スケール時にAIパターンがコスト超過する理由

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
パイロットは手頃に見えました。500件のドキュメントを処理し、60日間システムを動かし、400ドルを使いました。財務部は本格展開を承認しました。6カ月後、5万件のドキュメントを処理していて請求額は4万ドルです。4,000ドルでも8,000ドルでもない。4万ドル。ドキュメントの複雑さが増し、品質確認のために2回目のLLMパスを追加し、新しいドキュメントタイプを追加した時にエンベディングインデックスの再構築が必要になったからです。
スケールでのAIコスト超過は後から見ればほぼ常に予測可能です。推論ごとの価格モデル、ドキュメントサイズに伴うトークンのスケーリング動作、エンベディングのストレージコスト。これらは何も隠されていません。パイロットは低ボリュームで動作し、低ボリュームではコストが見えないため、導入前に注意深くモデル化されないだけです。
この記事では、パターンごとにコストの驚きを事前に予測可能にします。
AIコスト曲線がソフトウェアコスト曲線と異なる理由
従来のソフトウェアコストはほとんど固定です。ライセンス費用、実装コスト、比較的フラットなユーザーあたりの増分。シートに対して支払います。使用量にではありません。コストモデルは予測可能で前払い型です。
AIパターンのコストはデータボリューム、ドキュメントの複雑さ、クエリパターンと相互作用する方法で消費ベースです。McKinseyのAIの世界におけるエンタープライズテクノロジーの新しい経済性の分析はこのシフトを文書化しています。IT支出の79%は現在、資本支出ではなく運営費用であり、トークンベースのLLM使用量がFinOpsの複雑さの主要ドライバーです。ソフトウェアにはない4つのダイナミクス。
推論ごとの価格。 すべてのモデル呼び出しにトークンのコストがかかります。トークンコストは入力長と出力長に比例してスケールします。10ページのドキュメントは1ページのドキュメントの約10倍のコストがかかります。低ボリュームでは見えません。高ボリュームでは最大のコスト項目になります。
エンベディングとインデックスのストレージコスト。 RAG Assistantシステムはインデックスされたすべてのドキュメントのベクターエンベディングを保存します。ベクターストレージは次元ごと、レコードごとのコストがあります。エンベディングあたり1,536次元で100,000ドキュメントのナレッジベースはかなりのストレージを必要とし、ドキュメントを更新する時の再エンベディングはストレージの更新だけでなくコンピュートイベントです。
ビジネスの複雑さとともに増加する再トレーニングコスト。 スコアリングモデル、異常ベースライン、レコメンデーションエンジンはデータが変化するにつれて定期的な再トレーニングが必要です。初期の再トレーニングサイクルはデータが比較的少ないため安価です。後の再トレーニングサイクルはデータが増え、学習すべきパターンが複雑になるため高価になります。
複雑な入力に対する非線形のコスト動作。 50ページの契約書はLLMパスあたり1ページの契約書の約50倍のコストがかかります。8人の参加者がいるミーティングは2人の通話よりも帰属とサマリー作成にコストがかかります。複雑さ分布の低端でのユニットあたりコストは、本番ボリュームでの平均コストよりはるかに良く見えます。
Key Facts: スケールでのAIコスト
- エージェント型AIモデルは、標準的な生成AIチャットボットより1タスクあたり5〜30倍多くのトークンを必要とします。反復的に推論してツールを呼び出す自律型エージェントは、単一のユーザータスクあたり10〜20回のLLM呼び出しをトリガーする可能性があります。(Gartner, 2026年3月)
- トークン価格は2年間で280倍低下しましたが、エンタープライズの総AI支出は同期間に320%増加しました。コンテキストウィンドウを3〜5倍拡大するエージェント型ワークフローとRAGアーキテクチャへのシフトによって引き起こされています。(Oplexa Inference Cost Crisis Analysis, 2026)
