Generative Research: Comprimindo Horas de Leitura
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Um bom analista consegue sintetizar 30 fontes em um resumo coerente. Sabe quais fontes confiar, quais ponderar menos, como trazer à tona a tensão quando duas fontes credíveis discordam, e como tornar a saída legível para um VP que tem oito minutos antes de uma reunião de conselho.
A maioria das equipes não pode se dar ao luxo de ter analistas suficientes para fazer isso bem, de forma consistente, em cada mercado, conta e concorrente que importa. A pesquisa de conta antes de uma chamada de vendas é pulada. O relatório de inteligência competitiva está desatualizado há três semanas quando é usado. A due diligence em um possível alvo de aquisição é superficial porque ninguém teve tempo para ir mais fundo.
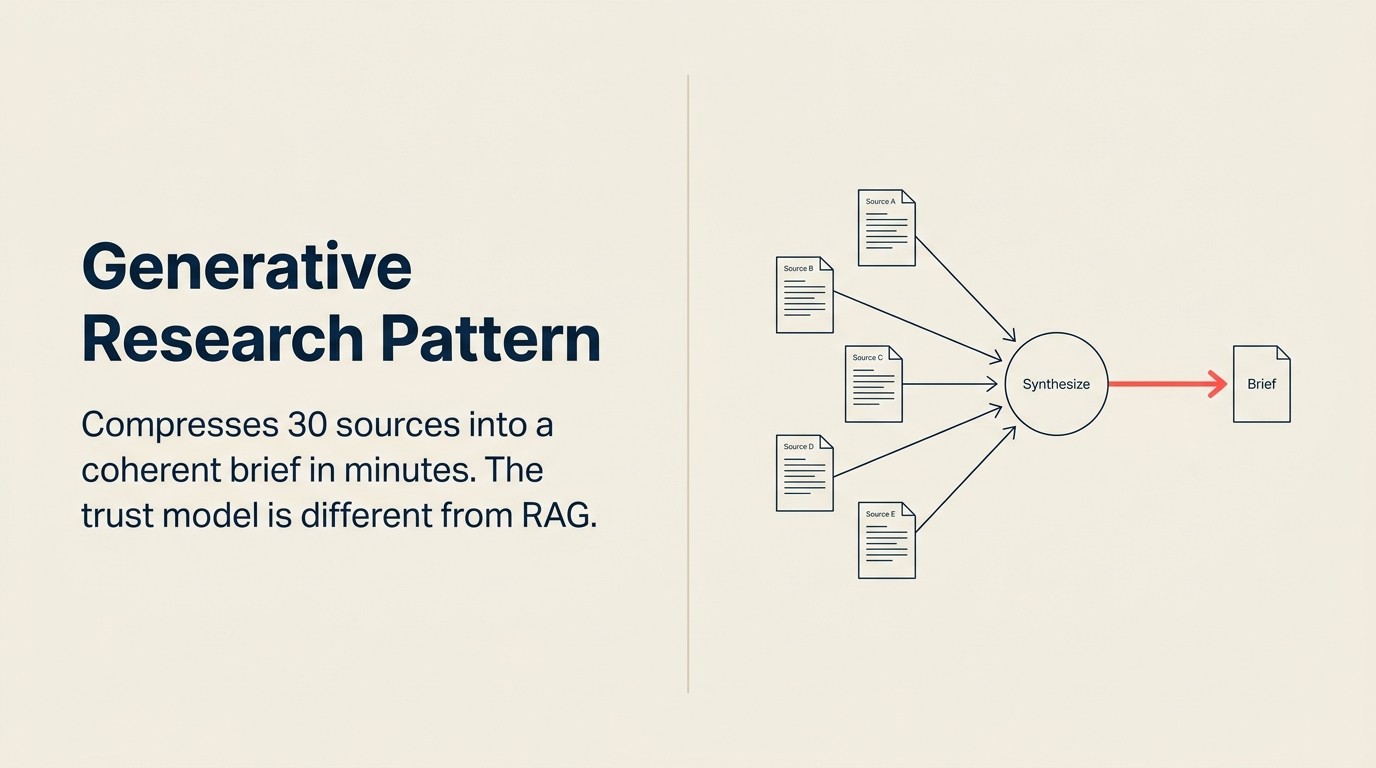
O Generative Research é o padrão de AI que comprime esse trabalho de síntese para minutos. Não eliminando a análise, mas automatizando a leitura, o cruzamento de referências e a estruturação inicial que consome a maior parte do tempo de um analista. O julgamento do analista ainda importa ao final. Mas o analista começa de um resumo de 10 páginas em vez de 30 abas do navegador.
