Scoring and Routing: Triage de AI a Escala
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
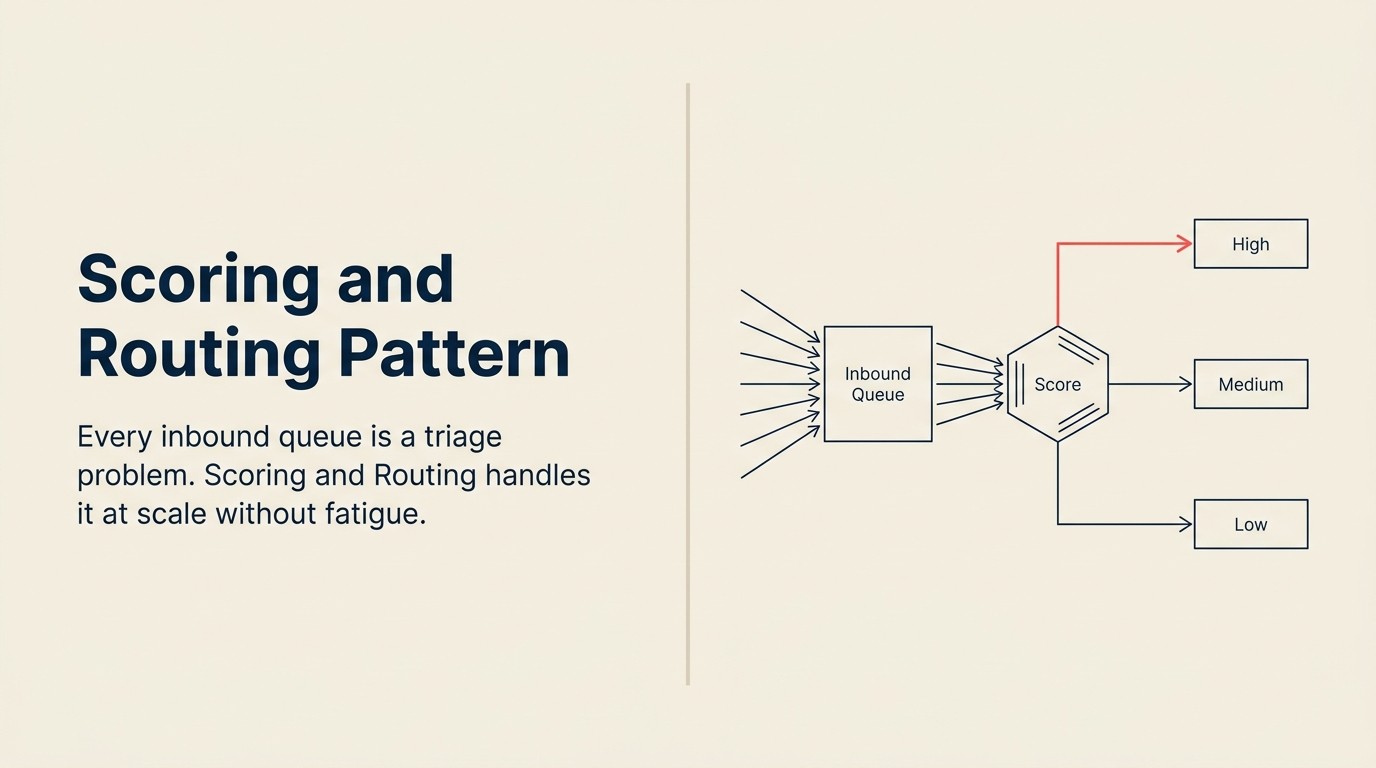
Cada cola entrante es un problema de triage.
Los leads llegan de una campaña de webinar: 400 contactos, 40 de los cuales son intención de compra real y 360 que hicieron clic porque el título era interesante. Los tickets de soporte se acumulan durante la noche: 300 nuevas solicitudes, 12 de las cuales son problemas enterprise urgentes y 288 que son preguntas de L1 ya respondidas en su documentación. Llegan solicitudes de préstamo: 1.200 esta semana, algunas solventes, otras no, algunas que parecen limpias pero son fraude.
