Ketika Pola AI Menjadi Mahal dalam Skala

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Pilotnya tampak terjangkau. Anda memproses 500 dokumen, menjalankan sistem selama 60 hari, dan menghabiskan $400. Keuangan menyetujui rollout penuh. Enam bulan kemudian, Anda memproses 50.000 dokumen dan tagihan adalah $40.000. Bukan $4.000. Bukan $8.000. $40.000, karena kompleksitas dokumen meningkat, Anda menambahkan pass LLM kedua untuk pemeriksaan kualitas, dan indeks embedding perlu dibangun ulang ketika Anda menambahkan tipe dokumen baru.
Cost overrun AI dalam skala hampir selalu dapat diprediksi dalam retrospektif. Model harga per-inference, perilaku penskalaan token dengan ukuran dokumen, biaya penyimpanan untuk embedding: tidak ada dari ini yang tersembunyi. Ini hanya tidak dimodelkan dengan hati-hati sebelum deployment karena pilot berjalan pada volume rendah dan biaya tidak terlihat pada volume rendah.
Artikel ini membuat kejutan biaya dapat diprediksi di awal, pola per pola.
Mengapa kurva biaya AI berbeda dari kurva biaya perangkat lunak
Biaya perangkat lunak tradisional sebagian besar tetap: biaya lisensi, biaya implementasi, dan kenaikan per pengguna yang relatif datar. Anda membayar untuk kursi, bukan untuk penggunaan. Model biayanya dapat diprediksi dan terdepan.
Biaya pola AI berbasis konsumsi dengan cara yang berinteraksi dengan volume data, kompleksitas dokumen, dan pola query Anda. Analisis McKinsey tentang ekonomi baru teknologi enterprise di dunia AI mendokumentasikan pergeseran ini: 79% pengeluaran TI sekarang adalah pengeluaran operasional daripada pengeluaran modal, dan penggunaan LLM berbasis token adalah driver utama kompleksitas FinOps. Empat dinamika yang tidak dimiliki perangkat lunak:
Harga per-inference. Setiap pemanggilan model membutuhkan token. Biaya token skala dengan panjang input dan panjang output. Dokumen 10 halaman biayanya sekitar 10x lebih mahal untuk diproses daripada dokumen 1 halaman. Pada volume rendah, ini tidak terlihat. Pada volume tinggi, ini adalah pos biaya terbesar Anda.
Biaya penyimpanan untuk embedding dan indeks. Sistem RAG Assistant menyimpan vector embedding untuk setiap dokumen yang diindeks. Penyimpanan vektor memiliki biaya per-dimensi, per-catatan. Knowledge base dengan 100.000 dokumen pada 1.536 dimensi per embedding memerlukan penyimpanan yang signifikan, dan re-embedding ketika Anda memperbarui dokumen adalah peristiwa komputasi, bukan hanya pembaruan penyimpanan.
Biaya retraining yang meningkat dengan kompleksitas bisnis. Model scoring, baseline anomali, dan rekomendasi engine membutuhkan retraining berkala seiring data Anda berubah. Siklus retraining awal murah karena Anda memiliki data yang relatif sedikit. Siklus retraining selanjutnya lebih mahal karena Anda memiliki lebih banyak data dan pola yang lebih kompleks untuk dipelajari.
Perilaku biaya non-linear pada input yang kompleks. Kontrak 50 halaman biayanya sekitar 50x lebih mahal untuk diproses per pass LLM daripada kontrak 1 halaman. Meeting dengan 8 peserta biayanya lebih mahal untuk diatribusikan dan diringkas daripada panggilan 2 orang. Biaya per unit di ujung bawah distribusi kompleksitas terlihat jauh lebih baik daripada biaya rata-rata pada volume produksi.
