Scoring and Routing: Triagem de AI em Escala
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
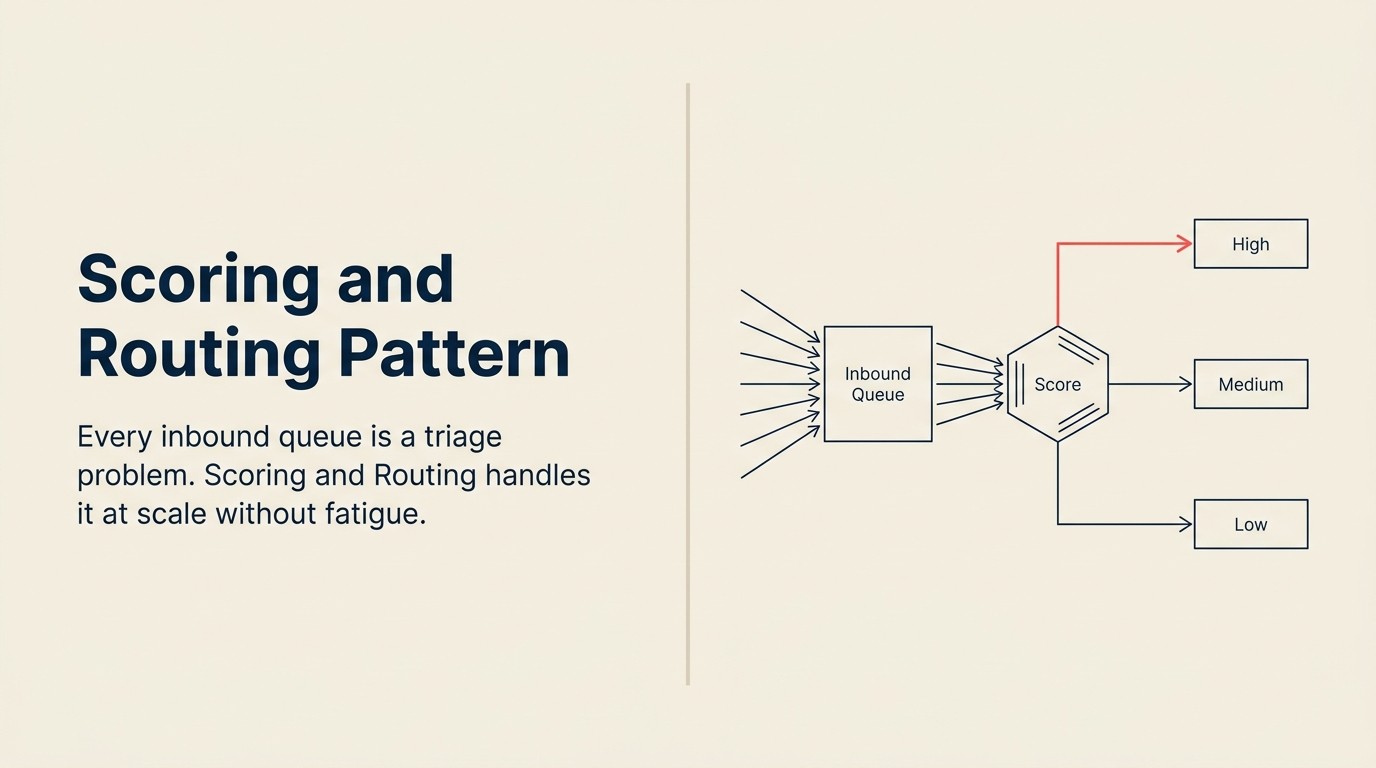
Toda fila de entrada é um problema de triagem.
