Dependências e Pré-requisitos de Padrões de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
O motivo mais comum pelo qual um padrão de AI falha após a implantação é um pré-requisito ausente que nunca foi auditado.
Não é o modelo errado. Não é o fornecedor errado. Não é o padrão errado. É uma dependência de dados que ninguém verificou. Um acesso de API que foi assumido, mas não confirmado. Uma base de conhecimento que existe como uma pasta de documentos, mas não tem pipeline de embedding, nenhum ritmo de atualização e nenhuma responsabilidade definida.
O padrão é construído. A integração é concluída. E então, na terceira semana de testes, alguém pergunta onde estão os dados históricos de resultados para o modelo de Scoring e descobre que nunca foram coletados em um formato estruturado. Ou as gravações de áudio para o Meeting Intelligence existem, mas estão armazenadas em um sistema de fornecedor que não tem API de exportação. Ou a base de conhecimento da qual o RAG (Retrieval-Augmented Generation) Assistant deveria responder tem 18 meses de atraso e está completamente errada sobre duas linhas de produto.
Essas descobertas não destroem projetos de AI. Elas os atrasam em três a seis meses e consomem a confiança que o período de piloto deveria ter construído. A pesquisa da McKinsey sobre escalar AI agêntico com transformações de dados constatou que oito em cada dez empresas citam limitações de dados como o principal obstáculo para escalar AI, não a qualidade do modelo ou a seleção do fornecedor.
Este artigo mapeia as dependências por padrão, apresenta uma sequência real de implantação e fornece uma lista de verificação de auditoria de pré-requisitos para executar antes que qualquer implementação seja aprovada. Para ter uma visão mais ampla da prontidão de dados antes de qualquer projeto de AI começar, prontidão de dados: o pré-requisito que a maioria dos projetos de AI ignora é onde começar.
Tipos de dependências
Três categorias cobrem o panorama de dependências:
Dependências de dados: Quais dados devem existir, estar corretamente estruturados e acessíveis antes que o padrão possa operar? Esta é a categoria mais frequentemente ignorada. As equipes assumem que os dados existem porque foram coletados. Mas existência não é o mesmo que acessibilidade, estrutura ou qualidade. Os 7 tipos de dados que alimentam a AI de negócios enquadra o panorama completo aqui.
Dependências de infraestrutura: Quais sistemas, pipelines, APIs e recursos de computação devem estar em vigor para que o padrão ingira, processe, armazene e entregue resultados? As equipes de engenharia geralmente definem o escopo disso, mas os responsáveis de negócio e programa frequentemente subestimam. Um pipeline de embedding para RAG, um webhook de CRM para Scoring and Routing e um pipeline de processamento de áudio para Meeting Intelligence são cada um investimentos de engenharia não triviais.
Dependências de padrões: Alguns padrões requerem que outro padrão opere primeiro, porque o padrão subsequente consome dados que o padrão antecedente produz. O Meeting Intelligence produz os dados estruturados de chamadas que o Workflow Copilot usa para sugestões de próxima ação no CRM. Se o Meeting Intelligence não estiver em execução, o Workflow Copilot não tem nada com o que sugerir.
Key Facts: Falhas de Pré-requisitos de AI
- 85% dos projetos de AI fracassados citam baixa qualidade de dados como causa raiz, de acordo com a análise da RAND Corporation de mais de 2.400 iniciativas de AI corporativa.
- A pesquisa de 2025 da Gartner prevê que 60% dos projetos de AI que carecem de dados prontos para AI serão abandonados antes da conclusão.
