Kebergantungan Corak dan Prasyarat
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sebab paling biasa corak AI gagal selepas penggunaan adalah prasyarat yang tiada yang tidak pernah diaudit.
Bukan model yang salah. Bukan vendor yang salah. Bukan corak yang salah. Kebergantungan data yang tidak diperiksa oleh sesiapa pun. Akses API yang diandaikan tetapi tidak disahkan. Pangkalan pengetahuan yang wujud sebagai folder dokumen tetapi tidak mempunyai pipeline pembenaman, tiada kadar penyegaran, dan tiada pemilikan.
Corak dibina. Integrasi diselesaikan. Kemudian, pada minggu ketiga pengujian, seseorang bertanya di mana data keputusan sejarah untuk model Scoring dan mendapati ia tidak pernah dikumpulkan dalam format berstruktur. Atau rakaman audio untuk Meeting Intelligence wujud tetapi disimpan dalam sistem vendor yang tidak mempunyai API eksport. Atau pangkalan pengetahuan yang RAG (Retrieval-Augmented Generation) Assistant sepatutnya menjawab daripadanya adalah lapuk 18 bulan dan benar-benar salah tentang dua lini produk.
Penemuan ini tidak membunuh projek AI. Ia melambatkan mereka selama tiga hingga enam bulan dan menghabiskan muhibah yang sepatutnya dibina oleh tempoh perintis. Penyelidikan McKinsey tentang mengembangkan AI agensi dengan transformasi data mendapati lapan daripada sepuluh syarikat menyebut had data sebagai halangan utama dalam mengembangkan AI, bukan kualiti model atau pemilihan vendor.
Artikel ini memetakan kebergantungan mengikut corak, membincangkan urutan penggunaan sebenar, dan memberi anda senarai semak audit prasyarat untuk dijalankan sebelum sebarang pelaksanaan diluluskan. Untuk gambaran kesediaan data yang lebih luas sebelum sebarang projek AI bermula, kesediaan data: prasyarat yang dilangkau oleh kebanyakan projek AI adalah tempat untuk bermula.
Jenis kebergantungan
Tiga kategori merangkumi lanskap kebergantungan:
Kebergantungan data: Data apakah yang mesti wujud, berstruktur dengan betul, dan boleh diakses sebelum corak boleh beroperasi? Ini adalah kategori yang paling kerap terlepas. Pasukan mengandaikan data wujud kerana ia telah dikumpulkan. Tetapi kewujudan tidak sama dengan kebolehaksesan, struktur, atau kualiti. 7 jenis data yang menggerakkan AI perniagaan merangkumi keseluruhan landskap di sini.
Kebergantungan infrastruktur: Sistem, pipeline, API, dan sumber pengiraan apa yang mesti ada untuk corak menelan, memproses, menyimpan, dan menghantar output? Pasukan kejuruteraan sering menentukan skopnya, tetapi pemilik perniagaan dan program kerap meremehkannya. Pipeline pembenaman untuk RAG, webhook CRM untuk Scoring and Routing, dan pipeline pemprosesan audio untuk Meeting Intelligence masing-masing adalah pelaburan kejuruteraan yang tidak remeh.
Kebergantungan corak: Beberapa corak memerlukan corak lain beroperasi terlebih dahulu, kerana corak hilir menggunakan data yang dihasilkan oleh corak hulu. Meeting Intelligence menghasilkan data panggilan berstruktur yang digunakan oleh Workflow Copilot untuk cadangan tindakan CRM seterusnya. Jika Meeting Intelligence tidak berjalan, Workflow Copilot tidak mempunyai apa-apa untuk dicadangkan.
Fakta Utama: Kegagalan Prasyarat AI
- 85% projek AI yang gagal menyebut kualiti data yang lemah sebagai punca utama, menurut analisis RAND Corporation terhadap lebih daripada 2,400 inisiatif AI syarikat besar.
- Penyelidikan Gartner 2025 meramalkan 60% projek AI yang kekurangan data sedia AI akan ditinggalkan sebelum selesai.