Key Facts: Biaya AI dalam Skala
- Model AI agentic memerlukan antara 5 dan 30 kali lebih banyak token per tugas daripada chatbot generative AI standar. Autonomous agent yang beralasan secara iteratif dan memanggil alat mungkin memicu 10-20 pemanggilan LLM per tugas pengguna tunggal. (Gartner, Maret 2026)
- Harga token telah turun 280x selama dua tahun, tetapi total pengeluaran AI enterprise naik 320% dalam periode yang sama, didorong oleh pergeseran ke alur kerja agentic dan arsitektur RAG yang mengembangkan context window 3-5x. (Oplexa Inference Cost Crisis Analysis, 2026)
- 55% model ML dalam produksi memerlukan retraining dalam 90 hari, menambahkan biaya retraining ke budget deployment awal yang tidak pernah dimodelkan sebagian besar tim dalam persetujuan tahun pertama. (DataRobot, 2025)
Driver biaya per pola
RAG Assistant
Driver biaya utama: ukuran context window selama retrieval dan generasi.
Query RAG sederhana mengambil 3-5 potongan dokumen dan menggunakannya sebagai konteks untuk jawaban. Jika setiap potongan adalah 500 token, context window Anda untuk generasi adalah 1.500-2.500 token ditambah pertanyaan. Dengan $0,01/1k token untuk model tier menengah, itu sekitar $0,02-0,03 per query.
Dengan 10.000 query/bulan: $200-300. Dapat dikelola.
Tetapi pada volume query tinggi dengan pertanyaan kompleks, sistem RAG sering mengambil lebih banyak potongan (akurasi yang lebih baik membutuhkan lebih banyak konteks) dan menggunakan context window yang lebih panjang. Pertanyaan kebijakan yang kompleks mungkin mengambil 10 potongan masing-masing 1.000 token: $0,10-0,15 per query. Dengan 50.000 query/bulan, itu $5.000-7.500/bulan hanya untuk biaya query, sebelum penyimpanan.
Biaya penyegaran indeks adalah kejutan kedua. Jika knowledge base Anda memiliki 500.000 dokumen dan Anda memperbarui 10% bulanan, itu 50.000 re-embedding per bulan. Dengan $0,0001 per embedding (harga text-embedding-3-small), itu $5/bulan. Dengan text-embedding-3-large: $0,13 per 1k token, rata-rata dokumen 500 kata (~667 token) = $0,087 per dokumen. 50.000 re-embedding = $4.350/bulan hanya untuk pemeliharaan indeks.
Scoring + Routing
Biaya per-inference rendah. Model scoring biasanya lebih kecil, lebih cepat, dan lebih murah daripada model generative. Risiko biaya utama adalah frekuensi retraining dan infrastruktur data.
Model scoring yang perlu retraining triwulanan memerlukan: penarikan dan pembersihan data, komputasi rekayasa fitur, komputasi pelatihan model, evaluasi, dan deployment. Untuk model in-house, ini adalah waktu rekayasa. Untuk model yang dikelola vendor, ini biasanya biaya layanan. Biayanya terbatas dan dapat diprediksi, tetapi tim sering tidak memanggarkannya di tahun ke-2 karena bukan bagian dari biaya deployment awal.
Vision Extract
Biaya pemrosesan per halaman skala persis linear dengan volume dokumen. Ini dapat diprediksi. Model biayanya jujur. Tetapi "kami akan memproses 200 dokumen sebulan" dalam pilot sering menjadi "kami perlu mengisi kembali 2 tahun faktur historis" (lonjakan pemrosesan satu kali) ditambah "semua faktur baru ditambah semua dokumen historis yang sekarang kami proses ulang untuk akurasi yang ditingkatkan."
Pemrosesan gambar resolusi tinggi biayanya lebih mahal daripada resolusi rendah. Jika vendor Anda menagih berdasarkan waktu komputasi per gambar dan Anda meningkatkan peralatan pemindaian, biaya per dokumen Anda meningkat bahkan pada volume dokumen yang sama.
Meeting Intelligence
Dua driver biaya yang keduanya skala dengan volume penggunaan:
Biaya transkripsi. API speech-to-text biasanya dihargai per menit audio. Transkripsi kelas Whisper berjalan $0,006-0,024/menit tergantung tier layanan. Panggilan penjualan 60 menit: $0,36-$1,44. Dengan 500 panggilan/bulan: $180-$720 hanya untuk transkripsi. Dengan 5.000 panggilan/bulan (skala enterprise): $1.800-$7.200/bulan.
