Document Review: AIをコンプライアンスの共同操縦士として
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ミッドマーケットのテクノロジー企業は年間約300件のベンダー契約に署名します。すべての契約は会社の標準条件に照らしてレビューされるべきです。異常な免責補償の表現はフラグが立てられるべきです。非標準のIP所有権条項は発見されるべきです。会社の60日標準から逸脱した支払条件は、誰かが署名する前に気づかれるべきです。
実際には、法務チームはこれらの契約の約20%を完全にレビューします。残りの80%は、何を探すべきかを知っているかもしれないし知らないかもしれないオペレーションマネージャーによって素早くスキャンされます。見逃された条項の一部は、ベンダーとの関係が変化した18ヶ月後に問題として戻ってきます。
これは法務チームの能力の問題ではありません。ボリュームの問題です。すべてのドキュメントを徹底的にレビューするのに十分な弁護士時間がないため、厳密さの代わりにトリアージが行われ、例外が見逃されます。
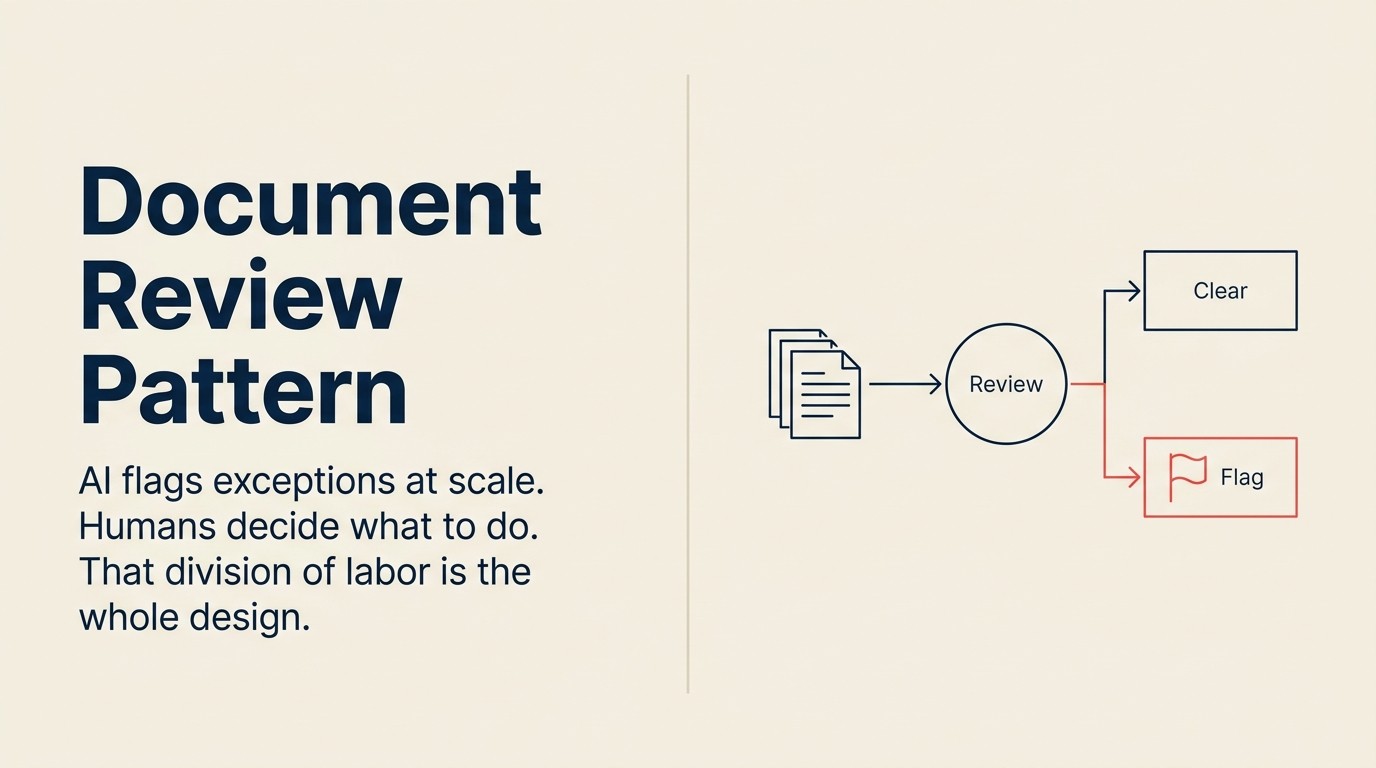
Document ReviewはこのI算数を変えるAIパターンです。法的判断を置き換えることによってではなく(それは以下でカバーするガバナンスの間違いです)、カバレッジをスケールさせることによってです。AIはすべてのドキュメントを読めます。すべての条項を標準と比較できます。どんなに小さくても、すべての逸脱をフラグできます。その後、人間がどの逸脱が重要で何をすべきかを決定します。ABAの2024年法的テクノロジー調査によると、法曹界のAI採用は1年で11%から30%にほぼ3倍に増え、精度への懸念が主な躊躇として残っています。それがまさにこのパターンが取り組むガバナンスモデルです。
このパターンは、ドキュメントを既知の標準と照合する必要がある法務、財務、HR、調達、コンプライアンスのコンテキスト全体で機能します。そして、このパターンのPredictステップは明確に理解する価値のある特定の何かをします: 将来を予測しません。現在のドキュメントをテンプレートと比較して逸脱をスコアリングします。
機能の式: Ingest、Analyze、Predict、Generate
Ingest(ドキュメント) はドキュメントを処理可能な形式でキャプチャします。これはレビューツールにアップロードされたPDF契約書、メールの添付ファイルとして受け取ったWordドキュメント、ベンダーポータルで共有されたSOC 2レポート、またはHRシステムからエクスポートされた従業員同意書のバッチの場合があります。Ingestステップはドキュメントをモデルが解析できる構造化された表現に変換します: ページマーカー、セクション境界、フォーマットの手がかりが保持されたクリーンなテキスト。
Analyze(条項、フィールド、エンティティの抽出) はドキュメントを読んでその構造を識別します。契約書の場合: 当事者、効力発生日、準拠法、各定義用語、各実質的な条項(免責補償、責任制限、支払条件、解約、知的財産、データ処理)を見つけます。モデルは抽出された各要素をタイプ別にラベル付けします。これは単なるテキスト抽出ではありません。意味論的抽出です。モデルは「いずれかの当事者は30日間の書面通知により本契約を解約できる」が、「解約」という単語を含む文ではなく、30日間の通知期間を持つ解約条項であることを理解します。
Predict(標準と比較し、逸脱をスコアリングする) はこのパターンにその名前を与えるステップです。ここで「Predict」が何を意味するかを正確に表現することが重要です: これは将来の結果を予測することではありません。Predictステップは抽出された条項を参照テンプレートと比較して逸脱スコアを生成します。本質的に「この条項は私たちの標準からどれほど異なっているか、その違いは重要か?」と尋ねています。「Net 60」と言う支払条件の条項は会社の標準に一致します。「5日後に2%の延滞手数料が発生するNet 15」と言う支払条件の条項は標準から大幅に逸脱しています。Predictはその逸脱をスコアリングして分類します: 存在対不在、標準対非標準、許容範囲内対例外。
