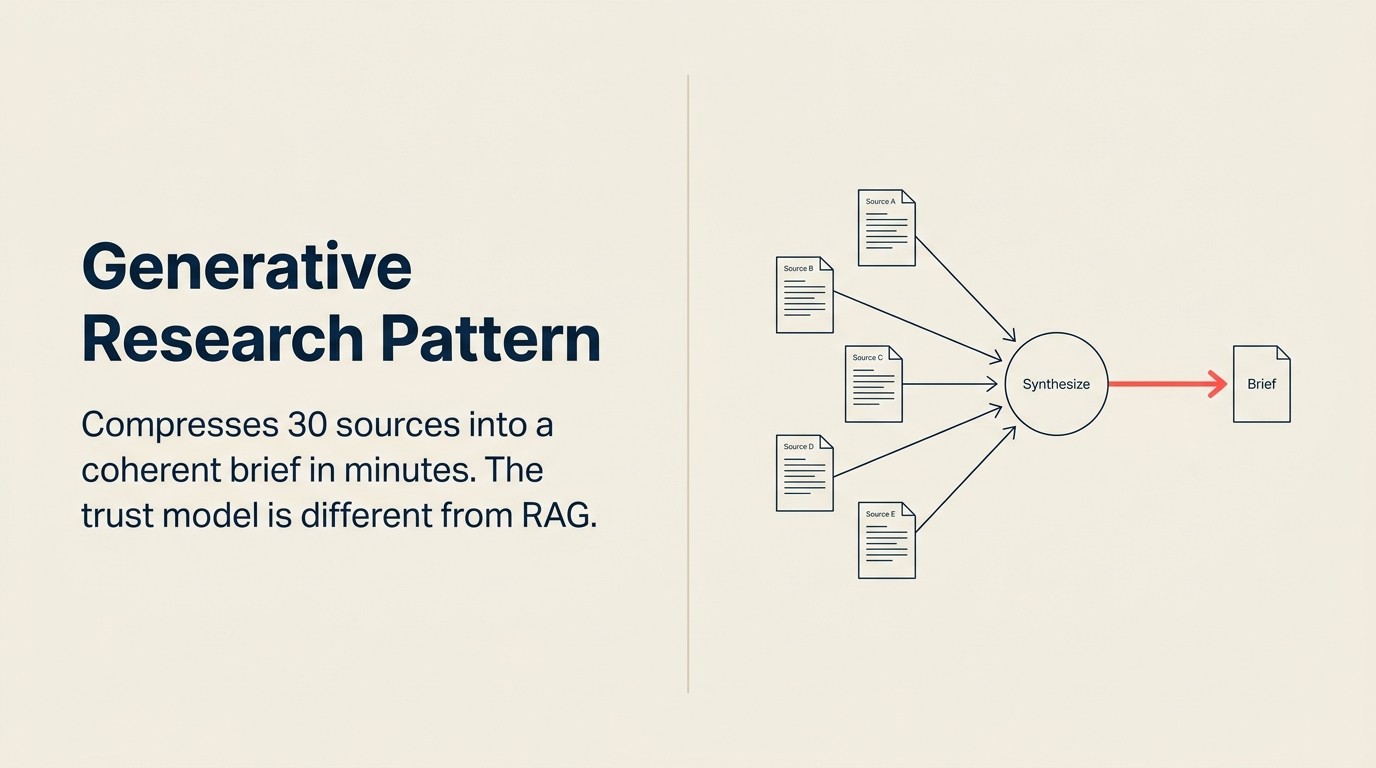
Generative Research là AI pattern nén công việc tổng hợp đó xuống còn vài phút. Không phải bằng cách loại bỏ phân tích. Bằng cách tự động hóa phần đọc, cross-reference và structuring ban đầu, những việc chiếm phần lớn thời gian của một analyst. Phán xét của analyst vẫn quan trọng ở cuối. Nhưng họ bắt đầu từ brief 10 trang thay vì 30 tab trình duyệt.
Pattern này kèm theo câu hỏi tin cậy mà pattern anh em của nó, RAG Assistant, không có. RAG retrieves từ knowledge base đã biết, được kiểm soát. Generative Research quét qua các nguồn live, bên ngoài hoặc cross-domain. Sự khác biệt đó thay đổi cả cách xác minh lẫn nơi failure mode tập trung.
