パターンの依存関係と前提条件
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
デプロイ後にAIパターンが失敗する最も一般的な理由は、誰も監査しなかった前提条件の欠如です。
間違ったモデルでも、間違ったベンダーでも、間違ったパターンでもありません。誰も確認しなかったデータの依存関係です。想定されていたが確認されていなかったAPIアクセス。ドキュメントのフォルダとしては存在しているが、埋め込みパイプラインも更新サイクルも所有者も存在しないナレッジベース。
パターンが構築され、統合が完了します。そしてテストの3週目に、誰かがスコアリングモデル用の過去のアウトカムデータがどこにあるか尋ね、それが構造化された形式で収集されていなかったことに気づきます。あるいは、Meeting Intelligence用の音声録音は存在するが、エクスポートAPIのないベンダーシステムに保存されているとします。あるいは、RAG(Retrieval-Augmented Generation)アシスタントが参照するはずだったナレッジベースが18ヶ月古く、2つの製品ラインについて完全に間違った情報が含まれているとします。
こうした発見はAIプロジェクトを終わらせません。ただし、3〜6ヶ月の遅延を引き起こし、パイロット期間で積み上げるべきだった信頼を消耗させます。McKinseyのエージェンティックAIとデータ変革に関する調査では、企業の10社中8社がモデルの品質やベンダーの選定ではなく、データの制約をAIのスケールにおける主要なボトルネックとして挙げています。
本記事ではパターン別に依存関係をマッピングし、実際のデプロイメントシーケンスを解説し、実装をGOサインする前に実行すべき前提条件の監査チェックリストを提供します。AIプロジェクト開始前のデータ準備の全体像については、データ準備: ほとんどのAIプロジェクトが省略する前提条件から始めてください。
依存関係の種類
依存関係は3つのカテゴリに分類されます。
データ依存関係: パターンが機能する前に、どのデータが存在し、正しく構造化され、アクセス可能でなければならないか。これは最もよく見落とされるカテゴリです。チームはデータが収集されているという理由で存在すると思い込みます。しかし存在とアクセス可能性、構造、品質は同じではありません。ビジネスAIを支える7種類のデータでは、この全体像を説明しています。
インフラ依存関係: パターンがアウトプットを取り込み、処理し、保存し、提供するために、どのシステム、パイプライン、API、コンピュートリソースを用意する必要があるか。エンジニアリングチームはこれらをスコープすることが多いですが、ビジネスおよびプログラムオーナーはしばしば過小評価します。RAGの埋め込みパイプライン、Scoring and RoutingのCRM Webhook、Meeting Intelligenceの音声処理パイプラインは、それぞれ無視できないエンジニアリング投資です。
パターン依存関係: 下流パターンが上流パターンが生成するデータを消費するため、一部のパターンには別のパターンが先に稼働していることが必要です。Meeting Intelligenceは、Workflow CopilotがCRMの次のアクション提案に使用する構造化された通話データを生成します。Meeting Intelligenceが稼働していなければ、Workflow Copilotには提案する材料がありません。
Key Facts: AIの前提条件の失敗
- RAND Corporationによる2,400以上のエンタープライズAIイニシアチブの分析によると、失敗したAIプロジェクトの85%がデータ品質の低さを根本原因として挙げています。
- Gartnerの2025年の調査では、AIに対応したデータが不足しているAIプロジェクトの60%が完了前に中止されると予測しています。
- AIアプリケーションを重要な事前作業なしにサポートするのに十分な品質のデータを持つ組織はわずか12%です。(MIT Project NANDA, 2025)
