Ketergantungan dan Prasyarat Pola AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Alasan paling umum pola AI gagal setelah deployment adalah prasyarat yang hilang dan tidak pernah diaudit.
Bukan model yang salah. Bukan vendor yang salah. Bukan pola yang salah. Melainkan ketergantungan data yang tidak pernah diperiksa siapa pun. Akses API yang diasumsikan tetapi tidak dikonfirmasi. Basis pengetahuan yang ada sebagai folder dokumen tetapi tidak memiliki embedding pipeline, tidak ada jadwal pembaruan, dan tidak ada pemilik yang bertanggung jawab.
Pola sudah dibangun. Integrasi sudah selesai. Kemudian, pada minggu ketiga pengujian, seseorang bertanya di mana data hasil historis untuk model Scoring berada dan menemukan bahwa data tersebut tidak pernah dikumpulkan dalam format terstruktur. Atau rekaman audio untuk Meeting Intelligence ada tetapi tersimpan di sistem vendor yang tidak memiliki export API. Atau basis pengetahuan yang seharusnya menjadi sumber jawaban RAG (Retrieval-Augmented Generation) Assistant sudah 18 bulan usang dan sama sekali salah tentang dua lini produk.
Temuan-temuan ini tidak membunuh proyek AI. Mereka menunda proyek selama tiga hingga enam bulan dan menghabiskan goodwill yang seharusnya dibangun selama periode pilot. Riset McKinsey tentang scaling agentic AI with data transformations menemukan bahwa delapan dari sepuluh perusahaan menyebut keterbatasan data sebagai hambatan utama dalam menskalakan AI, bukan kualitas model atau pemilihan vendor.
Artikel ini memetakan ketergantungan berdasarkan pola, memandu melalui urutan deployment nyata, dan memberikan daftar periksa audit prasyarat yang harus dijalankan sebelum implementasi apa pun disetujui. Untuk gambaran kesiapan data yang lebih luas sebelum proyek AI apa pun dimulai, data readiness: the prerequisite most AI projects skip adalah tempat untuk memulai.
Jenis-jenis ketergantungan
Tiga kategori mencakup seluruh lanskap ketergantungan:
Ketergantungan data: Data apa yang harus ada, terstruktur dengan benar, dan dapat diakses sebelum pola dapat beroperasi? Ini adalah kategori yang paling sering terlewatkan. Tim mengasumsikan data ada karena sudah dikumpulkan. Namun keberadaan tidak sama dengan aksesibilitas, struktur, atau kualitas. 7 types of data that power business AI memetakan seluruh lanskap ini.
Ketergantungan infrastruktur: Sistem, pipeline, API, dan sumber daya komputasi apa yang harus tersedia agar pola dapat menyerap, memproses, menyimpan, dan mengirimkan output? Tim engineering sering memperhitungkannya, tetapi pemilik bisnis dan program sering meremehkannya. Embedding pipeline untuk RAG, webhook CRM untuk Scoring and Routing, dan pipeline pemrosesan audio untuk Meeting Intelligence masing-masing merupakan investasi engineering yang tidak sepele.
Ketergantungan pola: Beberapa pola memerlukan pola lain untuk beroperasi terlebih dahulu, karena pola hilir mengonsumsi data yang diproduksi pola hulu. Meeting Intelligence menghasilkan data panggilan terstruktur yang digunakan Workflow Copilot untuk saran next action di CRM. Jika Meeting Intelligence tidak berjalan, Workflow Copilot tidak memiliki bahan untuk menyarankan apa pun.
Key Facts: Kegagalan Prasyarat AI
- 85% proyek AI yang gagal menyebut kualitas data yang buruk sebagai akar penyebabnya, menurut analisis RAND Corporation atas lebih dari 2.400 inisiatif AI enterprise.
- Riset Gartner 2025 memprediksi 60% proyek AI yang kekurangan data siap AI akan ditinggalkan sebelum selesai.