El trabajo es el mismo en todos los casos. Separar la señal del ruido. Priorizar los elementos correctos. Enrutar cada uno a la persona o proceso correcto. Hacerlo lo suficientemente rápido como para que las cosas genuinamente urgentes no se queden en una cola durante tres horas mientras un humano lee todo manualmente.
El triage manual no escala. Las reglas basadas en umbrales ("enrutar cualquier lead de una empresa con 500+ empleados al equipo enterprise") pierden contexto. No pueden leer el hilo de email que vino con el lead. No pueden ver que el visitante pasó 40 minutos en su página de precios. No pueden tener en cuenta que este prospecto se fue antes después de seis meses.
Scoring and Routing es el patrón de AI que maneja esto. Es uno de los patrones económicamente más importantes en la AI empresarial, y entenderlo claramente, incluyendo dónde sale mal, vale la inversión.
La fórmula: Ingest, Analyze, Predict, Execute
Ingest (registro entrante) captura la entrada bruta: un nuevo registro de lead, un ticket de soporte enviado, una solicitud de empleo, una reclamación de seguro enviada. En la mayoría de los despliegues, el paso Ingest no es solo el elemento en sí. Extrae contexto relacionado: el historial de navegación del lead, el nivel y antigüedad de la cuenta del cliente, el currículum del solicitante junto con la descripción del puesto, el fingerprint del dispositivo de la transacción y el historial del comerciante.
Analyze (extraer características) transforma la entrada bruta en las señales que usará el modelo. Para un lead: tamaño de empresa, seniority del cargo, páginas del sitio web visitadas, dominio de email, industria e historial de participación pasada. Para un ticket de soporte: clasificación de intención (¿facturación? ¿error? ¿solicitud de función?), sentimiento, nivel del cliente y si coincide con algún patrón de incidente conocido. Este paso es donde comienza la ventaja de la AI. El triage humano examina 3-5 señales. El modelo evalúa 20-50 simultáneamente, incluyendo interacciones entre señales que un humano no verificaría.
Predict (puntuar) es el modelo aplicando patrones aprendidos a las características. La salida es una puntuación: una probabilidad o rango de prioridad. Para leads: probabilidad de cierre en 90 días. Para tickets: probabilidad de que necesite escalación o un especialista. Para fraude: probabilidad de que esta transacción sea no autorizada. El paso Predict es pura coincidencia de patrones contra resultados históricos, típicamente implementado con regresión logística, árboles de gradiente boosted o LLMs ajustados para entradas con mucho texto. Ha estado observando qué sucedió con registros pasados que se parecían a este.
Execute (enrutar o asignar) toma la puntuación y actúa en base a ella. Asignar el lead al equipo enterprise. Mover el ticket a la cola de seguridad. Rechazar la transacción y activar un flujo de trabajo de revisión. Crear una tarea en Salesforce. Enviar una alerta de Slack al representante de guardia. Execute es donde la puntuación se convierte en una decisión con consecuencias. También es donde más importa la gobernanza. El paso Execute tiene efectos reales que no siempre pueden revertirse fácilmente.
Key Facts: Impacto Empresarial de Scoring and Routing
- McKinsey estima que la AI en ventas y marketing podría desbloquear entre $0,8 y $1,2 billones en productividad incremental, con los actores que invierten en AI viendo incrementos de ingresos del 3-15% e incrementos del ROI de ventas del 10-20% (McKinsey, 2023)
- Las empresas B2B que usan lead scoring impulsado por AI ven una mejora de 2-3x en la tasa de conversión en su nivel de leads con mayor puntuación comparado con las colas con triage manual, en despliegues maduros con 12+ meses de datos de resultados (Forrester B2B Sales AI Report, 2025)
- Las aseguradoras que usan el patrón Scoring and Routing reportan una reducción del 30-40% en los costos de procesamiento de reclamaciones en reclamaciones rutinarias, al acelerar las reclamaciones limpias y enrutar las complejas a ajustadores especializados (Deloitte Insurance AI Study, 2024)
Cinco ejemplos reales en profundidad
1. Lead scoring y asignación de representantes
El caso de uso canónico. Una campaña de marketing genera 300 leads entrantes. El modelo ingesta cada registro de lead más datos de comportamiento de su plataforma de analíticas del sitio y de participación de email. Analiza características como el cargo (VP de Ventas puntúa más alto que Practicante de Ventas), tamaño de empresa, ajuste de industria, páginas visitadas (visitar la página de precios más de dos veces es una señal fuerte), email abierto en dos horas e historial pasado de CRM si es un prospecto que regresa.