Biaya ringkasan LLM. Panggilan panjang menghasilkan transkrip panjang. Transkrip panggilan 60 menit adalah sekitar 8.000-12.000 kata (6.000-9.000 token). Memprosesnya untuk ringkasan, item tindakan, dan ekstraksi field CRM dengan $0,01/1k token input + $0,03/1k token output: sekitar $0,12-0,18 per panggilan. Dengan 5.000 panggilan/bulan: $600-$900/bulan.
Kejutan biaya terjadi ketika tim men-deploy Meeting Intelligence untuk semua meeting, bukan hanya yang berhadapan dengan pelanggan. Standup internal, meeting perencanaan, dan rapat pleno tidak menghasilkan data CRM yang berguna, tetapi mereka masih mengakumulasi biaya transkripsi dan pemrosesan. Kebijakan scoping sederhana (Meeting Intelligence hanya untuk panggilan eksternal) sering memotong biaya sebesar 60-70% tanpa mengurangi nilai.
Anomaly Agent
Biaya ingesti aliran pada volume data tinggi adalah risiko utama. Jika Anomaly Agent Anda memantau aliran transaksi dengan 1 juta event/hari, biaya penyimpanan dan pemrosesan signifikan sebelum Anda menambahkan pemanggilan LLM apa pun.
Untuk deteksi anomali statistik murni (tanpa LLM), biaya dapat dikelola dan skala secara dapat diprediksi. Risiko biaya masuk ketika Anomaly Agent menggunakan pemanggilan LLM untuk pengayaan konteks ("jelaskan mengapa transaksi ini anomalus dalam bahasa alami") atau untuk korelasi multi-sinyal yang kompleks. Pada volume alert tinggi, pemanggilan LLM tersebut bertambah.
Generative Research
Token LLM untuk sintesis skala dengan panjang materi sumber. Brief penelitian yang menarik 20 dokumen sumber, masing-masing 3.000 kata, menyajikan sekitar 60.000 kata konteks sebelum model menghasilkan apa pun. Dengan harga gpt-4, itu $1,80-$2,40 dalam token input saja per tugas penelitian. Generasi output menambahkan $0,30-0,60 lagi. Per tugas penelitian: $2-3.
Ini terdengar rendah. Tetapi jika tim operasi penelitian Anda menghasilkan 100 brief/bulan, itu $200-300/bulan hanya dalam biaya API, sebelum biaya infrastruktur mengelola pipeline penelitian. Skala ke 1.000 brief/bulan: $2.000-3.000/bulan. Untuk operasi konsultasi besar yang melakukan 5.000+ tugas penelitian/bulan, biaya LLM saja mendekati $15.000-20.000/bulan.
Lever kontrol biaya: pembatasan cakupan. Penelitian yang mensintesis 5 dokumen yang ditargetkan biayanya 75% lebih murah daripada penelitian yang membaca semua yang dapat ditemukannya. Prompt penelitian dengan batas sumber eksplisit ("gunakan 10 sumber paling relevan teratas") menghasilkan kualitas yang sebanding dengan sumber tak terbatas dengan sebagian kecil biaya.
Document Review
Panjang kontrak adalah driver biaya utama. Meninjau NDA 5 halaman biayanya jauh lebih murah daripada meninjau perjanjian perangkat lunak enterprise 150 halaman dengan 40 lampiran. Jika campuran dokumen Anda bergeser dari kontrak pendek (startup tahap awal) ke perjanjian enterprise yang kompleks (tahap pertumbuhan), biaya per dokumen Anda meningkat secara substansial tanpa perubahan volume apa pun.
Risiko kedua: beberapa pass tinjauan. Tim yang sadar kualitas sering menjalankan pass ekstraksi awal, kemudian pass perbandingan klausul, kemudian pass generasi ringkasan. Setiap pass mengalikan biaya dokumen dasar. Pipeline tinjauan 3-pass biayanya 3x dari pipeline single-pass. Tentukan pass yang diperlukan di awal dan anggarkan untuk itu.
Workflow Copilot
Manajemen context window adalah lever biaya kunci. Workflow Copilot yang menarik seluruh riwayat catatan CRM, 10 thread email terakhir, dokumen akun yang relevan, dan konteks tugas saat ini ke setiap pemanggilan saran mahal. Setiap pemanggilan saran mungkin menggunakan 8.000-15.000 token konteks bahkan untuk draf email sederhana.