Generate(フラグリスト、レッドライン、例外サマリー) はレビュー出力を生成します。これは検出されたすべての例外、関連する抽出された条項またはフィールド、標準からの逸脱、重大度評価をリストした構造化ドキュメントです。契約書レビューでは、Generateは提案されたレッドラインも生成する場合があります:「条項7.2を会社の標準免責補償表現に置き換えてください」。出力は人間のためのレビューワークパッケージです: 決定ではなく、法的意見でもなく、レビュアーが2時間ではなく20分で処理できる完全で追跡可能なフラグリストです。
Key Facts: Document Review AIの採用と影響
- 法曹界のAI採用は1年で11%から30%にほぼ3倍に増え、精度への懸念が主な躊躇として残っています(ABA Legal Technology Survey、2024年)
- AI Document Reviewは弁護士費用での契約あたりコストを300〜800ドルから、AI処理とオペレーションレビュー時間を含めて契約あたり20〜80ドルに削減し、80〜90%のコスト削減です(Thomson Reuters Legal AI Benchmark、2024年)
- AI Document Reviewを使用する組織は、契約の20〜40%を徹底的にレビューするから、AI第1パスカバレッジ95〜100%に移行し、手動サンプリングの70〜80%対してトレーニングされた逸脱タイプで85〜95%の検出率を達成します(Gartner Legal Ops Report、2025年)
Template-Comparison Method(テンプレート比較法)
Document Reviewは精密な比較メカニズムを通じて価値を提供します: Predictステップは抽出された条項と参照標準の間の逸脱距離を測定し、その逸脱を重大度によって分類します。これには3つの入力が必要です: 提出されたドキュメントからの抽出された条項、その条項タイプに対する会社の参照標準、重要な逸脱を許容可能な変動から区別するキャリブレートされた重大度閾値。明確に定義された参照標準なしには、Predictステップに比較するベースラインがなく、出力は特定の逸脱フラグではなく一般的なコメントになります。Template-Comparison Methodは参照標準をAIモデルと同様に重要にします。チームは条項ライブラリの定義と維持に、レビューツールの選択と設定に投資するのと同じくらいの努力を投資するべきです。
このパターンでの「Predict」の意味
チームがDocument Reviewを初めて接したときの最も一般的な誤解は、Predictステップに結果を予測することを期待することです:「この契約書は問題になるか?」それを確実に行うことはなく、それはパターンが設計されていることでもありません。
Document ReviewのPredictは比較ベースです。モデルは尋ねています: この条項は参照標準と一致するか、それとも逸脱しているか? この保険証書にはこのカバレッジ要件が含まれているか、除外されているか? このベンダーのSOC 2レポートはこのコントロール要件を満たしているか、満たしていないか? それは予測タスクではなく分類タスクです。
参照標準はPredictステップへの主要な入力です。定義された標準(会社の推奨契約条件、コンプライアンスチェックリスト、必要な保険カバレッジレベル)がなければ、比較するものがなく、Predictステップに参照点がありません。比較標準を定義せずにDocument Reviewをデプロイするチームは有用な出力を得られません。Predictが ACE 機能としてどのように機能するかの全体像については、Predict: AIがビジネス結果を予測する方法を参照してください。