O padrão traz uma questão de confiança que seu padrão irmão, o RAG Assistant, não tem. RAG recupera de uma base de conhecimento conhecida e controlada. O Generative Research varre fontes ao vivo, externas ou de domínios cruzados. Essa diferença muda como se parece a verificação e onde se concentram os modos de falha.
A fórmula: Ingest, Analyze, Generate
Ingest (corpus de múltiplas fontes) puxa o material de origem bruto. As fontes dependem do caso de uso. Para inteligência competitiva: comunicados de imprensa, avaliações no G2 e Capterra, postagens de emprego no LinkedIn, gravações de conferências, transcrições de chamadas de resultados, artigos da imprensa especializada. Para pesquisa de conta: notícias recentes da empresa-alvo, perfis do LinkedIn de lideranças, relatórios de analistas do setor, anúncios de financiamentos recentes, menções de concorrentes. Para síntese de tendências executivas: transcrições de chamadas de resultados de 10-20 empresas públicas no setor, trechos do Gartner ou Forrester, artigos de notícias de nível de conselho. A camada Ingest faz a coleta e a normalização inicial: convertendo PDFs, páginas web, transcrições e dados estruturados em blocos de texto legíveis.
Analyze (sintetizar) é a etapa mais exigente neste padrão. O modelo não apenas resume cada fonte de forma independente. Ele lê todas as fontes simultaneamente, identifica o que múltiplas fontes concordam (sinais de alta confiança), traz à tona onde as fontes conflitam (áreas de incerteza), extrai entidades nomeadas e fatos-chave, e constrói uma interpretação coerente do que as evidências coletivamente indicam. Essa síntese cruzada de fontes é onde o Generative Research se diferencia de uma simples sumarização de documentos. Resumir cada fonte separadamente não é o padrão. O valor está na camada de síntese. Veja Analyze: como a AI faz sentido do que você coletou para a definição completa da capacidade.
Generate (relatório, resumo ou saída estruturada) produz o entregável. Pode ser uma análise competitiva formatada como um resumo seção por seção com citações, um cartão de pesquisa de conta formatado para inserção no CRM, um memo executivo com pontos de bala e uma ação recomendada, ou uma tabela de dimensionamento de mercado com notas de rodapé de fontes. A etapa Generate formata o insight sintetizado no formato de saída que o solicitante precisa.
Observe que este padrão termina no Generate. Não há etapa Execute na fórmula base. A saída é um rascunho para um humano revisar antes de ir a qualquer lugar. Para a maioria dos casos de uso de Generative Research, essa revisão humana não é opcional. É o mecanismo de governança que torna o padrão seguro para distribuir.