- Hanya 12% organisasi mempunyai data berkualiti mencukupi untuk menyokong aplikasi AI tanpa fasa pra-kerja yang ketara. (MIT Project NANDA, 2025)
Peta kebergantungan mengikut corak
| Corak | Kebergantungan data | Kebergantungan infrastruktur | Kebergantungan corak biasa |
|---|---|---|---|
| RAG Assistant | Pangkalan pengetahuan yang dijaga (dasar, SOP, dokumen produk, tiket yang diselesaikan); terpotong dan terbenam dalam pangkalan data vektor | Pangkalan data vektor; pipeline pembenaman; pipeline pengambilan dan penyegaran dokumen | Tiada (sering berjalan dahulu) |
| Scoring + Routing | Rekod sejarah dengan hasil berlabel (tutup-menang/tutup-kalah, diselesaikan/dieskalasi, diambil/ditolak); medan ciri berstruktur setiap rekod | CRM atau sistem tiket dengan sokongan webhook; infrastruktur latihan dan latihan semula model; enjin peraturan penghalaan | Tiada (boleh menjadi corak pertama yang digunakan) |
| Vision Extract | Imej latihan atau contoh imbasan beranotasi untuk jenis dokumen sasaran; akses kepada dokumen sumber dalam bentuk digital atau fizikal | Pipeline pengambilan imej; API OCR atau model penglihatan; sistem rekod sasaran dengan akses tulis | Tiada (sering berjalan secara bebas) |
| Meeting Intelligence | Rakaman audio atau video dengan kualiti mencukupi; metadata mesyuarat (peserta, tarikh, konteks) | Sistem storan audio/video; API teks-ke-pertuturan; storan output berstruktur yang disambungkan ke sistem hilir | Tiada (sering berjalan dahulu dalam tindanan jualan/sokongan) |
| Anomaly Agent | Minimum 60-90 hari data garis dasar untuk metrik yang dipantau; kadar pengumpulan data yang konsisten | Aliran data masa nyata atau hampir masa nyata; pipeline amaran dan pemberitahuan; penghalaan eskalasi | Sering bergantung pada Scoring + Routing untuk pengumpulan data garis dasar |
| Generative Research | Sumber yang boleh diakses (web, korpus dalaman, suapan berita); kejelasan pelesenan kandungan untuk pengedaran semula dalaman | Akses web atau API carian korpus dalaman; sistem petikan sumber | Tiada, tetapi kualiti output bertambah baik dengan RAG Assistant untuk sumber dalaman |
| Document Review | Dokumen sampel yang mewakili kes biasa; standard atau templat untuk dibandingkan | Penghurai dokumen; model perbandingan; format output berstruktur yang serasi dengan sistem hilir | Tiada |
