Quando os Padrões de AI Ficam Caros em Escala

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
O piloto parecia acessível. Você processou 500 documentos, executou o sistema por 60 dias e gastou 400 dólares. O financeiro aprovou o rollout completo. Seis meses depois, você está processando 50.000 documentos e a conta é de 40.000 dólares. Não 4.000 dólares. Não 8.000 dólares. 40.000 dólares, porque a complexidade dos documentos aumentou, você adicionou uma segunda passagem de LLM para verificação de qualidade e o índice de embeddings precisou de uma reconstrução quando você adicionou novos tipos de documento.
Os excessos de custo de AI em escala são quase sempre previsíveis em retrospecto. O modelo de precificação por inferência, o comportamento de escala de tokens com o tamanho do documento, os custos de armazenamento para embeddings: nada disso está oculto. Simplesmente não é modelado com cuidado antes da implantação porque os pilotos rodam com baixo volume e o custo é invisível com baixo volume.
Este artigo torna as surpresas de custo previsíveis com antecedência, padrão por padrão.
Por que as curvas de custo de AI diferem das curvas de custo de software
O custo de software tradicional é principalmente fixo: taxa de licença, custo de implementação e um incremento por usuário relativamente plano. Você paga por assentos, não por uso. O modelo de custo é previsível e concentrado no início.
O custo de padrão de AI é baseado em consumo de maneiras que interagem com seu volume de dados, complexidade de documentos e padrões de consulta. A análise da McKinsey sobre a nova economia da tecnologia empresarial em um mundo com AI documenta essa mudança: 79% dos gastos de TI agora são despesas operacionais em vez de despesas de capital, e o uso de LLM baseado em tokens é um driver-chave da complexidade de FinOps. Quatro dinâmicas que o software não tem:
Precificação por inferência. Cada chamada de modelo custa tokens. O custo de tokens escala com o comprimento de input e o comprimento de output. Um documento de 10 páginas custa aproximadamente 10 vezes mais para processar do que um documento de 1 página. Com baixo volume, isso é invisível. Com alto volume, é o seu maior item de linha.
Custos de armazenamento para embeddings e índices. Os sistemas RAG Assistant armazenam embeddings vetoriais para cada documento indexado. O armazenamento vetorial tem custos por dimensão e por registro. Uma base de conhecimento com 100.000 documentos a 1.536 dimensões por embedding requer armazenamento significativo, e o re-embedding quando você atualiza documentos é um evento de computação, não apenas uma atualização de armazenamento.
Custos de retreinamento que aumentam com a complexidade do negócio. Modelos de pontuação, baselines de anomalia e engines de recomendação precisam de retreinamento periódico conforme seus dados mudam. Os primeiros ciclos de retreinamento são baratos porque você tem relativamente poucos dados. Os ciclos de retreinamento posteriores são mais caros porque você tem mais dados e padrões mais complexos para aprender.
Comportamento de custo não linear em inputs complexos. Um contrato de 50 páginas custa aproximadamente 50 vezes mais para processar por passagem de LLM do que um contrato de 1 página. Uma reunião com 8 participantes custa mais para atribuir e resumir do que uma chamada de 2 pessoas. O custo por unidade na extremidade inferior da distribuição de complexidade parece muito melhor do que o custo médio em volume de produção.
Key Facts: Custo de AI em Escala
- Os modelos de AI agêntica requerem entre 5 e 30 vezes mais tokens por tarefa do que um chatbot de AI generativa padrão. Um Autonomous Agent que raciocina iterativamente e chama ferramentas pode disparar de 10 a 20 chamadas de LLM por tarefa de usuário única. (Gartner, março de 2026)
- Os preços de tokens caíram 280 vezes ao longo de dois anos, mas o gasto total com AI empresarial aumentou 320% no mesmo período, impulsionado pela mudança para workflows agênticos e arquiteturas RAG que inflacionam as janelas de contexto em 3 a 5 vezes. (Oplexa Inference Cost Crisis Analysis, 2026)
- 55% dos modelos de ML em produção requerem retreinamento em 90 dias, adicionando custos de retreinamento ao orçamento inicial de implantação que a maioria das equipes nunca modela no primeiro ano de aprovação. (DataRobot, 2025)
Drivers de custo por padrão
RAG Assistant
Driver de custo principal: tamanho da janela de contexto durante a recuperação e geração.
