Cuando los Patrones de AI Se Vuelven Costosos a Escala

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
El piloto parecía asequible. Procesó 500 documentos, ejecutó el sistema durante 60 días y gastó $400. Finanzas aprobó el despliegue completo. Seis meses después, está procesando 50.000 documentos y la factura es de $40.000. No $4.000. No $8.000. $40.000, porque la complejidad de los documentos aumentó, agregó un segundo paso de LLM para verificación de calidad y el índice de embeddings necesitó una reconstrucción cuando añadió nuevos tipos de documentos.
Los excesos de costos de AI a escala son casi siempre predecibles en retrospectiva. El modelo de precios por inferencia, el comportamiento de escala de tokens con el tamaño del documento, los costos de almacenamiento para embeddings: nada de esto está oculto. Simplemente no se modela con cuidado antes del despliegue porque los pilotos funcionan a bajo volumen y los costos son invisibles a bajo volumen.
Este artículo hace que las sorpresas de costos sean predecibles con anticipación, patrón por patrón.
Por qué las curvas de costos de AI difieren de las del software
El costo del software tradicional es en su mayoría fijo: tarifa de licencia, costo de implementación y un incremento relativamente plano por usuario. Se paga por asientos, no por uso. El modelo de costos es predecible y se concentra al principio.
El costo de los patrones de AI es basado en consumo de maneras que interactúan con el volumen de datos, la complejidad de los documentos y los patrones de consulta. El análisis de McKinsey sobre la nueva economía de la tecnología empresarial en un mundo de AI documenta este cambio: el 79% del gasto en TI es ahora gasto operativo en lugar de gasto de capital, y el uso de LLM basado en tokens es un factor clave de la complejidad de FinOps. Cuatro dinámicas que el software no tiene:
Precios por inferencia. Cada llamada al modelo cuesta tokens. El costo de los tokens escala con la longitud de entrada y salida. Un documento de 10 páginas cuesta aproximadamente 10 veces más de procesar que uno de 1 página. A bajo volumen, esto es invisible. A alto volumen, es su línea de costo más grande.
Costos de almacenamiento para embeddings e índices. Los sistemas de RAG Assistant almacenan vector embeddings para cada documento indexado. El almacenamiento vectorial tiene costos por dimensión y por registro. Una base de conocimiento con 100.000 documentos a 1.536 dimensiones por embedding requiere un almacenamiento significativo, y re-hacer los embeddings cuando actualiza documentos es un evento de cómputo, no solo una actualización de almacenamiento.
Costos de reentrenamiento que aumentan con la complejidad del negocio. Los modelos de Scoring, las líneas de referencia de anomalías y los motores de recomendaciones necesitan reentrenamiento periódico a medida que cambian sus datos. Los ciclos de reentrenamiento tempranos son baratos porque tiene relativamente pocos datos. Los ciclos de reentrenamiento posteriores son más costosos porque tiene más datos y patrones más complejos que aprender.
Comportamiento de costos no lineal en entradas complejas. Un contrato de 50 páginas cuesta aproximadamente 50 veces más de procesar por paso de LLM que uno de 1 página. Una reunión con 8 participantes cuesta más de atribuir y resumir que una llamada de 2 personas. El costo por unidad en el extremo inferior de la distribución de complejidad se ve mucho mejor que el costo promedio a volumen de producción.
Key Facts: Costo de AI a Escala
- Los modelos de AI agéntica requieren entre 5 y 30 veces más tokens por tarea que un chatbot de AI generativa estándar. Un agente autónomo que razona iterativamente y llama herramientas puede activar 10-20 llamadas a LLM por tarea de usuario único. (Gartner, marzo de 2026)
- Los precios de tokens han bajado 280 veces en dos años, pero el gasto total de AI empresarial ha aumentado un 320% en el mismo período, impulsado por el cambio a flujos de trabajo agénticos y arquitecturas RAG que inflan las ventanas de contexto entre 3-5 veces. (Oplexa Inference Cost Crisis Analysis, 2026)
- El 55% de los modelos de ML en producción requieren reentrenamiento dentro de los 90 días, agregando costos de reentrenamiento al presupuesto de despliegue inicial que la mayoría de los equipos nunca modela en su aprobación del primer año. (DataRobot, 2025)
Factores de costo por patrón
RAG Assistant
Factor de costo principal: tamaño de la ventana de contexto durante la recuperación y generación.
