Scoring and Routing: Triage AI pada Skala
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
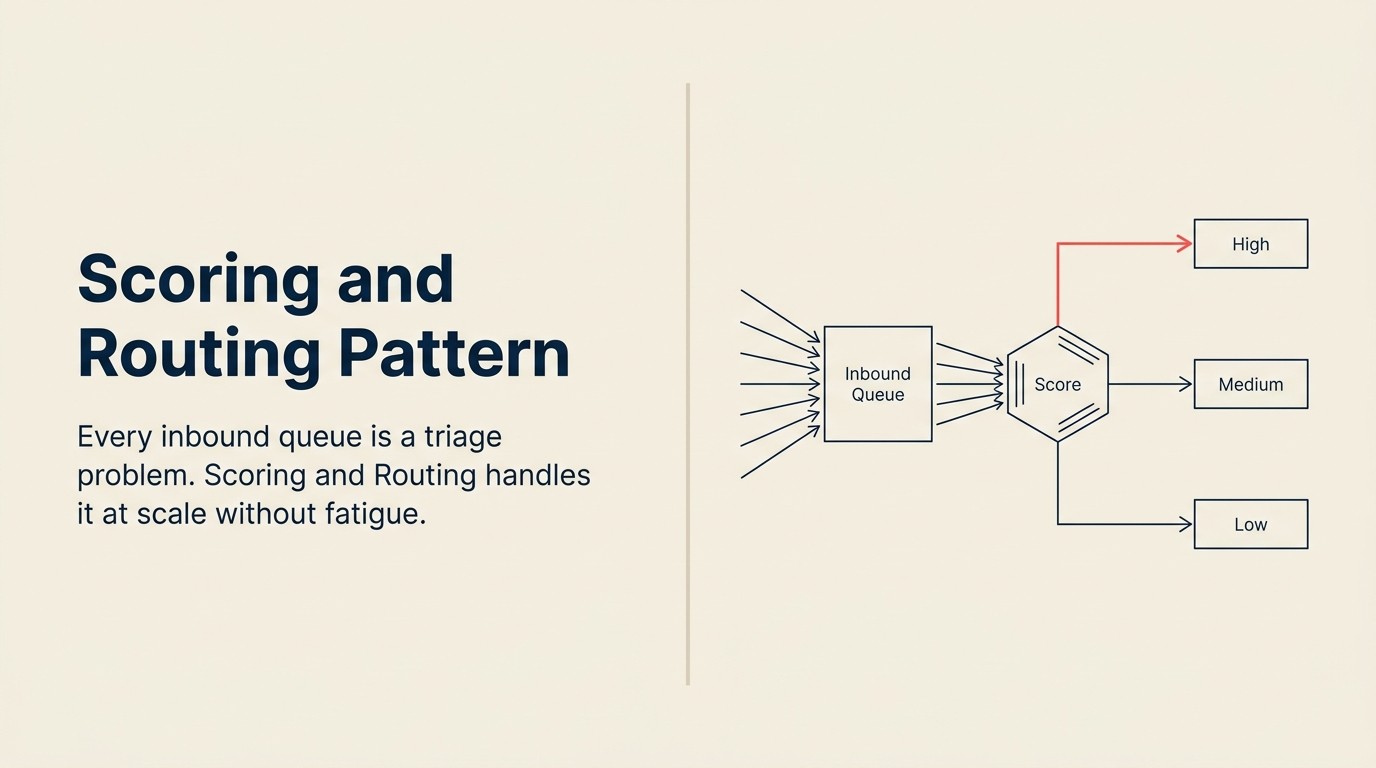
Setiap baris gilir masuk adalah masalah triage.
Lead tiba daripada kempen webinar: 400 kenalan, 40 daripadanya adalah niat membeli sebenar dan 360 yang klik kerana tajuk itu menarik. Tiket sokongan bertimbun semalam: 300 permintaan baru, 12 daripadanya adalah isu enterprise yang mendesak dan 288 adalah soalan L1 yang sudah dijawab dalam dokumen Anda. Permohonan pinjaman masuk: 1,200 minggu ini, sesetengahnya layak mendapat kredit, sesetengahnya tidak, beberapa yang kelihatan bersih tetapi merupakan penipuan.
Tugasan adalah sama dalam setiap kes. Asingkan isyarat daripada bunyi bising. Utamakan item yang betul. Halakan setiap satu kepada orang atau proses yang betul. Lakukan cukup cepat supaya perkara yang benar-benar mendesak tidak duduk dalam baris gilir selama tiga jam sementara manusia membaca semua perkara secara manual.
