Apabila Corak AI Menjadi Mahal pada Skala

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Percubaan kelihatan berpatutan. Anda memproses 500 dokumen, menjalankan sistem selama 60 hari, dan membelanjakan $400. Kewangan meluluskan pelancaran penuh. Enam bulan kemudian, Anda memproses 50,000 dokumen dan bil adalah $40,000. Bukan $4,000. Bukan $8,000. $40,000, kerana kerumitan dokumen meningkat, Anda menambah larian LLM kedua untuk semakan kualiti, dan indeks embeddings memerlukan pembinaan semula apabila Anda menambah jenis dokumen baharu.
Kos berlebihan AI pada skala hampir selalu boleh diramal secara retrospektif. Model harga setiap inferens, tingkah laku penskalaan token dengan saiz dokumen, kos penyimpanan untuk embeddings: tidak ada perkara ini yang tersembunyi. Ia hanya tidak dimodelkan dengan teliti sebelum pelancaran kerana percubaan dijalankan pada isipadu rendah dan kos tidak kelihatan pada isipadu rendah.
Artikel ini menjadikan kejutan kos boleh diramal lebih awal, corak demi corak.
Mengapa keluk kos AI berbeza daripada keluk kos perisian
Kos perisian tradisional kebanyakannya tetap: yuran lesen, kos pelaksanaan, dan kenaikan setiap pengguna yang agak mendatar. Anda membayar untuk tempat duduk, bukan untuk penggunaan. Model kos boleh diramal dan dihadapkan.
Kos corak AI adalah berasaskan penggunaan dengan cara yang berinteraksi dengan isipadu data, kerumitan dokumen, dan corak pertanyaan Anda. Analisis McKinsey tentang ekonomi baharu teknologi perusahaan dalam dunia AI mendokumenkan peralihan ini: 79% perbelanjaan IT kini adalah perbelanjaan operasi dan bukannya perbelanjaan modal, dan penggunaan LLM berasaskan token adalah pemacu utama kerumitan FinOps. Empat dinamik yang tidak dimiliki perisian:
Harga setiap inferens. Setiap panggilan model menelan kos token. Kos token berskala dengan panjang input dan panjang output. Dokumen 10 halaman menelan kos kira-kira 10x lebih untuk diproses daripada dokumen 1 halaman. Pada isipadu rendah, ini tidak kelihatan. Pada isipadu tinggi, ia adalah item baris terbesar Anda.
Kos penyimpanan untuk embeddings dan indeks. Sistem RAG Assistant menyimpan embeddings vektor untuk setiap dokumen yang diindeks. Penyimpanan vektor mempunyai kos setiap dimensi, setiap rekod. Pangkalan pengetahuan dengan 100,000 dokumen pada 1,536 dimensi setiap embedding memerlukan penyimpanan yang ketara, dan penyematan semula apabila Anda mengemas kini dokumen adalah peristiwa pengiraan, bukan sekadar kemas kini penyimpanan.
Kos latihan semula yang meningkat dengan kerumitan perniagaan. Model pemarkahan, garis dasar anomali, dan enjin cadangan memerlukan latihan semula berkala apabila data Anda berubah. Kitaran latihan semula awal adalah murah kerana Anda mempunyai data yang agak sedikit. Kitaran latihan semula kemudian adalah lebih mahal kerana Anda mempunyai lebih banyak data dan corak yang lebih kompleks untuk dipelajari.
Tingkah laku kos tidak linear pada input kompleks. Kontrak 50 halaman menelan kos kira-kira 50x lebih untuk diproses setiap larian LLM daripada kontrak 1 halaman. Mesyuarat dengan 8 peserta menelan kos lebih untuk dikaitkan dan diringkaskan daripada panggilan 2 orang. Kos setiap unit pada hujung bawah taburan kerumitan kelihatan jauh lebih baik daripada kos purata pada isipadu pengeluaran.