詳細な5つの実例
1. NDAのレビュー
スタートアップのオペレーションチームがベンダー、採用候補者、パートナーシップの会話から毎月40件のNDAを受け取ります。各NDAは以下を確認されるべきです: 相互対一方的な機密保持(スタートアップだけが開示者であるone-way NDAは危険信号)、管轄区域(会社の標準はデラウェア州; その他は法的レビューが必要)、存続条項(解約後どのくらい機密保持義務が続くか?)、および公知情報の除外条項。
モデルは各NDAを取り込みます。Analyzeは各ターゲット条項を抽出します。Predictが比較します: 相互か? 管轄区域はデラウェア州か? 存続期間は標準範囲内か? 標準の除外リスト(公知情報、独自開発、第三者から受け取ったもの)が表示されているか?
Generateは各NDAあたり1ページのフラグサマリーを生成します: 緑(例外なし)、黄色(軽微な逸脱)、または赤(重大な例外)。オペレーションチームは緑のNDAを直接実行に回し、黄色のNDAを法務の素早いスポットチェックに、赤のNDAを完全な法的レビューに回します。
このシステム以前は、すべてのNDAが法務に送られていました。実施後は60〜70%が直接回され、法務の時間は実際に必要なものに集中します。
2. ベンダーMSAのレビュー
調達チームが80件のアクティブなベンダー契約を管理し、四半期ごとに25件の新しいベンダーMSAを処理します。レビューチェックリストには以下が含まれます: 支払条件(60日標準)、IP所有権(会社は本契約の下で開発されたすべての成果物を所有する必要がある)、データ処理補足条項(個人データへのアクセスを持つすべてのベンダーに必要)、責任制限(契約額の12ヶ月に上限)、自動更新条項(非更新のために90日間の通知期間が必要)。
モデルは提出されたMSAから各条項カテゴリを抽出します。Predictは標準の条項ライブラリと比較します。よく見つかる逸脱: Net 30で支払いを求める独自の標準条件を提出しているベンダー(逸脱)、含まれるものの明確な定義なしに既存のベンダーIPを切り出すIP所有権条項(曖昧さフラグ)、120日以上前の通知を要求する自動更新条項(90日標準からの逸脱)。
Generateは各逸脱の条項テキスト、会社標準、提案されたレッドラインを含む逸脱テーブルを生成します。法務チームはMSA全体を最初から見るのではなく、逸脱テーブルをレビューします(30分かかります)。
この分野のツール: Ironclad、ContractPodAi、Luminance、Kira Systemsが主要な専用契約書レビュープラットフォームです。LLMと構造化抽出プロンプトを使用した汎用アプローチも小さなチームに広く使用されています。
3. 保険ポリシーの比較
リスクマネージャーが会社の新しい一般責任、E&O、サイバー保険ポリシーが会社の保険ポリシーチェックリストに指定された最低カバレッジ要件を満たしていることを確認する必要があります。チェックリストには以下が指定されています: 発生あたりと総計の最低カバレッジ額、必要な特約条項、保険会社の格付け要件、禁止される除外条項。
モデルは各ポリシードキュメントを取り込みます(セクション間の相互参照がある密度の高い40〜80ページのPDFであることが多い)。Analyzeはカバレッジ限度額、特約条項、除外条項、保険会社情報を抽出します。Predictは各抽出された値をチェックリスト要件と比較します: サイバーポリシーの発生あたり限度額は500万ドルの最低限を満たしているか? 必要な事業中断の特約条項が含まれているか? 除外条項のセクションには禁止された除外タイプのいずれかが含まれているか?
