Scoring and Routing: スケールで対応するAIトリアージ
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
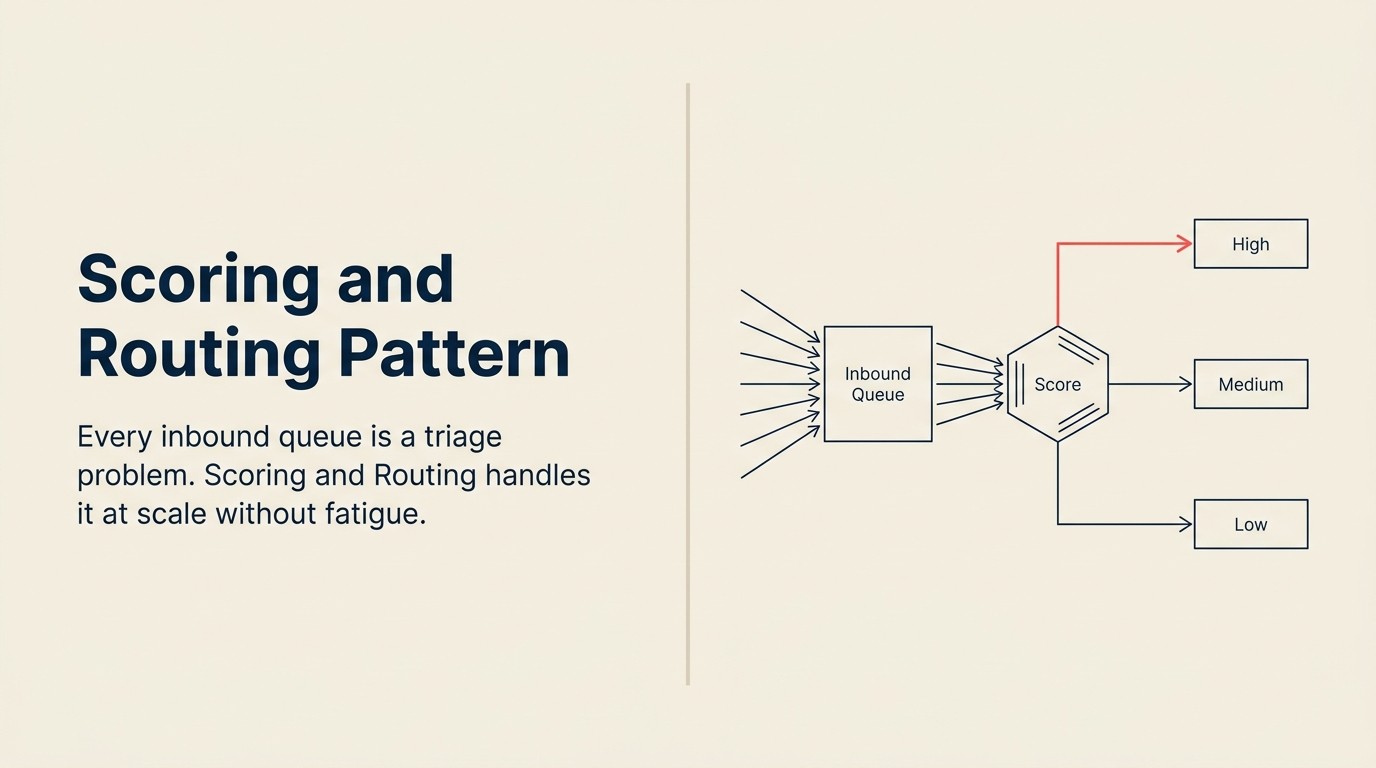
すべてのインバウンドキューはトリアージの問題です。
ウェビナーキャンペーンからリードが届きます。400件の連絡先のうち、実際に購買意図があるのは40件で、残りの360件はタイトルが面白そうだったためにクリックしただけです。一晩でサポートチケットが積み上がります。新規リクエストが300件あり、そのうち12件が緊急のエンタープライズ問題で、288件はドキュメントに既に回答がある L1 の質問です。ローン申請が来ます。今週1,200件で、一部は信用力があり、一部はなく、少数はクリーンに見えても詐欺です。
仕事はどのケースでも同じです。ノイズからシグナルを選別する。正しいアイテムを優先する。それぞれを適切な担当者またはプロセスにルーティングする。人間がすべてを手動で読み通す間に本当に緊急のものが3時間キューに留まらないよう、十分に速く処理する。
手動のトリアージはスケールしません。ルールベースの閾値(「500名以上の従業員の企業からのリードはすべてエンタープライズチームにルーティングする」)はコンテキストを見逃します。リードに添付されたメールスレッドを読めません。訪問者が価格ページに40分費やしたことを見れません。この見込み客が6ヶ月後に Churn した前歴があることを考慮できません。
Scoring and Routing はこれを処理するAIパターンです。ビジネスAIで最も経済的に重要なパターンの一つであり、何がうまくいかないかを含めて明確に理解することは投資する価値があります。
機能の式: Ingest、Analyze、Predict、Execute
Ingest(受信レコード) は生の入力をキャプチャします。新規リードレコード、送信されたサポートチケット、求人応募、提出された保険申請。ほとんどの導入では、Ingestステップはアイテム自体だけではありません。関連するコンテキストも取り込みます。リードのブラウジング履歴、顧客のティアとアカウント年齢、求人説明書と一緒に応募者がアップロードした履歴書、取引のデバイスフィンガープリントと加盟店の履歴。
Analyze(特徴量の抽出) は生の入力をモデルが使用するシグナルに変換します。リードの場合: 会社規模、タイトルのシニア度、訪問したWebサイトのページ、メールドメイン、業界、過去のエンゲージメント。サポートチケットの場合: インテント分類(請求? バグ? 機能リクエスト?)、センチメント、顧客ティア、既知のインシデントパターンに一致するかどうか。このステップでAIのアドバンテージが始まります。人間のトリアージは3〜5つのシグナルを見ます。モデルは、人間が確認しないシグナル間の相互作用を含む20〜50個を同時に評価します。