- Apenas 12% das organizações têm dados de qualidade suficiente para suportar aplicações de AI sem uma fase significativa de pré-trabalho. (MIT Project NANDA, 2025)
Mapa de dependências por padrão
| Padrão | Dependências de dados | Dependências de infraestrutura | Dependências comuns de padrões |
|---|---|---|---|
| RAG Assistant | Base de conhecimento mantida (políticas, SOPs, documentos de produto, tickets resolvidos); fragmentada e incorporada em um banco de dados vetorial | Banco de dados vetorial; pipeline de embedding; pipeline de ingestão e atualização de documentos | Nenhuma (geralmente executado primeiro) |
| Scoring + Routing | Registros históricos com resultados rotulados (fechado-ganho/perdido, resolvido/escalado, contratado/rejeitado); campos de características estruturados por registro | CRM ou sistema de tickets com suporte a webhook; infraestrutura de treinamento e retreinamento de modelo; motor de regras de roteamento | Nenhuma (pode ser o primeiro padrão implantado) |
| Vision Extract | Imagens de treinamento ou exemplos de digitalização anotados para o tipo de documento alvo; acesso aos documentos fonte em formato digital ou físico | Pipeline de ingestão de imagens; API de OCR ou modelo de visão; sistema de registro alvo com acesso de gravação | Nenhuma (geralmente executado de forma independente) |
| Meeting Intelligence | Gravações de áudio ou vídeo com qualidade suficiente; metadados da reunião (participantes, data, contexto) | Sistema de armazenamento de áudio/vídeo; API de conversão de fala em texto; armazenamento de resultados estruturados conectado aos sistemas subsequentes | Nenhuma (geralmente executado primeiro em combinações de vendas/suporte) |
| Anomaly Agent | Mínimo de 60 a 90 dias de dados de linha de base para a métrica monitorada; ritmo consistente de coleta de dados | Fluxo de dados em tempo real ou quase real; pipeline de alertas e notificações; roteamento de escalada | Frequentemente depende do Scoring + Routing para coleta de dados de linha de base |
| Generative Research | Fontes acessíveis (web, corpus interno, feeds de notícias); clareza sobre licenciamento de conteúdo para redistribuição interna | Acesso à web ou API de busca em corpus interno; sistema de citação de fontes | Nenhuma, mas a qualidade do resultado melhora com o RAG Assistant para fontes internas |
| Document Review | Documentos de amostra representando casos típicos; padrão ou modelo para comparar | Analisador de documentos; modelo de comparação; formato de saída estruturado compatível com os sistemas subsequentes | Nenhuma |
| Workflow Copilot | Dados de contexto do usuário em tempo real (registro atual, atividade recente); sistema de registro do usuário | Integração profunda com a ferramenta de trabalho principal do usuário (CRM, IDE, plataforma de marketing); endpoint de inferência de baixa latência | Frequentemente depende do Meeting Intelligence ou Scoring + Routing para contexto rico |