Key Facts: Impacto do Generative Research
- A McKinsey estima que a AI generativa pode automatizar 60-70% do tempo dos funcionários atualmente gasto em atividades de trabalho do conhecimento, com a síntese de pesquisa citada como uma das atividades de trabalho do conhecimento de maior valor que pode comprimiar (McKinsey, 2023)
- Representantes de vendas completam a pesquisa pré-chamada em 40-60% das chamadas sem assistência de AI; com resumos de conta gerados por AI, as taxas de conclusão de pesquisa pré-chamada sobem para 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- Resumos de inteligência competitiva com AI sintetizam 20-50 fontes em 2-4 horas versus 6-8 horas por analista por concorrente com pesquisa manual, uma melhoria de cobertura de fontes de 3-5x com redução de 85-90% no tempo (Gartner Competitive Intelligence Report, 2025)
O Padrão de Síntese Multi-Fonte
O valor central do Generative Research não é a sumarização de fontes individuais. É a síntese cruzada de fontes: encontrar o que múltiplas fontes concordam (sinais de alta confiança), trazer à tona onde as fontes conflitam (áreas de incerteza), e inferir o que as evidências combinadas implicam além do que qualquer fonte individual declara explicitamente. Uma implantação de Generative Research que resume cada fonte de forma independente e apresenta os resumos lado a lado não está usando este padrão. O padrão requer uma etapa Analyze que leia todas as fontes simultaneamente e produza uma interpretação unificada. Essa camada de síntese é o que comprime 30 fontes em um resumo coerente, e é o que separa o Generative Research de um lote de sumarizações costuradas juntas.
Generative Research vs. RAG Assistant: a distinção crítica
Esses dois padrões são os mais frequentemente confundidos na prática.
RAG Assistant recupera respostas de uma base de conhecimento interna controlada e conhecida. Você sabe o que está na base de conhecimento (seus documentos de produto, tickets de suporte anteriores, políticas de RH). A recuperação é delimitada. As respostas citam fontes que existem no seu sistema. O modo de falha é recuperar o documento errado ou a base de conhecimento estar desatualizada. Não fabricação da web aberta.
Generative Research sintetiza de um corpus que é muitas vezes externo, ao vivo ou de domínios cruzados. As fontes não estão pré-indexadas no seu sistema. Elas são puxadas no momento da consulta de buscas web, feeds de API, documentos carregados ou bancos de dados de terceiros. A síntese pode trazer à tona informações que nenhuma fonte individual declara explicitamente: o modelo infere da combinação. Essa capacidade de inferência é tanto o valor quanto o risco.
A implicação prática: as saídas do RAG podem ser verificadas verificando a fonte citada. As saídas do Generative Research requerem verificação pontual tanto da fonte citada (a fonte realmente diz o que é atribuído a ela?) quanto da lógica de síntese (a inferência se sustenta?). Processo de verificação diferente, requisito de governança diferente.
Cinco exemplos reais em profundidade
1. Relatório de inteligência competitiva
Um VP de Produto precisa de uma atualização competitiva trimestral sobre três concorrentes diretos. Cada concorrente tem um site, um perfil no G2, um LinkedIn ativo, comunicados de imprensa recentes e algumas menções de avaliação no Reddit e Capterra. Ler e sintetizar tudo isso manualmente leva a um analista de produto 6-8 horas por concorrente.
O Ingest puxa de todas essas fontes: páginas web coletadas no momento da solicitação, avaliações do G2 filtradas por data, posts e vagas de emprego do LinkedIn, comunicados de imprensa e menções de notícias. O Analyze cruza as fontes: quais funcionalidades os revisores mencionam consistentemente nas avaliações do G2 que não estão no próprio site da empresa? O que a vaga de emprego para "Head of Enterprise Sales" sinaliza sobre sua direção estratégica? Onde dois fontes discordam (uma avaliação chama a UX de excelente; outra a sinaliza como uma fraqueza)?
O Generate produz um resumo estruturado: atualizações de produto no trimestre, mudanças de posicionamento, sinais de preço de avaliações, sinais de talentos de vagas de emprego e citações-chave de fontes de terceiros. A saída é formatada como um resumo de uma página com seções expansíveis para cada categoria de fonte.
A revisão humana verifica: as citações realmente vêm das fontes citadas? As conclusões estratégicas inferidas se sustentam sob escrutínio?
Ferramentas que suportam isso: Perplexity API, Tavily para fundamentação de busca web, Claude e GPT-4 com ferramentas de busca, e plataformas de inteligência competitiva com propósito específico como Crayon, Klue e Battlecards.