El paso Predict asigna a cada lead una puntuación de 0-100 que representa la probabilidad estimada de conversión. El paso Execute enruta los leads por encima de 75 a sus representantes senior con SLA del mismo día, los leads entre 40-75 a SDRs para calificación, y los leads por debajo de 40 a una secuencia de nurture automatizada.
Las herramientas aquí incluyen Salesforce Einstein Lead Scoring, el Predictive Lead Scoring de HubSpot, y en Rework, la puntuación asistida por AI integrada en el flujo de trabajo de ventas. Un sistema bien calibrado típicamente desplaza el 20-30% más del pipeline hacia leads de alta conversión sin agregar personal. Para un análisis profundo de la implementación específica de ventas, vea AI lead scoring más allá de los modelos basados en reglas.
2. Priorización de tickets de soporte y enrutamiento de equipos
Una empresa SaaS B2B recibe 600 tickets de soporte diarios. El modelo ingesta el texto de cada ticket junto con los datos de cuenta del cliente que envía: ARR, nivel de contrato, patrones de uso, historial de tickets pasados y días hasta la renovación. Analyze clasifica la intención (problema de facturación, error técnico, solicitud de función, preocupación de seguridad), detecta el sentimiento y verifica indicadores de riesgo de escalación.
Predict puntúa la urgencia: los clientes de alto ARR con problemas de facturación tres semanas antes de la renovación puntúan en la parte superior. Execute enruta los tickets de alta urgencia a los account managers designados, los problemas técnicos al nivel de ingeniería correcto y las solicitudes de función de baja urgencia a la cola de backlog. El resultado: los problemas enterprise reciben una respuesta en minutos; el ruido de L1 no bloquea al equipo.
Las herramientas en este espacio incluyen Zendesk AI, la inteligencia de tickets de Intercom y Freddy AI de Freshdesk.
3. Revisión de currículums y asignación de reclutadores
Una empresa publica 12 posiciones abiertas y recibe 1.800 solicitudes en dos semanas. El modelo ingesta cada currículum y la descripción del puesto. Analyze extrae señales relevantes: años en roles relevantes, habilidades específicas mencionadas, empresas donde trabajó, nivel educativo, estructura y completitud del currículum. Compara cada currículum con el perfil objetivo para ese rol.
Predict genera una puntuación de ajuste por solicitante por rol. Execute muestra el cuartil superior al reclutador de ese rol, enruta a los candidatos en el límite a un paso de selección más ligero y envía al nivel inferior una respuesta automatizada. Nota: aquí también es donde el riesgo de sesgo es más alto. Se trata más adelante.
Las herramientas aquí incluyen Eightfold, HireVue, Paradox y los complementos de selección de AI de Greenhouse.
4. Aprobación rápida de reclamaciones de seguros vs. revisión humana
Una aseguradora procesa 5.000 reclamaciones mensuales. Las reclamaciones simples (choques de autos con documentación fotográfica y responsabilidad clara) pueden pagarse en 48 horas si el modelo les da una puntuación de "aprobación rápida". Las reclamaciones complejas necesitan ajustadores humanos.
El modelo ingesta los datos del formulario de reclamación, las fotos adjuntas, el historial del vehículo, el historial del tomador de seguro y los registros de terceros. Analyze extrae indicadores de complejidad: ¿es clara la responsabilidad? ¿Hay heridos? ¿El monto reclamado coincide con datos de incidentes comparables? ¿El historial del reclamante muestra patrones anómalos?
