Generative Research: Comprimiendo Horas de Lectura
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Un buen analista puede sintetizar 30 fuentes en un brief coherente. Sabe qué fuentes son confiables, cuáles ponderar con cautela, cómo mostrar la tensión cuando dos fuentes creíbles no están de acuerdo, y cómo hacer que el resultado sea legible para un VP que tiene ocho minutos antes de una reunión de junta.
La mayoría de los equipos no puede costear suficientes analistas para hacer esto bien, de manera consistente, para cada mercado, cuenta y competidor que les importa. La investigación de cuenta antes de una llamada de ventas se omite. El informe de inteligencia competitiva tiene tres semanas de retraso cuando se usa. La due diligence sobre un posible objetivo de adquisición es superficial porque nadie tuvo tiempo de profundizar.
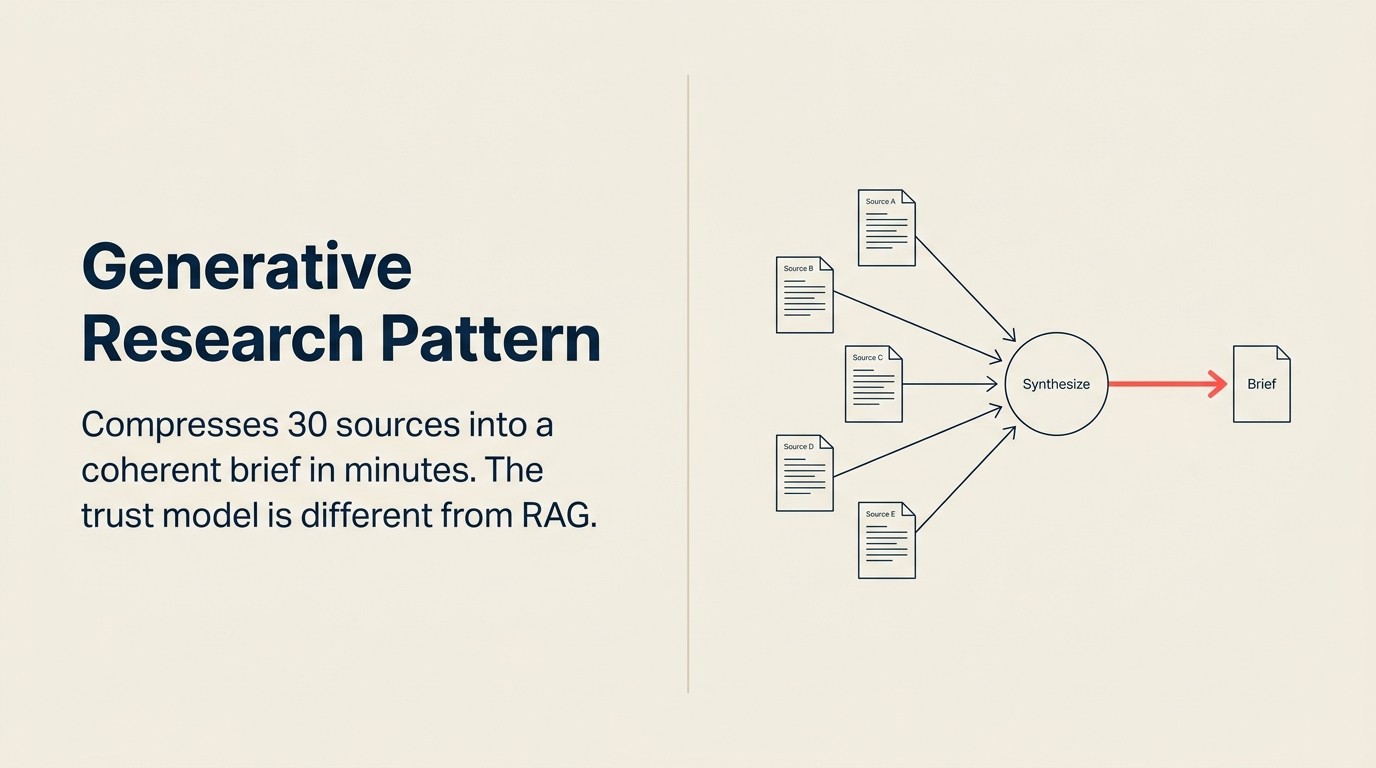
Generative Research es el patrón de IA que comprime este trabajo de síntesis a minutos. No eliminando el análisis, sino automatizando la lectura, la verificación cruzada y la estructuración inicial que consume la mayor parte del tiempo de un analista. El juicio del analista sigue importando al final. Pero el analista comienza desde un brief de 10 páginas en lugar de 30 pestañas del navegador.