Dengan 20 permintaan saran/pengguna/hari x 50 pengguna = 1.000 pemanggilan/hari. Dengan $0,15/pemanggilan (rata-rata di seluruh konteks + output): $150/hari, $4.500/bulan. Dengan 200 pengguna: $18.000/bulan.
Kompresi konteks (meringkas konteks historis daripada menyertakan catatan mentah), perutean query (permintaan lebih sederhana pergi ke model yang lebih murah), dan caching saran (permintaan serupa menggunakan kembali respons sebelumnya) dapat mengurangi biaya ini sebesar 50-70% tanpa kehilangan kualitas yang berarti.
Personalization Engine
Risiko biaya di sini adalah inference real-time dalam skala. Menyajikan rekomendasi yang dipersonalisasi memerlukan pemanggilan model (atau pencarian kesamaan vektor) untuk setiap interaksi pengguna. Dengan 100.000 daily active user yang membuat 10 keputusan relevan personalisasi masing-masing: 1 juta pemanggilan inference per hari.
Jika setiap pemanggilan menggunakan model kecil yang didedikasikan dengan $0,001/pemanggilan: $1.000/hari, $30.000/bulan. Jika Anda meningkatkan ke LLM berkualitas lebih tinggi untuk rekomendasi yang lebih baik: biaya berkali-kali lipat 10-20x. Keputusan rekayasa antara kualitas model dan biaya inference adalah keputusan arsitektur biaya terpenting untuk pola ini.
Caching mengurangi biaya secara substansial: jika 40% pengguna memiliki profil yang cukup serupa sehingga Anda dapat menyajikan rekomendasi yang di-cache, Anda menghilangkan 40% pemanggilan inference.
Autonomous Agent: risiko biaya tertinggi
Ini adalah pola yang paling mungkin menghasilkan peristiwa anggaran yang tidak terduga. Nyatakan dengan jelas: Autonomous Agent tanpa batas iterasi yang keras dan batas anggaran per tugas adalah liability, bukan alat.
Inilah yang terjadi ketika berjalan salah:
Autonomous Agent support pelanggan produksi diberi tugas: "Selesaikan tiket #48291: pelanggan mengatakan mereka ditagih dua kali." Agent memulai loopnya. Ia membaca tiket (1 pemanggilan). Ia menarik riwayat pembayaran (1 pemanggilan). Ia menemukan ambiguitas dan mencari tiket terkait (2 pemanggilan). Ia membuat draf respons (1 pemanggilan). Ia menentukan perlu persetujuan manajer dan mencari kebijakan eskalasi (1 pemanggilan). Ia menemukan kebijakan tidak jelas dan membaca dokumen kebijakan lengkap (1 pemanggilan). Ia memutuskan perlu memeriksa 3 bulan riwayat transaksi (3 pemanggilan). Ia membandingkan transaksi dan menghasilkan analisis (2 pemanggilan). Pada saat ini: 12 pemanggilan model untuk satu tiket support.
Tetapi agent juga mengalami cabang yang tidak terduga: pelanggan memiliki keluhan terkait dari 6 bulan lalu yang tampaknya relevan. Agent menarik thread tersebut. 4 pemanggilan lagi. Kemudian ia memutuskan riwayat akun pelanggan relevan. 3 pemanggilan lagi. Kemudian ia membuat draf dua opsi resolusi, merevisi masing-masing berdasarkan kebijakan perusahaan, dan memformat respons akhir. 6 pemanggilan lagi.
Total: 25 pemanggilan model untuk satu tiket support, dengan $0,05-0,15 per pemanggilan = $1,25-3,75 per resolusi tiket, versus biaya $0,10-0,20 yang Anda anggarkan berdasarkan pilot dengan tiket sederhana.
Dengan 10.000 tiket kompleks/bulan, biaya aktual adalah $12.500-37.500/bulan versus $1.000-2.000/bulan yang dianggarkan. Ini terjadi.
Persyaratan kontrol biaya: batas iterasi keras (maksimum 10 pemanggilan model per tugas), anggaran token per tugas, dan handoff otomatis ke agen manusia ketika batas tercapai. Ini bukan kemudahan operasional. Ini adalah kontrol keuangan.
