AI Lead Scoring jenseits regelbasierter Modelle

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Das meiste "Lead Scoring", das heute eingesetzt wird, ist manuelle Gewichtung, die als Intelligence verkleidet ist.
Die Logik lautet: Eine Formulareinreichung ist 10 Punkte wert, ein VP-Titel fügt 20 hinzu, ein Unternehmen mit 200+ Mitarbeitern fügt 15 hinzu, ein Besuch der Preisseite fügt 25 hinzu. Addieren Sie alles und alles über 70 ist ein "Hot Lead". Das Vertriebsteam arbeitet zuerst die Hot Leads ab.
Das Problem ist offensichtlich, sobald Sie es laut aussprechen: Ein Mensch hat diese Gewichtungen festgelegt. Er hat eine Ermessensentscheidung getroffen, wahrscheinlich durch etwas Intuition und ein paar Anekdoten des Vertriebsteams beeinflusst, und sie als statische Regeln kodiert. Die Gewichtungen werden nicht aktualisiert, wenn sich der Markt verschiebt. Sie kalibrieren sich nicht neu, wenn sich Ihr ICP nach einer Series-B-Finanzierung ändert.
Ein VP-Titel von einem 50-Personen-Unternehmen um 2 Uhr morgens an einem Samstag konvertiert zu einem völlig anderen Satz als derselbe Titel von einem 300-Personen-Unternehmen um 10 Uhr morgens an einem Dienstag.
Machine Learning (ML) Lead Scoring lässt die Daten statt der Menschen die Gewichtungen wählen. Das ist der gesamte konzeptionelle Unterschied. Aber es gut auszuführen, erfordert ein Verständnis dafür, wie das Modell funktioniert, welche Daten es benötigt und wo Implementierungen scheitern. Dies ist Muster 1 in der AI Sales Operator Architektur, und das Fundament, auf dem alles andere aufbaut.
Was regelbasiertes Scoring übersieht
Regeln sind kategorial. ML-Modelle sind probabilistisch. Diese Unterscheidung erzeugt eine Reihe von systematischen blinden Flecken bei regelbasierten Ansätzen:
Feld-Sparsamkeit. Die meisten Lead-Formulare erfassen 4-6 Felder. Die meisten CRM-Datensätze haben Dutzende potenziell relevanter Felder, von denen viele leer sind. Regeln behandeln leere Felder als neutral. ML-Modelle können lernen, dass eine fehlende LinkedIn-URL in einem bestimmten Unternehmensgrößenband mit niedrigeren Abschlussraten korreliert, weil das die historischen Daten zeigen.
Timing und Sequenz. Ein Lead, der die Preisseite am ersten Tag besucht und dasselbe Tag das Demo-Formular ausfüllt, konvertiert anders als ein Lead, der die Preisseite drei Wochen vor dem Formular besuchte. Regeln können "Preisseiten-Besuch = 25 Punkte" erkennen, aber keine Aktualitätskurven oder Verhaltenssequenzen erfassen. ML-Modelle schon.
Firmografische Veränderungssignale. Ein Unternehmen, das gerade einen VP of Sales eingestellt hat, ist ein grundlegend anderer Interessent als dasselbe Unternehmen sechs Monate zuvor. Statische Regeln erkennen diese dynamischen Signale nicht. ML-Modelle, die mit aktuellen firmografischen Daten (aus Quellen wie LinkedIn, Clearbit oder 6sense) gespeist werden, können sie berücksichtigen.
Multi-Touch-Interaktionen. Die Kombination aus "VP-Titel + Preisseite + Empfehlungsquelle = Partner-Kanal" könnte zu 40 % konvertieren. Jedes Element allein könnte 10 % wert sein. Regeln bewerten sie unabhängig; ML erfasst den Interaktionseffekt.
