Generative Research: Memampatkan Berjam-jam Pembacaan
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Seorang analis yang baik boleh mensintesis 30 sumber ke dalam ringkasan yang koheren. Mereka tahu sumber mana yang perlu dipercayai, mana yang perlu diberikan berat yang lebih ringan, cara menampilkan ketegangan apabila dua sumber yang boleh dipercayai tidak bersetuju, dan cara membuat output yang boleh dibaca oleh VP yang mempunyai lapan minit sebelum mesyuarat lembaga.
Kebanyakan pasukan tidak mampu mengupah analis yang mencukupi untuk melakukan ini dengan baik, secara konsisten, merentasi setiap pasaran, akaun, dan pesaing yang mereka pedulikan. Penyelidikan akaun sebelum panggilan jualan diabaikan. Laporan perisikan kompetitif sudah lapuk tiga minggu apabila ia digunakan. Penelitian wajar terhadap sasaran pengambilalihan yang berpotensi adalah cetek kerana tiada sesiapa yang mempunyai masa untuk pergi lebih mendalam.
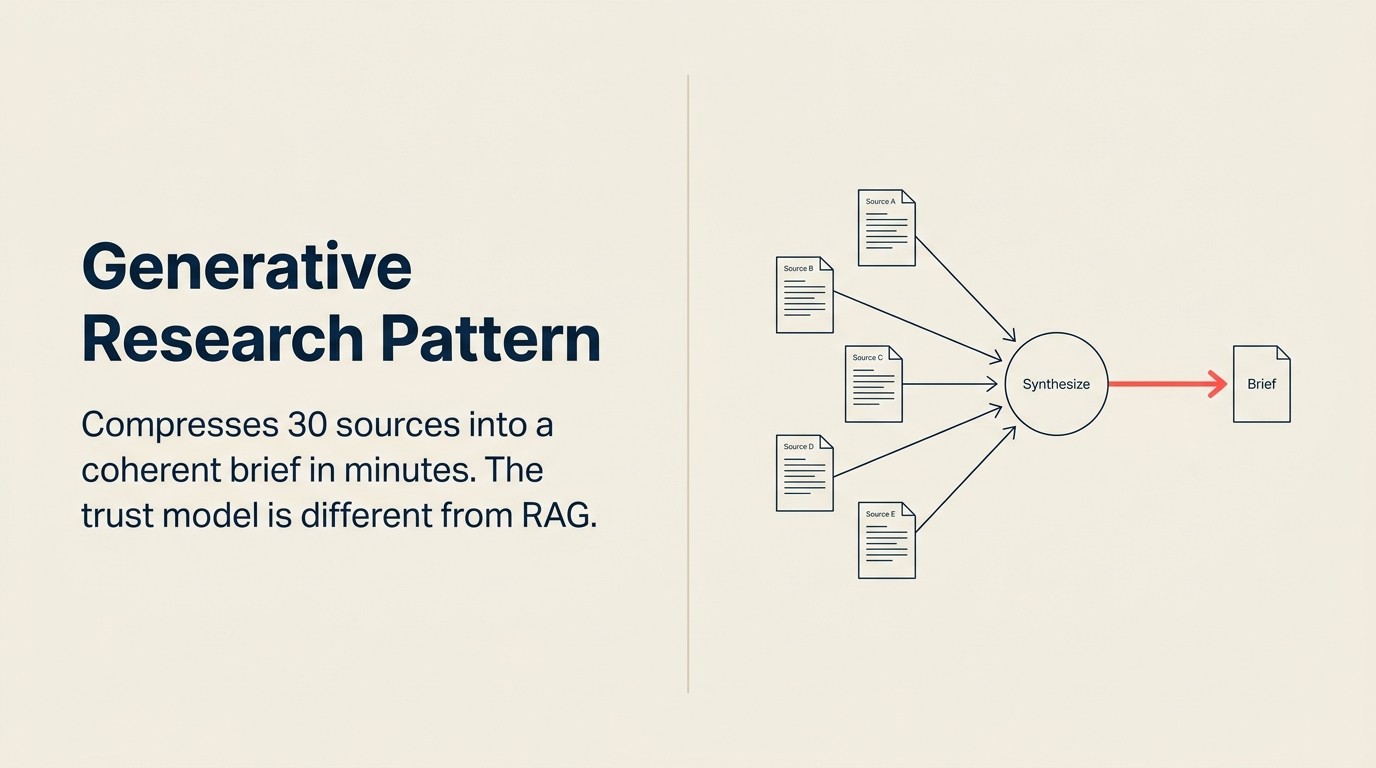
Generative Research adalah corak AI yang memampatkan kerja sintesis ini kepada beberapa minit. Bukan dengan menghapuskan analisis, tetapi dengan mengautomasikan pembacaan, rujukan silang, dan penstrukturan awal yang mengambil sebahagian besar masa analis. Pertimbangan analis masih penting pada akhirnya. Tetapi analis bermula dari ringkasan 10 halaman dan bukannya dari 30 tab pelayar.