Generateはカバレッジコンプライアンスマトリックスを生成します: 各要件、ポリシーの条項、合格/不合格/フラグのステータス。ギャップはギャップを生み出す具体的な条項の表現とともに強調されます。
4. セキュリティベンダーのSOC 2レビュー
情報セキュリティチームがクラウドベンダーから年間35件のSOC 2 Type IIレポートをレビューします。各レポートは会社のベンダーセキュリティ要件に照らして確認されるべきです: カバーされている特定のコントロールカテゴリ(可用性、機密性、処理の完全性)、適格意見か例外付き適格意見か、会社が要求する特定のコントロール、レポート期間(12ヶ月以内に最新のものでなければならない)。
手動のSOC 2レビューはレポートあたり3〜4時間かかり、SOC 2の構造とコントロールの表現に関する特定の知識を持つアナリストが必要です。モデルは各SOC 2レポートを取り込み、抽出します: カバーされているトラストサービスカテゴリ、監査法人と意見タイプ、レポート期間、特定の必要なコントロール(保存時の暗号化、アクセスコントロール、インシデント対応手順)がテストされたコントロールに現れるかどうか。
Predictがフラグします: 適格意見のレポート(セキュリティチームの完全なレビューが必要)、欠落している必要なコントロールカテゴリ、期間終了日が12ヶ月以上古いレポート。Generateは合格/不合格のステータスとフォローアップが必要な特定のフラグを含むベンダーセキュリティレビューサマリーを生成します。
5. ドキュメント完全性のための医療カルテレビュー
医療施設が患者カルテが請求と診療継続性のためのドキュメント標準を満たしていることを確認する必要があります。カルテには以下が含まれる必要があります: 問題リスト、薬剤調整ノート、処置の文書化されたインフォームドコンセント、主治医が署名したケアプラン。欠落したドキュメントは請求リスクと診療継続性のギャップを生み出します。
モデルは各カルテを取り込みます(EHRエクスポートからの構造化PDFであることが多い)。Analyzeが抽出します: 必要な各ドキュメント要素が存在するか、各セクションに誰が署名したか、日付が必要な時間枠内にあるか。Predictは各カルテをドキュメント標準に対する完全性についてスコアリングします。
Generateはカルテごとのドキュメント完全性レポートを生成します: どの要素が存在するか、どれが欠落しているか、請求提出前に追加の署名または日付確認が必要なもの。施設マネージャーはすべてのカルテを再読するのではなく、フラグをレビューします。
失敗モード: Document Reviewを壊すもの
| 失敗モード | 根本原因 | 軽減策 |
|---|---|---|
| 新しい条項タイプ | モデルがトレーニングで見ていない条項タイプが既知のタイプとして誤分類されるか、完全に無視される | 出力に「未分類の条項」フラグを組み込む。既知のタイプにマッピングされない条項セグメントは人間によるレビューのために明示的に表面化されるべき。 |
| 相互参照の失敗 | セクション3の条項がセクション12の条項を実質的に修正する; モデルはそれぞれを独立してレビューする | Analyze中に相互参照チェックパスを実行する: 条項Aが別のセクションを参照する場合、両方を抽出して複合条項として扱う。これは技術的に対処が最も困難な失敗モードです。 |
| 偽フラグ疲労 | モデルが重要性に関係なくすべての軽微な逸脱をフラグし、レビュアーがフラグを無視し始める | 重大度スコアリングをキャリブレートする。すべての逸脱が同様に重要なわけではありません。3段階のフラグを構築する: 赤(法的決定が必要な重大な逸脱)、黄色(許容範囲内の逸脱、レビュー推奨)、緑(例外なし)。 |
| 信頼度の過大表明 | モデルがトレーニングセットにない微妙な修正を持つ条項に対して「標準的な免責補償表現」と報告する | 出力に条項ごとの信頼度スコアを要求する。フラグステータスに関わらず、信頼度が80%を下回る条項は人間によるレビューのために表面化する。 |
| 標準ドキュメントのドリフト | 会社の標準契約条件が6ヶ月前に更新されたが、モデルはまだ古い標準と比較している | 参照標準をバージョン管理されたドキュメントとして扱う。テンプレートが変更されるたびに比較標準をレビューして更新する。 |