Predict(スコアリング) はモデルが特徴量に学習されたパターンを適用するステップです。出力はスコアで、確率または優先度ランクです。リードの場合: 90日以内にクロージングする確率。チケットの場合: エスカレーションまたはスペシャリストが必要な確率。詐欺の場合: この取引が不正である確率。Predictステップは過去の結果に対する純粋なパターンマッチングで、通常はテキストが豊富な入力にはロジスティック回帰、勾配ブーストツリー、またはファインチューニングされたLLMで実装されます。このレコードに似た過去のレコードに何が起きたかを学習しています。
Execute(ルーティングまたは割り当て) はスコアを取得して行動します。リードをエンタープライズチームに割り当てる。チケットをセキュリティキューに移す。取引を拒否してレビューワークフローをトリガーする。Salesforceタスクを作成する。オンコール担当者にSlackアラートを送信する。Executeはスコアが結果を伴う決定になる場所です。ガバナンスが最も重要な場所でもあります。Executeステップは常に簡単に元に戻せるとは限らない実際のダウンストリーム効果を持ちます。
Key Facts: Scoring and Routingのビジネス影響
- McKinseyによると、AIが営業とマーケティングにおいて0.8〜1.2兆ドルの追加生産性を解放できると推定しており、AIに投資するプレイヤーは収益が3〜15%、営業ROIが10〜20%向上しています(McKinsey、2023年)
- AI搭載のリードスコアリングを使用するB2B企業は、12ヶ月以上の結果データを持つ成熟した導入において、手動でトリアージされたキューと比較して最高スコアのリードティアで2〜3倍のコンバージョン率改善を見ています(Forrester B2B Sales AI Report、2025年)
- Scoring and Routingパターンを使用している保険会社は、クリーンな申請を迅速に処理し複雑な申請をスペシャリストアジャスターにルーティングすることで、通常申請の処理コストを30〜40%削減したと報告しています(Deloitte Insurance AI Study、2024年)
詳細な5つの実例
1. リードスコアリングと担当者割り当て
最も典型的なユースケース。マーケティングキャンペーンが300件のインバウンドリードを生み出します。モデルは各リードレコードと、サイト分析およびメールエンゲージメントプラットフォームからの行動データを取り込みます。タイトル(VP of SalesはSales Internより高くスコアリングされる)、会社規模、業界フィット、訪問ページ(価格ページを2回以上訪問するのは強いシグナル)、2時間以内にメールを開封、これが再訪問の見込み客の場合は過去のCRM履歴などの特徴量を Analyze します。
Predictステップは各リードに推定コンバージョン確率を表す0〜100のスコアを割り当てます。Executeステップは75以上のリードを同日SLAでシニア担当者にルーティングし、40〜75のリードをSDRに資格確認のために送り、40以下のリードを自動ナーチャリングシーケンスに送ります。
