パターン移行: AIのv1からv2へ
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
エンタープライズAIの第一世代はすでに老朽化しています。2022年にRAG Assistantを導入したチームはtext-embedding-ada-002の上に構築しました。2023年にスコアリングモデルを導入したチームはGPT-4以前のデータインフラでトレーニングしました。2024年初頭にWorkflow Copilotを構築したチームは、それ以来2世代に追い越されたモデル向けのプロンプトを設計しました。
これらのシステムはまだ動いています。それが問題です。より優れたアーキテクチャが移行一つ先にある中、静かに技術的および運用上の負債を蓄積しながら動き続けています。非推奨のインフラで動いているチームは失敗していません。ただ移行バックログが増える中でケイパビリティを諦めているだけです。
移行は任意ではありません。しかしソフトウェアのバージョンアップとも同じではありません。AIの動作は確率的です。「意図した通りに機能している」は二値状態ではありません。モデルを入れ替えて、テストスイートを実行して、完了と呼ぶことはできません。モデル更新による動作の変化は実在し、時に微妙で、時に重大です。古い動作の周りにワークフローを構築したユーザーは、何が変わったかを知る必要があります。
この記事は、2022〜2024年に何かを構築し、本番を壊さずにアップグレードする必要があるチームのためのものです。
パターンの移行を引き起こすもの
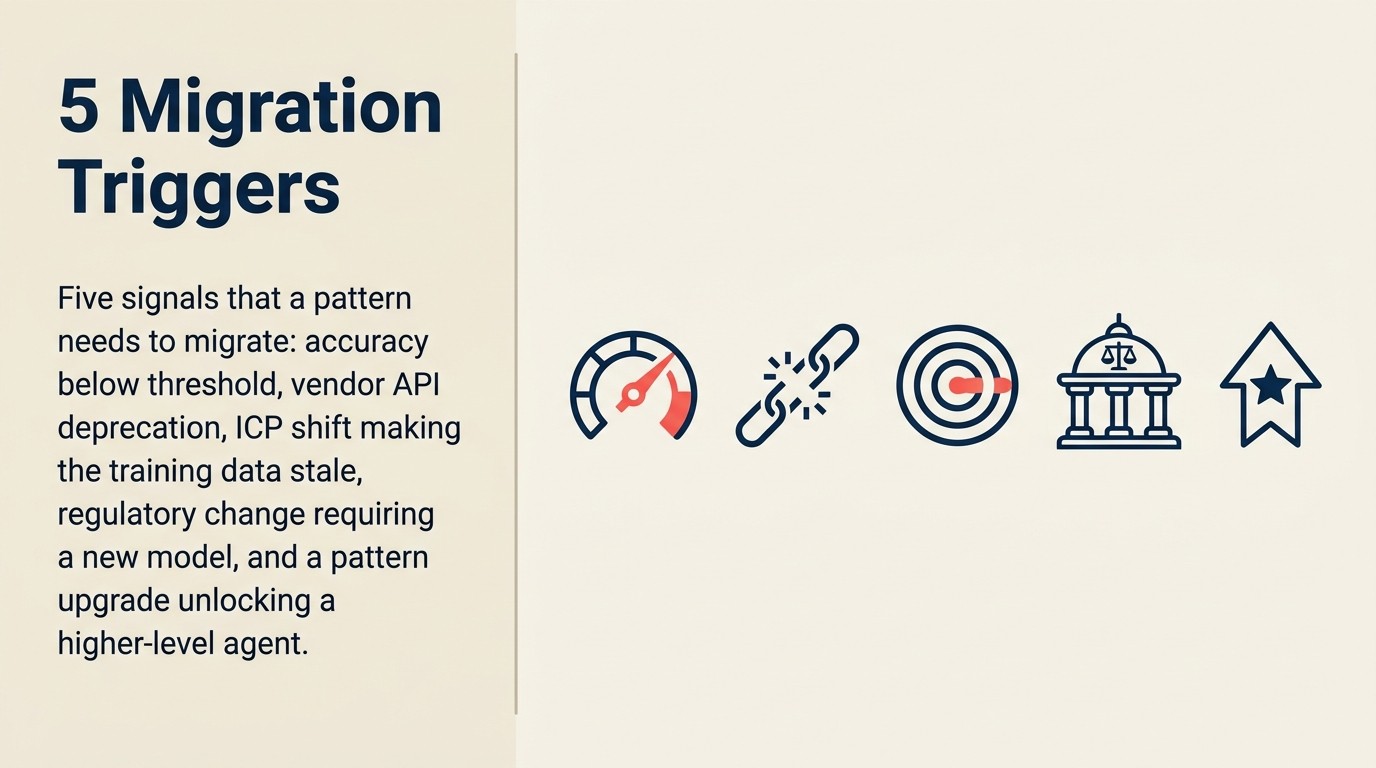
継続的なメンテナンスではなく移行にパターンを押し進める5つのシナリオ。
ベンダーによるモデルの非推奨化。 最も明確なトリガーです。OpenAI、Anthropic、Google、Azureはすべて廃止期日を含む非推奨のタイムラインを公開しています。パターンが依存するモデルがEOL(製品終了)に達した時、移行するか壊れるかです。ほとんどのエンタープライズAIチームはこれを少なくとも一度経験しています。APIが非推奨の通知を返し、ロードマップになかった移行が突然緊急になります。Anthropicのモデル非推奨ドキュメントは廃止の少なくとも60日前に通知を提供しますが、そのタイムラインは通知を監視していることを前提としています。廃止されたモデルへのAPIリクエストは、監視が設置されていない限り呼び出し元から見て静かに失敗します。
運用上の示唆: すべての本番パターンは「このモデルが次の四半期に非推奨になった場合どうなるか」の文書化された回答を持つべきです。必ずしも完全な移行計画ではなく、少なくとも移行スコープの評価。
大幅な精度の劣化。 四半期ごとの精度レビューが一貫した低下を示し、根本原因がデータの品質やプロンプトの品質ではなくモデルのケイパビリティにある場合、より良いモデルへの移行が修正策です。診断が重要です。データドリフトは再トレーニングまたはデータの更新が必要、プロンプト品質の問題はプロンプトエンジニアリングが必要、モデルのケイパビリティギャップはモデルの移行が必要です。