| コンテキストの崩壊 | セクション1の定義用語がセクション14の条項の意味を変える; モデルはその定義なしにセクション14を解釈する | 各条項を分析する際にセクション1からの定義用語を分析コンテキストに注入する。これはデータの問題ではなく、プロンプトエンジニアリングの要件です。 |
偽フラグ疲労は特に法務オペレーションで有害です。解決しようとしていた元の問題を模倣するからです。契約の80%を法的対応が必要としてフラグするDocument Reviewプロセスは、余分なステップがある手動レビューに過ぎません。よくキャリブレートされた商用Document Reviewツールは、本当に重要な例外に法的対応を集中させるために、契約の25〜35%がフォローオンのための人間によるフォローアップとしてフラグされる率を目標とし、ボリュームを生み出すのではなく重要な例外を集中させます(Ironclad Customer Benchmark Report、2025年)。
相互参照の失敗は最も高いコストを持つ失敗モードであるため、具体的な例に値します。契約書にはセクション7に免責補償条項があり、独立して見ると標準的に見えるかもしれません。しかしセクション2はセクション7での「損害賠償」の意味を劇的に拡大する方法で「損害賠償」を定義しています。セクション2の定義を適用せずにセクション7を読むモデルは、誤った「標準条項」評価を生み出します。唯一の軽減策は相互参照分析ステップを構築することです。しかし多くの商用ツールはこれをうまく行いません。完全な失敗モードマップについてはAIパターン別ハルシネーションリスクを参照してください。
ガバナンスの境界線: フラグリストであり、法的意見ではない
このポイントはこの記事のガバナンスセクションと結論の両方に現れます。なぜなら、これはチームが犯す最も一般的なガバナンスの間違いだからです。
Document Reviewの出力はフラグリストです。法的意見ではありません。
AI Document Reviewはあなたの標準と何が異なるかを教えてくれます。その違いが法的に重要かどうか、裁判所がそれを執行するかどうか、この特定の関係でそれが受け入れられるビジネスリスクかどうか、またはどのような交渉ポジションを取るべきかは教えてくれません。
それらは法的判断です。弁護士が必要です。AIは法的判断が必要なものを識別する作業を加速します。判断そのものを置き換えるのではありません。
ガバナンスの間違い: 調達オペレーションチームが、逸脱を法務にルーティングせずにDocument Reviewの出力を使って署名/署名しない決定を行い始めます。これは逸脱が本当に軽微な契約の90%については問題なく機能します。日常的に見えた逸脱が重大な法的影響を持つ10%については費用のかかる失敗をします。
正しい運用モデル:
- AI Document Reviewはすべての契約で実行される
- 出力は定義されたレビュアーに送られる(契約タイプとリスクレベルに応じて、法務、オペレーション、コンプライアンス)
- AIではなくレビュアーが各フラグについて判断する
- 高リスクフラグ(赤ティア)は法的判断のために弁護士に送られる
- 低リスクフラグ(緑ティア)は法務関与なしにオペレーションが承認できる場合がある
- 「オペレーションが決定できる」と「法務が決定しなければならない」の境界は明示的に定義されて年次でレビューされる
監査証跡もここでは重要です。規制対象業界(金融サービス、医療、上場企業)は、完全な情報にアクセスした資格のある人間によって契約レビューの決定がなされたことを証明する必要がある場合があります。人間のサインオフがあるフラグリストはその要件を満たします。AIのみのレビューは満たしません。GDPRおよび同様のデータ保護規制は、個人データの自動処理に対して文書化された意思決定プロセスを要求し、ベンダー契約は日常的にそのようなデータを含みます。
Document Reviewが機能するとき(しないとき)
うまく機能する場合:
- 比較するための明確で文書化された標準がある。「このNDAは相互か?」は定義された比較です。「この契約書は公正か?」は違います。
- ドキュメントが予測可能な構造に従っている。標準的な商業契約(NDA、MSA、雇用契約、保険証書)は条項抽出が信頼性高くなる十分な構造的一貫性を持っています。異常または高度にカスタマイズされたドキュメントタイプはより多くの設定が必要です。
- パターンは日常的な逸脱検出であり、例外分析ではない。Document Reviewは標準から明らかに外れた逸脱の80%を見つけることに優れています。文脈的判断を必要とする繊細な20%にはそれほど信頼性がありません。