Wichtige Fakten: AI Lead Scoring
- McKinsey identifiziert Lead-Qualifizierung als einen der wirkungsstärksten AI-Use-Cases für B2B-Vertriebsteams, weil besseres Scoring sich verstärkt: bessere Leads schließen öfter ab und generieren bessere Trainingsdaten für die nächste Modell-Iteration
- Mindestens 200 Closed-Won-Deals sind für ein zuverlässiges ML-Lead-Scoring-Modell erforderlich; unter 100 produzieren die meisten kommerziellen Tools Outputs, die statistisch nicht von zufälliger Zuweisung zu unterscheiden sind
- Unternehmen, die AI-unterstütztes Lead Scoring verwenden, berichten von 10-20 % höheren Lead-zu-Opportunity-Konversionsraten im Vergleich zu statischen regelbasierten Modellen, laut MadKudu- und 6sense-Kundendaten (2022-2024)
Wie ML Lead Scoring funktioniert (ohne das PhD)
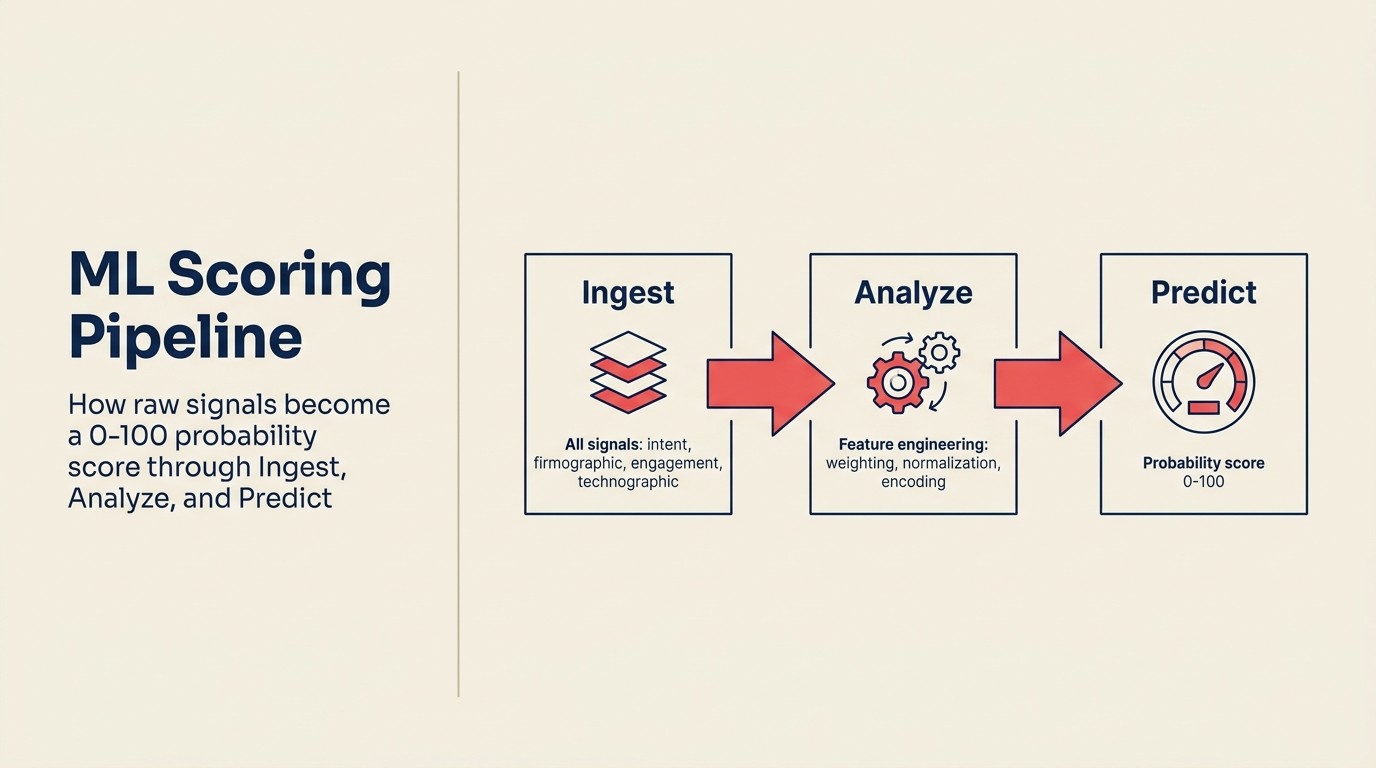
Die Mechanik ist einfacher als die meisten Anbieter es klingen lassen. Hier ist die operative Logik mit ACE-Framework-Vokabular:
Ingest zieht alle verfügbaren Signale für jeden Lead ein: CRM-Felder (Titel, Unternehmensgröße, Branche, Quelle), Verhaltensdaten (besuchte Seiten, geöffnete E-Mails, besuchtes Webinar), firmografische Anreicherung (Umsatzband, Mitarbeiterzahl, Finanzierungsphase, Tech-Stack) und zeitbasierte Daten (wann Aktivitäten stattfanden, Lücken zwischen ihnen).
