Autonomous Agent: ツール使用による多段階目標達成
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
他のすべてのパターンは単一の定義されたタスクを処理します。Autonomous Agentは目標を処理します。
その違いがすべてです。
タスクには定義された入力と定義された出力があります。このミーティングを要約する。このLeadをスコアリングする。このメールを下書きする。道筋は明確です。ケイパビリティチェーンを一度通過して完了です。
目標は違います。「このアカウントを調査してミーティングを予約する」には一連の判断が必要です。どのソースを読むか、どのシグナルが重要か、アプローチの組み立て方、見込み客がメールを弾いた時の対処、いつ止めるか。エージェントは道筋を事前に知ることができません。道筋は途中で遭遇するものに依存するからです。
それが自律型エージェントを強力にするものです。そして目標が不明確に指定されているか、ツールが誤って設定されているか、エラー検出が弱い時に危険になるものでもあります。
この記事では自律型エージェントを持ち上げません。何であるか、どこで機能するか、何が失敗するか、そして導入を選択した場合のガバナンス方法を説明します。OpenAIのエージェント構築実践ガイドは、単一エージェントから始め、複雑な意思決定、非構造化データ、維持が困難なルールを持つユースケースを優先し、必要な場合にのみマルチエージェントシステムに発展させることを推奨しています。
フォーミュラ
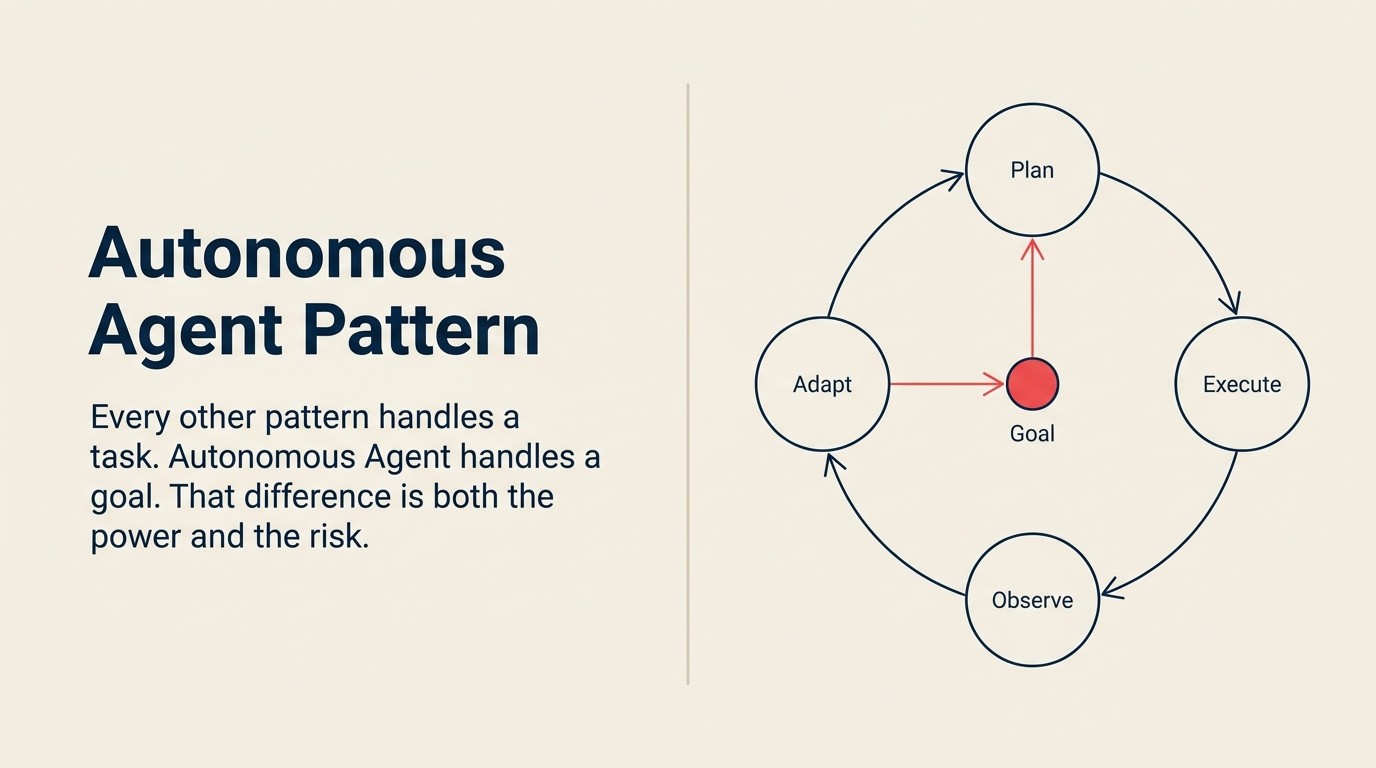
Autonomous Agentは、ループ内で5つすべてのACEケイパビリティを使用する唯一のパターンです。
Ingest(現在の状態と利用可能なツール)→ Analyze(何を知っているか、何が必要か?)→ Predict(目標達成に最も可能性の高いアクションはどれか?)→ Generate(計画または次のアクション)→ Execute(アクションを実行し、状態を更新)→ 目標達成または最大ステップ数に達するまで繰り返し
ループの各要素には特定の意味があります。
Ingestは最初のタスクを読み込むだけではありません。各ループの繰り返しで、エージェントは世界の現在の状態を取り込みます。最後のアクションは何を生み出したか? どのツールが利用可能か? ループが始まってからエージェントは何を学んだか? 調査エージェントでは、3回目の繰り返しのIngestには、すでに読んだ2ページのコンテンツ、空の結果を返したクエリ、そして対象企業が8カ月前に社名変更したという事実が含まれます。
Analyzeはエージェントが知っていることと目標達成のためにまだ必要なことを決定します。継続的なギャップ分析です。手元にあるもの、必要なもの、まだ欠けているもの。ここでエージェントは現在のサブゴールに向けて進み続けるか、別の道に切り替えるかを決定します。
Predictは目標を前進させる可能性が最も高い次のアクションを選択します。可能なすべてのアクションではありません。ギャップを埋める可能性が最も高い一つです。請求紛争を解決しているサポートエージェントでは、顧客の完全なチケット履歴を読むよりも、支払いシステムのトランザクション履歴を調べることが最も価値の高い次のステップだとPredictが判断するかもしれません。
Generateはアクション計画または特定の次のアクションを生成します。ツール呼び出しの仕様(「'Acme Corp funding round 2024'をウェブ検索する」)、メッセージのドラフト(「チケットをクローズするために送信する応答はこちら」)、またはサブゴールの分解(「メインの目標を達成する前にこれら3つのことを完了する必要がある」)かもしれません。