Uma consulta RAG simples recupera de 3 a 5 chunks de documentos e os usa como contexto para uma resposta. Se cada chunk tem 500 tokens, sua janela de contexto para geração é de 1.500 a 2.500 tokens mais a pergunta. A 0,01 dólares por 1k tokens para um modelo de nível médio, isso é cerca de 0,02 a 0,03 dólares por consulta.
Em 10.000 consultas/mês: 200 a 300 dólares. Gerenciável.
Mas com alto volume de consultas e perguntas complexas, os sistemas RAG frequentemente recuperam mais chunks (melhor precisão requer mais contexto) e usam janelas de contexto mais longas. Uma pergunta complexa sobre políticas pode recuperar 10 chunks de 1.000 tokens cada: 0,10 a 0,15 dólares por consulta. Em 50.000 consultas/mês, isso é 5.000 a 7.500 dólares/mês apenas para custos de consulta, antes do armazenamento.
O custo de atualização do índice é a segunda surpresa. Se sua base de conhecimento tem 500.000 documentos e você atualiza 10% mensalmente, isso são 50.000 re-embeddings por mês. A 0,0001 dólares por embedding (preço do text-embedding-3-small), isso é 5 dólares/mês. Com text-embedding-3-large: 0,13 dólares por 1k tokens, documento médio de 500 palavras (aproximadamente 667 tokens) = 0,087 dólares por documento. 50.000 re-embeddings = 4.350 dólares/mês apenas para manutenção do índice.
Scoring + Routing
O custo por inferência é baixo. Os modelos de pontuação são tipicamente menores, mais rápidos e mais baratos do que os modelos generativos. O principal risco de custo é a frequência de retreinamento e a infraestrutura de dados.
Um modelo de pontuação que precisa de retreinamento trimestral requer: extração e limpeza de dados, computação de feature engineering, computação de treinamento do modelo, avaliação e implantação. Para um modelo interno, isso é tempo de engenharia. Para um modelo gerenciado pelo fornecedor, é tipicamente uma taxa de serviço. O custo é limitado e previsível, mas as equipes frequentemente não o incluem no orçamento do ano 2 porque não fazia parte do custo inicial de implantação.
Vision Extract
O custo de processamento por página escala exatamente linearmente com o volume de documentos. Isso é previsível. O modelo de custo é honesto. Mas "vamos processar 200 documentos por mês" no piloto muitas vezes se torna "precisamos preencher 2 anos de faturas históricas" (um pico de processamento único) mais "todas as novas faturas mais todos os documentos históricos que agora estamos reprocessando para melhor precisão."
O processamento de imagens de alta resolução custa mais do que o de baixa resolução. Se seu fornecedor cobra com base no tempo de computação por imagem e você atualiza seu equipamento de digitalização, seu custo por documento aumenta mesmo no mesmo volume de documentos.
Meeting Intelligence
Dois drivers de custo que ambos escalam com o volume de uso:
Custo de transcrição. As APIs de speech-to-text tipicamente cobram por minuto de áudio. A transcrição da classe Whisper custa de 0,006 a 0,024 dólares/minuto dependendo do nível de serviço. Uma chamada de vendas de 60 minutos: 0,36 a 1,44 dólares. Em 500 chamadas/mês: 180 a 720 dólares apenas para transcrição. Em 5.000 chamadas/mês (escala empresarial): 1.800 a 7.200 dólares/mês.