El patrón viene con una pregunta de confianza que su patrón hermano, el RAG Assistant, no tiene. RAG recupera de una base de conocimiento conocida y controlada. Generative Research recorre fuentes en vivo, externas o entre dominios. Esa diferencia cambia cómo luce la verificación y dónde se agrupan los failure modes.
La fórmula: Ingest, Analyze, Generate
Ingest (corpus de múltiples fuentes) extrae el material fuente. Las fuentes dependen del caso de uso. Para inteligencia competitiva: comunicados de prensa, reseñas de G2 y Capterra, ofertas de trabajo en LinkedIn, grabaciones de conferencias, transcripciones de earnings calls, artículos de prensa especializada. Para investigación de cuentas: noticias recientes de la empresa objetivo, perfiles de LinkedIn del liderazgo, informes de analistas de la industria, anuncios de financiación recientes, menciones de competidores. Para síntesis de tendencias ejecutivas: transcripciones de earnings calls de 10-20 empresas públicas del sector, extractos de Gartner o Forrester, artículos de noticias a nivel de junta. La capa Ingest hace la recopilación y la normalización inicial: convirtiendo PDFs, páginas web, transcripciones y datos estructurados en fragmentos de texto legibles.
Analyze (sintetizar) es el paso más exigente en este patrón. El modelo no solo resume cada fuente de forma independiente. Lee todas las fuentes simultáneamente, identifica en qué coinciden múltiples fuentes (señales de alta confianza), muestra dónde las fuentes están en conflicto (áreas de incertidumbre), extrae entidades nombradas y hechos clave, y construye una interpretación coherente de lo que la evidencia dice colectivamente. Esta síntesis cruzada entre fuentes es donde Generative Research difiere de la simple summarización de documentos. Resumir cada fuente por separado no es el patrón. El valor está en la capa de síntesis. Vea Analyze: cómo la IA da sentido a lo que ha recopilado para la definición completa de la capacidad.
Generate (informe, brief o salida estructurada) produce el entregable. Puede ser un análisis competitivo formateado como un brief sección por sección con citas, una tarjeta de investigación de cuenta formateada para inserción en CRM, un memorando ejecutivo con puntos clave y una acción recomendada, o una tabla de dimensionamiento de mercado con notas al pie de fuentes. El paso Generate formatea el insight sintetizado en el formato de salida que necesita el solicitante.
Tenga en cuenta que este patrón termina en Generate. No hay paso Execute en la fórmula base. La salida es un borrador para que un humano lo revise antes de que vaya a cualquier parte. Para la mayoría de los casos de uso de Generative Research, esa revisión humana no es opcional. Es el mecanismo de gobernanza que hace que el patrón sea seguro de distribuir.