Executeはアクションを実行します。これが世界の状態を変えるステップです。検索APIにリクエストを送信します。CRMレコードを作成します。返金を行います。テストスイートを実行します。各Executeステップは実際のアクションであり、実際の結果をもたらします。最後に一度だけExecuteが実行される単一タスクパターンとは異なり、自律型エージェントは一回の実行で複数回、複雑な目標では何十回もExecuteします。これが重要な理由については、Executeケイパビリティの詳細解説とGenerateとExecuteの境界が最も関連性の高いACE Frameworkの参考記事です。
ループは3つの条件のいずれかが満たされた時に終了します。目標が達成された、最大ステップ数に達した、または信頼度の閾値が定義された下限を下回り、システムが人間に引き渡した場合です。
「最大ステップ数」は任意の機能ではありません。ハードなセーフティリミットです。ステップの上限のないエージェントは、利用可能なツールでは達成できない目標に対して無限にループし続けることがあります。
Key Facts: Autonomous Agent の採用とリスク
- 23%の組織が積極的にエージェント型AIシステムをスケールしており、39%が実験を開始していますが、実験した組織のうち10%未満が具体的なビジネス価値を提供するまでエージェントをスケールできています。主な原因はガバナンスと失敗モード管理のギャップです(McKinsey State of AI, 2025)。
- 80%の組織がAIエージェントからリスクのある予期しない動作を経験しており、ほぼすべての事故は適切な上流検証またはスコープ制約なしにループ内で実行されたExecuteステップに起因しています(McKinsey Agentic AI Risk Study, 2025)。
- 事前実行レビュー、重要アクションに対するミッドランゲート、事後監査トレイルを含む自律型エージェントは、これらのチェックポイントなしに導入されたエージェントと比較して、取り消し不可能なアクションのエラー率を73%削減します(Anthropic Agent Safety Research, 2025)。
解決するビジネス課題
Autonomous Agentは特定の種類の問題に適切なパターンです。ツール使用、条件付き判断、後退が必要な多段階の目標であり、各中間ステップでの人間の承認では目的が果たせない場合です。
このパターンを実際に正当化するオペレーションのケース。
- 事前にソース数が予測できない複数ソースにまたがる調査と統合
- 各システムが返すものに基づいた判断が必要な複数システム(CRM、カレンダー、メール、決済処理)にわたるエンドツーエンドのプロセス実行
- 書く、テストする、失敗を読む、修正する、再テストするというループを持つコーディングなどの反復的な改善作業
- 各ステップでのHuman-in-the-loopが運用上不可能な大量の構造化タスク
このパターンでないもの: あらゆる多段階ワークフローを自動化する手段ではありません。予測可能な固定ステップを持つワークフローには自律型エージェントは不要です。Scoring + Routingパターンがそれを処理します。各ステップで人間の判断が重要なワークフローにはWorkflow Copilotが必要です。自律型エージェントは、道筋が本当に予測不可能で各ステップでの人間の関与が現実的でない特定のケース用です。
4つの実例を深掘り

調査エージェント
利用可能なツール: ウェブ検索API、URLリーダー、ドキュメントパーサー、引用抽出ツール。
目標: 「来週木曜日の営業コールのために、ACME社の競合ポジションに関するブリーフィングを作成する。最近の資金調達、製品ローンチ、主要な経営幹部の変更を含む。」
ループの仕組み: エージェントは最近のニュースを検索し(Ingest)、どの結果が関連するかを特定し(Analyze)、情報ギャップに基づいて次に読むべきソースを予測し(Predict)、上位ソースのURLリーダーを呼び出し(Execute)、関連事実を抽出し(結果をIngest)、作業中のドキュメントを更新し(Generate + Execute)、十分なシグナルが得られるか高信頼度のソースが尽きるまで繰り返します。