Công thức: Ingest, Analyze, Generate

Ingest (multi-source corpus) lấy nguyên liệu thô. Các nguồn phụ thuộc vào use case. Với competitive intelligence: press release, đánh giá G2 và Capterra, tin tuyển dụng LinkedIn, recording hội nghị, transcript earnings call, bài báo thương mại. Với account research: tin tức gần đây của công ty mục tiêu, profile LinkedIn của lãnh đạo, báo cáo phân tích ngành, thông báo gọi vốn gần đây, các đề cập đến đối thủ. Với executive trend synthesis: transcript earnings call từ 10-20 công ty đại chúng trong lĩnh vực, trích đoạn Gartner hoặc Forrester, bài báo cấp board. Lớp Ingest làm việc thu thập và chuẩn hóa ban đầu: chuyển PDF, web page, transcript và dữ liệu có cấu trúc thành các đoạn văn bản có thể đọc.
Analyze (tổng hợp) là bước đòi hỏi nhất trong pattern này. Model không đơn giản tóm tắt từng nguồn riêng lẻ. Nó đọc qua tất cả các nguồn cùng lúc, xác định những điểm nhiều nguồn đồng thuận (tín hiệu độ tin cậy cao), bộc lộ chỗ các nguồn mâu thuẫn nhau (vùng không chắc chắn), trích xuất tên entity và sự kiện chính, rồi xây dựng cách diễn giải mạch lạc về những gì bằng chứng tổng thể nói lên. Khả năng cross-source synthesis này là điểm Generative Research khác với document summarization thông thường. Tóm tắt từng nguồn riêng rẽ không phải là pattern này. Giá trị nằm ở lớp tổng hợp. Xem Analyze: cách AI hiểu những gì bạn đã thu thập để có định nghĩa capability đầy đủ.
Generate (báo cáo, brief hoặc structured output) tạo ra deliverable. Có thể là competitive analysis được format theo từng phần với citation, account research card để insert vào CRM, executive memo với bullet point và hành động được đề xuất, hoặc bảng market sizing với chú thích nguồn. Bước Generate format insight tổng hợp thành định dạng đầu ra mà người yêu cầu cần.
Lưu ý: pattern này kết thúc ở Generate. Không có bước Execute trong công thức cơ bản. Đầu ra là bản nháp để con người xem xét trước khi đi đâu đó. Với hầu hết các Generative Research use case, việc xem xét đó không phải tùy chọn. Đó là cơ chế governance làm cho pattern an toàn để phân phối.
Số liệu thực tế: tác động của Generative Research
- McKinsey ước tính generative AI có thể tự động hóa 60-70% thời gian nhân viên dành cho các hoạt động knowledge work, với research synthesis được ghi nhận là một trong những hoạt động có giá trị cao nhất mà AI có thể nén lại (McKinsey, 2023)
- Sales rep hoàn thành pre-call research trên 40-60% cuộc gọi khi không có AI; với AI-generated account brief, tỷ lệ hoàn thành pre-call research tăng lên 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- Competitive intelligence brief có AI tổng hợp 20-50 nguồn trong 2-4 giờ, so với 6-8 giờ mỗi analyst cho mỗi đối thủ khi làm thủ công, cải thiện phạm vi nguồn 3-5 lần với giảm 85-90% thời gian (Gartner Competitive Intelligence Report, 2025)
Multi-Source Synthesis Pattern
Giá trị cốt lõi của Generative Research không phải là tóm tắt từng nguồn riêng lẻ. Đó là cross-source synthesis: tìm những điểm nhiều nguồn đồng thuận (tín hiệu tin cậy cao), bộc lộ chỗ các nguồn mâu thuẫn nhau (vùng không chắc chắn), và suy luận về ý nghĩa của bằng chứng tổng hợp ngoài những gì bất kỳ nguồn đơn lẻ nào nêu rõ. Một triển khai Generative Research tóm tắt từng nguồn riêng rẽ rồi đặt các bản tóm tắt cạnh nhau không phải đang dùng pattern này. Pattern đòi hỏi bước Analyze đọc tất cả các nguồn cùng lúc và tạo ra cách diễn giải thống nhất. Lớp tổng hợp đó là thứ nén 30 nguồn thành brief mạch lạc, và là thứ phân biệt Generative Research với một tập tóm tắt tài liệu được ghép lại với nhau.