このためのツールにはSalesforce Einstein Lead Scoring、HubSpotのPredictive Lead Scoring、Reworkには営業ワークフローに組み込まれたAI支援スコアリングがあります。よくキャリブレートされたシステムは通常、ヘッドカウントを増やすことなく高コンバージョンリードへのパイプラインを20〜30%多くシフトします。営業固有の実装の詳細については、ルールベースモデルを超えたAIリードスコアリングを参照してください。
2. サポートチケットの優先付けとチームルーティング
B2B SaaS企業が毎日600件のサポートチケットを受け取ります。モデルは各チケットのテキストと、提出した顧客のアカウントデータ(ARR、契約ティア、利用パターン、過去のチケット履歴、更新までの日数)を取り込みます。Analyzeはインテントを分類し(請求問題、技術バグ、機能リクエスト、セキュリティ懸念)、センチメントを検出し、エスカレーションリスクの指標を確認します。
Predictは緊急度をスコアリングします。更新3週間前の請求問題を持つ高ARR顧客が上位にスコアされます。Executeは高緊急度チケットを指名アカウントマネージャーにルーティングし、技術的な問題を適切なエンジニアリングティアに送り、低緊急度の機能リクエストをバックログキューに送ります。結果: エンタープライズの問題は数分で回答を受け取り、L1のノイズはチームをブロックしません。
この分野のツールにはZendesk AI、IntercomのチケットインテリジェンスAI、FreshdeskのFreddy AIがあります。
3. 履歴書スクリーニングとリクルーター割り当て
会社が12の空きポジションに求人を出し、2週間で1,800件の応募を受け取ります。モデルは各履歴書と職務記述書を取り込みます。Analyzeは関連するシグナルを抽出します。関連する役割での経験年数、言及されている特定のスキル、勤務した会社、学歴、履歴書の構成と完全性。各応募者を各役割の目標プロファイルと比較します。
Predictは応募者ごと、役割ごとのフィットスコアを出力します。Executeはそのポジションのリクルーターに上位四分位を表示し、境界線上の候補者を軽いスクリーニングステップにルーティングし、下位ティアには自動返答を送ります。注意: ここはバイアスリスクが最も高い場所でもあります。以下で説明します。
このためのツールにはEightfold、HireVue、Paradox、GreenhouseのAIスクリーニングアドオンがあります。
4. 保険申請の迅速処理 vs. 人間によるレビュー
保険会社が月に5,000件の申請を処理します。シンプルな申請(写真証拠と明確な過失がある軽微な事故)は、モデルが「迅速処理」スコアを付ければ48時間で支払えます。複雑な申請には人間のアジャスターが必要です。
モデルは申請フォームデータ、添付写真、車両履歴、契約者履歴、サードパーティレコードを取り込みます。Analyzeは複雑さの指標を抽出します。過失は明確か? 怪我はあるか? 申請額は同等のインシデントデータと一致するか? 申請者の履歴に異常なパターンがあるか?