Una consulta RAG simple recupera 3-5 fragmentos de documentos y los usa como contexto para una respuesta. Si cada fragmento tiene 500 tokens, su ventana de contexto para la generación es de 1.500-2.500 tokens más la pregunta. A $0,01/1k tokens para un modelo de nivel medio, eso es aproximadamente $0,02-0,03 por consulta.
Con 10.000 consultas/mes: $200-300. Manejable.
Pero a alto volumen de consultas con preguntas complejas, los sistemas RAG a menudo recuperan más fragmentos (mejor precisión requiere más contexto) y usan ventanas de contexto más largas. Una pregunta de política compleja puede recuperar 10 fragmentos de 1.000 tokens cada uno: $0,10-0,15 por consulta. Con 50.000 consultas/mes, eso son $5.000-7.500/mes solo en costos de consulta, antes del almacenamiento.
El costo de actualización del índice es la segunda sorpresa. Si su base de conocimiento tiene 500.000 documentos y actualiza el 10% mensualmente, eso son 50.000 re-embeddings por mes. A $0,0001 por embedding (precio de text-embedding-3-small), eso es $5/mes. Con text-embedding-3-large: $0,13 por 1k tokens, documento promedio de 500 palabras (~667 tokens) = $0,087 por documento. 50.000 re-embeddings = $4.350/mes solo para mantenimiento del índice.
Scoring + Routing
El costo por inferencia es bajo. Los modelos de Scoring típicamente son más pequeños, más rápidos y más baratos que los modelos generativos. El principal riesgo de costos es la frecuencia de reentrenamiento y la infraestructura de datos.
Un modelo de Scoring que necesita reentrenamiento trimestral requiere: extracción y limpieza de datos, cómputo de ingeniería de atributos, cómputo de entrenamiento del modelo, evaluación y despliegue. Para un modelo interno, esto es tiempo de ingeniería. Para un modelo gestionado por el proveedor, típicamente es una tarifa de servicio. El costo está acotado y es predecible, pero los equipos a menudo no lo presupuestan en el año 2 porque no fue parte del costo de despliegue inicial.
Vision Extract
El costo de procesamiento por página escala exactamente de forma lineal con el volumen de documentos. Esto es predecible. El modelo de costos es honesto. Pero "procesaremos 200 documentos al mes" en el piloto frecuentemente se convierte en "necesitamos cargar 2 años de facturas históricas" (un pico de procesamiento único) más "todas las nuevas facturas más todos los documentos históricos que ahora estamos reprocesando para mejorar la precisión."
El procesamiento de imágenes de alta resolución cuesta más que el de baja resolución. Si su proveedor cobra según el tiempo de cómputo por imagen y actualiza su equipo de escaneo, su costo por documento aumenta incluso al mismo volumen de documentos.
Meeting Intelligence
Dos factores de costo que ambos escalan con el volumen de uso:
Costo de transcripción. Las APIs de voz a texto típicamente tienen precios por minuto de audio. La transcripción de clase Whisper va de $0,006 a $0,024/minuto según el nivel de servicio. Una llamada de ventas de 60 minutos: $0,36-$1,44. Con 500 llamadas/mes: $180-$720 solo en transcripción. Con 5.000 llamadas/mes (escala empresarial): $1.800-$7.200/mes.
Costo de resumen por LLM. Las llamadas largas producen transcripciones largas. Una transcripción de una llamada de 60 minutos tiene aproximadamente 8.000-12.000 palabras (6.000-9.000 tokens). Procesar eso para resumen, acciones a tomar y extracción de campos del CRM a $0,01/1k tokens de entrada + $0,03/1k tokens de salida: aproximadamente $0,12-0,18 por llamada. Con 5.000 llamadas/mes: $600-$900/mes.