Key Facts: Kos AI pada Skala
- Model AI ejen memerlukan antara 5 dan 30 kali lebih banyak token setiap tugasan daripada chatbot AI generatif standard. Autonomous Agent yang bernaakulan secara berulang dan memanggil alat mungkin mencetuskan 10-20 panggilan LLM setiap tugasan pengguna tunggal. (Gartner, Mac 2026)
- Harga token telah jatuh 280x dalam dua tahun, tetapi jumlah perbelanjaan AI perusahaan meningkat 320% dalam tempoh yang sama, didorong oleh peralihan kepada aliran kerja ejen dan seni bina RAG yang mengembang tetingkap konteks 3-5x. (Oplexa Inference Cost Crisis Analysis, 2026)
- 55% model ML dalam pengeluaran memerlukan latihan semula dalam tempoh 90 hari, menambah kos latihan semula kepada bajet pelancaran awal yang kebanyakan pasukan tidak pernah modelkan dalam kelulusan tahun pertama mereka. (DataRobot, 2025)
Pemacu kos mengikut corak
RAG Assistant
Pemacu kos utama: saiz tetingkap konteks semasa pengambilan semula dan penjanaan.
Pertanyaan RAG mudah mengambil semula 3-5 bahagian dokumen dan menggunakannya sebagai konteks untuk jawapan. Jika setiap bahagian adalah 500 token, tetingkap konteks Anda untuk penjanaan adalah 1,500-2,500 token ditambah soalan. Pada $0.01/1k token untuk model peringkat pertengahan, itu kira-kira $0.02-0.03 setiap pertanyaan.
Pada 10,000 pertanyaan/bulan: $200-300. Boleh diurus.
Tetapi pada isipadu pertanyaan tinggi dengan soalan kompleks, sistem RAG sering mengambil semula lebih banyak bahagian (ketepatan lebih baik memerlukan lebih banyak konteks) dan menggunakan tetingkap konteks yang lebih panjang. Soalan dasar yang kompleks mungkin mengambil semula 10 bahagian pada 1,000 token setiap satu: $0.10-0.15 setiap pertanyaan. Pada 50,000 pertanyaan/bulan, itu $5,000-7,500/bulan untuk kos pertanyaan sahaja, sebelum penyimpanan.
Kos kemas kini indeks adalah kejutan kedua. Jika pangkalan pengetahuan Anda mempunyai 500,000 dokumen dan Anda mengemas kini 10% setiap bulan, itu adalah 50,000 penyematan semula setiap bulan. Pada $0.0001 setiap embedding (harga text-embedding-3-small), itu $5/bulan. Pada text-embedding-3-large: $0.13 per 1k token, purata dokumen 500 perkataan (kira-kira 667 token) = $0.087 setiap dokumen. 50,000 penyematan semula = $4,350/bulan hanya untuk penyelenggaraan indeks.
Scoring + Routing
Kos setiap inferens adalah rendah. Model pemarkahan biasanya lebih kecil, lebih pantas, dan lebih murah daripada model generatif. Risiko kos utama adalah kekerapan latihan semula dan infrastruktur data.
Model pemarkahan yang memerlukan latihan semula suku tahunan memerlukan: penarikan dan pembersihan data, pengiraan kejuruteraan ciri, pengiraan latihan model, penilaian, dan pelancaran. Untuk model dalam rumah, ini adalah masa kejuruteraan. Untuk model yang diurus vendor, ia biasanya adalah yuran perkhidmatan. Kosnya terbatas dan boleh diramal, tetapi pasukan sering tidak membajetkannya pada tahun 2 kerana ia bukan sebahagian daripada kos pelancaran awal.
Vision Extract
Kos pemprosesan setiap halaman berskala tepat secara linear dengan isipadu dokumen. Ini boleh diramal. Model kos adalah jujur. Tetapi "kami akan memproses 200 dokumen sebulan" dalam percubaan sering menjadi "kami perlu mengisi semula 2 tahun invois sejarah" (lonjakan pemprosesan satu kali) ditambah "semua invois baharu ditambah semua dokumen sejarah yang kini kami proses semula untuk ketepatan yang lebih baik."
Pemprosesan imej resolusi tinggi menelan kos lebih daripada resolusi rendah. Jika vendor Anda mengenakan caj berdasarkan masa pengiraan setiap imej dan Anda menaik taraf peralatan pengimbasan, kos setiap dokumen Anda meningkat walaupun pada isipadu dokumen yang sama.
Meeting Intelligence
Dua pemacu kos yang kedua-duanya berskala dengan isipadu penggunaan:
Kos transkripsi. API suara-ke-teks biasanya menetapkan harga setiap minit audio. Transkripsi kelas Whisper berjalan pada $0.006-0.024/minit bergantung pada peringkat perkhidmatan. Panggilan jualan 60 minit: $0.36-$1.44. Pada 500 panggilan/bulan: $180-$720 hanya untuk transkripsi. Pada 5,000 panggilan/bulan (skala perusahaan): $1,800-$7,200/bulan.