既存のアプローチを時代遅れにする新しいケイパビリティ。 純粋なベクター検索RAGからハイブリッドのキーワード-ベクター-リランクへの移行が最近の最も明確な例です。2022年に純粋なセマンティック検索でRAGを構築したチームは、ハイブリッドアプローチと比較して検索品質の向上20〜40%を諦めています。パターン別のハルシネーションリスク記事はRAGの精度にとって検索品質がなぜそれほど重要かを説明しています。既存のシステムは壊れていません。v1が構築された時には存在しなかったv2アーキテクチャに大幅に上回られているだけです。
新しいアプローチを好むコストの変化。 2023年の価格でGPT-4上に構築されたパターンは、現在ケイパビリティに追いついたより小型で、より速く、より安価なモデルで経済的に置き換えられるかもしれません。あるいは、独自のベンダーツールで構築されたパターンは、コストの一部でオープンソースインフラに置き換えられるかもしれません。コストモデルの比較についてはコスト超過記事をご覧ください。
ベンダー関係の変化。 買収、価格再編、製品の廃止が起きます。スタートアップのAI APIで構築されたパターンがそのスタートアップが廃止した場合が最悪のシナリオです。緊急のタイムラインで強制移行になります。ベンダー集中リスクの評価はAIガバナンスレビューの一部であるべきです。
Key Facts: AIパターン移行の現実
- エンタープライズAIの第一世代(2022〜2024年導入)はすでに移行トリガーに達しています。モデルの非推奨化、新しいアーキテクチャからのケイパビリティギャップ(ハイブリッドRAG対ナイーブなベクター検索では検索品質が20〜40%向上)、蓄積されたデータ負債です。
- シャドウテストに続く1〜10%のトラフィックでのカナリアデプロイは、エンタープライズAIモデルのロールアウトの標準的な手法になっており、4フェーズのアプローチを取ります。POC(2〜4週間)、5〜10%トラフィックでのパイロット(4〜8週間)、本格スケールデプロイ(8〜12週間)。(MLOps Deployment Research, 2026)
- 適切なカナリアシーケンスを伴うAI駆動の移行は、直接カットオーバーのアプローチと比較して運用効率を20〜25%向上させ、デプロイサイクル時間を70%削減します。(QualityKiosk Migration Analysis, 2026)
リスクプロファイルが異なる3つの移行タイプ
タイプ1: インプレースモデル移行。 アーキテクチャを維持しながら基礎となるモデルを入れ替えます。同じ検索パイプライン、同じプロンプト構造、同じ統合レイヤー。ただし別のモデルの呼び出し。インフラの観点から最も低リスクな移行タイプですが、新しいモデルは同じプロンプトに異なる方法で応答するかもしれないため、それでも動作の回帰テストが必要です。
例: RAG AssistantのGPT-3.5 TurboをGPT-4o Miniに置き換える。同じアーキテクチャ、より良いモデル。しかしGPT-4o MiniはGPT-3.5 Turboより精確に指示に従います。つまり古いモデルのフォーマットに関するゆるさに依存していたプロンプトが、予期しないフォーマットのアウトプットを生成するかもしれません。
タイプ2: アーキテクチャ移行。 異なるアプローチでパターンを再構築します。ユースケースは同じで実装が根本的に異なります。ナイーブな単一ベクター検索からハイブリッドのキーワード-ベクター-リランクへのRAGはアーキテクチャ移行です。文字起こしのみのパイプラインから文字起こし-プラス-話者識別-プラス-トピック検出パイプラインへのMeeting Intelligenceはアーキテクチャ移行です。
