Generative Research: 何時間もの読み取りを圧縮する
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
優秀なアナリストは30のソースを一貫したブリーフに合成できます。どのソースを信頼するか、どれを軽く重み付けするか、2つの信頼できるソースが異なる意見のときに緊張を表面化させる方法、ボードミーティングの8分前に8分しかない VPにとって読みやすい出力にする方法を知っています。
ほとんどのチームは、自分たちが気にするすべての市場、アカウント、競合他社において、一貫してこれをうまく行うのに十分なアナリストを確保できません。営業電話前のアカウントリサーチはスキップされます。競合インテリジェンスレポートは使用されるときに3週間古くなっています。潜在的な買収対象についてのデューデリジェンスは、誰も深く進む時間がなかったため浅いままです。
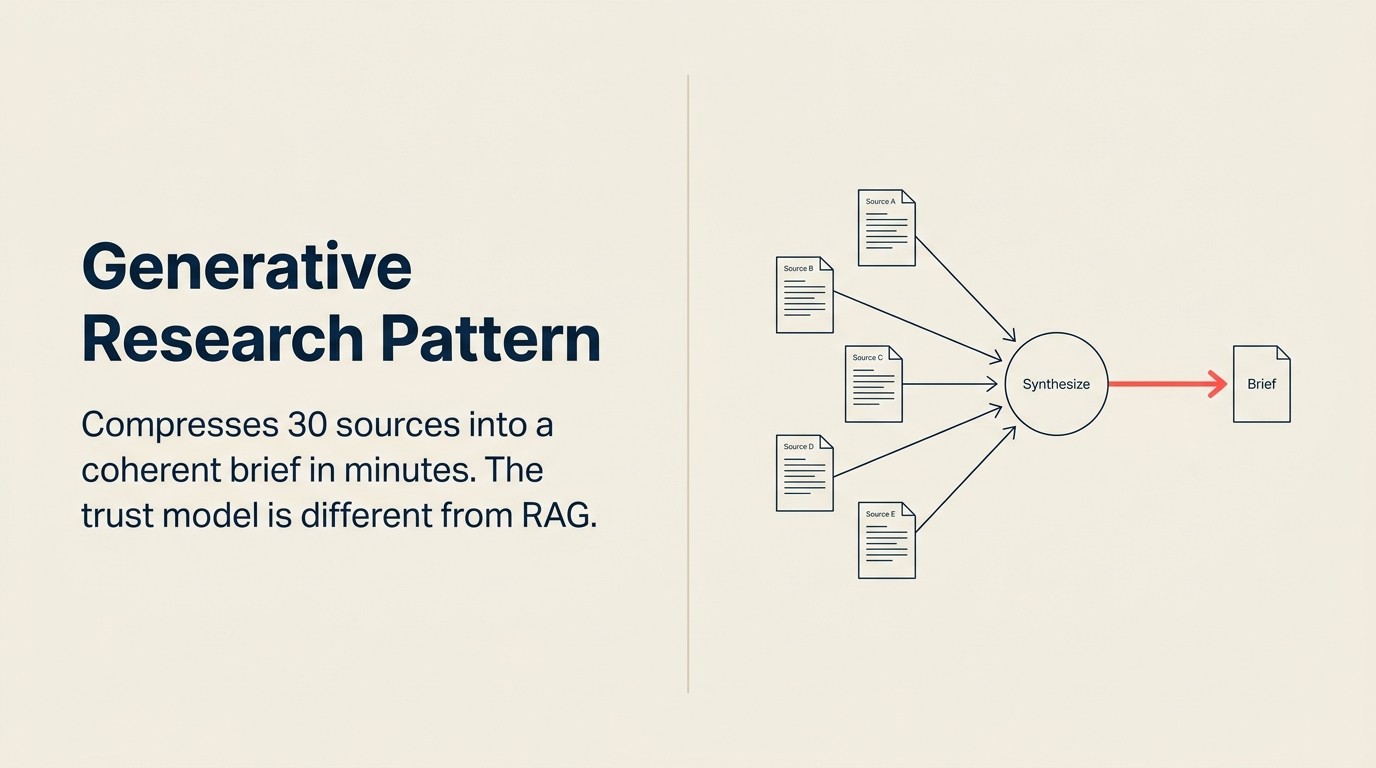
Generative Researchはこの合成作業を数分に圧縮するAIパターンです。分析を排除するのではなく、アナリストの時間のほとんどを消費する読み取り、相互参照、初期構造化を自動化することによって。アナリストの判断は最後には依然として重要です。しかしアナリストは30のブラウザタブではなく10ページのブリーフから始めます。
このパターンには、兄弟パターンのRAG Assistantが持たない信頼の問題が伴います。RAGは既知のコントロールされたナレッジベースから検索します。Generative Researchはライブ、外部、またはクロスドメインのソースを調査します。その違いが検証がどのように見えるか、失敗モードがどこにクラスターするかを変えます。
機能の式: Ingest、Analyze、Generate
Ingest(マルチソースコーパス) は生のソース資料を取得します。ソースはユースケースによって異なります。競合インテリジェンス向け: プレスリリース、G2とCapterraのレビュー、LinkedInの求人掲載、カンファレンス録音、決算説明会のトランスクリプト、業界誌の記事。アカウントリサーチ向け: ターゲット企業の最近のニュース、リーダーシップのLinkedInプロファイル、業界アナリストレポート、最近の資金調達発表、競合他社の言及。エグゼクティブトレンド合成向け: セクターの10〜20の上場企業の決算説明会トランスクリプト、GartnerまたはForresterの抜粋、ボードレベルのニュース記事。Ingestレイヤーは収集と初期正規化を行います: PDF、Webページ、トランスクリプト、構造化データを読み取り可能なテキストチャンクに変換します。
Analyze(合成) はこのパターンで最も要求の高いステップです。モデルは各ソースを独立して要約するだけではありません。すべてのソースを同時に読み取り、複数のソースが同意するものを識別し(高信頼度のシグナル)、ソースが矛盾する箇所を表面化させ(不確実性の領域)、名前付きエンティティと主要な事実を抽出し、証拠が集合的に何を言っているかの一貫した解釈を構築します。このクロスソース合成が、Generative Researchを単純なドキュメント要約と区別するものです。各ソースを個別に要約することはパターンではありません。価値は合成レイヤーにあります。完全な機能定義についてはAnalyze: AIが収集したものを理解する方法を参照してください。