vs. RAG Assistant: RAG Assistantはドキュメントに関する質問に答えます。「この契約書の解約通知期間は何か?」はRAGの質問です。Document Reviewは定義された参照に対して構造化されたコンプライアンス分析を実行します。「解約条項は私たちの標準要件を満たしているか?」はDocument Reviewです。両方が同じドキュメントに順番に適用される場合があります。
vs. Generative Research: Generative Researchは多くのソースにわたって合成して新しいインサイトを生み出します。Document Reviewは既知の標準に対して1つの特定のドキュメントを監査します。異なる入力、異なる出力。組み合わせることができますが(市場ベンチマークから比較標準を構築するGenerative Research; その標準を受信した契約書に適用するDocument Review)、代替案ではありません。
vs. Vision Extract: Vision ExtractはDocument Reviewの前のステップであることがよくあります。Vision ExtractはDocument Reviewモデルが分析できる構造化テキストを作成するために、画像またはPDFからフィールドとテキストを抽出します。スキャンされたPDFとして受信した契約書(一部の業界では一般的)では、Vision Extractが最初に実行され、その後Document Reviewが抽出されたテキストを分析します。
ROIシグナル: 影響の測定
| 指標 | 手動のベースライン | Document Review使用時 | 典型的な改善 |
|---|---|---|---|
| ドキュメントあたりのレビュー時間 | 2〜4時間(弁護士)または45〜90分(オペレーション、それほど徹底的でない) | 15〜30分(AIフラグリストのレビュー) | 75〜85%の時間削減 |
| ドキュメントカバレッジ率 | 契約の20〜40%が徹底的にレビューされる | AI審査95〜100%; 人間フォローオンが40〜60% | サンプリングから完全カバレッジへ |
| 例外検出率 | 人間レビューで重大な逸脱の70〜80%が発見される | トレーニングされた逸脱タイプでAI検出率85〜95% | キャッチ率が10〜20%改善 |
| 契約レビューあたりのコスト | 300〜800ドル(市場レートの弁護士費用) | 20〜80ドル(AI処理 + オペレーションレビュー時間) | 契約あたり80〜90%のコスト削減 |
| 法務チームの時間の再配分 | 法務時間の60〜70%が日常的な契約書レビューに | 日常的なレビューに20〜30%; 複雑/重要な作業に70〜80% | より高い価値の作業のための法務チームのキャパシティ |
カバレッジ率の指標は多くの場合最も意味のあるものです。「契約の20%がレビューされる」から「100%がAIによってレビューされ、フラグが立てられた契約が人間によってレビューされる」に移行することは、リスクプロファイルを意味のある形で変えます。McKinseyのコーポレート機能におけるAIの分析は、スピードではなくカバレッジが制約条件であるため、法務とコンプライアンスをAIが不均衡な価値を提供する領域として特定しています。以前は全くレビューされていなかった契約が少なくとも第1パスのカバレッジを持つようになります。
Rework分析: 最も費用のかかるDocument Reviewのガバナンスの間違いは、フラグリストが法的判断を置き換えることを許可することです。AI Document Reviewはカバレッジのスケールに優れています: すべての契約書を読み、すべての条項を比較し、すべての逸脱を表面化させます。できないのは、特定のベンダーとの関係のコンテキストでの特定の逸脱が受け入れられるビジネスリスクかどうかを決定することです。その判断は弁護士を必要とします。困難に陥らないチームはAI Document Reviewを使って「読まなかったから発見できなかった」問題を排除し、すべての重要なフラグを弁護士にルーティングします。問題に陥るチームはAI Document Reviewを使って弁護士関与を完全に排除し、逸脱の10%がAIが提供できないコンテキストを必要とすることを発見し、10分の法的レビューで発見できたはずの条項を巡って訴訟になります。
よくある質問
Document Review AIパターンとは何ですか?