Corak ini datang dengan soalan kepercayaan yang corak saudaranya, RAG Assistant, tidak ada. RAG mengambil dari pangkalan pengetahuan yang diketahui dan terkawal. Generative Research menyapu sumber langsung, luar, atau antara domain. Perbezaan itu mengubah rupa pengesahan dan di mana mod kegagalan berkelompok.
Formula: Ingest, Analyze, Generate
Ingest (korpus pelbagai sumber) menarik bahan sumber mentah. Sumber bergantung pada kes penggunaan. Untuk perisikan kompetitif: siaran akhbar, ulasan G2 dan Capterra, iklan pekerjaan LinkedIn, rakaman persidangan, transkrip panggilan pendapatan, artikel akhbar perdagangan. Untuk penyelidikan akaun: berita terkini syarikat sasaran, profil LinkedIn kepimpinan, laporan penganalisis industri, pengumuman pembiayaan terkini, sebutan pesaing. Untuk sintesis trend eksekutif: transkrip panggilan pendapatan dari 10-20 syarikat awam dalam sektor tersebut, petikan Gartner atau Forrester, artikel berita peringkat lembaga. Lapisan Ingest melakukan pengumpulan dan penormalan awal: menukar PDF, halaman web, transkrip, dan data berstruktur kepada bahagian teks yang boleh dibaca.
Analyze (sintesis) adalah langkah yang paling mencabar dalam corak ini. Model tidak sekadar meringkaskan setiap sumber secara bebas. Ia membaca merentasi semua sumber secara serentak, mengenal pasti apa yang pelbagai sumber persetujui (isyarat keyakinan tinggi), menampilkan di mana sumber bercanggah (bidang ketidakpastian), mengekstrak entiti bernama dan fakta utama, serta membina tafsiran koheren tentang apa yang bukti secara kolektif katakan. Sintesis merentasi sumber inilah yang membezakan Generative Research daripada ringkasan dokumen mudah. Meringkaskan setiap sumber secara berasingan bukanlah corak ini. Nilainya adalah dalam lapisan sintesis. Lihat Analyze: cara AI memahami apa yang anda kumpulkan untuk takrifan keupayaan penuh.
Generate (laporan, ringkasan, atau output berstruktur) menghasilkan hasil yang boleh dihantar. Ini mungkin analisis kompetitif yang diformat sebagai ringkasan bahagian demi bahagian dengan petikan, kad penyelidikan akaun yang diformat untuk sisipan CRM, memo eksekutif dengan poin-poin dan tindakan yang disyorkan, atau jadual penyesuaian saiz pasaran dengan nota kaki sumber. Langkah Generate memformat pandangan yang disintesis ke dalam format output yang diperlukan oleh pemohon.
Perhatikan bahawa corak ini berakhir di Generate. Tiada langkah Execute dalam formula asas. Output adalah draf untuk disemak oleh manusia sebelum ia pergi ke mana-mana. Untuk kebanyakan kes penggunaan Generative Research, semakan manusia itu bukan pilihan. Ia adalah mekanisme tadbir urus yang menjadikan corak ini selamat untuk diedarkan.
Key Facts: Impak Generative Research
- McKinsey menganggarkan AI generatif boleh mengautomasikan 60-70% masa pekerja yang kini digunakan untuk aktiviti kerja pengetahuan, dengan sintesis penyelidikan disebut sebagai salah satu aktiviti kerja pengetahuan bernilai tinggi yang boleh dimampatkannya (McKinsey, 2023)
- Wakil jualan menyelesaikan penyelidikan pra-panggilan pada 40-60% panggilan tanpa bantuan AI; dengan ringkasan akaun yang dijana AI, kadar penyelesaian penyelidikan pra-panggilan meningkat kepada 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- Ringkasan perisikan kompetitif berkuasa AI mensintesis 20-50 sumber dalam 2-4 jam berbanding 6-8 jam bagi setiap analis bagi setiap pesaing menggunakan penyelidikan manual, penambahbaikan liputan sumber 3-5x pada pengurangan masa 85-90% (Gartner Competitive Intelligence Report, 2025)
Corak Sintesis Pelbagai Sumber
Nilai teras Generative Research bukanlah ringkasan sumber individu. Ia adalah sintesis merentasi sumber: mencari apa yang pelbagai sumber persetujui (isyarat keyakinan tinggi), menampilkan di mana sumber bercanggah (bidang ketidakpastian), dan membuat inferens tentang apa yang bukti gabungan berimplikasi melebihi apa yang mana-mana sumber secara eksplisit nyatakan. Penggunaan Generative Research yang meringkaskan setiap sumber secara bebas dan mempersembahkan ringkasan secara bersebelahan tidak menggunakan corak ini. Corak ini memerlukan langkah Analyze yang membaca semua sumber secara serentak dan menghasilkan tafsiran bersepadu. Lapisan sintesis itulah yang memampatkan 30 sumber ke dalam ringkasan yang koheren, dan itulah yang memisahkan Generative Research daripada kelompok ringkasan yang disatukan.