Generate(レポート、ブリーフ、または構造化出力) は成果物を生成します。これは、引用付きのセクションごとのブリーフとしてフォーマットされた競合分析、CRMインサートとしてフォーマットされたアカウントリサーチカード、箇条書きと推奨アクションを含むエグゼクティブメモ、ソース脚注付きの市場規模テーブルの場合があります。Generateステップは合成されたインサイトを依頼者が必要とする出力フォーマットにフォーマットします。
このパターンはGenerateで終わることに注意してください。基本の式にはExecuteステップがありません。出力はどこかに送られる前に人間がレビューするためのドラフトです。ほとんどのGenerative Researchのユースケースでは、その人間によるレビューはオプションではありません。それがパターンを配布する上で安全にするガバナンスメカニズムです。
Key Facts: Generative Researchの影響
- McKinseyによると、生成AIは現在ナレッジワーク活動に費やされる従業員の時間の60〜70%を自動化できると推定しており、リサーチ合成が圧縮できる最も高価値のナレッジワーク活動の一つとして挙げられています(McKinsey、2023年)
- AIの支援なしでは40〜60%の通話で通話前リサーチを完了する営業担当者は、AI生成アカウントブリーフがあると通話前リサーチ完了率が85〜95%に上昇します(Forrester B2B Sales AI Benchmark、2025年)
- AI搭載の競合インテリジェンスブリーフは、手動リサーチを使用してアナリスト1人が競合1社あたり6〜8時間かける場合と比べて、20〜50のソースを2〜4時間で合成します(85〜90%の時間削減で3〜5倍のソースカバレッジ改善)(Gartner Competitive Intelligence Report、2025年)
Multi-Source Synthesis Pattern(マルチソース合成パターン)
Generative Researchのコア価値は個々のソースの要約ではありません。クロスソース合成です: 複数のソースが同意するものを見つけ(高信頼度のシグナル)、ソースが矛盾する箇所を表面化させ(不確実性の領域)、どの単一ソースも明示的に述べていないものを組み合わされた証拠が含意していることを推論します。各ソースを独立して要約してサマリーを並べて提示するGenerative Researchのデプロイはこのパターンを使用していません。パターンはすべてのソースを同時に読んで統一された解釈を生み出すAnalyzeステップを必要とします。その合成レイヤーが30のソースを一貫したブリーフに圧縮するものであり、Generative Researchを合わせてつなぎ合わせた要約のバッチから区別するものです。
