Phụ thuộc và điều kiện tiên quyết của pattern
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
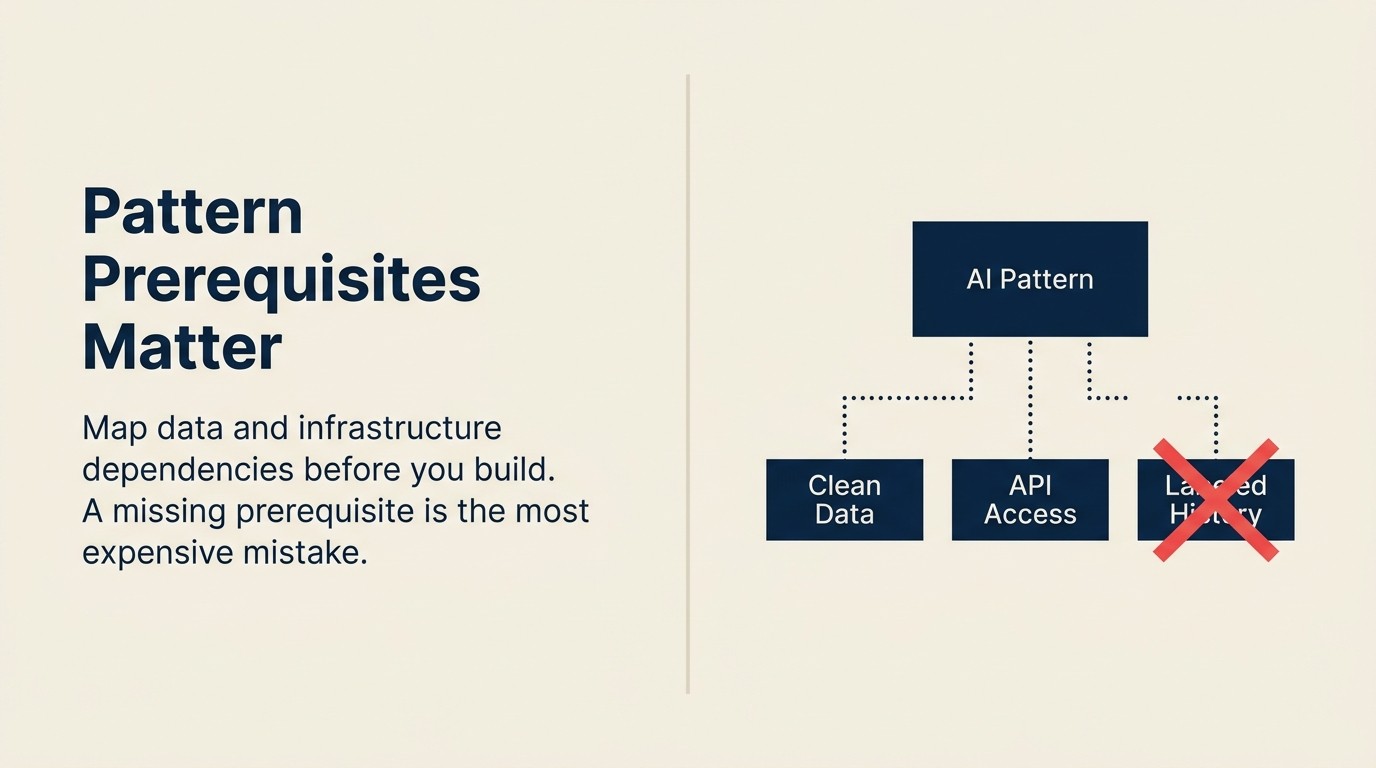
Lý do phổ biến nhất khiến AI pattern thất bại sau triển khai là điều kiện tiên quyết bị thiếu mà không ai kiểm toán.
Không phải model sai. Không phải vendor sai. Không phải pattern sai. Một phụ thuộc dữ liệu không ai kiểm tra. Một quyền truy cập API được giả định mà chưa xác nhận. Một knowledge base tồn tại dưới dạng thư mục tài liệu nhưng không có embedding pipeline, không có cadence làm mới, và không có người chịu trách nhiệm.
Pattern được xây dựng xong. Integration hoàn tất. Rồi đến tuần thứ ba kiểm tra, ai đó hỏi dữ liệu kết quả lịch sử cho Scoring model ở đâu thì phát hiện ra nó chưa bao giờ được thu thập ở định dạng có cấu trúc. Hoặc bản ghi âm audio cho Meeting Intelligence có tồn tại nhưng lại lưu trong hệ thống vendor không có export API. Hoặc knowledge base mà RAG Assistant dựa vào đã 18 tháng không cập nhật và hoàn toàn sai về hai dòng sản phẩm.
Những phát hiện này không giết chết dự án AI. Chúng làm trì hoãn ba đến sáu tháng và tiêu hao thiện chí mà giai đoạn pilot lẽ ra phải tạo ra. Nghiên cứu McKinsey về mở rộng quy mô agentic AI với các chuyển đổi dữ liệu cho thấy tám trong mười công ty trích dẫn hạn chế dữ liệu là rào cản chính để mở rộng AI, không phải chất lượng model hay lựa chọn vendor.