Custo de sumarização por LLM. Chamadas longas produzem transcrições longas. Uma transcrição de chamada de 60 minutos tem aproximadamente 8.000 a 12.000 palavras (6.000 a 9.000 tokens). Processar isso para resumo, itens de ação e extração de campos de CRM a 0,01 dólares/1k tokens de input + 0,03 dólares/1k tokens de output: aproximadamente 0,12 a 0,18 dólares por chamada. Em 5.000 chamadas/mês: 600 a 900 dólares/mês.
A surpresa de custo acontece quando as equipes implantam Meeting Intelligence para todas as reuniões, não apenas as voltadas ao cliente. Standups internos, reuniões de planejamento e reuniões gerais não produzem dados úteis de CRM, mas ainda acumulam custos de transcrição e processamento. Uma política de escopo simples (Meeting Intelligence apenas para chamadas externas) frequentemente reduz o custo em 60 a 70% sem reduzir o valor.
Anomaly Agent
O custo de ingestão de stream com alto volume de dados é o principal risco. Se o seu Anomaly Agent monitora streams de transações a 1 milhão de eventos/dia, os custos de armazenamento e processamento são significativos antes de você adicionar qualquer chamada de LLM.
Para detecção de anomalias puramente estatística (sem LLM), os custos são gerenciáveis e escalam de forma previsível. O risco de custo entra quando o Anomaly Agent usa chamadas de LLM para enriquecimento de contexto ("explique por que esta transação é anômala em linguagem natural") ou para correlação complexa de múltiplos sinais. Com altos volumes de alertas, essas chamadas de LLM se acumulam.
Generative Research
Os tokens de LLM para síntese escalam com o comprimento do material fonte. Um briefing de pesquisa que extrai 20 documentos fonte, cada um com 3.000 palavras, apresenta aproximadamente 60.000 palavras de contexto antes que o modelo gere qualquer coisa. Nos preços do gpt-4, isso é 1,80 a 2,40 dólares em tokens de input apenas por tarefa de pesquisa. A geração de output adiciona mais 0,30 a 0,60 dólares. Por tarefa de pesquisa: 2 a 3 dólares.
Isso parece baixo. Mas se sua equipe de operações de pesquisa gera 100 briefings/mês, isso são 200 a 300 dólares/mês apenas em custos de API, antes dos custos de infraestrutura de gerenciamento do pipeline de pesquisa. Escalando para 1.000 briefings/mês: 2.000 a 3.000 dólares/mês. Para uma grande operação de consultoria fazendo mais de 5.000 tarefas de pesquisa/mês, os custos de LLM sozinhos se aproximam de 15.000 a 20.000 dólares/mês.
O mecanismo de controle de custo: limitação de escopo. A pesquisa que sintetiza 5 documentos direcionados custa 75% menos do que a pesquisa que lê tudo que consegue encontrar. Os prompts de pesquisa com limites explícitos de fontes ("use as 10 fontes mais relevantes") produzem qualidade comparável à de sourcing ilimitado a uma fração do custo.
Document Review
O comprimento do contrato é o driver de custo principal. Revisar um NDA de 5 páginas custa muito menos do que revisar um contrato de software empresarial de 150 páginas com 40 anexos. Se seu mix de documentos muda de contratos curtos (startups em estágio inicial) para acordos empresariais complexos (estágio de crescimento), seu custo por documento aumenta substancialmente sem nenhuma mudança no volume.
O segundo risco: múltiplas passagens de revisão. Equipes rigorosas em qualidade frequentemente executam uma passagem de extração inicial, depois uma passagem de comparação de cláusulas, depois uma passagem de geração de resumo. Cada passagem multiplica o custo base do documento. Um pipeline de revisão de 3 passagens custa 3 vezes o que um pipeline de passagem única custa. Defina suas passagens necessárias antecipadamente e inclua-as no orçamento.
Workflow Copilot
O gerenciamento de janela de contexto é o principal mecanismo de controle de custo. Um Workflow Copilot que extrai o histórico completo do registro de CRM, os últimos 10 threads de e-mail, os documentos de conta relevantes e o contexto da tarefa atual em cada chamada de sugestão é caro. Cada chamada de sugestão pode usar de 8.000 a 15.000 tokens de contexto mesmo para um rascunho de e-mail simples.