Kos rumusan LLM. Panggilan panjang menghasilkan transkrip yang panjang. Transkrip panggilan 60 minit adalah kira-kira 8,000-12,000 perkataan (6,000-9,000 token). Memprosesnya untuk ringkasan, item tindakan, dan pengekstrakan medan CRM pada $0.01/1k token input + $0.03/1k token output: kira-kira $0.12-0.18 setiap panggilan. Pada 5,000 panggilan/bulan: $600-$900/bulan.
Kejutan kos berlaku apabila pasukan melancarkan Meeting Intelligence untuk semua mesyuarat, bukan hanya yang berhadapan pelanggan. Mesyuarat dalaman, mesyuarat perancangan, dan panggilan semua-tangan tidak menghasilkan data CRM yang berguna, tetapi masih menanggung kos transkripsi dan pemprosesan. Dasar skop mudah (Meeting Intelligence untuk panggilan luaran sahaja) sering memotong kos sebanyak 60-70% tanpa mengurangkan nilai.
Anomaly Agent
Kos pengelanan aliran pada isipadu data tinggi adalah risiko utama. Jika Anomaly Agent Anda memantau aliran transaksi pada 1 juta peristiwa/hari, kos penyimpanan dan pemprosesan adalah ketara sebelum Anda menambah sebarang panggilan LLM.
Untuk pengesanan anomali statistik tulen (tanpa LLM), kos boleh diurus dan berskala secara boleh diramal. Risiko kos masuk apabila Anomaly Agent menggunakan panggilan LLM untuk pengayaan konteks ("terangkan mengapa transaksi ini adalah anomali dalam bahasa semula jadi") atau untuk korelasi berbilang isyarat yang kompleks. Pada isipadu amaran tinggi, panggilan LLM tersebut bertambah.
Generative Research
Token LLM untuk sintesis berskala dengan panjang bahan sumber. Taklimat penyelidikan yang menarik 20 dokumen sumber, setiap satu 3,000 perkataan, mempersembahkan kira-kira 60,000 perkataan konteks sebelum model menjana apa-apa. Pada harga gpt-4, itu $1.80-$2.40 dalam token input sahaja setiap tugasan penyelidikan. Penjanaan output menambah lagi $0.30-0.60. Setiap tugasan penyelidikan: $2-3.
Ini terdengar rendah. Tetapi jika pasukan operasi penyelidikan Anda menjana 100 taklimat/bulan, itu $200-300/bulan hanya dalam kos API, sebelum kos infrastruktur mengurus saluran penyelidikan. Skala kepada 1,000 taklimat/bulan: $2,000-3,000/bulan. Untuk operasi perundingan besar yang melakukan 5,000+ tugasan penyelidikan/bulan, kos LLM sahaja mendekati $15,000-20,000/bulan.
Tuas kawalan kos: had skop. Penyelidikan yang mensintesis 5 dokumen bertarget menelan kos 75% lebih sedikit daripada penyelidikan yang membaca semua yang boleh ditemui. Templat prompt penyelidikan dengan had sumber eksplisit ("gunakan 10 sumber paling relevan teratas") menghasilkan kualiti yang setanding dengan sumber tanpa had pada sebahagian kecil kos.
Document Review
Panjang kontrak adalah pemacu kos utama. Menyemak NDA 5 halaman menelan kos jauh lebih sedikit daripada menyemak perjanjian perisian perusahaan 150 halaman dengan 40 ekshibit. Jika campuran dokumen Anda beralih dari kontrak pendek (syarikat permulaan peringkat awal) kepada perjanjian perusahaan yang kompleks (peringkat pertumbuhan), kos setiap dokumen Anda meningkat secara ketara tanpa sebarang perubahan dalam isipadu.
Risiko kedua: berbilang larian semakan. Pasukan yang mementingkan kualiti sering menjalankan larian pengekstrakan awal, kemudian larian perbandingan klausa, kemudian larian penjanaan ringkasan. Setiap larian mendarab kos dokumen asas. Saluran semakan 3 larian menelan kos 3x berbanding saluran satu larian. Takrifkan larian yang diperlukan lebih awal dan bajetkan untuk mereka.