Bài viết này lập bản đồ các phụ thuộc theo từng pattern, đi qua một chuỗi triển khai thực tế, và cung cấp checklist kiểm toán điều kiện tiên quyết để chạy trước khi bất kỳ triển khai nào được phê duyệt. Để có bức tranh rộng hơn về sẵn sàng dữ liệu trước khi bất kỳ dự án AI nào bắt đầu, sẵn sàng dữ liệu: điều kiện tiên quyết mà hầu hết các dự án AI bỏ qua là nơi bắt đầu đúng.
Các loại phụ thuộc
Ba danh mục bao phủ toàn bộ cảnh quan phụ thuộc:
Phụ thuộc dữ liệu: Dữ liệu nào phải tồn tại, được cấu trúc đúng, và có thể truy cập trước khi pattern có thể vận hành? Đây là danh mục bị bỏ qua nhiều nhất. Các team giả định dữ liệu tồn tại vì nó đã được thu thập. Nhưng tồn tại không đồng nghĩa với có thể truy cập, có cấu trúc, hay đủ chất lượng. 7 loại dữ liệu tạo nên AI kinh doanh phác thảo toàn cảnh đầy đủ.
Phụ thuộc cơ sở hạ tầng: Hệ thống, pipeline, API, và tài nguyên tính toán nào phải có sẵn để pattern ingest, xử lý, lưu trữ, và phân phối đầu ra? Engineering team thường xác định phạm vi những thứ này, nhưng business và program owner thường đánh giá thấp chúng. Một embedding pipeline cho RAG, một CRM webhook cho Scoring and Routing, và một audio processing pipeline cho Meeting Intelligence, mỗi cái đều là khoản đầu tư kỹ thuật không nhỏ.
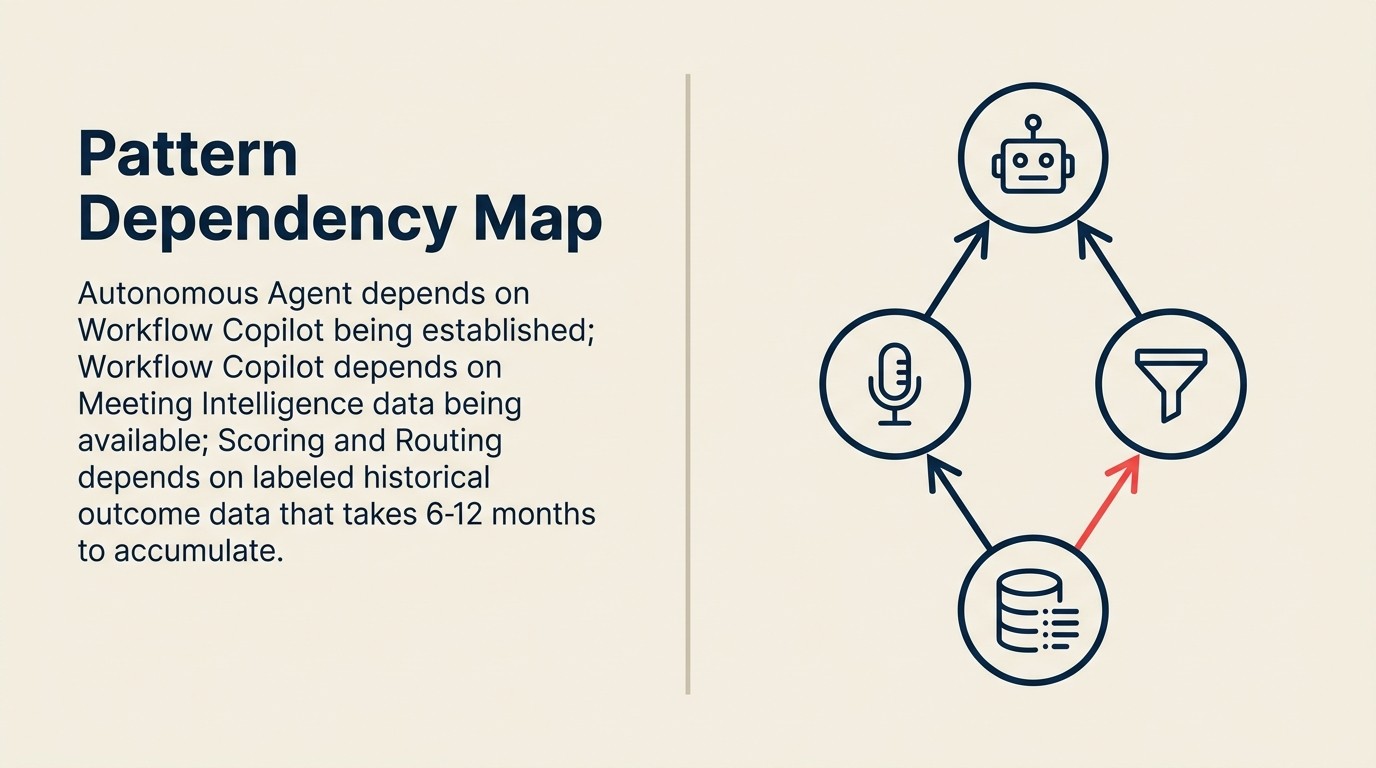
Phụ thuộc pattern: Một số pattern yêu cầu pattern khác phải vận hành trước, vì pattern downstream tiêu thụ dữ liệu mà pattern upstream tạo ra. Meeting Intelligence tạo ra dữ liệu call có cấu trúc mà Workflow Copilot dùng để gợi ý next-action trong CRM. Nếu Meeting Intelligence không chạy, Workflow Copilot không có gì để gợi ý từ đó.