La sorpresa de costos ocurre cuando los equipos despliegan Meeting Intelligence para todas las reuniones, no solo las de cara al cliente. Los standups internos, las reuniones de planificación y las reuniones generales no producen datos útiles del CRM, pero siguen acumulando costos de transcripción y procesamiento. Una política de alcance simple (Meeting Intelligence solo para llamadas externas) a menudo reduce los costos entre un 60-70% sin reducir el valor.
Anomaly Agent
El costo de ingesta de flujos a alto volumen de datos es el principal riesgo. Si su Anomaly Agent monitorea flujos de transacciones a 1 millón de eventos/día, los costos de almacenamiento y procesamiento son significativos antes de agregar cualquier llamada a LLM.
Para la detección de anomalías puramente estadística (sin LLM), los costos son manejables y escalan de manera predecible. El riesgo de costos entra cuando el Anomaly Agent usa llamadas a LLM para enriquecimiento de contexto ("explique en lenguaje natural por qué esta transacción es anómala") o para correlación compleja de múltiples señales. A alto volumen de alertas, esas llamadas a LLM se acumulan.
Generative Research
Los tokens de LLM para síntesis escalan con la longitud del material fuente. Un informe de investigación que extrae 20 documentos fuente, cada uno de 3.000 palabras, presenta aproximadamente 60.000 palabras de contexto antes de que el modelo genere algo. A los precios de gpt-4, eso son $1,80-$2,40 solo en tokens de entrada por tarea de investigación. La generación de salida agrega otros $0,30-0,60. Por tarea de investigación: $2-3.
Esto suena bajo. Pero si su equipo de operaciones de investigación genera 100 informes/mes, eso son $200-300/mes solo en costos de API, antes de los costos de infraestructura de gestión del Pipeline de investigación. A 1.000 informes/mes: $2.000-3.000/mes. Para una operación de consultoría grande que realiza más de 5.000 tareas de investigación/mes, los costos de LLM solos se acercan a $15.000-20.000/mes.
El mecanismo de control de costos: limitación del alcance. La investigación que sintetiza 5 documentos dirigidos cuesta un 75% menos que la investigación que lee todo lo que puede encontrar. Los prompts de investigación con límites explícitos de fuentes ("use las 10 fuentes más relevantes") producen una calidad comparable a las fuentes ilimitadas a una fracción del costo.
Document Review
La longitud del contrato es el principal factor de costo. Revisar un NDA de 5 páginas cuesta mucho menos que revisar un acuerdo de software empresarial de 150 páginas con 40 anexos. Si su mix de documentos cambia de contratos cortos (startups en etapa temprana) a acuerdos empresariales complejos (etapa de crecimiento), su costo por documento aumenta sustancialmente sin ningún cambio en el volumen.
El segundo riesgo: múltiples pasadas de revisión. Los equipos conscientes de la calidad a menudo ejecutan una pasada de extracción inicial, luego una pasada de comparación de cláusulas, luego una pasada de generación de resumen. Cada pasada multiplica el costo base del documento. Un Pipeline de revisión de 3 pasadas cuesta 3 veces más que uno de 1 pasada. Defina sus pasadas requeridas con anticipación y presupueste para ellas.
Workflow Copilot
La gestión de la ventana de contexto es el principal mecanismo de control de costos. Un Workflow Copilot que extrae el historial completo del registro del CRM, los últimos 10 hilos de correo, los documentos de cuenta relevantes y el contexto de la tarea actual en cada llamada de sugerencia es costoso. Cada llamada de sugerencia puede usar de 8.000 a 15.000 tokens de contexto incluso para un borrador de correo simple.