アーキテクチャ移行は最高の複雑さと最高の潜在的な品質向上を持ちます。既存のシステムのアップグレードよりも新しいシステムの構築に近く、完全な移行フレームワークが必要です。
タイプ3: ベンダー移行。 同じパターン実装を異なるベンダーに移動します。RAG AssistantをAzure OpenAIからAnthropic Claudeに切り替えます。Meeting IntelligenceをAssemblyAIからDeepgramに切り替えます。パターンは同じままでベンダースタックが変わります。
ベンダー移行はしばしば見た目より単純です。異なるベンダーは異なるAPI規約、異なるレイテンシ特性、異なる出力フォーマットのデフォルト、同じプロンプトに対する異なるモデルの動作を持ちます。ベンダーAで機能したものは、両方のベンダーが同等のケイパビリティを主張しても、ベンダーBでプロンプトの調整が必要かもしれません。
パターンによって移行リスクがどう異なるか

すべてのパターン移行が同じリスクを持つわけではありません。リスクが集中する場所を理解することで、テストとステージングの時間を優先するのに役立ちます。
高移行リスクのパターン:
Scoring and Routing: 新しいスコアリングモデルは異なるスコアを生成するだけではありません。異なる分布を生成します。古いモデルが高品質Leadを70〜90でスコアし、新しいモデルが80〜95でスコアする場合、ルーティングの閾値は初日から間違っています。「スコアが75以上であれば企業チームにルーティングする」に基づいて構築されたルーティングロジックは、Lead数量の大部分を誤って割り当てる可能性があります。閾値の再キャリブレーションは任意ではなく、すべてのモデル入れ替えの後に必要です。
Autonomous Agent: エージェントのレパートリーのすべてのツールAPIは移行前に互換性の確認が必要です。新しいエージェントバージョンは同じAPIを呼び出すかもしれませんが、応答を異なる方法で解析するか、異なる順序でツールを呼び出すかもしれません。同じ入力に対して異なるExecuteの動作を生み出します。完全な動作回帰テストが必要です。
Personalization Engine: 古いシステムからのユーザープロファイルの表現は新しいアーキテクチャに意味のある形で移せないかもしれません。新しいモデルが異なる方法でユーザープロファイルを構築する場合、本番の最初の数週間はプロファイルが再構築される間パーソナライズの品質が低下します。
中程度の移行リスクのパターン:
RAG Assistant: エンベディングモデルの変更は完全な再インデックスが必要です。異なるエンベディングモデルは同じドキュメントに対して異なるベクター表現を生成するため、同じインデックスに異なるモデルからのエンベディングを混在させることはできません。500,000ドキュメントのナレッジベースでの完全な再インデックスは発見されるのではなく計画される必要のある重要なコンピュートイベントです。
Workflow Copilot: モデル間でプロンプトの動作が変わります。古いモデルで簡潔な提案を生み出した指示は、新しいモデルで詳細な提案を生み出すかもしれません。プロモーション前に提案のトーン、長さ、精度の品質レビューが必要です。