- 本番環境のMLモデルの55%は90日以内に再トレーニングが必要であり、ほとんどのチームが1年目の承認で予算化しない最初の導入コストに加えて再トレーニングコストが発生します。(DataRobot, 2025)
パターン別のコストドライバー
RAG Assistant
主なコストドライバー: 検索と生成時のコンテキストウィンドウサイズ。
シンプルなRAGクエリは3〜5個のドキュメントチャンクを検索し、回答のコンテキストとして使用します。各チャンクが500トークンであれば、生成のコンテキストウィンドウは質問に加えて1,500〜2,500トークンです。中間クラスのモデルで$0.01/1kトークンで、1クエリあたり約$0.02〜0.03。
月10,000クエリで: $200〜300。管理可能です。
しかし高クエリボリュームで複雑な質問では、RAGシステムはしばしば多くのチャンクを検索し(より良い精度にはより多くのコンテキストが必要)、より長いコンテキストウィンドウを使用します。複雑なポリシーに関する質問は1,000トークンずつのチャンクを10個検索するかもしれません。1クエリあたり$0.10〜0.15。月50,000クエリで、ストレージ前のクエリコストだけで月$5,000〜7,500です。
インデックスの更新コストが2つ目の驚きです。ナレッジベースに500,000ドキュメントがあり、月10%を更新する場合、月50,000回の再エンベディングです。text-embedding-3-smallの$0.0001/エンベディング価格で月$5。text-embedding-3-largeで: 1kトークンあたり$0.13、平均ドキュメント500語(約667トークン)= ドキュメントあたり$0.087。50,000回の再エンベディング = インデックスメンテナンスだけで月$4,350。
Scoring + Routing
推論ごとのコストは低いです。スコアリングモデルは通常、生成モデルより小型で、高速で、安価です。主なコストリスクは再トレーニングの頻度とデータインフラです。
四半期ごとの再トレーニングが必要なスコアリングモデルには: データの取り出しとクリーニング、特徴エンジニアリングの計算、モデルトレーニングの計算、評価、デプロイが必要です。社内モデルでは工数です。ベンダー管理のモデルでは通常サービス料金です。コストは限定的で予測可能ですが、チームはしばしば2年目の予算に計上しません。最初の導入コストの一部ではなかったからです。
Vision Extract
ページごとの処理コストはドキュメントボリュームに対して正確に線形にスケールします。これは予測可能です。コストモデルは正直です。しかしパイロットの「月200件のドキュメントを処理する」は多くの場合「2年分の過去の請求書をバックフィルする必要がある」(一時的な処理スパイク)と「すべての新しい請求書と精度向上のために再処理しているすべての過去のドキュメント」になります。
高解像度の画像処理は低解像度より高コストです。ベンダーが画像ごとの計算時間に基づいて課金し、スキャン機器をアップグレードした場合、同じドキュメントボリュームでもドキュメントあたりのコストが増加します。
Meeting Intelligence
どちらも利用ボリュームとともにスケールする2つのコストドライバー。
文字起こしコスト。 音声テキスト変換APIは通常、音声の分ごとに価格を設定します。Whisperクラスの文字起こしはサービス層に応じて$0.006〜0.024/分で動作します。60分の営業コール: $0.36〜$1.44。月500コール: $180〜$720は文字起こしだけです。月5,000コール(エンタープライズスケール): 月$1,800〜$7,200。
LLMサマリー化コスト。 長いコールは長い文字起こしを生成します。60分のコールの文字起こしは約8,000〜12,000語(6,000〜9,000トークン)です。サマリー、アクションアイテム、CRMフィールドの抽出のために$0.01/1kトークン入力 + $0.03/1kトークン出力で処理: コールあたり約$0.12〜0.18。月5,000コール: 月$600〜$900。