Leads chegam de uma campanha de webinar: 400 contatos, 40 dos quais são intenção real de compra e 360 que clicaram porque o título era interessante. Tickets de suporte se acumulam durante a noite: 300 novas solicitações, 12 das quais são problemas urgentes de enterprise e 288 que são perguntas de nível 1 já respondidas na sua documentação. Solicitações de empréstimo chegam: 1.200 esta semana, algumas de bons pagadores, algumas não, algumas que parecem limpas mas são fraude.
O trabalho é o mesmo em todos os casos. Separar o sinal do ruído. Priorizar os itens certos. Rotear cada um para a pessoa ou processo certo. Fazer isso rápido o suficiente para que as coisas genuinamente urgentes não fiquem na fila por três horas enquanto um humano lê tudo manualmente.
A triagem manual não escala. Regras baseadas em limites ("rotear qualquer lead de uma empresa com 500+ funcionários para a equipe enterprise") perdem contexto. Elas não conseguem ler o thread de e-mail que veio com o lead. Não conseguem ver que o visitante passou 40 minutos na sua página de preços. Não conseguem levar em conta que esse prospect fez churn após seis meses anteriormente.
Scoring and Routing é o padrão de AI que trata disso. É um dos padrões economicamente mais importantes na AI para negócios, e entendê-lo claramente, incluindo onde ele falha, vale o investimento.
A fórmula: Ingest, Analyze, Predict, Execute
Ingest (registro recebido) captura a entrada bruta: um novo registro de lead, um ticket de suporte enviado, uma candidatura de emprego, um sinistro de seguro enviado. Na maioria das implantações, o passo Ingest não é apenas o item em si. Ele puxa contexto relacionado: o histórico de navegação do lead, o nível e a idade de conta do cliente, o currículo do candidato junto com a descrição da vaga, a impressão digital do dispositivo da transação e o histórico do comerciante.
Analyze (extrair features) transforma a entrada bruta nos sinais que o modelo usará. Para um lead: tamanho da empresa, senioridade do cargo, páginas do site visitadas, domínio de e-mail, setor e engajamento passado. Para um ticket de suporte: classificação de intenção (cobrança? bug? solicitação de feature?), sentimento, nível do cliente e se corresponde a padrões de incidentes conhecidos. Este passo é onde a vantagem da AI começa. A triagem humana olha de 3 a 5 sinais. O modelo avalia de 20 a 50 simultaneamente, incluindo interações entre sinais que um humano não verificaria.
Predict (pontuar) é o modelo aplicando padrões aprendidos às features. O output é uma pontuação: uma probabilidade ou classificação de prioridade. Para leads: probabilidade de fechar em 90 dias. Para tickets: probabilidade de precisar de escalada ou especialista. Para fraude: probabilidade de essa transação ser não autorizada. O passo Predict é correspondência de padrões pura contra resultados históricos, tipicamente implementado com regressão logística, árvores de gradient boosting ou LLMs ajustados para entradas ricas em texto. Ele estava observando o que aconteceu com registros passados que se pareciam com este.
Execute (rotear ou atribuir) pega a pontuação e age sobre ela. Atribui o lead à equipe enterprise. Move o ticket para a fila de segurança. Recusa a transação e aciona um workflow de revisão. Cria uma tarefa no Salesforce. Envia um alerta no Slack para o representante de plantão. Execute é onde a pontuação se torna uma decisão com consequências. É também onde a governança importa mais. O passo Execute tem efeitos reais downstream que nem sempre podem ser facilmente revertidos.