Document Review: 抽出スキーマの互換性。新しいモデルはわずかに異なるフォーマットで条項情報を抽出するかもしれず、下流の法務ワークフロー統合が壊れます。
低移行リスクのパターン:
Meeting Intelligence: 異なる文字起こしベンダーへの切り替えは比較的低リスクです。なぜなら文字起こしのアウトプットはタイムスタンプ付きテキストに標準化されているからです。高レベルの分析(サマリー、アクションアイテム)はより多くの動作リスクを持ちます。
Vision Extract: 抽出スキーマが維持される限り、アウトプットが特定のフィールドに制約されているため、モデルの変更はリスクが低いです。フォーマットのドリフトが主なリスクであり、動作の予測不可能性ではありません。
Anomaly Agent: より良い異常検出モデルへの移行はベースラインの再確立が必要ですが、基本的なアラートロジックは通常モデルに依存しません。
移行フレームワーク
ステップ1: 現在のシステムをベースライン化する。
移行で何かに触れる前に、現在のシステムの動作の包括的なベースラインをキャプチャします。これが回帰比較セットです。
RAG Assistantの場合: 現在のシステムに対して200件の代表的なクエリを実行します。クエリ、検索されたドキュメント、生成された応答を記録します。グランドトゥルースに対して各応答を正確、部分的に正確、または不正確として分類します。これが承認テストスイートになります。
Scoring+Routingモデルの場合: 過去90日間のスコアリング決定を取り出します。500件の代表的なレコードの入力特徴とスコアを記録します。実際の結果を記録します(高スコアのLeadはコンバージョンしたか? フラグが立てられた異常は本物だったか?)。これがキャリブレーションのベースラインです。
ベースラインなしで移行を開始しないでください。新しいシステムの動作を同じ入力で古いシステムの動作と比較できなければ、移行の基準がありません。感覚だけです。
ステップ2: 新しいシステムをシャドウモードで実行する。
古いシステムと並行して新しいシステムをデプロイします。両方のシステムが同じ入力を処理します。古いシステムのアウトプットのみが本番で使用されます。新しいシステムのアウトプットはログに記録されますが、実行には使われません。
シャドウモードは高トラフィックまたは顧客向けのデプロイメントには任意ではありません。30日間並行して動かすコストは悪いカットオーバーのコストよりはるかに低いです。シャドウ期間に月10,000クエリを処理するRAG AssistantはシャドウAPIコストに約50%追加します。悪いカットオーバーのインシデントはユーザーの信頼、緊急対処、ステークホルダーの信頼においてはるかに多くのコストがかかります。
シャドウモードの期間: 最低14日間。推奨: 統計的に意味のある比較データを生成するのに十分なトラフィックで30日間。
ステップ3: システム間のアウトプットを比較する。
シャドウ期間の各入力について、古いシステムのアウトプットと新しいシステムのアウトプットを比較します。カテゴリを特定します。
- 合意: 両方のシステムが同等のアウトプットを生成する