Generative Research berbanding RAG Assistant: perbezaan kritikal
Dua corak ini paling kerap dikacaubilaukan dalam amalan.
RAG Assistant mengambil jawapan dari pangkalan pengetahuan dalaman yang terkawal dan diketahui. Anda tahu apa yang ada dalam pangkalan pengetahuan (dokumen produk anda, tiket sokongan lalu, dasar HR). Pengambilan adalah terhad. Jawapan memetik sumber yang wujud dalam sistem anda. Mod kegagalan adalah mengambil dokumen yang salah atau pangkalan pengetahuan yang lapuk. Bukan fabrikasi dari web terbuka.
Generative Research mensintesis dari korpus yang sering kali luar, langsung, atau antara domain. Sumber tidak dipraindeks dalam sistem anda. Mereka ditarik pada masa pertanyaan dari carian web, suapan API, dokumen yang dimuat naik, atau pangkalan data pihak ketiga. Sintesis boleh menampilkan maklumat yang tiada sumber tunggal secara eksplisit nyatakan: model membuat inferens dari gabungan. Keupayaan inferens itu adalah kedua-duanya nilai dan risiko.
Implikasi praktikal: output RAG boleh disahkan dengan menyemak sumber yang dipetik. Output Generative Research memerlukan semakan spot ke atas sumber yang dipetik (adakah sumber itu sebenarnya menyatakan apa yang dinisbahkan?) dan logik sintesis (adakah inferens itu bertahan?). Proses pengesahan yang berbeza, keperluan tadbir urus yang berbeza.
Lima contoh nyata secara mendalam
1. Pelaporan perisikan kompetitif
VP Produk memerlukan kemas kini kompetitif suku tahunan tentang tiga pesaing langsung. Setiap pesaing mempunyai laman web, profil G2, LinkedIn yang aktif, siaran akhbar terkini, dan beberapa sebutan ulasan di Reddit dan Capterra. Membaca dan mensintesis semua itu secara manual mengambil masa analis produk 6-8 jam bagi setiap pesaing.
Ingest menarik dari semua sumber ini: halaman web yang diskrap pada masa penarikan, ulasan G2 ditapis mengikut tarikh, siaran dan iklan pekerjaan LinkedIn, siaran akhbar, dan sebutan berita. Analyze merujuk silang sumber: ciri apakah yang penyemak secara konsisten sebut dalam ulasan G2 yang tidak ada di laman web syarikat sendiri? Apa yang iklan pekerjaan untuk "Ketua Jualan Perusahaan" isyaratkan tentang hala tuju strategik mereka? Di mana dua sumber tidak bersetuju (satu ulasan menyebut UX sebagai cemerlang; yang lain menandakannya sebagai kelemahan)?
Generate menghasilkan ringkasan berstruktur: kemas kini produk dalam suku tersebut, peralihan kedudukan, isyarat harga dari ulasan, isyarat bakat dari iklan pekerjaan, dan petikan utama dari sumber pihak ketiga. Output diformat sebagai ringkasan satu halaman dengan bahagian yang boleh dikembangkan bagi setiap kategori sumber.
Semakan manusia menyemak: adakah petikan yang dipetik sebenarnya datang dari sumber yang dipetik? Adakah kesimpulan strategik yang diinferens bertahan di bawah penelitian?
Alat yang menyokong ini: Perplexity API, Tavily untuk penempatan carian web, Claude dan GPT-4 dengan alat carian, dan platform perisikan kompetitif yang dibina khas seperti Crayon, Klue, dan Battlecards.
2. Ringkasan penyelidikan akaun sebelum panggilan jualan
Pengarah jualan mempunyai panggilan dalam 90 minit dengan VP Operasi di syarikat pembuatan yang belum pernah dibertuturnya sebelum ini. Dia perlu tahu: apa yang berlaku di syarikat ini, apa cabaran terkini mereka, siapa pemegang kepentingan, dan apa konteks industri.