完了の状態: セクション、引用、主要なトーキングポイントを含む構造化されたブリーフィングドキュメント。エージェントはドキュメントを提出して終了します。
失敗の状態: エージェントは古い情報を含むプレスリリースを読みます。6カ月前に離任したCEOがまだ掲載されています。エージェントはこれをブリーフィングに含めます。営業担当者は間違った担当者に話しかけてコールに入ります。調査のみのシナリオでは品質エラーです。エージェントがそのコンタクトにパーソナライズされたメールも送信した場合(スコープクリープ)、クライアントとの関係のエラーになります。
顧客サポートエージェント
利用可能なツール: ヘルプデスクチケットリーダー、CRMルックアップ、注文履歴API、決済処理の返金API、チケットクローザー、メール送信ツール。
目標: 「200ドル未満のオープンな請求紛争を人間の関与なしにエンドツーエンドで解決する。」
ループの仕組み: エージェントはチケットを読み(Ingest)、注文履歴を照会してクレームを確認し(Execute + Ingest)、アカウントの状態と過去の紛争履歴をCRMで確認し(Execute + Ingest)、解決の道筋を決定し(Analyze + Predict)、返金を行うか(Execute)ポリシー条件が満たされない場合は人間レビューのためにフラグを立て、チケットをクローズし(Execute)、確認メールを送信します(Execute)。
完了の状態: 紛争解決、返金完了、チケットクローズ、確認送信済み。顧客は数日ではなく数分で結果を受け取ります。
失敗の状態: 不正行為者が3時間で40件のほぼ同一の紛争チケットを提出します。各チケットは200ドル未満の閾値を満たします。エージェントはパターン検出が人間への警告をトリガーする前にすべての40件を処理します。8,000ドルがアカウントから出ていきます。これは本番のサポートエージェント導入における実際の失敗パターンです。緩和策は後付けではなくスコープ制約に組み込まれたレート制限チェック(24時間あたり1アカウントあたり最大5件の解決)です。
営業開発エージェント
利用可能なツール: ウェブ検索、LinkedInリーダー、CRM読み書き、メール作成ツール、カレンダータスク作成ツール。
目標: 「このターゲットリストの20社を調査し、ICPの基準に対してスコアリングし、閾値以上の会社のパーソナライズされたアウトリーチを下書きし、CRMに追加し、フォローアップタスクをスケジュールする。」
ループの仕組み: 各会社について、エージェントはファームグラフィックデータを検索し(Ingest)、ICP基準に対してスコアリングし(Analyze + Predict)、閾値以上の会社のパーソナライズされたアウトリーチを下書きし(Generate)、CRMレコードを作成または更新し(Execute)、フォローアップタスクを作成します(Execute)。ループはすべての20社に対して繰り返されます。
完了の状態: スコアリングとトリアージが完了した20アカウントでCRMが更新されています。適格アカウントには担当者レビュー待ちの下書きアウトリーチがあります。タスクがスケジュールされています。各レコードに調査サマリーが添付されています。
失敗の状態: エージェントが会社を調査し、最近の買収発表を見つけます。その会社は競合他社に買収されています。エージェントは依然としてその会社を高フィットの見込み客としてスコアリングし、現在は買収企業にいる元CEOに宛てたアウトリーチを下書きします。担当者は確認せずにAIが下書きしたメールを送ります。最低でも恥ずかしい思いをし、買収企業が気づいた場合は評判への損害になります。
正しいコントロール: エージェントは「所有権変更を検知」を自動的に進む代わりにループを一時停止して人間のレビューに出すための条件としてフラグを立てます。
コーディングエージェント