Generative Research vs. RAG Assistant: 重要な区別
この2つのパターンは実際に最もよく混同されます。
RAG Assistant は管理された既知の社内ナレッジベースから回答を検索します。ナレッジベースに何があるかを知っています(製品ドキュメント、過去のサポートチケット、HRポリシー)。検索は範囲が限定されています。回答はシステム内に存在するソースを引用します。失敗モードは間違ったドキュメントを検索するかナレッジベースが古くなることです。オープンウェブからの捏造ではありません。
Generative Research は多くの場合外部の、ライブの、またはクロスドメインのコーパスから合成します。ソースはシステムに事前インデックスされていません。クエリ時にWebサーチ、APIフィード、アップロードされたドキュメント、またはサードパーティデータベースから取得されます。合成はどの単一ソースも明示的に述べていない情報を表面化させることができます: モデルは組み合わせから推論します。その推論機能は価値であるとともにリスクでもあります。
実際的な意味: RAGの出力は引用されたソースを確認することで検証できます。Generative Researchの出力は、引用されたソース(ソースは帰属された主張を実際に言っているか?)と合成ロジック(推論は耐えられるか?)の両方をスポットチェックする必要があります。異なる検証プロセス、異なるガバナンス要件。
詳細な5つの実例
1. 競合インテリジェンスレポーティング
製品VPが3つの直接競合他社の四半期競合アップデートを必要としています。各競合他社はWebサイト、G2プロファイル、アクティブなLinkedIn、最近のプレスリリース、RedditとCapterraでのいくつかのレビュー言及を持っています。これらすべてを読んで合成するには、製品アナリストが競合1社あたり6〜8時間かかります。
Ingestはこれらすべてのソースから取得します: 取得時にスクレイプしたWebページ、日付でフィルタリングされたG2レビュー、LinkedInの投稿と求人リスト、プレスリリース、ニュース言及。Analyzeはソースを相互参照します: レビュアーがG2レビューで一貫して言及しているが会社自身のWebサイトにはない機能は何か? 「エンタープライズセールス責任者」の求人は戦略的方向性について何を示唆しているか? 2つのソースが一致しない場合(あるレビューはUXが優秀と言い、別のレビューはそれを弱点としてフラグする)はどこか?
Generateは構造化されたブリーフを生成します: 四半期中の製品アップデート、ポジショニングの変化、レビューからの価格シグナル、求人リストからの人材シグナル、サードパーティソースからの主要な引用。出力は各ソースカテゴリの展開可能なセクションを含む1ページの要約としてフォーマットされます。
人間によるレビューの確認: 引用された引用は実際に引用されたソースから来ているか? 推論された戦略的結論は精査に耐えられるか?