Key Facts: Impacto de Negócio do Scoring and Routing
- A McKinsey estima que a AI em vendas e marketing pode desbloquear de US$ 0,8 a US$ 1,2 trilhão em produtividade incremental, com os players que investem em AI vendo aumentos de receita de 3 a 15% e aumentos de ROI de vendas de 10 a 20% (McKinsey, 2023)
- Empresas B2B que usam lead scoring com AI veem uma melhoria de 2 a 3x na taxa de conversão em seu nível de leads com maior pontuação em comparação com filas triadas manualmente, em implantações maduras com 12+ meses de dados de resultado (Forrester B2B Sales AI Report, 2025)
- Seguradoras que usam o padrão Scoring and Routing relatam redução de 30 a 40% nos custos de processamento de sinistros em sinistros de rotina, ao encaminhar rapidamente sinistros simples e rotear os complexos para ajustadores especialistas (Deloitte Insurance AI Study, 2024)
Cinco exemplos reais em profundidade
1. Lead scoring e atribuição de representantes
O caso de uso canônico. Uma campanha de marketing gera 300 leads recebidos. O modelo ingere cada registro de lead mais dados comportamentais da sua plataforma de analytics do site e de engajamento de e-mail. Ele analisa features como cargo (VP de Vendas pontua mais alto do que Estagiário de Vendas), tamanho da empresa, adequação ao setor, páginas visitadas (página de preços visitada mais de duas vezes é um sinal forte), e-mail aberto em duas horas e histórico de CRM anterior se for um prospect recorrente.
O passo Predict atribui a cada lead uma pontuação de 0 a 100 representando a probabilidade estimada de conversão. O passo Execute roteia leads acima de 75 para seus representantes sênior com SLA no mesmo dia, leads entre 40 e 75 para SDRs para qualificação e leads abaixo de 40 para uma sequência de nutrição automatizada.
As ferramentas aqui incluem Salesforce Einstein Lead Scoring, HubSpot's Predictive Lead Scoring e, no Rework, scoring assistido por AI integrado ao workflow de vendas. Um sistema bem calibrado normalmente desloca 20 a 30% mais Pipeline para leads de alta conversão sem adicionar headcount. Para uma análise aprofundada da implementação específica de vendas, veja lead scoring de AI além de modelos baseados em regras.
2. Priorização de tickets de suporte e roteamento de equipes
Uma empresa SaaS B2B recebe 600 tickets de suporte diariamente. O modelo ingere o texto de cada ticket junto com os dados da conta do cliente que enviou: ARR, nível de contrato, padrões de uso, histórico de tickets anteriores e dias até a renovação. Analyze classifica a intenção (problema de cobrança, bug técnico, solicitação de feature, preocupação de segurança), detecta sentimento e verifica indicadores de risco de escalada.
Predict pontua urgência: clientes de alto ARR com problemas de cobrança três semanas antes da renovação pontuam no topo. Execute roteia tickets de alta urgência para gerentes de contas nomeados, problemas técnicos para o nível de engenharia certo e solicitações de feature de baixa urgência para a fila de backlog. O resultado: problemas enterprise recebem uma resposta em minutos; o ruído de nível 1 não bloqueia o time.
As ferramentas nesse espaço incluem Zendesk AI, inteligência de tickets da Intercom e Freddy AI da Freshdesk.
3. Triagem de currículos e atribuição de recrutadores
Uma empresa publica 12 vagas abertas e recebe 1.800 candidaturas em duas semanas. O modelo ingere cada currículo e a descrição da vaga. Analyze extrai sinais relevantes: anos em funções relevantes, habilidades específicas mencionadas, empresas em que trabalhou, nível de educação, estrutura e completude do currículo. Ele compara cada currículo com o perfil alvo para aquela vaga.
Predict gera uma pontuação de adequação por candidato por vaga. Execute apresenta o quartil superior ao recrutador para aquela vaga, roteia candidatos limítrofes para uma etapa de triagem mais leve e envia ao nível inferior uma resposta automatizada. Nota: esse também é onde o risco de viés é mais alto. Abordado abaixo.
As ferramentas aqui incluem Eightfold, HireVue, Paradox e os add-ons de triagem com AI do Greenhouse.
4. Fast-track de sinistros de seguro vs. revisão humana
Uma seguradora processa 5.000 sinistros mensais. Sinistros simples (colisões menores com documentação fotográfica e responsabilidade clara) podem ser pagos em 48 horas se o modelo lhes der uma pontuação de "fast-track." Sinistros complexos precisam de ajustadores humanos.