Analyze extrahiert Features aus diesen Rohdaten. Features sind die Eingabevariablen, auf denen das Modell tatsächlich trainiert. Einige sind direkt (Titel = "VP" = binäres Feature). Einige sind entwickelt (Tage zwischen erstem Besuch und Formulareinreichung = numerisches Feature). Einige sind Interaktionsterme (Unternehmensgröße × Engagement-Häufigkeit = zusammengesetztes Signal).
Predict trainiert ein Modell auf historisch gelabelten Daten: Deals, die abgeschlossen wurden (won) und Deals, die es nicht taten (lost), zusammen mit allen obigen Features. Unter der Haube verwenden die meisten kommerziellen Lead-Scoring-Tools logistische Regression oder Gradient Boosting, beides gut verstandene ML-Techniken, die eine Wahrscheinlichkeit zwischen 0 und 1 ausgeben.
Das ist es. Eine Wahrscheinlichkeitszahl von 0 bis 100, verankert in Ihrer eigenen Win/Loss-Historie, aktualisiert, wenn neue Deals abgeschlossen werden.
Der probabilistische Lead-Score-Standard
Der probabilistische Lead-Score-Standard definiert, was ein vertretbarer AI-Lead-Score beinhalten muss: einen Wahrscheinlichkeits-Output zwischen 0 und 1, verankert in der eigenen Win/Loss-Historie des Unternehmens, trainiert auf mindestens 200 Closed-Won-Ergebnissen, mindestens vierteljährlich neu kalibriert anhand neuer Deal-Ergebnisse und Reps mit Feature-Attribution präsentiert (welche Signale diesen Score trieben). Jedes Scoring-System, das eines dieser vier Kriterien nicht erfüllt, wird besser als verbessertes regelbasiertes Scoring denn als echtes ML-Scoring klassifiziert.
Signaltypen nach Konversions-Lift gerankt

Nicht alle Signale sind gleich nützlich. Basierend auf Mustern aus MadKudu-Recherchen und 6sense Buyer Intent Daten, die zwischen 2022 und 2024 veröffentlicht wurden, ist dies die allgemeine Rangliste der Signalkategorien nach Lift-Beitrag für B2B SaaS:
| Signaltyp | Beispiele | Lift-Beitrag | Hinweise |
|---|---|---|---|
| Intent-Signale | Preisseiten-Besuche, Konkurrenz-Vergleichsseiten, G2-Kategorie-Ansichten | Sehr hoch | Kaufsignale in der späten Phase; Aktualität wichtig (letzte 7 Tage >> letzte 30 Tage) |
| Engagement-Aktualität | E-Mail-Öffnungen, Website-Besuche in den letzten 14 Tagen, Webinar besucht | Hoch | Aktualitätskurve wichtig: exponentielle Abklingkurve nach 30 Tagen |
| Firmografischer Fit | Unternehmensgröße, Branche, Finanzierungsphase | Hoch | Ihre ICP-Definition mathematisch kodiert |