Ingest menarik: siaran akhbar dan liputan berita terkini syarikat (90 hari terakhir), profil LinkedIn prospek dan aktiviti terkini, komen awam terkini CEO dan CFO, berita industri dari outlet perdagangan pembuatan, dan sebarang data CRM sedia ada dan benang e-mel lalu.
Analyze menampilkan: pengambilalihan baru-baru ini yang mengubah keutamaan rantaian bekalan mereka, siaran LinkedIn dari prospek yang menyebut kerumitan operasi sebagai cabaran, petikan panggilan pendapatan dari CEO tentang "kecekapan operasi" sebagai keutamaan 2026, dan corak dalam pengambilan pekerja terkini yang mencadangkan mereka sedang membina pasukan data.
Generate menghasilkan ringkasan pra-panggilan dua halaman: konteks syarikat utama (2 poin), perkembangan terkini (3 poin), latar belakang kenalan (2 poin), keutamaan yang mungkin berdasarkan bukti (3 poin dengan sumber), dan cadangan soalan pembuka yang dikaitkan dengan perisikan. Wakil menyemak dalam 8 minit, menyesuaikan soalan pembuka berdasarkan pengetahuannya sendiri, dan menggunakan ringkasan sebagai konteks dan bukannya sebagai skrip.
Corak ini dibina ke dalam "ringkasan akaun" Salesforce Einstein, ciri penyelidikan AI HubSpot, dan merupakan teras alat yang dibina khas seperti penyelidikan AI Apollo.io dan Warmly. Untuk versi khusus jualan penuh kes penggunaan ini, lihat penyelidikan akaun AI sebelum sentuhan pertama.
3. Sintesis trend industri eksekutif
CFO di syarikat teknologi penjagaan kesihatan mahukan ringkasan 20 minit sebelum mesyuarat lembaga tentang "di mana AI mempengaruhi kitaran hasil penjagaan kesihatan." Sintesis itu biasanya memerlukan membaca 6-8 laporan penganalisis, 3 transkrip panggilan pendapatan dari syarikat awam yang relevan, dan sedozen artikel akhbar perdagangan.
Ingest menarik dari petikan Gartner (jika tersedia), liputan persidangan HIMSS, transkrip panggilan pendapatan dari syarikat IT kesihatan (Veeva, rakan kongsi Epic, Waystar), akhbar perdagangan dari Healthcare IT News dan Health Data Management, dan pengumuman pelaburan VC dalam ruang tersebut.
Analyze mengenal pasti tema konsensus (automasi penyelarasan tuntutan secara konsisten ditandakan merentasi 7 daripada 10 sumber), perdebatan yang muncul (vendor AI mana yang sebenarnya menyampaikan berbanding berjanji), dan syarikat utama yang disebut. Ia juga menyemak isyarat yang bercanggah (satu sumber meramalkan pengurangan kos pentadbiran 30%; laporan penganalisis lain menyebutnya "optimistik").
Generate menghasilkan ringkasan dua halaman: tiga trend konsensus dengan bukti, dua bidang perselisihan aktif yang ditandakan secara eksplisit, lima syarikat yang patut diperhatikan, dan bahagian "soalan yang mungkin anda hadapi" dengan respons yang dicadangkan. CFO boleh mempersembahkan ini sebagai ulasan berdasarkan maklumat, bukan sebagai teks yang dijana AI.
4. Penyesuaian saiz pasaran dengan sumber yang dipetik
Ketua Pembangunan Perniagaan syarikat permulaan memerlukan penyesuaian saiz pasaran kasar untuk segmen baharu sebelum mesyuarat pengumpulan dana. Analisis TAM/SAM/SOM perlu boleh dipertahankan: bukan nombor ajaib, tetapi anggaran yang boleh dijejaki dengan sumber yang boleh disemak oleh pelabur modal teroka.
Ingest menarik: laporan penganalisis industri, pangkalan data statistik kerajaan (BLS, Banci), panggilan pendapatan syarikat awam yang menyebut segmen tersebut, dan pusingan pembiayaan syarikat permulaan terkini dalam ruang tersebut dengan andaian pasaran yang tersirat.
Analyze merujuk silang anggaran penyesuaian saiz dari pelbagai sumber: satu penganalisis menyebut TAM $12B, S-1 pesaing berimplikasi $9B, laporan Gartner dari 2024 menyebut $8B berkembang pada 14%. Ia mengenal pasti perbezaan metodologi (satu mengira perisian sahaja; yang lain termasuk perkhidmatan). Ia menampilkan julat anggaran yang boleh dipertahankan dan andaian yang mendorong setiap satu.
Generate menghasilkan memo penyesuaian saiz pasaran: bahagian metodologi, tiga senario (konservatif/asas/optimistik), petikan sumber bagi setiap nombor, dan satu perenggan "cara mempertahankan ini" untuk mesyuarat pengumpulan dana.