これをサポートするツール: Perplexity API、Webサーチグラウンディング向けのTavily、サーチツール付きのClaudeとGPT-4、Crayon、Klue、Battlecardsのような専用の競合インテリジェンスプラットフォーム。
2. 営業電話前のアカウントリサーチブリーフィング
営業ディレクターが90分後に、以前話したことのない製造会社のVP of Operationsとの通話を控えています。彼女が知る必要があること: この会社で何が起きているか、最近の課題は何か、ステークホルダーは誰か、業界のコンテキストは何か。
Ingestが取得するもの: 会社の最近のプレスリリースとニュースカバレッジ(過去90日間)、見込み客のLinkedInプロファイルと最近のアクティビティ、CEOとCFOの最近の公開コメント、製造業界誌からの業界ニュース、既存のCRMデータと過去のメールスレッド。
Analyzeが表面化させるもの: サプライチェーンの優先事項を変えた最近の買収、業務の複雑さを課題として言及している見込み客のLinkedIn投稿、2026年の優先事項として「業務効率」についてのCEOの決算説明会の引用、データチームを構築していることを示唆する最近の採用パターン。
Generateが生成するもの: 主要な会社のコンテキスト(2つの箇条書き)、最近の動向(3つの箇条書き)、連絡先の背景(2つの箇条書き)、証拠に基づいた可能性の高い優先事項(ソース付き3つの箇条書き)、インテリジェンスに関連した提案の冒頭の質問。担当者は8分でレビューし、自分の知識に基づいて冒頭の質問を調整し、スクリプトとしてではなくコンテキストとしてブリーフを使用します。
このパターンはSalesforce Einsteinの「アカウントサマリー」、HubSpotのAIリサーチ機能に組み込まれており、Apollo.io の AIリサーチやWarmlyのような専用ツールのコアです。このユースケースの完全な営業固有バージョンについては、初回コンタクト前のAIアカウントリサーチを参照してください。
3. エグゼクティブ業界トレンド合成
ヘルスケアテクノロジー企業のCFOがボードミーティング前に「AIがヘルスケアの収益サイクルにどのような影響を与えているか」についての20分ブリーフを必要としています。その合成は通常、6〜8件のアナリストレポート、関連する上場企業からの3件の決算説明会トランスクリプト、数十件の業界誌の記事を読む必要があります。
IngestはGartner抜粋(利用可能な場合)、HIMSSカンファレンスカバレッジ、ヘルスIT企業の決算説明会トランスクリプト(Veeva、Epicパートナー、Waystar)、Healthcare IT NewsとHealth Data Managementの業界誌、この分野のVCの投資発表から取得します。
Analyzeはコンセンサステーマを識別します(請求審査の自動化が10のソースのうち7つで一貫してフラグされている)、新興の議論(どのAIベンダーが実際に提供しているか対約束しているか)、引用されている主要企業。また矛盾するシグナルも確認します(あるソースは管理コストを30%削減と予測し、別のアナリストレポートはそれを「楽観的」と呼んでいる)。
Generateは2ページのブリーフを生成します: 証拠を伴う3つのコンセンサストレンド、明示的にフラグされた活発な議論の2つの領域、注目すべき5つの会社、提案された応答を含む「おそらく直面する質問」セクション。CFOはこれをAI生成テキストとしてではなく、情報に基づいたコメントとして提示できます。
4. 引用ソース付きの市場規模推定
スタートアップのビジネス開発責任者が資金調達ミーティング前に新しいセグメントの概算市場規模を必要としています。TAM/SAM/SOM分析は防御可能である必要があります: 魔法の数値ではなく、VCが確認できるソース付きの追跡可能な推定値。
Ingestが取得するもの: 業界アナリストレポート、政府統計データベース(BLS、Census)、セグメントに言及している上場企業の決算説明会、その市場の仮定が含まれるスペースの最近のスタートアップ資金調達ラウンド。