| Technografischer Fit | CRM-Typ (Salesforce vs. HubSpot), bekannte Integrationen | Mittel-Hoch | Stärkster Lift, wenn Ihr Produkt ein bestimmtes Tool ersetzt oder ergänzt |
| Nachrichten-Trigger | Aktuelle Finanzierung, neue Mitarbeiterankündigungen, Produktlaunches | Mittel | Starkes Signal für Cold Outbound; weniger prädiktiv für Inbound |
| Kontakt-Level-Fit | Titel, Seniorität, Abteilung | Mittel | Am stärksten in Kombination mit Unternehmens-Level-Fit |
| Lead-Quelle | Organische Suche, Partner-Empfehlung, Content-Download | Niedrig-Mittel | Variiert stark je Unternehmen; immer testen statt annehmen |
| Formular-Verhalten | Zeit im Formular, ausgefüllte Felder, Gerätetyp | Niedrig | Nützlich als Tiebreaker; kein primäres Signal |
Datenbereitschafts-Checkliste vor dem Einsatz
Das ist der Schritt, den die meisten Unternehmen überspringen. AI Lead Scoring liefert mit schlechten Daten keine guten Ergebnisse. Führen Sie diese Checkliste durch, bevor Sie ein ML-Scoring-Tool kaufen oder konfigurieren:
Mindestanforderungen:
- Mindestens 6 Monate Closed Deals mit konsistentem Won/Lost-Labeling (12 Monate bevorzugt)
- Mindestens 200 Closed-Won-Deals insgesamt (mehr ist besser; unter 100 produziert unzuverlässige Modelle)
- CRM-Deal-Stages sind teamweit konsistent
- First-Touch-Quelle ist auf mindestens 70 % der Datensätze erfasst
- Unternehmensname und -domain sind auf 80 %+ der Datensätze ausgefüllt
Stark zu haben (verbessert die Modellqualität erheblich):
- Kontakt-Titel und Seniorität auf mindestens 60 % der Leads erfasst
- Unternehmensgröße für 70 %+ der Datensätze erfasst oder anreicherbar
- Website-Verhaltensdaten senden Events an CRM
- Mindestens eine firmografische Anreicherungsquelle (Clearbit, Apollo, ZoomInfo)
Warnsignale, die auf Datenarbeit vor dem Scoring hinweisen:
- Mehr als 20 % der Deals ohne Ergebnis-Label abgeschlossen
- Drei oder mehr verschiedene Stage-Namen für dieselbe Lifecycle-Position
- Weniger als 6 Monate Deal-Historie seit einer CRM-Migration
- Null Verhaltenstracking-Daten
Wenn Ihnen mehrere Punkte auf der Mindestliste fehlen, verbringen Sie vier bis sechs Wochen damit, Daten zu bereinigen, bevor Sie Scoring einsetzen.
Vom Modell-Output zur Routing-Schwelle
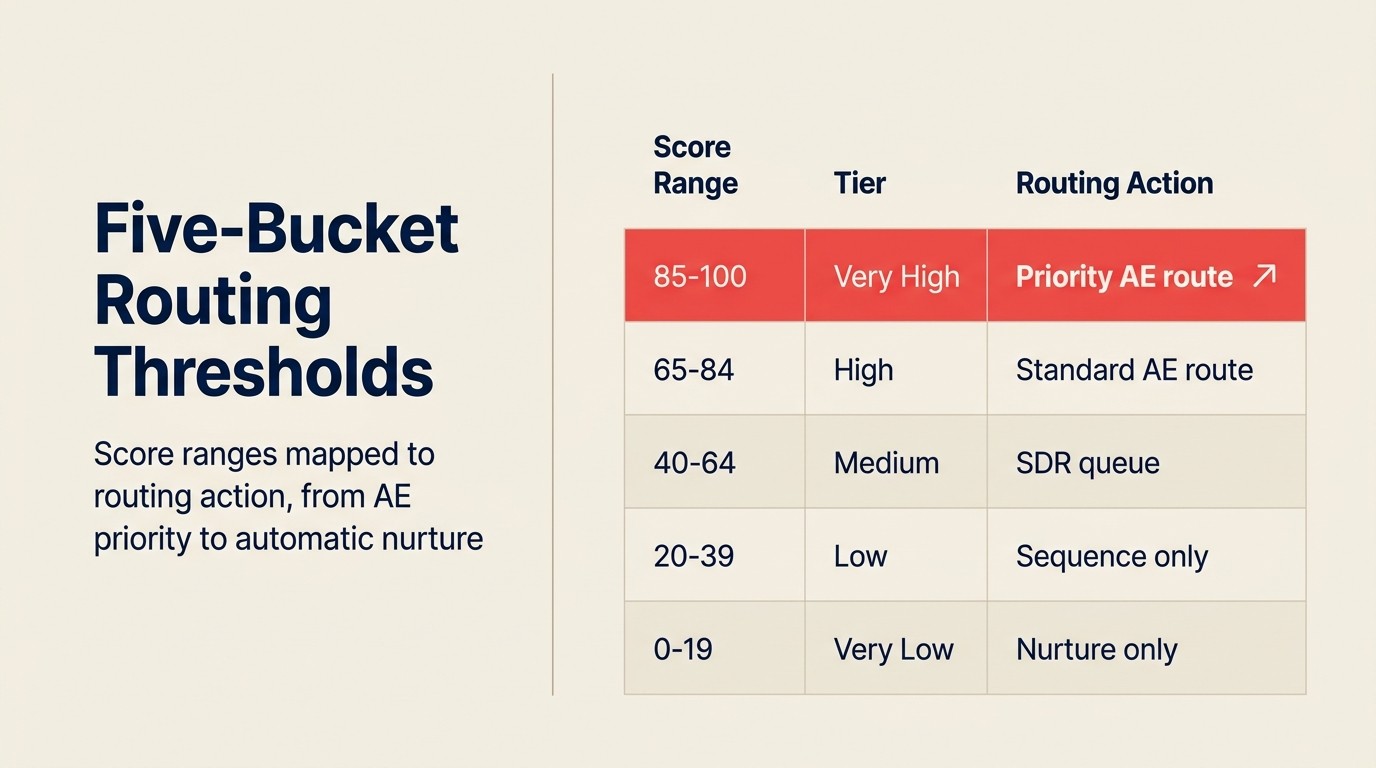
Ein Modell gibt Ihnen eine Wahrscheinlichkeit. Sie müssen immer noch entscheiden, was Sie damit tun.