- Hanya 12% organisasi yang memiliki data berkualitas cukup untuk mendukung aplikasi AI tanpa fase pra-kerja yang signifikan. (MIT Project NANDA, 2025)
Peta ketergantungan berdasarkan pola
| Pola | Ketergantungan data | Ketergantungan infrastruktur | Ketergantungan pola yang umum |
|---|---|---|---|
| RAG Assistant | Basis pengetahuan yang terpelihara (kebijakan, SOP, dokumentasi produk, tiket yang terselesaikan); dipartisi dan diembedding dalam vector database | Vector database; embedding pipeline; pipeline ingesti dan pembaruan dokumen | Tidak ada (sering berjalan pertama) |
| Scoring + Routing | Catatan historis dengan label hasil (closed-won/lost, diselesaikan/dieskalasi, dipekerjakan/ditolak); field fitur terstruktur per catatan | CRM atau sistem tiket dengan dukungan webhook; infrastruktur pelatihan dan pelatihan ulang model; mesin aturan perutean | Tidak ada (dapat menjadi pola pertama yang diterapkan) |
| Vision Extract | Gambar pelatihan atau contoh pemindaian beranotasi untuk jenis dokumen target; akses ke dokumen sumber dalam bentuk digital atau fisik | Pipeline ingesti gambar; API OCR atau vision model; sistem pencatatan target dengan akses tulis | Tidak ada (sering berjalan mandiri) |
| Meeting Intelligence | Rekaman audio atau video dengan kualitas yang memadai; metadata rapat (peserta, tanggal, konteks) | Sistem penyimpanan audio/video; API speech-to-text; penyimpanan output terstruktur yang terhubung ke sistem hilir | Tidak ada (sering berjalan pertama dalam stack sales/support) |
| Anomaly Agent | Minimal 60-90 hari data baseline untuk metrik yang dipantau; cadence pengumpulan data yang konsisten | Aliran data real-time atau mendekati real-time; pipeline alert dan notifikasi; perutean eskalasi | Sering bergantung pada Scoring + Routing untuk pengumpulan data baseline |
| Generative Research | Sumber yang dapat diakses (web, korpus internal, feed berita); kejelasan lisensi konten untuk redistribusi internal | Akses web atau API pencarian korpus internal; sistem kutipan sumber | Tidak ada, tetapi kualitas output meningkat dengan RAG Assistant untuk sumber internal |
| Document Review | Contoh dokumen yang mewakili kasus tipikal; standar atau template untuk dibandingkan | Parser dokumen; model perbandingan; format output terstruktur yang kompatibel dengan sistem hilir | Tidak ada |