Generative Research so với RAG Assistant: sự khác biệt quan trọng
Hai pattern này bị nhầm lẫn nhiều nhất trong thực tế.
RAG Assistant retrieves câu trả lời từ internal knowledge base được kiểm soát, đã biết. Bạn biết knowledge base có gì (tài liệu sản phẩm, support ticket cũ, HR policy). Retrieval có giới hạn. Câu trả lời trích dẫn nguồn tồn tại trong hệ thống của bạn. Failure mode là retrieve sai tài liệu hoặc knowledge base đã cũ, không phải confabulation từ web mở.
Generative Research tổng hợp từ corpus thường là bên ngoài, live hoặc cross-domain. Các nguồn không được index trước trong hệ thống của bạn. Chúng được lấy vào thời điểm query từ web search, API feed, tài liệu được upload hoặc database bên thứ ba. Quá trình tổng hợp có thể bộc lộ thông tin mà không có nguồn đơn lẻ nào nêu rõ, model suy luận từ sự kết hợp. Khả năng suy luận đó vừa là giá trị vừa là rủi ro.
Hàm ý thực tế: đầu ra RAG có thể xác minh bằng cách kiểm tra nguồn được trích dẫn. Đầu ra Generative Research đòi hỏi spot-check cả nguồn được trích dẫn (nguồn có thực sự nói điều được gán cho nó không?) lẫn logic tổng hợp (inference có đứng vững không?). Quy trình xác minh khác nhau, yêu cầu governance khác nhau.
Năm ví dụ thực tế chuyên sâu

1. Báo cáo competitive intelligence
VP Product cần cập nhật cạnh tranh hàng quý về ba đối thủ trực tiếp. Mỗi đối thủ có website, profile G2, LinkedIn hoạt động, press release gần đây và một số đề cập đánh giá trên Reddit và Capterra. Đọc và tổng hợp thủ công tất cả những thứ đó mất analyst sản phẩm 6-8 giờ mỗi đối thủ.
Ingest lấy từ tất cả các nguồn này: web page được scrape tại thời điểm lấy, đánh giá G2 được lọc theo ngày, bài đăng và tin tuyển dụng LinkedIn, press release và đề cập tin tức. Analyze cross-reference các nguồn: tính năng nào reviewer nhắc đến liên tục trong đánh giá G2 nhưng không có trên website chính thức của công ty? Tin tuyển dụng "Head of Enterprise Sales" báo hiệu gì về định hướng chiến lược của họ? Hai nguồn bất đồng ở đâu, một đánh giá khen UX xuất sắc, một đánh giá khác gắn cờ nó là điểm yếu?
Generate tạo ra structured brief: cập nhật sản phẩm trong quý, thay đổi positioning, tín hiệu về giá từ đánh giá, talent signal từ tin tuyển dụng và các trích dẫn chính từ nguồn bên thứ ba. Đầu ra được format thành one-page summary với expandable section cho từng loại nguồn.
Kiểm tra của con người: các trích dẫn được ghi nhận có thực sự đến từ nguồn đó không? Các kết luận chiến lược suy luận ra có đứng vững khi xem xét kỹ không?
Các tool hỗ trợ việc này: Perplexity API, Tavily cho web search grounding, Claude và GPT-4 với search tool, và các competitive intelligence platform chuyên dụng như Crayon, Klue và Battlecards.
2. Account research brief trước cuộc gọi sales
Sales director có cuộc gọi trong 90 phút với VP Operations tại một công ty sản xuất mà cô chưa từng nói chuyện. Cô cần biết: điều gì đang xảy ra tại công ty này, thách thức gần đây của họ là gì, các stakeholder là ai và bối cảnh ngành là gì.
Ingest lấy: press release và tin tức gần đây của công ty (90 ngày qua), profile LinkedIn và hoạt động gần đây của prospect, nhận xét công khai gần đây của CEO và CFO, tin tức ngành từ các báo thương mại sản xuất, và bất kỳ CRM data cũ nào cùng các email thread cũ.
Analyze bộc lộ: một vụ mua lại gần đây đã thay đổi ưu tiên supply chain của họ, một bài đăng LinkedIn từ prospect đề cập sự phức tạp vận hành như một thách thức, một câu trích dẫn từ earnings call của CEO về "operational efficiency" như ưu tiên năm 2026, và một pattern trong các tuyển dụng gần đây cho thấy họ đang xây dựng data team.