コストの驚きは、チームが顧客向けのものだけでなくすべてのミーティングにMeeting Intelligenceを導入した時に発生します。内部スタンドアップ、計画ミーティング、全社ミーティングは有用なCRMデータを生成しませんが、それでも文字起こしと処理コストが発生します。シンプルなスコーピングポリシー(外部コールのみにMeeting Intelligence)は価値を削減することなくコストを60〜70%削減することが多いです。
Anomaly Agent
高データボリュームでのストリーム取り込みコストが主なリスクです。Anomaly Agentが1日100万件のトランザクションストリームを監視する場合、LLM呼び出しを追加する前にストレージと処理コストはすでに重要です。
純粋に統計的な異常検出(LLMなし)では、コストは管理可能で予測可能にスケールします。コストリスクが入ってくるのは、Anomaly AgentがコンテキストのエンリッチメントにLLM呼び出しを使用する場合(「このトランザクションが異常な理由を自然言語で説明する」)または複雑なマルチシグナルの相関に使用する場合です。高アラートボリュームでは、それらのLLM呼び出しが積み重なります。
Generative Research
統合のためのLLMトークンはソース材料の長さとともにスケールします。20のソースドキュメント(それぞれ3,000語)を引き出すリサーチブリーフは、モデルが何かを生成する前に約60,000語のコンテキストを提示します。GPT-4の価格で、それはリサーチタスクあたり入力トークンだけで$1.80〜$2.40です。出力生成がさらに$0.30〜0.60追加します。リサーチタスクあたり: $2〜3。
低く聞こえます。しかしリサーチ業務チームが月100件のブリーフを生成する場合、インフラコストを除いたAPIコストだけで月$200〜300です。月1,000件にスケールすると月$2,000〜3,000。月5,000件以上のリサーチタスクを行う大規模なコンサルティング業務では、LLMコストだけで月$15,000〜20,000に近づきます。
コスト制御のレバー: スコープの制限。5つのターゲットドキュメントを統合するリサーチは、見つけられるすべてを読むリサーチより75%少ないコストです。明示的なソース制限を持つリサーチプロンプト(「最も関連性の高い上位10ソースを使用する」)はコストの一部でも同等の品質を生み出します。
Document Review
契約の長さが主なコストドライバーです。5ページのNDAのレビューは40の別紙を持つ150ページのエンタープライズソフトウェア契約のレビューよりはるかに安価です。ドキュメントのミックスが短い契約(初期段階のスタートアップ)から複雑なエンタープライズ契約(成長段階)に移行する場合、ボリュームに変化がなくてもドキュメントあたりのコストが大幅に増加します。
2つ目のリスク: 複数のレビューパス。品質を重視するチームはしばしば初期の抽出パス、次に条項比較パス、次にサマリー生成パスを実行します。各パスが基本ドキュメントコストを倍増させます。3パスのレビューパイプラインは1パスのパイプラインの3倍のコストがかかります。必要なパスを事前に定義して予算を組みます。
Workflow Copilot
コンテキストウィンドウの管理が主要なコストレバーです。すべての提案呼び出しにCRMレコードの全履歴、直近10件のメールスレッド、関連するアカウントドキュメント、現在のタスクコンテキストを取り込むWorkflow Copilotは高コストです。各提案呼び出しはシンプルなメールドラフトでも8,000〜15,000トークンのコンテキストを使用するかもしれません。
ユーザーあたり1日20件の提案リクエスト × 50ユーザー = 1,000呼び出し/日。コンテキスト+出力の平均$0.15/呼び出しで: $150/日、月$4,500。200ユーザーで: 月$18,000。