"Autonomous Agent tanpa batas iterasi yang keras bukan alat produktivitas. Ini adalah liability keuangan. Analisis Gartner Maret 2026 mengkonfirmasi model agentic memerlukan 5-30x lebih banyak token per tugas daripada chatbot standar. Agent yang mencapai ujung atas kisaran tersebut pada tiket support yang kompleks biayanya $3-4 per resolusi dengan harga token enterprise, versus $0,10-0,20 yang dianggarkan." (Rework Autonomous Agent Cost Analysis, 2026)
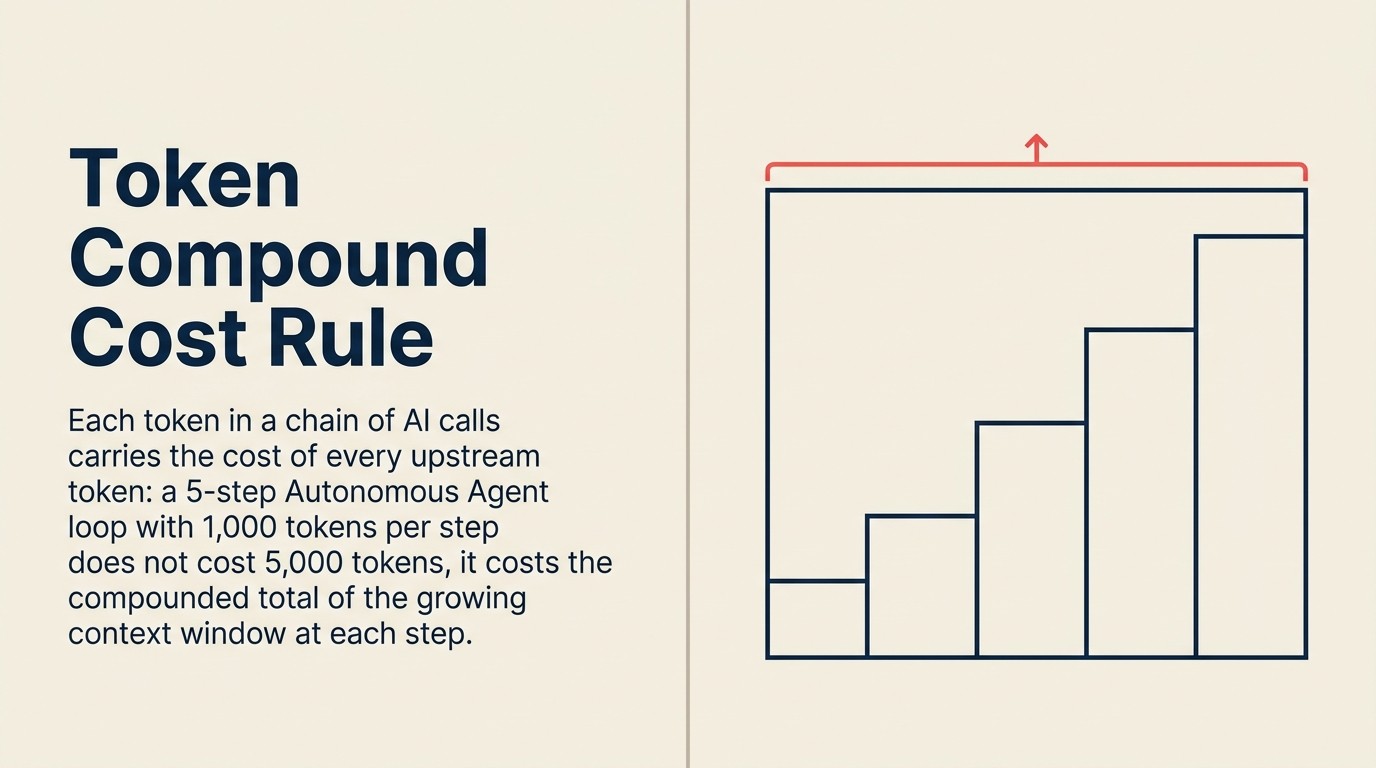
Token Compound Cost Rule
Token Compound Cost Rule menyatakan bahwa total pengeluaran AI enterprise skala dengan jumlah pemanggilan LLM per tugas pengguna, ukuran context window rata-rata per pemanggilan, dan frekuensi retraining per pola, bukan dengan harga per token. Ini menjelaskan mengapa total pengeluaran AI enterprise naik 320% sementara harga token individual turun 280x: pergeseran ke alur kerja agentic (10-20 pemanggilan per tugas), arsitektur RAG (inflasi context window 3-5x), dan agen pemantauan always-on menciptakan volume pemanggilan yang bertambah yang mengalahkan pengurangan harga per token. Implikasi praktis Rule ini adalah bahwa kontrol biaya dalam skala memerlukan pembatasan pemanggilan per tugas, caching konteks yang berulang, dan pembatasan deployment ke alur kerja bernilai tertinggi, bukan menunggu harga token turun lebih jauh.