Predict puntúa cada reclamación en dos dimensiones: probabilidad de aprobación rápida (¿es esto rutinario?) y probabilidad de fraude (¿coincide esto con patrones de fraude conocidos?). Execute enruta las reclamaciones de aprobación rápida y baja probabilidad de fraude al pago automatizado, las reclamaciones de complejidad media a los ajustadores y las de alta probabilidad de fraude a la unidad de investigación especial.
Este es uno de los casos de uso mejor probados para el patrón, con aseguradoras reportando una reducción del 30-40% en los costos de procesamiento en la mayoría rutinaria.
5. Detección de fraude en pagos
Stripe Radar es uno de los sistemas de puntuación más ampliamente desplegados en el mundo, aunque la mayoría de los operadores lo piensan como "prevención de fraude" en lugar de "AI." Para cada transacción con tarjeta, el modelo de Stripe ingesta metadatos de la tarjeta, fingerprint del dispositivo, monto de la transacción, categoría del comerciante, datos geográficos y señales de comportamiento (qué tan rápido se llenó el formulario, si las direcciones de facturación y envío coinciden).
Analyze extrae características. Predict asigna una puntuación de probabilidad de fraude: 99,5% (casi con certeza fraude) o 0,2% (casi con certeza legítimo). Execute actúa sobre esa puntuación: aprobar, enviar a revisión 3D Secure o bloquear completamente.
El paso Execute aquí es de altísimas consecuencias y ocurre en milisegundos. Por eso la calibración del umbral de puntuación es crítica. Un umbral demasiado agresivo bloquea transacciones legítimas y genera contracargos de clientes enojados. Demasiado permisivo y las pérdidas por fraude aumentan. El umbral correcto es una decisión de negocio, no solo un parámetro del modelo.
El Bucle Puntuar-Luego-Ejecutar
Scoring and Routing funciona en dos fases distintas que no deben colapsarse: una fase de puntuación donde cada elemento entrante recibe un rango de prioridad basado en características extraídas y patrones de resultados históricos, y una fase de ejecución donde ese rango impulsa una decisión de enrutamiento. Saltar la fase de puntuación y enrutar directamente desde reglas (tamaño de empresa, categoría de ticket) pierde las señales contextuales que distinguen a un lead enterprise de baja intención de un lead SMB de alta intención. Saltar el mapeo puntuación-a-umbral y usar directamente la confianza bruta del modelo como desencadenante de enrutamiento produce inestabilidad de enrutamiento mientras el modelo se calibra. La estructura de dos fases, puntuar primero luego ejecutar basándose en umbrales validados, es lo que hace que el patrón sea confiable a volumen.
Modos de fallo: qué sale mal realmente
| Modo de fallo | Causa raíz | Corrección |
|---|---|---|
| Sesgo en los datos de entrenamiento | Modelo entrenado en resultados históricamente sesgados (los representantes pasados solo cerraron desde el mercado medio; los leads enterprise fueron injustamente despriorizados) | Auditar las distribuciones de puntuación entre segmentos. Verificar correlaciones demográficas en los datos de candidatos o clientes. |
| Mala calibración de umbrales | Un umbral de 70 puntos que envía el 60% de los leads de alta intención a representantes junior porque el corte no se validó contra las tasas de ganados reales | Validar los umbrales contra resultados. Tratar la configuración de umbrales como un elemento de revisión trimestral del negocio, no una configuración única. |
| Obsolescencia de características | Modelo entrenado con datos del Q1 pierde una nueva línea de producto lanzada en Q3, por lo que los prospectos que visitaron esa página de producto no puntúan bien | Configurar calendarios de reentrenamiento automático vinculados a cambios de producto/segmento. Rastrear la deriva de la distribución de puntuaciones con el tiempo. |
| Fallo del bucle de retroalimentación | Nadie monitorea si los leads enrutados realmente cerraron, los tickets se resolvieron, o las reclamaciones enrutadas realmente se pagaron limpias | Construir el seguimiento de resultados en el flujo de trabajo desde el primer día. El modelo necesita datos históricos etiquetados para mantenerse calibrado. |
| Inflación de puntuación sin acción | La puntuación se ejecuta, pero los representantes ignoran el orden de la cola; todos trabajan su propio pipeline | Hacer visible la puntuación en la interfaz del flujo de trabajo (CRM, herramienta de soporte). Vincular las métricas de rendimiento del equipo al cumplimiento de la puntuación, no solo a los resultados. |
| Errores de enrutamiento silenciosos | Execute envía elementos a la cola incorrecta silenciosamente (nadie lo nota durante semanas) | Registrar cada decisión de enrutamiento. Construir un informe de excepciones que muestre discrepancias entre el nivel puntuado y el nivel de resultado. |
Los dos modos de fallo de mayor impacto (mala calibración de umbrales y fallo del bucle de retroalimentación) son también los menos emocionantes de corregir. No requieren nuevos modelos. Requieren disciplina operacional: revisiones regulares de quién fue enrutado adónde y si esa decisión de enrutamiento fue rentable.