Workflow Copilot
Pengurusan tetingkap konteks adalah tuas kos utama. Workflow Copilot yang menarik sejarah rekod CRM penuh, 10 thread e-mel terakhir, dokumen akaun yang relevan, dan konteks tugasan semasa ke dalam setiap panggilan cadangan adalah mahal. Setiap panggilan cadangan mungkin menggunakan 8,000-15,000 token konteks walaupun untuk draf e-mel mudah.
Pada 20 permintaan cadangan/pengguna/hari x 50 pengguna = 1,000 panggilan/hari. Pada $0.15/panggilan (purata merentas konteks + output): $150/hari, $4,500/bulan. Pada 200 pengguna: $18,000/bulan.
Pemampatan konteks (meringkaskan konteks sejarah dan bukannya menyertakan rekod mentah), penghalaan pertanyaan (permintaan lebih mudah pergi ke model yang lebih murah), dan caching cadangan (permintaan yang serupa menggunakan semula respons sebelumnya) boleh mengurangkan kos ini sebanyak 50-70% tanpa kehilangan kualiti yang bermakna.
Personalization Engine
Risiko kos di sini adalah inferens masa nyata pada skala. Menyediakan cadangan yang diperibadikan memerlukan panggilan model (atau carian persamaan vektor) untuk setiap interaksi pengguna. Pada 100,000 pengguna aktif harian yang membuat 10 keputusan relevan pemperibadian setiap satu: 1 juta panggilan inferens setiap hari.
Jika setiap panggilan menggunakan model kecil yang berdedikasi pada $0.001/panggilan: $1,000/hari, $30,000/bulan. Jika Anda menaik taraf kepada LLM kualiti lebih tinggi untuk cadangan yang lebih baik: kos berganda 10-20x. Keputusan kejuruteraan antara kualiti model dan kos inferens adalah keputusan seni bina kos paling penting untuk corak ini.
Caching mengurangkan kos secara ketara: jika 40% pengguna mempunyai profil yang cukup serupa sehingga Anda boleh menyediakan cadangan yang dicache, Anda menghapuskan 40% panggilan inferens.
Autonomous Agent: risiko kos tertinggi
Ini adalah corak yang paling berkemungkinan menghasilkan peristiwa bajet yang tidak dijangka. Namakan dengan jelas: Autonomous Agent tanpa had iterasi keras dan had bajet setiap tugasan adalah liabiliti, bukan alat.
Inilah yang berlaku apabila ia tidak berjalan baik:
Autonomous Agent sokongan pelanggan pengeluaran diberikan tugasan: "Selesaikan tiket #48291: pelanggan mengatakan mereka dikenakan caj berganda." Ejen memulakan gelung. Ia membaca tiket (1 panggilan). Ia menarik sejarah pembayaran (1 panggilan). Ia mendapati kekaburan dan mencari tiket berkaitan (2 panggilan). Ia membuat draf respons (1 panggilan). Ia menentukan ia memerlukan kelulusan pengurus dan mencari dasar eskalasi (1 panggilan). Ia mendapati dasar tidak jelas dan membaca dokumen dasar penuh (1 panggilan). Ia memutuskan ia perlu menyemak 3 bulan sejarah transaksi (3 panggilan). Ia membandingkan transaksi dan menjana analisis (2 panggilan). Pada ketika ini: 12 panggilan model untuk satu tiket sokongan.
Tetapi ejen juga mencapai cabang yang tidak dijangka: pelanggan mempunyai aduan berkaitan dari 6 bulan lalu yang kelihatan relevan. Ejen menarik thread itu. 4 panggilan lagi. Kemudian ia memutuskan sejarah akaun pelanggan adalah relevan. 3 panggilan lagi. Kemudian ia membuat draf dua pilihan penyelesaian, menyemak semula setiap satu berdasarkan dasar syarikat, dan memformat respons akhir. 6 panggilan lagi.
Jumlah: 25 panggilan model untuk satu tiket sokongan, pada $0.05-0.15 setiap panggilan = $1.25-3.75 setiap penyelesaian tiket, berbanding kos $0.10-0.20 yang dibajetkan berdasarkan percubaan Anda dengan tiket mudah.
Pada 10,000 tiket kompleks/bulan, kos sebenar adalah $12,500-37,500/bulan berbanding bajet $1,000-2,000/bulan. Ini berlaku.
Keperluan kawalan kos: had iterasi keras (maksimum 10 panggilan model setiap tugasan), had token setiap tugasan, dan penyerahan automatik kepada ejen manusia apabila had dicapai. Ini bukan kemudahan operasional. Ia adalah kawalan kewangan.