Key Facts: Impacto de Generative Research
- McKinsey estima que la IA generativa puede automatizar el 60-70% del tiempo de los empleados actualmente dedicado a actividades de trabajo del conocimiento, citando la síntesis de investigación como una de las actividades de mayor valor que puede comprimir (McKinsey, 2023)
- Los representantes de ventas completan la investigación previa a la llamada en el 40-60% de las llamadas sin asistencia de IA; con briefs de cuenta generados por IA, las tasas de completación de investigación previa a la llamada suben al 85-95% (Forrester B2B Sales AI Benchmark, 2025)
- Los briefs de inteligencia competitiva impulsados por IA sintetizan 20-50 fuentes en 2-4 horas versus 6-8 horas por analista por competidor en investigación manual, una mejora de cobertura de fuentes de 3-5x con una reducción de tiempo del 85-90% (Gartner Competitive Intelligence Report, 2025)
El Patrón de Síntesis Multi-Fuente
El valor central de Generative Research no es la summarización de fuentes individuales. Es la síntesis entre fuentes: encontrar en qué coinciden múltiples fuentes (señales de alta confianza), mostrar dónde las fuentes están en conflicto (áreas de incertidumbre) e inferir lo que la evidencia combinada implica más allá de lo que cualquier fuente individual establece explícitamente. Un despliegue de Generative Research que resume cada fuente de forma independiente y presenta los resúmenes uno al lado del otro no está usando este patrón. El patrón requiere un paso Analyze que lea todas las fuentes simultáneamente y produzca una interpretación unificada. Esa capa de síntesis es lo que comprime 30 fuentes en un brief coherente, y es lo que separa Generative Research de un conjunto de resúmenes cosidos juntos.
Generative Research vs. RAG Assistant: la distinción crítica
Estos dos patrones son los más frecuentemente confundidos en la práctica.
RAG Assistant recupera respuestas de una base de conocimiento interna controlada y conocida. Usted sabe qué hay en la base de conocimiento (la documentación de su producto, tickets de soporte pasados, políticas de RR.HH.). La recuperación está acotada. Las respuestas citan fuentes que existen en su sistema. El failure mode es recuperar el documento incorrecto o que la base de conocimiento esté desactualizada. No la fabricación desde la web abierta.
Generative Research sintetiza desde un corpus que a menudo es externo, en vivo o entre dominios. Las fuentes no están pre-indexadas en su sistema. Se extraen en el momento de la consulta desde búsquedas web, feeds de API, documentos cargados o bases de datos de terceros. La síntesis puede mostrar información que ninguna fuente individual establece explícitamente: el modelo infiere de la combinación. Esa capacidad de inferencia es tanto el valor como el riesgo.
La implicación práctica: los resultados de RAG pueden verificarse comprobando la fuente citada. Los resultados de Generative Research requieren verificar tanto la fuente citada (¿la fuente realmente dice lo que se le atribuye?) como la lógica de síntesis (¿se sostiene la inferencia?). Proceso de verificación diferente, requisito de gobernanza diferente.
Cinco ejemplos reales en profundidad
1. Informes de inteligencia competitiva
Un VP de Producto necesita una actualización competitiva trimestral sobre tres competidores directos. Cada competidor tiene un sitio web, un perfil en G2, un LinkedIn activo, comunicados de prensa recientes y un puñado de menciones de reseñas en Reddit y Capterra. Leer y sintetizar manualmente todo eso le toma a un analista de producto 6-8 horas por competidor.
Ingest extrae de todas estas fuentes: páginas web capturadas en el momento de la extracción, reseñas de G2 filtradas por fecha, publicaciones y ofertas de trabajo en LinkedIn, comunicados de prensa y menciones de noticias. Analyze hace la verificación cruzada de las fuentes: ¿qué características mencionan consistentemente los reviewers en G2 que no están en el propio sitio web de la empresa? ¿Qué señala la oferta de trabajo para "Head of Enterprise Sales" sobre su dirección estratégica? ¿Dónde están en conflicto dos fuentes (una reseña llama al UX excelente; otra lo señala como una debilidad)?
Generate produce un brief estructurado: actualizaciones del producto en el trimestre, cambios de posicionamiento, señales de precios de reseñas, señales de talento de ofertas de trabajo y citas clave de fuentes de terceros. La salida está formateada como un resumen de una página con secciones expandibles para cada categoría de fuente.
La revisión humana comprueba: ¿las citas realmente provienen de las fuentes citadas? ¿Se sostienen las conclusiones estratégicas inferidas bajo escrutinio?
Herramientas que lo apoyan: Perplexity API, Tavily para búsqueda web con grounding, Claude y GPT-4 con herramientas de búsqueda, y plataformas de inteligencia competitiva de propósito específico como Crayon, Klue y Battlecards.