Key Facts: Thất bại điều kiện tiên quyết AI
- 85% các dự án AI thất bại trích dẫn chất lượng dữ liệu kém là nguyên nhân gốc rễ, theo phân tích RAND Corporation trên hơn 2.400 sáng kiến AI doanh nghiệp.
- Nghiên cứu năm 2025 của Gartner dự đoán 60% các dự án AI thiếu dữ liệu sẵn sàng AI sẽ bị từ bỏ trước khi hoàn thành.
- Chỉ 12% tổ chức có dữ liệu đủ chất lượng để hỗ trợ ứng dụng AI mà không cần giai đoạn tiền xử lý đáng kể. (MIT Project NANDA, 2025)
Bản đồ phụ thuộc theo pattern
| Pattern | Phụ thuộc dữ liệu | Phụ thuộc cơ sở hạ tầng | Phụ thuộc pattern phổ biến |
|---|---|---|---|
| RAG Assistant | Knowledge base được duy trì (chính sách, SOP, tài liệu sản phẩm, ticket đã giải quyết); được chunked và embedded trong vector database | Vector database; embedding pipeline; pipeline ingestion và làm mới tài liệu | Không có (thường chạy trước) |
| Scoring + Routing | Hồ sơ lịch sử với nhãn kết quả (closed-won/lost, resolved/escalated, hired/rejected); các trường tính năng có cấu trúc mỗi hồ sơ | CRM hoặc ticketing system có webhook support; cơ sở hạ tầng train và retrain model; routing rules engine | Không có (có thể là pattern đầu tiên deploy) |
| Vision Extract | Hình ảnh training hoặc ví dụ scan có chú thích cho loại tài liệu mục tiêu; truy cập tài liệu nguồn ở dạng kỹ thuật số hoặc vật lý | Pipeline ingestion hình ảnh; OCR hoặc vision model API; hệ thống hồ sơ mục tiêu với quyền ghi | Không có (thường chạy độc lập) |
| Meeting Intelligence | Bản ghi âm audio hoặc video đủ chất lượng; metadata cuộc họp (người tham gia, ngày, ngữ cảnh) | Hệ thống lưu trữ audio/video; speech-to-text API; kho lưu trữ đầu ra có cấu trúc kết nối với hệ thống downstream | Không có (thường chạy trước trong stack sales/support) |
| Anomaly Agent | Tối thiểu 60-90 ngày dữ liệu baseline cho metric được giám sát; cadence thu thập dữ liệu nhất quán | Luồng dữ liệu real-time hoặc gần real-time; pipeline cảnh báo và thông báo; routing escalation | Thường phụ thuộc vào Scoring + Routing để thu thập baseline |
| Generative Research | Các nguồn có thể truy cập (web, corpus nội bộ, nguồn tin tức); rõ ràng về cấp phép nội dung để phân phối nội bộ | Truy cập web hoặc API tìm kiếm corpus nội bộ; hệ thống trích dẫn nguồn | Không có, nhưng chất lượng đầu ra cải thiện khi dùng RAG Assistant cho các nguồn nội bộ |
| Document Review | Tài liệu mẫu đại diện cho các trường hợp điển hình; tiêu chuẩn hoặc template để so sánh | Document parser; comparison model; định dạng đầu ra có cấu trúc tương thích với hệ thống downstream | Không có |
| Workflow Copilot | Dữ liệu ngữ cảnh người dùng real-time (hồ sơ hiện tại, hoạt động gần đây); hệ thống hồ sơ của người dùng | Tích hợp sâu với công cụ làm việc chính của người dùng (CRM, IDE, marketing platform); low-latency inference endpoint | Thường phụ thuộc vào Meeting Intelligence hoặc Scoring + Routing để có ngữ cảnh phong phú |