5. Penyelidikan meja penelitian wajar M&A
Pasukan strategi pengambil alih memerlukan pandangan awal tentang syarikat sasaran sebelum penglibatan rasmi. Mereka mahukan perisikan sumber awam sahaja, sebelum mereka menandatangani NDA. Ini adalah penyelidikan meja, bukan penelitian wajar penuh, tetapi ia perlu menyeluruh.
Ingest menarik: laman web dan dokumentasi produk sasaran, semua liputan akhbar awam, data LinkedIn tentang bilangan pekerja dan trajektori pertumbuhan (proksi untuk prestasi kewangan), ulasan Glassdoor untuk isyarat budaya, Crunchbase untuk sejarah pembiayaan dan nama pelabur, G2 untuk sentimen pelanggan, dan pemfailan paten jika relevan.
Analyze mensintesis: anggaran julat hasil dari pembiayaan + isyarat pertumbuhan, kualiti pasukan dan isyarat churn dari LinkedIn dan Glassdoor, penilaian pembezaan produk dari bahan awam dan ulasan, kedudukan kompetitif dalam konteks pengambilalihan lain dalam ruang tersebut.
Generate menghasilkan memo penelitian wajar dalam format yang digunakan pasukan strategi: gambaran keseluruhan perniagaan, anggaran kewangan dengan tahap keyakinan, penilaian pasukan, penilaian produk, tanda-tanda risiko, dan soalan terbuka untuk proses penelitian wajar rasmi.
Mod kegagalan: apa yang merosakkan Generative Research
| Mod kegagalan | Punca akar | Mitigasi |
|---|---|---|
| Konfabulasi | Model mengisi jurang antara sumber nyata dengan tuntutan yang terdengar munasabah yang tiada sumber sebenarnya menyokong | Perlukan petikan bagi setiap tuntutan. Semak spot 3-5 petikan bagi setiap ringkasan sebelum diedarkan. Jangan pernah edaran tanpa penyemak manusia bernama yang telah menyemak sumber. |
| Ketinggalan mata wang sumber | Indeks carian web 2-3 hari di belakang; sintesis dokumen dalaman hanya segar seperti jalankan indeks terakhir | Sertakan cap masa perangkakan atau indeks dalam output. Tandakan tuntutan sensitif masa dengan tarikh sumbernya. Untuk perisikan kompetitif atau pasaran langsung, sahkan tuntutan utama secara langsung. |
| Sumber bercanggah yang dibentangkan sebagai bersepadu | Model memilih satu tafsiran apabila sumber tidak bersetuju, tanpa menandakan perselisihan | Segera untuk penampilan konflik eksplisit: "Jika sumber tidak bersetuju mengenai topik ini, tandakan perselisihan dan petik kedua-dua pihak." Anggap sebarang ringkasan yang mempersembahkan segala-galanya sebagai konsensus dengan syak wasangka. |
| Pengubahan suci petikan | Model memetik sumber nyata yang bereputasi untuk tuntutan yang sumber itu sebenarnya tidak buat | Semak spot petikan: bukan sahaja bahawa sumber wujud, tetapi bahawa petikan yang dinisbahkan menyokong tuntutan yang dinisbahkan. Ini adalah mod kegagalan yang paling berbahaya kerana ia kelihatan berwibawa. |
| Peralihan skop | Segera yang terbuka menghasilkan output 40 halaman yang menyeluruh tetapi tidak dapat digunakan | Tentukan skop dengan tepat: julat masa, jenis sumber, format output, dan had perkataan. Segera yang lebih sempit menghasilkan output yang lebih berguna daripada yang luas. |
| Berat sebelah sumber tunggal | Satu sumber dominan berkualiti tinggi menguasai sintesis; output mencerminkan satu perspektif, bukan pandangan pelbagai sumber | Semak pengagihan sumber dalam output. Jika 80% petikan menghala ke satu sumber, sintesis tidak melakukan tugasnya. |
Pengubahan suci petikan adalah mod kegagalan yang paling berbahaya kerana ia menghasilkan output yang kelihatan berwibawa. Ringkasan yang memetik laporan Gartner nyata untuk tuntutan yang laporan itu sebenarnya tidak buat akan lulus semakan kasual dan gagal di bawah penelitian. Penilaian Stanford HAI 2024 tentang LLM terkemuka mengenai ketepatan petikan mendapati bahawa 23% petikan yang dijana secara automatik dalam tugas sintesis bentuk panjang sama ada memetik sumber yang tidak mengandungi tuntutan yang dinisbahkan atau sedikit salah gambaran kedudukan sumber. Ini tidak menjadikan Generative Research tidak boleh digunakan. Ia menjadikan semakan manusia 15 minit tidak boleh dinafikan.