| Workflow Copilot | Data konteks pengguna secara real-time (catatan saat ini, aktivitas terkini); sistem pencatatan pengguna | Integrasi mendalam dengan alat kerja utama pengguna (CRM, IDE, platform marketing); endpoint inferensi berlatensi rendah | Sering bergantung pada Meeting Intelligence atau Scoring + Routing untuk konteks yang kaya |
| Personalization Engine | Data perilaku pengguna (minimal 5-10 interaksi per pengguna untuk personalisasi yang berguna); katalog produk atau perpustakaan konten | Penangkapan event real-time; penyimpanan profil; sistem pengiriman konten yang mendukung rendering dinamis | Tidak ada secara mandiri; bekerja lebih baik dengan Anomaly Agent untuk integrasi sinyal churn |
| Autonomous Agent | Semua alat yang perlu digunakan agent harus dapat diakses melalui API yang telah diuji; kemampuan rollback atau undo untuk setiap jenis tindakan yang tidak dapat dibatalkan | Registri alat dengan skema yang telah diuji; penegakan jumlah langkah maksimum; sistem log audit; jalur eskalasi | Bergantung pada tujuan spesifik; umumnya bergantung pada Scoring + Routing untuk triase dan pada RAG untuk akses pengetahuan |
"Program enterprise yang mengalokasikan 50-70% dari timeline proyek AI mereka untuk kesiapan data, termasuk ekstraksi, normalisasi, metadata governance, dan pemeriksaan kualitas, mencapai tingkat deployment produksi 3x lebih tinggi dari program yang memulai pekerjaan model sebelum fondasi data dikonfirmasi." (Integrate.io Data Transformation Report, 2026)
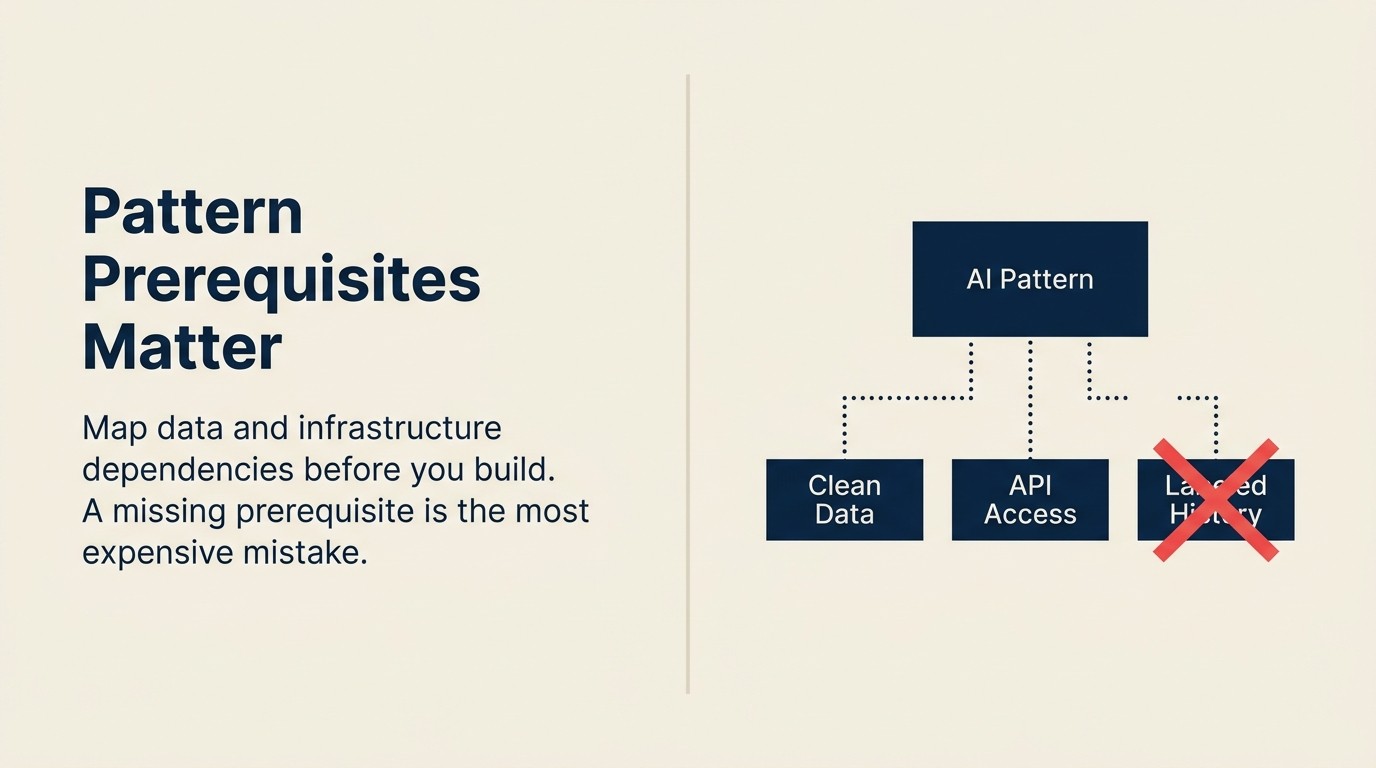
Pattern Dependency Map
Pattern Dependency Map adalah struktur audit prasyarat yang mengategorikan setiap pola AI berdasarkan tiga sumbu sebelum implementasi dimulai: Data Dependencies (data terstruktur apa yang harus ada dan dapat diakses), Infrastructure Dependencies (pipeline, API, dan komputasi apa yang harus tersedia), dan Pattern Dependencies (pola hulu mana yang harus menghasilkan data sebelum pola ini dapat diuji secara bermakna). Menjalankan peta ini sebelum keputusan build apa pun mengeliminasi penundaan tiga hingga enam bulan yang membunuh goodwill pilot ketika prasyarat yang hilang terungkap di tengah integrasi.