| Personalization Engine | Dữ liệu hành vi người dùng (tối thiểu 5-10 tương tác mỗi người dùng để personalization có ý nghĩa); product catalog hoặc content library | Thu thập sự kiện real-time; profile store; hệ thống phân phối nội dung hỗ trợ dynamic rendering | Không có khi dùng độc lập; hoạt động tốt hơn khi kết hợp Anomaly Agent để tích hợp churn signal |
| Autonomous Agent | Tất cả các tool agent cần dùng phải truy cập được qua API đã kiểm tra; rollback hoặc undo capability cho mọi loại hành động không thể đảo ngược | Tool registry với schema đã kiểm tra; giới hạn số bước tối đa; audit log system; đường dẫn escalation | Phụ thuộc vào mục tiêu cụ thể; thường phụ thuộc Scoring + Routing để phân loại và RAG để truy cập kiến thức |
"Các enterprise program dành 50-70% timeline dự án AI cho công việc sẵn sàng dữ liệu, bao gồm trích xuất, chuẩn hóa, governance metadata, và kiểm tra chất lượng, đạt tỷ lệ production deployment cao hơn 3 lần so với các chương trình bắt đầu công việc model trước khi nền tảng dữ liệu được xác nhận." (Integrate.io Data Transformation Report, 2026)
Pattern Dependency Map
Pattern Dependency Map là cấu trúc kiểm toán điều kiện tiên quyết phân loại mọi AI pattern theo ba trục trước khi triển khai bắt đầu: phụ thuộc dữ liệu (dữ liệu có cấu trúc nào phải tồn tại và truy cập được), phụ thuộc cơ sở hạ tầng (pipeline, API, và tính toán nào phải có sẵn), và phụ thuộc pattern (pattern upstream nào phải đang tạo ra dữ liệu trước khi pattern này có thể kiểm tra có ý nghĩa). Chạy map này trước bất kỳ quyết định xây dựng nào loại bỏ các trì hoãn ba đến sáu tháng làm tiêu hao thiện chí pilot khi điều kiện tiên quyết bị thiếu xuất hiện giữa quá trình integration.
Rework Analysis: Dựa trên phát hiện McKinsey rằng tám trong mười công ty trích dẫn hạn chế dữ liệu là rào cản mở rộng AI chính, và dữ liệu corroborating từ RAND Corporation (85% dự án AI thất bại trích dẫn chất lượng dữ liệu là nguyên nhân gốc rễ), Pattern Dependency Map là khoản đầu tư trước khi build có ROI cao nhất trong bất kỳ dự án AI nào. Kinh nghiệm triển khai của Rework cho thấy team hoàn thành kiểm toán điều kiện tiên quyết chính thức trước khi bắt đầu build rút ngắn thời gian đến production trung bình 11 tuần so với team phát hiện phụ thuộc trong quá trình integration testing.
Con đường quan trọng: chuỗi triển khai AI Sales Operator
Một công ty muốn deploy AI Sales Operator kết hợp Meeting Intelligence, Scoring and Routing, RAG Assistant, và Workflow Copilot. Đây là thứ tự được dẫn dắt bởi phụ thuộc:
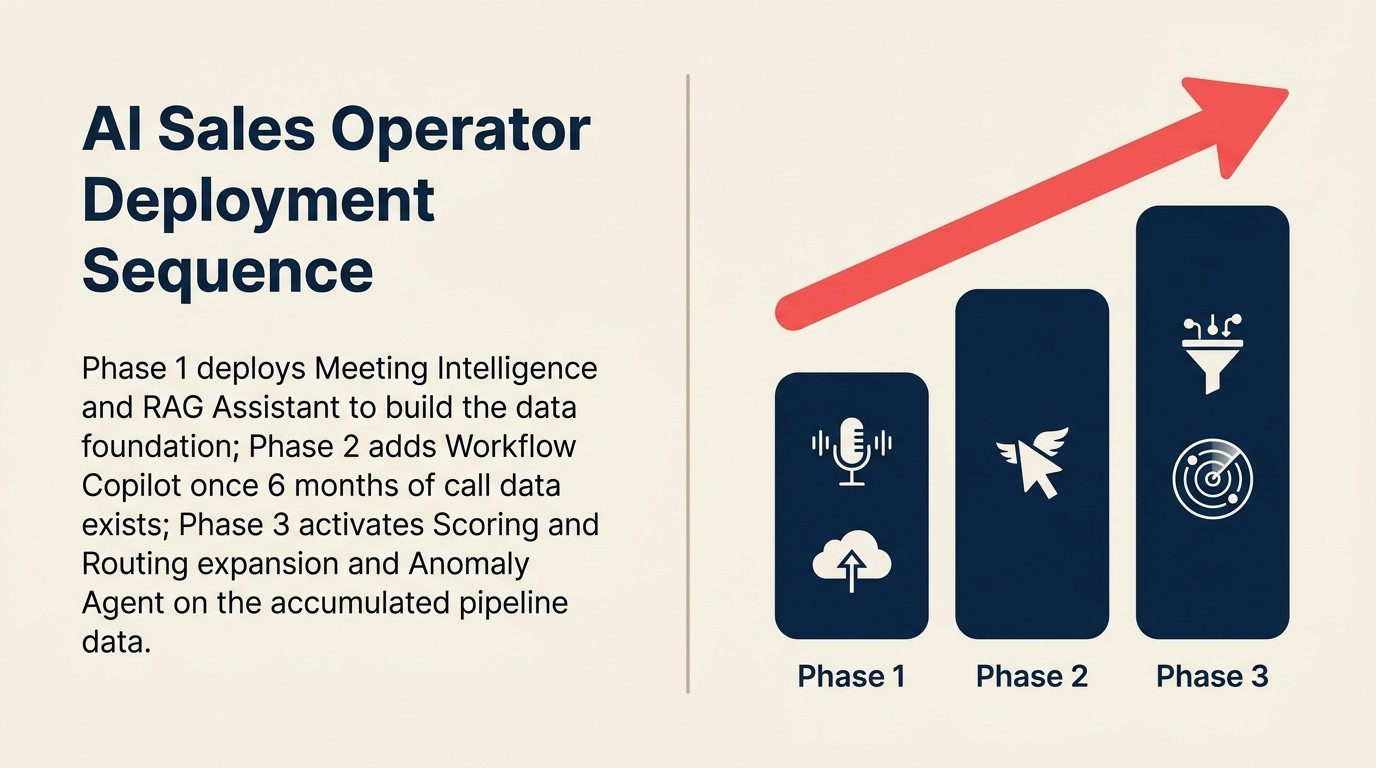
Phase 1 (song song, tuần 1-4)
Chạy song song vì hai phần này độc lập với nhau:
Thiết lập Scoring and Routing: Export hồ sơ CRM lịch sử với nhãn kết quả (closed-won/closed-lost, qualified/disqualified). Tối thiểu 6 tháng dữ liệu có nhãn, lý tưởng là 12. Train scoring model ban đầu. Cấu hình routing rules engine. Kiểm tra trên tập holdout trước khi đưa vào production.