Con 20 solicitudes de sugerencia/usuario/día × 50 usuarios = 1.000 llamadas/día. A $0,15/llamada (promedio entre contexto y salida): $150/día, $4.500/mes. Con 200 usuarios: $18.000/mes.
La compresión de contexto (resumir el contexto histórico en lugar de incluir registros sin procesar), el enrutamiento de consultas (las solicitudes más simples van a modelos más baratos) y el almacenamiento en caché de sugerencias (solicitudes similares reutilizan respuestas anteriores) pueden reducir este costo entre un 50-70% sin pérdida significativa de calidad.
Personalization Engine
El riesgo de costo aquí es la inferencia en tiempo real a escala. Servir recomendaciones personalizadas requiere una llamada al modelo (o búsqueda de similitud vectorial) para cada interacción del usuario. Con 100.000 usuarios activos diarios que toman 10 decisiones relevantes de personalización cada uno: 1 millón de llamadas de inferencia por día.
Si cada llamada usa un modelo dedicado pequeño a $0,001/llamada: $1.000/día, $30.000/mes. Si actualiza a un LLM de mayor calidad para mejores recomendaciones: los costos se multiplican 10-20 veces. La decisión de ingeniería entre la calidad del modelo y el costo de inferencia es la decisión de arquitectura de costos más importante para este patrón.
El almacenamiento en caché reduce los costos sustancialmente: si el 40% de los usuarios tienen perfiles suficientemente similares como para que se puedan servir recomendaciones en caché, elimina el 40% de las llamadas de inferencia.
Autonomous Agent: el mayor riesgo de costos
Este es el patrón más probable de producir eventos presupuestarios inesperados. Nómbrelo claramente: un Autonomous Agent sin límites de iteración fijos y caps de presupuesto por tarea es una responsabilidad, no una herramienta.
Esto es lo que ocurre cuando sale mal:
Un Autonomous Agent de soporte al cliente en producción recibe una tarea: "Resolver el ticket #48291: el cliente dice que se le cobró dos veces." El agente comienza su bucle. Lee el ticket (1 llamada). Extrae el historial de pagos (1 llamada). Encuentra una ambigüedad y busca tickets relacionados (2 llamadas). Redacta una respuesta (1 llamada). Determina que necesita aprobación del manager y busca la política de escalada (1 llamada). Encuentra la política poco clara y lee el documento de política completo (1 llamada). Decide que necesita verificar 3 meses de historial de transacciones (3 llamadas). Compara las transacciones y genera un análisis (2 llamadas). En este punto: 12 llamadas al modelo para un ticket de soporte.
Pero el agente también encontró una rama inesperada: el cliente tenía una queja relacionada de hace 6 meses que parecía relevante. El agente extrajo ese hilo. 4 llamadas más. Luego decidió que el historial de cuenta del cliente era relevante. 3 llamadas más. Luego redactó dos opciones de resolución, revisó cada una basándose en la política de la empresa y formateó la respuesta final. 6 llamadas más.
Total: 25 llamadas al modelo para un ticket de soporte, a $0,05-0,15 por llamada = $1,25-3,75 por resolución de ticket, versus el costo de $0,10-0,20 que presupuestó basándose en su piloto con tickets simples.
Con 10.000 tickets complejos/mes, el costo real es de $12.500-37.500/mes versus un presupuesto de $1.000-2.000/mes. Esto ocurre.
El requisito de control de costos: límites de iteración fijos (máximo 10 llamadas al modelo por tarea), presupuestos de tokens por tarea y traspaso automático al agente humano cuando se alcanzan los límites. Estos no son conveniencias operativas. Son controles financieros.