| Workflow Copilot | Data konteks pengguna secara masa nyata (rekod semasa, aktiviti terkini); sistem rekod pengguna | Integrasi mendalam dengan alat kerja utama pengguna (CRM, IDE, platform pemasaran); endpoint inferens kependaman rendah | Sering bergantung pada Meeting Intelligence atau Scoring + Routing untuk konteks yang kaya |
| Personalization Engine | Data tingkah laku pengguna (minimum 5-10 interaksi setiap pengguna untuk personalisasi yang berguna); katalog produk atau perpustakaan kandungan | Penangkapan peristiwa masa nyata; storan profil; sistem penghantaran kandungan yang menyokong pemaparan dinamik | Tiada secara bebas; lebih baik dengan Anomaly Agent untuk integrasi isyarat churn |
| Autonomous Agent | Semua alat yang diperlukan ejen mesti boleh diakses melalui API yang telah diuji; keupayaan rollback atau batal untuk setiap jenis tindakan tidak boleh balik | Daftar alat dengan skema yang telah diuji; penguatkuasaan bilangan langkah maksimum; sistem log audit; laluan eskalasi | Bergantung pada matlamat tertentu; biasanya bergantung pada Scoring + Routing untuk triase dan pada RAG untuk akses pengetahuan |
"Program syarikat besar yang memperuntukkan 50-70% daripada garis masa projek AI mereka untuk kesediaan data, termasuk pengekstrakan, penormalan, metadata tadbir urus, dan pemeriksaan kualiti, mencapai kadar penggunaan produksi 3x lebih tinggi daripada program yang memulakan kerja model sebelum asas data disahkan." (Laporan Transformasi Data Integrate.io, 2026)
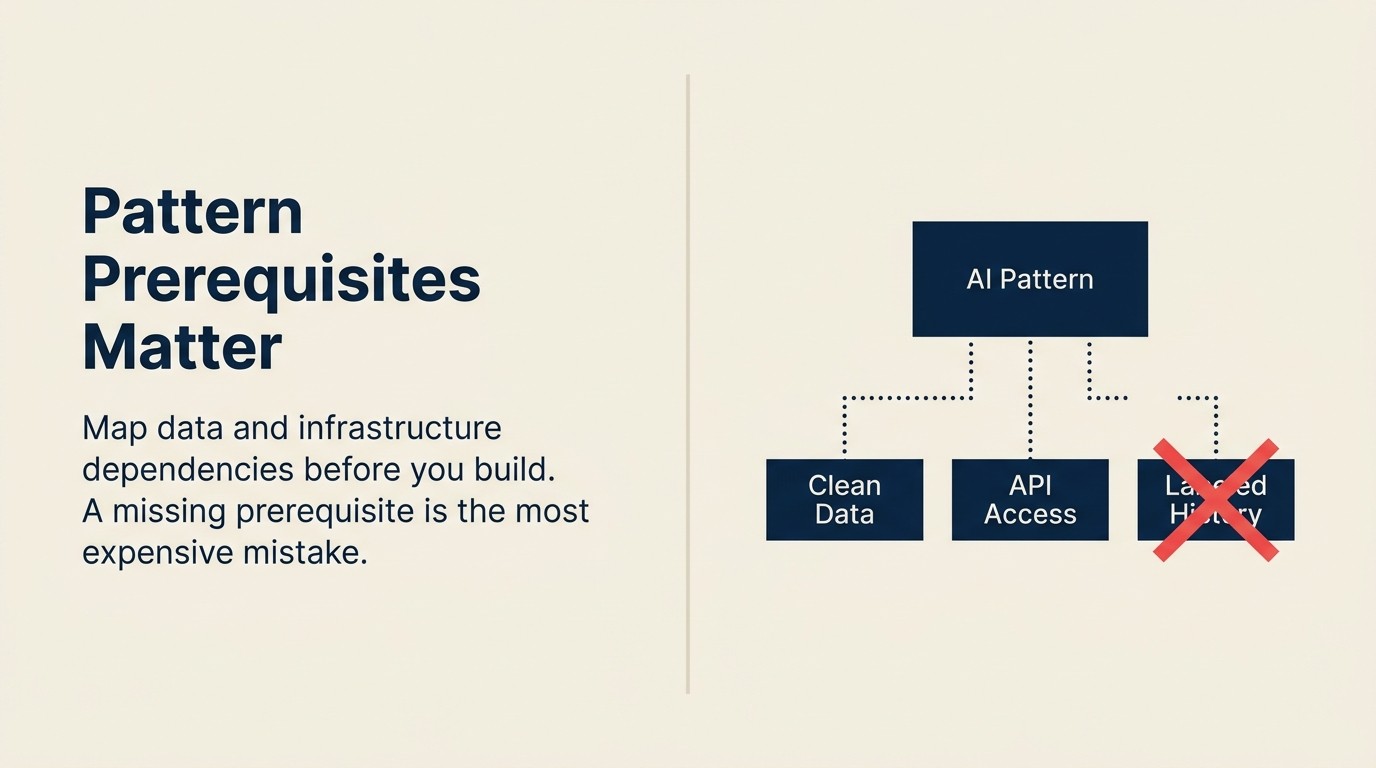
Peta Kebergantungan Corak
Peta Kebergantungan Corak adalah struktur audit prasyarat yang mengkategorikan setiap corak AI merentasi tiga paksi sebelum pelaksanaan bermula: Kebergantungan Data (data berstruktur apa yang mesti wujud dan boleh diakses), Kebergantungan Infrastruktur (pipeline, API, dan pengiraan apa yang mesti ada), dan Kebergantungan Corak (corak hulu mana yang mesti menghasilkan data sebelum corak ini boleh diuji dengan bermakna). Menjalankan peta sebelum sebarang keputusan membina menghapuskan kelewatan tiga hingga enam bulan yang merosakkan muhibah perintis apabila prasyarat yang tiada muncul semasa integrasi.