Analyzeは複数のソースからの規模推定を相互参照します: あるアナリストは120億ドルのTAMと言い、競合のS-1は90億ドルを含意し、2024年のGartnerレポートは14%成長で80億ドルと言っています。方法論の違いを識別します(一方はソフトウェアのみをカウント、もう一方はサービスを含む)。防御可能な推定の範囲と各範囲を動かす前提を表面化させます。
Generateは市場規模メモを生成します: 方法論セクション、3つのシナリオ(保守的/基本/楽観的)、数値ごとのソース引用、資金調達ミーティング向けの「どう防御するか」の1段落ノート。
5. M&Aデューデリジェンスのデスクリサーチ
買収側の戦略チームが正式な関与前に対象会社についての予備的な見解を必要としています。彼らはNDAに署名する前に公的ソースのインテリジェンスのみを求めています。これはデスクリサーチであり、完全なデューデリジェンスではありませんが、徹底的である必要があります。
Ingestが取得するもの: ターゲットのWebサイトと製品ドキュメント、すべての公開プレスカバレッジ、従業員数と成長軌跡に関するLinkedInデータ(財務パフォーマンスの代理変数)、文化シグナルのためのGlassdoorレビュー、資金調達履歴と投資家名のためのCrunchbase、顧客センチメントのためのG2、関連する場合は特許申請。
Analyzeが合成するもの: 資金調達+成長シグナルからの収益範囲推定、LinkedInとGlassdoorからのチーム品質とChurnシグナル、公開資料とレビューからの製品差別化評価、スペース内の他の買収のコンテキストでの競合ポジショニング。
Generateは戦略チームが使用するフォーマットのデューデリジェンスメモを生成します: ビジネス概要、信頼度レベル付きの財務推定、チーム評価、製品評価、リスクフラグ、正式なデューデリジェンスプロセスへのオープンな質問。
失敗モード: Generative Researchを壊すもの
| 失敗モード | 根本原因 | 軽減策 |
|---|---|---|
| 作り話(Confabulation) | モデルが実際にはどのソースも支持していない、もっともらしく聞こえる主張で実際のソース間のギャップを埋める | 主張ごとに引用を要求する。配布前にブリーフごとに3〜5件の引用をスポットチェックする。ソースを確認した指名された人間のレビュアーなしには絶対に回覧しない。 |
| ソースの現在性の遅れ | Webサーチインデックスは2〜3日遅れ; 社内ドキュメント合成は最後のインデックス実行と同程度にしか新鮮でない | 出力にクロールまたはインデックスのタイムスタンプを含める。時間に敏感な主張にソースの日付でフラグを立てる。ライブの競合または市場インテリジェンスには、主要な主張を直接確認する。 |
| コンフリクトするソースが統一されたものとして提示される | モデルがソースが一致しない場合に異議を立てずに1つの解釈を選択する | 明示的なコンフリクトの表面化を促す: 「ソースがこのトピックで一致しない場合は、異議をフラグして両方の側を引用してください。」すべてをコンセンサスとして提示するブリーフは疑って扱う。 |
| 引用のロンダリング(Citation Laundering) | モデルがそのソースが実際には行っていない主張に対して実際の信頼できるソースを引用する | 引用をスポットチェックする: ソースが存在するだけでなく、引用されたパッセージが帰属された主張を支持しているかも確認する。これは権威があるように見えるため最も陰険な失敗モードです。 |
| スコープのドリフト | 開放型のプロンプトが包括的だが使用不能な40ページの出力を生み出す | スコープを正確に定義する: 時間範囲、ソースタイプ、出力フォーマット、文字数制限。より狭いプロンプトは広いものより有用な出力を生み出します。 |
| 単一ソースのバイアス | 1つの支配的な高品質ソースが合成を圧倒し、出力が1つの視点を反映し、マルチソースビューにならない | 出力のソース分布を確認する。引用の80%が1つのソースを指している場合、合成は機能していません。 |
Citation Launderingは権威あるように見える出力を生み出すため、最も陰険な失敗モードです。そのレポートが実際には行っていない主張に対して実際のGartnerレポートを引用するブリーフは、カジュアルなレビューを通過しますが精査には失敗します。Stanford HAIの2024年の引用精度に関するトップLLMの評価では、長形式の合成タスクでAI生成引用の23%が、帰属された主張を含まないソースを引用したか、ソースのポジションを少し誤って表現したかのどちらかだったと発見しました。これはGenerative Researchを使用不能にするものではありません。配布前の15分間の人間によるレビューを交渉不可能にするものです。