Em 20 solicitações de sugestão/usuário/dia x 50 usuários = 1.000 chamadas/dia. A 0,15 dólares/chamada (média entre contexto + output): 150 dólares/dia, 4.500 dólares/mês. Em 200 usuários: 18.000 dólares/mês.
A compressão de contexto (resumindo o contexto histórico em vez de incluir registros brutos), o roteamento de consultas (solicitações mais simples vão para modelos mais baratos) e o caching de sugestões (solicitações similares reutilizam respostas anteriores) podem reduzir esse custo em 50 a 70% sem perda significativa de qualidade.
Personalization Engine
O risco de custo aqui é a inferência em tempo real em escala. Servir recomendações personalizadas requer uma chamada de modelo (ou busca de similaridade vetorial) para cada interação de usuário. Em 100.000 usuários ativos diários fazendo 10 decisões relevantes para personalização cada: 1 milhão de chamadas de inferência por dia.
Se cada chamada usa um modelo dedicado pequeno a 0,001 dólares/chamada: 1.000 dólares/dia, 30.000 dólares/mês. Se você atualizar para um LLM de maior qualidade para melhores recomendações: os custos se multiplicam de 10 a 20 vezes. A decisão de engenharia entre qualidade do modelo e custo de inferência é a decisão de custo-arquitetura mais importante para este padrão.
O caching reduz o custo substancialmente: se 40% dos usuários têm perfis similares o suficiente para que você possa servir recomendações em cache, você elimina 40% das chamadas de inferência.
Autonomous Agent: o maior risco de custo
Este é o padrão com maior probabilidade de produzir eventos de orçamento inesperados. Diga claramente: um Autonomous Agent sem limites rígidos de iteração e caps de orçamento por tarefa é uma responsabilidade, não uma ferramenta.
Veja o que acontece quando dá errado:
Um Autonomous Agent de suporte ao cliente em produção recebe uma tarefa: "Resolver ticket #48291: cliente diz que foi cobrado em duplicidade." O agente inicia seu loop. Ele lê o ticket (1 chamada). Ele extrai o histórico de pagamentos (1 chamada). Ele encontra uma ambiguidade e pesquisa tickets relacionados (2 chamadas). Ele rascunha uma resposta (1 chamada). Ele determina que precisa de aprovação do gerente e pesquisa a política de escalada (1 chamada). Ele acha a política pouco clara e lê o documento de política completo (1 chamada). Ele decide que precisa verificar 3 meses de histórico de transações (3 chamadas). Ele compara as transações e gera uma análise (2 chamadas). Neste ponto: 12 chamadas de modelo para um ticket de suporte.
Mas o agente também atingiu um ramo inesperado: o cliente tinha uma reclamação relacionada de 6 meses atrás que parecia relevante. O agente extraiu esse thread. 4 chamadas a mais. Depois ele decidiu que o histórico de conta do cliente era relevante. 3 chamadas a mais. Depois ele rascunhou duas opções de resolução, revisou cada uma com base na política da empresa e formatou a resposta final. 6 chamadas a mais.
Total: 25 chamadas de modelo para um ticket de suporte, a 0,05 a 0,15 dólares por chamada = 1,25 a 3,75 dólares por resolução de ticket, versus o custo de 0,10 a 0,20 dólares que você orçou com base no seu piloto com tickets simples.
Em 10.000 tickets complexos/mês, o custo real é de 12.500 a 37.500 dólares/mês versus um orçado de 1.000 a 2.000 dólares/mês. Isso acontece.
O requisito de controle de custo: limites rígidos de iteração (máximo de 10 chamadas de modelo por tarefa), budgets de tokens por tarefa e handoff automático para agente humano quando os limites são atingidos. Esses não são conveniências operacionais. São controles financeiros.