Analisis Rework: Berdasarkan penemuan McKinsey bahawa lapan daripada sepuluh syarikat menyebut had data sebagai halangan utama pengembangan AI, dan data sokongan dari RAND Corporation (85% projek AI yang gagal menyebut kualiti data sebagai punca utama), Peta Kebergantungan Corak mewakili pra-pelaburan pulangan tertinggi tunggal dalam mana-mana projek AI. Pengalaman pelaksanaan Rework menunjukkan pasukan yang menyelesaikan audit prasyarat formal sebelum memulakan kerja pembinaan memendekkan masa-ke-produksi mereka purata 11 minggu berbanding pasukan yang menemui kebergantungan semasa pengujian integrasi.
Laluan kritikal: urutan penggunaan AI Sales Operator
Sebuah syarikat ingin menggunakan AI Sales Operator yang menggabungkan Meeting Intelligence, Scoring and Routing, RAG Assistant, dan Workflow Copilot. Berikut adalah urutan yang didorong kebergantungan:
Fasa 1 (selari, minggu 1-4)
Jalankan ini secara selari kerana tiada yang bergantung kepada yang lain:
Persediaan Scoring and Routing: Eksport rekod CRM sejarah dengan label hasil (tutup-menang/tutup-kalah, layak/tidak layak). Minimum 6 bulan data berlabel, idealnya 12. Latih model scoring awal. Konfigurasikan enjin peraturan penghalaan. Uji pada set holdout sebelum digunakan secara langsung.
Persediaan Meeting Intelligence: Sahkan akses storan audio dan keserasian format. Sediakan pipeline teks-ke-pertuturan. Tentukan skema output berstruktur: medan mana (item tindakan, bantahan, isyarat peringkat, sentimen) mengalir ke sistem hilir yang mana. Uji dengan 20 rakaman panggilan sebelum produksi.
Fasa 2 (berurutan, minggu 5-8)
Ini bergantung kepada output fasa 1:
Persediaan RAG Assistant: Memerlukan pangkalan pengetahuan yang dijaga. Audit dokumentasi sedia ada. Kenal pasti yang terkini berbanding yang lapuk. Tugaskan pemilikan untuk setiap kategori dokumen. Bina pipeline pembenaman. Potong dan benamkan pangkalan pengetahuan. Sediakan kadar penyegaran (mingguan untuk dokumen yang berubah cepat, bulanan untuk dasar yang stabil).
Integrasi Workflow Copilot: Memerlukan Meeting Intelligence menghasilkan output berstruktur (supaya ia mempunyai konteks panggilan untuk ditindaki) dan memerlukan Scoring and Routing berjalan (supaya isyarat keutamaan menyuap copilot). Konfigurasi Copilot boleh bermula di fasa 1 sebagai tugasan pembinaan, tetapi tidak boleh diuji dengan bermakna sehingga corak hulu menghasilkan data.
Fasa 3 (minggu 9-12)
Pengujian tindanan penuh. Jalankan kesemua empat corak bersama-sama dengan kumpulan perintis 10-15 wakil jualan. Ukur secara berasingan: adakah Meeting Intelligence menghasilkan ringkasan yang tepat? Adakah Scoring and Routing menghalakan dengan betul? Adakah RAG Assistant memaparkan dokumen yang relevan? Adakah Workflow Copilot diterima atau diabaikan oleh wakil jualan? Betulkan pada peringkat corak sebelum melaraskan tindanan.
Pengurutan ini bukan pilihan. Pasukan yang cuba membina keempat-empat corak secara serentak mendapati semasa pengujian integrasi bahawa corak hulu tidak bersedia, dan corak hilir perlu dirombak semula.