Confabulationは、最も信頼を損なう失敗モードであるため、直接的な注意に値します。引用されたソースが実際には行っていない1つの自信を持って引用された主張を含むGenerative Researchブリーフは、発見されると、その特定のブリーフだけでなくパターン全体への信頼を破壊します。OpenAIのGPT-4に関する研究はこれを直接認めています: 高性能モデルでも、もっともらしく聞こえるが不正確なコンテンツを生み出すことがあり、これがモデルの品質に関わらず引用の検証が人間の責任である理由です。軽減策はパターンを避けることではありません。配布前にワークフローに検証を組み込むことです。これが他のGenerate中心のパターンの失敗モードとどのように比較されるかについてはAIパターン別ハルシネーションリスクを参照してください。
信頼モデル: 検証はオプションではない
RAG Assistantパターンは比較的限定された信頼モデルの恩恵を受けます。ナレッジベースはあなたのものです。ソースは既知です。回答が間違っている場合、ソースが間違っており、ソースを修正できます。
Generative Researchは外部の、ライブの、クロスドメインのソースから引用します。合成はどの個別のソースも明示的に支持していない推論を生み出すことができます。それが価値です。しかし信頼モデルが明示的でなければならない理由でもあります。
Generative Researchの出力が配布される前に、指名された人間のレビュアーは:
- 要約だけでなく完全なドキュメントとして出力を読む
- 3〜5件の引用をスポットチェックし、ソースが存在し、帰属された主張が実際にソースにあることを確認する
- 証拠基盤を考えると誇張に感じるコンセンサス主張をフラグする
- ソースが矛盾した箇所(AIがまだフラグしていない場合)にマークする
- レビューを行うアナリストとしてドキュメントに自分の名前を追加する
このレビューは、よくフォーマットされたブリーフで15〜30分かかります。元の6〜8時間のリサーチ作業とは同じではありません。それが生産性向上です。しかし15分のレビューはオプションではありません。
よくある失敗: チームがGenerative Researchをデプロイし、出力が「問題ないように見える」ため最初の6ヶ月後にスポットチェックを止めます。その後、捏造された統計を含むブリーフがボードプレゼンテーションに届きます。修正はスポットチェックをオプションのレビューではなく、文書化されたワークフローステップにすることです。
Generative Researchが機能するとき(しないとき)
うまく機能する場合:
- 質問に定義されたスコープがある。「競合他社XはQ1 2026年に何を発表したか?」はスコープが定まっています。「競合他社Xについてすべて教えてください」は違います。
- ソースが利用可能でアクセス可能である。上場企業、市場リサーチ、競合インテリジェンスでは、公開ソースは通常リッチです。非上場企業や新興市場では、ソースの品質が落ちます。
- 出力は配布前にレビューされる。これはテクノロジーに対する信頼の問題ではありません。決定を知らせる任意のリサーチ出力に対するワークフロー要件です。
- ニーズは合成であり、特定の事実の検索ではない。「Acme CorpのARRは何か?」が必要な場合、それは単一の権威あるソースが合成より良い事実検索です。「公開シグナルからAcme Corpの成長軌跡について何が推論できるか?」が必要な場合、それは合成です。
vs. RAG Assistant: RAGは既知の質問に答える社内ナレッジベースです。Generative Researchは外部またはクロスドメインのソースから新しいインサイトを生み出す合成です。よく一緒に使われます: 外部ソースからインテリジェンスブリーフを構築するためのGenerative Research、過去のブリーフと通話ノートから「このアカウントについて何を学んだか?」に答えるためのRAG Assistant。