Triage manual tidak berskala. Peraturan berasaskan ambang ("halakan mana-mana lead dari syarikat dengan 500+ pekerja ke pasukan enterprise") terlepas konteks. Mereka tidak dapat membaca rangkaian e-mel yang datang bersama lead. Mereka tidak dapat melihat bahawa pelawat itu menghabiskan 40 minit pada halaman harga Anda. Mereka tidak dapat mengambil kira bahawa prospek ini sebelumnya telah churn selepas enam bulan.
Scoring and Routing adalah AI pattern yang mengendalikan ini. Ia adalah salah satu patterns yang paling penting secara ekonomi dalam AI perniagaan, dan memahaminya dengan jelas, termasuk di mana ia silap, adalah berbaloi pelaburannya.
Formula: Ingest, Analyze, Predict, Execute
Ingest (rekod masuk) menangkap input mentah: rekod lead baru, tiket sokongan yang dihantar, permohonan kerja, tuntutan insurans yang dihantar. Dalam kebanyakan penempatan, langkah Ingest bukan hanya item itu sendiri. Ia menarik konteks berkaitan: sejarah pelayaran lead, peringkat dan usia akaun pelanggan, resume pemohon di samping keterangan kerja, cap jari peranti transaksi dan sejarah peniaga.
Analyze (ekstrak ciri) mengubah input mentah kepada isyarat yang akan digunakan oleh model. Untuk lead: saiz syarikat, kanan jawatan, halaman web yang dilawati, domain e-mel, industri, dan penglibatan lalu. Untuk tiket sokongan: pengklasifikasian niat (pengebilan? pepijat? permintaan ciri?), sentimen, peringkat pelanggan, dan sama ada ia sepadan dengan mana-mana corak insiden yang diketahui. Langkah ini adalah di mana kelebihan AI bermula. Triage manusia melihat 3-5 isyarat. Model menilai 20-50 secara serentak, termasuk interaksi antara isyarat yang tidak akan disemak oleh manusia.
Predict (skor) adalah model yang menerapkan corak yang dipelajari kepada ciri. Keluaran adalah skor: kebarangkalian atau kedudukan keutamaan. Untuk lead: kebarangkalian menutup dalam 90 hari. Untuk tiket: kebarangkalian ini memerlukan eskalasi atau pakar. Untuk penipuan: kebarangkalian transaksi ini tidak dibenarkan. Langkah Predict adalah pemadanan corak tulen terhadap hasil sejarah, biasanya dilaksanakan dengan regresi logistik, pokok yang diperkuat kecerunan, atau LLM yang dilaraskan halus untuk input kaya teks. Ia telah memerhati apa yang berlaku kepada rekod lalu yang kelihatan seperti ini.
Execute (halakan atau tugaskan) mengambil skor dan bertindak atasnya. Tugaskan lead kepada pasukan enterprise. Pindahkan tiket ke baris gilir keselamatan. Tolak transaksi dan pencetuskan aliran kerja semakan. Cipta tugasan Salesforce. Hantar makluman Slack kepada wakil on-call. Execute adalah di mana skor menjadi keputusan dengan akibat. Di sinilah tadbir urus paling penting. Langkah Execute mempunyai kesan hiliran sebenar yang tidak selalu mudah dibalikkan.
Key Facts: Impak Perniagaan Scoring and Routing
- McKinsey menganggarkan AI dalam jualan dan pemasaran boleh membuka kunci $0.8 hingga $1.2 trilion dalam produktiviti tambahan, dengan pemain yang melabur dalam AI melihat peningkatan hasil 3-15% dan peningkatan ROI jualan 10-20% (McKinsey, 2023)
- Syarikat B2B yang menggunakan pemarkahan lead berkuasa AI melihat peningkatan kadar penukaran 2-3x dalam peringkat lead yang mendapat skor tertinggi berbanding baris gilir yang ditriage secara manual, dalam penempatan matang dengan data hasil 12+ bulan (Forrester B2B Sales AI Report, 2025)
- Syarikat insurans yang menggunakan pattern Scoring and Routing melaporkan pengurangan 30-40% dalam kos pemprosesan tuntutan pada tuntutan rutin, dengan mempercepatkan tuntutan bersih dan menghalakan yang kompleks kepada pelarasan pakar (Deloitte Insurance AI Study, 2024)
Lima contoh sebenar secara mendalam
1. Pemarkahan lead dan tugasan wakil
Kes penggunaan yang tipikal. Kempen pemasaran mendorong 300 lead masuk. Model menelan setiap rekod lead ditambah data tingkah laku daripada analitik tapak dan platform penglibatan e-mel Anda. Ia menganalisis ciri seperti jawatan (VP Jualan mendapat skor lebih tinggi daripada Perantis Jualan), saiz syarikat, keserasian industri, halaman yang dilawati (halaman harga dilawati lebih daripada dua kali adalah isyarat yang kuat), e-mel dibuka dalam dua jam, dan sejarah CRM lalu jika ini adalah prospek yang kembali.