Predictは各申請を2つの側面でスコアリングします。迅速処理確率(これは定型的か?)と詐欺確率(これは既知の詐欺パターンに一致するか?)。Executeは迅速処理の低詐欺申請を自動支払いにルーティングし、中程度の複雑さの申請をアジャスターに送り、高詐欺確率の申請を特別調査部門に送ります。
これはパターンで最もよく証明されたユースケースの一つで、定型的な大多数での処理コストの30〜40%削減を報告しています。
5. 決済における詐欺検出
Stripe Radarは世界で最も広く展開されているスコアリングシステムの一つです。ほとんどのオペレーターが「詐欺防止」と考えていても「AI」とは思っていませんが。すべてのカード取引に対して、Stripeのモデルはカードメタデータ、デバイスフィンガープリント、取引金額、加盟店カテゴリ、地理データ、行動シグナル(フォームがどれだけ速く記入されたか、請求先と配送先住所が一致するか)を取り込みます。
Analyzeが特徴量を抽出します。Predictが詐欺確率スコアを割り当てます。99.5%(ほぼ確実に詐欺)または0.2%(ほぼ確実に正当)。Executeはそのスコアに基づいて行動します。承認、3D Secureレビューに送信、または完全にブロック。
ここでのExecuteステップは非常に高リスクで、ミリ秒単位で発生します。だからこそスコア閾値のキャリブレーションが重要です。積極的すぎる閾値は正当な取引をブロックし、怒った顧客からのチャージバックを生み出します。緩すぎると詐欺の損失が増加します。適切な閾値はビジネス上の決定であり、単なるモデルパラメータではありません。
Score-Then-Execute Loop(スコア後実行ループ)
Scoring and Routingは崩してはならない2つの異なるフェーズで機能します。すべてのインバウンドアイテムが抽出された特徴量と過去の結果パターンに基づいて優先度ランクを受け取るスコアリングフェーズと、そのランクがルーティング決定を導く実行フェーズです。スコアリングフェーズをスキップしてルール(会社規模、チケットカテゴリ)から直接ルーティングすると、高意図のエンタープライズリードと低意図のSMBリードを区別するコンテキストシグナルを見逃します。スコアから閾値マッピングをスキップして、生のモデル信頼度をルーティングトリガーとして直接使用すると、モデルのキャリブレーション中にルーティングの不安定性が生じます。スコアを最初に計算し、検証済みの閾値に基づいて実行するという2フェーズ構造が、このパターンをボリュームで信頼できるものにします。
失敗モード: 実際に何が起きるか
| 失敗モード | 根本原因 | 修正方法 |
|---|---|---|
| トレーニングデータのバイアス | 過去に偏った結果でモデルが訓練されている(過去の担当者はミッドマーケットからのみクロージングし、エンタープライズリードが不当に優先度を下げられていた) | セグメント間のスコア分布を監査する。候補者や顧客データの人口統計的相関を確認する。 |
| 閾値のキャリブレーション誤り | 実際の受注率に対して検証されていなかったため、高意図リードの60%をジュニア担当者に送る70ポイントの閾値 | 結果に対して閾値を検証する。閾値設定を一度限りのセットアップではなく四半期ビジネスレビューアイテムとして扱う。 |
| 特徴量の陳腐化 | Q1データで訓練されたモデルはQ3に立ち上げた新製品ラインを見逃すため、その製品ページを訪問した見込み客のスコアが上がらない | 製品/セグメントの変更に合わせた自動再トレーニングスケジュールを設定する。スコア分布のドリフトを時間をかけて追跡する。 |
| フィードバックループの失敗 | ルーティングされたリードが実際にクロージングしたか、チケットが解決したか、ルーティングされた申請がクリーンに支払われたかを誰も監視していない | ワークフローにアウトカムトラッキングを最初から組み込む。モデルはキャリブレーションを維持するためにラベル付けされた履歴データが必要。 |