Konfabulasi layak mendapat perhatian langsung kerana ia adalah mod kegagalan yang mewujudkan kerosakan kepercayaan paling besar. Ringkasan Generative Research yang mengandungi satu tuntutan yang dipetik dengan yakin yang sumber yang dipetik sebenarnya tidak buat akan, apabila ditemui, memusnahkan kepercayaan terhadap keseluruhan ringkasan dan terhadap corak itu secara lebih luas. Penyelidikan OpenAI tentang GPT-4 mengakui ini secara langsung: walaupun model berkeupayaan tinggi boleh menghasilkan kandungan yang terdengar munasabah tetapi tidak tepat, itulah sebabnya pengesahan petikan kekal tanggungjawab manusia tanpa mengira kualiti model. Mitigasinya bukan untuk mengelak corak tersebut. Ia adalah untuk membina pengesahan ke dalam alur kerja sebelum pengedaran. Lihat risiko halusinasi mengikut AI pattern untuk cara ini dibandingkan dengan mod kegagalan dalam corak lain yang berat Generate.
Model kepercayaan: pengesahan adalah tidak pilihan
Corak RAG Assistant mendapat manfaat daripada model kepercayaan yang agak terkandung. Pangkalan pengetahuan adalah milik anda. Sumber diketahui. Jika jawapan salah, sumber salah, dan anda boleh betulkan sumber.
Generative Research menarik dari sumber luar, langsung, dan antara domain. Sintesis boleh menghasilkan inferens yang tiada sumber individu secara eksplisit menyokong. Itulah nilainya. Tetapi itulah juga sebabnya model kepercayaan mesti eksplisit.
Sebelum sebarang output Generative Research diedarkan, penyemak manusia bernama harus:
- Baca output sebagai dokumen penuh, bukan sekadar ringkasan
- Semak spot 3-5 petikan, mengesahkan bahawa sumber wujud dan bahawa tuntutan yang dinisbahkan sebenarnya ada dalam sumber
- Tandakan sebarang tuntutan konsensus yang terasa terlalu dilebih-lebihkan berdasarkan asas buktinya
- Tandakan sebarang bahagian di mana sumber bercanggah (jika belum ditandakan oleh AI)
- Tambah nama mereka ke dokumen sebagai analis penyemak
Semakan ini mengambil masa 15-30 minit untuk ringkasan yang diformat dengan baik. Ia bukan sama dengan kerja penyelidikan asal 6-8 jam. Itulah keuntungan produktiviti. Tetapi semakan 15 minit itu bukan pilihan.
Kegagalan biasa: pasukan menggunakan Generative Research dan berhenti melakukan semakan spot selepas enam bulan pertama kerana output "kelihatan baik." Kemudian ringkasan dengan statistik yang dibuat-buat sampai ke pembentangan lembaga. Pembaikannya adalah menjadikan semakan spot sebagai langkah alur kerja yang didokumenkan, bukan semakan pilihan.
Bila Generative Research berfungsi (dan bila tidak)
Berfungsi dengan baik apabila:
- Soalan mempunyai skop yang ditentukan. "Apa yang Pesaing X umumkan pada S1 2026?" adalah berskop. "Beritahu saya segala-galanya tentang Pesaing X" tidak.
- Sumber tersedia dan boleh diakses. Untuk syarikat awam, penyelidikan pasaran, dan perisikan kompetitif, sumber awam biasanya kaya. Untuk syarikat swasta atau pasaran yang muncul, kualiti sumber menurun.
- Output akan disemak sebelum pengedaran. Ini bukan soal kepercayaan terhadap teknologi. Ini adalah keperluan alur kerja untuk sebarang output penyelidikan yang memaklumkan keputusan.
- Keperluan adalah untuk sintesis, bukan untuk carian fakta tertentu. Jika anda memerlukan "apa ARR Corp Acme?", itu adalah carian fakta di mana satu sumber berwibawa lebih baik daripada sintesis. Jika anda memerlukan "apa yang boleh kita inferens tentang trajektori pertumbuhan Corp Acme dari isyarat awam?", itu adalah sintesis.
berbanding RAG Assistant: RAG adalah pangkalan pengetahuan dalaman anda yang menjawab soalan yang diketahui. Generative Research adalah sintesis dari sumber luar atau antara domain yang menghasilkan pandangan baharu. Mereka sering digunakan bersama: Generative Research untuk membina ringkasan perisikan dari sumber luar, RAG Assistant untuk menjawab "apa yang telah kita pelajari tentang akaun ini?" dari ringkasan dan nota panggilan lalu.