"Autonomous Agent tanpa had iterasi keras bukan alat produktiviti. Ia adalah liabiliti kewangan. Analisis Gartner Mac 2026 mengesahkan model ejen memerlukan 5-30x lebih banyak token setiap tugasan daripada chatbot standard. Ejen yang mencapai hujung atas julat itu pada tiket sokongan yang kompleks menelan kos $3-4 setiap penyelesaian pada harga token perusahaan, berbanding bajet $0.10-0.20." (Rework Autonomous Agent Cost Analysis, 2026)
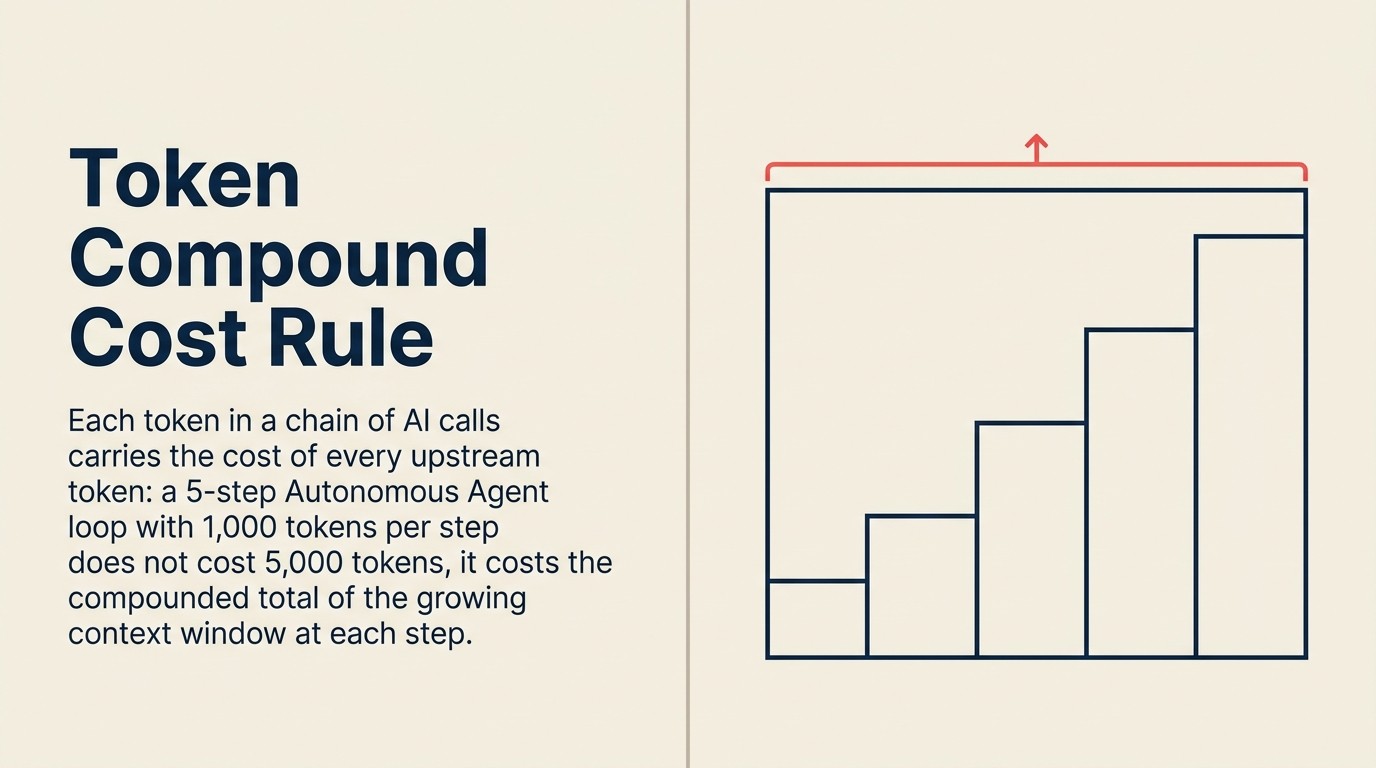
Peraturan Kos Sebatian Token
Peraturan Kos Sebatian Token menyatakan bahawa jumlah perbelanjaan AI perusahaan berskala dengan bilangan panggilan LLM setiap tugasan pengguna, saiz tetingkap konteks purata setiap panggilan, dan kekerapan latihan semula setiap corak, bukan dengan harga setiap token. Ini menerangkan mengapa jumlah perbelanjaan AI perusahaan meningkat 320% sementara harga token individu jatuh 280x: peralihan kepada aliran kerja ejen (10-20 panggilan setiap tugasan), seni bina RAG (pengembangan tetingkap konteks 3-5x), dan ejen pemantauan sentiasa aktif mewujudkan isipadu panggilan bergabung yang mengatasi pengurangan harga setiap token. Implikasi praktikal Peraturan ialah kawalan kos pada skala memerlukan mengehadkan panggilan setiap tugasan, menyimpan cache konteks berulang, dan mengeskopkan pelancaran kepada aliran kerja bernilai tertinggi, bukan menunggu harga token jatuh lebih jauh.