2. Resumo de pesquisa de conta antes de uma chamada de vendas
Uma diretora de vendas tem uma chamada em 90 minutos com um VP de Operações em uma empresa de manufatura com quem ela nunca falou antes. Ela precisa saber: o que está acontecendo nesta empresa, quais são seus desafios recentes, quem são as partes interessadas e qual é o contexto do setor.
O Ingest puxa: os comunicados de imprensa recentes e cobertura de notícias da empresa (últimos 90 dias), o perfil do LinkedIn do prospect e atividade recente, os comentários públicos recentes do CEO e CFO, notícias do setor de publicações especializadas em manufatura e quaisquer dados existentes no CRM e threads de e-mail anteriores.
O Analyze traz à tona: uma aquisição recente que mudou suas prioridades de cadeia de suprimentos, um post do LinkedIn do prospect mencionando complexidade operacional como um desafio, uma citação de chamada de resultados do CEO sobre "eficiência operacional" como uma prioridade para 2026, e um padrão em contratações recentes sugerindo que estão construindo uma equipe de dados.
O Generate produz um resumo pré-chamada de duas páginas: contexto principal da empresa (2 pontos), desenvolvimentos recentes (3 pontos), histórico do contato (2 pontos), prioridades prováveis baseadas em evidências (3 pontos com fontes) e perguntas de abertura sugeridas vinculadas à inteligência. O representante revisa em 8 minutos, ajusta a pergunta de abertura com base em seu próprio conhecimento e usa o resumo como contexto em vez de script.
Este padrão está integrado nos "account summaries" do Salesforce Einstein, nos recursos de pesquisa de AI do HubSpot, e é o núcleo de ferramentas com propósito específico como a pesquisa de AI do Apollo.io e o Warmly. Para a versão específica de vendas deste caso de uso, veja pesquisa de conta de AI antes do primeiro contato.
3. Síntese de tendências do setor para executivos
Um CFO em uma empresa de tecnologia de saúde quer um resumo de 20 minutos antes de uma reunião de conselho sobre "como a AI está afetando os ciclos de receita de saúde." Essa síntese normalmente requer a leitura de 6-8 relatórios de analistas, 3 transcrições de chamadas de resultados de empresas públicas relevantes e uma dúzia de artigos da imprensa especializada.
O Ingest puxa de trechos do Gartner (se disponível), cobertura de conferências do HIMSS, transcrições de chamadas de resultados de empresas de health IT (Veeva, parceiros Epic, Waystar), imprensa especializada do Healthcare IT News e Health Data Management, e anúncios de investimentos de capital de risco na área.
O Analyze identifica os temas consensuais (automação de adjudicação de sinistros é consistentemente sinalizada em 7 de 10 fontes), os debates emergentes (quais fornecedores de AI estão realmente entregando versus prometendo) e as empresas-chave sendo citadas. Também verifica sinais conflitantes (uma fonte projeta redução de 30% nos custos administrativos; outro relatório de analista chama isso de "otimista").
O Generate produz um resumo de duas páginas: três tendências consensuais com evidências, duas áreas de discordância ativa sinalizadas explicitamente, cinco empresas a observar e uma seção "perguntas que você provavelmente enfrentará" com respostas sugeridas. O CFO pode apresentar isso como comentário informado, não como texto gerado por AI.
4. Dimensionamento de mercado com fontes citadas
O Head of Business Development de uma startup precisa de um dimensionamento aproximado de mercado para um novo segmento antes de uma reunião de captação de recursos. A análise TAM/SAM/SOM precisa ser defensável: não um número mágico, mas uma estimativa rastreável com fontes que um VC possa verificar.
O Ingest puxa: relatórios de analistas do setor, bancos de dados estatísticos governamentais, chamadas de resultados de empresas públicas mencionando o segmento e rodadas de financiamento recentes de startups no espaço com suas suposições de mercado implícitas.
O Analyze cruza as estimativas de dimensionamento de múltiplas fontes: um analista diz TAM de US$ 12B, o S-1 de um concorrente implica US$ 9B, um relatório do Gartner de 2024 disse US$ 8B crescendo a 14%. Identifica as diferenças metodológicas (um conta apenas software; outro inclui serviços). Traz à tona o intervalo de estimativas defensáveis e as suposições que impulsionam cada uma.