| アクションなしのスコアインフレーション | スコアリングは実行されるが、担当者がキューの順序を無視して独自のパイプラインで作業する | ワークフローインターフェース(CRM、サポートツール)でスコアを見えるようにする。チームのパフォーマンス指標をアウトプットだけでなくスコアリングコンプライアンスに結びつける。 |
| サイレントルーティングエラー | Executeが誰も数週間気づかずにアイテムを間違ったキューに送る | すべてのルーティング決定をログに記録する。スコアリングされたティアとアウトカムティアの不一致を表示する例外レポートを構築する。 |
最も影響力の高い2つの失敗モード(閾値のキャリブレーション誤りとフィードバックループの失敗)は、修正するのが最も刺激的でないものでもあります。新しいモデルを必要としません。運用上の規律を必要とします。誰がどこにルーティングされたか、そのルーティング決定が成果を上げたかの定期的なレビューです。
Gartnerの2025年AI Operations報告では、最初のベンチマークを下回るAIスコアリングシステムの68%が、フィードバックループの失敗に劣化を追跡できると発見しました。モデルが新しい結果で再トレーニングされなかったため、2022年のクロージングデータから学習したパターンに対して2024年のリードをスコアリングし続けます。
閾値のキャリブレーション: 最も見落とされているレバー
スコアリングシステムを導入するほとんどのオペレーターは、モデルの選択に90%の注意を払い、閾値の設定に10%を払います。その投資の収益は逆です。
モデルの仕事はアイテムをランク付けすることです。閾値の仕事はそのランクが運用上何を意味するかを決定することです。リードスコアリングモデルは300件のリードを1から300に正確にランク付けするかもしれません。しかし、「高優先度」の閾値を100点中60点に設定し、300件のリードのうち200件が60以上にスコアされた場合、シニア担当者は圧倒されてセグメンテーションは意味がなくなります。
閾値のキャリブレーションには3つの入力が必要です。過去データのスコア分布、各ルーティングティアでの運用上のキャパシティ(エンタープライズチームは1日何件のアイテムを処理できるか?)、結果データ(どのスコア範囲が実際に受注と相関するか?)。これらの3つがあれば、単なる統計的カットオフではなく、運用上の現実に合った閾値を設定できます。
少なくとも四半期ごとに閾値を見直してください。市場の変化、キャンペーンミックスの変化、製品の拡大はすべて、あなたの下にあるスコア分布を変えます。
Scoring + Routingが機能するとき、しないとき
うまく機能する場合:
- ラベル付けされた過去の結果がある。モデルは過去のデータから学習します。どのリードがクロージングしたか、どの申請が詐欺だったか、どの応募者が採用されて継続したか。ラベル付きの履歴がなければ意味のある予測もありません。
- ボリュームがある。Scoring and Routingはトリアージの問題が実際にある場合に効果を発揮します。週15件のリードを受け取るなら、営業担当者が手動で10分でトリアージできます。500件を受け取るなら、このパターンが必要です。
- ルーティング決定が明確で実行可能なアクションにマッピングされている。「エンタープライズチームにルーティングする」は実行可能です。「このリードをより慎重に扱う」はそうではありません。
- データが合理的に完全で一貫している。欠落フィールド(役職のないリード、アカウントリンクのないチケット)は予測品質を低下させます。
代替案を検討する場合:
vs. Anomaly Agent: Scoring and Routingは既知のカテゴリ内でアイテムに優先度を割り当てます。Anomaly Agentは期待されるどのカテゴリにも属さないアイテムをフラグします(未知の未知)。過去の詐欺に似ていない新しい詐欺パターンを発見する必要がある場合、Anomaly Agentが適切なツールです。Scoring and Routingはこれらの新しいケースを、既知の詐欺パターンに見えないため通常レコードに似ているとして中リスクとスコアリングします。