"Um Autonomous Agent sem limites rígidos de iteração não é uma ferramenta de produtividade. É uma responsabilidade financeira. A análise da Gartner de março de 2026 confirma que os modelos agênticos requerem 5 a 30 vezes mais tokens por tarefa do que os chatbots padrão. Um agente que atinge a extremidade superior desse intervalo em tickets de suporte complexos custa de 3 a 4 dólares por resolução aos preços de tokens empresariais, versus um orçado de 0,10 a 0,20 dólares." (Rework Autonomous Agent Cost Analysis, 2026)
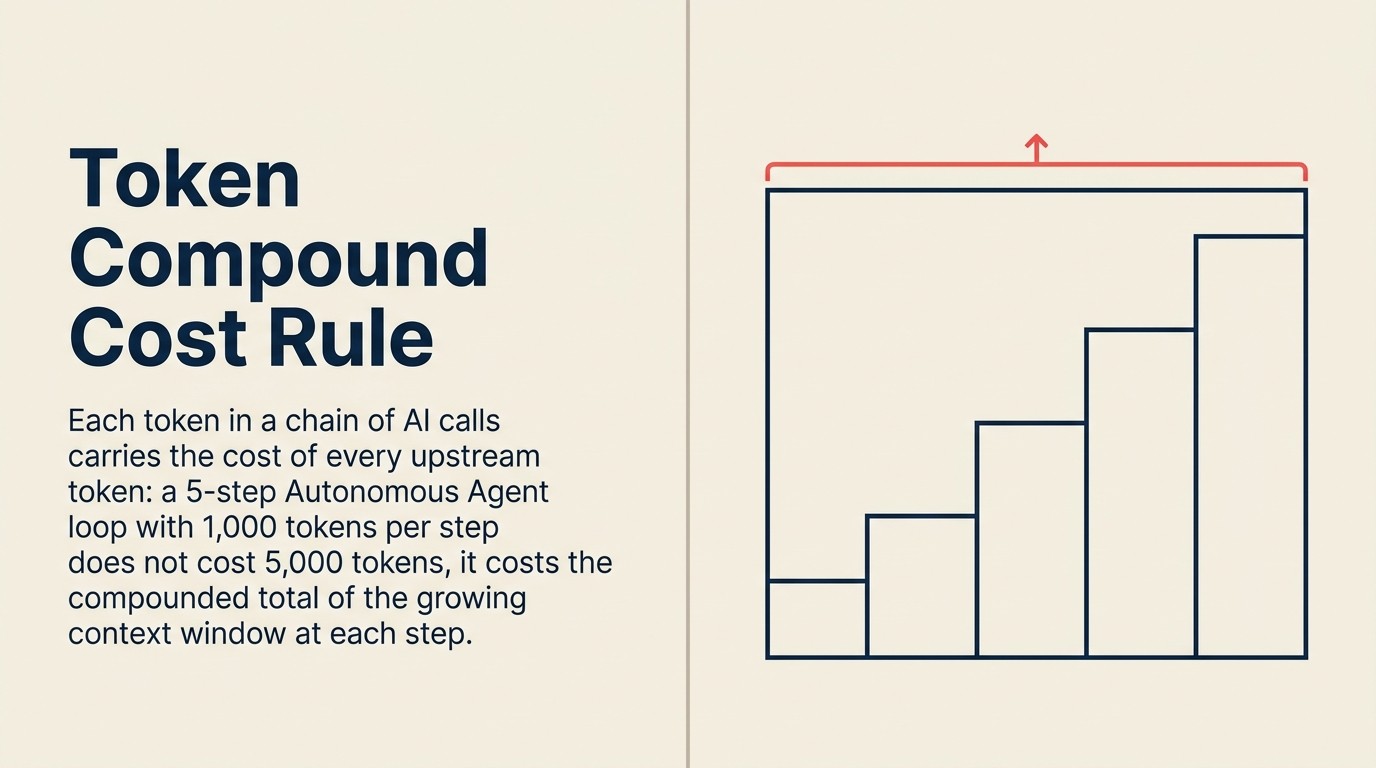
O Token Compound Cost Rule
O Token Compound Cost Rule afirma que o gasto total com AI empresarial escala com o número de chamadas de LLM por tarefa de usuário, o tamanho médio da janela de contexto por chamada e a frequência de retreinamento por padrão, não com o preço por token. Isso explica por que o gasto total com AI empresarial aumentou 320% enquanto os preços individuais de tokens caíram 280 vezes: a mudança para workflows agênticos (10 a 20 chamadas por tarefa), arquiteturas RAG (inflação de janela de contexto de 3 a 5 vezes) e agentes de monitoramento sempre ativos cria volume de chamadas composto que supera as reduções de preços por token. A implicação prática da regra é que o controle de custos em escala requer limitar as chamadas por tarefa, cachear contexto repetido e escopar a implantação para os workflows de maior valor, e não esperar que os preços de tokens continuem caindo.