Rework Analysis: Berdasarkan temuan McKinsey bahwa delapan dari sepuluh perusahaan menyebut keterbatasan data sebagai hambatan utama dalam skalabilitas AI, dan data korroboratif dari RAND Corporation (85% proyek AI yang gagal menyebut kualitas data sebagai akar penyebab), Pattern Dependency Map mewakili pra-investasi dengan imbal hasil tertinggi dalam proyek AI apa pun. Pengalaman implementasi Rework menunjukkan bahwa tim yang menyelesaikan audit prasyarat formal sebelum memulai pekerjaan build mempersingkat waktu-ke-produksi mereka rata-rata 11 minggu dibandingkan tim yang menemukan ketergantungan selama pengujian integrasi.
Jalur kritis: urutan deployment AI Sales Operator
Sebuah perusahaan ingin menerapkan AI Sales Operator yang menggabungkan Meeting Intelligence, Scoring and Routing, RAG Assistant, dan Workflow Copilot. Berikut urutan yang didorong oleh ketergantungan:
Fase 1 (paralel, minggu 1-4)
Jalankan ini secara paralel karena keduanya tidak saling bergantung:
Setup Scoring and Routing: Ekspor catatan CRM historis dengan label hasil (closed-won/closed-lost, qualified/disqualified). Minimal 6 bulan data berlabel, idealnya 12 bulan. Latih model scoring awal. Konfigurasikan mesin aturan perutean. Uji pada holdout set sebelum ditayangkan.
Setup Meeting Intelligence: Konfirmasi akses penyimpanan audio dan kompatibilitas format. Bangun pipeline speech-to-text. Definisikan skema output terstruktur: field mana (tindak lanjut, keberatan, sinyal tahap, sentimen) mengalir ke sistem hilir mana. Uji dengan 20 rekaman panggilan sebelum produksi.
Fase 2 (berurutan, minggu 5-8)
Ini bergantung pada output fase 1:
Setup RAG Assistant: Memerlukan basis pengetahuan yang terpelihara. Audit dokumentasi yang ada. Identifikasi mana yang terkini vs. usang. Tetapkan kepemilikan untuk setiap kategori dokumen. Bangun embedding pipeline. Partisi dan embedding basis pengetahuan. Siapkan cadence pembaruan (mingguan untuk dokumen yang sering berubah, bulanan untuk kebijakan yang stabil).
Integrasi Workflow Copilot: Memerlukan Meeting Intelligence yang menghasilkan output terstruktur (agar memiliki konteks panggilan untuk ditindaklanjuti) dan memerlukan Scoring and Routing yang berjalan (agar sinyal prioritas memberi makan copilot). Konfigurasi Copilot dapat dimulai di fase 1 sebagai tugas build, tetapi tidak dapat diuji secara bermakna hingga pola hulu menghasilkan data.
Fase 3 (minggu 9-12)
Pengujian stack penuh. Jalankan keempat pola bersama-sama dengan kelompok pilot 10-15 sales rep. Ukur secara terpisah: apakah Meeting Intelligence menghasilkan ringkasan yang akurat? Apakah Scoring and Routing merutekan dengan benar? Apakah RAG Assistant menampilkan dokumen yang relevan? Apakah Workflow Copilot diterima atau diabaikan oleh sales rep? Perbaiki di level pola sebelum menyesuaikan stack.