Generate tạo ra brief 2 trang trước cuộc gọi: bối cảnh chính của công ty (2 bullet), phát triển gần đây (3 bullet), thông tin về contact (2 bullet), likely priority dựa trên bằng chứng (3 bullet có nguồn) và câu hỏi mở đầu được đề xuất gắn với intelligence. Rep xem xét trong 8 phút, điều chỉnh câu hỏi mở đầu dựa trên kiến thức riêng của mình và dùng brief như context thay vì như script.
Pattern này được tích hợp vào "account summaries" của Salesforce Einstein, tính năng AI research của HubSpot, và là cốt lõi của các tool chuyên dụng như AI research của Apollo.io và Warmly. Phiên bản đầy đủ dành riêng cho sales của use case này: xem AI account research trước khi tiếp xúc đầu tiên.
3. Executive industry-trend synthesis
CFO tại một công ty healthcare technology muốn brief 20 phút trước board meeting về "AI đang ảnh hưởng đến healthcare revenue cycle ở đâu." Tổng hợp đó thường đòi hỏi đọc 6-8 báo cáo phân tích, 3 transcript earnings call từ các công ty đại chúng liên quan và hàng chục bài báo thương mại.
Ingest lấy từ trích đoạn Gartner (nếu có), coverage hội nghị HIMSS, transcript earnings call từ các health IT company (Veeva, Epic partner, Waystar), báo chí thương mại từ Healthcare IT News và Health Data Management, và thông báo đầu tư VC trong lĩnh vực này.
Analyze xác định các chủ đề đồng thuận (tự động hóa claims adjudication được đề cập nhất quán trong 7 trên 10 nguồn), các cuộc tranh luận đang nổi lên (vendor AI nào đang thực sự deliver so với chỉ hứa hẹn), và các công ty chính được trích dẫn. Nó cũng kiểm tra tín hiệu mâu thuẫn, một nguồn dự báo giảm 30% chi phí quản trị, một báo cáo phân tích khác gọi điều đó là "quá lạc quan."
Generate tạo ra brief 2 trang: ba xu hướng đồng thuận kèm bằng chứng, hai vùng bất đồng tích cực được gắn cờ rõ ràng, năm công ty đáng theo dõi, và phần "câu hỏi bạn có thể phải đối mặt" kèm câu trả lời được đề xuất. CFO có thể trình bày đây như bình luận có thông tin, không phải như văn bản do AI tạo.
4. Market sizing có trích dẫn nguồn
Head of Business Development của một startup cần phân tích market sizing sơ bộ cho một phân khúc mới trước fundraise meeting. Phân tích TAM/SAM/SOM cần có thể bảo vệ được, không phải con số ma thuật mà là ước tính có thể truy nguyên với nguồn VC có thể kiểm tra.
Ingest lấy: báo cáo phân tích ngành, cơ sở dữ liệu thống kê chính phủ (BLS, Census), earnings call của công ty đại chúng đề cập đến phân khúc này, và các vòng gọi vốn startup gần đây trong lĩnh vực kèm các giả định về market size ngụ ý của chúng.
Analyze cross-reference các ước tính quy mô từ nhiều nguồn: một analyst nói TAM 12 tỷ đô la, S-1 của đối thủ ngụ ý 9 tỷ, báo cáo Gartner 2024 nói 8 tỷ tăng trưởng 14%. Nó xác định sự khác biệt về phương pháp, một nguồn chỉ tính phần mềm, nguồn khác bao gồm cả dịch vụ. Nó bộc lộ phạm vi ước tính có thể bảo vệ được và các giả định định hướng từng con số.
Generate tạo ra market sizing memo: phần phương pháp, ba kịch bản (thận trọng/cơ bản/lạc quan), citation nguồn cho mỗi con số, và một đoạn "cách bảo vệ điều này" cho fundraise meeting.
5. M&A desk research
Strategy team của bên mua lại cần quan điểm sơ bộ về một công ty mục tiêu trước khi tham gia chính thức. Họ muốn public-source intelligence, trước khi ký NDA. Đây là desk research, không phải full diligence, nhưng cần kỹ lưỡng.