- 新システムの改善: 新しいシステムが明らかに優れている(より高い精度、より良いフォーマット、より完全な応答)
- 新システムの後退: 古いシステムが優れていた(新しいシステムが悪いか間違った回答を生成する)
- 新しい動作: 新しいシステムが古いシステムでは生成しなかったアウトプットを生成する(正または負)
後退が重要なカテゴリです。プロモーション前にすべての後退を調査して対処しなければなりません。
ステップ4: 承認基準を定義する。
移行を開始する前に、「プロモーションに十分に良い」とはどういう意味かを定義します。シャドウモードの結果を見た後で定義しないでください。それは合理化であり、承認ではありません。
RAG Assistant移行の承認基準の例。
- ベースラインテストセットでの新システムの精度: クエリの95%で古いシステム以上
- ベースラインクエリでの後退率: 3%未満
- 新システムの応答レイテンシ: 古いシステムのレイテンシの20%以内
- シャドウモードのユーザー満足度シグナル(測定可能な場合): 古いシステムと比較して低下なし
ステップ5: トラフィックを段階的にシフトする。
「新しいスコアリングモデルは異なるスコアを生成するだけではありません。異なる分布を生成します。古いモデルが高品質Leadを70〜90でスコアし、新しいモデルが80〜95でスコアする場合、ルーティングの閾値は初日から間違っています。最初に本番トラフィックの10%をルーティングします。50%にプロモートする前に分布の整合性を確認します。100%の前に再確認します。閾値の再キャリブレーションはすべてのモデル入れ替えの後に必要であり、任意ではありません。」(Rework Scoring Model Migration Analysis, 2026)
一度に100%カットオーバーしないでください。最初に本番トラフィックの10%を新しいシステムにルーティングします。エラー、レイテンシの問題、品質シグナルを監視します。48〜72時間保ちます。クリーンであれば25%に増やし、次に50%、次に100%へ。これはソフトウェアエンジニアリングではカナリアデプロイと呼ばれ、Martin FowlerがレガシーモダナイゼーションのためのStrangler Figパターンとして説明しているものに直接マッピングされます。古いシステムを安全に廃止できるまで、トラフィックを古いものから新しいものに徐々にシフトします。AI移行に直接適用されます。
いずれかのステージで品質シグナルがシャドウモードの期待から乖離した場合、進む前にトラフィックシフトを止めて調査します。
ステップ6: 本番前にロールバック計画を定義する。
新しいシステムにトラフィックをプロモートする前に、古いシステムにロールバックする方法を正確に知っておきます。復元する設定。ロールバックにかかる時間。ロールバックをトリガーする権限を持つ人。ロールバックのトリガー基準。
ロールバック計画は文書化されて、オペレーションチームの誰でもアクセスできるようにすべきです。「インシデントが発生した場合に言い換える」はロールバック計画ではありません。
シャドウモード期間の詳細
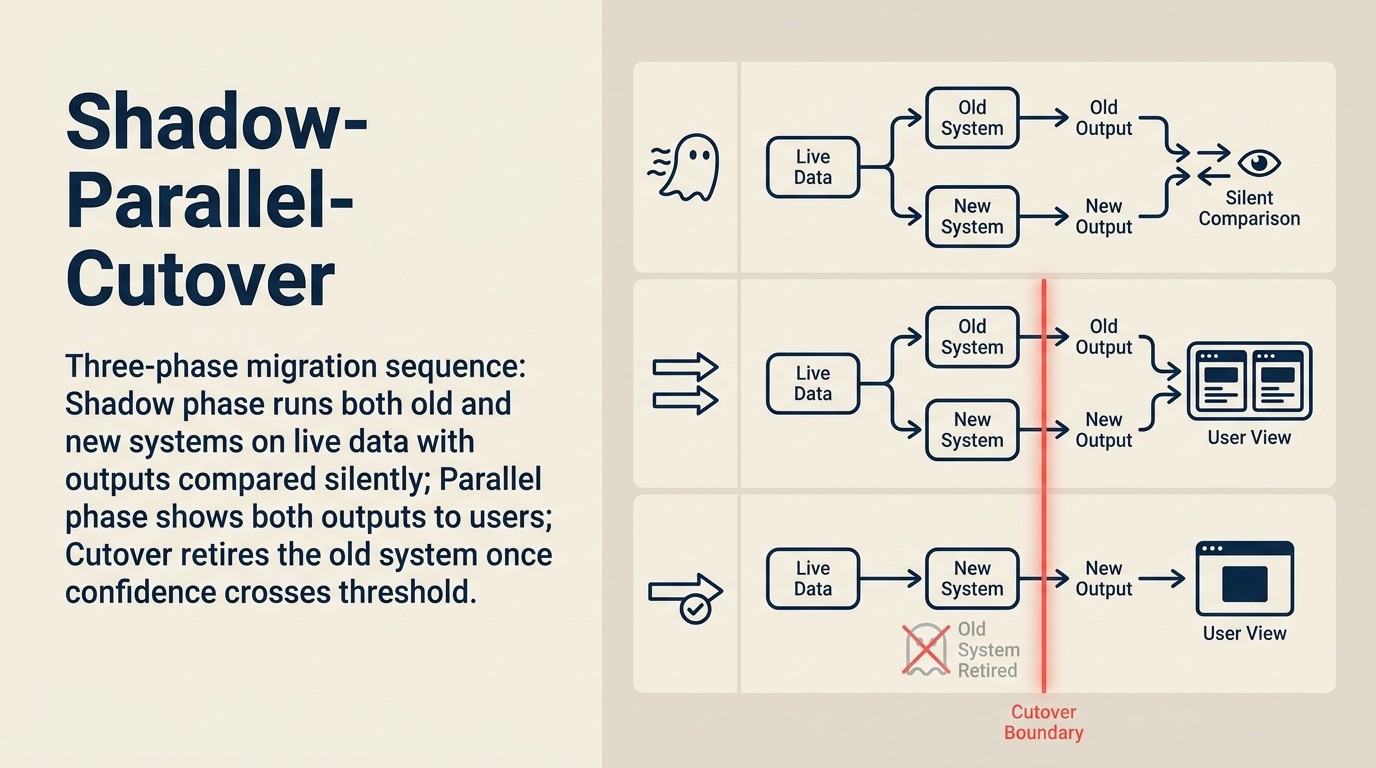
シャドウモードは意味のある動作の違いを検出するのに十分なトラフィックを必要とします。必要なサンプルサイズは気にする検出閾値に依存します。