コンテキスト圧縮(生のレコードを含める代わりに過去のコンテキストを要約する)、クエリルーティング(よりシンプルなリクエストを安価なモデルに送る)、提案のキャッシュ(類似したリクエストが以前の応答を再利用する)は品質への影響なしにこのコストを50〜70%削減できます。
Personalization Engine
ここでのコストリスクはスケールでのリアルタイム推論です。パーソナライズされたレコメンデーションを提供するには、すべてのユーザーインタラクションにモデル呼び出し(またはベクター類似性検索)が必要です。10個のパーソナライズ関連の判断を行う1日あたりのアクティブユーザーが100,000人の場合: 1日100万回の推論呼び出し。
各呼び出しが$0.001/呼び出しの小型専用モデルを使用する場合: $1,000/日、月$30,000。より高品質なレコメンデーションのためにより高品質なLLMにアップグレードする場合: コストが10〜20倍になります。モデルの品質と推論コストの間のエンジニアリングの判断が、このパターンにとって最も重要なコストアーキテクチャの決定です。
キャッシングはコストを大幅に削減します。ユーザーの40%が十分に類似したプロファイルを持ち、キャッシュされたレコメンデーションを提供できる場合、推論呼び出しの40%が不要になります。
Autonomous Agent: 最も高いコストリスク
このパターンは予期しない予算イベントを生み出す可能性が最も高いです。はっきり言います。ハードな繰り返し制限とタスクごとの予算上限のないAutonomous Agentはツールではなく負債です。
うまくいかない時に何が起きるか。
本番の顧客サポートAutonomous Agentにタスクが与えられます。「チケット#48291を解決する: 顧客が二重請求されたと言っている。」エージェントはループを始めます。チケットを読みます(1呼び出し)。支払い履歴を取得します(1呼び出し)。曖昧さを見つけて関連チケットを調べます(2呼び出し)。応答を下書きします(1呼び出し)。マネージャーの承認が必要と判断してエスカレーションポリシーを調べます(1呼び出し)。ポリシーが不明確だと判断してポリシードキュメント全体を読みます(1呼び出し)。3カ月分のトランザクション履歴を確認する必要があると判断します(3呼び出し)。トランザクションを比較して分析を生成します(2呼び出し)。この時点で: 1つのサポートチケットに12回のモデル呼び出し。
しかしエージェントは予期しないブランチにもぶつかりました。6カ月前の関連する苦情が関連するように見えました。エージェントはそのスレッドを引き出しました。4回の呼び出しが追加されました。次に顧客のアカウント履歴が関連すると判断しました。3回の呼び出しが追加されました。次に2つの解決オプションを下書きし、それぞれを会社のポリシーに基づいて修正し、最終応答をフォーマットしました。6回の呼び出しが追加されました。
合計: 1つのサポートチケットに25回のモデル呼び出し、呼び出しあたり$0.05〜0.15で = チケット解決あたり$1.25〜3.75。シンプルなチケットでのパイロットに基づいて予算した$0.10〜0.20に対して。
月10,000件の複雑なチケットで、実際のコストは月$12,500〜37,500、予算の月$1,000〜2,000に対して。これは実際に起きます。
コスト制御の要件: ハードな繰り返し制限(タスクあたり最大10回のモデル呼び出し)、タスクごとのトークン予算、制限に達した時の人間のエージェントへの自動引き渡し。これらは運用上の利便性ではありません。財務上のコントロールです。
「ハードな繰り返し制限のないAutonomous Agentは生産性ツールではありません。財務上の負債です。Gartnerの2026年3月の分析は、エージェント型モデルが標準的なチャットボットより1タスクあたり5〜30倍多くのトークンを必要とすることを確認しています。複雑なサポートチケットでその範囲の上限に達するエージェントは、エンタープライズのトークン価格で解決あたり$3〜4のコストがかかります。予算した$0.10〜0.20に対して。」(Rework Autonomous Agent Cost Analysis, 2026)