O modelo ingere dados do formulário de sinistro, fotos anexadas, histórico do veículo, histórico do segurado e registros de terceiros. Analyze extrai indicadores de complexidade: a responsabilidade está clara? Há feridos? O valor reivindicado corresponde a dados de incidentes comparáveis? O histórico do reclamante mostra padrões anômalos?
Predict pontua cada sinistro em duas dimensões: probabilidade de fast-track (é este rotineiro?) e probabilidade de fraude (corresponde a padrões de fraude conhecidos?). Execute roteia sinistros de fast-track e baixa fraude para pagamento automatizado, sinistros de complexidade média para ajustadores e sinistros de alta probabilidade de fraude para a unidade de investigação especial.
Este é um dos casos de uso mais comprovados para o padrão, com seguradoras relatando redução de 30 a 40% nos custos de processamento na maioria rotineira.
5. Detecção de fraude em pagamentos
O Stripe Radar é um dos sistemas de scoring mais amplamente implantados do mundo, mesmo que a maioria dos operadores o considere "prevenção de fraude" em vez de "AI." Para cada transação de cartão, o modelo do Stripe ingere metadados do cartão, impressão digital do dispositivo, valor da transação, categoria do comerciante, dados geográficos e sinais comportamentais (quão rapidamente o formulário foi preenchido, se os endereços de cobrança e entrega correspondem).
Analyze extrai features. Predict atribui uma pontuação de probabilidade de fraude: 99,5% (quase certamente fraude) ou 0,2% (quase certamente legítimo). Execute age sobre essa pontuação: aprovar, enviar para revisão 3D Secure ou bloquear completamente.
O passo Execute aqui é extremamente de alto risco e acontece em milissegundos. É por isso que a calibração do limite de pontuação é crítica. Um limite definido agressivamente demais bloqueia transações legítimas e gera chargebacks de clientes irritados. Permissivo demais e as perdas por fraude aumentam. O limite certo é uma decisão de negócio, não apenas um parâmetro de modelo.
O Loop Pontuar-Depois-Executar
O Scoring and Routing funciona em duas fases distintas que não devem ser colapsadas: uma fase de pontuação onde cada item recebido recebe uma classificação de prioridade com base em features extraídas e padrões históricos de resultado, e uma fase de execução onde essa classificação aciona uma decisão de roteamento. Pular a fase de pontuação e rotear diretamente a partir de regras (tamanho da empresa, categoria do ticket) perde os sinais contextuais que distinguem um lead enterprise de baixa intenção de um lead PME de alta intenção. Pular o mapeamento de pontuação para limite e usar a confiança bruta do modelo diretamente como gatilho de roteamento produz instabilidade no roteamento conforme o modelo calibra. A estrutura de duas fases, pontuar primeiro depois executar com base em limites validados, é o que torna o padrão confiável em volume.