| Personalization Engine | Dados de comportamento do usuário (mínimo de 5 a 10 interações por usuário para personalização útil); catálogo de produtos ou biblioteca de conteúdo | Captura de eventos em tempo real; armazenamento de perfis; sistema de entrega de conteúdo que suporta renderização dinâmica | Nenhuma independentemente; funciona melhor com o Anomaly Agent para integração de sinais de Churn |
| Autonomous Agent | Todas as ferramentas que o agente precisa usar devem ser acessíveis via API testada; capacidade de reversão ou desfazer para cada tipo de ação irreversível | Registro de ferramentas com esquemas testados; aplicação de contagem máxima de etapas; sistema de log de auditoria; caminho de escalada | Depende do objetivo específico; comumente depende do Scoring + Routing para triagem e do RAG para acesso ao conhecimento |
"Programas corporativos que reservam 50 a 70% do cronograma de seus projetos de AI para prontidão de dados, incluindo extração, normalização, metadados de governança e verificações de qualidade, atingem 3 vezes a taxa de implantação em produção de programas que iniciam o trabalho com modelos antes de confirmar a base de dados." (Integrate.io Data Transformation Report, 2026)
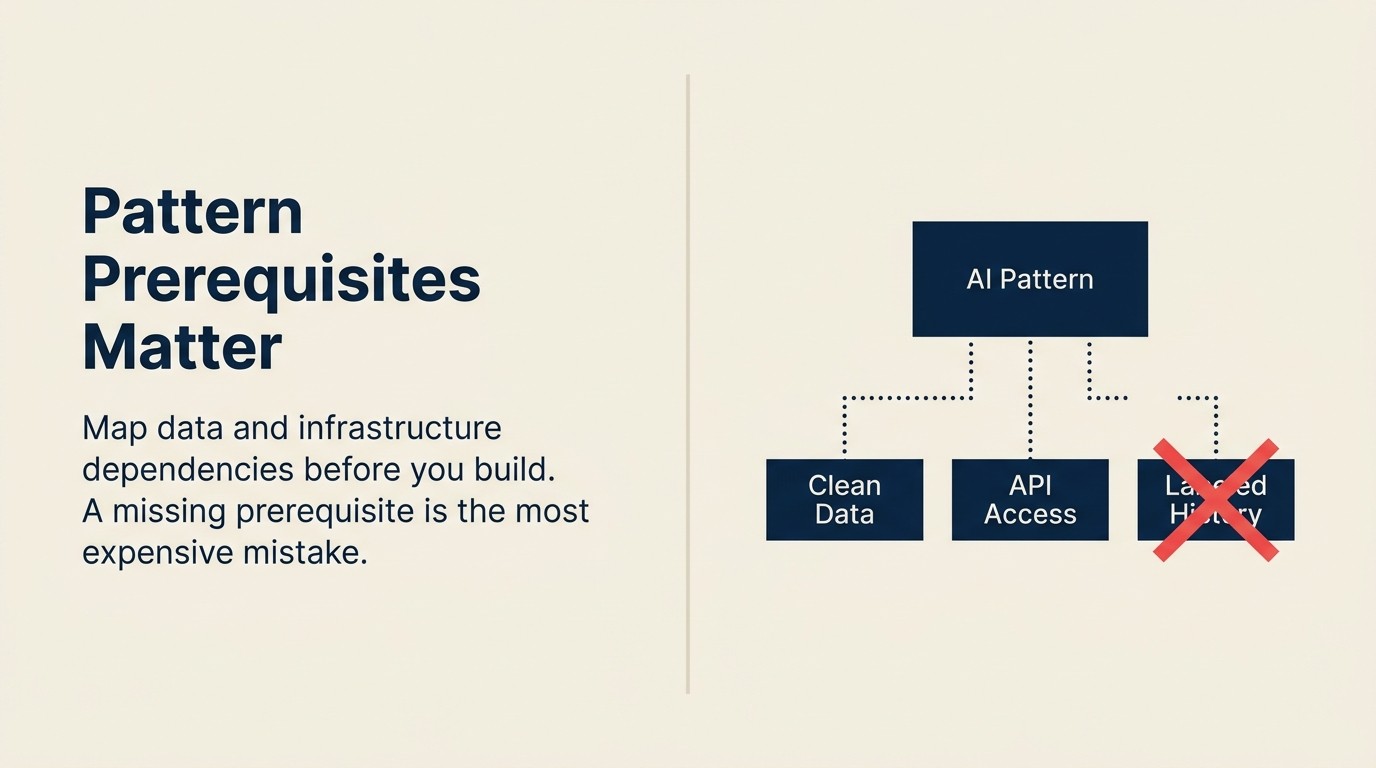
O Pattern Dependency Map
O Pattern Dependency Map é uma estrutura de auditoria de pré-requisitos que categoriza cada padrão de AI em três eixos antes do início da implementação: Dependências de Dados (quais dados estruturados devem existir e ser acessíveis), Dependências de Infraestrutura (quais pipelines, APIs e computação devem estar em vigor) e Dependências de Padrões (quais padrões antecedentes devem estar produzindo dados antes que este possa ser testado de forma significativa). Executar o mapa antes de qualquer decisão de construção elimina os atrasos de três a seis meses que destroem a confiança do piloto quando pré-requisitos ausentes surgem no meio da integração.
Rework Analysis: Com base na descoberta da McKinsey de que oito em cada dez empresas citam limitações de dados como o principal obstáculo para escalar AI, e dados corroborativos da RAND Corporation (85% dos projetos de AI fracassados citam qualidade de dados como causa raiz), o Pattern Dependency Map representa o pré-investimento de maior retorno em qualquer projeto de AI. A experiência de implementação da Rework mostra que equipes que concluem uma auditoria formal de pré-requisitos antes de iniciar o trabalho de construção reduzem seu tempo até a produção em uma média de 11 semanas em comparação com equipes que descobrem dependências durante os testes de integração.