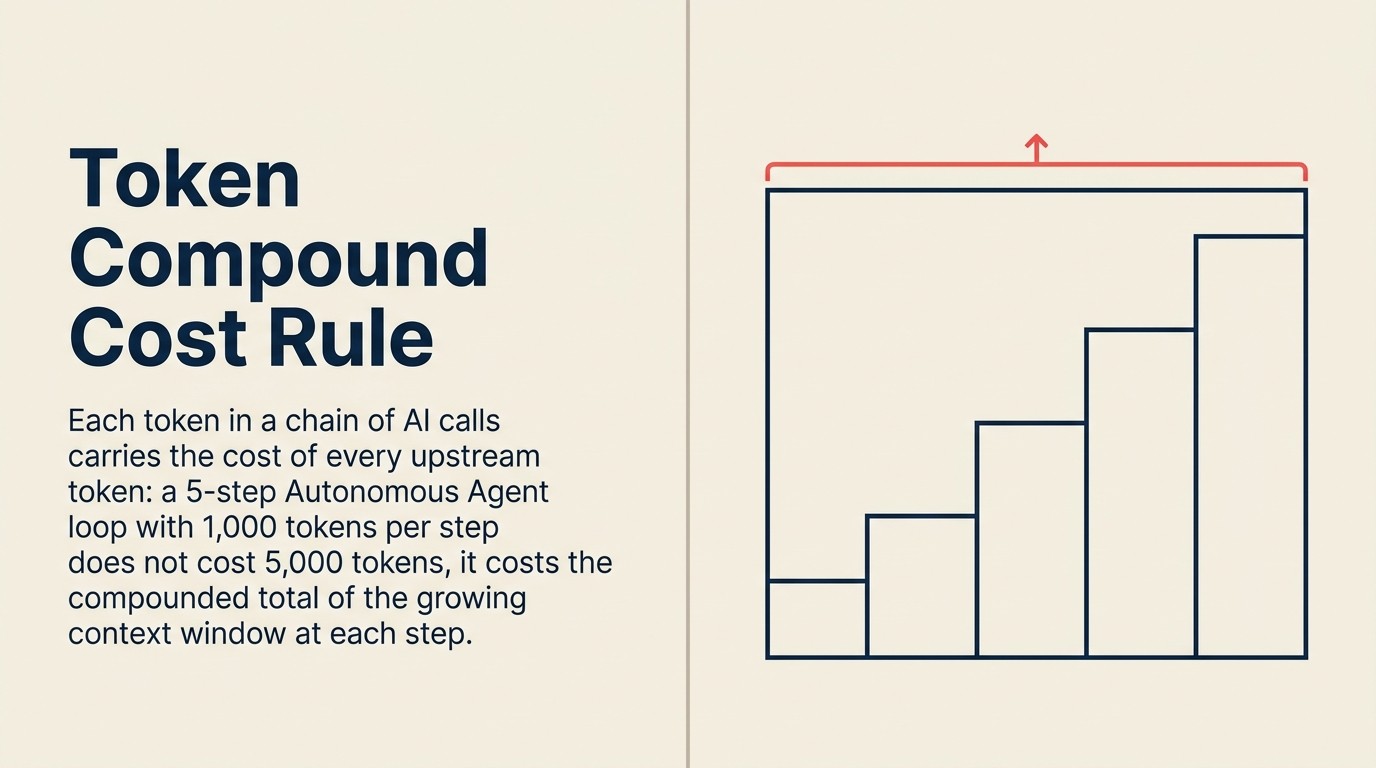
トークン複合コストルール
トークン複合コストルールは、エンタープライズの総AI支出がトークンあたりの価格ではなく、ユーザータスクあたりのLLM呼び出し数、呼び出しあたりの平均コンテキストウィンドウサイズ、パターンあたりの再トレーニング頻度とともにスケールすると規定します。これが、個々のトークン価格が280倍低下した一方でエンタープライズの総AI支出が320%増加した理由を説明しています。エージェント型ワークフロー(1タスクあたり10〜20呼び出し)、RAGアーキテクチャ(コンテキストウィンドウ3〜5倍の膨張)、常時監視エージェントへのシフトがトークンあたりの価格削減を圧倒する複合する呼び出しボリュームを生み出します。ルールの実践的な示唆は、スケールでのコスト制御にはトークン価格がさらに低下するのを待つのではなく、タスクあたりの呼び出しを制限し、繰り返されるコンテキストをキャッシュし、最高価値のワークフローに導入をスコーピングすることが必要ということです。
Rework Analysis: エージェント型モデルが1タスクあたり5〜30倍多くのトークンを必要とするというGartnerの発見と、トークン価格の280倍低下にもかかわらずエンタープライズAI支出が320%増加したというOplexaの発見に基づき、トークン複合コストルールはパイロット予算が組織的に見落とす3つのコスト乗数を特定します。自律ループからの呼び出しボリュームの複合、RAGと履歴検索からのコンテキストウィンドウの膨張、データの複雑さとともにスケールする再トレーニング頻度コストです。Reworkの実装データは、導入承認前に3つすべての乗数をモデル化するチームが平均23%の本番コスト超過を持つことを示しています。トークンあたりの価格のみをモデル化するチームは平均287%の超過を持ちます。
4つの最も一般的なコスト超過シナリオ
シナリオ1: プルーニングなしに成長するエンベディングインデックス。 RAGシステムがクリーンな10,000ドキュメントのナレッジベースで導入されます。ポリシーが更新されたり製品が廃止されたりしても、古いドキュメントを削除する人がいません。2年後、インデックスには80,000ドキュメント(そのほとんどが古い)があり、モデルが古いコンテンツを検索するにつれて検索品質が低下し、それを修正するための再インデックス作業は最初の導入より高コストです。初日からインデックスメンテナンスの予算を組みます。これはRAGシステムが技術的負債になる仕組みでもあります。完全なコスト軌跡についてはAIパターンが技術的負債になる時をご覧ください。
シナリオ2: 繰り返し制限のないAutonomous Agent。 上記で説明しました。これは完全な解決策を持つ有限のリスクです。導入前に定義された予算上限と繰り返し制限。これらを譲れない要件として含まないすべてのAutonomous Agent導入提案は差し戻すべきです。Andreessen HorowitzのLLMflationと推論の経済性の分析は、トークンあたりのコストが年10倍低下しているが、使用量が価格低下よりも速く成長しているためエンタープライズの総推論支出が増加していることを示しています。そのダイナミクスにより、個々のトークンがどれだけ安くなっても繰り返し制限は重要です。
シナリオ3: すべての内部ミーティングを処理するMeeting Intelligence。 最も避けやすいコスト超過です。多くの組織のミーティングの70%は内部です。Meeting Intelligenceは内部ミーティングに対してゼロのCRM価値を提供します。請求書が届いた後ではなく、ローンチ前に顧客向けコールのみに導入をスコーピングします。