Langkah Predict menugaskan setiap lead skor daripada 0-100 yang mewakili anggaran kebarangkalian penukaran. Langkah Execute menghalakan lead di atas 75 kepada wakil kanan Anda dengan SLA hari yang sama, lead antara 40-75 kepada SDR untuk kelayakan, dan lead di bawah 40 kepada urutan pemeliharaan automatik.
Tooling di sini termasuk Salesforce Einstein Lead Scoring, HubSpot's Predictive Lead Scoring, dan dalam Rework, pemarkahan berbantuan AI yang dibina ke dalam aliran kerja jualan. Sistem yang ditentukur dengan baik biasanya mengalihkan 20-30% lebih banyak pipeline kepada lead berpenukaran tinggi tanpa menambah headcount.
2. Pengutamaan tiket sokongan dan penghalaan pasukan
Sebuah syarikat B2B SaaS menerima 600 tiket sokongan setiap hari. Model menelan teks setiap tiket bersama data akaun pelanggan yang menghantar: ARR, peringkat kontrak, corak penggunaan, sejarah tiket lalu, dan hari untuk pembaharuan. Analyze mengklasifikasikan niat (isu pengebilan, pepijat teknikal, permintaan ciri, kebimbangan keselamatan), mengesan sentimen, dan menyemak petunjuk risiko eskalasi.
Predict memberi skor kemendesakan: pelanggan ARR tinggi dengan isu pengebilan tiga minggu sebelum pembaharuan mendapat skor teratas. Execute menghalakan tiket kemendesakan tinggi kepada pengurus akaun yang dinamakan, isu teknikal kepada peringkat kejuruteraan yang betul, dan permintaan ciri kemendesakan rendah kepada baris gilir tunggakan. Hasilnya: isu enterprise mendapat respons dalam minit; bunyi bising L1 tidak menyekat pasukan.
Alat dalam ruang ini termasuk Zendesk AI, perisikan tiket Intercom, dan Freddy AI Freshdesk.
3. Penyaringan resume dan tugasan perekrut
Sebuah syarikat menyiarkan 12 peranan terbuka dan menerima 1,800 permohonan dalam dua minggu. Model menelan setiap resume dan keterangan kerja. Analyze mengekstrak isyarat relevan: tahun dalam peranan yang relevan, kemahiran khusus yang disebutkan, syarikat yang telah bekerja, tahap pendidikan, struktur dan kelengkapan resume. Ia membandingkan setiap resume terhadap profil sasaran untuk peranan tersebut.
Predict mengeluarkan skor keserasian per pemohon per peranan. Execute mengemukakan kuartil teratas kepada perekrut untuk peranan tersebut, menghalakan calon sempadan kepada langkah penyaringan yang lebih ringan, dan menghantar peringkat bawah respons automatik. Nota: di sinilah risiko berat sebelah juga paling tinggi. Dibincangkan di bawah.
Alat di sini termasuk Eightfold, HireVue, Paradox, dan tambahan penyaringan AI Greenhouse.
4. Fast-track tuntutan insurans berbanding semakan manusia
Syarikat insurans memproses 5,000 tuntutan sebulan. Tuntutan mudah (kemalangan bumper dengan dokumentasi foto dan liabiliti yang jelas) boleh dibayar dalam 48 jam jika model memberi mereka skor "fast-track." Tuntutan yang kompleks memerlukan pelaras manusia.
Model menelan data borang tuntutan, foto yang dilampirkan, sejarah kenderaan, sejarah pemegang polisi, dan rekod pihak ketiga. Analyze mengekstrak petunjuk kerumitan: adakah liabiliti jelas? Adakah terdapat kecederaan? Adakah jumlah yang dituntut sepadan dengan data insiden yang setanding? Adakah sejarah penuntut menunjukkan corak yang tidak normal?