パターン別の依存関係マップ
| パターン | データ依存関係 | インフラ依存関係 | 一般的なパターン依存関係 |
|---|---|---|---|
| RAG Assistant | 維持されたナレッジベース(ポリシー、SOP、製品ドキュメント、解決済みチケット)。ベクターデータベースにチャンク化・埋め込み済み | ベクターデータベース、埋め込みパイプライン、ドキュメントの取り込みと更新パイプライン | なし(最初に稼働することが多い) |
| Scoring + Routing | ラベル付きアウトカムを持つ過去のレコード(クローズド勝/負、解決/エスカレーション、採用/不採用)。レコードごとの構造化されたフィーチャーフィールド | Webhookをサポートするシステム(CRMまたはチケットシステム)、モデルのトレーニングと再トレーニングインフラ、ルーティングルールエンジン | なし(最初にデプロイするパターンにもなれる) |
| Vision Extract | 対象ドキュメントタイプのトレーニング画像またはアノテーション付きスキャンサンプル。デジタルまたは物理形式のソースドキュメントへのアクセス | 画像取り込みパイプライン、OCRまたはビジョンモデルAPI、書き込みアクセスを持つターゲットの記録システム | なし(スタンドアローンで稼働することが多い) |
| Meeting Intelligence | 十分な品質の音声または動画録音。ミーティングのメタデータ(参加者、日時、コンテキスト) | 音声/動画ストレージシステム、音声テキスト変換API、下流システムに接続された構造化アウトプットストア | なし(営業/サポートスタックで最初に稼働することが多い) |
| Anomaly Agent | 監視する指標の最低60〜90日間のベースラインデータ。一貫したデータ収集サイクル | リアルタイムまたはほぼリアルタイムのデータストリーム、アラートと通知パイプライン、エスカレーションルーティング | ベースラインデータ収集のためにScoring + Routingに依存することが多い |
| Generative Research | アクセス可能なソース(ウェブ、内部コーパス、ニュースフィード)。内部再配布のためのコンテンツライセンスの明確化 | ウェブアクセスまたは内部コーパス検索API、ソース引用システム | なし。ただし内部ソースにRAG Assistantを使用するとアウトプット品質が向上する |
| Document Review | 典型的なケースを代表するサンプルドキュメント。比較対象となる標準またはテンプレート | ドキュメントパーサー、比較モデル、下流システムと互換性のある構造化アウトプット形式 | なし |
| Workflow Copilot | リアルタイムのユーザーコンテキストデータ(現在のレコード、最近のアクティビティ)。ユーザーの記録システム | ユーザーの主要な作業ツール(CRM、IDE、マーケティングプラットフォーム)との深い統合、低遅延の推論エンドポイント | 豊富なコンテキストのためにMeeting IntelligenceまたはScoring + Routingに依存することが多い |
| Personalization Engine | ユーザー行動データ(有用なパーソナライゼーションのためにユーザーあたり最低5〜10回のインタラクション)。製品カタログまたはコンテンツライブラリ | リアルタイムイベントキャプチャ、プロフィールストア、動的レンダリングをサポートするコンテンツ配信システム | スタンドアローンではなし。Anomaly AgentによるChurnシグナル統合でより効果的に機能する |
| Autonomous Agent | Agentが使用する必要があるすべてのツールは、テスト済みAPIを通じてアクセス可能であること。すべての不可逆的なアクションタイプのロールバックまたは元に戻す機能 | テスト済みスキーマを持つツールレジストリ、最大ステップ数の制限、監査ログシステム、エスカレーションパス | 特定の目標に依存。トリアージのためにScoring + Routingに、ナレッジアクセスのためにRAGに依存することが多い |