"Un Autonomous Agent sin límites de iteración fijos no es una herramienta de productividad. Es una responsabilidad financiera. El análisis de Gartner de marzo de 2026 confirma que los modelos agénticos requieren 5-30 veces más tokens por tarea que los chatbots estándar. Un agente que alcanza el extremo superior de ese rango en tickets de soporte complejos cuesta $3-4 por resolución a los precios de tokens empresariales, versus un presupuesto de $0,10-0,20." (Rework Autonomous Agent Cost Analysis, 2026)
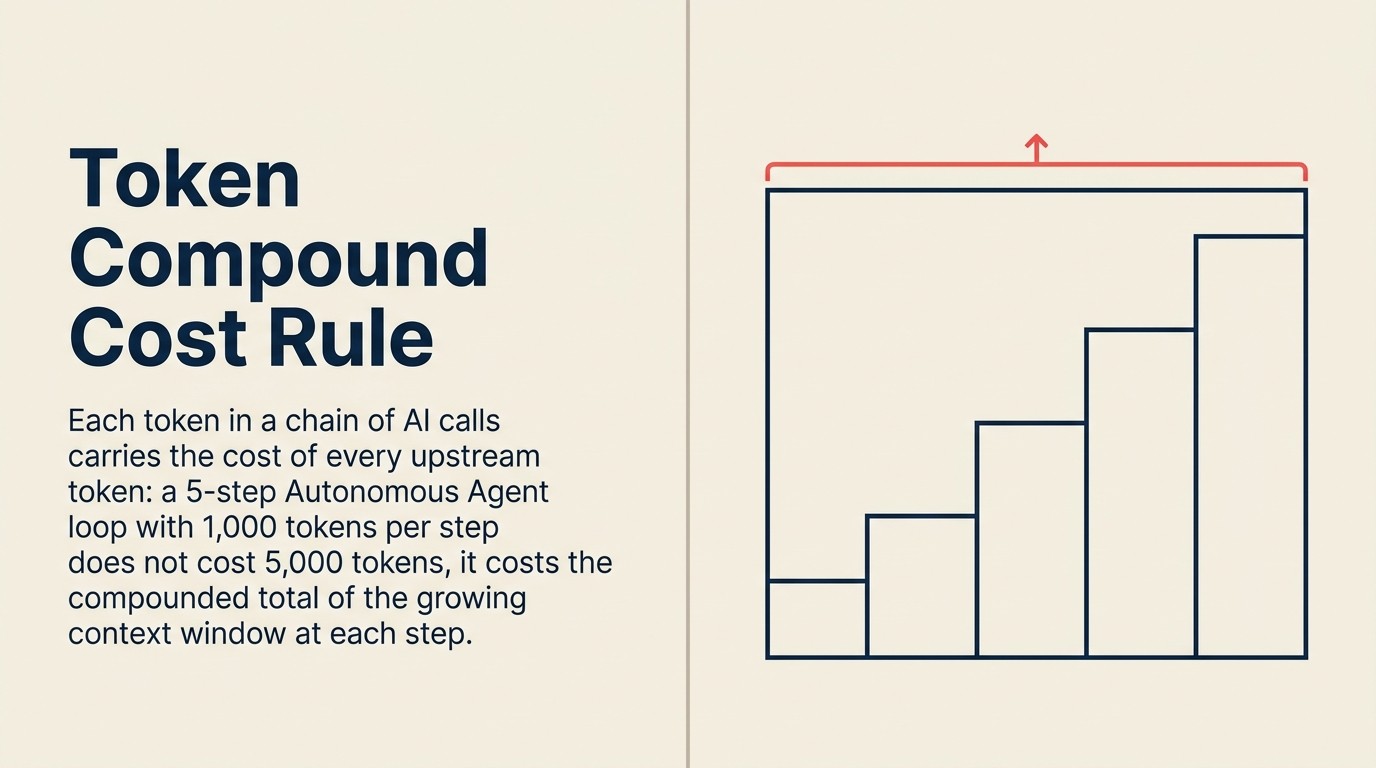
La Regla del Costo Compuesto de Tokens
La Regla del Costo Compuesto de Tokens establece que el gasto total de AI empresarial escala con el número de llamadas a LLM por tarea de usuario, el tamaño promedio de la ventana de contexto por llamada y la frecuencia de reentrenamiento por patrón, no con el precio por token. Esto explica por qué el gasto total de AI empresarial ha subido un 320% mientras que los precios individuales de tokens cayeron 280 veces: el cambio a flujos de trabajo agénticos (10-20 llamadas por tarea), arquitecturas RAG (inflación de ventana de contexto de 3-5 veces) y agentes de monitoreo siempre activos crea un volumen de llamadas compuesto que supera las reducciones de precio por token. La implicación práctica de la Regla es que el control de costos a escala requiere limitar las llamadas por tarea, almacenar en caché el contexto repetido y limitar el despliegue a los flujos de trabajo de mayor valor, no esperar a que los precios de tokens bajen más.