Predict memberi skor setiap tuntutan pada dua dimensi: kebarangkalian fast-track (adakah ini rutin?) dan kebarangkalian penipuan (adakah ini sepadan dengan corak penipuan yang diketahui?). Execute menghalakan tuntutan fast-track, penipuan rendah ke pembayaran automatik, tuntutan kerumitan sederhana kepada pelaras, dan tuntutan kebarangkalian penipuan tinggi kepada unit siasatan khas.
Ini adalah salah satu kes penggunaan yang paling terbukti untuk pattern ini, dengan syarikat insurans melaporkan pengurangan 30-40% dalam kos pemprosesan pada majoriti rutin.
5. Pengesanan penipuan dalam pembayaran
Stripe Radar adalah salah satu sistem pemarkahan yang paling meluas digunakan di dunia, walaupun kebanyakan pengendali menganggapnya sebagai "pencegahan penipuan" berbanding "AI." Untuk setiap transaksi kad, model Stripe menelan metadata kad, cap jari peranti, jumlah transaksi, kategori peniaga, data geografi, dan isyarat tingkah laku (seberapa cepat borang diisi, sama ada alamat pengebilan dan penghantaran sepadan).
Analyze mengekstrak ciri. Predict menugaskan skor kebarangkalian penipuan: 99.5% (hampir pasti penipuan) atau 0.2% (hampir pasti sah). Execute bertindak atas skor itu: lulus, hantar ke semakan 3D Secure, atau sekat sepenuhnya.
Langkah Execute di sini adalah berisiko tinggi dan berlaku dalam milisaat. Itulah sebabnya penentukuran ambang skor adalah kritikal. Ambang yang ditetapkan terlalu agresif menyekat transaksi yang sah dan menjana chargeback daripada pelanggan yang marah. Terlalu longgar dan kerugian penipuan meningkat. Ambang yang betul adalah keputusan perniagaan, bukan sekadar parameter model.
Gelung Skor-Kemudian-Execute
Scoring and Routing berfungsi dalam dua fasa yang berbeza yang tidak boleh digabungkan: fasa pemarkahan di mana setiap item masuk menerima kedudukan keutamaan berdasarkan ciri yang diekstrak dan corak hasil sejarah, dan fasa execute di mana kedudukan itu mendorong keputusan penghalaan. Menggabungkan dua fasa, seperti menghalakan terus daripada peraturan berasaskan ambang tanpa pemarkahan model, terlepas isyarat kontekstual yang membezakan lead enterprise dengan niat rendah daripada lead UKM dengan niat tinggi. Menghalakan terus daripada keyakinan model mentah tanpa pemetaan skor-ke-ambang yang disahkan menghasilkan ketidakstabilan penghalaan semasa model menentukur. Struktur dua fasa, skor dahulu kemudian execute berdasarkan ambang yang disahkan, adalah yang menjadikan pattern boleh dipercayai pada volum.
Mod kegagalan: apa yang sebenarnya silap
| Mod kegagalan | Punca utama | Pembetulan |
|---|---|---|
| Berat sebelah data latihan | Model dilatih pada hasil yang condong secara historis (wakil lalu hanya menutup daripada pasaran sederhana; lead enterprise dikurangkan keutamaan secara tidak adil) | Audit taburan skor merentasi segmen. Semak korelasi demografik dalam data calon atau pelanggan. |
| Salah penentukuran ambang | Ambang 70 mata yang menghantar 60% lead dengan niat tinggi kepada wakil junior kerana ambang tidak disahkan terhadap kadar menang sebenar | Sahkan ambang terhadap hasil. Anggap penetapan ambang sebagai item semakan perniagaan suku tahunan, bukan persediaan sekali sahaja. |
| Kelapukan ciri | Model yang dilatih pada data Q1 terlepas lini produk baru yang dilancarkan dalam Q3, jadi prospek yang melawati halaman produk itu tidak mendapat skor yang baik | Sediakan jadual latihan semula automatik yang dikaitkan dengan perubahan produk/segmen. Jejak penyimpangan taburan skor dari masa ke masa. |
| Kegagalan gelung maklum balas | Tiada siapa yang memantau sama ada lead yang dihalakan benar-benar ditutup, tiket benar-benar diselesaikan, atau tuntutan yang dihalakan benar-benar dibayar dengan bersih | Bina penjejakan hasil ke dalam aliran kerja dari hari pertama. Model memerlukan data sejarah berlabel untuk kekal ditentukur. |
| Inflasi skor tanpa tindakan | Pemarkahan berjalan, tetapi wakil mengabaikan susunan baris gilir; semua orang bekerja pada pipeline mereka sendiri | Jadikan skor kelihatan dalam antara muka aliran kerja (CRM, alat sokongan). Kaitkan metrik prestasi pasukan kepada pematuhan pemarkahan, bukan hanya keluaran. |
| Ralat penghalaan yang senyap | Execute menghantar item ke baris gilir yang salah secara senyap (tiada yang menyedari selama berminggu-minggu) | Log setiap keputusan penghalaan. Bina laporan pengecualian yang mengemukakan ketidakpadanan antara peringkat yang diberi skor dan peringkat hasil. |
Dua mod kegagalan dengan impak tertinggi (salah penentukuran ambang dan kegagalan gelung maklum balas) juga adalah yang paling tidak menarik untuk dibaiki. Mereka tidak memerlukan model baru. Mereka memerlukan disiplin operasi: semakan tetap tentang siapa yang dihalakan ke mana, dan sama ada keputusan penghalaan itu berhasil.