「抽出、正規化、ガバナンスメタデータ、品質チェックを含むデータ準備にAIプロジェクトのタイムラインの50〜70%を割り当てるエンタープライズプログラムは、データ基盤が確認される前にモデル作業を開始するプログラムの3倍の本番デプロイ率を達成しています。」(Integrate.io Data Transformation Report, 2026)
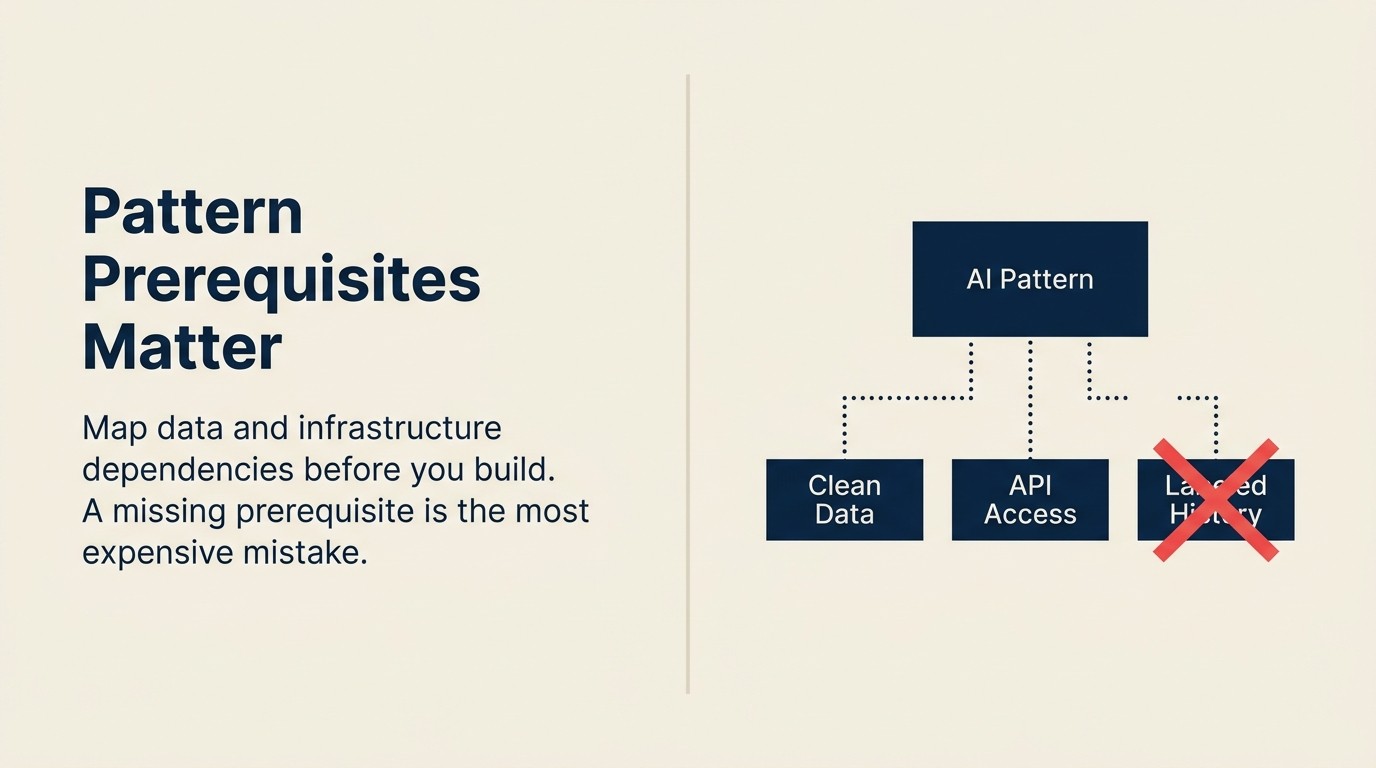
パターン依存関係マップ
パターン依存関係マップは、実装前にすべてのAIパターンを3つの軸で分類する前提条件の監査構造です。データ依存関係(どの構造化データが存在し、アクセス可能でなければならないか)、インフラ依存関係(どのパイプライン、API、コンピュートが用意されていなければならないか)、そしてパターン依存関係(このパターンを意義ある形でテストできるようになる前に、どの上流パターンがデータを生成していなければならないか)の3つです。ビルド判断の前にこのマップを実行することで、前提条件の欠如が統合の途中で表面化するときに生じるパイロットへの信頼を損なう3〜6ヶ月の遅延を排除できます。
Rework分析: McKinseyの調査(10社中8社がデータの制約をAIスケールの主要なボトルネックとして挙げている)とRAND Corporationの補完データ(失敗したAIプロジェクトの85%がデータ品質を根本原因として挙げている)に基づくと、パターン依存関係マップはあらゆるAIプロジェクトにおいて最も高いリターンをもたらす事前投資を代表しています。Reworkの実装経験では、構築作業を開始する前に正式な前提条件の監査を完了するチームは、統合テスト中に依存関係を発見するチームと比較して、平均11週間短縮して本番稼働に至っています。
クリティカルパス: AI Sales Operatorのデプロイメントシーケンス
ある企業がMeeting Intelligence、Scoring and Routing、RAG Assistant、Workflow Copilotを組み合わせたAI Sales Operatorをデプロイしたいと考えています。以下が依存関係に基づく順序です。
フェーズ1(並行作業、1〜4週目)
どちらも互いに依存していないため、並行して実行します。
Scoring and Routingのセットアップ: アウトカムラベル(クローズド勝/クローズド負、適格/不適格)を持つ過去のCRMレコードをエクスポートします。ラベル付きデータは最低6ヶ月、理想的には12ヶ月必要です。初期スコアリングモデルをトレーニングし、ルーティングルールエンジンを設定します。本稼働前にホールドアウトセットでテストします。
Meeting Intelligenceのセットアップ: 音声ストレージへのアクセスと形式の互換性を確認します。音声テキスト変換パイプラインを立ち上げます。構造化アウトプットスキーマを定義します。どのフィールド(アクションアイテム、反論、ステージシグナル、センチメント)がどの下流システムに流れるかを定めます。本番前に録音済みの20件の通話でテストします。
フェーズ2(順次作業、5〜8週目)
これらはフェーズ1のアウトプットに依存します。
RAG Assistantのセットアップ: 維持されたナレッジベースが必要です。既存のドキュメントを監査します。現在のものと古いものを特定します。各ドキュメントカテゴリの所有者を割り当てます。埋め込みパイプラインを構築し、ナレッジベースをチャンク化・埋め込みします。更新サイクルを設定します(変化の早いドキュメントは週次、安定したポリシーは月次)。
Workflow Copilotの統合: Workflow Copilotには、Meeting Intelligenceが構造化アウトプットを生成していること(処理できる通話コンテキストがあること)と、Scoring and Routingが稼働していること(優先度シグナルがCopilotに供給されること)が必要です。Copilotの設定はフェーズ1でビルドタスクとして開始できますが、上流パターンがデータを生成するまでは意義ある形でテストできません。