2. Brief de investigación de cuenta antes de una llamada de ventas
Una directora de ventas tiene una llamada en 90 minutos con un VP de Operaciones de una empresa manufacturera con la que no ha hablado antes. Necesita saber: qué está pasando en esta empresa, cuáles son sus desafíos recientes, quiénes son los stakeholders y cuál es el contexto de la industria.
Ingest extrae: los comunicados de prensa recientes y la cobertura de noticias de la empresa (últimos 90 días), el perfil de LinkedIn del prospecto y su actividad reciente, los comentarios públicos recientes del CEO y CFO, noticias de la industria de publicaciones especializadas de manufactura, y cualquier dato existente en CRM e hilos de correos pasados.
Analyze muestra: una adquisición reciente que cambió sus prioridades de cadena de suministro, una publicación en LinkedIn del prospecto mencionando la complejidad operativa como un desafío, una cita de earnings call del CEO sobre "eficiencia operativa" como prioridad para 2026, y un patrón en contrataciones recientes que sugiere que están construyendo un equipo de datos.
Generate produce un brief pre-llamada de dos páginas: contexto clave de la empresa (2 puntos), desarrollos recientes (3 puntos), antecedentes del contacto (2 puntos), prioridades probables basadas en evidencia (3 puntos con fuentes) y preguntas de apertura sugeridas vinculadas a la inteligencia. El representante revisa en 8 minutos, ajusta la pregunta de apertura según su propio conocimiento y usa el brief como contexto en lugar de como guión.
Este patrón está integrado en los "resúmenes de cuenta" de Salesforce Einstein, las funciones de investigación de IA de HubSpot, y es el núcleo de herramientas de propósito específico como la investigación de IA de Apollo.io y Warmly. Para la versión completa específica de ventas de este caso de uso, vea investigación de cuenta con IA antes del primer contacto.
3. Síntesis ejecutiva de tendencias de la industria
Un CFO en una empresa de tecnología de salud quiere un brief de 20 minutos antes de una reunión de junta sobre "dónde la IA está afectando los ciclos de ingresos de salud". Esa síntesis normalmente requiere leer 6-8 informes de analistas, 3 transcripciones de earnings calls de empresas públicas relevantes y una docena de artículos de prensa especializada.
Ingest extrae de extractos de Gartner (si están disponibles), cobertura de la conferencia HIMSS, transcripciones de earnings calls de empresas de HIT (Veeva, socios de Epic, Waystar), prensa especializada de Healthcare IT News y Health Data Management, y anuncios de inversión de VC en el espacio.
Analyze identifica los temas de consenso (la automatización de la adjudicación de reclamaciones se señala consistentemente en 7 de 10 fuentes), los debates emergentes (qué proveedores de IA realmente están entregando vs. prometiendo) y las empresas clave que se citan. También verifica señales contradictorias (una fuente proyecta una reducción del 30% en costos administrativos; otro informe de analistas lo llama "optimista").
Generate produce un brief de dos páginas: tres tendencias de consenso con evidencia, dos áreas de desacuerdo activo marcadas explícitamente, cinco empresas que vale la pena observar y una sección de "preguntas que probablemente enfrentará" con respuestas sugeridas. El CFO puede presentar esto como comentario informado, no como texto generado por IA.
4. Dimensionamiento de mercado con fuentes citadas
El Head of Business Development de una startup necesita un dimensionamiento de mercado aproximado para un nuevo segmento antes de una reunión de fundraise. El análisis TAM/SAM/SOM debe ser defendible: no un número mágico, sino una estimación trazable con fuentes que un VC pueda verificar.
Ingest extrae: informes de analistas de la industria, bases de datos estadísticas gubernamentales (BLS, Census), earnings calls de empresas públicas que mencionan el segmento, y rondas recientes de financiación de startups en el espacio con sus supuestos implícitos de mercado.