Rework Analysis: Berdasarkan penemuan Gartner bahawa model ejen memerlukan 5-30x lebih banyak token setiap tugasan dan penemuan Oplexa bahawa perbelanjaan AI perusahaan meningkat 320% walaupun harga token jatuh 280x, Peraturan Kos Sebatian Token mengenal pasti tiga pengganda kos yang secara sistematik terlepas oleh bajet percubaan: penggabungan isipadu panggilan dari gelung autonomi, pengembangan tetingkap konteks dari pengambilan semula RAG dan sejarah, dan kos kekerapan latihan semula yang berskala dengan kerumitan data. Data pelaksanaan Rework menunjukkan bahawa pasukan yang memodelkan ketiga-tiga pengganda sebelum kelulusan pelancaran mempunyai purata kos berlebihan pengeluaran sebanyak 23%. Pasukan yang hanya memodelkan harga setiap token mempunyai purata kos berlebihan sebanyak 287%.
Empat senario kos berlebihan paling biasa
Senario 1: Indeks embedding yang berkembang tanpa pemangkasan. Sistem RAG dilancarkan dengan pangkalan pengetahuan bersih 10,000 dokumen. Tiada siapa yang mengalih keluar dokumen lama apabila dasar dikemas kini atau produk dihentikan. Dua tahun kemudian, indeks mempunyai 80,000 dokumen (kebanyakannya lapuk), kualiti pengambilan semula merosot apabila model mengambil semula kandungan lapuk, dan mengindeks semula untuk membetulkan masalah ini menelan kos lebih daripada pelancaran asal. Bajetkan untuk penyelenggaraan indeks dari hari pertama. Inilah juga cara sistem RAG menjadi hutang teknikal. Lihat apabila corak AI menjadi hutang teknikal untuk trajektori kos penuh.
Senario 2: Autonomous Agent tanpa had iterasi. Diterangkan di atas. Ini adalah risiko terhad dengan penyelesaian lengkap: had bajet dan had iterasi, ditakrifkan sebelum pelancaran. Mana-mana cadangan pelancaran Autonomous Agent yang tidak menyertakan ini sebagai keperluan tidak boleh dirunding perlu dihantar balik. Analisis Andreessen Horowitz tentang LLMflation dan ekonomi inferens menunjukkan bahawa walaupun kos setiap token turun 10x setahun, jumlah perbelanjaan inferens perusahaan meningkat kerana penggunaan berkembang lebih cepat daripada harga jatuh. Dinamik itu menjadikan had iterasi kritikal tanpa mengira betapa murahnya token individu menjadi.
Senario 3: Meeting Intelligence memproses setiap mesyuarat dalaman. Kos berlebihan yang paling mudah dielakkan. 70% mesyuarat dalam kebanyakan organisasi adalah dalaman. Meeting Intelligence memberikan nilai CRM sifar untuk mesyuarat dalaman. Eskopkan pelancaran kepada panggilan berhadapan pelanggan sahaja sebelum pelancaran, bukan selepas bil tiba.
Senario 4: Generative Research pada skop yang terlalu luas. Prompt penyelidikan yang berkata "teliti semua yang relevan dengan X" menghasilkan keputusan lengkap tetapi kos lengkap. Takrifkan kiraan sumber maksimum, kedalaman dokumen maksimum, dan skop topik dalam templat prompt penyelidikan Anda. "Teliti 6 bulan terakhir aktiviti persaingan dari Pesaing X, menggunakan 10 sumber paling relevan teratas" menghasilkan 85% daripada nilai "teliti semua tentang Pesaing X" pada 20% kos.