フェーズ3(9〜12週目)
フルスタックのテスト。10〜15人の担当者のパイロットグループで4つのパターンすべてを一緒に実行します。別々に測定します。Meeting Intelligenceは正確なサマリーを生成しているか。Scoring and Routingは正しくルーティングしているか。RAG Assistantは関連するドキュメントを表示しているか。Workflow Copilotは担当者に受け入れられているか、無視されているか。スタックを調整する前に、パターンレベルで修正します。
このシーケンスは任意ではありません。4つのパターンを同時に構築しようとするチームは、統合テスト中に上流パターンの準備ができていなかったことを発見し、下流パターンの手直しが必要になります。
「アウトカムラベル付きの過去のデータなしにデプロイされたスコアリングモデルは、実際の結果と相関しないスコアを生成します。高スコアのLeadは予測どおりにクローズしません。スコアリングはアクティブに見えますが、ノイズにすぎません。根本原因は、別々のシステムに存在し、モデルのトレーニング前に結合されたことがなかったフィーチャーデータとアウトカムデータです。」(Folio3 AI Enterprise Pattern Analysis, 2026)
パターン別の一般的な前提条件の失敗
維持されたナレッジベースなしにデプロイされたRAG Assistant。 症状: アシスタントが18ヶ月前の古い情報に基づいた自信に満ちた回答を返します。ユーザーはその回答を信頼し、それに基づいて行動し、間違いに気づきます。根本原因は、一度構築されただけで更新されなかったナレッジベースです。3ヶ月後、製品ドキュメントは変更され、ポリシーは更新されており、RAG Assistantは古くなったコンテンツを引用しています。修正方法: RAG Assistantをデプロイする前にナレッジベースの所有者を割り当てなければなりません。各ドキュメントカテゴリには、更新の責任を持つ指名されたオーナーが必要です。埋め込みの更新サイクルは手動の介入ではなく、スケジュールされたジョブによって実施されます。
ラベル付きの過去のアウトカムデータなしにデプロイされたScoring and Routing。 症状: スコアリングモデルが実際のアウトカムと相関しないスコアを出力します。高スコアのLeadがクローズしません。低スコアのLeadがコンバートします。スコアリングはアクティブに見えますが、本質的にノイズです。根本原因は、過去のアウトカムデータがないか、一方のシステムにアウトカムデータが存在し、別のシステムにフィーチャーデータが存在しており、結合されたことがないケースです。修正方法: スコアリングモデルをトレーニングする前に、過去のレコードセットに一貫したアウトカムラベルがあり、スコアリングに使用されるフィーチャーフィールドがレコードの80%以上に入力されていることを検証します。
ベースライン期間なしにデプロイされたAnomaly Agent。 症状: Agentがすべてに対してアラートを発するか、何に対しても発しません。モデルには比較するためのベースラインがなく、すべての変動を異常として扱うか、実際の分布を代表しないデータが少なすぎる状態からベースラインを学習します。修正方法: 異常検知をアクティブ化する前に60〜90日間のベースラインデータを収集します。ベースライン収集中にシャドウモードでモデルを実行します。フラグを立てたであろうものをログに記録し、実際のアウトカムと比較し、本番稼働前にしきい値を調整します。
テスト済みのツールAPIなしにデプロイされたAutonomous Agent。 症状: Agentが実行されてツールを呼び出し、予期しないレスポンス形式を受け取り、無限ループに陥るか、誤ったパースに基づいて意図しないアクションを取ります。根本原因は、APIレベルでテストされていない記述されただけのツールスキーマです。修正方法: Agentをデプロイする前に、Agentがアクセスできるすべてのツールを個別にテストします。レスポンス形式がAgentの期待値と一致することを確認します。最初の本番実行の前に各ツールの失敗モードのエラー分岐を構築します。