Document Reviewは特定のドキュメントを定義された参照標準と照合して逸脱、欠落要素、コンプライアンスのギャップをフラグする AIパターンです。式は: Ingest(ドキュメント)、Analyze(条項とエンティティを抽出する)、Predict(抽出された条項を参照標準と比較し逸脱をスコアリングする)、Generate(フラグリスト、レッドライン、またはコンプライアンスサマリー)です。弁護士時間を比例的にスケールさせることなく、レビューカバレッジをサンプリングから完全カバレッジにスケールさせます。
Template-Comparison Method(テンプレート比較法)とは何ですか?
Template-Comparison Methodは Document Review パターンのPredictステップのコアメカニズムです。抽出された条項とその条項タイプに対する会社の参照標準の間の逸脱距離を測定し、重大度によって逸脱を分類します。このメソッドには3つの入力が必要です: 抽出された条項、参照標準条項、キャリブレートされた重大度閾値。明確に定義された参照標準なしには、Predictステップは特定の逸脱フラグではなく一般的なコメントを生み出します。参照標準はAIツール自体と同様の投資に値します。
Document ReviewとRAG Assistantの違いは何ですか?
RAG Assistantはドキュメントに関する質問に答えます。「この契約書の解約通知期間は何か?」はRAGの質問です。Document Reviewは定義された参照に対して構造化されたコンプライアンス分析を実行します。「解約条項は私たちの標準的な30日通知要件を満たしているか?」はDocument Reviewです。両方が同じドキュメントに順番に適用される場合があり、本番の法務オペレーションWorkflowでよく組み合わされます。
AI Document ReviewからどのようなROIを期待できますか?
AI Document Reviewは弁護士費用での契約あたりコストを300〜800ドルから20〜80ドルに削減します(80〜90%のコスト削減)。カバレッジ率は契約の20〜40%が徹底的にレビューされるから、AI第1パスカバレッジが95〜100%に改善されます。例外検出は手動サンプリングの70〜80%からトレーニングされた逸脱タイプで85〜95%に改善されます。法務チームの時間が日常的なレビューの60〜70%から20〜30%に再配分され、70〜80%が複雑で重要な作業のために解放されます。
AIはDocument Reviewで法的決定を行えますか?
いいえ。Document Reviewの出力はフラグリストであり、法的意見ではありません。AIはあなたの標準と何が異なるかを教えてくれます。逸脱が法的に重要かどうか、裁判所がそれを執行するかどうか、それが受け入れられるビジネスリスクかどうか、またはどのような交渉ポジションを取るべきかは決定しません。それらは弁護士を必要とする法的判断です。正しい運用モデルは重要なフラグ(赤ティア)を法的判断のために弁護士にルーティングします。オペレーションチームは軽微なフラグ(緑ティア)を弁護士関与なしに処理できる場合がありますが、「オペレーションが決定できる」と「法務が決定しなければならない」の境界が明示的に定義されている場合のみです。
最も一般的なDocument Reviewの失敗モードは何ですか?
6つの主な失敗モードは: 新しい条項タイプ(トレーニングデータになかったため誤分類または無視される)、相互参照の失敗(条項Aが条項Bを修正するが両方が独立してレビューされる)、偽フラグ疲労(重要性が低すぎる多すぎるフラグがレビュアーにキューを無視させる)、信頼度の過大表明(モデルが微妙に修正された条項に「標準表現」と報告する)、標準ドキュメントのドリフト(参照標準が更新されたがモデルはまだ古いバージョンと比較する)、コンテキストの崩壊(セクション1からの定義用語がセクション14の条項の分析時に適用されない)です。相互参照の失敗は他のセクションで範囲が拡大された条項に対して偽の「標準条項」評価を生み出すため、最も高い法的コストを持ちます。
参考リンク

Co-Founder, Rework.com