Modos de falha: o que realmente dá errado
| Modo de falha | Causa raiz | Correção |
|---|---|---|
| Viés nos dados de treinamento | Modelo treinado em resultados historicamente distorcidos (representantes passados fecharam apenas de médio porte; leads enterprise injustamente despriorizados) | Audite distribuições de pontuação entre segmentos. Verifique correlações demográficas nos dados de candidatos ou clientes. |
| Descalibração de limites | Um limite de 70 pontos que envia 60% dos leads de alta intenção para representantes juniores porque o corte não foi validado contra taxas de ganho reais | Valide limites contra resultados. Trate a definição de limites como um item de revisão de negócio trimestral, não uma configuração única. |
| Obsolescência de features | Modelo treinado em dados do T1 perde uma nova linha de produto lançada no T3, então prospects que visitaram a página desse produto não pontuam bem | Configure agendamentos automáticos de retreinamento vinculados a mudanças de produto/segmento. Rastreie drift na distribuição de pontuações ao longo do tempo. |
| Falha no loop de feedback | Ninguém monitora se leads roteados realmente fecharam, tickets foram realmente resolvidos ou sinistros roteados foram realmente pagos sem problemas | Construa rastreamento de resultados no workflow desde o primeiro dia. O modelo precisa de dados históricos rotulados para permanecer calibrado. |
| Inflação de pontuação sem ação | O scoring roda, mas os representantes ignoram a ordem da fila; todos trabalham seu próprio Pipeline | Torne a pontuação visível na interface do workflow (CRM, ferramenta de suporte). Vincule métricas de desempenho da equipe à conformidade com o scoring, não apenas ao output. |
| Erros de roteamento silenciosos | Execute envia itens para a fila errada silenciosamente (ninguém percebe por semanas) | Registre toda decisão de roteamento. Construa um relatório de exceções que traga à tona incompatibilidades entre o nível pontuado e o nível de resultado. |
Os dois modos de falha de maior impacto (descalibração de limites e falha no loop de feedback) também são os menos emocionantes para corrigir. Eles não requerem novos modelos. Requerem disciplina operacional: revisões regulares de quem foi roteado para onde e se essa decisão de roteamento valeu a pena.
O relatório de Operações de AI do Gartner de 2025 descobriu que 68% dos sistemas de scoring de AI que têm desempenho abaixo dos benchmarks iniciais rastreiam a degradação para falha no loop de feedback. O modelo nunca foi retreinado com novos resultados, então continua pontuando leads de 2025 contra padrões aprendidos com dados de fechamento de 2022.
Calibração de limites: a alavanca mais negligenciada
A maioria dos operadores que implanta um sistema de scoring gasta 90% de sua atenção na seleção de modelo e 10% na definição de limites. O retorno sobre esse investimento está invertido.
O trabalho do modelo é classificar os itens. O trabalho do limite é decidir o que essa classificação significa operacionalmente. Um modelo de lead scoring pode classificar com precisão 300 leads de 1 a 300. Mas se você definir o limite de "alta prioridade" em 60 de 100 e 200 dos seus 300 leads pontuarem acima de 60, seus representantes sênior estão sobrecarregados e a segmentação não tem sentido.
A calibração de limites requer três entradas: a distribuição de pontuações dos dados históricos, sua capacidade operacional em cada nível de roteamento (quantos itens seu time enterprise pode tratar por dia?) e seus dados de resultado (qual faixa de pontuação realmente se correlaciona com ganhos?). Com essas três, você pode definir limites que correspondam à realidade operacional, não apenas cortes estatísticos.
Revise os limites pelo menos trimestralmente. Mudanças de mercado, mudanças no mix de campanha e expansão de produto mudam a distribuição de pontuações abaixo de você.
Quando Scoring plus Routing funciona e quando não funciona
Funciona bem quando:
- Você tem resultados históricos rotulados. O modelo aprende com dados passados: quais leads fecharam, quais sinistros foram fraudulentos, quais candidatos foram contratados e ficaram. Sem histórico rotulado não há previsões significativas.
- Você tem volume. Scoring and Routing vale a pena quando o problema de triagem é real. Se você recebe 15 leads por semana, um representante de vendas pode triá-los manualmente em 10 minutos. Se você recebe 500, precisa do padrão.
- A decisão de roteamento mapeia para uma ação clara e executável. "Rotear para a equipe enterprise" é executável. "Tratar este lead com mais cuidado" não é.
- Seus dados são razoavelmente completos e consistentes. Campos ausentes (leads sem cargo, tickets sem link de conta) degradam a qualidade das previsões.