Rework Analysis: Berdasarkan temuan Gartner bahwa model agentic memerlukan 5-30x lebih banyak token per tugas dan temuan Oplexa bahwa pengeluaran AI enterprise naik 320% meskipun harga token turun 280x, Token Compound Cost Rule mengidentifikasi tiga pengali biaya yang secara sistematis dilewatkan budget pilot: penggabungan volume pemanggilan dari loop otonom, inflasi context window dari RAG dan retrieval riwayat, dan biaya frekuensi retraining yang skala dengan kompleksitas data. Data implementasi Rework menunjukkan bahwa tim yang memodelkan ketiga pengali sebelum persetujuan deployment memiliki rata-rata cost overrun produksi 23%. Tim yang hanya memodelkan harga per token memiliki rata-rata overrun 287%.
Empat skenario cost overrun paling umum
Skenario 1: Indeks embedding yang tumbuh tanpa pemangkasan. Sistem RAG di-deploy dengan knowledge base bersih 10.000 dokumen. Tidak ada yang menghapus dokumen lama ketika kebijakan diperbarui atau produk dihentikan. Dua tahun kemudian, indeks memiliki 80.000 dokumen (sebagian besar sudah usang), kualitas retrieval menurun karena model mengambil konten usang, dan re-indexing untuk memperbaikinya biayanya lebih dari deployment asli. Anggarkan pemeliharaan indeks dari hari pertama. Ini juga bagaimana sistem RAG menjadi tech debt. Lihat ketika pola AI menjadi tech debt untuk trajektori biaya lengkap.
Skenario 2: Autonomous Agent tanpa batas iterasi. Dijelaskan di atas. Ini adalah risiko terbatas dengan solusi lengkap: batas anggaran dan batas iterasi, yang ditentukan sebelum deployment. Proposal deployment Autonomous Agent mana pun yang tidak menyertakan ini sebagai persyaratan yang tidak dapat dinegosiasikan harus dikembalikan. Analisis Andreessen Horowitz tentang LLMflation dan ekonomi inference menunjukkan bahwa sementara biaya per token turun 10x per tahun, total pengeluaran inference enterprise naik karena penggunaan tumbuh lebih cepat dari harga turun. Dinamika tersebut membuat batas iterasi kritis terlepas dari seberapa murah token individu menjadi.
Skenario 3: Meeting Intelligence memproses setiap meeting internal. Cost overrun paling mudah dihindari. 70% meeting di sebagian besar organisasi bersifat internal. Meeting Intelligence memberikan nilai CRM nol untuk meeting internal. Batasi deployment ke panggilan yang berhadapan dengan pelanggan saja sebelum peluncuran, bukan setelah tagihan tiba.
Skenario 4: Generative Research dengan cakupan yang terlalu luas. Prompt penelitian yang mengatakan "teliti semua yang relevan dengan X" menghasilkan hasil lengkap tetapi biaya lengkap. Tentukan jumlah sumber maksimum, kedalaman dokumen maksimum, dan cakupan topik dalam template prompt penelitian Anda. "Teliti aktivitas kompetitif 6 bulan terakhir dari Pesaing X, menggunakan 10 sumber paling relevan teratas" menghasilkan 85% nilai dari "teliti semua tentang Pesaing X" dengan 20% biaya.