"Model Scoring yang digunakan tanpa data sejarah berlabel hasil menghasilkan skor yang tidak berkorelasi dengan keputusan sebenar. Lead berskor tinggi gagal ditutup pada kadar yang dijangka. Scoring kelihatan aktif tetapi adalah hingar. Punca utamanya adalah data ciri dan data hasil yang wujud dalam sistem berasingan dan tidak pernah digabungkan sebelum model dilatih." (Analisis Corak Enterprise AI Folio3, 2026)
Kegagalan prasyarat biasa mengikut corak
RAG Assistant digunakan tanpa pangkalan pengetahuan yang dijaga. Gejala: penolong memberikan jawapan yang yakin yang lapuk 18 bulan. Pengguna mempercayai jawapan, bertindak atasnya, mendapati ia salah. Punca utamanya adalah pangkalan pengetahuan yang dibina sekali dan tidak pernah disegarkan. Tiga bulan kemudian, dokumentasi produk telah berubah, dasar telah dikemaskini, dan RAG Assistant memetik kandungan yang telah digantikan. Penyelesaian: pemilikan pangkalan pengetahuan mesti ditetapkan sebelum RAG Assistant digunakan. Setiap kategori dokumen mempunyai pemilik yang dinamakan yang bertanggungjawab untuk kemaskini. Kadar penyegaran pembenaman dikuatkuasakan oleh tugas berjadual, bukan oleh campur tangan manual.
Scoring and Routing digunakan tanpa data hasil sejarah berlabel. Gejala: model scoring menghasilkan skor yang tidak berkorelasi dengan hasil sebenar. Lead berskor tinggi tidak ditutup. Lead berskor rendah ditukar. Scoring kelihatan aktif tetapi pada dasarnya adalah hingar. Punca utamanya sama ada tiada data hasil sejarah, atau data hasil yang wujud dalam satu sistem dan data ciri yang wujud dalam sistem lain, tidak pernah digabungkan. Penyelesaian: sebelum melatih mana-mana model scoring, sahkan bahawa set rekod sejarah mempunyai label hasil yang konsisten dan bahawa medan ciri yang digunakan untuk scoring disi dalam lebih daripada 80% rekod.
Anomaly Agent digunakan tanpa tempoh garis dasar. Gejala: ejen membunyikan amaran untuk semua atau tiada apa-apa. Model tidak mempunyai garis dasar untuk dibandingkan, jadi ia sama ada memperlakukan semua variasi sebagai anomali atau mempelajari garis dasar dari data yang terlalu sedikit yang tidak mewakili taburan sebenar. Penyelesaian: kumpulkan 60 hingga 90 hari data garis dasar sebelum mengaktifkan pengesanan anomali. Jalankan model dalam mod bayangan semasa pengumpulan garis dasar: log apa yang ia akan tandakan, bandingkan dengan keputusan sebenar, kalibrasi ambang sebelum digunakan secara langsung.
Autonomous Agent digunakan tanpa API alat yang diuji. Gejala: ejen berjalan, memanggil alat, menerima format respons yang tidak dijangka, dan sama ada menggelung tanpa henti atau mengambil tindakan yang tidak disengajakan berdasarkan penghuraian yang salah. Punca utamanya adalah skema alat yang digambarkan tetapi tidak diuji pada peringkat API. Penyelesaian: uji setiap alat yang boleh diakses ejen secara berasingan sebelum menggunakan ejen. Sahkan format respons sepadan dengan jangkaan ejen. Bina cawangan ralat untuk setiap mod kegagalan alat sebelum perlarian produksi pertama.