El informe de Operaciones de AI de Gartner 2025 encontró que el 68% de los sistemas de puntuación de AI que no alcanzan sus benchmarks iniciales rastrean la degradación hasta el fallo del bucle de retroalimentación. El modelo nunca fue reentrenado con nuevos resultados, por lo que sigue puntuando leads actuales contra patrones aprendidos de datos de ventas cerradas de hace dos o tres años.
Calibración de umbrales: la palanca más ignorada
La mayoría de los operadores que despliegan un sistema de puntuación pasan el 90% de su atención en la selección del modelo y el 10% en la configuración de umbrales. El retorno de esa inversión está al revés.
El trabajo del modelo es clasificar los elementos. El trabajo del umbral es decidir qué significa operacionalmente esa clasificación. Un modelo de lead scoring podría clasificar con precisión 300 leads del 1 al 300. Pero si establece el umbral de "alta prioridad" en 60 de 100 y 200 de sus 300 leads puntúan por encima de 60, sus representantes senior están abrumados y la segmentación no tiene sentido.
La calibración de umbrales requiere tres entradas: la distribución de puntuaciones de los datos históricos, su capacidad operacional en cada nivel de enrutamiento (¿cuántos elementos puede manejar su equipo enterprise por día?) y sus datos de resultados (¿qué rango de puntuaciones se correlaciona realmente con las victorias?). Cuando tiene estos tres, puede establecer umbrales que coincidan con la realidad operacional, no solo con cortes estadísticos.
Revise los umbrales al menos trimestralmente. Los cambios de mercado, los cambios en la mezcla de campañas y la expansión del producto cambian la distribución de puntuaciones bajo sus pies.
Cuándo Scoring plus Routing funciona y cuándo no
Funciona bien cuando:
- Tiene resultados históricos etiquetados. El modelo aprende de datos pasados: qué leads cerraron, qué reclamaciones fueron fraudulentas, qué solicitantes fueron contratados y se quedaron. Sin historial etiquetado no hay predicciones significativas.
- Tiene volumen. Scoring and Routing da resultado cuando el problema de triage es real. Si recibe 15 leads por semana, un representante de ventas puede hacer el triage manualmente en 10 minutos. Si recibe 500, necesita el patrón.
- La decisión de enrutamiento mapea a una acción clara y ejecutable. "Enrutar al equipo enterprise" es ejecutable. "Tratar este lead con más cuidado" no lo es.
- Sus datos son razonablemente completos y consistentes. Los campos faltantes (leads sin cargo, tickets sin vinculación a cuenta) degradan la calidad de la predicción.
Considere alternativas cuando:
vs. Anomaly Agent: Scoring and Routing asigna prioridad dentro de categorías conocidas. Anomaly Agent marca elementos que no pertenecen a ninguna categoría esperada (la incógnita desconocida). Si necesita detectar patrones de fraude novedosos que no se parecen a ningún fraude pasado, Anomaly Agent es la herramienta correcta. Scoring and Routing puntúa esos casos novedosos como riesgo medio porque se parecen a registros normales, no porque sean patrones de fraude familiares.
vs. Workflow Copilot: La puntuación actúa sin el usuario. El copilot asiste al usuario durante su trabajo. Si su proceso requiere un juicio que no puede delegarse algorítmicamente (una llamada de ventas enterprise compleja, una negociación sutil, una situación sensible con el cliente), Copilot asiste al humano en lugar de reemplazar su decisión de triage.
vs. Autonomous Agent: Scoring and Routing toma una decisión en un punto de un flujo de trabajo. Un Autonomous Agent ejecuta un bucle de múltiples pasos, tomando múltiples decisiones para completar un objetivo. Scoring and Routing es un módulo dentro de un flujo de trabajo más amplio; los Autonomous Agents son el flujo de trabajo completo.