Membina model kos sebelum pelancaran
Untuk setiap pelancaran corak, modelkan input ini sebelum kelulusan:
| Input | Dari mana asalnya |
|---|---|
| Purata kiraan token input setiap panggilan | Ukur 20-30 sampel representatif |
| Purata kiraan token output setiap panggilan | Anggarkan dari reka bentuk prompt |
| Isipadu panggilan yang dijangka (bulanan) | Garis dasar isipadu aliran kerja semasa |
| Harga model (setiap 1k token) | Kadar kad harga vendor |
| Kos penyimpanan (embeddings, rakaman, indeks) | Harga penyimpanan vendor |
| Kekerapan dan kos latihan semula | Keputusan seni bina |
Bina tiga senario: konservatif (isipadu semasa), sederhana (2x isipadu semasa pada tahun 1), dan agresif (5x isipadu pada puncak). Jika senario agresif menghasilkan kos yang tidak boleh diterima, reka bentuk kawalan kos sebelum pelancaran, bukan selepas.
Mengapa anggaran pra-pelancaran biasanya terlalu rendah: sampel datang dari kes yang paling mudah dan paling representatif. Pengeluaran merangkumi semua kes tepi, dokumen panjang, pertanyaan kompleks, dan corak penggunaan yang tidak dijangka yang percubaan tapis. Tambahkan penampan 50-100% kepada anggaran pusat Anda.
Pemantauan anomali kos
Terapkan konsep Anomaly Agent kepada data kos AI Anda sendiri. Sediakan papan pemuka kos-setiap-transaksi untuk setiap corak yang dilancarkan. Takrifkan julat kos normal berdasarkan 60 hari pertama data pengeluaran Anda. Tetapkan amaran apabila kos-setiap-transaksi meningkat lebih daripada 30% di atas garis dasar.
Isyarat amaran awal:
- Saiz tetingkap konteks purata meningkat (tanda peluasan skop prompt atau perubahan saiz input)
- Kiraan iterasi setiap tugasan Autonomous Agent meningkat (tanda peluasan kerumitan tugasan atau hanyut model)
- Kekerapan kemas kini indeks meningkat (tanda pertumbuhan pangkalan pengetahuan tanpa pemangkasan)
- Kadar ralat meningkat seiring kos (tanda model bergelut, membawa kepada kos cuba semula)
Apabila corak menjadi terlalu mahal
Rangka kerja keputusan:
Optimumkan dahulu. Pemampatan konteks, caching, penurunan taraf model untuk tugasan lebih mudah, pemprosesan berkumpulan dan bukannya masa nyata. Larian pengoptimuman biasa memulihkan 30-50% kos tanpa impak kualiti.
Kurangkan skop kemudian. Takrifkan kes penggunaan bernilai tertinggi dalam corak dan hadkan pelancaran kepada itu. Meeting Intelligence untuk akaun perusahaan sahaja. Generative Research untuk akaun peringkat 1 sahaja. Ini bukan kegagalan. Ia adalah peruntukan kos yang rasional.
Gantikan dengan corak yang lebih murah jika pengoptimuman dan pengurangan skop tidak berfungsi. Autonomous Agent yang melakukan penghalaan tugasan mungkin boleh digantikan dengan model Scoring and Routing pada 5% kos, jika kerumitan tugasan sebenarnya tidak memerlukan autonomi berbilang langkah. Pemilihan corak sentiasa boleh disemak semula. Artikel keputusan beli berbanding bina mengikut corak menunjukkan di mana penyelesaian vendor mengurangkan kos berbanding binaan tersuai.
Lihat apabila corak AI menjadi hutang teknikal untuk trajektori kos jangka panjang corak yang tidak direka untuk kebolehselenggaraan, dan mengukur ROI corak AI untuk cara menjejaki kos berbanding nilai. Matlamatnya bukan pelancaran yang paling murah. Ia adalah pelancaran bernilai tertinggi pada kos yang boleh ditanggung perniagaan pada skala.
Soalan Lazim
Apakah Peraturan Kos Sebatian Token?
Peraturan Kos Sebatian Token menyatakan bahawa jumlah perbelanjaan AI perusahaan berskala dengan tiga pengganda yang bergabung bersama: bilangan panggilan LLM setiap tugasan pengguna (aliran kerja ejen mencetuskan 10-20 panggilan berbanding 1-2 untuk pertanyaan mudah), saiz tetingkap konteks purata setiap panggilan (seni bina RAG mengembang konteks 3-5x), dan kekerapan latihan semula setiap corak (55% model memerlukan latihan semula dalam 90 hari). Pengurangan harga setiap token tidak mengimbangi isipadu panggilan bergabung. Perbelanjaan AI perusahaan meningkat 320% sementara harga setiap token jatuh 280x tepat kerana pengganda ini.