Rework Analysis: Basándose en el hallazgo de Gartner de que los modelos agénticos requieren 5-30 veces más tokens por tarea y el hallazgo de Oplexa de que el gasto de AI empresarial subió un 320% a pesar de la caída de los precios de tokens en 280 veces, la Regla del Costo Compuesto de Tokens identifica tres multiplicadores de costos que los presupuestos piloto sistemáticamente pasan por alto: la acumulación de volumen de llamadas de los bucles autónomos, la inflación de la ventana de contexto de RAG y la recuperación del historial, y los costos de frecuencia de reentrenamiento que escalan con la complejidad de los datos. Los datos de implementación de Rework muestran que los equipos que modelan los tres multiplicadores antes de la aprobación del despliegue tienen excesos de costos de producción promedio del 23%. Los equipos que solo modelan el precio por token tienen excesos promedio del 287%.
Los cuatro escenarios de exceso de costos más comunes
Escenario 1: El índice de embeddings que crece sin poda. Se despliega un sistema RAG con una base de conocimiento limpia de 10.000 documentos. Nadie elimina documentos antiguos cuando las políticas se actualizan o los productos se descontinúan. Dos años después, el índice tiene 80.000 documentos (la mayoría desactualizados), la calidad de recuperación está declinando a medida que el modelo recupera contenido obsoleto y re-indexar para solucionarlo cuesta más que el despliegue original. Presupueste el mantenimiento del índice desde el primer día. Esto es también cómo los sistemas RAG se convierten en deuda técnica. Consulte cuando los patrones de AI se convierten en deuda técnica para la trayectoria de costos completa.
Escenario 2: Autonomous Agent sin límites de iteración. Descrito anteriormente. Este es un riesgo finito con una solución completa: caps de presupuesto y límites de iteración, definidos antes del despliegue. Cualquier propuesta de despliegue de Autonomous Agent que no incluya estos como requisitos no negociables debe enviarse de vuelta. El análisis de Andreessen Horowitz sobre LLMflation y la economía de la inferencia muestra que aunque los costos por token están cayendo 10 veces por año, el gasto total de inferencia empresarial está aumentando porque el uso crece más rápido que los precios bajan. Esa dinámica hace que los límites de iteración sean críticos independientemente de cuán baratos sean los tokens individuales.
Escenario 3: Meeting Intelligence procesando cada reunión interna. El exceso de costos más fácil de evitar. El 70% de las reuniones en la mayoría de las organizaciones son internas. Meeting Intelligence proporciona cero valor de CRM para las reuniones internas. Limite el despliegue a las llamadas de cara al cliente solo antes del lanzamiento, no después de recibir la factura.
Escenario 4: Generative Research con un alcance demasiado amplio. Los prompts de investigación que dicen "investigue todo lo relevante para X" producen resultados completos pero costos completos. Defina recuentos máximos de fuentes, profundidad máxima de documentos y alcance de temas en sus plantillas de prompts de investigación. "Investigue los últimos 6 meses de actividad competitiva del Competidor X, usando las 10 fuentes más relevantes" produce el 85% del valor de "investigue todo sobre el Competidor X" al 20% del costo.