Laporan AI Operations Gartner 2025 mendapati bahawa 68% sistem pemarkahan AI yang berprestasi di bawah penanda aras awal mereka menjejak degradasi kepada kegagalan gelung maklum balas. Model tidak pernah dilatih semula pada hasil baru, jadi ia terus memberi skor lead 2025 terhadap corak yang dipelajari daripada data closed-won 2022.
Penentukuran ambang: tuas yang paling diabaikan
Kebanyakan pengendali yang menggunakan sistem pemarkahan menghabiskan 90% perhatian mereka pada pemilihan model dan 10% pada penetapan ambang. Pulangan pelaburan itu adalah terbalik.
Tugasan model adalah untuk menilai item. Tugasan ambang adalah untuk memutuskan apa yang kedudukan itu bermaksud secara operasi. Model pemarkahan lead mungkin memberi kedudukan dengan tepat kepada 300 lead dari 1 hingga 300. Tetapi jika Anda menetapkan ambang "keutamaan tinggi" pada 60 daripada 100 dan 200 daripada 300 lead Anda mendapat skor di atas 60, wakil kanan Anda terlalu sibuk dan segmentasi itu tidak bermakna.
Penentukuran ambang memerlukan tiga input: taburan skor data sejarah, kapasiti operasi Anda di setiap peringkat penghalaan (berapa banyak item yang boleh dikendalikan pasukan enterprise Anda setiap hari?), dan data hasil Anda (julat skor mana yang sebenarnya berkorelasi dengan kemenangan?). Apabila Anda mempunyai tiga ini, Anda boleh menetapkan ambang yang sepadan dengan realiti operasi, bukan hanya potongan statistik.
Semak semula ambang sekurang-kurangnya setiap suku tahun. Perubahan pasaran, perubahan campuran kempen, dan pengembangan produk semuanya mengalihkan taburan skor di bawah Anda.
Bila Scoring plus Routing berfungsi, dan bila tidak
Berfungsi dengan baik apabila:
- Anda mempunyai hasil sejarah berlabel. Model belajar daripada data lalu: lead mana yang ditutup, tuntutan mana yang penipuan, pemohon mana yang diambil bekerja dan kekal. Tiada sejarah berlabel bermakna tiada ramalan yang bermakna.
- Anda mempunyai volum. Scoring and Routing berhasil apabila masalah triage adalah nyata. Jika Anda menerima 15 lead seminggu, wakil jualan boleh membuat triage secara manual dalam 10 minit. Jika Anda menerima 500, Anda memerlukan pattern itu.
- Keputusan penghalaan memetakan kepada tindakan yang jelas dan boleh dilaksanakan. "Halakan ke pasukan enterprise" boleh dilaksanakan. "Layani lead ini dengan lebih berhati-hati" tidak.
- Data Anda agak lengkap dan konsisten. Medan yang hilang (lead tanpa jawatan, tiket tanpa pautan akaun) menurunkan kualiti ramalan.