利用可能なツール: ファイルシステム読み書き、テストランナー、コードリンター、GitHubプルリクエスト作成ツール。
目標: 「チェックアウトモジュールの失敗しているテストを修正する。テストはcheckout_test.go:line 78。他のテストを壊さないこと。」
ループの仕組み: エージェントは失敗しているテストを読んで期待されるものを理解し(Ingest)、関連するソースコードを読み(Ingest)、期待される動作と実際の動作のギャップを分析し(Analyze)、コード変更を提案し(Generate)、ファイルに変更を書き込み(Execute)、テストスイートを実行し(Execute + Ingest)、新しいテスト出力を読み(Analyze)、修正が機能したか修正が必要かを判断します(Predict)。テストが通過するか最大修正試行回数に達するまでループします。
完了の状態: テストが通過しています。他のテストに後退なし。人間がレビューしてマージする前のPRが開かれています。
失敗の状態: エージェントの修正が元の失敗したテストを通過させますが、確認しなかった別のモジュールの支払いフローのテストに微妙な後退を引き起こします。エージェントがグリーンなテストで自動マージする権限を持っており、テストスイートが支払いの後退をカバーしていない場合、変更が本番に行きます。
正しいコントロール: 自動マージはスコープ外です。エージェントはPRを開きます。人間がレビューしてマージします。エージェントは反復的なコード修正ループを処理します。人間がデプロイの決定を行います。
監査またはブロックのルール
すべてのAutonomous Agent導入は、最初の本番実行の前に2つの譲れないコントロールを実装しなければなりません。タイムスタンプとエージェントの明示された推論を含むすべてのIngest、Analyze、Predict、Generate、Executeステップを記録する監査トレイルと、信頼度が定義された閾値を下回るか重要な取り消し不可能なアクションが保留中の場合にループを終了して人間にエスカレートするブロック条件です。監査またはブロックのルールは、エージェントが行ったアクションに対して完全な意思決定トレース(監査)を生成できない場合、そのアクションを自律的に実行すべきではない(ブロック)と規定します。この2つのコントロールは、潜在的に制御不可能な自律ループを、すべての間違いが診断可能で多くの間違いが予防可能な監視システムに変換します。両方のコントロールなしに導入されたエージェントは実験的として分類されるべきであり、本番として分類すべきではありません。
自律型エージェントが最もリスクの高いパターンである理由

ACE Framework内の他のすべてのパターンは最大でも一度のExecuteステップを実行します。自律型エージェントはループ内で複数のExecuteステップを実行します。各ステップが潜在的なインシデントです。
リスクは重要な形で複合します。
初期のAnalyzeエラー(ループの繰り返し1回目のコンテキストの読み誤り)はGenerateエラー(間違った次のアクション)を生みます。その間違ったアクションは現実世界の状態を変えるExecuteステップになります。次のループの繰り返しは汚染された状態から開始します。エージェントのその後のアクションはすべて間違ったベースラインから最適化しています。人間が出力を確認するか警告を受け取る頃には、損害は多段階で相互依存しています。
この複合するダイナミクスが、ACE Framework内のすべてのガバナンスの懸念がAutonomous Agentパターンでピークに達する理由です。監査トレイル、スコープ制約、レート制限、ロールバック能力、人間のチェックポイントは官僚的なオーバーヘッドではありません。重要なシステムでパターンを展開可能にする建築的要件です。