Analyze hace la verificación cruzada de las estimaciones de dimensionamiento de múltiples fuentes: un analista dice $12B de TAM, el S-1 de un competidor implica $9B, un informe de Gartner de 2024 dijo $8B creciendo al 14%. Identifica las diferencias metodológicas (uno cuenta solo software; otro incluye servicios). Muestra el rango de estimaciones defendibles y los supuestos que impulsan cada una.
Generate produce un memorando de dimensionamiento de mercado: sección de metodología, tres escenarios (conservador/base/optimista), citas de fuentes por número y un párrafo de "cómo defender esto" para la reunión de fundraise.
5. Investigación de escritorio de due diligence en M&A
El equipo de estrategia de un adquirente necesita una perspectiva preliminar sobre una empresa objetivo antes del compromiso formal. Quieren inteligencia de fuentes públicas únicamente, antes de haber firmado un NDA. Esta es una investigación de escritorio, no una due diligence completa, pero debe ser exhaustiva.
Ingest extrae: el sitio web y la documentación del producto del objetivo, toda la cobertura de prensa pública, datos de LinkedIn sobre el número de empleados y la trayectoria de crecimiento (un indicador proxy del rendimiento financiero), reseñas de Glassdoor para señales de cultura, Crunchbase para el historial de financiación y los nombres de inversores, G2 para el sentimiento del cliente, y patentes si son relevantes.
Analyze sintetiza: estimación del rango de ingresos a partir de señales de financiación y crecimiento, calidad del equipo y señales de churn de LinkedIn y Glassdoor, evaluación de diferenciación del producto a partir de materiales y reseñas públicas, posicionamiento competitivo en el contexto de otras adquisiciones en el espacio.
Generate produce un memorando de due diligence en el formato que usa el equipo de estrategia: resumen del negocio, estimaciones financieras con niveles de confianza, evaluación del equipo, evaluación del producto, señales de riesgo y preguntas abiertas para el proceso de diligencia formal.
Failure modes: qué rompe Generative Research
| Failure mode | Causa raíz | Mitigación |
|---|---|---|
| Confabulación | El modelo llena los huecos entre fuentes reales con afirmaciones que suenan plausibles pero que ninguna fuente realmente respalda | Requerir citas por afirmación. Verificar 3-5 citas por brief antes de distribuir. Nunca circular sin un revisor humano nombrado que haya comprobado las fuentes. |
| Retraso en la actualidad de las fuentes | El índice de búsqueda web tiene 2-3 días de retraso; la síntesis de documentos internos es tan actualizada como la última ejecución del índice | Incluir marcas de tiempo de rastreo o indexación en la salida. Marcar las afirmaciones sensibles al tiempo con su fecha de fuente. Para inteligencia competitiva o de mercado en vivo, verificar las afirmaciones clave directamente. |
| Fuentes en conflicto presentadas como unificadas | El modelo selecciona una interpretación cuando las fuentes no están de acuerdo, sin marcar el desacuerdo | Indicar el surgimiento explícito del conflicto: "Si las fuentes no están de acuerdo en este tema, marca el desacuerdo y cita ambos lados." Tratar con sospecha cualquier brief que presente todo como consenso. |
| Lavado de citas | El modelo cita una fuente real y creíble para una afirmación que esa fuente no hace realmente | Verificar citas: no solo que la fuente exista, sino que el pasaje citado respalde la afirmación atribuida. Este es el failure mode más insidioso porque parece autoritativo. |
| Deriva de alcance | Los prompts de final abierto producen salidas de 40 páginas que son comprehensivas pero inutilizables | Definir el alcance con precisión: rango de tiempo, tipos de fuentes, formato de salida y límite de palabras. Los prompts más acotados producen salidas más útiles que los amplios. |
| Sesgo de fuente única | Una fuente dominante y de alta calidad abruma la síntesis; la salida refleja una perspectiva, no una visión de múltiples fuentes | Verificar la distribución de fuentes en la salida. Si el 80% de las citas apuntan a una fuente, la síntesis no está haciendo su trabajo. |
El lavado de citas es el failure mode más insidioso porque produce salidas que parecen autoritativas. Un brief que cita un informe real de Gartner para una afirmación que ese informe no hace realmente pasará una revisión casual y fallará bajo escrutinio. La evaluación del Stanford HAI de 2024 sobre LLMs líderes en precisión de citas encontró que el 23% de las citas generadas automáticamente en tareas de síntesis de larga extensión o bien citaban una fuente que no contenía la afirmación atribuida o representaban erróneamente la posición de la fuente. Esto no hace que Generative Research sea inutilizable. Hace que la revisión humana de 15 minutos sea innegociable.