Thiết lập Meeting Intelligence: Xác nhận quyền truy cập lưu trữ audio và tính tương thích định dạng. Dựng pipeline speech-to-text. Xác định schema đầu ra có cấu trúc: trường nào (action items, phản đối, tín hiệu stage, sentiment) chảy đến hệ thống downstream nào. Kiểm tra với 20 call đã ghi trước khi đưa vào production.
Phase 2 (tuần tự, tuần 5-8)
Hai phần này phụ thuộc vào đầu ra của Phase 1:
Thiết lập RAG Assistant: Cần knowledge base được duy trì. Kiểm toán tài liệu hiện có. Xác định cái gì còn hiệu lực, cái gì đã lỗi thời. Giao quyền sở hữu cho mỗi danh mục tài liệu. Xây dựng embedding pipeline. Chunk và embed knowledge base. Thiết lập cadence làm mới (hàng tuần cho tài liệu thay đổi nhanh, hàng tháng cho chính sách ổn định).
Tích hợp Workflow Copilot: Cần Meeting Intelligence đang tạo ra đầu ra có cấu trúc (để có call context để hành động) và cần Scoring and Routing đang chạy (để priority signal cung cấp cho copilot). Cấu hình Copilot có thể bắt đầu ở Phase 1 như một build task, nhưng không thể kiểm tra có ý nghĩa cho đến khi các pattern upstream đang tạo ra dữ liệu.
Phase 3 (tuần 9-12)
Kiểm tra full stack. Chạy cả bốn pattern cùng nhau với nhóm pilot 10-15 reps. Đo lường riêng từng pattern: Meeting Intelligence có tạo ra bản tóm tắt chính xác không? Scoring and Routing có routing đúng không? RAG Assistant có hiển thị tài liệu liên quan không? Workflow Copilot có được reps chấp nhận hay bị bỏ qua? Sửa ở cấp pattern trước khi điều chỉnh toàn stack.
Chuỗi này không phải tùy chọn. Các team cố build cả bốn pattern đồng thời sẽ phát hiện trong integration testing rằng các pattern upstream chưa sẵn sàng, và các pattern downstream phải làm lại từ đầu.
"Scoring model được deploy mà không có dữ liệu lịch sử nhãn kết quả sẽ tạo ra điểm số không tương quan với kết quả thực tế. Lead điểm cao thất bại đóng deal ở tỷ lệ kỳ vọng. Điểm số trông hoạt động nhưng thực chất là nhiễu. Nguyên nhân gốc rễ là feature data và outcome data tồn tại trong các hệ thống riêng biệt và chưa bao giờ được join trước khi model được train." (Folio3 AI Enterprise Pattern Analysis, 2026)
Các failure mode điều kiện tiên quyết phổ biến theo pattern

RAG Assistant deploy mà không có knowledge base được duy trì. Triệu chứng: trợ lý đưa ra câu trả lời tự tin đã 18 tháng lỗi thời. Người dùng tin tưởng câu trả lời, hành động theo đó, rồi phát hiện sai. Nguyên nhân gốc rễ là knowledge base được xây dựng một lần và không bao giờ làm mới. Ba tháng sau, tài liệu sản phẩm đã thay đổi, chính sách đã cập nhật, và RAG Assistant đang trích dẫn nội dung đã bị thay thế. Giải pháp: giao quyền sở hữu knowledge base trước khi deploy RAG Assistant. Mỗi danh mục tài liệu có người chịu trách nhiệm cập nhật. Cadence làm mới embedding do một scheduled job thực thi, không phải can thiệp thủ công.