Considere alternativas quando:
vs. Anomaly Agent: Scoring and Routing atribui prioridade dentro de categorias conhecidas. Anomaly Agent sinaliza itens que não pertencem a nenhuma categoria esperada (a incógnita desconhecida). Se você precisa capturar padrões de fraude novos que não se parecem com nenhuma fraude passada, o Anomaly Agent é a ferramenta certa. O Scoring and Routing pontuaria esses casos novos como risco médio porque se assemelham a registros normais, não porque são padrões de fraude familiares.
vs. Workflow Copilot: O Scoring age sem o usuário. O Copilot auxilia o usuário durante seu trabalho. Se seu processo exige julgamento que não pode ser delegado algoritmicamente (uma chamada de vendas complexa de enterprise, uma negociação sutil, uma situação delicada com um cliente), o Copilot auxilia o humano em vez de substituir sua decisão de triagem.
vs. Autonomous Agent: Scoring and Routing toma uma decisão em um ponto de um workflow. Um Autonomous Agent executa um loop de múltiplas etapas, tomando múltiplas decisões para completar uma meta. Scoring and Routing é um módulo dentro de um workflow maior; Autonomous Agents são o workflow completo.
Sinais de ROI: como medir se está funcionando
| Métrica | O que mede | Benchmark plausível |
|---|---|---|
| Velocidade para o primeiro contato | Tempo do envio do lead ao primeiro alcance do representante | Redução de 50 a 70% vs. fila manual |
| Utilização de representantes por nível | Participação do tempo do representante enterprise em leads pontuados como enterprise | Baseline: ~40%. Com scoring: 65 a 80% |
| Taxa de ganho: pontuado vs. não pontuado | Comparação da taxa de conversão entre faixas de pontuação alta/média/baixa | A faixa alta deve ter 2 a 3x a taxa de ganho da faixa baixa em implantações maduras |
| Tempo de resolução de tickets por caminho de roteamento | Tickets roteados por AI vs. triados manualmente | Redução de 20 a 35% no tempo de resolução para os roteados por AI |
| Taxa de falsos positivos | Itens roteados para a fila prioritária que não mereciam prioridade | Rastreie trimestralmente; meta <15% de falsos positivos no nível enterprise |
| Drift na distribuição de pontuações | Se a distribuição de pontuações do modelo está mudando ao longo do tempo | Sinalizar se a pontuação média mudar mais de 10 pontos trimestre a trimestre |
A comparação de taxa de ganho entre leads pontuados e não pontuados é seu ponto de prova mais forte. Se leads na faixa de pontuação superior fecham a 28% e leads na faixa inferior fecham a 7%, o modelo está valendo a pena. Se esses números forem semelhantes, o modelo não está discriminando de forma útil, e você tem um problema de dados de treinamento ou features.
Requisitos de governança
Scoring and Routing toca resultados econômicos das pessoas: comissão dos representantes de vendas, ofertas de emprego dos candidatos, aprovação ou recusa dos clientes. Isso não é razão para evitá-lo. É razão para governá-lo bem.
Audite o modelo trimestralmente. Verifique distribuições de pontuações em segmentos demográficos, geográficos e firmográficos. Se seu modelo de lead scoring sistematicamente dá pontuações menores a leads de regiões ou setores específicos sem uma razão de negócio, você tem um problema de viés mesmo que o modelo seja tecnicamente "preciso."
Defina a substituição humana claramente. Qualquer representante deve poder sinalizar um lead de baixa pontuação que acredita ser de alta intenção. Qualquer recrutador deve poder mover um currículo para a próxima rodada manualmente. O processo de substituição deve ser registrado para que você possa verificar se as substituições diferem sistematicamente das previsões do modelo e se as substituições estavam certas.
Cadência de retreinamento. Para a maioria das aplicações de negócio, o retreinamento trimestral é um padrão razoável. Mensal se seu mercado muda rapidamente. Anual é quase sempre muito lento. Você está pontuando prospects de 2025 contra um modelo de 2023.