Senarai semak audit kesediaan data
Jalankan ini sebelum meluluskan sebarang pelaksanaan corak:
Ketersediaan data
- Data yang diperlukan wujud dan boleh diakses oleh sistem yang anda bina
- Kebenaran akses disahkan (bukan diandaikan dari carta org)
- Jumlah data mencukupi (kiraan rekod minimum untuk latihan, pembenaman, atau garis dasar)
Kualiti data
- Label hasil wujud dan tepat untuk corak yang memerlukannya (Scoring, Anomaly)
- Medan utama mempunyai kadar pengisian lebih daripada 80% (tidak kebanyakannya kosong atau null)
- Tiada berat sebelah sistematik dalam set latihan yang akan mengelincirkan output model
Rangka Kerja Pengurusan Risiko AI NIST mengenal pasti ketepatan data, kelengkapan, konsistensi, kesahihan, keunikan, dan ketepatan masa sebagai enam dimensi utama yang menentukan sama ada sistem AI menghasilkan output yang boleh dipercayai. Setiap item dalam senarai semak ini dipetakan kepada satu atau lebih dimensi tersebut.
Kesegaran data
- Data cukup terkini untuk relevan (data lapuk lebih buruk daripada tiada data untuk beberapa corak)
- Kadar penyegaran ditakrifkan dan dimiliki, bukan diandaikan
- Data lama melebihi ufuk yang berguna dikecualikan atau diberi pemberat yang lebih rendah
Kesediaan infrastruktur
- Pipeline pengambilan dibina dan diuji
- Storan dan pengiraan diperuntukkan
- Endpoint API disahkan boleh diakses dengan kebenaran yang betul
- Keperluan kependaman dipenuhi oleh konfigurasi infrastruktur
Tadbir urus
- Penggunaan data dilindungi oleh terma perkhidmatan atau persetujuan pengguna
- Pengendalian PII ditakrifkan dan mematuhi peraturan yang terpakai
- Jejak audit ada untuk mana-mana output laluan Laksana
Jika mana-mana kotak semak tidak ditanda, corak tidak bersedia untuk digunakan. Item yang tiada adalah prasyarat, bukan pilihan tambahan.
Prasyarat infrastruktur yang terlepas oleh pasukan
Pipeline pembenaman untuk RAG. Ini bukan "muat naik dokumen anda ke alat." Ini adalah pipeline berjadual yang: membaca dokumen baharu atau yang dikemaskini, memotongnya mengikut bahagian, menjana pembenaman menggunakan versi model yang sama seperti endpoint pengambilan, menulis ke pangkalan data vektor, dan mengendalikan dokumen yang dipadam atau digantikan dengan mengalih keluar pembenaman mereka. Pipeline ini adalah pelaburan kejuruteraan. Menentukan skopnya sebagai "vendor menguruskannya" biasanya bermakna ia sebenarnya tidak berjalan, itulah sebabnya pangkalan pengetahuan menjadi lapuk.
Webhook CRM untuk Scoring and Routing. Model scoring perlu berjalan setiap kali rekod yang relevan berubah. Itu memerlukan webhook CRM yang dikonfigurasi untuk menyala pada peristiwa yang betul (lead dicipta, peringkat urusan niaga dikemaskini, maklumat kenalan berubah). Banyak pelaksanaan CRM mempunyai webhook tersedia tetapi tidak dikonfigurasi. Ini adalah tugasan kejuruteraan tiga hari yang menyekat keseluruhan corak Scoring jika terlepas.
Pipeline pemprosesan audio untuk Meeting Intelligence. Rakaman perlu: ditangkap dengan kualiti mencukupi (minimum 16 kHz mono), disimpan dengan boleh diakses, dikaitkan dengan metadata peserta dan urusan niaga yang betul, dan diproses dalam tempoh masa yang munasabah selepas mesyuarat berakhir. Jika rakaman disimpan dalam sistem vendor yang tidak mempunyai API eksport, atau jika kualiti terlalu rendah untuk transkripsi yang tepat, corak tidak boleh berjalan. Ini adalah kekangan infrastruktur fizikal yang tidak dapat diselesaikan oleh sebarang kualiti model.