Die meisten Implementierungen definieren drei bis fünf Buckets mit zugehöriger Routing-Logik:
| Score-Bereich | Label | Routing-Aktion |
|---|---|---|
| 85-100 % | Sehr hoch | An Senior-AE weiterleiten, sofortige Slack-Benachrichtigung, kein SDR-Filter |
| 65-84 % | Hoch | In AE-Warteschlange, SLA: Kontakt innerhalb von 2 Stunden |
| 40-64 % | Mittel | An SDR zur Qualifizierung weiterleiten, in Mid-Touch-Sequenz einschreiben |
| 20-39 % | Niedrig | Automatisch in Nurture-Sequenz einschreiben, keine Rep-Zuweisung |
| 0-19 % | Sehr niedrig | Keine Aktion; nur zum Newsletter-Verteiler hinzufügen |
Die Schwellenwerte setzen Sie, nicht der Anbieter. Sie sollten reflektieren: wie viel Rep-Kapazität Sie haben, wie oft Sie eine falsch-positive Bewertung tolerieren können, und welche SLA-Verpflichtungen Sie derzeit haben.
Schwellenwerte richtig zu setzen ist eine Kalibrierungsübung, keine einmalige Konfiguration. Führen Sie die anfänglichen Schwellenwerte 60 Tage lang durch, und vergleichen Sie dann: Für jeden Bucket, wie hoch war die tatsächliche Konversionsrate? Wenn Ihr "Hoch"-Bucket zu 8 % und Ihr "Mittel"-Bucket zu 12 % konvertiert, sind Ihre Schwellenwerte falsch kalibriert.
Häufige Fehlermodi
Auf voreingenommenen historischen Daten trainiertes Modell. Wenn Ihre historischen Gewinne zu einem bestimmten Kanal neigen (z.B. 70 % Ihrer abgeschlossenen Deals kamen von Partner-Empfehlungen), lernt das Modell, partner-gesourcte Leads hoch zu bewerten. Wenn Sie einen neuen Kanal erschließen, bewertet das Modell diese Leads schlecht, nicht weil sie schlechte Leads sind, sondern weil es keine Trainingsdaten für dieses Muster hat.
Scores, die Reps nicht präsentiert werden. Das Modell produziert gute Outputs, aber diese leben in einem CRM-Feld, das niemand anschaut. Reps arbeiten Leads weiterhin nach Ankunftsreihenfolge ab.
Keine Feedback-Schleife zum Neutraining. Das Modell ist im Januar konfiguriert und wird nie wieder berührt. Zwölf Monate später hat sich der Markt verschoben, der ICP hat sich weiterentwickelt, und das Modell optimiert noch für Muster von vor 18 Monaten.
Schwellenwert eingestellt und vergessen. Anfängliche Schwellenwerte werden bei Go-Live gesetzt und nie überprüft. 90 Tage später bewertet 40 % aller Leads "Hoch", weil das Modell zu breit gelernt hat.
Vollständige Behandlung häufiger AI-Lead-Scoring-Fallstricke.