O Generate produz um memo de dimensionamento de mercado: seção de metodologia, três cenários (conservador/base/otimista), citações de fontes por número e uma nota de um parágrafo "como defender isso" para a reunião de captação de recursos.
5. Pesquisa de desk para due diligence de M&A
A equipe de estratégia de um comprador precisa de uma visão preliminar sobre uma empresa-alvo antes do engajamento formal. Eles querem inteligência de fontes públicas apenas, antes de assinar um NDA. Esta é pesquisa de desk, não due diligence completa, mas precisa ser completa.
O Ingest puxa: o site e a documentação de produto da empresa-alvo, toda a cobertura de imprensa pública, dados do LinkedIn sobre contagem de funcionários e trajetória de crescimento (um proxy para desempenho financeiro), avaliações do Glassdoor para sinais de cultura, Crunchbase para histórico de financiamento e nomes de investidores, G2 para sentimento de clientes e registros de patentes, se relevante.
O Analyze sintetiza: estimativa de intervalo de receita a partir de financiamento + sinais de crescimento, sinais de qualidade e churn da equipe do LinkedIn e Glassdoor, avaliação de diferenciação de produto a partir de materiais públicos e avaliações, posicionamento competitivo no contexto de outras aquisições no espaço.
O Generate produz um memo de due diligence no formato que a equipe de estratégia usa: visão geral do negócio, estimativas financeiras com níveis de confiança, avaliação da equipe, avaliação do produto, sinalizações de risco e perguntas abertas para o processo formal de due diligence.
Modos de falha: o que quebra o Generative Research
| Modo de falha | Causa raiz | Mitigação |
|---|---|---|
| Confabulação | O modelo preenche lacunas entre fontes reais com afirmações que parecem plausíveis, mas que nenhuma fonte realmente sustenta | Exigir citações por afirmação. Verificar pontualmente 3-5 citações por resumo antes de distribuir. Nunca circular sem um revisor humano nomeado que tenha verificado as fontes. |
| Defasagem de atualidade das fontes | O índice de busca web está 2-3 dias atrasado; a síntese de documentos internos é tão atualizada quanto o último ciclo de indexação | Incluir timestamps de coleta ou indexação na saída. Sinalizar afirmações sensíveis ao tempo com sua data de fonte. Para inteligência competitiva ou de mercado ao vivo, verificar afirmações-chave diretamente. |
| Fontes conflitantes apresentadas como unificadas | O modelo seleciona uma interpretação quando as fontes discordam, sem sinalizar a discordância | Solicitar explicitamente a exposição de conflitos: "Se as fontes discordarem sobre este tópico, sinalize a discordância e cite ambos os lados." Trate qualquer resumo que apresente tudo como consenso com suspeita. |
| Lavagem de citações | O modelo cita uma fonte real e credível para uma afirmação que essa fonte não faz realmente | Verificar citações pontualmente: não apenas que a fonte existe, mas que a passagem citada sustenta a afirmação atribuída. Este é o modo de falha mais insidioso porque parece autoritativo. |
| Deriva de escopo | Prompts muito abertos produzem saídas de 40 páginas que são abrangentes, mas inutilizáveis | Definir o escopo com precisão: intervalo de tempo, tipos de fonte, formato de saída e limite de palavras. Prompts mais estreitos produzem saídas mais úteis do que os amplos. |
| Viés de fonte única | Uma fonte dominante e de alta qualidade domina a síntese; a saída reflete uma perspectiva, não uma visão de múltiplas fontes | Verificar a distribuição de fontes na saída. Se 80% das citações apontam para uma fonte, a síntese não está fazendo seu trabalho. |
A lavagem de citações é o modo de falha mais insidioso porque produz saídas que parecem autoritativas. Um resumo que cita um relatório real do Gartner para uma afirmação que esse relatório não faz realmente passará por uma revisão casual e falhará sob escrutínio. A avaliação de 2024 do Stanford HAI sobre LLMs líderes em precisão de citações descobriu que 23% das citações geradas automaticamente em tarefas de síntese de longa duração ou citaram uma fonte que não continha a afirmação atribuída ou representaram incorretamente a posição da fonte. Isso não torna o Generative Research inutilizável. Torna a revisão humana de 15 minutos inegociável.