Documentação para setores regulados. Em serviços financeiros, empréstimos, seguros e contratações, as decisões de scoring automatizadas podem exigir explicabilidade sob ECOA, GDPR Artigo 22 ou leis estaduais de AI. Conheça sua jurisdição. "O modelo disse isso" não é uma explicação defensável para uma decisão adversa de crédito.
Cenário de fornecedores e ferramentas
| Caso de uso | Principais ferramentas |
|---|---|
| Lead scoring | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Roteamento de tickets de suporte | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Triagem de candidatos | Eightfold, HireVue, Paradox, Greenhouse AI |
| Detecção de fraude | Stripe Radar, Kount, Featurespace, Sardine |
| Sinistros de seguro | Shift Technology, Tractable, Cape Analytics |
| Infraestrutura de scoring personalizado | Pinecone (embeddings vetoriais para similaridade de features), Tecton (feature stores), AWS SageMaker, Azure ML |
Para equipes construindo scoring personalizado: Pinecone e Weaviate são frequentemente usados para recuperação de features baseada em similaridade, mas o modelo de scoring principal geralmente é uma árvore de gradient boosting (LightGBM, XGBoost) ou um LLM ajustado para entradas ricas em texto. A infraestrutura importa menos do que a qualidade dos dados históricos rotulados e o rigor da calibração de limites.
Conexão com o AI Sales Operator
Scoring and Routing é um dos quatro padrões no núcleo do AI Sales Operator (Nível 3 no ACE Framework). Nesse contexto, o lead scoring não é apenas um recurso de automação de marketing. É a camada de decisão no topo do Funnel que determina como o dia de cada representante é organizado. O conceito de AI Sales Operator explica como esses quatro padrões funcionam juntos na prática.
As organizações de vendas de melhor desempenho usam o scoring não apenas para priorizar leads recebidos, mas para priorizar o tempo dos representantes em todo o Pipeline: quais negócios avançar, quais contas engajar para expansão, quais renovações estão em risco de churn. Quando o Scoring and Routing se conecta ao Meeting Intelligence (análise de chamadas) e ao Workflow Copilot (sugestões integradas ao CRM), os três padrões juntos formam um loop fechado: a AI pontua a oportunidade, a AI analisa a chamada, a AI sugere a próxima ação.
Essa arquitetura é o que separa os times de vendas com AI dos times que apenas têm uma ferramenta de AI para atribuição de leads.
Rework Analysis: A maioria dos times que implanta lead scoring acerta o modelo e erra as operações. O modelo pontua os leads com precisão. Mas os limites foram definidos uma vez no lançamento, os dados de resultado nunca foram alimentados de volta e o time nunca auditou se leads de alta pontuação estão de fato fechando a uma taxa maior do que leads de baixa pontuação. Seis meses depois, os representantes pararam de confiar na ordem da fila e estão trabalhando seu próprio Pipeline. O ROI do modelo evapora não porque a AI falhou, mas porque o loop de feedback nunca foi construído. Scoring and Routing requer dois compromissos organizacionais, não apenas um: um sistema de scoring e uma revisão trimestral de resultados que o mantém calibrado. Times que assumem os dois compromissos veem as melhorias de conversão de 2 a 3x. Times que assumem apenas o primeiro veem um retorno gradual à triagem manual.
Perguntas Frequentes
O que é o padrão de AI Scoring and Routing?
Scoring and Routing é um padrão de AI que prioriza e atribui automaticamente itens recebidos (leads, tickets, candidaturas, sinistros) usando uma fórmula de quatro passos: Ingest registros e contexto recebidos, Analyze features extraídas, Predict uma pontuação de prioridade e Execute uma decisão de roteamento. O padrão trata triagem em volumes que a revisão manual não consegue sustentar, e avalia de 20 a 50 sinais simultaneamente versus os 3 a 5 que um humano lê durante a triagem manual.
Como funciona o lead scoring com AI?