Pengurutan ini tidak opsional. Tim yang mencoba membangun keempat pola secara bersamaan menemukan selama pengujian integrasi bahwa pola hulu belum siap, dan pola hilir perlu dikerjakan ulang.
"Model scoring yang diterapkan tanpa data historis berlabel hasil menghasilkan skor yang tidak berkorelasi dengan hasil aktual. Lead berperingkat tinggi gagal untuk close pada tingkat yang diharapkan. Skoringnya terlihat aktif tetapi hanya noise. Akar penyebabnya adalah data fitur dan data hasil yang ada di sistem terpisah dan tidak pernah digabungkan sebelum model dilatih." (Folio3 AI Enterprise Pattern Analysis, 2026)
Kegagalan prasyarat yang umum berdasarkan pola
RAG Assistant diterapkan tanpa basis pengetahuan yang terpelihara. Gejala: asisten memberikan jawaban yang percaya diri tetapi sudah 18 bulan usang. Pengguna mempercayai jawabannya, bertindak berdasarkannya, lalu menemukan itu salah. Akar penyebabnya adalah basis pengetahuan yang dibangun sekali dan tidak pernah diperbarui. Tiga bulan kemudian, dokumentasi produk telah berubah, kebijakan telah diperbarui, dan RAG Assistant mengutip konten yang sudah tidak berlaku. Solusi: kepemilikan basis pengetahuan harus ditetapkan sebelum RAG Assistant diterapkan. Setiap kategori dokumen memiliki pemilik yang bertanggung jawab atas pembaruan. Cadence pembaruan embedding ditegakkan oleh pekerjaan terjadwal, bukan intervensi manual.
Scoring and Routing diterapkan tanpa data hasil historis berlabel. Gejala: model scoring menghasilkan skor yang tidak berkorelasi dengan hasil aktual. Lead berperingkat tinggi tidak close. Lead berperingkat rendah berkonversi. Skoringnya terlihat aktif tetapi pada dasarnya hanya noise. Akar penyebabnya adalah tidak ada data hasil historis, atau data hasil yang ada di satu sistem sementara data fitur ada di sistem lain, tidak pernah digabungkan. Solusi: sebelum melatih model scoring apa pun, validasi bahwa kumpulan catatan historis memiliki label hasil yang konsisten dan bahwa field fitur yang digunakan untuk scoring terisi lebih dari 80% catatan.
Anomaly Agent diterapkan tanpa periode baseline. Gejala: agent menembakkan alert untuk segalanya atau sama sekali tidak ada. Model tidak memiliki baseline untuk dibandingkan, sehingga ia memperlakukan semua variasi sebagai anomali atau mempelajari baseline dari terlalu sedikit data yang tidak mewakili distribusi nyata. Solusi: kumpulkan 60 hingga 90 hari data baseline sebelum mengaktifkan deteksi anomali. Jalankan model dalam shadow mode selama pengumpulan baseline: catat apa yang akan ditandainya, bandingkan dengan hasil aktual, kalibrasi threshold sebelum ditayangkan.
Autonomous Agent diterapkan tanpa API alat yang telah diuji. Gejala: agent berjalan, memanggil alat, menerima format respons yang tidak terduga, dan baik berputar tanpa henti atau mengambil tindakan yang tidak dimaksudkan berdasarkan parsing yang salah. Akar penyebabnya adalah skema alat yang dideskripsikan tetapi tidak diuji di level API. Solusi: uji setiap alat yang dapat diakses agent secara terisolasi sebelum menerapkan agent. Verifikasi format respons sesuai dengan ekspektasi agent. Bangun cabang error untuk setiap mode kegagalan alat sebelum produksi pertama.