Membangun model biaya sebelum deployment
Untuk setiap deployment pola, modelkan input ini sebelum persetujuan:
| Input | Dari mana asalnya |
|---|---|
| Jumlah token input rata-rata per pemanggilan | Ukur 20-30 sampel representatif |
| Jumlah token output rata-rata per pemanggilan | Perkirakan dari desain prompt |
| Volume pemanggilan yang diharapkan (bulanan) | Baseline volume alur kerja saat ini |
| Harga model (per 1k token) | Rate card vendor |
| Biaya penyimpanan (embedding, rekaman, indeks) | Harga penyimpanan vendor |
| Frekuensi dan biaya retraining | Keputusan arsitektur |
Bangun tiga skenario: konservatif (volume saat ini), moderat (2x volume saat ini di tahun 1), dan agresif (5x volume pada puncak). Jika skenario agresif menghasilkan biaya yang tidak dapat diterima, rancang kontrol biaya sebelum deployment, bukan setelah.
Mengapa estimasi pra-deployment biasanya terlalu rendah: sampel berasal dari kasus termudah dan paling representatif. Produksi mencakup semua edge case, dokumen panjang, query kompleks, dan pola penggunaan yang tidak terduga yang disaring pilot. Tambahkan buffer 50-100% ke estimasi sentral Anda.
Memantau anomali biaya
Terapkan konsep Anomaly Agent ke data biaya AI Anda sendiri. Siapkan dashboard biaya-per-transaksi untuk setiap pola yang di-deploy. Tentukan kisaran biaya normal berdasarkan 60 hari pertama data produksi Anda. Tetapkan alert ketika biaya-per-transaksi naik lebih dari 30% di atas baseline.
Sinyal peringatan dini:
- Ukuran context window rata-rata meningkat (tanda creep cakupan prompt atau perubahan ukuran input)
- Jumlah iterasi per tugas Autonomous Agent meningkat (tanda creep kompleksitas tugas atau model drift)
- Frekuensi penyegaran indeks meningkat (tanda pertumbuhan knowledge base tanpa pemangkasan)
- Tingkat kesalahan meningkat bersama biaya (tanda model berjuang, yang mengarah ke biaya retry)
Ketika sebuah pola menjadi terlalu mahal
Framework keputusan:
Optimasi terlebih dahulu. Kompresi konteks, caching, downgrade model untuk tugas yang lebih sederhana, batching daripada pemrosesan real-time. Pass optimasi tipikal memulihkan 30-50% biaya tanpa dampak kualitas.
Kurangi cakupan kedua. Tentukan kasus penggunaan bernilai tertinggi dalam pola dan batasi deployment ke sana. Meeting Intelligence hanya untuk akun enterprise. Generative Research hanya untuk akun tier-1. Ini bukan kegagalan. Ini adalah alokasi biaya yang rasional.
Ganti dengan pola yang lebih murah jika optimasi dan scoping tidak berhasil. Autonomous Agent yang melakukan perutean tugas mungkin dapat digantikan dengan model Scoring dan Routing dengan 5% biaya, jika kompleksitas tugas sebenarnya tidak memerlukan otonomi multi-langkah. Pemilihan pola selalu dapat direvisi. Artikel keputusan buy vs. build per pola menunjukkan di mana solusi vendor mengurangi biaya dibandingkan build kustom.
Lihat ketika pola AI menjadi tech debt untuk trajektori biaya jangka panjang dari pola yang tidak dirancang untuk keterpeliharaan, dan mengukur ROI pola AI untuk cara melacak biaya dalam hubungannya dengan nilai. Tujuannya bukan deployment termurah. Ini adalah deployment bernilai tertinggi dengan biaya yang dapat ditanggung bisnis dalam skala.
Pertanyaan yang Sering Diajukan
Apa itu Token Compound Cost Rule?