vs. Workflow Copilot: スコアリングはユーザーなしで機能します。Copilotは作業中にユーザーを支援します。アルゴリズム的に委任できない判断を必要とするプロセスの場合(複雑なエンタープライズ営業電話、繊細な交渉、微妙な顧客対応)、Copilotはトリアージ決定を置き換えるのではなく人間を支援します。
vs. Autonomous Agent: Scoring and Routingはワークフロー内の1つのポイントで1つの決定を行います。Autonomous Agentは目標を達成するために複数のステップのループを実行し、複数の決定を行います。Scoring and Routingは大きなワークフロー内のモジュールです。Autonomous Agentは完全なワークフローです。
ROIシグナル: 機能しているかを測定する方法
| 指標 | 測定内容 | 妥当なベンチマーク |
|---|---|---|
| 初回コンタクトまでの時間 | リード提出から最初の担当者アウトリーチまでの時間 | 手動キューと比較して50〜70%削減 |
| ティア別担当者の稼働率 | エンタープライズスコアのリードへのシニア担当者の時間のシェア | ベースライン: 約40%。スコアリングあり: 65〜80% |
| 受注率: スコアありvs.なし | 高/中/低スコアバンド間のコンバージョン率比較 | 成熟した導入では高スコアバンドが低スコアバンドの2〜3倍の受注率になるべき |
| ルーティングパス別チケット解決時間 | AIルーティングvs.手動ソートチケット | AI ルーティングで解決時間が20〜35%削減 |
| 偽陽性率 | 優先度に値しない優先キューにルーティングされたアイテム | 四半期ごとに追跡; エンタープライズティアで偽陽性15%以下を目標 |
| スコア分布のドリフト | モデルのスコア分布が時間とともに変化しているか | 平均スコアが前四半期比で10ポイント以上変化した場合にフラグを立てる |
スコアありとなしのリード間の受注率比較が最も強力な証明です。上位スコアバンドのリードが28%でクロージングし、下位スコアバンドのリードが7%でクロージングする場合、モデルは価値を発揮しています。それらの数値が似ている場合、モデルは有用に識別しておらず、トレーニングデータまたは特徴量の問題があります。
ガバナンス要件
Scoring and Routingは人々の経済的な結果に触れます。営業担当者のコミッション、候補者の内定、顧客の承認または却下。これはそれを避ける理由ではありません。うまく管理する理由です。
四半期ごとにモデルを監査する。 人口統計、地理的、およびファーモグラフィックセグメント間のスコア分布を確認します。リードスコアリングモデルがビジネス上の理由なく特定の地域や業界からのリードに体系的に低いスコアを付けている場合、モデルが技術的に「正確」であってもバイアスの問題があります。
人間のオーバーライドを明確に定義する。 どの担当者も高意図だと思う低スコアのリードをフラグできるべきです。どのリクルーターも履歴書を手動で次のラウンドに進められるべきです。オーバーライドプロセスはログに記録されるべきで、オーバーライドがモデルの予測と体系的に異なるかどうか、そしてオーバーライドが正しかったかどうかを確認できるようにします。
再トレーニングのリズム。 ほとんどのビジネスアプリケーションでは、四半期ごとの再トレーニングが合理的なデフォルトです。市場の変化が速い場合は月次。年次はほぼ常に遅すぎます。2023年のモデルに対して2025年の見込み客をスコアリングしています。
規制業界のドキュメンテーション。 金融サービス、融資、保険、採用では、自動化されたスコアリング決定は ECOA、GDPR第22条、または州レベルのAI法の下で説明可能性を必要とする場合があります。管轄区域を把握してください。「モデルがそう言った」は不利な与信決定に対する弁護可能な説明ではありません。
ベンダーとツールの全景
| ユースケース | 主要ツール |
|---|---|
| リードスコアリング | Salesforce Einstein、HubSpot Predictive Scoring、Marketo AI、Rework AI |