| Jenis kegagalan prasyarat | Corak yang paling terjejas | Masa penemuan biasa | Kelewatan purata yang disebabkan |
|---|---|---|---|
| Tiada data hasil berlabel | Scoring + Routing, Anomaly Agent | Minggu 3-4 pengujian | 8-12 minggu |
| Pangkalan pengetahuan tidak pernah disegarkan | RAG Assistant | Minggu 3 perintis (apabila pengguna menjumpai jawapan salah) | 4-6 minggu |
| Audio disimpan tanpa API eksport | Meeting Intelligence | Audit vendor pra-pembinaan (jika dilakukan) atau minggu 1 integrasi | 6-10 minggu |
| API alat tidak diuji | Autonomous Agent | Perlarian produksi pertama | 2-4 minggu ditambah pemulihan insiden |
| Webhook CRM tidak dikonfigurasi | Scoring + Routing, Workflow Copilot | Pengujian integrasi, minggu 2 | 1-3 minggu |
Pengurutan untuk pasukan dengan sumber terhad
Apabila anda tidak dapat membina semua corak serentak, urutkan untuk nilai awal maksimum dan hutang prasyarat minimum:
Mulakan dengan corak tanpa kebergantungan yang mempunyai nilai bebas. RAG Assistant (jika anda mempunyai pangkalan pengetahuan) dan Scoring and Routing (jika anda mempunyai data sejarah berlabel) kedua-duanya boleh digunakan secara bebas dan memberikan nilai segera. Mereka juga tidak menghasilkan output yang bergantung kepada corak lain, jadi memulakan mereka tidak mewujudkan hutang teknikal untuk pelaksanaan hilir. Untuk cara mengaturkan pilihan ini merentasi rancangan berbilang tahun, lihat mengaturkan corak AI dalam Roadmap.
Kumpulkan data yang anda perlukan kemudian, mulai sekarang. Jika anda merancang untuk menambah Meeting Intelligence dalam enam bulan, mulakan menyimpan rakaman panggilan dalam format yang betul hari ini. Jika anda merancang untuk menambah Anomaly Agent, mulakan mengumpulkan metrik yang konsisten dari tarikh garis dasar yang ditakrifkan. Kos pengumpulan data adalah rendah. Penemuan bahawa anda memerlukan 90 hari data dan hanya mempunyai 12 adalah tinggi.
Gunakan Workflow Copilot selepas kebergantungan hulunya berjalan. Copilot yang dibina sebelum Meeting Intelligence dan Scoring and Routing menghasilkan cadangan generik berbanding yang kaya konteks. Tunggu sehingga corak hulu menghasilkan data sebelum melabur dalam lapisan copilot.
Mengemaskini prasyarat dari semasa ke semasa
Corak yang berfungsi pada tahun 1 mungkin merosot pada tahun 2 jika prasyarat mereka tidak dijaga:
- Pangkalan pengetahuan menjadi lapuk apabila produk dan dasar berubah
- Model Scoring menyimpang apabila komposisi pasaran berubah (lebih ramai pelanggan besar berbanding ketika model dilatih, kadar penutupan berbeza, kitaran jualan berbeza)
- Garis dasar pengesanan anomali yang dibina dalam satu suku mungkin salah untuk corak bermusim yang berbeza
Penyelidikan McKinsey tentang memetakan laluan ke perusahaan berasaskan data dan AI mengesyorkan membina satu asas data untuk analitik dan AI, digunakan di mana-mana berbanding pipeline berasingan setiap sistem. Pendekatan itu adalah setara infrastruktur dengan mentakrifkan kalendar penyelenggaraan prasyarat anda sebelum anda memerlukannya.
Bina kalendar penyelenggaraan untuk prasyarat setiap corak:
- Pangkalan pengetahuan RAG: semak dan kemaskini setiap suku tahun sekurang-kurangnya; perubahan produk utama mencetuskan penyegaran segera
- Model Scoring: latih semula setiap 6 bulan terhadap data hasil yang segar; pantau metrik hanyutan model setiap bulan
- Garis dasar Anomaly: kalibrasi semula setiap kali ada perubahan perniagaan yang ketara (lini produk baharu, pasaran baharu, perubahan pasukan utama)
Audit prasyarat semasa penggunaan bukan peristiwa sekali sahaja. Ia adalah titik permulaan untuk irama penyelenggaraan yang berterusan.