Señales de ROI: cómo medir si está funcionando
| Métrica | Qué mide | Benchmark plausible |
|---|---|---|
| Velocidad de primer contacto | Tiempo desde el envío del lead hasta el primer alcance del representante | Reducción del 50-70% frente a la cola manual |
| Utilización de representantes por nivel | Porcentaje del tiempo del representante enterprise en leads puntuados como enterprise | Línea base: ~40%. Con puntuación: 65-80% |
| Tasa de ganados: puntuados vs. no puntuados | Comparación de tasa de conversión entre bandas de puntuación alta/media/baja | La banda alta debería multiplicar por 2-3x la tasa de ganados de la banda baja en despliegues maduros |
| Tiempo de resolución de tickets por ruta de enrutamiento | Tickets enrutados por AI vs. clasificados manualmente | Reducción del 20-35% en el tiempo de resolución para los enrutados por AI |
| Tasa de falsos positivos | Elementos enrutados a la cola de prioridad que no merecían prioridad | Rastrear trimestralmente; objetivo <15% de falsos positivos en el nivel enterprise |
| Deriva de la distribución de puntuaciones | Si la distribución de puntuaciones del modelo está cambiando con el tiempo | Marcar si la puntuación media cambia más de 10 puntos trimestre a trimestre |
La comparación de tasa de ganados entre leads puntuados y no puntuados es su prueba más sólida. Si los leads en la banda de puntuación superior cierran al 28% y los leads en la banda inferior cierran al 7%, el modelo está ganando su lugar. Si esos números son similares, el modelo no está discriminando útilmente y tiene un problema de datos de entrenamiento o de características.
Requisitos de gobernanza
Scoring and Routing toca los resultados económicos de las personas: las comisiones de los representantes de ventas, las ofertas de trabajo de los candidatos, la aprobación o denegación de los clientes. Esa no es una razón para evitarlo. Es una razón para gobernarlo bien.
Auditar el modelo trimestralmente. Verificar las distribuciones de puntuaciones entre segmentos demográficos, geográficos y firmográficos. Si su modelo de lead scoring sistemáticamente asigna puntuaciones más bajas a leads de regiones o industrias específicas sin una razón de negocio, tiene un problema de sesgo incluso si el modelo es técnicamente "preciso."
Definir claramente la anulación humana. Cualquier representante debería poder marcar un lead de baja puntuación que cree que es de alta intención. Cualquier reclutador debería poder mover un currículum a la siguiente ronda manualmente. El proceso de anulación debe registrarse para que pueda verificar si las anulaciones difieren sistemáticamente de las predicciones del modelo y si las anulaciones fueron correctas.
Cadencia de reentrenamiento. Para la mayoría de las aplicaciones empresariales, el reentrenamiento trimestral es un valor predeterminado razonable. Mensual si su mercado cambia rápido. Anual es casi siempre demasiado lento. Está puntuando prospectos de 2025 contra un modelo de 2023.
Documentación para industrias reguladas. En servicios financieros, préstamos, seguros y contratación, las decisiones de puntuación automatizadas pueden requerir explicabilidad bajo ECOA, GDPR Artículo 22 o leyes de AI estatales. Conozca su jurisdicción. "El modelo lo dijo" no es una explicación defendible para una decisión crediticia adversa.