| サポートチケットルーティング | Zendesk AI、Intercom AI、Freshdesk Freddy、Kustomer |
| 候補者スクリーニング | Eightfold、HireVue、Paradox、Greenhouse AI |
| 詐欺検出 | Stripe Radar、Kount、Featurespace、Sardine |
| 保険申請 | Shift Technology、Tractable、Cape Analytics |
| カスタムスコアリングインフラ | Pinecone(特徴量類似度のベクトル埋め込み)、Tecton(特徴量ストア)、AWS SageMaker、Azure ML |
カスタムスコアリングを構築するチームへ: PineconeとWeaviateは類似性ベースの特徴量検索によく使用されますが、コアスコアリングモデルは通常、テキストが豊富な入力には勾配ブーストツリー(LightGBM、XGBoost)またはファインチューニングされたLLMです。インフラはラベル付けされた過去データの品質と閾値キャリブレーションの厳密さよりも重要ではありません。
AI Sales Operatorとの関連
Scoring and RoutingはAI Sales Operator(ACE Frameworkのレベル3)のコアにある4つのパターンの一つです。その文脈では、リードスコアリングは単なるマーケティングオートメーション機能ではありません。すべての担当者の1日がどのように構成されるかを決定するファネルの先頭意思決定レイヤーです。AI Sales Operatorのコンセプトは、これらの4つのパターンが実際にどのように連携するかを説明します。
最もパフォーマンスの高い営業組織は、スコアリングをインバウンドリードの優先付けだけでなく、完全なパイプライン全体での担当者の時間の優先付けにも使用します。どの取引を進めるか、どのアカウントを拡大のためにエンゲージするか、どの更新がChurnリスクにあるか。Scoring and RoutingがMeeting Intelligence(通話分析)とWorkflow Copilot(CRM組み込み提案)に接続されると、3つのパターンが一緒にクローズドループを形成します。AIが機会をスコアリングし、AIが通話を分析し、AIが次のアクションを提案します。
このアーキテクチャが、AIで強化された営業チームと、リード割り当てのためのAIツールを持つだけのチームを分けます。
Rework分析: リードスコアリングを導入するほとんどのチームはモデルを正しく実装し、運用を誤ります。モデルはリードを正確にスコアリングします。しかし、閾値はリリース時に一度設定され、結果データが再び取り込まれることはなく、チームは高スコアのリードが低スコアのリードより実際に高い率でクロージングしているかどうかを監査しませんでした。6ヶ月後、担当者はキューの順序を信頼しなくなり、独自のパイプラインで作業しています。モデルのROIは、AIが失敗したからではなくフィードバックループが構築されなかったために消えます。Scoring and Routingには1つではなく2つの組織上のコミットメントが必要です。スコアリングシステムと、キャリブレーションを維持する四半期ごとの結果レビューです。両方のコミットメントをするチームが2〜3倍のコンバージョン改善を見ます。最初のコミットメントだけをするチームは、手動トリアージへのゆっくりとした後退を見ます。
よくある質問
Scoring and Routing AIパターンとは何ですか?
Scoring and Routingは、4ステップの式を使ってインバウンドアイテム(リード、チケット、応募書類、申請)を自動的に優先付けして割り当てるAIパターンです。受信レコードとコンテキストを Ingest し、抽出された特徴量を Analyze し、優先度スコアを Predict し、ルーティング決定を Execute します。このパターンは手動レビューでは対応できないボリュームでトリアージを処理し、手動トリアージ中に人間が読む3〜5つではなく、20〜50のシグナルを同時に評価します。
AIリードスコアリングはどのように機能しますか?