A confabulação merece atenção direta porque é o modo de falha que cria mais danos à confiança. Um resumo de Generative Research que contém uma afirmação confidentemente citada que a fonte citada não faz realmente vai, quando descoberta, destruir a confiança em todo o resumo e no padrão de forma mais ampla. A pesquisa da OpenAI sobre GPT-4 reconhece isso diretamente: mesmo modelos de alta capacidade podem produzir conteúdo plausível, mas impreciso, razão pela qual a verificação de citações permanece uma responsabilidade humana independentemente da qualidade do modelo. A mitigação não é evitar o padrão. É construir a verificação no fluxo de trabalho antes da distribuição. Veja risco de alucinação por padrão de AI para como isso se compara aos modos de falha em outros padrões com forte componente de Generate.
O modelo de confiança: a verificação não é opcional
O padrão RAG Assistant se beneficia de um modelo de confiança relativamente contido. A base de conhecimento é sua. As fontes são conhecidas. Se uma resposta estiver errada, a fonte está errada e você pode corrigir a fonte.
O Generative Research extrai de fontes externas, ao vivo e de domínios cruzados. A síntese pode produzir inferências que nenhuma fonte individual sustenta explicitamente. Esse é o valor. Mas também é por isso que o modelo de confiança deve ser explícito.
Antes de qualquer saída do Generative Research ser distribuída, um revisor humano nomeado deve:
- Ler a saída como um documento completo, não apenas o resumo
- Verificar pontualmente 3-5 citações, confirmando que a fonte existe e que a afirmação atribuída realmente está na fonte
- Sinalizar quaisquer afirmações de consenso que pareçam exageradas dada sua base de evidências
- Marcar qualquer seção onde as fontes estiveram em conflito (se ainda não sinalizado pela AI)
- Adicionar seu nome ao documento como o analista revisor
Esta revisão leva 15-30 minutos para um resumo bem formatado. Não é o mesmo que o trabalho de pesquisa original de 6-8 horas. Esse é o ganho de produtividade. Mas a revisão de 15 minutos não é opcional.
A falha comum: equipes implantam o Generative Research e param de fazer verificações pontuais após os primeiros seis meses porque as saídas "parecem boas." Então um resumo com uma estatística fabricada chega a uma apresentação de conselho. A solução é tornar a verificação pontual uma etapa documentada do fluxo de trabalho, não uma revisão opcional.
Quando o Generative Research funciona (e quando não funciona)
Funciona bem quando:
- A questão tem um escopo definido. "O que o Concorrente X anunciou no T1 de 2026?" tem escopo. "Me fale tudo sobre o Concorrente X" não tem.
- As fontes estão disponíveis e acessíveis. Para empresas públicas, pesquisa de mercado e inteligência competitiva, as fontes públicas geralmente são ricas. Para empresas privadas ou mercados emergentes, a qualidade das fontes cai.
- A saída será revisada antes da distribuição. Esta não é uma questão de confiança na tecnologia. É um requisito de fluxo de trabalho para qualquer saída de pesquisa que informe decisões.