La confabulación merece atención directa porque es el failure mode que crea el mayor daño a la confianza. Un brief de Generative Research que contiene una afirmación citada con confianza que la fuente citada no hace realmente, cuando se descubre, destruirá la confianza en el brief completo y en el patrón más ampliamente. La investigación de OpenAI sobre GPT-4 reconoce esto directamente: incluso los modelos de alta capacidad pueden producir contenido que suena plausible pero es inexacto, por lo que la verificación de citas sigue siendo una responsabilidad humana independientemente de la calidad del modelo. La mitigación no es evitar el patrón. Es incorporar la verificación al flujo de trabajo antes de la distribución. Vea riesgo de alucinación por patrón de IA para saber cómo esto se compara con los failure modes en otros patrones con uso intensivo de Generate.
El modelo de confianza: la verificación no es opcional
El patrón RAG Assistant se beneficia de un modelo de confianza relativamente acotado. La base de conocimiento es suya. Las fuentes son conocidas. Si una respuesta es incorrecta, la fuente es incorrecta, y usted puede corregir la fuente.
Generative Research extrae de fuentes externas, en vivo y entre dominios. La síntesis puede producir inferencias que ninguna fuente individual respalda explícitamente. Ese es el valor. Pero también es por qué el modelo de confianza debe ser explícito.
Antes de que cualquier salida de Generative Research se distribuya, un revisor humano nombrado debe:
- Leer la salida como un documento completo, no solo el resumen
- Verificar 3-5 citas, comprobando que la fuente exista y que la afirmación atribuida esté realmente en la fuente
- Marcar cualquier afirmación de consenso que parezca exagerada dado su base de evidencia
- Señalar cualquier sección donde las fuentes estuvieran en conflicto (si no está ya marcado por la IA)
- Agregar su nombre al documento como analista revisor
Esta revisión toma 15-30 minutos para un brief bien formateado. No es lo mismo que el trabajo de investigación original de 6-8 horas. Esa es la ganancia de productividad. Pero la revisión de 15 minutos no es opcional.
El fallo común: los equipos despliegan Generative Research y dejan de hacer verificaciones al azar después de los primeros seis meses porque los resultados "parecen correctos". Luego un brief con una estadística fabricada llega a una presentación de junta. La solución es convertir la verificación al azar en un paso documentado del flujo de trabajo, no en una revisión opcional.
Cuándo funciona Generative Research (y cuándo no)
Funciona bien cuando:
- La pregunta tiene un alcance definido. "¿Qué anunció el Competidor X en el Q1 2026?" está acotado. "Cuéntame todo sobre el Competidor X" no lo está.
- Las fuentes están disponibles y son accesibles. Para empresas públicas, investigación de mercado e inteligencia competitiva, las fuentes públicas suelen ser ricas. Para empresas privadas o mercados emergentes, la calidad de las fuentes cae.
- La salida será revisada antes de la distribución. Esto no es una cuestión de confianza en la tecnología. Es un requisito del flujo de trabajo para cualquier salida de investigación que informe decisiones.