Construir un modelo de costos antes del despliegue
Para cada despliegue de patrón, modele estas entradas antes de la aprobación:
| Entrada | De dónde proviene |
|---|---|
| Recuento promedio de tokens de entrada por llamada | Mida 20-30 muestras representativas |
| Recuento promedio de tokens de salida por llamada | Estime a partir del diseño del prompt |
| Volumen esperado de llamadas (mensual) | Referencia del volumen actual del flujo de trabajo |
| Precios del modelo (por 1k tokens) | Lista de tarifas del proveedor |
| Costos de almacenamiento (embeddings, grabaciones, índices) | Precios de almacenamiento del proveedor |
| Frecuencia y costo de reentrenamiento | Decisión de arquitectura |
Construya tres escenarios: conservador (volumen actual), moderado (2 veces el volumen actual en el año 1) y agresivo (5 veces el volumen en el pico). Si el escenario agresivo produce un costo inaceptable, diseñe los controles de costos antes del despliegue, no después.
Por qué las estimaciones previas al despliegue suelen ser demasiado bajas: las muestras provienen de los casos más fáciles y representativos. La producción incluye todos los casos límite, los documentos largos, las consultas complejas y los patrones de uso inesperados que los pilotos filtran. Agregue un buffer del 50-100% a su estimación central.
Monitoreo para anomalías de costos
Aplique el concepto del Anomaly Agent a sus propios datos de costos de AI. Configure dashboards de costo por transacción para cada patrón desplegado. Defina rangos de costo normal basados en sus primeros 60 días de datos de producción. Configure alertas cuando el costo por transacción suba más de un 30% sobre la referencia.
Señales de advertencia temprana:
- Tamaño promedio de ventana de contexto en aumento (señal de expansión del alcance del prompt o cambios en el tamaño de entrada)
- Recuento de iteraciones por tarea del Autonomous Agent en aumento (señal de aumento de la complejidad de las tareas o deriva del modelo)
- Frecuencia de actualización del índice en aumento (señal de crecimiento de la base de conocimiento sin poda)
- Tasas de error en aumento junto con los costos (señal de que el modelo está teniendo dificultades, generando costos de reintento)
Cuando un patrón se vuelve prohibitivamente costoso
El marco de decisión:
Optimizar primero. Compresión de contexto, almacenamiento en caché, degradación del modelo para tareas más simples, procesamiento por lotes en lugar de en tiempo real. Una pasada de optimización típica recupera entre el 30-50% del costo sin impacto en la calidad.
Reducir el alcance en segundo lugar. Defina los casos de uso de mayor valor dentro del patrón y restrinja el despliegue a esos. Meeting Intelligence solo para cuentas empresariales. Generative Research solo para cuentas de nivel 1. Esto no es un fracaso. Es una asignación racional de costos.
Reemplazar con un patrón menos costoso si la optimización y la reducción del alcance no funcionan. Un Autonomous Agent que realiza enrutamiento de tareas puede ser reemplazable por un modelo de Scoring and Routing al 5% del costo, si la complejidad de la tarea en realidad no requiere autonomía de múltiples pasos. La selección de patrones siempre es revisable. El artículo sobre la decisión de comprar vs. construir por patrón muestra dónde las soluciones de proveedores reducen los costos en comparación con las construcciones personalizadas.
Consulte cuando los patrones de AI se convierten en deuda técnica para la trayectoria de costos a largo plazo de los patrones que no fueron diseñados para la mantenibilidad, y medición del ROI por patrón de AI para rastrear los costos en relación con el valor. El objetivo no es el despliegue más barato. Es el despliegue de mayor valor a un costo que el negocio pueda sostener a escala.
Preguntas Frecuentes
¿Qué es la Regla del Costo Compuesto de Tokens?
La Regla del Costo Compuesto de Tokens establece que el gasto total de AI empresarial escala con tres multiplicadores que se acumulan juntos: el número de llamadas a LLM por tarea de usuario (los flujos de trabajo agénticos activan 10-20 llamadas versus 1-2 para consultas simples), el tamaño promedio de la ventana de contexto por llamada (las arquitecturas RAG inflan el contexto 3-5 veces) y la frecuencia de reentrenamiento por patrón (el 55% de los modelos necesitan reentrenamiento en 90 días). Las reducciones en el precio por token no compensan el volumen de llamadas acumulado. El gasto de AI empresarial subió un 320% mientras que los precios por token cayeron 280 veces precisamente por estos multiplicadores.