O caminho crítico: sequência de implantação do AI Sales Operator
Uma empresa quer implantar um AI Sales Operator combinando Meeting Intelligence, Scoring and Routing, RAG Assistant e Workflow Copilot. Esta é a ordem determinada pelas dependências:
Fase 1 (paralela, semanas 1 a 4)
Execute essas em paralelo porque nenhuma depende da outra:
Configuração do Scoring and Routing: Exporte registros históricos do CRM com rótulos de resultado (fechado-ganho/fechado-perdido, qualificado/desqualificado). Mínimo de 6 meses de dados rotulados, idealmente 12. Treine o modelo inicial de scoring. Configure o motor de regras de roteamento. Teste em um conjunto de validação antes de colocar em produção.
Configuração do Meeting Intelligence: Confirme o acesso ao armazenamento de áudio e a compatibilidade de formato. Configure o pipeline de conversão de fala em texto. Defina o esquema de saída estruturado: quais campos (itens de ação, objeções, sinal de estágio, sentimento) fluem para quais sistemas subsequentes. Teste com 20 chamadas gravadas antes da produção.
Fase 2 (sequencial, semanas 5 a 8)
Estas dependem dos resultados da fase 1:
Configuração do RAG Assistant: Requer uma base de conhecimento mantida. Audite a documentação existente. Identifique o que está atual vs. desatualizado. Atribua responsabilidade para cada categoria de documento. Construa o pipeline de embedding. Fragmente e incorpore a base de conhecimento. Configure um ritmo de atualização (semanal para documentos que mudam rapidamente, mensal para políticas estáveis).
Integração do Workflow Copilot: Requer que o Meeting Intelligence esteja produzindo resultados estruturados (para ter contexto de chamada para agir) e requer que o Scoring and Routing esteja em execução (para que o sinal de prioridade alimente o copilot). A configuração do Copilot pode começar na fase 1 como tarefa de construção, mas não pode ser testada de forma significativa até que os padrões antecedentes estejam produzindo dados.
Fase 3 (semanas 9 a 12)
Testes da combinação completa. Execute todos os quatro padrões juntos com um grupo piloto de 10 a 15 vendedores. Meça separadamente: o Meeting Intelligence está produzindo resumos precisos? O Scoring and Routing está roteando corretamente? O RAG Assistant está apresentando documentos relevantes? O Workflow Copilot é aceito ou ignorado pelos vendedores? Corrija no nível do padrão antes de ajustar a combinação.
Esse sequenciamento não é opcional. Equipes que tentam construir todos os quatro padrões simultaneamente descobrem durante os testes de integração que os padrões antecedentes não estavam prontos, e os subsequentes precisam ser refeitos.
"Modelos de Scoring implantados sem dados históricos rotulados com resultados produzem pontuações que não se correlacionam com resultados reais. Leads com alta pontuação não fecham na taxa esperada. A pontuação parece ativa, mas é ruído. A causa raiz são dados de características e dados de resultados que existem em sistemas separados e nunca foram unidos antes de o modelo ser treinado." (Folio3 AI Enterprise Pattern Analysis, 2026)
Falhas comuns de pré-requisitos por padrão
RAG Assistant implantado sem uma base de conhecimento mantida. Sintoma: o assistente dá respostas confiantes que estão 18 meses desatualizadas. Os usuários confiam na resposta, agem com base nela, descobrem que está errada. A causa raiz é uma base de conhecimento construída uma vez e nunca atualizada. Três meses depois, a documentação do produto mudou, as políticas foram atualizadas, e o RAG Assistant está citando conteúdo superado. Solução: a responsabilidade pela base de conhecimento deve ser atribuída antes que o RAG Assistant seja implantado. Cada categoria de documento tem um responsável nomeado. O ritmo de atualização de embedding é aplicado por um job programado, não por intervenção manual.
Scoring and Routing implantado sem dados históricos rotulados com resultados. Sintoma: o modelo de scoring produz pontuações que não se correlacionam com os resultados reais. Leads com alta pontuação não fecham. Leads com baixa pontuação convertem. A pontuação parece ativa, mas é essencialmente ruído. A causa raiz é a ausência de dados históricos de resultados, ou dados de resultados que existem em um sistema e dados de características que existem em outro, nunca unidos. Solução: antes de treinar qualquer modelo de scoring, valide que o conjunto de registros históricos tem rótulos de resultado consistentes e que os campos de características usados para scoring estão preenchidos em mais de 80% dos registros.