- La necesidad es de síntesis, no de una búsqueda factual específica. Si necesita "¿cuál es el ARR de Acme Corp?", eso es una búsqueda factual donde una sola fuente autoritativa es mejor que la síntesis. Si necesita "¿qué podemos inferir sobre la trayectoria de crecimiento de Acme Corp a partir de señales públicas?", eso es síntesis.
vs. RAG Assistant: RAG es su base de conocimiento interna respondiendo preguntas conocidas. Generative Research es síntesis de fuentes externas o entre dominios que produce nuevo insight. A menudo se usan juntos: Generative Research para construir briefs de inteligencia a partir de fuentes externas, RAG Assistant para responder "¿qué hemos aprendido sobre esta cuenta?" a partir de briefs pasados y notas de llamadas.
vs. Document Review: Document Review toma un documento específico y lo verifica contra un estándar o plantilla conocida. Generative Research toma muchos documentos y sintetiza una nueva salida de ellos. La distinción: un documento vs. muchas fuentes; verificación de cumplimiento vs. síntesis de insight.
vs. Meeting Intelligence: Meeting Intelligence procesa sus propias grabaciones de conversaciones. Generative Research extrae de material externo. Pueden combinarse: Meeting Intelligence captura sus propias conversaciones con clientes, Generative Research sintetiza el contexto del mercado externo, y un estratega combina ambos para una vista completa de la cuenta.
Señales de ROI: midiendo el impacto
| Métrica | Baseline manual | Con Generative Research | Mejora típica |
|---|---|---|---|
| Horas de analista por brief | 4-8 horas para un brief competitivo completo | 30-60 minutos (IA + revisión) | Reducción de tiempo del 85-90% |
| Tiempo desde solicitud hasta entregable | 1-3 días (backlog + tiempo de redacción) | 2-4 horas (entrega el mismo día) | Reducción del tiempo de ciclo del 80-90% |
| Cobertura de fuentes por brief | 5-10 fuentes (límite práctico para un analista) | 20-50 fuentes (el límite de síntesis de IA es más amplio) | Mejora de cobertura de 3-5x |
| Frecuencia del brief | 1 brief exhaustivo por mes por tema | Los briefs semanales se vuelven factibles | Mejora de cadencia de 4-6x |
| Tasa de completación de investigación pre-llamada | El 40-60% de las llamadas de ventas tiene alguna investigación pre-llamada | 85-95% con generación automática de briefs de cuenta | Mejora del 40-50% |
La tasa de completación de investigación pre-llamada suele ser la métrica más fácil de rastrear, y se conecta directamente con los resultados del pipeline. Cuando los representantes entran a las llamadas con un brief, la calidad de la llamada mejora. La investigación de McKinsey sobre IA en ventas B2B encuentra que la investigación de cuentas y la preparación pre-llamada son algunos de los casos de uso de IA de mayor entusiasmo para los líderes de ventas, precisamente porque la ganancia de productividad es medible e inmediata. No porque el brief sea perfecto, sino porque tener contexto cambia la apertura de "cuénteme sobre su empresa" a "vi que acaban de abrir una nueva oficina en Austin. ¿Está relacionado con el impulso de expansión que mencionaron en su earnings call?"
Rework Analysis: Los despliegues de Generative Research que tienen éxito tienen una cosa en común: un revisor nombrado que es responsable de la verificación al azar de 15 minutos antes de que cada brief se distribuya. No es la IA lo que hace que un brief de investigación sea confiable. Es el nombre del revisor en el documento. Los equipos que omiten este paso en favor de la velocidad eventualmente hacen circular un brief con una estadística fabricada a una junta, un cliente o un inversor. Cuando eso sucede, la confianza en todo el programa colapsa, no solo en el brief específico. El trabajo del revisor no es repetir la investigación. Es verificar 3-5 citas y marcar cualquier afirmación que parezca demasiado segura dado su base de evidencia. Eso toma 15-30 minutos para un brief de 10 páginas. Convierte un resultado potencialmente peligroso en un entregable confiable. Ningún otro control de gobernanza entrega más ROI a menor costo.
Preguntas Frecuentes
¿Qué es el patrón de IA Generative Research?
Generative Research es un patrón de IA que sintetiza múltiples fuentes en un resultado de investigación coherente. La fórmula es: Ingest (corpus de múltiples fuentes), Analyze (síntesis entre fuentes que identifica señales de consenso, conflictos e inferencias), Generate (informe estructurado, brief o análisis). Se diferencia del RAG Assistant en que extrae de fuentes externas, en vivo o entre dominios en lugar de una base de conocimiento interna controlada, y produce nuevas inferencias de la combinación de fuentes.