AIリードスコアリングは各リードレコードと行動データ(訪問ページ、メールエンゲージメント、価格ページの閲覧時間)を取り込み、特徴量(会社規模、タイトルのシニア度、業界、過去のCRM履歴)を抽出し、訓練されたモデルを適用して確率スコアを割り当てます。モデルは過去の結果から学習しました。似たプロファイルを持つ過去のリードが実際にどのようにクロージングしたか。スコアがルーティングを駆動します。高スコアは同日SLAでシニア担当者に、中スコアは資格確認のためにSDRに、低スコアは自動ナーチャリングシーケンスに送られます。
Scoring and Routingで最も一般的な失敗モードは何ですか?
最も影響力の高い2つの失敗は閾値のキャリブレーション誤りとフィードバックループの失敗です。閾値のキャリブレーション誤りは各ルーティングティアに誤った割合のリードを送ります。シニア担当者を中品質のリードで圧倒するか、本当に高意図の見込み客をルーティングし損ねるかです。フィードバックループの失敗は、結果データ(誰がクロージングしたか、誰が Churn したか、どの申請が詐欺だったか)がモデルの再トレーニングのために取り込まれないときに発生し、現在のレコードを古い過去のパターンに対してスコアリングします。Gartnerによると、パフォーマンスが低下するスコアリングシステムの68%がフィードバックループの失敗に劣化を追跡できます。
Score-Then-Execute Loop(スコア後実行ループ)とは何ですか?
Score-Then-Execute Loopは Scoring and Routingパターンの2フェーズ構造です。すべてのアイテムが抽出された特徴量と過去の結果パターンから優先度ランクを受け取るスコアリングフェーズと、検証済みの閾値がそのランクをルーティング決定に変換する実行フェーズです。2つのフェーズを統合すること(例えば、モデルスコアリングなしでルールベースの閾値から直接ルーティングする)は、高意図のエンタープライズリードと低意図のリードを区別するコンテキストシグナルを見逃します。閾値検証なしで生のモデル信頼度をルーティングトリガーとして直接使用すると、ルーティングの不安定性が生じます。
Scoring and Routing vs. Anomaly Agentはいつ使い分けますか?
既知のカテゴリ内でアイテムをトリアージする必要がある場合(リード、チケット、応募書類の優先度割り当て)はScoring and Routingを使用します。期待されるどのカテゴリにも属さないアイテムを発見する必要がある場合(過去の詐欺に似ていない新しい詐欺パターンなど)はAnomaly Agentを使用します。Scoring and Routingは新しい詐欺を通常取引に似ているとして中リスクとスコアリングします。Anomaly Agentは統計的ベースラインからの逸脱を検出するため、具体的にフラグを立てます。
Scoring and Routingからどのような ROI を期待すべきですか?
12ヶ月以上の結果データを持つ成熟した導入では、最高スコアのリードティアで2〜3倍のコンバージョン率改善が見られます。営業チームは初回コンタクトまでの時間が50〜70%削減されます。サポートチケットルーティングは通常、解決時間を20〜35%削減します。保険会社は処理コストの30〜40%削減を報告します。これらのベンチマークを達成するには、キャリブレートされたスコアリングシステムと、新しいクロージングデータでモデルを再トレーニングする四半期ごとの結果レビューの両方が必要です。
参考リンク

Co-Founder, Rework.com
On this page
- 機能の式: Ingest、Analyze、Predict、Execute
- 詳細な5つの実例
- 1. リードスコアリングと担当者割り当て
- 2. サポートチケットの優先付けとチームルーティング
- 3. 履歴書スクリーニングとリクルーター割り当て
- 4. 保険申請の迅速処理 vs. 人間によるレビュー
- 5. 決済における詐欺検出
- Score-Then-Execute Loop(スコア後実行ループ)
- 失敗モード: 実際に何が起きるか
- 閾値のキャリブレーション: 最も見落とされているレバー
- Scoring + Routingが機能するとき、しないとき
- ROIシグナル: 機能しているかを測定する方法
- ガバナンス要件
- ベンダーとツールの全景
- AI Sales Operatorとの関連
- 参考リンク