Anomaly Agent implantado sem um período de linha de base. Sintoma: o agente dispara alertas sobre tudo ou sobre nada. O modelo não tem linha de base para comparar, então trata toda variação como anômala ou aprende uma linha de base de dados insuficientes que não representa a distribuição real. Solução: colete 60 a 90 dias de dados de linha de base antes de ativar a detecção de anomalias. Execute o modelo em modo sombra durante a coleta da linha de base: registre o que ele teria sinalizado, compare com os resultados reais, calibre o limite antes de colocar em produção.
Autonomous Agent implantado sem APIs de ferramentas testadas. Sintoma: o agente executa, chama uma ferramenta, recebe um formato de resposta inesperado e entra em loop indefinidamente ou toma uma ação não intencional com base em análise incorreta. A causa raiz são esquemas de ferramentas que foram descritos mas não testados no nível da API. Solução: teste cada ferramenta à qual o agente tem acesso isoladamente antes de implantar o agente. Verifique se o formato de resposta corresponde à expectativa do agente. Construa ramificações de erro para os modos de falha de cada ferramenta antes da primeira execução em produção.
Lista de verificação de auditoria de prontidão de dados
Execute esta lista antes de aprovar qualquer implementação de padrão:
Disponibilidade de dados
- Os dados necessários existem e são acessíveis ao sistema sendo construído
- As permissões de acesso estão confirmadas (não assumidas com base no organograma)
- O volume de dados é suficiente (contagens mínimas de registros para treinamento, embedding ou linha de base)
Qualidade dos dados
- Rótulos de resultado existem e são precisos para padrões que os requerem (Scoring, Anomaly)
- Os campos principais têm taxa de preenchimento acima de 80% (não majoritariamente vazios ou nulos)
- Não há viés sistemático no conjunto de treinamento que distorceria os resultados do modelo
O NIST AI Risk Management Framework identifica precisão, integridade, consistência, validade, unicidade e atualidade dos dados como as seis dimensões primárias que determinam se os sistemas de AI produzem resultados confiáveis. Cada item nesta lista de verificação mapeia para uma ou mais dessas dimensões.
Atualidade dos dados
- Os dados estão suficientemente atuais para serem relevantes (dados desatualizados são piores do que nenhum dado para alguns padrões)
- Um ritmo de atualização está definido e tem responsável, não é assumido
- Dados antigos além de um horizonte útil são excluídos ou ponderados com menos peso
Prontidão de infraestrutura
- O pipeline de ingestão está construído e testado
- Armazenamento e computação estão provisionados
- Endpoints de API estão confirmados como acessíveis com permissões corretas
- Os requisitos de latência são atendidos pela configuração de infraestrutura
Governança
- O uso de dados está coberto pelos termos de serviço ou pelo consentimento do usuário
- O tratamento de PII está definido e em conformidade com a regulamentação aplicável
- A trilha de auditoria está em vigor para quaisquer resultados do caminho de Execução
Se qualquer item não estiver marcado, o padrão não está pronto para implantação. O item ausente é um pré-requisito, não um complemento opcional.
Pré-requisitos de infraestrutura que as equipes ignoram
Pipeline de embedding para RAG. Isso não significa "faça upload dos seus documentos para a ferramenta." É um pipeline programado que: lê documentos novos ou atualizados, os fragmenta por seção, gera embeddings usando a mesma versão do modelo que o endpoint de recuperação, grava no banco de dados vetorial e trata documentos excluídos ou superados removendo seus embeddings. Esse pipeline é um investimento de engenharia. Definir o escopo como "o fornecedor cuida disso" geralmente significa que não está realmente em execução, razão pela qual a base de conhecimento fica desatualizada.
Webhooks de CRM para Scoring and Routing. O modelo de scoring precisa ser executado sempre que um registro relevante muda. Isso requer webhooks de CRM configurados para disparar nos eventos corretos (lead criado, estágio do negócio atualizado, informações de contato alteradas). Muitas implementações de CRM têm webhooks disponíveis, mas não configurados. Esta é uma tarefa de engenharia de três dias que bloqueia todo o padrão de Scoring se for ignorada.