90%の統計的検出力で古いシステムと新しいシステムの間のアウトプット品質の5%の差を検出するには: 約500〜700の比較可能なペア。月10,000クエリで、それは2〜3日のトラフィックです。月1,000クエリでは2〜3週間です。
Scoring+Routingの場合: スコア分布が正しくキャリブレーションされているかを検証するのに十分なスコアされたレコードが必要です。典型的なルーティング閾値が70の場合、新しいモデルの70が古いモデルの70と同じ意味を持つことを確認するために、その閾値の両側に十分なレコードが必要です。通常スコアの十分位ごとに100〜200レコードが必要です。
シャドウモードでキャッチされないもの: エッジケースでの動作ドリフト。シャドウモードからの比較データセットは実際のトラフィック分布を反映しており、一般的なケースに偏っています。まれだが影響の大きいケース(珍しい契約タイプ、エッジケースの異常、複雑なマルチホップクエリ)は過小表現されています。エッジケースの明示的なテストケースを設計し、シャドウモードのトラフィックだけでなく直接実行します。
| 移行タイプ | 最低シャドウ期間 | カナリア開始 | 主要回帰テスト | 最高リスクパターン |
|---|---|---|---|---|
| インプレースモデル | 14日 | 10%トラフィック | 出力フォーマットの一貫性、指示に従うデルタ | Workflow Copilot(プロンプトの動作変化) |
| アーキテクチャ移行 | 30日 | 5%トラフィック | 200件以上の代表的な入力での完全な動作回帰 | RAG Assistant(完全な再インデックスが必要) |
| ベンダー移行 | 21日 | 10%トラフィック | API応答フォーマットの互換性、レイテンシ比較 | Autonomous Agent(ツールAPIの変化) |
シャドウ-パラレル-カットオーバーシーケンス
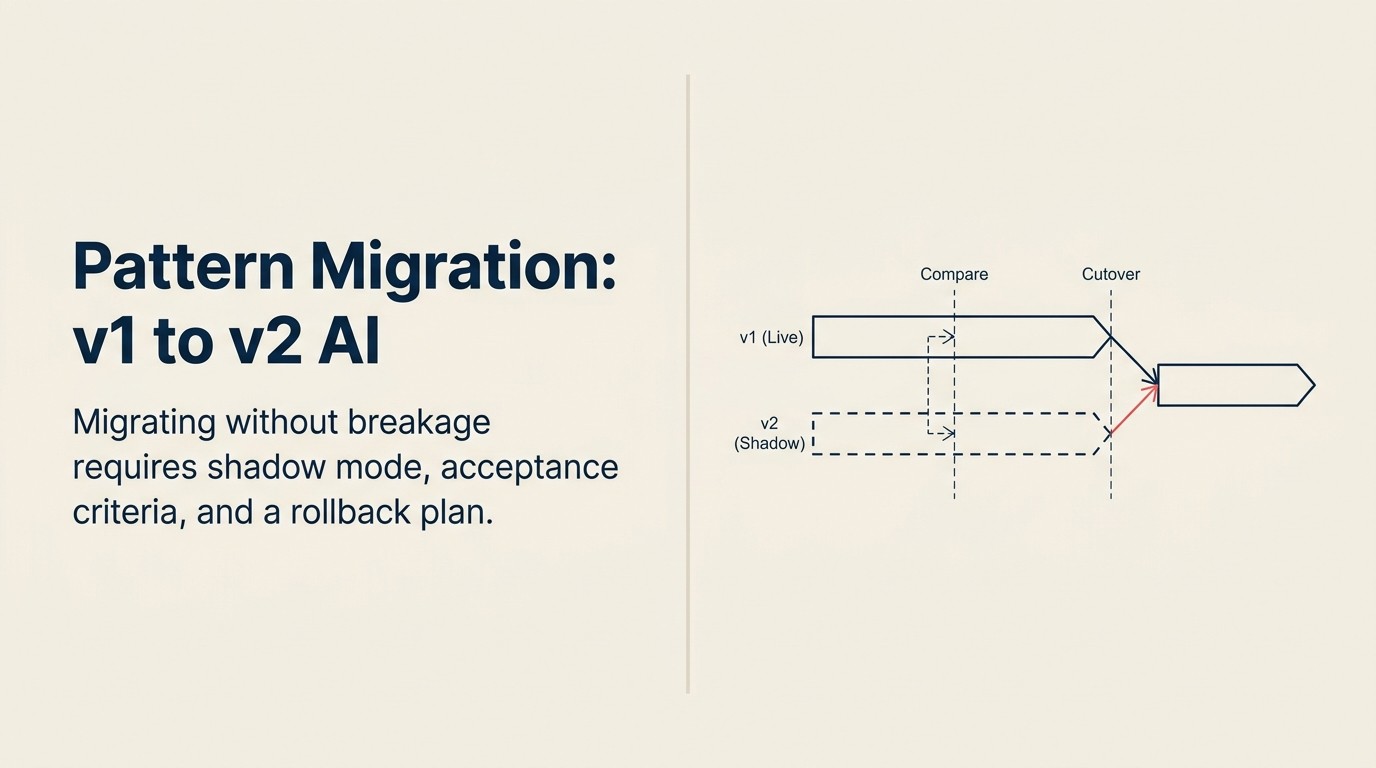
シャドウ-パラレル-カットオーバーシーケンスはAIパターンのアップグレードのための3フェーズの移行フレームワークです。フェーズ1(シャドウ): 新しいシステムを並行してデプロイし、両方のシステムが同じ入力を処理しますが古いシステムのアウトプットだけが本番で使用されます。ログを取り比較します。フェーズ2(パラレル): 定義された割合のトラフィック(1〜10%から開始)を新しいシステムにルーティングします。増分前に48〜72時間、品質シグナルと復帰トリガーを監視します。開始前に承認基準を定義します。フェーズ3(カットオーバー): 少なくとも3つの増分にまたがる段階的なトラフィックシフトがすべての承認基準をクリアした後にのみ100%のトラフィックをプロモートします。カットオーバーの30日後までロールバック能力を活性化したままにします。シャドウからカットオーバーにパラレルフェーズなしで進まないでください。
Rework Analysis: カナリアデプロイが直接カットオーバーと比較して移行インシデント率を70%削減するというMLOpsデプロイ研究と、Rework自身のAIパターンアップグレードからの内部移行データに基づき、シャドウ-パラレル-カットオーバーシーケンスはアップグレードサイクルあたり平均0.4件の移行インシデントを生み出します。直接モデル入れ替えを使用するチームの2.3件に対して。パラレルフェーズはエンタープライズAI移行で最も省略されるステップです。通常「時間がない」と正当化されるチームは、それを省略すると10倍の時間をインシデント対応に費やすことになります。