Token Compound Cost Rule menyatakan bahwa total pengeluaran AI enterprise skala dengan tiga pengali yang bertambah bersama: jumlah pemanggilan LLM per tugas pengguna (alur kerja agentic memicu 10-20 pemanggilan versus 1-2 untuk query sederhana), ukuran context window rata-rata per pemanggilan (arsitektur RAG mengembangkan konteks 3-5x), dan frekuensi retraining per pola (55% model membutuhkan retraining dalam 90 hari). Pengurangan harga per token tidak mengimbangi volume pemanggilan yang bertambah. Pengeluaran AI enterprise naik 320% sementara harga per token turun 280x justru karena pengali-pengali ini.
Mengapa biaya pilot AI terlihat sangat berbeda dari biaya produksi?
Pilot menyaring semua edge case, dokumen panjang, query kompleks, dan pola penggunaan yang tidak biasa yang termasuk dalam produksi. Pilot yang memproses 500 dokumen representatif dengan kompleksitas rata-rata melewatkan 15% dokumen produksi yang panjang, non-standar, atau memerlukan beberapa pass pemrosesan. Tambahkan buffer 50-100% ke estimasi biaya pilot untuk perencanaan produksi. Untuk Autonomous Agent khususnya, tambahkan juga buffer jumlah iterasi.
Apa kontrol biaya tunggal yang paling berpengaruh untuk Autonomous Agent?
Batas iterasi keras (pemanggilan LLM maksimum per tugas) dan batas anggaran token per tugas. Autonomous Agent tanpa kontrol keuangan ini adalah komitmen biaya terbuka. Analisis Gartner menunjukkan agent memerlukan 5-30x lebih banyak token per tugas daripada chatbot standar, dengan tugas kompleks mencapai ujung atas kisaran tersebut. Menetapkan maksimum 10 pemanggilan per tugas dan handoff otomatis ke agen manusia ketika batas tercapai bukan kemudahan operasional. Ini adalah kontrol keuangan.
Bagaimana cakupan deployment Meeting Intelligence mempengaruhi biaya?
Mengerahkan Meeting Intelligence untuk semua meeting daripada hanya meeting yang berhadapan dengan pelanggan biasanya menambahkan 60-70% ke biaya transkripsi dan pemrosesan dengan nol nilai CRM tambahan. Meeting internal (standup, perencanaan, rapat pleno) tidak menghasilkan data deal yang berguna tetapi masih mengakumulasi biaya transkripsi per menit dan biaya ringkasan per panggilan. Pembatasan cakupan ke panggilan eksternal saja sebelum peluncuran adalah optimasi biaya tunggal termudah dalam pola Meeting Intelligence.
Kapan organisasi harus memilih model yang lebih murah daripada model yang lebih baik?
Ketika kompleksitas query tidak memerlukan kemampuan model yang lebih baik. Model routing, mengarahkan permintaan lebih sederhana ke model yang lebih murah dan permintaan kompleks ke model premium, mengurangi biaya AI enterprise sebesar 30-50% tanpa kehilangan kualitas pada tugas sederhana. Untuk Workflow Copilot, saran konteks-pendek (pemeriksaan nada email, penyelesaian field sederhana) dapat berjalan pada model yang lebih kecil dengan sebagian kecil biaya inference GPT-4 kelas full-context. Bangun model routing ke dalam arsitektur sebelum deployment, bukan sebagai retrofit penghemat biaya.
Tren biaya apa yang harus dipersiapkan enterprise hingga 2030?
Gartner memprediksi biaya inference akan turun lebih dari 90% pada 2030. Tetapi harga saat ini disubsidi oleh modal ventura dan cross-subsidi hyperscaler, menciptakan lantai yang secara artifisial rendah yang mungkin menormalisasi ke atas sebelum penurunan jangka panjang berlanjut. Organisasi yang membangun model biaya untuk cakrawala waktu 3+ tahun harus merencanakan periode volatilitas harga daripada mengasumsikan penurunan biaya linear. Pertumbuhan volume dari adopsi agentic juga menekan margin penyedia, yang dapat sebagian mengimbangi pengurangan biaya inference mentah.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Mengapa kurva biaya AI berbeda dari kurva biaya perangkat lunak
- Driver biaya per pola
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: risiko biaya tertinggi
- Token Compound Cost Rule
- Empat skenario cost overrun paling umum
- Membangun model biaya sebelum deployment
- Memantau anomali biaya
- Ketika sebuah pola menjadi terlalu mahal
- Pelajari lebih lanjut