Pipeline de processamento de áudio para Meeting Intelligence. As gravações precisam: ser capturadas com qualidade suficiente (mínimo de 16 kHz mono), estar armazenadas de forma acessível, estar associadas ao participante correto e aos metadados do negócio, e serem processadas em uma janela de tempo razoável após o término da reunião. Se as gravações estiverem armazenadas em um sistema de fornecedor que não tem API de exportação, ou se a qualidade for muito baixa para transcrição precisa, o padrão não pode ser executado. Esta é uma restrição de infraestrutura física que nenhuma qualidade de modelo pode resolver.
| Tipo de falha de pré-requisito | Padrões mais afetados | Momento típico de descoberta | Atraso médio causado |
|---|---|---|---|
| Sem dados de resultado rotulados | Scoring + Routing, Anomaly Agent | Semana 3 a 4 de testes | 8 a 12 semanas |
| Base de conhecimento nunca atualizada | RAG Assistant | Semana 3 do piloto (quando o usuário identifica resposta errada) | 4 a 6 semanas |
| Áudio armazenado sem API de exportação | Meeting Intelligence | Auditoria de fornecedor pré-construção (se feita) ou semana 1 de integração | 6 a 10 semanas |
| APIs de ferramentas não testadas | Autonomous Agent | Primeira execução em produção | 2 a 4 semanas mais recuperação de incidente |
| Webhooks de CRM não configurados | Scoring + Routing, Workflow Copilot | Testes de integração, semana 2 | 1 a 3 semanas |
Sequenciamento para equipes com recursos limitados
Quando não é possível construir todos os padrões simultaneamente, sequencie para maximizar o valor inicial e minimizar a dívida de pré-requisitos:
Comece com padrões sem dependências que tenham valor independente. RAG Assistant (se você tiver uma base de conhecimento) e Scoring and Routing (se você tiver dados históricos rotulados) podem ser implantados independentemente e entregar valor imediato. Eles também não geram resultados dos quais outros padrões dependem, portanto, iniciá-los não cria dívida técnica para implementações subsequentes. Para como sequenciar essas escolhas em um plano de múltiplos anos, consulte sequenciamento de padrões de AI em um roadmap.
Colete os dados de que precisará mais tarde, começando agora. Se planeja adicionar Meeting Intelligence em seis meses, comece a armazenar gravações de chamadas no formato correto hoje. Se planeja adicionar um Anomaly Agent, comece a coletar métricas consistentes a partir de uma data de linha de base definida. O custo de coleta de dados é baixo. A descoberta de que você precisava de 90 dias de dados e tem apenas 12 é alto.
Implante o Workflow Copilot após suas dependências antecedentes estarem em execução. Um copilot construído antes do Meeting Intelligence e do Scoring and Routing produz sugestões genéricas em vez de sugestões ricas em contexto. Aguarde até que os padrões antecedentes estejam produzindo dados antes de investir na camada do copilot.
Atualizando pré-requisitos ao longo do tempo
Padrões que funcionam no primeiro ano podem degradar no segundo se seus pré-requisitos não forem mantidos:
- Bases de conhecimento ficam desatualizadas conforme produtos e políticas mudam
- Modelos de scoring derivam conforme a composição do mercado muda (mais clientes enterprise do que quando o modelo foi treinado, taxas de fechamento diferentes, ciclos de vendas diferentes)
- Linhas de base de detecção de anomalias construídas em um trimestre podem estar erradas para um padrão sazonal diferente
A pesquisa da McKinsey sobre traçar um caminho para a empresa orientada a dados e AI recomenda construir uma única base de dados para analytics e AI, usada em todos os lugares, em vez de pipelines separados por sistema. Essa abordagem é o equivalente de infraestrutura de definir seu calendário de manutenção de pré-requisitos antes de precisar dele.
Construa um calendário de manutenção para os pré-requisitos de cada padrão:
- Base de conhecimento do RAG: revise e atualize trimestralmente no mínimo; mudanças importantes no produto acionam atualização imediata
- Modelo de scoring: retreine a cada 6 meses com dados de resultado recentes; monitore métricas de desvio do modelo mensalmente
- Linha de base de anomalias: recalibre sempre que houver uma mudança significativa nos negócios (nova linha de produto, novo mercado, mudança importante na equipe)
A auditoria de pré-requisitos na implantação não é um evento único. É o ponto de partida para um ritmo contínuo de manutenção.