シナリオ4: 広すぎるスコープのGenerative Research。 「Xに関連するすべてをリサーチする」というリサーチプロンプトは完全な結果と完全なコストを生みます。リサーチプロンプトテンプレートで最大ソース数、最大ドキュメント深度、トピックスコープを定義します。「競合他社Xからの直近6カ月の競合活動を、最も関連性の高い上位10ソースを使用してリサーチする」は「競合他社Xについてすべてをリサーチする」の価値の85%を20%のコストで生み出します。
導入前のコストモデルの構築
各パターン導入で、承認前にこれらの入力をモデル化します。
| 入力 | 入手元 |
|---|---|
| 呼び出しあたりの平均入力トークン数 | 20〜30の代表的なサンプルを測定 |
| 呼び出しあたりの平均出力トークン数 | プロンプト設計から推定 |
| 予想呼び出しボリューム(月次) | 現在のワークフローボリュームのベースライン |
| モデル価格(1kトークンあたり) | ベンダーの料金表 |
| ストレージコスト(エンベディング、録音、インデックス) | ベンダーのストレージ価格 |
| 再トレーニング頻度とコスト | アーキテクチャの決定 |
3つのシナリオを構築します。保守的(現在のボリューム)、中程度(1年目に現在のボリュームの2倍)、積極的(ピーク時に5倍のボリューム)。積極的なシナリオが許容できないコストを生み出す場合、導入後ではなく導入前にコストコントロールを設計します。
導入前の見積もりが通常低すぎる理由: サンプルは最も簡単な代表的なケースから来ます。本番にはパイロットがフィルタリングするすべてのエッジケース、長いドキュメント、複雑なクエリ、予期しない使用パターンが含まれます。中央値の見積もりに50〜100%のバッファを追加します。
コストの異常のモニタリング
Anomaly Agentのコンセプトを自分たちのAIコストデータに適用します。導入されたパターンごとにトランザクションあたりのコストのダッシュボードを設定します。最初の60日間の本番データに基づいて通常のコスト範囲を定義します。トランザクションあたりのコストがベースラインより30%以上上昇した時にアラートを設定します。
早期警告シグナル。
- 平均コンテキストウィンドウサイズの増加(プロンプトのスコープクリープまたは入力サイズの変化のサイン)
- Autonomous Agentタスクあたりの繰り返し回数の増加(タスクの複雑さのクリープまたはモデルドリフトのサイン)
- インデックス更新頻度の増加(プルーニングなしのナレッジベース成長のサイン)
- コストの増加に伴うエラー率の増加(モデルが苦労していて再試行コストにつながるサイン)
パターンが高すぎるコストになった時
意思決定フレームワーク。
まず最適化する。 コンテキスト圧縮、キャッシング、よりシンプルなタスクのためのモデルダウングレード、リアルタイム処理ではなくバッチ処理。典型的な最適化パスは品質への影響なしにコストの30〜50%を回収します。
次にスコープを縮小する。 パターン内で最も価値の高いユースケースを定義し、それらに導入を制限します。エンタープライズアカウントのみにMeeting Intelligence。ティア1アカウントのみにGenerative Research。これは失敗ではありません。合理的なコスト配分です。
最適化とスコーピングが機能しない場合は、より安価なパターンに置き換える。 タスクルーティングを行うAutonomous Agentは、タスクの複雑さが実際に多段階の自律性を必要としない場合、コストの5%でScoring and Routingモデルに置き換えられるかもしれません。パターン選択は常に再検討可能です。パターン別の購入対構築の決定の記事ではカスタム構築と比較してベンダーソリューションがコストを削減する場所を示しています。
メンテナビリティのために設計されていなかったパターンの長期コスト軌跡についてはAIパターンが技術的負債になる時を、コストと価値の関係を追跡する方法についてはAIパターンのROIの測定をご覧ください。目標は最も安価な導入ではありません。ビジネスがスケールで持続可能なコストで最も価値の高い導入です。
よくある質問
トークン複合コストルールとは何ですか?