データ準備の監査チェックリスト
パターン実装をGOサインする前に実行してください。
データの可用性
- 必要なデータが存在し、構築しているシステムからアクセス可能
- アクセス権限が確認済み(組織図から推定ではなく)
- データ量が十分(トレーニング、埋め込み、ベースラインに必要な最小レコード数)
データ品質
- アウトカムラベルが必要なパターン(Scoring、Anomaly)に存在し、正確
- 主要フィールドが80%以上入力済み(ほぼ空またはnullでない)
- モデルのアウトプットを歪めるような系統的バイアスがトレーニングセットにない
NIST AI Risk Management Frameworkは、データの正確性、完全性、一貫性、妥当性、独自性、適時性の6つの主要次元をAIシステムが信頼できるアウトプットを生成するかどうかを決定するものとして特定しています。このチェックリストの各項目はこれらの次元の1つ以上にマッピングされます。
データの鮮度
- データが関連性を持つのに十分な最新性(一部のパターンでは古いデータはデータがないよりも悪い)
- 更新サイクルが定義され、所有者が決まっており、前提としていない
- 有用な期間を超えた古いデータは除外または低重み付け済み
インフラの準備
- 取り込みパイプラインが構築・テスト済み
- ストレージとコンピュートがプロビジョニング済み
- APIエンドポイントが正しい権限でアクセス可能であることが確認済み
- 遅延要件がインフラ構成によって満たされている
ガバナンス
- データ使用がサービス利用規約またはユーザーの同意でカバーされている
- 個人情報の取り扱いが定義され、適用される規制に準拠している
- Executeパスのアウトプットに対して監査証跡が用意されている
チェックボックスのいずれかが未チェックの場合、そのパターンはデプロイ準備ができていません。欠けている項目は「あると望ましいもの」ではなく前提条件です。
チームが見落とすインフラの前提条件
RAGの埋め込みパイプライン。 これは「ツールにドキュメントをアップロードする」ことではありません。以下を実行するスケジュールされたパイプラインです。新規または更新されたドキュメントを読み取り、セクションでチャンク化し、取得エンドポイントと同じモデルバージョンを使用して埋め込みを生成し、ベクターデータベースに書き込み、削除または置き換えられたドキュメントの埋め込みを削除します。このパイプラインはエンジニアリング投資です。「ベンダーが対応する」とスコープすると、通常は実際には稼働しておらず、それがナレッジベースが古くなる理由です。
Scoring and RoutingのCRM Webhook。 スコアリングモデルは関連するレコードが変更されるたびに実行される必要があります。これには、正しいイベント(Leadの作成、ディールステージの更新、コンタクト情報の変更)で発火するよう設定されたCRM Webhookが必要です。多くのCRM実装ではWebhookが利用可能ですが、設定されていません。これは、見落とした場合にScoring パターン全体をブロックする3日間のエンジニアリングタスクです。
Meeting Intelligenceの音声処理パイプライン。 録音は以下の条件を満たす必要があります。十分な品質で収集されていること(最低16 kHzモノラル)、アクセス可能な状態で保存されていること、正しい参加者とディールのメタデータに関連付けられていること、そしてミーティング終了後の合理的な時間内に処理されること。録音がエクスポートAPIのないベンダーシステムに保存されている場合、または正確な文字起こしには品質が低すぎる場合、パターンは稼働できません。これは、どれだけモデルの品質が高くても解決できない物理的なインフラの制約です。