vs. Document Review: Document Reviewは特定のドキュメントを取得し、既知の標準またはテンプレートと照合します。Generative Researchは多くのドキュメントを取得し、それらから新しい出力を合成します。区別: 1つのドキュメント対多くのソース; コンプライアンスチェック対インサイト合成。
vs. Meeting Intelligence: Meeting Intelligenceは自分自身の会話の録音を処理します。Generative Researchは外部資料から引用します。組み合わせることができます: Meeting Intelligenceが自分自身の顧客会話をキャプチャし、Generative Researchが外部の市場コンテキストを合成し、戦略家が両方を組み合わせて完全なアカウントビューを作成します。
ROIシグナル: 影響の測定
| 指標 | 手動のベースライン | Generative Research使用時 | 典型的な改善 |
|---|---|---|---|
| ブリーフあたりのアナリスト時間 | 完全な競合ブリーフに4〜8時間 | 30〜60分(AI + レビュー) | 85〜90%の時間削減 |
| リクエストから成果物までの時間 | 1〜3日(バックログ + 執筆時間) | 2〜4時間(当日の納品) | 80〜90%のサイクルタイム削減 |
| ブリーフあたりのソースカバレッジ | 5〜10件のソース(1人のアナリストの現実的な上限) | 20〜50件のソース(AI合成の上限は広い) | 3〜5倍のカバレッジ改善 |
| ブリーフの頻度 | トピックごとに月1回の包括的なブリーフ | 週次ブリーフが実現可能になる | 4〜6倍のリズム改善 |
| 通話前リサーチ完了率 | 営業電話の40〜60%に何らかの通話前リサーチがある | 自動アカウントブリーフ生成で85〜95% | 40〜50%の改善 |
通話前リサーチ完了率は多くの場合最も追跡しやすい指標であり、パイプラインの成果に直接つながります。担当者がブリーフを持って通話に臨む場合、通話の品質が向上します。McKinseyのB2B営業におけるAIに関する調査では、アカウントリサーチと通話前準備が営業リーダーにとって最も興奮度が高いAIのユースケースの中にあると発見しています。ブリーフが完璧だからではなく、コンテキストを持つことで冒頭が「会社について教えてください」から「あなたが先ほどオースティンに新しいオフィスを開設したのを見ました。決算説明会で言及されていた拡大の取り組みと関連していますか?」に変わるからです。
Rework分析: 成功するGenerative Researchの導入に共通するものが1つあります: すべてのブリーフが配布される前に15分のスポットチェックを所有する指名されたレビュアーです。リサーチブリーフを信頼できるものにするのはAIではありません。ドキュメントにあるレビュアーの名前です。スピードのためにこのステップをスキップするチームは最終的に、捏造された統計を含むブリーフをボード、クライアント、または投資家に回覧します。それが起きると、その特定のブリーフだけでなくプログラム全体への信頼が崩壊します。レビュアーの仕事はリサーチを繰り返すことではありません。3〜5件の引用を確認し、証拠基盤を考えると過信に感じる主張をフラグすることです。10ページのブリーフで15〜30分かかります。潜在的に危険な出力を信頼できる成果物に変換します。それより低いコストでより高いROIを提供するガバナンスコントロールは他にありません。
よくある質問
Generative Research AIパターンとは何ですか?
Generative Researchは複数のソースを一貫したリサーチ出力に合成するAIパターンです。式は: Ingest(マルチソースコーパス)、Analyze(コンセンサスシグナル、コンフリクト、推論を識別するクロスソース合成)、Generate(構造化レポート、ブリーフ、または分析)です。管理された社内ナレッジベースではなく、外部の、ライブの、またはクロスドメインのソースから引用し、ソースの組み合わせから新しい推論を生み出す点でRAG Assistantとは異なります。
Multi-Source Synthesis Pattern(マルチソース合成パターン)とは何ですか?