Scoring and Routing deploy mà không có dữ liệu kết quả lịch sử có nhãn. Triệu chứng: scoring model tạo ra điểm số không tương quan với kết quả thực tế. Lead điểm cao không đóng được. Lead điểm thấp lại chuyển đổi. Điểm số trông hoạt động nhưng thực chất là nhiễu. Nguyên nhân gốc rễ là không có dữ liệu kết quả lịch sử, hoặc outcome data tồn tại ở một hệ thống còn feature data ở hệ thống khác, chưa bao giờ được join. Giải pháp: trước khi train bất kỳ scoring model nào, xác nhận rằng tập hồ sơ lịch sử có nhãn kết quả nhất quán và các feature field dùng để scoring điền được trên 80% hồ sơ.
Anomaly Agent deploy mà không có thời gian baseline. Triệu chứng: agent báo cảnh báo cho mọi thứ hoặc không báo gì. Model không có baseline để so sánh, nên nó coi mọi biến thể là bất thường, hoặc học một baseline từ quá ít dữ liệu không đại diện cho phân phối thực. Giải pháp: thu thập 60 đến 90 ngày dữ liệu baseline trước khi kích hoạt anomaly detection. Chạy model ở chế độ shadow trong quá trình thu thập baseline: log những gì nó sẽ flag, so sánh với kết quả thực tế, rồi calibrate ngưỡng trước khi đưa vào production.
Autonomous Agent deploy mà không có tool API đã được kiểm tra. Triệu chứng: agent chạy, gọi một tool, nhận response format không mong đợi, rồi hoặc lặp vô hạn hoặc thực hiện hành động không có chủ ý do phân tích sai. Nguyên nhân gốc rễ là tool schema được mô tả nhưng không được kiểm tra ở cấp API. Giải pháp: kiểm tra riêng từng tool mà agent có quyền truy cập trước khi deploy agent. Xác minh response format khớp với kỳ vọng của agent. Xây dựng error branch cho từng failure mode của mỗi tool trước lần production run đầu tiên.
Checklist kiểm toán sẵn sàng dữ liệu
Chạy checklist này trước khi phê duyệt bất kỳ triển khai pattern nào:
Tính sẵn có của dữ liệu
- Dữ liệu cần thiết tồn tại và có thể truy cập bởi hệ thống đang xây dựng
- Quyền truy cập được xác nhận (không phải giả định từ sơ đồ tổ chức)
- Khối lượng dữ liệu đủ (số lượng record tối thiểu để training, embedding, hoặc baseline)
Chất lượng dữ liệu
- Nhãn kết quả tồn tại và chính xác cho các pattern yêu cầu chúng (Scoring, Anomaly)
- Các trường chính có tỷ lệ điền trên 80% (không chủ yếu trống hoặc null)
- Không có thiên kiến có hệ thống trong tập training có thể làm lệch đầu ra model
NIST AI Risk Management Framework xác định độ chính xác, tính đầy đủ, tính nhất quán, tính hợp lệ, tính duy nhất, và tính kịp thời là sáu chiều chính quyết định liệu hệ thống AI có tạo ra đầu ra đáng tin cậy hay không. Mỗi mục trong checklist này ánh xạ đến một hoặc nhiều chiều đó.
Độ tươi mới của dữ liệu
- Dữ liệu đủ mới để có liên quan (dữ liệu lỗi thời tệ hơn không có dữ liệu với một số pattern)
- Cadence làm mới được xác định và có người chịu trách nhiệm, không phải giả định
- Dữ liệu cũ vượt quá ngưỡng hữu ích bị loại trừ hoặc giảm trọng số
Sẵn sàng cơ sở hạ tầng
- Pipeline ingestion được xây dựng và kiểm tra
- Lưu trữ và tính toán được cấp phát
- Các API endpoint được xác nhận có thể truy cập với quyền đúng
- Yêu cầu độ trễ được đáp ứng bởi cấu hình cơ sở hạ tầng
Governance
- Việc sử dụng dữ liệu được đề cập bởi điều khoản dịch vụ hoặc sự đồng ý của người dùng
- Xử lý PII được xác định và tuân thủ quy định áp dụng
- Audit trail có sẵn cho bất kỳ đầu ra Execute-path nào
Nếu bất kỳ checkbox nào chưa được đánh dấu, pattern chưa sẵn sàng để deploy. Mục còn thiếu là điều kiện tiên quyết, không phải thứ tốt để có.
Điều kiện tiên quyết cơ sở hạ tầng mà các team thường bỏ qua
Embedding pipeline cho RAG. Đây không phải là "upload tài liệu vào tool." Đó là một scheduled pipeline thực hiện: đọc tài liệu mới hoặc đã cập nhật, chunk theo phần, generate embedding dùng cùng phiên bản model với retrieval endpoint, ghi vào vector database, và xử lý tài liệu đã xóa hoặc được thay thế bằng cách xóa embedding tương ứng. Pipeline này là khoản đầu tư kỹ thuật thực sự. Khi scope thành "vendor xử lý" thường có nghĩa là nó không thực sự chạy, đó là lý do knowledge base trở nên lỗi thời.