Ingest lấy: website và tài liệu sản phẩm của mục tiêu, tất cả press coverage công khai, dữ liệu LinkedIn về số nhân viên và quỹ đạo tăng trưởng (proxy cho hiệu suất tài chính), đánh giá Glassdoor cho culture signal, Crunchbase cho lịch sử gọi vốn và tên nhà đầu tư, G2 cho sentiment khách hàng, và patent filing nếu liên quan.
Analyze tổng hợp: ước tính doanh thu từ tín hiệu gọi vốn và tăng trưởng, team quality và churn signal từ LinkedIn và Glassdoor, đánh giá product differentiation từ tài liệu công khai và review, competitive positioning trong bối cảnh các vụ mua lại khác trong lĩnh vực.
Generate tạo ra due diligence memo theo format mà strategy team sử dụng: business overview, financial estimate kèm mức độ tin cậy, team assessment, product assessment, risk flag, và câu hỏi mở cho quy trình diligence chính thức.
Failure mode: những gì phá vỡ Generative Research
| Failure mode | Nguyên nhân gốc rễ | Biện pháp giảm thiểu |
|---|---|---|
| Confabulation | Model lấp khoảng trống giữa các nguồn thực bằng tuyên bố nghe hợp lý nhưng không nguồn nào thực sự hỗ trợ | Yêu cầu citation cho mỗi tuyên bố. Spot-check 3-5 citation mỗi brief trước khi phân phối. Không bao giờ lưu hành mà không có người xem xét được đặt tên đã kiểm tra nguồn. |
| Source currency lag | Web search index chậm hơn 2-3 ngày; tổng hợp tài liệu nội bộ chỉ tươi bằng lần chạy index cuối cùng | Thêm crawl hoặc index timestamp vào đầu ra. Gắn cờ các tuyên bố nhạy cảm theo thời gian với ngày nguồn. Với competitive hoặc market intelligence live, xác minh trực tiếp các tuyên bố chính. |
| Conflicting sources presented as unified | Model chọn một cách diễn giải khi các nguồn bất đồng mà không gắn cờ sự bất đồng | Prompt rõ ràng yêu cầu bộc lộ mâu thuẫn: "Nếu các nguồn bất đồng về chủ đề này, gắn cờ sự bất đồng và cite cả hai phía." Xem bất kỳ brief nào trình bày mọi thứ như đồng thuận với sự nghi ngờ. |
| Citation laundering | Model cite nguồn thực, đáng tin cậy cho tuyên bố mà nguồn đó không thực sự đưa ra | Spot-check citation: không chỉ nguồn có tồn tại, mà đoạn được cite có hỗ trợ tuyên bố được gán cho nó không. Đây là failure mode nguy hiểm nhất vì trông rất có thẩm quyền. |
| Scope drift | Prompt mở tạo ra đầu ra 40 trang đầy đủ nhưng không thể dùng được | Xác định scope chính xác: khoảng thời gian, loại nguồn, format đầu ra và giới hạn từ. Prompt hẹp hơn cho đầu ra hữu ích hơn so với prompt rộng. |
| Single-source bias | Một nguồn chiếm ưu thế, chất lượng cao lấn át tổng hợp; đầu ra phản ánh một quan điểm thay vì góc nhìn đa nguồn | Kiểm tra phân phối nguồn trong đầu ra. Nếu 80% citation chỉ đến một nguồn, synthesis không đang làm việc của nó. |
Citation laundering là failure mode nguy hiểm nhất vì nó tạo ra đầu ra trông có thẩm quyền. Brief cite báo cáo Gartner thực cho tuyên bố mà báo cáo đó không thực sự đưa ra sẽ qua được review thông thường nhưng vỡ trận khi ai đó kiểm tra kỹ. Đánh giá năm 2024 của Stanford HAI về các LLM hàng đầu trên độ chính xác citation phát hiện 23% citation do AI tạo trong các tác vụ long-form synthesis cite nguồn không chứa tuyên bố được gán hoặc diễn đạt sai quan điểm của nguồn. Điều này không làm Generative Research không thể dùng được. Nó làm cho 15-minute human review không thể thương lượng.