Anbieter-Überblick
Salesforce Einstein Lead Scoring ist in Sales Cloud Enterprise und höher enthalten. Es trainiert direkt auf Ihren Salesforce-Daten, ohne Export oder Verbindung zu einem Drittanbieter-Tool. Stark für Unternehmen mit sauberen Salesforce-Daten und 12+ Monaten Geschichte.
HubSpot Predictive Lead Scoring ist auf Marketing Hub Professional/Enterprise und Sales Hub Enterprise verfügbar. Schwächer für Unternehmen mit signifikanten Verhaltensdaten außerhalb von HubSpot oder komplexen firmografischen Segmentierungsanforderungen.
MadKudu ist eine zweckgebundene B2B-Scoring-Plattform, die sich mit Salesforce, HubSpot und mehreren Datenanreicherungsquellen verbindet. Legt Feature-Importance offen (welche Signale trieben einen bestimmten Score), was es für RevOps einfacher macht, zu prüfen und zu kalibrieren.
6sense konzentriert sich auf Intent-Signale (Buying-Committee-Identifizierung, anonymes Besucher-Tracking). Oft über einem CRM-nativen Scoring-Modell geschichtet, anstatt es zu ersetzen.
Rework Sales AI enthält Scoring+Routing als Teil der vollständigen AI-Sales-Operator-Architektur im CRM. Scores kalibrieren sich aus Deal-Ergebnissen neu, leiten automatisch in Rep-Warteschlangen weiter und fließen direkt in den Workflow Copilot für Entwurfs-Follow-ups ein.
Rework-Analyse: Das häufigste ML-Lead-Scoring-Scheitern, das wir sehen, ist kein schlechtes Modell. Es ist ein gutes Modell, das niemand neu kalibriert. Teams setzen es in Q1 ein, sehen starke Ergebnisse in Q2, und bis Q4 fragen sie sich, warum die "heißen" Leads nicht mehr abschließen. Das Modell wurde auf einem Markt trainiert, der vor 9 Monaten existierte. Ihr ICP verlagerte sich nach einer Preisänderung, ein neuer Wettbewerber trat ein oder ein neuer Use Case entstanden. Vierteljährliche Neukalibrierung ist keine optionale Wartung; es ist der Mechanismus, der den Wahrscheinlichkeits-Output mit der aktuellen Realität verbunden hält.
Die Feedback-Schleife ist das ganze Spiel
Regelbasiertes Scoring ist eine Hypothese: Diese Attribute sollten die Konversion vorhersagen. Sie setzen es einmal und hoffen, dass es gut altert.
ML-Scoring ist eine Messung: Diese Attribute haben die Konversion vorhergesagt, basierend auf tatsächlichen Ergebnissen, aktualisiert, wenn neue Ergebnisse eintreffen.
Aber "ML-Scoring ist eine Messung" gilt nur, wenn das Messsystem eine Feedback-Schleife hat. Ohne Neukalibrierung ist das Modell auch eine Hypothese, nur eine, die auf Daten statt auf Intuition trainiert ist.
Die Implementierungen, die nachhaltigen ROI liefern, sind die, bei denen RevOps die Feedback-Schleife besitzt. Sie verfolgen die Modellgenauigkeit vierteljährlich. Sie trainieren neu, wenn die Genauigkeit sinkt. Sie prüfen die Schwellenwert-Performance monatlich. Sie behandeln das Scoring-Modell als Infrastruktur, nicht als einmaliges Projekt.
Mehr erfahren
- Was ist ein AI Sales Operator?
- Automatisiertes Lead Routing: Round Robin vs. AI
- SDR-Workload-Balancing mit AI
- Häufige AI-Lead-Scoring-Fallstricke
- Inbound Lead Triage im Maßstab
- Fehlermodi: Wenn AI Sales Ops nach hinten losgeht
- Scoring und Routing: AI Triage im Maßstab
- Predict: Wie AI Geschäftsergebnisse vorhersagt

Co-Founder, Rework.com
On this page
- Was regelbasiertes Scoring übersieht
- Wie ML Lead Scoring funktioniert (ohne das PhD)
- Der probabilistische Lead-Score-Standard
- Signaltypen nach Konversions-Lift gerankt
- Datenbereitschafts-Checkliste vor dem Einsatz
- Vom Modell-Output zur Routing-Schwelle
- Häufige Fehlermodi
- Anbieter-Überblick
- Die Feedback-Schleife ist das ganze Spiel
- Mehr erfahren