| 前提条件の失敗タイプ | 最も影響を受けるパターン | 一般的な発見タイミング | 平均的な遅延 |
|---|---|---|---|
| ラベル付きアウトカムデータなし | Scoring + Routing、Anomaly Agent | テストの3〜4週目 | 8〜12週間 |
| ナレッジベースが更新されていない | RAG Assistant | パイロットの3週目(ユーザーが誤った回答を発見したとき) | 4〜6週間 |
| エクスポートAPIなしで音声が保存されている | Meeting Intelligence | 事前ビルドのベンダー監査(実施した場合)または統合の1週目 | 6〜10週間 |
| ツールAPIが未テスト | Autonomous Agent | 最初の本番実行 | 2〜4週間 + インシデント対応 |
| CRM Webhookが設定されていない | Scoring + Routing、Workflow Copilot | 統合テスト、2週目 | 1〜3週間 |
リソースが限られたチームのためのシーケンシング
すべてのパターンを同時に構築できない場合は、初期価値の最大化と前提条件の負債の最小化を目標にシーケンスを組みます。
スタンドアローンで価値を持つ依存関係のないパターンから始める。 RAG Assistant(ナレッジベースがある場合)とScoring and Routing(ラベル付きの過去のデータがある場合)は両方とも独立してデプロイし、即座に価値を提供できます。また、他のパターンが依存するアウトプットを生成しないため、それらを開始しても下流実装の技術的負債が生まれません。複数年計画でこれらの選択をシーケンスする方法については、ロードマップにおけるAIパターンのシーケンシングをご覧ください。
後で必要になるデータを今すぐ収集し始める。 6ヶ月後にMeeting Intelligenceを追加する予定なら、今日から正しい形式で通話録音を保存し始めましょう。Anomaly Agentを追加する予定なら、定義されたベースライン日から一貫した指標の収集を始めましょう。データ収集のコストは低いですが、90日分のデータが必要なのに12日分しかないという発見のコストは高くなります。
上流の依存関係が稼働してからWorkflow Copilotをデプロイする。 Meeting IntelligenceとScoring and Routingより前に構築されたCopilotは、コンテキストの豊富な提案ではなく汎用的な提案を生成します。Copilotレイヤーへの投資は、上流パターンがデータを生成するまで待ってください。
時間の経過に伴う前提条件の更新
1年目に機能するパターンが、前提条件が維持されない場合、2年目に劣化する可能性があります。
- 製品やポリシーが変化するにつれて、ナレッジベースは古くなります
- 市場の構成が変化するにつれて(モデルがトレーニングされた時よりもエンタープライズ顧客が増え、クローズ率や営業サイクルが異なる)、スコアリングモデルはドリフトします
- ある四半期に構築された異常検知のベースラインは、異なる季節パターンには間違っている可能性があります
McKinseyの調査では、分析とAIのためのデータ基盤を統一し、システムごとに別々のパイプラインを持つのではなくどこでも使えるように構築することを推奨しています。そのアプローチは、必要になる前に前提条件の保守カレンダーを定義するというインフラ上の同等物です。
各パターンの前提条件の保守カレンダーを構築します。
- RAGナレッジベース: 最低四半期に1回レビューと更新。主要な製品変更は即時の更新をトリガーします
- スコアリングモデル: 新鮮なアウトカムデータに対して6ヶ月ごとに再トレーニング。月次でモデルドリフト指標を監視します
- 異常検知ベースライン: 重大なビジネス変更(新製品ライン、新市場、大規模なチーム変更)があるたびに再調整します
デプロイ時の前提条件の監査は一回限りのイベントではありません。継続的な保守リズムの出発点です。
よくある質問
AI実装で最もよく見落とされる前提条件は何ですか?