移行後のユーザーの再オンボーディング
このセクションはほぼすべての移行プロジェクトで省略されます。技術的な移行がクリーンでも信頼負債を生み出します。
AIの動作が変わった時(より良くなった場合でも)、古い動作の周りにメンタルモデルを構築したユーザーは何が変わったかを理解する必要があります。以前よりも長く詳細な提案を生成するようになったWorkflow Copilotは、担当者が知る必要がある動作の変化を生み出します。以前のバージョンより具体的にソースを引用するようになったRAG Assistantは異なるアウトプットを生み出し、ざっと読むことを覚えたユーザーが改善された帰属を見逃すかもしれません。
再オンボーディングはトレーニングプログラムを必要としません。次のことが必要です。
- 変更メモ: 「システムはXを異なる方法で行うようになりました。どのように見えるか説明します。」
- フィードバックチャネル: 「新しい動作があなたのワークフローに悪影響を及ぼす場合はここで教えてください。」
- 見える改善例: 「実際のクエリでの古いアウトプットと新しいアウトプットの比較です。」
再オンボーディングを省略すると、ユーザーが予期しない動作に遭遇して静かに離脱するにつれて、移行の2〜4週間後に使用指標で採用の低下が見えます。新しいシステムはより良いかもしれません。それを知らないユーザーはそこから利益を得ることができません。
パターン別の移行の主要考慮事項
RAG Assistant: エンベディングモデルの選択はインデックス全体の依存関係です。エンベディングモデルを変更するにはナレッジベースのすべてのドキュメントを再エンベディングする必要があります。これはエンタープライズスケールでは素早い操作ではありません。再インデックスの計算を後付けではなく移行ステップとして計画します。また、検索拡張生成のプロンプトはしばしばモデル固有の指示を持ちます。新しいモデルの指示に従う規約のためにプロンプトをレビューして更新します。
Scoring + Routing: 閾値の再キャリブレーションが必要です。古い閾値が新しいモデルに適用されると思わないでください。過去6カ月のラベル付きレコードに対して新しいモデルを実行し、スコア分布をプロットし、本番トラフィックの前に新しい分布に基づいてルーティング閾値を再キャリブレーションします。
Autonomous Agent: 移行開始前にツールAPIの互換性チェック。エージェントが呼び出すすべての外部APIをリストアップし、現在の認証要件と応答フォーマットをレビューし、新しいエージェントバージョンとの互換性を確認します。多段階ループで一つの壊れたツール呼び出しが予測不可能なカスケード失敗を生み出します。
メンテナンスを続けるか移行するかの決定
決定は費用比較になります。レガシーパターンのメンテナンスには年間いくらかかるか(エンジニアリング時間、劣化したアウトプット品質、ユーザーの信頼への影響)、対して移行のコスト(アーキテクチャ作業、テスト、ロールバックリスク、ユーザーの再オンボーディング)はいくらか?