Confabulation đáng được chú ý trực tiếp vì đây là failure mode gây hại tin cậy nhiều nhất. Brief Generative Research chứa một tuyên bố được cite tự tin mà nguồn được cite không thực sự đưa ra sẽ, khi bị phát hiện, phá hủy lòng tin vào toàn bộ brief và vào pattern rộng hơn. Nghiên cứu của OpenAI về GPT-4 thừa nhận điều này trực tiếp: ngay cả các model có khả năng cao cũng có thể tạo ra nội dung nghe hợp lý nhưng không chính xác, đó là lý do tại sao xác minh citation vẫn là trách nhiệm của con người bất kể chất lượng model. Biện pháp giảm thiểu không phải là tránh pattern. Đó là xây dựng xác minh vào workflow trước khi phân phối. Xem rủi ro hallucination theo AI pattern để thấy điều này so sánh thế nào với failure mode trong các Generate-heavy pattern khác.
Mô hình tin cậy: xác minh không phải tùy chọn

RAG Assistant hưởng lợi từ mô hình tin cậy tương đối được kiểm soát. Knowledge base là của bạn. Các nguồn đã biết. Nếu câu trả lời sai, nguồn sai, và bạn sửa nguồn được.
Generative Research lấy từ các nguồn bên ngoài, live và cross-domain. Quá trình tổng hợp có thể tạo ra inference mà không có nguồn đơn lẻ nào hỗ trợ rõ ràng. Đó là giá trị. Nhưng đó cũng là lý do tại sao mô hình tin cậy phải rõ ràng.
Trước khi bất kỳ đầu ra Generative Research nào được phân phối, một người xem xét được đặt tên nên:
- Đọc đầu ra như một tài liệu hoàn chỉnh, không chỉ phần tóm tắt
- Spot-check 3-5 citation, xác minh rằng nguồn tồn tại và tuyên bố được gán cho nó thực sự có trong nguồn
- Gắn cờ bất kỳ consensus claim nào có vẻ phóng đại so với cơ sở bằng chứng của nó
- Đánh dấu bất kỳ phần nào có nguồn mâu thuẫn (nếu AI chưa gắn cờ)
- Thêm tên của họ vào tài liệu như reviewing analyst
Việc xem xét này mất 15-30 phút cho brief được format tốt. Đây không phải công việc nghiên cứu 6-8 giờ ban đầu. Đó là lợi ích về năng suất. Nhưng 15-minute review không phải tùy chọn.
Lỗi phổ biến: các team triển khai Generative Research và dừng spot-check sau 6 tháng vì đầu ra "có vẻ ổn." Rồi một brief với số liệu thống kê được bịa đặt đến board presentation. Cách sửa là biến spot-check thành một bước workflow được ghi lại, không phải review tùy chọn.
Khi Generative Research hoạt động (và khi không)
Hoạt động tốt khi:
- Câu hỏi có scope được xác định. "Đối thủ X thông báo gì trong Q1 2026?" có scope. "Cho tôi biết tất cả về Đối thủ X" thì không.
- Các nguồn có sẵn và có thể truy cập. Với công ty đại chúng, market research và competitive intelligence, các nguồn công khai thường phong phú. Với công ty tư nhân hoặc thị trường mới nổi, chất lượng nguồn giảm.
- Đầu ra sẽ được xem xét trước khi phân phối. Đây không phải vấn đề tin cậy về công nghệ. Đây là yêu cầu workflow cho bất kỳ research output nào thông báo cho các quyết định.
- Nhu cầu là synthesis, không phải factual lookup cụ thể. Nếu bạn cần "ARR của Acme Corp là bao nhiêu?", đó là factual lookup trong đó một nguồn có thẩm quyền duy nhất tốt hơn synthesis. Nếu bạn cần "chúng ta có thể suy luận gì về quỹ đạo tăng trưởng của Acme Corp từ tín hiệu công khai?", đó là synthesis.
So với RAG Assistant: RAG là internal knowledge base của bạn trả lời các câu hỏi đã biết. Generative Research là synthesis từ các nguồn bên ngoài hoặc cross-domain tạo ra insight mới. Chúng thường được dùng cùng nhau: Generative Research để xây dựng intelligence brief từ nguồn bên ngoài, RAG Assistant để trả lời "chúng ta đã học được gì về tài khoản này?" từ các brief cũ và call note.