berbanding Document Review: Document Review mengambil dokumen tertentu dan menyemaknya terhadap piawaian atau templat yang diketahui. Generative Research mengambil banyak dokumen dan mensintesis output baharu darinya. Perbezaan: satu dokumen berbanding banyak sumber; semakan pematuhan berbanding sintesis pandangan.
berbanding Meeting Intelligence: Meeting Intelligence memproses rakaman perbualan anda sendiri. Generative Research menarik dari bahan luar. Mereka boleh dipasangkan: Meeting Intelligence menangkap perbualan pelanggan anda sendiri, Generative Research mensintesis konteks pasaran luar, dan ahli strategi menggabungkan kedua-duanya untuk pandangan akaun yang penuh.
Isyarat ROI: mengukur impak
| Metrik | Asas manual | Dengan Generative Research | Penambahbaikan tipikal |
|---|---|---|---|
| Jam analis bagi setiap ringkasan | 4-8 jam untuk ringkasan kompetitif penuh | 30-60 minit (AI + semakan) | Pengurangan masa 85-90% |
| Masa dari permintaan ke hasil boleh hantar | 1-3 hari (tunggakan + masa penulisan) | 2-4 jam (penghantaran pada hari yang sama) | Pengurangan masa kitaran 80-90% |
| Liputan sumber bagi setiap ringkasan | 5-10 sumber (had praktikal untuk seorang analis) | 20-50 sumber (had sintesis AI lebih luas) | Penambahbaikan liputan 3-5x |
| Kekerapan ringkasan | 1 ringkasan menyeluruh sebulan bagi setiap topik | Ringkasan mingguan menjadi boleh dilaksanakan | Penambahbaikan kadence 4-6x |
| Kadar penyelesaian penyelidikan pra-panggilan | 40-60% panggilan jualan mempunyai sebarang penyelidikan pra-panggilan | 85-95% dengan penjanaan ringkasan akaun automatik | Penambahbaikan 40-50% |
Kadar penyelesaian penyelidikan pra-panggilan sering merupakan metrik yang paling mudah dijejaki, dan ia berhubung secara langsung dengan hasil pipeline. Apabila wakil masuk ke panggilan dengan ringkasan, kualiti panggilan meningkat. Penyelidikan McKinsey tentang AI dalam jualan B2B mendapati bahawa penyelidikan akaun dan persediaan pra-panggilan adalah antara kes penggunaan AI dengan keseronokan tertinggi untuk pemimpin jualan, tepat kerana keuntungan produktiviti boleh diukur dan segera. Bukan kerana ringkasan itu sempurna, tetapi kerana mempunyai konteks mengalihkan pembukaan dari "ceritakan tentang syarikat anda" kepada "saya nampak anda baru membuka pejabat baharu di Austin. Adakah itu berkaitan dengan dorongan pengembangan yang anda sebutkan dalam panggilan pendapatan anda?"
Rework Analysis: Penggunaan Generative Research yang berjaya mempunyai satu persamaan: penyemak bernama yang memiliki semakan spot 15 minit sebelum setiap ringkasan diedarkan. Bukan AI yang menjadikan ringkasan penyelidikan boleh dipercayai. Ia adalah nama penyemak pada dokumen. Pasukan yang melangkau langkah ini demi kelajuan akhirnya mengedarkan ringkasan dengan statistik yang dibuat-buat kepada lembaga, pelanggan, atau pelabur. Apabila itu berlaku, kepercayaan terhadap keseluruhan program runtuh, bukan sahaja terhadap ringkasan khusus itu. Tugas penyemak bukan untuk mengulangi penyelidikan. Ia adalah untuk mengesahkan 3-5 petikan dan menandakan sebarang tuntutan yang terasa terlalu yakin berdasarkan asas buktinya. Itu mengambil masa 15-30 minit untuk ringkasan 10 halaman. Ia menukar output yang berpotensi berbahaya kepada hasil boleh hantar yang boleh dipercayai. Tiada kawalan tadbir urus lain memberikan lebih ROI pada kos yang lebih rendah.
Soalan Lazim
Apakah corak AI Generative Research?
Generative Research adalah corak AI yang mensintesis pelbagai sumber ke dalam output penyelidikan yang koheren. Formulanya adalah: Ingest (korpus pelbagai sumber), Analyze (sintesis merentasi sumber yang mengenal pasti isyarat konsensus, konflik, dan inferens), Generate (laporan berstruktur, ringkasan, atau analisis). Ia berbeza daripada RAG Assistant kerana ia menarik dari sumber luar, langsung, atau antara domain dan bukannya pangkalan pengetahuan dalaman yang terkawal, dan ia menghasilkan inferens baharu dari gabungan sumber.