メンテナンスコストが移行コストを超えたら、移行します。数字を入れると計算が明確になります。
手動のナレッジベース更新サイクルを維持するレガシーRAG Assistant: 月8時間のエンジニアリング時間。自動インデックス更新を持つハイブリッド検索アーキテクチャへの移行: 80時間のアーキテクチャ作業。損益分岐点: 10カ月。レガシーシステムに24カ月以上の残存期間がある場合、移行は1年目に経済的に正当化されます。
メンテナンスの負担がパターンが積極的に信頼できなくなるポイントまで蓄積した場合、そのメンテナンスコストはもはやエンジニアリング時間だけではありません。ユーザーの信頼とビジネスの影響です。移行はその時単に経済的に正当化されるだけでなく、緊急になります。
メンテナンスが移行領域に閾値を超えたと示す負債の指標については技術的負債の記事を、移行ベースライン収集を可能にする監査トレイルについてはガバナンスフレームワークを、シャドウモード中に具体的に回帰テストする失敗モードについてはハルシネーションリスクの記事をご覧ください。
移行は蓄積された負債の解決策です。シャドウモード、承認基準、段階的なロールアウトで適切に行えば、ルーティンオペレーションです。適切に行わなければ(完全なカットオーバー、ロールバック計画なし、ユーザーコミュニケーションなし)、インシデントが起きるのを待っているだけです。
移行をうまく行うチームは、最初のデプロイを最終的な回答ではなくv1として扱ったチームです。
よくある質問
シャドウ-パラレル-カットオーバーシーケンスとは何ですか?
シャドウ-パラレル-カットオーバーシーケンスは3フェーズの移行フレームワークです。フェーズ1(シャドウ): 両方のシステムが同じ入力を処理しますが、古いシステムのアウトプットのみが本番に行きます。新しいシステムのアウトプットはログを取り比較されます。フェーズ2(パラレル): 定義された割合のトラフィック(1〜10%から開始)が定義された復帰トリガーを持つ新しいシステムにルーティングされます。フェーズ3(カットオーバー): 少なくとも3つの増分にまたがる段階的なトラフィックシフトが承認基準をクリアした後にのみ100%のトラフィックがプロモートされます。カットオーバーの30日後までロールバック能力が活性化されたままです。
継続的なメンテナンスではなくパターンの移行を引き起こすものは何ですか?
5つのシナリオが移行を引き起こします。ベンダーによるモデルの非推奨化(AIプロバイダーが非推奨のタイムラインを公開する最も明確なトリガー)、データの品質ではなくモデルのケイパビリティが根本原因の大幅な精度の劣化、既存のアプローチを大幅に上回る新しいアーキテクチャケイパビリティ(ハイブリッドRAG対ナイーブなベクター検索では検索品質が20〜40%向上)、新しいアプローチを好むコストの変化、買収、価格再編、廃止を含むベンダー関係の変化です。
どのAIパターンが最も高い移行リスクを持ちますか?
Scoring and Routingは高い移行リスクを持ちます。新しいモデルが異なるスコア分布を生み出し、本番トラフィックの前にルーティング閾値の再キャリブレーションが必要なためです。Autonomous Agentは高い移行リスクを持ちます。エージェントのレパートリーのすべてのツールAPIが互換性確認を必要とし、新しいエージェントバージョンが異なる解析で同じAPIを呼び出すことで予期しないExecuteの動作を生み出す可能性があるためです。Personalization Engineは高い移行リスクを持ちます。古いシステムからのユーザープロファイルの表現が新しいアーキテクチャに移せない可能性があるためです。
カットオーバーの前にシャドウモードはどのくらい実行すべきですか?
インプレースモデル移行には最低14日間。アーキテクチャ移行には最低30日間。必要なサンプルサイズは検出閾値によります。90%の統計的検出力で5%の品質差を検出するには500〜700の比較可能なペアが必要です。月1,000クエリでは30日で統計的に意味のあるデータが得られます。月10,000クエリでは3日で統計的要件には十分ですが、エッジケースと動作ドリフトをキャッチするためには依然として14日間が最低限です。
なぜエンベディングモデルの変更は完全な再インデックスを必要とするのですか?
異なるエンベディングモデルは同じドキュメントに対して異なるベクター表現を生成します。一つのエンベディングモデルのベクターは同じインデックスで異なるモデルのベクターと比較できません。エンベディングモデルを変更するには新しいモデルが本番で使用される前にナレッジベースのすべてのドキュメントを再エンベディングする必要があります。500,000ドキュメントのナレッジベースでの完全な再インデックスは移行の途中で発見されるのではなく、明示的な移行ステップとして計画されなければならない重要なコンピュートイベントです。
AI移行後に最も一般的なユーザーの再オンボーディングの間違いは何ですか?
完全に省略することです。AIの動作が変わった時(より良くなった場合でも)、古い動作の周りにワークフローを構築したユーザーは何が変わったかを理解する必要があります。再オンボーディングを省略するチームは、ユーザーが予期しない動作に遭遇して静かに離脱するにつれて、移行の2〜4週間後に採用の低下を見ます。再オンボーディングはトレーニングプログラムを必要としません。何が変わったかを説明する変更メモ、フィードバックチャネル、実際のクエリでの古いアウトプットと新しいアウトプットの見える比較が必要です。
関連リンク