CRM webhooks cho Scoring and Routing. Scoring model cần chạy bất cứ khi nào một record liên quan thay đổi. Điều đó yêu cầu CRM webhooks được cấu hình để kích hoạt trên đúng các sự kiện (lead được tạo, deal stage được cập nhật, thông tin liên hệ thay đổi). Nhiều CRM implementation có webhooks khả dụng nhưng không được cấu hình. Đây là một tác vụ kỹ thuật ba ngày nhưng block toàn bộ Scoring pattern nếu bị bỏ qua.
Audio processing pipeline cho Meeting Intelligence. Bản ghi âm cần: được thu với chất lượng đủ tốt (tối thiểu 16 kHz mono), được lưu trữ có thể truy cập, được liên kết với đúng người tham gia và deal metadata, và được xử lý trong khoảng thời gian hợp lý sau khi cuộc họp kết thúc. Nếu bản ghi âm lưu trong hệ thống vendor không có export API, hoặc nếu chất lượng quá thấp để phiên âm chính xác, pattern không thể chạy. Đây là ràng buộc hạ tầng cứng mà không chất lượng model nào có thể vượt qua.
| Loại thất bại điều kiện tiên quyết | Pattern bị ảnh hưởng nhiều nhất | Thời điểm phát hiện điển hình | Thời gian trì hoãn trung bình |
|---|---|---|---|
| Không có dữ liệu kết quả có nhãn | Scoring + Routing, Anomaly Agent | Tuần 3-4 kiểm tra | 8-12 tuần |
| Knowledge base không bao giờ làm mới | RAG Assistant | Tuần 3 của pilot (khi người dùng phát hiện câu trả lời sai) | 4-6 tuần |
| Audio lưu trữ không có export API | Meeting Intelligence | Kiểm toán vendor trước build (nếu được thực hiện) hoặc tuần 1 integration | 6-10 tuần |
| Tool API chưa được kiểm tra | Autonomous Agent | Lần production run đầu tiên | 2-4 tuần cộng phục hồi sự cố |
| CRM webhooks không được cấu hình | Scoring + Routing, Workflow Copilot | Integration testing, tuần 2 | 1-3 tuần |
Chuỗi triển khai cho team bị hạn chế tài nguyên
Khi bạn không thể build tất cả pattern đồng thời, ưu tiên chuỗi đạt giá trị sớm nhất và ít nợ điều kiện tiên quyết nhất:
Bắt đầu với các pattern không có phụ thuộc và có giá trị độc lập. RAG Assistant (nếu bạn có knowledge base) và Scoring and Routing (nếu bạn có dữ liệu lịch sử có nhãn) đều có thể deploy độc lập và mang lại giá trị ngay lập tức. Chúng cũng không tạo ra đầu ra mà các pattern khác phụ thuộc vào, nên bắt đầu hai pattern này không tạo ra technical debt cho các downstream implementation. Để biết cách chuỗi các lựa chọn này qua kế hoạch nhiều năm, xem chuỗi AI patterns trong lộ trình.
Thu thập dữ liệu bạn sẽ cần sau này, bắt đầu ngay bây giờ. Nếu bạn dự định thêm Meeting Intelligence trong sáu tháng, hãy bắt đầu lưu bản ghi âm call ở đúng định dạng ngay hôm nay. Nếu bạn dự định thêm Anomaly Agent, hãy bắt đầu thu thập metric nhất quán từ một ngày baseline được xác định. Chi phí thu thập dữ liệu thấp. Việc phát hiện ra bạn cần 90 ngày dữ liệu nhưng chỉ có 12 ngày mới thực sự đắt.
Deploy Workflow Copilot sau khi các phụ thuộc upstream đang chạy. Copilot được xây dựng trước Meeting Intelligence và Scoring and Routing chỉ tạo ra gợi ý chung chung thay vì gợi ý giàu ngữ cảnh. Đợi cho đến khi các pattern upstream đang tạo ra dữ liệu trước khi đầu tư vào layer copilot.
Cập nhật điều kiện tiên quyết theo thời gian
Các pattern vận hành tốt ở năm 1 có thể xuống cấp ở năm 2 nếu điều kiện tiên quyết không được duy trì:
- Knowledge base trở nên lỗi thời khi sản phẩm và chính sách thay đổi
- Scoring model drift khi thành phần thị trường thay đổi (nhiều enterprise customer hơn so với khi model được train, close rate khác, sales cycle khác)
- Anomaly detection baseline xây dựng trong một quý có thể sai cho một mẫu theo mùa khác
Nghiên cứu McKinsey về lập bản đồ con đường đến doanh nghiệp dựa trên dữ liệu và AI khuyến nghị xây dựng một nền tảng dữ liệu cho analytics và AI, dùng ở mọi nơi thay vì các pipeline riêng biệt cho từng hệ thống. Cách tiếp cận đó là phiên bản hạ tầng của việc xác định lịch bảo trì điều kiện tiên quyết trước khi bạn cần đến nó.