トークン複合コストルールは、エンタープライズの総AI支出が一緒に複合する3つの乗数とともにスケールすると規定します。ユーザータスクあたりのLLM呼び出し数(エージェント型ワークフローは単純なクエリの1〜2回に対して10〜20回の呼び出しをトリガーします)、呼び出しあたりの平均コンテキストウィンドウサイズ(RAGアーキテクチャはコンテキストを3〜5倍膨張させます)、パターンあたりの再トレーニング頻度(モデルの55%が90日以内に再トレーニングが必要です)。トークンあたりの価格削減は複合する呼び出しボリュームを相殺しません。エンタープライズのAI支出はトークンあたりの価格が280倍低下した一方で320%増加しました。まさにこれらの乗数のために。
なぜAIパイロットのコストは本番コストとこれほど異なるのですか?
パイロットは本番が含むすべてのエッジケース、長いドキュメント、複雑なクエリ、普通でない使用パターンをフィルタリングします。平均的な複雑さで500件の代表的なドキュメントを処理するパイロットは、長い、非標準、または複数の処理パスが必要な本番ドキュメントの15%を見逃します。本番計画のためにパイロットコスト見積もりに50〜100%のバッファを追加します。Autonomous Agentについては、繰り返し回数のバッファも追加します。
Autonomous Agentにとって最もインパクトのある単一のコストコントロールは何ですか?
ハードな繰り返し制限(タスクあたりの最大LLM呼び出し数)とタスクごとのトークン予算上限。これらの財務コントロールのないAutonomous Agentはオープンエンドのコスト負担です。Gartnerの分析は、エージェントが標準的なチャットボットより1タスクあたり5〜30倍多くのトークンを必要とし、複雑なタスクがその範囲の上限に達することを示しています。タスクあたり最大10呼び出しを設定し、制限に達した時に人間のエージェントへの自動引き渡しを設定することは運用上の利便性ではありません。財務上のコントロールです。
Meeting Intelligenceの導入スコープはコストにどう影響しますか?
顧客向けミーティングのみではなくすべてのミーティングにMeeting Intelligenceを導入すると、追加のCRM価値ゼロで文字起こしと処理コストが通常60〜70%増加します。内部ミーティング(スタンドアップ、計画、全社)は有用な商談データを生成しませんが、それでも分ごとの文字起こしコストとコールごとのサマリー化コストが発生します。ローンチ前に外部コールのみにスコーピングすることが、Meeting Intelligenceパターンで最も簡単な単一のコスト最適化です。
組織はいつより安価なモデルをより良いモデルの代わりに選ぶべきですか?
クエリの複雑さがより良いモデルの能力を必要としない時。モデルルーティング(よりシンプルなリクエストを安価なモデルに、複雑なリクエストをプレミアムモデルに誘導する)は、シンプルなタスクでの品質損失なしにエンタープライズのAIコストを30〜50%削減します。Workflow Copilotで、短いコンテキストの提案(メールのトーンチェック、シンプルなフィールド補完)はフルコンテキストのGPT-4クラスの推論コストの一部で小型モデルで実行できます。導入後のコスト削減の後付けではなく、導入前にアーキテクチャにモデルルーティングを組み込みます。
企業は2030年に向けてどのようなコストトレンドに備えるべきですか?
Gartnerは2030年までに推論コストが90%以上低下すると予測しています。しかし現在の価格はベンチャーキャピタルとハイパースケーラーのクロス補助金によって補助されており、長期的な低下が再開する前に上方に正規化するかもしれない人工的に低い底を生み出しています。3年以上の時間軸でコストモデルを構築する組織は、線形のコスト低下を前提とするのではなく価格の変動期間を計画すべきです。エージェント型採用からのボリューム成長もプロバイダーのマージンを圧縮しており、これが純粋な推論コスト削減を部分的に相殺するかもしれません。
関連リンク

Co-Founder, Rework.com
On this page
- AIコスト曲線がソフトウェアコスト曲線と異なる理由
- パターン別のコストドライバー
- RAG Assistant
- Scoring + Routing
- Vision Extract
- Meeting Intelligence
- Anomaly Agent
- Generative Research
- Document Review
- Workflow Copilot
- Personalization Engine
- Autonomous Agent: 最も高いコストリスク
- トークン複合コストルール
- 4つの最も一般的なコスト超過シナリオ
- 導入前のコストモデルの構築
- コストの異常のモニタリング
- パターンが高すぎるコストになった時
- 関連リンク