Apakah Corak Sintesis Pelbagai Sumber?
Corak Sintesis Pelbagai Sumber adalah keupayaan yang menentukan Generative Research: membaca pelbagai sumber secara serentak untuk mencari apa yang mereka secara kolektif persetujui, menampilkan di mana mereka bercanggah, dan membuat inferens tentang apa yang bukti gabungan berimplikasi melebihi apa yang mana-mana sumber tunggal nyatakan. Penggunaan yang meringkaskan setiap sumber secara bebas tidak menggunakan corak ini. Lapisan sintesis adalah apa yang memampatkan 30 sumber ke dalam ringkasan yang koheren dan membezakan Generative Research daripada kelompok ringkasan dokumen yang disatukan.
Bagaimana Generative Research berbeza daripada RAG Assistant?
RAG Assistant mengambil jawapan dari pangkalan pengetahuan dalaman yang terkawal yang anda miliki. Generative Research mensintesis dari sumber luar, langsung, atau antara domain pada masa pertanyaan. Model kepercayaan adalah berbeza: output RAG boleh disahkan dengan menyemak sumber dalaman yang dipetik. Output Generative Research memerlukan pengesahan bahawa sumber luar yang dipetik sebenarnya menyokong tuntutan yang dinisbahkan dan bahawa inferens yang disintesis bertahan di bawah penelitian. Semakan manusia 15 minit sebelum pengedaran adalah keperluan tadbir urus untuk Generative Research yang kurang kritikal untuk RAG.
Apakah pengubahan suci petikan dalam penyelidikan AI?
Pengubahan suci petikan berlaku apabila model AI memetik sumber nyata yang bereputasi untuk tuntutan yang sumber itu sebenarnya tidak buat. Penilaian Stanford HAI 2024 mendapati 23% petikan yang dijana AI dalam tugas sintesis bentuk panjang sama ada memetik sumber yang tidak mengandungi tuntutan yang dinisbahkan atau salah gambaran kedudukan sumber. Ini menghasilkan output yang kelihatan berwibawa dan lulus semakan kasual tetapi gagal di bawah penelitian. Mitigasinya adalah semakan spot 3-5 petikan bagi setiap ringkasan sebelum pengedaran.
ROI apa yang patut anda jangkakan dari Generative Research?
Jam analis bagi setiap ringkasan kompetitif turun dari 4-8 jam kepada 30-60 minit (pengurangan masa 85-90%). Liputan sumber bagi setiap ringkasan meningkat dari 5-10 sumber kepada 20-50 sumber (penambahbaikan 3-5x). Kadar penyelesaian penyelidikan pra-panggilan untuk wakil jualan meningkat dari 40-60% kepada 85-95%. Kadence ringkasan meningkat 4-6x (ringkasan mingguan menjadi boleh dilaksanakan di mana bulanan adalah had sebelumnya). Kadar penyelesaian penyelidikan pra-panggilan adalah metrik yang paling boleh dijejaki dan berhubung secara langsung dengan hasil pipeline.
Apakah mod kegagalan Generative Research yang paling biasa?
Enam mod kegagalan utama adalah konfabulasi (tuntutan yang terdengar munasabah tidak disokong oleh mana-mana sumber), pengubahan suci petikan (sumber nyata dipetik untuk tuntutan yang sumber itu tidak buat), ketinggalan mata wang sumber (indeks beberapa hari di belakang), sumber bercanggah yang dibentangkan sebagai konsensus bersepadu, peralihan skop (segera yang terlalu luas menghasilkan output yang tidak dapat digunakan), dan berat sebelah sumber tunggal (satu sumber dominan menguasai sintesis). Pengubahan suci petikan adalah yang paling berbahaya kerana ia kelihatan berwibawa. Konfabulasi adalah yang paling merosakkan kepercayaan apabila ditemui.
Ketahui lebih lanjut

Co-Founder, Rework.com
On this page
- Formula: Ingest, Analyze, Generate
- Corak Sintesis Pelbagai Sumber
- Generative Research berbanding RAG Assistant: perbezaan kritikal
- Lima contoh nyata secara mendalam
- 1. Pelaporan perisikan kompetitif
- 2. Ringkasan penyelidikan akaun sebelum panggilan jualan
- 3. Sintesis trend industri eksekutif
- 4. Penyesuaian saiz pasaran dengan sumber yang dipetik
- 5. Penyelidikan meja penelitian wajar M&A
- Mod kegagalan: apa yang merosakkan Generative Research
- Model kepercayaan: pengesahan adalah tidak pilihan
- Bila Generative Research berfungsi (dan bila tidak)
- Isyarat ROI: mengukur impak
- Ketahui lebih lanjut