データの可用性は仮定されますが、データのアクセス可能性と品質は確認されません。CRMに存在するレコードは、アウトカムラベルが正確で、フィーチャーフィールドが入力されており、消費するモデルと互換性のある形式を持つレコードとは同じではありません。RAND Corporationは、失敗したAIプロジェクトの85%がデータ品質を根本原因として挙げていると発見しました。
前提条件の監査には通常どのくらいの時間がかかりますか?
3つの依存関係カテゴリ(データ、インフラ、パターン依存関係)をすべてカバーする徹底的な前提条件の監査は、単一パターンで2〜3週間、マルチパターンスタックで4〜6週間かかります。この投資は、前提条件の欠如が統合テスト中に表面化する際に発生する8〜12週間の遅延を排除します。成功するプログラムはAIプロジェクトのタイムラインの50〜70%をデータ準備作業に割り当てます。
すべてのAIパターンは同じ前提条件を持ちますか?
いいえ。RAG Assistant、Document Review、Vision Extractは上流パターンへの依存関係がなく、最初にデプロイできます。Meeting Intelligence、Scoring and Routing、Generative Researchもパターン依存関係がありませんが、特定のデータ要件があります。Workflow CopilotとAnomaly Agentは、コンテキスト豊富なアウトプットを生成するために上流パターンに依存することが多いです。Autonomous Agentはインフラの前提条件が最も厳しく、デプロイ前にすべてのツールAPIのテストが必要です。
ラベル付きの過去のデータなしにスコアリングモデルをデプロイするとどうなりますか?
スコアリングモデルは実際のアウトカムと相関しないスコアを生成します。高スコアのLeadは予測レートでクローズしません。低スコアのLeadはモデルが低確率を割り当てたレートでコンバートします。モデルはアクティブに見えますが、ノイズとして機能します。修正方法: トレーニング前に、過去のレコードセットに一貫したアウトカムラベルがあり、フィーチャーフィールドがレコードの80%以上に入力されていることを検証します。
初期デプロイ後、AIパターンの前提条件をどのくらいの頻度で再監査すべきですか?
RAGナレッジベースは最低四半期に1回レビューし、製品やポリシーの大きな変更があれば即時に更新します。スコアリングモデルは新鮮なアウトカムデータに対して6ヶ月ごとに再トレーニングし、ドリフト指標を月次で監視します。異常検知のベースラインは重大なビジネス変更(新製品ライン、新市場、大規模なチーム再編)があるたびに再調整が必要です。前提条件は一回限りの確認ではありません。
パターン依存関係マップとは何ですか?
パターン依存関係マップは、実装前にすべてのAIパターンを3つの軸で分類する前提条件の監査構造です。データ依存関係、インフラ依存関係、そしてパターン依存関係(最初に稼働していなければならない上流パターン)の3つです。ビルド判断の前にこのマップを実行することで、前提条件の欠如が統合の途中で表面化するときに発生する3〜6ヶ月の遅延を排除できます。
関連記事