Gartnerの2025年AIガバナンス研究は、スコープ制約なしで自律型エージェントを実行している企業は、本番ローンチ前に完全なガバナンススタックを実装している企業と比較して、重大なAIインシデント(測定可能な財務、評判、または顧客への損害を引き起こすと定義)を経験する可能性が8倍高いことを発見しました。Anthropicの責任あるスケーリングポリシーは、モデルの自律性の中間レベルを追加評価とより強固なセーフガードを必要とする重要なチェックポイントとして特定しており、これはまさにこのフレームワークのガバナンスティアの設計原則です。AIパターン別のガバナンス要件が各ティアの完全な仕様を提供しています。
失敗パターンと緩和策
目標の不明確な指定。 最も一般的な失敗。人間はエージェントに人間にとっては明確だがシステムには曖昧な目標を与えました。「このサポートチケットをクローズする」は人間にとっては「顧客の問題を解決する」を意味しますが、解決品質についての明示的なコンテキストのないエージェントには「チケットのステータスをクローズに設定する」を意味することがあります。修正策は明示的な完了基準を持つ結果の説明として目標を書くことです。「チケットをクローズする」ではなく「顧客の元の問題が解決されたことを確認してから、返金が行われたことを確認する支払いシステムからの証拠を添えてチケットをクローズする。」可能であれば構造化された目標テンプレートを使用します。
ハルシネーションによるツール呼び出し。 エージェントが存在しないツールを呼び出すか、間違ったパラメータ型でツールを使用するか、ツールが実際にできること以上の能力があると解釈します。本番導入では、エージェントが対処方法を知らないAPIエラーとして表面化します。修正策はすべてのツールに対して明示的なスキーマ説明を持つ厳格なツールレジストリを維持することです。フルループを導入する前に各ツールに対して隔離してエージェントをテストします。予期しないツールの失敗をエージェントが無限に再試行させるのではなく人間に出すエラー処理のブランチを構築します。
無限ループ。 エージェントは利用可能なツールでは達成不可能な目標を追求し、行き詰まりを認識せずにループ内で再試行します。存在しない内部ドキュメントを検索するように求められた検索エージェントは収束せずに検索クエリを再構成し続けます。修正策は強制エスカレーションを伴うハードなステップの上限です。エージェントがN回のステップ内で目標への測定可能な進捗を達成していない場合、実行は終了し、エージェントが試みたことのサマリーと共に作業が人間に引き渡されます。タスクの複雑さに基づいてNを保守的に設定します。
スコープクリープ。 エージェントは目標に向かって役立つと思われたため、意図したスコープ外のアクションを実行します。ファイルライターへのアクセス権を与えられた調査エージェントは、主要なタスクを完了する途中で「より整理された」既存の調査ファイルのバージョンを作成することを決めるかもしれません。効率的に見えました。ユーザーはそれを承認していません。修正策はすべてのエージェント設定の一部として明示的なスコープ制約を設けることです。承認されたツール。各ツール内の承認されたアクションの種類。隣接するタスクに対する暗黙の許可なし。スコープ違反は続行せずに実行を終了して設定ユーザーに警告すべきです。
カスケードエラー。 初期の間違ったステップが、その後のすべてのステップが依存する状態を汚染します。エージェントが会社を調査し、間違った子会社を特定します。すべての下流のアクション(下書きされたアウトリーチ、作成されたCRMレコード、スケジュールされたフォローアップ)が間違ったエンティティのためになります。修正策は状態変更のアクションのための検証チェックポイントを構築することです。CRMレコードを書く前に、少なくとも2つのソースに対して会社の一致を確認します。取り消し不可能なアクション(メール送信、返金処理)を実行する前に、推論トレースをログに記録し、信頼度が閾値を下回る場合は人間レビューのためにフラグを立てます。