Daftar periksa audit kesiapan data
Jalankan ini sebelum menyetujui implementasi pola apa pun:
Ketersediaan data
- Data yang diperlukan ada dan dapat diakses oleh sistem yang sedang dibangun
- Izin akses dikonfirmasi (tidak diasumsikan dari bagan organisasi)
- Volume data mencukupi (jumlah catatan minimum untuk pelatihan, embedding, atau baseline)
Kualitas data
- Label hasil ada dan akurat untuk pola yang membutuhkannya (Scoring, Anomaly)
- Field kunci memiliki tingkat pengisian lebih dari 80% (tidak sebagian besar kosong atau null)
- Tidak ada bias sistematis dalam set pelatihan yang akan mengbiaskan output model
NIST AI Risk Management Framework mengidentifikasi akurasi, kelengkapan, konsistensi, validitas, keunikan, dan ketepatan waktu data sebagai enam dimensi utama yang menentukan apakah sistem AI menghasilkan output yang dapat dipercaya. Setiap item dalam daftar periksa ini dipetakan ke satu atau lebih dimensi tersebut.
Kesegaran data
- Data cukup terkini untuk relevan (data usang lebih buruk dari tidak ada data untuk beberapa pola)
- Cadence pembaruan terdefinisi dan dimiliki, tidak diasumsikan
- Data lama yang melewati cakrawala yang berguna dikecualikan atau diberi bobot lebih rendah
Kesiapan infrastruktur
- Pipeline ingesti dibangun dan diuji
- Penyimpanan dan komputasi telah disediakan
- Endpoint API dikonfirmasi dapat diakses dengan izin yang benar
- Persyaratan latensi terpenuhi oleh konfigurasi infrastruktur
Governance
- Penggunaan data tercakup oleh ketentuan layanan atau persetujuan pengguna
- Penanganan PII terdefinisi dan sesuai dengan regulasi yang berlaku
- Jejak audit tersedia untuk setiap output jalur Execute
Jika ada item yang belum dicentang, pola tersebut belum siap untuk diterapkan. Item yang hilang adalah prasyarat, bukan sesuatu yang bagus untuk dimiliki.
Prasyarat infrastruktur yang sering terlewatkan tim
Embedding pipeline untuk RAG. Ini bukan "unggah dokumen Anda ke alat." Ini adalah pipeline terjadwal yang: membaca dokumen baru atau yang diperbarui, mempartisinya berdasarkan bagian, menghasilkan embedding menggunakan versi model yang sama dengan endpoint pengambilan, menulis ke vector database, dan menangani dokumen yang dihapus atau digantikan dengan menghapus embeddingnya. Pipeline ini adalah investasi engineering. Menganggapnya sebagai "vendor yang menanganinya" biasanya berarti pipeline tersebut sebenarnya tidak berjalan, itulah mengapa basis pengetahuan menjadi usang.
Webhook CRM untuk Scoring and Routing. Model scoring perlu berjalan setiap kali catatan yang relevan berubah. Ini memerlukan webhook CRM yang dikonfigurasi untuk aktif pada event yang tepat (lead dibuat, tahap deal diperbarui, informasi kontak berubah). Banyak implementasi CRM memiliki webhook yang tersedia tetapi tidak dikonfigurasi. Ini adalah tugas engineering tiga hari yang memblokir seluruh pola Scoring jika terlewatkan.
Pipeline pemrosesan audio untuk Meeting Intelligence. Rekaman perlu: diambil dengan kualitas yang memadai (minimal 16 kHz mono), disimpan secara dapat diakses, dikaitkan dengan peserta yang benar dan metadata deal, dan diproses dalam jendela waktu yang wajar setelah rapat berakhir. Jika rekaman tersimpan di sistem vendor yang tidak memiliki export API, atau jika kualitasnya terlalu rendah untuk transkripsi yang akurat, pola tidak dapat berjalan. Ini adalah batasan infrastruktur fisik yang tidak dapat diatasi oleh kualitas model sebaik apa pun.