O lead scoring com AI ingere cada registro de lead mais dados comportamentais (páginas visitadas, engajamento de e-mail, tempo de navegação em preços), extrai features (tamanho da empresa, senioridade do cargo, setor, histórico de CRM passado) e aplica um modelo treinado para atribuir uma pontuação de probabilidade. O modelo aprendeu com resultados históricos: quais leads passados com perfis semelhantes realmente fecharam. A pontuação aciona o roteamento: pontuações altas vão para representantes sênior com SLA no mesmo dia, pontuações médias vão para SDRs para qualificação, pontuações baixas vão para sequências de nutrição automatizadas.
Quais são os modos de falha mais comuns no Scoring and Routing?
As duas falhas de maior impacto são descalibração de limites e falha no loop de feedback. A descalibração de limites envia a proporção errada de leads para cada nível de roteamento, seja sobrecarregando representantes sênior com leads de qualidade média ou sub-roteando prospects genuinamente de alta intenção. A falha no loop de feedback ocorre quando os dados de resultado (quem fechou, quem fez churn, quais sinistros foram fraudulentos) não são alimentados de volta para retreinar o modelo, fazendo com que ele pontue registros atuais contra padrões históricos desatualizados. O Gartner descobriu que 68% dos sistemas de scoring com desempenho abaixo do esperado rastreiam a degradação para falha no loop de feedback.
O que é o Loop Pontuar-Depois-Executar?
O Loop Pontuar-Depois-Executar é a estrutura de duas fases do padrão Scoring and Routing: primeiro uma fase de pontuação onde cada item recebe uma classificação de prioridade com base em features extraídas e padrões históricos de resultado, depois uma fase de execução onde limites validados traduzem essa classificação em uma decisão de roteamento. Colapsar as duas fases, como rotear diretamente a partir de limites baseados em regras sem scoring do modelo, perde os sinais contextuais que distinguem um lead enterprise de baixa intenção de um lead PME de alta intenção.
Quando você deve usar Scoring and Routing vs. um Anomaly Agent?
Use Scoring and Routing quando precisar triar itens dentro de categorias conhecidas: atribuindo prioridade entre leads, tickets ou candidaturas que seguem padrões familiares. Use Anomaly Agent quando precisar capturar itens que não pertencem a nenhuma categoria esperada, como padrões de fraude novos que não se assemelham a fraudes passadas. O Scoring and Routing pontuaria fraudes novas como risco médio porque se parecem com uma transação normal. O Anomaly Agent as sinaliza especificamente porque desviam da linha de base estatística.
Qual ROI você deve esperar do Scoring and Routing?
Implantações maduras com 12+ meses de dados de resultado veem melhoria de 2 a 3x na taxa de conversão no nível de leads de maior pontuação. Times de vendas veem redução de 50 a 70% na velocidade para o primeiro contato. O roteamento de tickets de suporte normalmente reduz o tempo de resolução em 20 a 35%. Seguradoras relatam redução de 30 a 40% nos custos de processamento de sinistros. Alcançar esses benchmarks requer tanto um sistema de scoring calibrado quanto uma revisão trimestral de resultados que retreina o modelo com novos dados de fechamento.
Saiba mais

Co-Founder, Rework.com
On this page
- A fórmula: Ingest, Analyze, Predict, Execute
- Cinco exemplos reais em profundidade
- 1. Lead scoring e atribuição de representantes
- 2. Priorização de tickets de suporte e roteamento de equipes
- 3. Triagem de currículos e atribuição de recrutadores
- 4. Fast-track de sinistros de seguro vs. revisão humana
- 5. Detecção de fraude em pagamentos
- O Loop Pontuar-Depois-Executar
- Modos de falha: o que realmente dá errado
- Calibração de limites: a alavanca mais negligenciada
- Quando Scoring plus Routing funciona e quando não funciona
- Sinais de ROI: como medir se está funcionando
- Requisitos de governança
- Cenário de fornecedores e ferramentas
- Conexão com o AI Sales Operator
- Saiba mais