Pertimbangkan alternatif apabila:
berbanding Anomaly Agent: Scoring and Routing menugaskan keutamaan dalam kategori yang diketahui. Anomaly Agent menandakan item yang tidak tergolong dalam kategori yang dijangka (unknown unknown). Jika Anda perlu menangkap corak penipuan baharu yang tidak kelihatan seperti penipuan lalu, Anomaly Agent adalah alat yang betul. Scoring and Routing akan memberi skor kes baharu itu sebagai risiko sederhana kerana ia menyerupai rekod biasa, bukan kerana ia adalah corak penipuan yang biasa.
berbanding Workflow Copilot: Pemarkahan bertindak tanpa pengguna. Copilot membantu pengguna semasa kerja mereka. Jika proses Anda memerlukan pertimbangan yang tidak boleh didelegasikan secara algoritmik (panggilan jualan enterprise yang kompleks, rundingan yang halus, situasi pelanggan yang sensitif), Copilot membantu manusia berbanding menggantikan keputusan triage mereka.
berbanding Autonomous Agent: Scoring and Routing membuat satu keputusan pada satu titik dalam aliran kerja. Autonomous Agent menjalankan gelung berbilang langkah, membuat pelbagai keputusan untuk mencapai matlamat. Scoring and Routing adalah modul dalam aliran kerja yang lebih besar; Autonomous Agents adalah aliran kerja penuh.
Isyarat ROI: cara mengukur sama ada ia berfungsi
| Metrik | Apa yang diukur | Penanda aras yang munasabah |
|---|---|---|
| Kelajuan-kenalan-pertama | Masa dari penghantaran lead kepada jangkauan wakil pertama | Pengurangan 50-70% berbanding baris gilir manual |
| Penggunaan wakil mengikut peringkat | Bahagian masa wakil enterprise pada lead yang diberi skor enterprise | Garis asas: ~40%. Dengan pemarkahan: 65-80% |
| Kadar menang: diberi skor berbanding tidak diberi skor | Perbandingan kadar penukaran merentasi band skor tinggi/sederhana/rendah | Band tinggi harus 2-3x kadar menang band rendah dalam penempatan matang |
| Masa penyelesaian tiket mengikut laluan penghalaan | Tiket yang dihalakan AI berbanding yang disusun secara manual | Pengurangan 20-35% dalam masa-untuk-penyelesaian bagi yang dihalakan AI |
| Kadar positif palsu | Item yang dihalakan ke baris gilir keutamaan yang tidak memerlukan keutamaan | Jejak setiap suku tahun; sasarkan <15% positif palsu dalam peringkat enterprise |
| Penyimpangan taburan skor | Sama ada taburan skor model beranjak dari masa ke masa | Tandakan jika skor min berubah lebih daripada 10 mata suku-ke-suku |
Perbandingan kadar menang antara lead yang diberi skor dan tidak diberi skor adalah bukti terkuat Anda. Jika lead dalam band skor teratas ditutup pada 28% dan lead dalam band skor terbawah ditutup pada 7%, model itu membuktikan nilainya. Jika nombor itu serupa, model tidak membeza dengan berguna, dan Anda mempunyai masalah data latihan atau ciri.
Keperluan tadbir urus
Scoring and Routing menyentuh hasil ekonomi orang: komisyen wakil jualan, tawaran kerja calon, kelulusan atau penolakan pelanggan. Itu bukan alasan untuk mengelakkannya. Ia adalah alasan untuk mentadbirnya dengan baik.
Audit model setiap suku tahun. Semak taburan skor merentasi segmen demografik, geografi, dan firmografi. Jika model pemarkahan lead Anda secara sistematik memberi skor yang lebih rendah kepada lead dari kawasan atau industri tertentu tanpa alasan perniagaan, Anda mempunyai masalah berat sebelah walaupun model itu secara teknikal "tepat."
Takrifkan penggantian manusia dengan jelas. Mana-mana wakil harus dapat menandakan lead yang diberi skor rendah yang diyakini mereka berintent tinggi. Mana-mana perekrut harus dapat memindahkan resume ke pusingan seterusnya secara manual. Proses penggantian harus dilog supaya Anda boleh menyemak sama ada penggantian secara sistematik berbeza daripada ramalan model, dan sama ada penggantian itu betul.
Kadang latihan semula. Untuk kebanyakan aplikasi perniagaan, latihan semula suku tahunan adalah lalai yang munasabah. Bulanan jika pasaran Anda berubah dengan cepat. Tahunan hampir selalu terlalu perlahan. Anda memberi skor prospek 2025 terhadap model 2023.
Dokumentasi untuk industri yang dikawal selia. Dalam perkhidmatan kewangan, pinjaman, insurans, dan pengambilan pekerja, keputusan pemarkahan automatik mungkin memerlukan kejelasan di bawah ECOA, GDPR Artikel 22, atau undang-undang AI peringkat negeri. Ketahui bidang kuasa Anda. "Model berkata begitu" bukan penjelasan yang boleh dipertahankan untuk keputusan kredit yang merugikan.