So với Document Review: Document Review lấy một tài liệu cụ thể và kiểm tra nó so với tiêu chuẩn hoặc template đã biết. Generative Research lấy nhiều tài liệu và tổng hợp đầu ra mới từ chúng. Sự phân biệt: một tài liệu so với nhiều nguồn; compliance check so với insight synthesis.
So với Meeting Intelligence: Meeting Intelligence xử lý recording cuộc trò chuyện của chính bạn. Generative Research lấy từ tài liệu bên ngoài. Chúng có thể kết hợp: Meeting Intelligence nắm bắt cuộc trò chuyện khách hàng của bạn, Generative Research tổng hợp bối cảnh thị trường bên ngoài, và một strategist kết hợp cả hai để có account view đầy đủ.
Tín hiệu ROI: đo lường tác động
| Chỉ số | Baseline thủ công | Với Generative Research | Cải thiện thông thường |
|---|---|---|---|
| Giờ analyst mỗi brief | 4-8 giờ cho brief cạnh tranh đầy đủ | 30-60 phút (AI + review) | Giảm 85-90% thời gian |
| Thời gian từ yêu cầu đến deliverable | 1-3 ngày (backlog + thời gian viết) | 2-4 giờ (same-day turnaround) | Giảm 80-90% cycle time |
| Phạm vi nguồn mỗi brief | 5-10 nguồn (giới hạn thực tế cho một analyst) | 20-50 nguồn (AI synthesis có giới hạn rộng hơn) | Cải thiện 3-5 lần |
| Tần suất brief | 1 brief toàn diện mỗi tháng mỗi chủ đề | Brief hàng tuần trở nên khả thi | Cải thiện nhịp độ 4-6 lần |
| Tỷ lệ hoàn thành pre-call research | 40-60% cuộc gọi sales có bất kỳ pre-call research nào | 85-95% với việc tạo account brief tự động | Cải thiện 40-50% |
Tỷ lệ hoàn thành pre-call research thường là chỉ số dễ theo dõi nhất và kết nối trực tiếp với kết quả pipeline. Khi rep vào cuộc gọi với brief, chất lượng cuộc gọi tăng. Nghiên cứu của McKinsey về AI trong B2B sales phát hiện account research và chuẩn bị trước cuộc gọi nằm trong số AI use case được sales leader hứng khởi nhất, chính xác vì lợi ích năng suất có thể đo lường và thấy ngay. Không phải vì brief hoàn hảo, mà vì có context thay đổi phần mở đầu từ "hãy cho tôi biết về công ty của bạn" thành "Tôi thấy bạn vừa mở văn phòng mới ở Austin. Điều đó có liên quan đến đợt mở rộng bạn đề cập trong earnings call của mình không?"
Phân tích Rework: Các triển khai Generative Research thành công có một điểm chung: một người xem xét được đặt tên sở hữu 15-minute spot-check trước mỗi brief được phân phối. Không phải AI làm cho research brief đáng tin cậy. Đó là tên của người xem xét trên tài liệu. Các team bỏ qua bước này để ưu tiên tốc độ rốt cuộc lưu hành brief có số liệu thống kê được bịa đặt đến board, khách hàng hoặc nhà đầu tư. Khi điều đó xảy ra, lòng tin vào toàn bộ chương trình sụp đổ, không chỉ vào brief cụ thể. Công việc của người xem xét không phải là lặp lại nghiên cứu. Đó là xác minh 3-5 citation và gắn cờ bất kỳ tuyên bố nào có vẻ quá tự tin so với cơ sở bằng chứng của nó. Điều đó mất 15-30 phút cho brief 10 trang. Nó chuyển đổi đầu ra có khả năng nguy hiểm thành deliverable đáng tin cậy. Không có governance control nào khác mang lại ROI nhiều hơn với chi phí thấp hơn.
Câu hỏi thường gặp
AI pattern Generative Research là gì?
Generative Research là AI pattern tổng hợp nhiều nguồn thành research output mạch lạc. Công thức: Ingest (multi-source corpus), Analyze (cross-source synthesis xác định consensus signal, mâu thuẫn và inference), Generate (báo cáo, brief hoặc phân tích có cấu trúc). Nó khác với RAG Assistant ở chỗ lấy từ các nguồn bên ngoài, live hoặc cross-domain thay vì internal knowledge base được kiểm soát, và tạo ra inference mới từ sự kết hợp của các nguồn.