Rework Analysis: Com base na descoberta da Gartner de que os modelos agênticos requerem 5 a 30 vezes mais tokens por tarefa e na descoberta da Oplexa de que o gasto com AI empresarial aumentou 320% apesar das quedas de 280 vezes nos preços de tokens, o Token Compound Cost Rule identifica três multiplicadores de custo que os orçamentos piloto sistematicamente ignoram: composição de volume de chamadas de loops autônomos, inflação de janela de contexto de RAG e recuperação de histórico, e custos de frequência de retreinamento que escalam com a complexidade dos dados. Os dados de implementação da Rework mostram que as equipes que modelam os três multiplicadores antes da aprovação de implantação têm excessos médios de custos de produção de 23%. As equipes que modelam apenas o preço por token têm excessos médios de 287%.
Os quatro cenários mais comuns de excesso de custo
Cenário 1: O índice de embedding que cresce sem poda. Um sistema RAG é implantado com uma base de conhecimento limpa de 10.000 documentos. Ninguém remove documentos antigos quando as políticas são atualizadas ou os produtos são descontinuados. Dois anos depois, o índice tem 80.000 documentos (a maioria deles desatualizados), a qualidade de recuperação está diminuindo conforme o modelo recupera conteúdo obsoleto e a re-indexação para corrigir isso custa mais do que a implantação original. Inclua no orçamento a manutenção do índice desde o primeiro dia. É também assim que os sistemas RAG se tornam tech debt. Veja quando os padrões de AI se tornam tech debt para a trajetória completa de custo.
Cenário 2: Autonomous Agent sem limites de iteração. Descrito acima. Este é um risco finito com uma solução completa: caps de orçamento e limites de iteração, definidos antes da implantação. Qualquer proposta de implantação de Autonomous Agent que não inclua esses como requisitos não negociáveis deve ser devolvida. A análise da Andreessen Horowitz sobre LLMflation e economia de inferência mostra que, embora os custos por token estejam caindo 10 vezes por ano, o gasto total com inferência empresarial está aumentando porque o uso cresce mais rápido do que os preços caem. Essa dinâmica torna os limites de iteração críticos independentemente de quão baratos os tokens individuais se tornem.
Cenário 3: Meeting Intelligence processando todas as reuniões internas. O excesso de custo mais fácil de evitar. 70% das reuniões na maioria das organizações são internas. O Meeting Intelligence fornece zero valor de CRM para reuniões internas. Escope a implantação apenas para chamadas voltadas ao cliente antes do lançamento, não depois que a conta chegar.
Cenário 4: Generative Research com escopo amplo demais. Prompts de pesquisa que dizem "pesquise tudo relevante para X" produzem resultados completos, mas custos completos. Defina contagens máximas de fontes, profundidade máxima de documentos e escopo de tópico nos seus templates de prompt de pesquisa. "Pesquise os últimos 6 meses de atividade competitiva do Concorrente X, usando as 10 fontes mais relevantes" produz 85% do valor de "pesquise tudo sobre o Concorrente X" a 20% do custo.