Panorama de proveedores y herramientas
| Caso de uso | Herramientas principales |
|---|---|
| Lead scoring | Salesforce Einstein, HubSpot Predictive Scoring, Marketo AI, Rework AI |
| Enrutamiento de tickets de soporte | Zendesk AI, Intercom AI, Freshdesk Freddy, Kustomer |
| Selección de candidatos | Eightfold, HireVue, Paradox, Greenhouse AI |
| Detección de fraude | Stripe Radar, Kount, Featurespace, Sardine |
| Reclamaciones de seguros | Shift Technology, Tractable, Cape Analytics |
| Infraestructura de puntuación personalizada | Pinecone (embeddings vectoriales para similitud de características), Tecton (feature stores), AWS SageMaker, Azure ML |
Para los equipos que construyen puntuación personalizada: Pinecone y Weaviate se usan a menudo para la recuperación de características basada en similitud, pero el modelo de puntuación principal suele ser un árbol de gradiente boosted (LightGBM, XGBoost) o un LLM ajustado para entradas con mucho texto. La infraestructura importa menos que la calidad de los datos históricos etiquetados y el rigor de la calibración de umbrales.
Conexión con el AI Sales Operator
Scoring and Routing es uno de los cuatro patrones en el núcleo del AI Sales Operator (Nivel 3 en el ACE Framework). En ese contexto, el lead scoring no es solo una característica de automatización de marketing. Es la capa de decisión al frente del funnel que determina cómo se organiza el día de cada representante. El concepto del AI Sales Operator explica cómo estos cuatro patrones funcionan juntos en la práctica.
Las organizaciones de ventas de mayor rendimiento usan la puntuación no solo para priorizar los leads entrantes sino para priorizar el tiempo de los representantes en todo el pipeline: qué tratos avanzar, qué cuentas involucrar para la expansión, qué renovaciones están en riesgo de churn. Cuando Scoring and Routing se conecta a Meeting Intelligence (análisis de llamadas) y Workflow Copilot (sugerencias integradas en CRM), los tres patrones juntos forman un bucle cerrado: la AI puntúa la oportunidad, la AI analiza la llamada, la AI sugiere la siguiente acción.
Esa arquitectura es lo que separa a los equipos de ventas aumentados por AI de los equipos que solo tienen una herramienta de AI para la asignación de leads.
Rework Analysis: La mayoría de los equipos que despliegan lead scoring aciertan con el modelo pero fallan con las operaciones. El modelo puntúa leads con precisión. Pero los umbrales se establecieron una vez al lanzamiento, los datos de resultados nunca se retroalimentaron y el equipo nunca auditó si los leads de alta puntuación están realmente cerrando a una tasa más alta que los de baja puntuación. Seis meses después, los representantes han dejado de confiar en el orden de la cola y están trabajando su propio pipeline. El ROI del modelo se evapora no porque la AI haya fallado sino porque el bucle de retroalimentación nunca se construyó. Scoring and Routing requiere dos compromisos organizacionales, no uno: un sistema de puntuación y una revisión trimestral de resultados que lo mantenga calibrado. Los equipos que asumen ambos compromisos ven las mejoras de conversión de 2-3x. Los que solo asumen el primero ven un lento regreso al triage manual.
Preguntas Frecuentes
¿Qué es el patrón de AI Scoring and Routing?
Scoring and Routing es un patrón de AI que prioriza y asigna automáticamente elementos entrantes (leads, tickets, solicitudes, reclamaciones) usando una fórmula de cuatro pasos: Ingest registros entrantes y contexto, Analyze características extraídas, Predict una puntuación de prioridad y Execute una decisión de enrutamiento. El patrón maneja el triage a volúmenes que la revisión manual no puede sostener, y evalúa 20-50 señales simultáneamente frente a las 3-5 que lee un humano durante el triage manual.
¿Cómo funciona el AI lead scoring?
El AI lead scoring ingesta cada registro de lead más datos de comportamiento (páginas visitadas, participación en email, tiempo de navegación en precios), extrae características (tamaño de empresa, seniority del cargo, industria, historial pasado de CRM) y aplica un modelo entrenado para asignar una puntuación de probabilidad. El modelo aprendió de resultados históricos: qué leads pasados con perfiles similares realmente cerraron. La puntuación impulsa el enrutamiento: las puntuaciones altas van a representantes senior con SLA del mismo día, las puntuaciones medias van a SDRs para calificación, las puntuaciones bajas van a secuencias de nurture automatizadas.