Multi-Source Synthesis Pattern là gì?
Multi-Source Synthesis Pattern là khả năng xác định của Generative Research: đọc nhiều nguồn cùng lúc để tìm những điểm chúng đồng thuận, bộc lộ chỗ chúng mâu thuẫn nhau, và suy luận về ý nghĩa của bằng chứng tổng hợp ngoài những gì bất kỳ nguồn đơn lẻ nào nêu. Triển khai tóm tắt từng nguồn riêng rẽ không phải là pattern này. Lớp tổng hợp là thứ nén 30 nguồn thành brief mạch lạc và phân biệt Generative Research với một tập tóm tắt tài liệu được ghép lại.
Generative Research khác gì với RAG Assistant?
RAG Assistant retrieves câu trả lời từ internal knowledge base được kiểm soát mà bạn sở hữu. Generative Research tổng hợp từ các nguồn bên ngoài, live hoặc cross-domain tại thời điểm query. Mô hình tin cậy khác nhau: đầu ra RAG có thể xác minh bằng cách kiểm tra nguồn nội bộ được cite. Đầu ra Generative Research đòi hỏi xác minh cả rằng nguồn bên ngoài được cite thực sự hỗ trợ tuyên bố được gán cho nó lẫn inference tổng hợp có đứng vững không. 15-minute human review trước khi phân phối là yêu cầu governance cho Generative Research, ít quan trọng hơn với RAG.
Citation laundering trong AI research là gì?
Citation laundering xảy ra khi AI model cite nguồn thực, đáng tin cậy cho tuyên bố mà nguồn đó không thực sự đưa ra. Đánh giá năm 2024 của Stanford HAI phát hiện 23% citation do AI tạo trong các tác vụ long-form synthesis cite nguồn không chứa tuyên bố được gán hoặc diễn đạt sai quan điểm của nguồn. Điều này tạo ra đầu ra trông có thẩm quyền và qua được review thông thường nhưng thất bại khi xem xét kỹ. Biện pháp giảm thiểu là spot-check 3-5 citation mỗi brief trước khi phân phối.
Bạn nên kỳ vọng ROI nào từ Generative Research?
Giờ analyst mỗi competitive brief giảm từ 4-8 giờ xuống còn 30-60 phút (giảm 85-90% thời gian). Phạm vi nguồn mỗi brief cải thiện từ 5-10 nguồn lên 20-50 nguồn (cải thiện 3-5 lần). Tỷ lệ hoàn thành pre-call research của sales rep tăng từ 40-60% lên 85-95%. Nhịp độ briefing cải thiện 4-6 lần, brief hàng tuần trở nên khả thi ở nơi hàng tháng là giới hạn trước đây. Tỷ lệ hoàn thành pre-call research là chỉ số dễ theo dõi nhất và kết nối trực tiếp với kết quả pipeline.
Failure mode phổ biến nhất của Generative Research là gì?
Sáu failure mode chính: confabulation (tuyên bố nghe hợp lý không được bất kỳ nguồn nào hỗ trợ), citation laundering (nguồn thực được cite cho tuyên bố nguồn đó không đưa ra), source currency lag (index chậm vài ngày), conflicting sources được trình bày như unified consensus, scope drift (prompt quá rộng tạo ra đầu ra không thể dùng), và single-source bias (một nguồn chiếm ưu thế lấn át synthesis). Citation laundering nguy hiểm nhất vì trông rất có thẩm quyền. Confabulation gây hại tin cậy nhiều nhất khi bị phát hiện.
Tìm hiểu thêm

Co-Founder, Rework.com
On this page
- Công thức: Ingest, Analyze, Generate
- Multi-Source Synthesis Pattern
- Generative Research so với RAG Assistant: sự khác biệt quan trọng
- Năm ví dụ thực tế chuyên sâu
- 1. Báo cáo competitive intelligence
- 2. Account research brief trước cuộc gọi sales
- 3. Executive industry-trend synthesis
- 4. Market sizing có trích dẫn nguồn
- 5. M&A desk research
- Failure mode: những gì phá vỡ Generative Research
- Mô hình tin cậy: xác minh không phải tùy chọn
- Khi Generative Research hoạt động (và khi không)
- Tín hiệu ROI: đo lường tác động
- Tìm hiểu thêm