Construindo um modelo de custo antes da implantação
Para cada implantação de padrão, modele esses inputs antes da aprovação:
| Input | De onde vem |
|---|---|
| Contagem média de tokens de input por chamada | Meça de 20 a 30 amostras representativas |
| Contagem média de tokens de output por chamada | Estime a partir do design do prompt |
| Volume esperado de chamadas (mensal) | Baseline do volume atual do fluxo de trabalho |
| Precificação do modelo (por 1k tokens) | Tabela de preços do fornecedor |
| Custos de armazenamento (embeddings, gravações, índices) | Precificação de armazenamento do fornecedor |
| Frequência e custo de retreinamento | Decisão de arquitetura |
Construa três cenários: conservador (volume atual), moderado (2 vezes o volume atual no ano 1) e agressivo (5 vezes o volume no pico). Se o cenário agressivo produz um custo inaceitável, projete os controles de custo antes da implantação, não depois.
Por que as estimativas pré-implantação geralmente são muito baixas: as amostras vêm dos casos mais fáceis e representativos. A produção inclui todos os casos extremos, documentos longos, consultas complexas e padrões de uso inesperados que os pilotos filtram. Adicione um buffer de 50 a 100% à sua estimativa central.
Monitorando anomalias de custo
Aplique o conceito do Anomaly Agent aos seus próprios dados de custo de AI. Configure dashboards de custo por transação para cada padrão implantado. Defina intervalos de custo normais com base nos seus primeiros 60 dias de dados de produção. Configure alertas quando o custo por transação aumentar mais de 30% acima do baseline.
Sinais de alerta antecipado:
- Tamanho médio da janela de contexto aumentando (sinal de scope creep de prompt ou mudanças no tamanho do input)
- Contagem de iterações por tarefa do Autonomous Agent aumentando (sinal de scope creep de complexidade de tarefa ou deriva do modelo)
- Frequência de atualização do índice aumentando (sinal de crescimento da base de conhecimento sem poda)
- Taxas de erro aumentando junto com o custo (sinal de modelo com dificuldades, levando a custo de nova tentativa)
Quando um padrão se torna proibitivamente caro
O framework de decisão:
Otimizar primeiro. Compressão de contexto, caching, downgrade de modelo para tarefas mais simples, processamento em lote em vez de processamento em tempo real. Uma passagem típica de otimização recupera de 30 a 50% do custo sem impacto na qualidade.
Reduzir escopo em segundo lugar. Defina os casos de uso de maior valor dentro do padrão e restrinja a implantação a eles. Meeting Intelligence apenas para contas enterprise. Generative Research apenas para contas tier-1. Isso não é fracasso. É alocação racional de custos.
Substituir por um padrão menos caro se otimização e redução de escopo não funcionarem. Um Autonomous Agent fazendo roteamento de tarefas pode ser substituível por um modelo Scoring and Routing a 5% do custo, se a complexidade da tarefa não exigir realmente autonomia em múltiplas etapas. A seleção de padrões é sempre revisável. O artigo sobre a decisão de comprar vs. construir por padrão mostra onde as soluções de fornecedores reduzem o custo em comparação com builds customizadas.
Veja quando os padrões de AI se tornam tech debt para a trajetória de custo a longo prazo de padrões que não foram projetados para manutenção, e medindo ROI de padrão de AI para como rastrear o custo em relação ao valor. O objetivo não é a implantação mais barata. É a implantação de maior valor a um custo que o negócio consegue sustentar em escala.
Perguntas Frequentes
O que é o Token Compound Cost Rule?