- A necessidade é de síntese, não de uma consulta factual específica. Se você precisa de "qual é o ARR da Acme Corp?", isso é uma consulta factual onde uma única fonte autoritativa é melhor que a síntese. Se você precisa de "o que podemos inferir sobre a trajetória de crescimento da Acme Corp a partir de sinais públicos?", isso é síntese.
vs. RAG Assistant: O RAG é sua base de conhecimento interna respondendo a perguntas conhecidas. O Generative Research é síntese de fontes externas ou de domínios cruzados produzindo novos insights. Eles são frequentemente usados juntos: o Generative Research para construir resumos de inteligência a partir de fontes externas, o RAG Assistant para responder "o que aprendemos sobre esta conta?" a partir de resumos anteriores e notas de chamadas.
vs. Document Review: O Document Review pega um documento específico e o verifica em relação a um padrão ou modelo conhecido. O Generative Research pega muitos documentos e sintetiza uma nova saída deles. A distinção: um documento versus muitas fontes; verificação de conformidade versus síntese de insight.
vs. Meeting Intelligence: O Meeting Intelligence processa suas próprias gravações de conversas. O Generative Research extrai de material externo. Eles podem ser combinados: o Meeting Intelligence captura suas próprias conversas com clientes, o Generative Research sintetiza contexto de mercado externo, e um estrategista combina ambos para uma visão completa da conta.
Sinais de ROI: medindo o impacto
| Métrica | Linha de base manual | Com Generative Research | Melhoria típica |
|---|---|---|---|
| Horas de analista por resumo | 4-8 horas para um resumo competitivo completo | 30-60 minutos (AI + revisão) | Redução de 85-90% no tempo |
| Tempo da solicitação até o entregável | 1-3 dias (backlog + tempo de escrita) | 2-4 horas (entrega no mesmo dia) | Redução de 80-90% no tempo de ciclo |
| Cobertura de fontes por resumo | 5-10 fontes (limite prático para um analista) | 20-50 fontes (o limite de síntese de AI é mais amplo) | Melhoria de 3-5x na cobertura |
| Frequência de resumos | 1 resumo abrangente por mês por tópico | Resumos semanais tornam-se viáveis | Melhoria de 4-6x na cadência |
| Taxa de conclusão de pesquisa pré-chamada | 40-60% das chamadas de vendas têm alguma pesquisa pré-chamada | 85-95% com geração automatizada de resumo de conta | Melhoria de 40-50% |
A taxa de conclusão de pesquisa pré-chamada é frequentemente a métrica mais rastreável e se conecta diretamente a resultados de pipeline. Quando os representantes entram em chamadas com um resumo, a qualidade da chamada melhora. A pesquisa da McKinsey sobre AI em vendas B2B constata que a pesquisa de conta e a preparação pré-chamada estão entre os casos de uso de AI de maior entusiasmo para líderes de vendas, precisamente porque o ganho de produtividade é mensurável e imediato. Não porque o resumo seja perfeito, mas porque ter contexto muda a abertura de "me fale sobre sua empresa" para "vi que você acabou de abrir um novo escritório em São Paulo. Isso está ligado ao movimento de expansão que você mencionou na chamada de resultados?"
Rework Analysis: As implantações de Generative Research que têm sucesso têm uma coisa em comum: um revisor nomeado que é dono da verificação pontual de 15 minutos antes de cada resumo ser distribuído. Não é a AI que torna um resumo de pesquisa confiável. É o nome do revisor no documento. As equipes que pulam esta etapa em favor da velocidade eventualmente circulam um resumo com uma estatística fabricada para um conselho, um cliente ou um investidor. Quando isso acontece, a confiança em todo o programa entra em colapso, não apenas no resumo específico. O trabalho do revisor não é repetir a pesquisa. É verificar 3-5 citações e sinalizar qualquer afirmação que pareça excessivamente confiante dada sua base de evidências. Isso leva 15-30 minutos para um resumo de 10 páginas. Converte uma saída potencialmente perigosa em um entregável confiável. Nenhum outro controle de governança oferece mais ROI a um custo menor.
Perguntas Frequentes
O que é o padrão de AI Generative Research?
O Generative Research é um padrão de AI que sintetiza múltiplas fontes em uma saída de pesquisa coerente. A fórmula é: Ingest (corpus de múltiplas fontes), Analyze (síntese cruzada de fontes identificando sinais de consenso, conflitos e inferências), Generate (relatório estruturado, resumo ou análise). Difere do RAG Assistant porque extrai de fontes externas, ao vivo ou de domínios cruzados em vez de uma base de conhecimento interna controlada, e produz novas inferências a partir da combinação de fontes.