Mengapa kos percubaan AI kelihatan begitu berbeza daripada kos pengeluaran?
Percubaan menapis semua kes tepi, dokumen panjang, pertanyaan kompleks, dan corak penggunaan luar biasa yang termasuk dalam pengeluaran. Percubaan yang memproses 500 dokumen representatif pada kerumitan purata terlepas 15% dokumen pengeluaran yang panjang, bukan standard, atau memerlukan berbilang larian pemprosesan. Tambahkan penampan 50-100% kepada anggaran kos percubaan Anda untuk perancangan pengeluaran. Untuk Autonomous Agent khususnya, tambahkan juga penampan kiraan iterasi.
Apakah kawalan kos paling berkesan tunggal untuk Autonomous Agent?
Had iterasi keras (maksimum panggilan LLM setiap tugasan) dan had bajet token setiap tugasan. Autonomous Agent tanpa kawalan kewangan ini adalah komitmen kos terbuka. Analisis Gartner menunjukkan ejen memerlukan 5-30x lebih banyak token setiap tugasan daripada chatbot standard, dengan tugasan kompleks mencapai hujung atas julat itu. Menetapkan maksimum 10 panggilan setiap tugasan dan penyerahan automatik kepada ejen manusia apabila had dicapai bukan kemudahan operasional. Ia adalah kawalan kewangan.
Bagaimana skop pelancaran Meeting Intelligence mempengaruhi kos?
Melancarkan Meeting Intelligence untuk semua mesyuarat dan bukannya mesyuarat berhadapan pelanggan sahaja biasanya menambah 60-70% kepada kos transkripsi dan pemprosesan tanpa sebarang nilai CRM tambahan. Mesyuarat dalaman (mesyuarat singkat, perancangan, semua tangan) tidak menghasilkan data perjanjian yang berguna tetapi masih menanggung kos transkripsi setiap minit dan kos rumusan setiap panggilan. Mengeskopkan kepada panggilan luaran sahaja sebelum pelancaran adalah pengoptimuman kos paling mudah tunggal dalam corak Meeting Intelligence.
Bilakah organisasi perlu memilih model yang lebih murah berbanding model yang lebih baik?
Apabila kerumitan pertanyaan tidak memerlukan keupayaan model yang lebih baik. Penghalaan model, mengarahkan permintaan lebih mudah kepada model yang lebih murah dan permintaan kompleks kepada model premium, mengurangkan kos AI perusahaan sebanyak 30-50% tanpa kehilangan kualiti pada tugasan mudah. Untuk Workflow Copilot, cadangan konteks pendek (semakan nada e-mel, pelengkapan medan mudah) boleh dijalankan pada model yang lebih kecil pada sebahagian kecil kos inferens kelas GPT-4 konteks penuh. Bina penghalaan model ke dalam seni bina sebelum pelancaran, bukan sebagai pembaikan penjimatan kos.
Trend kos apa yang perlu disediakan perusahaan menjelang 2030?
Gartner meramalkan kos inferens akan jatuh melebihi 90% menjelang 2030. Tetapi harga semasa disubsidi oleh modal teroka dan subsidi silang hyperscaler, mewujudkan lantai yang rendah secara buatan yang mungkin menormalkan ke atas sebelum penurunan jangka panjang disambung semula. Organisasi yang membina model kos untuk tempoh masa 3+ tahun perlu merancang untuk tempoh volatiliti harga dan bukannya menganggap penurunan kos secara linear. Pertumbuhan isipadu dari penggunaan ejen juga memampatkan margin penyedia, yang mungkin sebahagiannya mengimbangi pengurangan kos inferens mentah.
Ketahui lebih lanjut

Co-Founder, Rework.com
On this page
- Mengapa keluk kos AI berbeza daripada keluk kos perisian
- Pemacu kos mengikut corak
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: risiko kos tertinggi
- Peraturan Kos Sebatian Token
- Empat senario kos berlebihan paling biasa
- Membina model kos sebelum pelancaran
- Pemantauan anomali kos
- Apabila corak menjadi terlalu mahal
- Ketahui lebih lanjut