Landskap vendor dan tooling
| Kes penggunaan | Alat utama |
|---|---|
| Pemarkahan lead | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Penghalaan tiket sokongan | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Penyaringan calon | Eightfold, HireVue, Paradox, Greenhouse AI |
| Pengesanan penipuan | Stripe Radar, Kount, Featurespace, Sardine |
| Tuntutan insurans | Shift Technology, Tractable, Cape Analytics |
| Infrastruktur pemarkahan tersuai | Pinecone (embeddings vektor untuk kesamaan ciri), Tecton (storan ciri), AWS SageMaker, Azure ML |
Untuk pasukan yang membina pemarkahan tersuai: Pinecone dan Weaviate sering digunakan untuk pengambilan semula ciri berasaskan kesamaan, tetapi model pemarkahan teras biasanya adalah pokok yang diperkuat kecerunan (LightGBM, XGBoost) atau LLM yang dilaraskan halus untuk input kaya teks. Infrastruktur kurang penting berbanding kualiti data sejarah berlabel dan ketelitian penentukuran ambang.
Sambungan kepada AI Sales Operator
Scoring and Routing adalah salah satu daripada empat patterns di teras AI Sales Operator (Tahap 3 dalam ACE Framework). Dalam konteks itu, pemarkahan lead bukan sekadar ciri automasi pemasaran. Ia adalah lapisan keputusan hadapan-corong yang menentukan cara setiap hari wakil diatur. Konsep AI Sales Operator menerangkan cara empat patterns ini berfungsi bersama dalam amalan.
Organisasi jualan yang berprestasi tertinggi menggunakan pemarkahan bukan hanya untuk mengutamakan lead masuk tetapi untuk mengutamakan masa wakil merentasi pipeline penuh: tawaran mana yang perlu dimajukan, akaun mana yang perlu dilibatkan untuk pengembangan, pembaharuan mana yang berisiko churn. Apabila Scoring and Routing disambungkan kepada Meeting Intelligence (analisis panggilan) dan Workflow Copilot (cadangan yang terbenam dalam CRM), ketiga-tiga patterns bersama membentuk gelung tertutup: AI memberi skor peluang, AI menganalisis panggilan, AI mencadangkan tindakan seterusnya.
Seni bina itulah yang memisahkan pasukan jualan yang ditambah AI daripada pasukan yang hanya mempunyai alat AI untuk tugasan lead.
Rework Analysis: Kebanyakan pasukan yang menggunakan pemarkahan lead mendapat model yang betul dan mendapat operasi yang salah. Model memberi skor lead dengan tepat. Tetapi ambang telah ditetapkan sekali pada pelancaraan, data hasil tidak pernah dimasukkan semula, dan pasukan tidak pernah mengaudit sama ada lead yang diberi skor tinggi sebenarnya ditutup pada kadar yang lebih tinggi daripada lead yang diberi skor rendah. Enam bulan kemudian, wakil telah berhenti mempercayai susunan baris gilir dan bekerja pada pipeline mereka sendiri. ROI model menguap bukan kerana AI gagal tetapi kerana gelung maklum balas tidak pernah dibina. Scoring and Routing memerlukan dua komitmen organisasi, bukan satu: sistem pemarkahan dan semakan hasil suku tahunan yang mengekalkan penentukurannya. Pasukan yang membuat kedua-dua komitmen melihat peningkatan penukaran 2-3x. Pasukan yang hanya membuat komitmen pertama melihat hanyutan perlahan kembali kepada triage manual.
Soalan Lazim
Apakah pattern AI Scoring and Routing?
Scoring and Routing adalah AI pattern yang secara automatik mengutamakan dan menugaskan item masuk (lead, tiket, permohonan, tuntutan) menggunakan formula empat langkah: Ingest rekod masuk dan konteks, Analyze ciri yang diekstrak, Predict skor keutamaan, dan Execute keputusan penghalaan. Pattern ini mengendalikan triage pada volum yang semakan manual tidak dapat menampung, dan ia menilai 20-50 isyarat secara serentak berbanding 3-5 yang dibaca manusia semasa triage manual.
Bagaimana pemarkahan lead AI berfungsi?