Xây dựng lịch bảo trì cho điều kiện tiên quyết của mỗi pattern:
- RAG knowledge base: review và cập nhật tối thiểu hàng quý; thay đổi sản phẩm lớn kích hoạt làm mới ngay lập tức
- Scoring model: retrain mỗi 6 tháng với fresh outcome data; giám sát model drift metrics hàng tháng
- Anomaly baseline: recalibrate bất cứ khi nào có thay đổi kinh doanh đáng kể (dòng sản phẩm mới, thị trường mới, tái cơ cấu team lớn)
Kiểm toán điều kiện tiên quyết khi deploy không phải sự kiện một lần. Đó là điểm khởi đầu cho một nhịp bảo trì liên tục.
Câu Hỏi Thường Gặp
Điều kiện tiên quyết AI bị bỏ qua nhiều nhất là gì?
Tính sẵn có của dữ liệu được giả định, nhưng khả năng truy cập và chất lượng lại không được xác nhận. Một record tồn tại trong CRM không đồng nghĩa với record đó có nhãn kết quả chính xác, các feature field được điền đầy đủ, và định dạng tương thích với model cần tiêu thụ nó. RAND Corporation cho thấy 85% dự án AI thất bại trích dẫn chất lượng dữ liệu là nguyên nhân gốc rễ.
Kiểm toán điều kiện tiên quyết thường mất bao lâu?
Kiểm toán toàn diện qua cả ba danh mục phụ thuộc (dữ liệu, cơ sở hạ tầng, phụ thuộc pattern) mất 2-3 tuần cho một pattern đơn và 4-6 tuần cho một multi-pattern stack. Khoản đầu tư đó loại bỏ các trì hoãn 8-12 tuần xảy ra khi điều kiện tiên quyết bị thiếu xuất hiện trong integration testing. Các chương trình thành công dành 50-70% timeline dự án AI cho công việc sẵn sàng dữ liệu.
Tất cả AI pattern có cùng điều kiện tiên quyết không?
Không. RAG Assistant, Document Review, và Vision Extract không có phụ thuộc pattern upstream và có thể deploy trước. Meeting Intelligence, Scoring and Routing, và Generative Research cũng không có phụ thuộc pattern nhưng có yêu cầu dữ liệu cụ thể. Workflow Copilot và Anomaly Agent thường phụ thuộc vào pattern upstream để tạo ra đầu ra giàu ngữ cảnh. Autonomous Agent có điều kiện tiên quyết cơ sở hạ tầng nghiêm ngặt nhất, yêu cầu mọi tool API phải được kiểm tra trước khi deploy.
Điều gì xảy ra nếu bạn deploy Scoring model mà không có dữ liệu lịch sử có nhãn?
Scoring model tạo ra điểm số không tương quan với kết quả thực tế. Lead điểm cao thất bại đóng ở tỷ lệ dự đoán. Lead điểm thấp chuyển đổi ở tỷ lệ model gán xác suất thấp. Model trông hoạt động nhưng thực chất là nhiễu. Giải pháp: trước khi train, xác nhận tập hồ sơ lịch sử có nhãn kết quả nhất quán và feature field được điền trong hơn 80% hồ sơ.
Điều kiện tiên quyết AI pattern nên được kiểm toán lại bao lâu một lần sau khi deploy?
RAG knowledge base nên review tối thiểu hàng quý, với làm mới ngay lập tức khi có thay đổi sản phẩm hoặc chính sách lớn. Scoring model nên retrain mỗi sáu tháng với fresh outcome data, kèm giám sát model drift hàng tháng. Anomaly detection baseline cần recalibrate bất cứ khi nào có thay đổi kinh doanh đáng kể (dòng sản phẩm mới, thị trường mới, tái cơ cấu team lớn). Điều kiện tiên quyết không phải là kiểm tra một lần.
Pattern Dependency Map là gì?
Pattern Dependency Map là cấu trúc kiểm toán điều kiện tiên quyết phân loại mọi AI pattern theo ba trục trước khi triển khai: phụ thuộc dữ liệu, phụ thuộc cơ sở hạ tầng, và phụ thuộc pattern (các pattern upstream phải đang chạy trước). Chạy map trước quyết định build loại bỏ các trì hoãn ba đến sáu tháng xảy ra khi điều kiện tiên quyết bị thiếu xuất hiện giữa quá trình integration.
Tìm hiểu thêm

Co-Founder, Rework.com
On this page
- Các loại phụ thuộc
- Bản đồ phụ thuộc theo pattern
- Pattern Dependency Map
- Con đường quan trọng: chuỗi triển khai AI Sales Operator
- Các failure mode điều kiện tiên quyết phổ biến theo pattern
- Checklist kiểm toán sẵn sàng dữ liệu
- Điều kiện tiên quyết cơ sở hạ tầng mà các team thường bỏ qua
- Chuỗi triển khai cho team bị hạn chế tài nguyên
- Cập nhật điều kiện tiên quyết theo thời gian
- Tìm hiểu thêm