Multi-Source Synthesis Patternは Generative Research の定義的な機能です: 複数のソースを同時に読んで、それらが集合的に同意するものを見つけ、どこで矛盾しているかを表面化させ、どの単一ソースも述べていないものを組み合わされた証拠が含意していることを推論します。各ソースを独立して要約するデプロイはこのパターンを使用していません。合成レイヤーが30のソースを一貫したブリーフに圧縮するものであり、Generative Researchを合わせてつなぎ合わせたドキュメントサマリーのバッチから区別するものです。
Generative ResearchはRAG Assistantとどう違いますか?
RAG Assistantはあなたが所有する管理された社内ナレッジベースから回答を検索します。Generative Researchはクエリ時に外部の、ライブの、またはクロスドメインのソースから合成します。信頼モデルが異なります: RAGの出力は引用された社内ソースを確認することで検証できます。Generative Researchの出力は、引用された外部ソースが帰属された主張を実際に支持しているか、合成された推論が精査に耐えられるかを確認する必要があります。配布前の15分間の人間によるレビューは、RAGよりもGenerative Researchにとってより重要なガバナンス要件です。
AIリサーチにおけるCitation Laundering(引用のロンダリング)とは何ですか?
Citation Launderingは、AIモデルがそのソースが実際には行っていない主張に対して実際の信頼できるソースを引用するときに発生します。Stanford HAIの2024年の評価では、長形式の合成タスクにおけるAI生成引用の23%が、帰属された主張を含まないソースを引用したか、ソースのポジションを誤って表現したかのどちらかだったと発見しました。これは権威あるように見え、カジュアルなレビューを通過しますが精査には失敗する出力を生み出します。軽減策は配布前にブリーフごとに3〜5件の引用をスポットチェックすることです。
Generative Researchからどのような ROI を期待すべきですか?
競合ブリーフあたりのアナリスト時間が4〜8時間から30〜60分に削減(85〜90%の時間削減)。ブリーフあたりのソースカバレッジが5〜10件から20〜50件に改善(3〜5倍の改善)。営業担当者の通話前リサーチ完了率が40〜60%から85〜95%に上昇。ブリーフの頻度が4〜6倍改善(月次が以前の上限だったところで週次ブリーフが実現可能になる)。通話前リサーチ完了率は最も追跡しやすい指標であり、パイプラインの成果に直接つながります。
最も一般的なGenerative Researchの失敗モードは何ですか?
6つの主な失敗モードは、作り話(どのソースも支持していないもっともらしく聞こえる主張)、Citation Laundering(ソースが行っていない主張に対して引用された実際のソース)、ソースの現在性の遅れ(インデックスが数日遅れ)、コンフリクトするソースが統一されたコンセンサスとして提示される、スコープのドリフト(使用不能な出力を生み出す広すぎるプロンプト)、単一ソースのバイアス(合成を圧倒する1つの支配的なソース)です。Citation Launderingは権威あるように見えるため最も陰険です。Confabulationは発見されると信頼に最も損害を与えます。
参考リンク

Co-Founder, Rework.com
On this page
- 機能の式: Ingest、Analyze、Generate
- Multi-Source Synthesis Pattern(マルチソース合成パターン)
- Generative Research vs. RAG Assistant: 重要な区別
- 詳細な5つの実例
- 1. 競合インテリジェンスレポーティング
- 2. 営業電話前のアカウントリサーチブリーフィング
- 3. エグゼクティブ業界トレンド合成
- 4. 引用ソース付きの市場規模推定
- 5. M&Aデューデリジェンスのデスクリサーチ
- 失敗モード: Generative Researchを壊すもの
- 信頼モデル: 検証はオプションではない
- Generative Researchが機能するとき(しないとき)
- ROIシグナル: 影響の測定
- 参考リンク