| Jenis kegagalan prasyarat | Pola yang paling terpengaruh | Waktu penemuan tipikal | Rata-rata penundaan yang disebabkan |
|---|---|---|---|
| Tidak ada data hasil berlabel | Scoring + Routing, Anomaly Agent | Minggu 3-4 pengujian | 8-12 minggu |
| Basis pengetahuan tidak pernah diperbarui | RAG Assistant | Minggu 3 pilot (saat pengguna menemukan jawaban yang salah) | 4-6 minggu |
| Audio disimpan tanpa export API | Meeting Intelligence | Audit vendor pra-build (jika dilakukan) atau minggu 1 integrasi | 6-10 minggu |
| API alat tidak diuji | Autonomous Agent | Produksi pertama kali berjalan | 2-4 minggu plus pemulihan insiden |
| Webhook CRM tidak dikonfigurasi | Scoring + Routing, Workflow Copilot | Pengujian integrasi, minggu 2 | 1-3 minggu |
Pengurutan untuk tim dengan sumber daya terbatas
Ketika Anda tidak dapat membangun semua pola secara bersamaan, urutkan untuk nilai awal yang maksimal dan hutang prasyarat yang minimal:
Mulailah dengan pola tanpa ketergantungan yang memiliki nilai mandiri. RAG Assistant (jika Anda memiliki basis pengetahuan) dan Scoring and Routing (jika Anda memiliki data historis berlabel) keduanya dapat diterapkan secara independen dan memberikan nilai segera. Mereka juga tidak menghasilkan output yang bergantung pada pola lain, sehingga memulai mereka tidak menciptakan hutang teknis untuk implementasi hilir. Untuk cara mengurutkan pilihan ini dalam rencana multi-tahun, lihat sequencing AI patterns in a roadmap.
Kumpulkan data yang Anda butuhkan nanti, mulai sekarang. Jika Anda berencana menambahkan Meeting Intelligence dalam enam bulan, mulailah menyimpan rekaman panggilan dalam format yang tepat sekarang. Jika Anda berencana menambahkan Anomaly Agent, mulailah mengumpulkan metrik yang konsisten dari tanggal baseline yang terdefinisi. Biaya pengumpulan data rendah. Menemukan bahwa Anda membutuhkan 90 hari data tetapi hanya memiliki 12 sangatlah mahal.
Terapkan Workflow Copilot setelah ketergantungan hulunya berjalan. Copilot yang dibangun sebelum Meeting Intelligence dan Scoring and Routing menghasilkan saran generik, bukan saran yang kaya konteks. Tunggu hingga pola hulu menghasilkan data sebelum berinvestasi di lapisan copilot.
Memperbarui prasyarat dari waktu ke waktu
Pola yang bekerja di tahun pertama mungkin mengalami degradasi di tahun kedua jika prasyaratnya tidak dirawat:
- Basis pengetahuan menjadi usang seiring produk dan kebijakan berubah
- Model scoring mengalami drift seiring komposisi pasar berubah (lebih banyak pelanggan enterprise daripada saat model dilatih, close rate yang berbeda, siklus sales yang berbeda)
- Baseline deteksi anomali yang dibangun dalam satu kuartal mungkin salah untuk pola musiman yang berbeda
Riset McKinsey tentang charting a path to the data- and AI-driven enterprise merekomendasikan membangun satu fondasi data untuk analitik dan AI, digunakan di mana-mana daripada pipeline terpisah per sistem. Pendekatan tersebut adalah padanan infrastruktur dari mendefinisikan kalender pemeliharaan prasyarat Anda sebelum Anda membutuhkannya.
Bangun kalender pemeliharaan untuk prasyarat setiap pola:
- Basis pengetahuan RAG: tinjau dan perbarui minimal setiap kuartal; perubahan produk atau kebijakan besar memicu pembaruan segera
- Model Scoring: latih ulang setiap 6 bulan terhadap data hasil yang segar; pantau metrik drift model setiap bulan
- Baseline Anomaly: kalibrasi ulang setiap kali ada perubahan bisnis yang signifikan (lini produk baru, pasar baru, perubahan tim besar)
Audit prasyarat saat deployment bukan merupakan peristiwa satu kali. Ini adalah titik awal untuk ritme pemeliharaan yang berkelanjutan.