¿Por qué los costos del piloto de AI se ven tan diferentes de los costos de producción?
Los pilotos filtran todos los casos límite, los documentos largos, las consultas complejas y los patrones de uso inusuales que incluye la producción. Un piloto que procesa 500 documentos representativos de complejidad promedio pasa por alto el 15% de los documentos de producción que son largos, no estándar o requieren múltiples pasadas de procesamiento. Agregue un buffer del 50-100% a su estimación de costos del piloto para la planificación de producción. Para los Autonomous Agents específicamente, agregue también un buffer de recuento de iteraciones.
¿Cuál es el control de costos de mayor impacto para los Autonomous Agents?
Los límites de iteración fijos (máximo de llamadas a LLM por tarea) y los caps de presupuesto de tokens por tarea. Un Autonomous Agent sin estos controles financieros es un compromiso de costo de extremo abierto. El análisis de Gartner muestra que los agentes requieren 5-30 veces más tokens por tarea que los chatbots estándar, con las tareas complejas alcanzando el extremo alto de ese rango. Establecer un máximo de 10 llamadas por tarea y el traspaso automático a agentes humanos cuando se alcanzan los límites no es una conveniencia operativa. Es un control financiero.
¿Cómo afecta el alcance del despliegue de Meeting Intelligence a los costos?
Desplegar Meeting Intelligence para todas las reuniones en lugar de solo las de cara al cliente típicamente agrega entre un 60-70% a los costos de transcripción y procesamiento sin valor adicional del CRM. Las reuniones internas (standups, planificación, reuniones generales) no producen datos útiles de deals pero siguen acumulando costos por minuto de transcripción y costos de resumen por llamada. Limitar el alcance a las llamadas externas antes del lanzamiento es la optimización de costos más fácil en el patrón Meeting Intelligence.
¿Cuándo debería una organización elegir un modelo más barato sobre un mejor modelo?
Cuando la complejidad de las consultas no requiere las capacidades del mejor modelo. El enrutamiento de modelos, dirigir las solicitudes más simples a modelos más baratos y las complejas a modelos premium, reduce los costos de AI empresarial entre un 30-50% sin pérdida de calidad en las tareas simples. Para el Workflow Copilot, las sugerencias de contexto corto (verificación de tono del correo, completado simple de campos) pueden ejecutarse en modelos más pequeños a una fracción del costo de la inferencia de clase GPT-4 de contexto completo. Incorpore el enrutamiento de modelos en la arquitectura antes del despliegue, no como una retroalimentación para reducir costos.
¿Qué tendencia de costos deben preparar las empresas hasta 2030?
Gartner predice que los costos de inferencia caerán más del 90% para 2030. Pero los precios actuales están subsidiados por capital de riesgo y subsidios cruzados de hiperescaladores, creando un suelo artificialmente bajo que puede normalizarse al alza antes de que se reanude el declive a largo plazo. Las organizaciones que construyen modelos de costos para horizontes de tiempo de 3 o más años deben planificar un período de volatilidad de precios en lugar de asumir un declive lineal de costos. El crecimiento de volumen de la adopción agéntica también está comprimiendo los márgenes de los proveedores, lo que puede compensar parcialmente las reducciones de costos de inferencia pura.
Más información

Co-Founder, Rework.com
On this page
- Por qué las curvas de costos de AI difieren de las del software
- Factores de costo por patrón
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: el mayor riesgo de costos
- La Regla del Costo Compuesto de Tokens
- Los cuatro escenarios de exceso de costos más comunes
- Construir un modelo de costos antes del despliegue
- Monitoreo para anomalías de costos
- Cuando un patrón se vuelve prohibitivamente costoso
- Más información