O Token Compound Cost Rule afirma que o gasto total com AI empresarial escala com três multiplicadores que se compõem: o número de chamadas de LLM por tarefa de usuário (os workflows agênticos disparam de 10 a 20 chamadas versus 1 a 2 para consultas simples), o tamanho médio da janela de contexto por chamada (as arquiteturas RAG inflacionam o contexto em 3 a 5 vezes) e a frequência de retreinamento por padrão (55% dos modelos precisam de retreinamento em 90 dias). As reduções de preço por token não compensam o volume de chamadas composto. O gasto com AI empresarial aumentou 320% enquanto os preços por token caíram 280 vezes exatamente por causa desses multiplicadores.
Por que os custos do piloto de AI parecem tão diferentes dos custos de produção?
Os pilotos filtram todos os casos extremos, documentos longos, consultas complexas e padrões de uso incomuns que a produção inclui. Um piloto que processa 500 documentos representativos com complexidade média não leva em conta os 15% dos documentos de produção que são longos, não padrão ou requerem múltiplas passagens de processamento. Adicione um buffer de 50 a 100% à sua estimativa de custo do piloto para o planejamento de produção. Para Autonomous Agents especificamente, adicione também um buffer de contagem de iterações.
Qual é o controle de custo de maior impacto para Autonomous Agents?
Limites rígidos de iteração (máximo de chamadas de LLM por tarefa) e caps de budget de tokens por tarefa. Um Autonomous Agent sem esses controles financeiros é um compromisso de custo em aberto. A análise da Gartner mostra que os agentes requerem de 5 a 30 vezes mais tokens por tarefa do que os chatbots padrão, com tarefas complexas atingindo a extremidade alta desse intervalo. Definir um máximo de 10 chamadas por tarefa e handoff automático para agentes humanos quando os limites são atingidos não é uma conveniência operacional. É um controle financeiro.
Como o escopo da implantação do Meeting Intelligence afeta os custos?
Implantar o Meeting Intelligence para todas as reuniões em vez de apenas reuniões voltadas ao cliente normalmente adiciona 60 a 70% aos custos de transcrição e processamento sem valor adicional de CRM. As reuniões internas (standups, planejamento, reuniões gerais) não produzem dados úteis de negócios, mas ainda acumulam custos de transcrição por minuto e custos de sumarização por chamada. Escopar apenas para chamadas externas antes do lançamento é a otimização de custo mais fácil no padrão Meeting Intelligence.
Quando uma organização deve escolher um modelo mais barato em vez de um modelo melhor?
Quando a complexidade da consulta não exige as capacidades do modelo melhor. O roteamento de modelos, direcionando solicitações mais simples para modelos mais baratos e solicitações complexas para modelos premium, reduz os custos de AI empresarial em 30 a 50% sem perda de qualidade nas tarefas simples. Para Workflow Copilot, sugestões de contexto curto (verificação de tom de e-mail, conclusão simples de campo) podem ser executadas em modelos menores a uma fração do custo da inferência de classe GPT-4 de contexto completo. Construa o roteamento de modelos na arquitetura antes da implantação, não como um retrofit de economia de custos.
Para qual tendência de custos as empresas devem se preparar até 2030?
A Gartner prevê que os custos de inferência cairão mais de 90% até 2030. Mas os preços atuais são subsidiados por capital de risco e subsídios cruzados de hyperscalers, criando um piso artificialmente baixo que pode se normalizar para cima antes que o declínio de longo prazo seja retomado. As organizações que constroem modelos de custo para horizontes de tempo de 3 ou mais anos devem planejar um período de volatilidade de preços em vez de assumir um declínio linear de custo. O crescimento de volume da adoção agêntica também está comprimindo as margens dos provedores, o que pode parcialmente compensar as reduções brutas de custo de inferência.
Saiba mais

Co-Founder, Rework.com
On this page
- Por que as curvas de custo de AI diferem das curvas de custo de software
- Drivers de custo por padrão
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: o maior risco de custo
- O Token Compound Cost Rule
- Os quatro cenários mais comuns de excesso de custo
- Construindo um modelo de custo antes da implantação
- Monitorando anomalias de custo
- Quando um padrão se torna proibitivamente caro
- Saiba mais