Soalan Lazim
Apakah prasyarat pelaksanaan AI yang paling kerap terlepas?
Ketersediaan data diandaikan, tetapi kebolehaksesan dan kualiti data tidak disahkan. Rekod yang wujud dalam CRM tidak sama dengan rekod yang label hasilnya tepat, medan cirinya disi, dan formatnya serasi dengan model yang perlu menggunakannya. RAND Corporation mendapati 85% projek AI yang gagal menyebut kualiti data sebagai punca utama.
Berapa lama audit prasyarat biasanya mengambil masa?
Audit prasyarat menyeluruh merentasi ketiga-tiga kategori kebergantungan (data, infrastruktur, kebergantungan corak) mengambil masa 2-3 minggu untuk satu corak dan 4-6 minggu untuk tindanan berbilang corak. Pelaburan itu menghapuskan kelewatan 8-12 minggu yang berlaku apabila prasyarat yang tiada muncul semasa pengujian integrasi. Program yang menang memperuntukkan 50-70% daripada garis masa projek AI mereka untuk kerja kesediaan data.
Adakah semua corak AI mempunyai prasyarat yang sama?
Tidak. RAG Assistant, Document Review, dan Vision Extract tidak mempunyai kebergantungan corak hulu dan boleh digunakan dahulu. Meeting Intelligence, Scoring and Routing, dan Generative Research juga tidak mempunyai kebergantungan corak tetapi mempunyai keperluan data yang khusus. Workflow Copilot dan Anomaly Agent kerap bergantung kepada corak hulu untuk menghasilkan output yang kaya konteks. Autonomous Agent mempunyai prasyarat infrastruktur yang paling ketat, memerlukan setiap API alat diuji sebelum penggunaan.
Apa yang berlaku jika anda menggunakan model Scoring tanpa data sejarah berlabel?
Model scoring menghasilkan skor yang tidak berkorelasi dengan hasil sebenar. Lead berskor tinggi gagal ditutup pada kadar yang diramalkan. Lead berskor rendah ditukar pada kadar yang diberikan kebarangkalian rendah oleh model. Model kelihatan aktif tetapi berfungsi sebagai hingar. Penyelesaian: sebelum melatih, sahkan bahawa set rekod sejarah mempunyai label hasil yang konsisten dan bahawa medan ciri disi dalam lebih daripada 80% rekod.
Seberapa kerap prasyarat corak AI perlu diaudit semula selepas penggunaan awal?
Pangkalan pengetahuan RAG harus disemak setiap suku tahun sekurang-kurangnya, dengan penyegaran segera dicetuskan oleh perubahan produk atau dasar utama. Model Scoring harus dilatih semula setiap enam bulan terhadap data hasil yang segar, dengan pemantauan hanyutan bulanan. Garis dasar pengesanan anomali memerlukan kalibrasi semula setiap kali perubahan perniagaan yang ketara berlaku (lini produk baharu, pasaran baharu, penstrukturan semula pasukan utama). Prasyarat bukan pemeriksaan sekali sahaja.
Apakah Peta Kebergantungan Corak?
Peta Kebergantungan Corak adalah struktur audit prasyarat yang mengkategorikan setiap corak AI merentasi tiga paksi sebelum pelaksanaan: kebergantungan data, kebergantungan infrastruktur, dan kebergantungan corak (corak hulu yang mesti berjalan dahulu). Menjalankan peta sebelum keputusan pembinaan menghapuskan kelewatan tiga hingga enam bulan yang berlaku apabila prasyarat yang tiada muncul semasa integrasi.
Ketahui lebih lanjut

Co-Founder, Rework.com
On this page
- Jenis kebergantungan
- Peta kebergantungan mengikut corak
- Peta Kebergantungan Corak
- Laluan kritikal: urutan penggunaan AI Sales Operator
- Kegagalan prasyarat biasa mengikut corak
- Senarai semak audit kesediaan data
- Prasyarat infrastruktur yang terlepas oleh pasukan
- Pengurutan untuk pasukan dengan sumber terhad
- Mengemaskini prasyarat dari semasa ke semasa
- Ketahui lebih lanjut