Pemarkahan lead AI menelan setiap rekod lead ditambah data tingkah laku (halaman yang dilawati, penglibatan e-mel, masa pelayaran pada harga), mengekstrak ciri (saiz syarikat, kanan jawatan, industri, sejarah CRM lalu), dan menerapkan model terlatih untuk menugaskan skor kebarangkalian. Model belajar daripada hasil sejarah: lead lalu yang mana dengan profil serupa yang sebenarnya ditutup. Skor mendorong penghalaan: skor tinggi pergi ke wakil kanan dengan SLA hari yang sama, skor tengah pergi ke SDR untuk kelayakan, skor rendah pergi ke urutan pemeliharaan automatik.
Apakah mod kegagalan yang paling biasa dalam Scoring and Routing?
Dua kegagalan yang paling memberi impak adalah salah penentukuran ambang dan kegagalan gelung maklum balas. Salah penentukuran ambang menghantar bahagian yang salah daripada lead kepada setiap peringkat penghalaan, sama ada membebankan wakil kanan dengan lead berkualiti sederhana atau menghalakan prospek dengan niat tinggi yang sebenar secara rendah. Kegagalan gelung maklum balas berlaku apabila data hasil (siapa yang ditutup, siapa yang churn, tuntutan mana yang penipuan) tidak dimasukkan semula untuk melatih semula model, menyebabkannya memberi skor rekod semasa terhadap corak sejarah yang lapuk. Gartner mendapati 68% sistem pemarkahan yang berprestasi rendah menjejak degradasi kepada kegagalan gelung maklum balas.
Apakah Gelung Skor-Kemudian-Execute?
Gelung Skor-Kemudian-Execute adalah struktur dua fasa Scoring and Routing: pertama fasa pemarkahan di mana setiap item menerima kedudukan keutamaan daripada ciri yang diekstrak dan corak hasil sejarah, kemudian fasa execute di mana ambang yang disahkan menterjemahkan kedudukan itu kepada keputusan penghalaan. Menggabungkan dua fasa, seperti menghalakan terus daripada ambang berasaskan peraturan tanpa pemarkahan model, terlepas isyarat kontekstual yang membezakan lead enterprise berintent tinggi daripada yang berintent rendah.
Bila Anda harus menggunakan Scoring and Routing berbanding Anomaly Agent?
Gunakan Scoring and Routing apabila Anda perlu membuat triage item dalam kategori yang diketahui: menugaskan keutamaan merentasi lead, tiket, atau permohonan yang semuanya mengikuti corak biasa. Gunakan Anomaly Agent apabila Anda perlu menangkap item yang tidak tergolong dalam kategori yang dijangka, seperti corak penipuan baharu yang tidak menyerupai penipuan lalu. Scoring and Routing akan memberi skor penipuan baharu sebagai risiko sederhana kerana ia kelihatan seperti transaksi biasa. Anomaly Agent menandakannya khusus kerana ia menyimpang daripada garis asas statistik.
ROI apa yang harus dijangka daripada Scoring and Routing?
Penempatan matang dengan data hasil 12+ bulan melihat peningkatan kadar penukaran 2-3x dalam peringkat lead yang mendapat skor tertinggi. Pasukan jualan melihat pengurangan 50-70% dalam kelajuan-kenalan-pertama. Penghalaan tiket sokongan biasanya mengurangkan masa-untuk-penyelesaian sebanyak 20-35%. Syarikat insurans melaporkan pengurangan 30-40% dalam kos pemprosesan tuntutan. Mencapai penanda aras ini memerlukan sistem pemarkahan yang ditentukur dan semakan hasil suku tahunan yang melatih semula model pada data yang ditutup baharu.
Ketahui lebih lanjut

Co-Founder, Rework.com
On this page
- Formula: Ingest, Analyze, Predict, Execute
- Lima contoh sebenar secara mendalam
- 1. Pemarkahan lead dan tugasan wakil
- 2. Pengutamaan tiket sokongan dan penghalaan pasukan
- 3. Penyaringan resume dan tugasan perekrut
- 4. Fast-track tuntutan insurans berbanding semakan manusia
- 5. Pengesanan penipuan dalam pembayaran
- Gelung Skor-Kemudian-Execute
- Mod kegagalan: apa yang sebenarnya silap
- Penentukuran ambang: tuas yang paling diabaikan
- Bila Scoring plus Routing berfungsi, dan bila tidak
- Isyarat ROI: cara mengukur sama ada ia berfungsi
- Keperluan tadbir urus
- Landskap vendor dan tooling
- Sambungan kepada AI Sales Operator
- Ketahui lebih lanjut