Pertanyaan yang Sering Diajukan
Apa prasyarat implementasi AI yang paling sering terlewatkan?
Ketersediaan data diasumsikan, tetapi aksesibilitas dan kualitas data tidak dikonfirmasi. Catatan yang ada di CRM tidak sama dengan catatan yang label hasilnya akurat, field fiturnya terisi, dan formatnya kompatibel dengan model yang perlu mengonsumsinya. RAND Corporation menemukan 85% proyek AI yang gagal menyebut kualitas data sebagai akar penyebab.
Berapa lama audit prasyarat biasanya memerlukan waktu?
Audit prasyarat menyeluruh di tiga kategori ketergantungan (data, infrastruktur, ketergantungan pola) membutuhkan 2-3 minggu untuk satu pola dan 4-6 minggu untuk stack multi-pola. Investasi tersebut mengeliminasi penundaan 8-12 minggu yang terjadi ketika prasyarat yang hilang muncul selama pengujian integrasi. Program-program yang berhasil mengalokasikan 50-70% dari timeline proyek AI mereka untuk pekerjaan kesiapan data.
Apakah semua pola AI memiliki prasyarat yang sama?
Tidak. RAG Assistant, Document Review, dan Vision Extract tidak memiliki ketergantungan pola hulu dan dapat diterapkan pertama kali. Meeting Intelligence, Scoring and Routing, dan Generative Research juga tidak memiliki ketergantungan pola tetapi memiliki persyaratan data spesifik. Workflow Copilot dan Anomaly Agent sering bergantung pada pola hulu untuk menghasilkan output yang kaya konteks. Autonomous Agent memiliki prasyarat infrastruktur paling ketat, yang mengharuskan setiap API alat diuji sebelum deployment.
Apa yang terjadi jika Anda menerapkan model Scoring tanpa data historis berlabel?
Model scoring menghasilkan skor yang tidak berkorelasi dengan hasil aktual. Lead berperingkat tinggi gagal untuk close pada tingkat yang diprediksi. Lead berperingkat rendah berkonversi pada tingkat yang modelnya memberi probabilitas rendah. Model terlihat aktif tetapi berfungsi sebagai noise. Solusi: sebelum pelatihan, validasi bahwa kumpulan catatan historis memiliki label hasil yang konsisten dan bahwa field fitur terisi lebih dari 80% catatan.
Seberapa sering prasyarat pola AI perlu diaudit ulang setelah deployment awal?
Basis pengetahuan RAG harus ditinjau minimal setiap kuartal, dengan pembaruan segera dipicu oleh perubahan produk atau kebijakan besar. Model scoring harus dilatih ulang setiap enam bulan terhadap data hasil yang segar, dengan pemantauan drift bulanan. Baseline deteksi anomali perlu dikalibrasi ulang setiap kali terjadi perubahan bisnis yang signifikan (lini produk baru, pasar baru, restrukturisasi tim besar). Prasyarat bukan pemeriksaan satu kali.
Apa itu Pattern Dependency Map?
Pattern Dependency Map adalah struktur audit prasyarat yang mengategorikan setiap pola AI berdasarkan tiga sumbu sebelum implementasi: ketergantungan data, ketergantungan infrastruktur, dan ketergantungan pola (pola hulu yang harus berjalan terlebih dahulu). Menjalankan peta ini sebelum keputusan build mengeliminasi penundaan tiga hingga enam bulan yang terjadi ketika prasyarat yang hilang muncul di tengah integrasi.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Jenis-jenis ketergantungan
- Peta ketergantungan berdasarkan pola
- Pattern Dependency Map
- Jalur kritis: urutan deployment AI Sales Operator
- Kegagalan prasyarat yang umum berdasarkan pola
- Daftar periksa audit kesiapan data
- Prasyarat infrastruktur yang sering terlewatkan tim
- Pengurutan untuk tim dengan sumber daya terbatas
- Memperbarui prasyarat dari waktu ke waktu
- Pelajari lebih lanjut