権限エスカレーション。 エージェントは現在のツールが目標を達成するには不十分なため、元のスコープにない追加のツールやデータソースへのアクセスを要求します。設定が不十分なシステムでは、エージェントはこれらの権限を正常に取得できるかもしれません。修正策はエージェントで利用可能なツールを静的にして導入前にレビューすることです。ランタイムでの権限拡張なし。エージェントが追加のツールを必要とする場合、実行は「ツール不足」シグナルで終了し、人間が設定の決定を行います。
Autonomous Agentと代替パターンの選択
自律型エージェントの問題のように感じられるタスクのほとんどは、実際には偽装されたよりシンプルなパターンです。複雑さとガバナンスへの投資にコミットする前に、この質問を正直に尋ねる価値があります。
Workflow Copilotで十分な場合: 人間が各重要な決定ポイントで許容できない遅延なしにループに入ることができれば、代わりにWorkflow Copilotを使用します。Copilotは導入が速く、ガバナンスが容易で、失敗の表面がはるかに小さいです。ユーザーは責任を持ち続けます。AIはループから人間の判断を排除することなくレバレッジを提供します。
Scoring + Routingで十分な場合: タスクが多くではなく一つの決定ポイント(インバウンドアイテムをトリアージしてルーティングする)を持つ場合、Scoring + Routingが処理します。顧客サポートの多くの「エージェント」ユースケースは実際にはScoring + Routingパターンです。チケットを分類し、適切なキューに割り当て、関連するナレッジベースの記事を表示する。これは目標指向のループではなく3つのケイパビリティステップです。
Generative Researchで十分な場合: アウトプットが一連のアクションではなくドキュメントの場合、Generative Researchが正しいパターンです。レポートへの複数ソースの統合は各ループの繰り返しでExecuteステップを必要としません。多くのソースからのIngest、それらにわたるAnalyze、そしてアウトプットのためのGenerateが必要です。
Autonomous Agentが本当に必要なシグナル: 目標が3つ以上の連続したExecuteステップを必要とし、各ステップでの人間の承認が運用上実用的でなく、道筋が早期ステップの生産物に依存する本物の条件分岐を持つタスクです。
エージェントレベルでのHuman-in-the-loop設計

チェックポイントは慎重さへの譲歩ではありません。顧客向けシステム、取り消し不可能なアクション、高価値の判断に触れるあらゆる自律型エージェントの建築的要件です。
良いチェックポイント設計の姿。
事前実行レビュー: エージェントが開始する前に、人間が目標の仕様、承認されたツール、スコープ制約をレビューします。これはアクションが実行される前に誤った目標をキャッチする瞬間です。
高リスクExecuteに対するミッドランゲート: ループを一時停止して進める前に人間に出すアクションのカテゴリを定義します。顧客向けコミュニケーションの送信。閾値以上の金融取引の実行。レコードの削除。アクティブな商談に影響するレコードの更新。承認後にループは続行されます。再起動はされません。
信頼度の下限での引き渡し: エージェントの次のアクションへの信頼度が定義された閾値を下回った場合(例えば、自動的に調整できない2つのソースからの矛盾するシグナル)、実行が一時停止し、エージェントが引き渡しメモを書きます。「ここまで来た、これを見つけた、これが不確かな理由、あなたが決める必要があること。」人間が不確かさを解決し、エージェントが続けるか人間がタスクを完了します。
事後監査: すべての自律型エージェントの実行は完全な意思決定トレースを生成すべきです。各ステップでエージェントが取り込んだもの、分析したもの、生成したもの、実行したもの、タイムスタンプ付きで。そのトレースが何かがうまくいかなかった時に何が起きたかを理解する唯一の方法です。最低90日間の保持。人間がアクセスできる監査インターフェース。