¿Qué es el Patrón de Síntesis Multi-Fuente?
El Patrón de Síntesis Multi-Fuente es la capacidad definitoria de Generative Research: leer múltiples fuentes simultáneamente para encontrar en qué coinciden colectivamente, mostrar dónde están en conflicto e inferir lo que la evidencia combinada implica más allá de lo que cualquier fuente individual establece. Un despliegue que resume cada fuente de forma independiente no está usando este patrón. La capa de síntesis es lo que comprime 30 fuentes en un brief coherente y distingue Generative Research de un conjunto de resúmenes de documentos cosidos juntos.
¿En qué se diferencia Generative Research de un RAG Assistant?
RAG Assistant recupera respuestas de una base de conocimiento interna controlada que usted posee. Generative Research sintetiza de fuentes externas, en vivo o entre dominios en el momento de la consulta. Los modelos de confianza son diferentes: los resultados de RAG pueden verificarse comprobando la fuente interna citada. Los resultados de Generative Research requieren verificar que la fuente externa citada realmente respalde la afirmación atribuida y que la inferencia sintetizada se sostenga bajo escrutinio. La revisión humana de 15 minutos antes de la distribución es un requisito de gobernanza para Generative Research que es menos crítico para RAG.
¿Qué es el lavado de citas en investigación de IA?
El lavado de citas ocurre cuando un modelo de IA cita una fuente real y creíble para una afirmación que esa fuente no hace realmente. La evaluación del Stanford HAI de 2024 encontró que el 23% de las citas generadas por IA en tareas de síntesis de larga extensión o bien citaban una fuente que no contenía la afirmación atribuida o representaban erróneamente la posición de la fuente. Esto produce salidas que parecen autoritativas y pasan la revisión casual pero fallan bajo escrutinio. La mitigación es verificar 3-5 citas por brief antes de la distribución.
¿Qué ROI debería esperar de Generative Research?
Las horas de analista por brief competitivo caen de 4-8 horas a 30-60 minutos (reducción de tiempo del 85-90%). La cobertura de fuentes por brief mejora de 5-10 fuentes a 20-50 fuentes (mejora de 3-5x). Las tasas de completación de investigación pre-llamada para representantes de ventas suben del 40-60% al 85-95%. La cadencia del briefing mejora 4-6x (los briefs semanales se vuelven factibles donde los mensuales eran el límite anterior). La tasa de completación de investigación pre-llamada es la métrica más fácil de rastrear y se conecta directamente con los resultados del pipeline.
¿Cuáles son los failure modes más comunes de Generative Research?
Los seis principales failure modes son la confabulación (afirmaciones que suenan plausibles no respaldadas por ninguna fuente), el lavado de citas (fuente real citada para una afirmación que la fuente no hace), el retraso en la actualidad de las fuentes (el índice tiene días de retraso), las fuentes en conflicto presentadas como consenso unificado, la deriva de alcance (un prompt demasiado amplio produce una salida inutilizable) y el sesgo de fuente única (una fuente dominante abruma la síntesis). El lavado de citas es el más insidioso porque parece autoritativo. La confabulación es la más dañina para la confianza cuando se descubre.
Más información

Co-Founder, Rework.com
On this page
- La fórmula: Ingest, Analyze, Generate
- El Patrón de Síntesis Multi-Fuente
- Generative Research vs. RAG Assistant: la distinción crítica
- Cinco ejemplos reales en profundidad
- 1. Informes de inteligencia competitiva
- 2. Brief de investigación de cuenta antes de una llamada de ventas
- 3. Síntesis ejecutiva de tendencias de la industria
- 4. Dimensionamiento de mercado con fuentes citadas
- 5. Investigación de escritorio de due diligence en M&A
- Failure modes: qué rompe Generative Research
- El modelo de confianza: la verificación no es opcional
- Cuándo funciona Generative Research (y cuándo no)
- Señales de ROI: midiendo el impacto
- Más información