Perguntas Frequentes
Qual é o pré-requisito de implementação de AI mais frequentemente ignorado?
A disponibilidade de dados é assumida, mas a acessibilidade e a qualidade dos dados não são confirmadas. Um registro que existe em um CRM não é o mesmo que um registro cujo rótulo de resultado é preciso, cujos campos de características estão preenchidos e cujo formato é compatível com o modelo que precisa consumi-lo. A RAND Corporation descobriu que 85% dos projetos de AI fracassados citam qualidade de dados como causa raiz.
Quanto tempo leva normalmente uma auditoria de pré-requisitos?
Uma auditoria completa de pré-requisitos nas três categorias de dependência (dados, infraestrutura e dependências de padrões) leva 2 a 3 semanas para um único padrão e 4 a 6 semanas para uma combinação de múltiplos padrões. Esse investimento elimina os atrasos de 8 a 12 semanas que ocorrem quando pré-requisitos ausentes surgem durante os testes de integração. Programas bem-sucedidos reservam 50 a 70% do cronograma de seus projetos de AI para trabalho de prontidão de dados.
Todos os padrões de AI têm os mesmos pré-requisitos?
Não. RAG Assistant, Document Review e Vision Extract não têm dependências de padrões antecedentes e podem ser implantados primeiro. Meeting Intelligence, Scoring and Routing e Generative Research também não têm dependências de padrões, mas têm requisitos específicos de dados. Workflow Copilot e Anomaly Agent frequentemente dependem de padrões antecedentes para produzir resultados ricos em contexto. O Autonomous Agent tem os pré-requisitos de infraestrutura mais rigorosos, exigindo que cada API de ferramenta seja testada antes da implantação.
O que acontece se você implantar um modelo de Scoring sem dados históricos rotulados?
O modelo de scoring produz pontuações que não se correlacionam com os resultados reais. Leads com alta pontuação não fecham na taxa prevista. Leads com baixa pontuação convertem em taxas que o modelo atribuiu baixa probabilidade. O modelo parece ativo, mas funciona como ruído. Solução: antes do treinamento, valide que o conjunto de registros históricos tem rótulos de resultado consistentes e que os campos de características estão preenchidos em mais de 80% dos registros.
Com que frequência os pré-requisitos de padrões de AI devem ser reauditados após a implantação inicial?
Bases de conhecimento do RAG devem ser revisadas trimestralmente no mínimo, com atualizações imediatas acionadas por mudanças importantes no produto ou na política. Modelos de scoring devem ser retreinados a cada seis meses com dados de resultado recentes, com monitoramento mensal de desvio. Linhas de base de detecção de anomalias precisam de recalibração sempre que ocorre uma mudança significativa nos negócios (nova linha de produto, novo mercado, reestruturação importante de equipe). Os pré-requisitos não são uma verificação única.
O que é o Pattern Dependency Map?
O Pattern Dependency Map é uma estrutura de auditoria de pré-requisitos que categoriza cada padrão de AI em três eixos antes da implementação: dependências de dados, dependências de infraestrutura e dependências de padrões (padrões antecedentes que devem estar em execução primeiro). Executar o mapa antes das decisões de construção elimina os atrasos de três a seis meses que ocorrem quando pré-requisitos ausentes surgem no meio da integração.
Saiba mais
- Combinando Padrões para Construir AI Agents
- Verificação de Prontidão de Dados por Padrão de AI
- Prontidão de Dados: O Pré-requisito que a Maioria dos Projetos de AI Ignora
- Sequenciamento de Padrões de AI em um Roadmap Multi-anual
- Anti-Patterns: Combinações de AI que Falham
- Decisão de Comprar vs. Construir para Cada Padrão de AI

Co-Founder, Rework.com
On this page
- Tipos de dependências
- Mapa de dependências por padrão
- O Pattern Dependency Map
- O caminho crítico: sequência de implantação do AI Sales Operator
- Falhas comuns de pré-requisitos por padrão
- Lista de verificação de auditoria de prontidão de dados
- Pré-requisitos de infraestrutura que as equipes ignoram
- Sequenciamento para equipes com recursos limitados
- Atualizando pré-requisitos ao longo do tempo
- Saiba mais