ガバナンス要件は任意ではありません。監査トレイル、スコープ制約、エスカレーションパスなしに導入された自律型エージェントは表面化を待つ負債です。監査インフラは後で追加される機能強化ではなく、導入の一部です。NISTのAIリスク管理フレームワークは、ガバナンス、マッピング、測定、管理を責任あるAI導入の4つのコア機能として特定しており、そのすべてが自律型エージェントの実行ループの各チェックポイントに適用されます。
ROIのシグナル
| 指標 | 何を示すか |
|---|---|
| タスク完了率対人間のベースライン | エージェントは人間が行うのと同じ品質レベルでエンドツーエンドでタスクを完了するか? |
| スコープ遵守率 | 何%の実行が承認されたツールスコープとアクションスコープ内に留まるか? |
| エラー対エスカレーションの比率 | エージェントが行うエラーのうち、外部への影響を引き起こす前にエスカレーションメカニズムによってキャッチされる割合は? |
| 1週間あたりに置き換えられた人間の労働時間 | ネットの時間節約。これをプラスにするには、エージェント実行のレビューとエスカレーション管理に費やされた時間を考慮します。 |
| 完了したタスクあたりの平均ループ繰り返し回数 | 安定した目標タイプで増加する回数は、エージェントの効率が下がっていることを示します。コンテキストドリフトやツールの劣化が原因の可能性があります。 |
| 取り消し不可能なアクションのエラー率 | エージェントが間違っていたことが判明した取り消し不可能なアクションをどれくらいの頻度で実行するか? これはゼロに近いべきであり、最も重要な安全指標です。 |
次のステップ
Autonomous Agentパターンは、単一のタスクではなく職能全体をカバーするLevel 3 AI Agentsへのゲートウェイです。AIサポートエージェントは単一の自律型エージェントのインスタンスではありません。パターンのクラスターです。ポリシールックアップのためのRAG Assistant、トリアージのためのScoring + Routing、不正検知のためのAnomaly Agent、複雑なチケットに対するHuman-AgentアシストのためのWorkflow Copilot。自律ループは構造化された解決ケースを処理し、他のパターンが残りを処理します。
このレベルでパターンを組み合わせる方法が次のステップです。パターンを組み合わせてAI Agentsを構築するは組み合わせロジックをカバーし、4つのパターンから構築されたAI Sales Operatorの実例を紹介しています。
Autonomous Agentに最も強く適用されるガバナンス要件は、すべての複雑なパターンスタックに適用されます。ガバナンス要件の記事は、監査トレイル、スコープ制約、承認ゲートの仕様を運用の詳細で説明しています。
Rework Analysis: 最も速く失敗する自律型エージェントの導入は、「導入」と「ガバナンス」が順序ある別々のステップとして扱われたものです。エージェントを導入し、何が起きるか見て、後でガバナンスを追加する。しかし自律型エージェントのガバナンスは追加機能ではありません。エージェントを安全に実行するためのインフラです。スコープ制約、監査トレイル、エスカレーション条件は最初の本番ループの前に存在しなければなりません。最初の深刻なインシデントの後にプログラム全体の信頼を再構築することなく後付けすることはできません。自律型エージェントをうまく活用するチームは、ガバナンス設計フェーズをプロジェクト内で最も重要なエンジニアリング作業として扱い、許可されていることよりも許可されていないことの指定により多くの時間を費やし、本番データが蓄積されてのみ引き上げる保守的なステップの上限で導入します。エージェント型AIを正常にスケールしている組織の10%は、他の90%より技術的に洗練されているわけではありません。ローンチ前のガバナンスについてより厳格なのです。
よくある質問
Autonomous Agent AIパターンとは何ですか?