¿Cuáles son los modos de fallo más comunes en Scoring and Routing?
Los dos fallos de mayor impacto son la mala calibración de umbrales y el fallo del bucle de retroalimentación. La mala calibración de umbrales envía la proporción incorrecta de leads a cada nivel de enrutamiento, ya sea abrumando a los representantes senior con leads de calidad media o subenrutando prospectos de alta intención genuinos. El fallo del bucle de retroalimentación ocurre cuando los datos de resultados (quién cerró, quién hizo churn, qué reclamaciones fueron fraudulentas) no se retroalimentan para reentrenar el modelo, haciendo que puntúe los registros actuales contra patrones históricos obsoletos. Gartner encontró que el 68% de los sistemas de puntuación con bajo rendimiento rastrean la degradación hasta el fallo del bucle de retroalimentación.
¿Qué es el Bucle Puntuar-Luego-Ejecutar?
El Bucle Puntuar-Luego-Ejecutar es la estructura de dos fases del patrón Scoring and Routing: primero una fase de puntuación donde cada elemento recibe un rango de prioridad de características extraídas y patrones de resultados históricos, luego una fase de ejecución donde los umbrales validados traducen ese rango en una decisión de enrutamiento. Colapsar las dos fases, como enrutar directamente desde umbrales basados en reglas sin puntuación del modelo, pierde las señales contextuales que distinguen a un lead enterprise de alta intención de uno de baja intención. Enrutar directamente desde la confianza bruta del modelo sin validación de umbrales produce inestabilidad de enrutamiento.
¿Cuándo debe usar Scoring and Routing frente a un Anomaly Agent?
Use Scoring and Routing cuando necesita clasificar elementos dentro de categorías conocidas: asignando prioridad entre leads, tickets o solicitudes que siguen patrones familiares. Use Anomaly Agent cuando necesita detectar elementos que no pertenecen a ninguna categoría esperada, como patrones de fraude novedosos que no se parecen a ningún fraude pasado. Scoring and Routing puntuaría el fraude novedoso como riesgo medio porque parece una transacción normal. Anomaly Agent lo marca específicamente porque se desvía de la línea base estadística.
¿Qué ROI debe esperar de Scoring and Routing?
Los despliegues maduros con 12+ meses de datos de resultados ven una mejora de 2-3x en la tasa de conversión en el nivel de leads de mayor puntuación. Los equipos de ventas ven una reducción del 50-70% en la velocidad del primer contacto. El enrutamiento de tickets de soporte típicamente reduce el tiempo de resolución en un 20-35%. Las aseguradoras reportan una reducción del 30-40% en los costos de procesamiento de reclamaciones. Alcanzar estos benchmarks requiere tanto un sistema de puntuación calibrado como una revisión trimestral de resultados que reentrena el modelo con nuevos datos de cierre.
Aprenda más
- Anomaly Agent: Detectando lo Inesperado
- El Gradiente de Riesgo entre los Patrones de AI
- AI Lead Scoring Más Allá de los Modelos Basados en Reglas
- Enrutamiento Automatizado de Leads: Round Robin vs. AI Driven
- Requisitos de Gobernanza por Patrón de AI
- Por Qué 10 Patrones Cubren el 90% de la AI Empresarial

Co-Founder, Rework.com
On this page
- La fórmula: Ingest, Analyze, Predict, Execute
- Cinco ejemplos reales en profundidad
- 1. Lead scoring y asignación de representantes
- 2. Priorización de tickets de soporte y enrutamiento de equipos
- 3. Revisión de currículums y asignación de reclutadores
- 4. Aprobación rápida de reclamaciones de seguros vs. revisión humana
- 5. Detección de fraude en pagos
- El Bucle Puntuar-Luego-Ejecutar
- Modos de fallo: qué sale mal realmente
- Calibración de umbrales: la palanca más ignorada
- Cuándo Scoring plus Routing funciona y cuándo no
- Señales de ROI: cómo medir si está funcionando
- Requisitos de gobernanza
- Panorama de proveedores y herramientas
- Conexión con el AI Sales Operator
- Aprenda más