O que é o Padrão de Síntese Multi-Fonte?
O Padrão de Síntese Multi-Fonte é a capacidade definidora do Generative Research: ler múltiplas fontes simultaneamente para encontrar no que elas coletivamente concordam, trazer à tona onde conflitam e inferir o que as evidências combinadas implicam além do que qualquer fonte única declara. Uma implantação que resume cada fonte de forma independente não está usando este padrão. A camada de síntese é o que comprime 30 fontes em um resumo coerente e distingue o Generative Research de um lote de sumarizações de documentos costuradas juntas.
Como o Generative Research é diferente de um RAG Assistant?
O RAG Assistant recupera respostas de uma base de conhecimento interna controlada que você possui. O Generative Research sintetiza de fontes externas, ao vivo ou de domínios cruzados no momento da consulta. Os modelos de confiança são diferentes: as saídas do RAG podem ser verificadas verificando a fonte interna citada. As saídas do Generative Research requerem verificar que a fonte externa citada realmente sustenta a afirmação atribuída e que a inferência sintetizada se sustenta sob escrutínio. A revisão humana de 15 minutos antes da distribuição é um requisito de governança para o Generative Research que é menos crítico para o RAG.
O que é lavagem de citações em pesquisa de AI?
A lavagem de citações ocorre quando um modelo de AI cita uma fonte real e credível para uma afirmação que essa fonte não faz realmente. A avaliação de 2024 do Stanford HAI descobriu que 23% das citações geradas por AI em tarefas de síntese de longa duração ou citaram uma fonte que não continha a afirmação atribuída ou representaram incorretamente a posição da fonte. Isso produz saídas que parecem autoritativas e passam por revisão casual, mas falham sob escrutínio. A mitigação é verificar pontualmente 3-5 citações por resumo antes da distribuição.
Qual ROI você deve esperar do Generative Research?
As horas de analista por resumo competitivo caem de 4-8 horas para 30-60 minutos (redução de 85-90% no tempo). A cobertura de fontes por resumo melhora de 5-10 fontes para 20-50 fontes (melhoria de 3-5x). As taxas de conclusão de pesquisa pré-chamada para representantes de vendas sobem de 40-60% para 85-95%. A cadência de resumos melhora 4-6x (resumos semanais tornam-se viáveis onde o mensal era o limite anterior). A taxa de conclusão de pesquisa pré-chamada é a métrica mais rastreável e se conecta diretamente aos resultados do pipeline.
Quais são os modos de falha mais comuns do Generative Research?
Os seis principais modos de falha são: confabulação (afirmações plausíveis não sustentadas por nenhuma fonte), lavagem de citações (fonte real citada para uma afirmação que a fonte não faz), defasagem de atualidade das fontes (o índice está dias atrasado), fontes conflitantes apresentadas como consenso unificado, deriva de escopo (prompt muito amplo produzindo uma saída inutilizável) e viés de fonte única (uma fonte dominante sobrecarregando a síntese). A lavagem de citações é a mais insidiosa porque parece autoritativa. A confabulação é a mais prejudicial para a confiança quando descoberta.
Saiba mais

Co-Founder, Rework.com
On this page
- A fórmula: Ingest, Analyze, Generate
- O Padrão de Síntese Multi-Fonte
- Generative Research vs. RAG Assistant: a distinção crítica
- Cinco exemplos reais em profundidade
- 1. Relatório de inteligência competitiva
- 2. Resumo de pesquisa de conta antes de uma chamada de vendas
- 3. Síntese de tendências do setor para executivos
- 4. Dimensionamento de mercado com fontes citadas
- 5. Pesquisa de desk para due diligence de M&A
- Modos de falha: o que quebra o Generative Research
- O modelo de confiança: a verificação não é opcional
- Quando o Generative Research funciona (e quando não funciona)
- Sinais de ROI: medindo o impacto
- Saiba mais