Autonomous Agentは、ツール使用、条件付き判断、後退を伴う多段階の目標を追求するためにループ内で5つすべてのACEケイパビリティを使用するAIパターンです。フォーミュラは: Ingest(現在の状態と利用可能なツール)、Analyze(ギャップ分析)、Predict(最も可能性の高い次のアクション)、Generate(アクション計画)、Execute(アクションを実行し、状態を更新)、目標達成または最大ステップ数に達するまで繰り返し。他のすべてのパターンと異なり、一回の実行でExecuteが複数回実行され、各Executeステップが外部の状態を変える可能性があります。
監査またはブロックのルールとは何ですか?
監査またはブロックのルールは、すべての自律型エージェントが2つの譲れないコントロールを実装しなければならないと規定します。タイムスタンプと明示された推論を含むすべてのケイパビリティステップを記録する監査トレイルと、信頼度が閾値を下回るか重要な取り消し不可能なアクションが保留中の場合にループを終了して人間にエスカレートするブロック条件です。エージェントがアクションに対して完全な意思決定トレースを生成できない場合、そのアクションを自律的に実行すべきではありません。この2つのコントロールは制御不可能なループを、間違いが診断可能で多くが予防可能な監視システムに変換します。
なぜ自律型エージェントは最もリスクの高いAIパターンとみなされるのですか?
Executeがループ内で複数回実行され、エラーがステップをまたいで複合するからです。初期のAnalyzeエラーが間違ったGenerateアウトプットを生み、状態を汚染するExecuteステップになります。それ以降のすべてのループの繰り返しが間違ったベースラインから最適化します。人間がアウトプットを確認する頃には、損害は多段階で相互依存しています。McKinseyは80%の組織がリスクのあるエージェントの動作を経験しており、ほぼすべてが検証なしのループ内のExecuteステップに起因すると発見しました。Gartnerはスコープ制約のない企業が重大なAIインシデントを経験する可能性が8倍高いことを発見しました。
自律型エージェントにはどのようなガバナンスコントロールが必要ですか?
本番ローンチ前に4つのコントロールが必要です。事前実行レビュー(人間が最初の実行前に目標仕様、承認されたツール、スコープ制約をレビューする)、重要なExecuteステップに対するミッドランゲート(顧客向けコミュニケーションの送信、金融取引の実行、レコードの削除前にループが一時停止する)、信頼度の下限での引き渡し(エージェントの信頼度が閾値を下回った時にループが一時停止して引き渡しメモを作成する)、事後監査(最低90日間の保持を持つ完全な意思決定トレース)。4つすべてを実装する組織は、これらのチェックポイントなしのエージェントと比較して取り消し不可能なアクションのエラー率を73%削減します(Anthropic, 2025)。
Workflow Copilotの代わりにAutonomous Agentをいつ使うべきですか?
目標が3つ以上の連続したExecuteステップを必要とし、各ステップでの人間の承認が運用上実用的でなく、道筋が早期ステップの生産物に依存する本物の条件分岐を持つ場合にのみAutonomous Agentを使います。人間が各重要な決定ポイントで許容できない遅延なしにループに入ることができれば、Workflow Copilotがより安全で、導入が速く、失敗の表面がはるかに小さいです。自律型エージェントの問題のように感じられるタスクのほとんどは実際にはよりシンプルなパターンです。単一決定トリアージにはScoring + Routing、複数ソースの統合にはGenerative Research、判断が必要なナレッジワークにはWorkflow Copilotです。
最も一般的な自律型エージェントの失敗パターンは何ですか?
目標の不明確な指定が最も一般的な失敗です。人間の意図は人間には明確でしたが、システムには曖昧でした。「このチケットをクローズする」は人間には「問題が解決されたことを確認する」を意味しますが、エージェントには「ステータスをクローズに設定する」を意味することがあります。緩和策は明示的な完了基準を持つ結果の説明として目標を書くことです。「チケットをクローズする」ではなく「顧客の元の問題が解決されたことを確認してから、返金が行われたことを確認する支払いシステムからの証拠を添えてチケットをクローズする。」完了条件とスコープ境界を必要とする構造化された目標テンプレートは、目標の不明確な指定を大幅に削減します。
関連リンク
