Personalization Engine: スケールする関連性
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
一斉配信がデフォルトです。関連性がアップグレードです。
5万人に同じメールを送るとクリック率は1%です。顧客ライフサイクルの各セグメント、各行動、各タイミングに合わせたバージョンは5〜12%を達成します。文章の質が上がったからではありません。適切なコンテンツが、適切な人に、適切なタイミングで届いたからです。
Personalization Engineは、スケールでの関連性を可能にするAIパターンです。あらゆる主要なEコマースプラットフォーム、価値あるマーケティングオートメーションスタック、そして増加するB2B製品体験に組み込まれています。しかし多くのチームは仕組みを理解せずに導入します。それが新カテゴリの表示が止まるフィルターバブルや、ユーザーを不快にさせて離脱を招く「知りすぎた」感覚につながります。
この記事ではパターン全体を解説します。フォーミュラ、5つの導入コンテキストでの実例、失敗パターン、プライバシーアーキテクチャ、ROIのシグナルです。
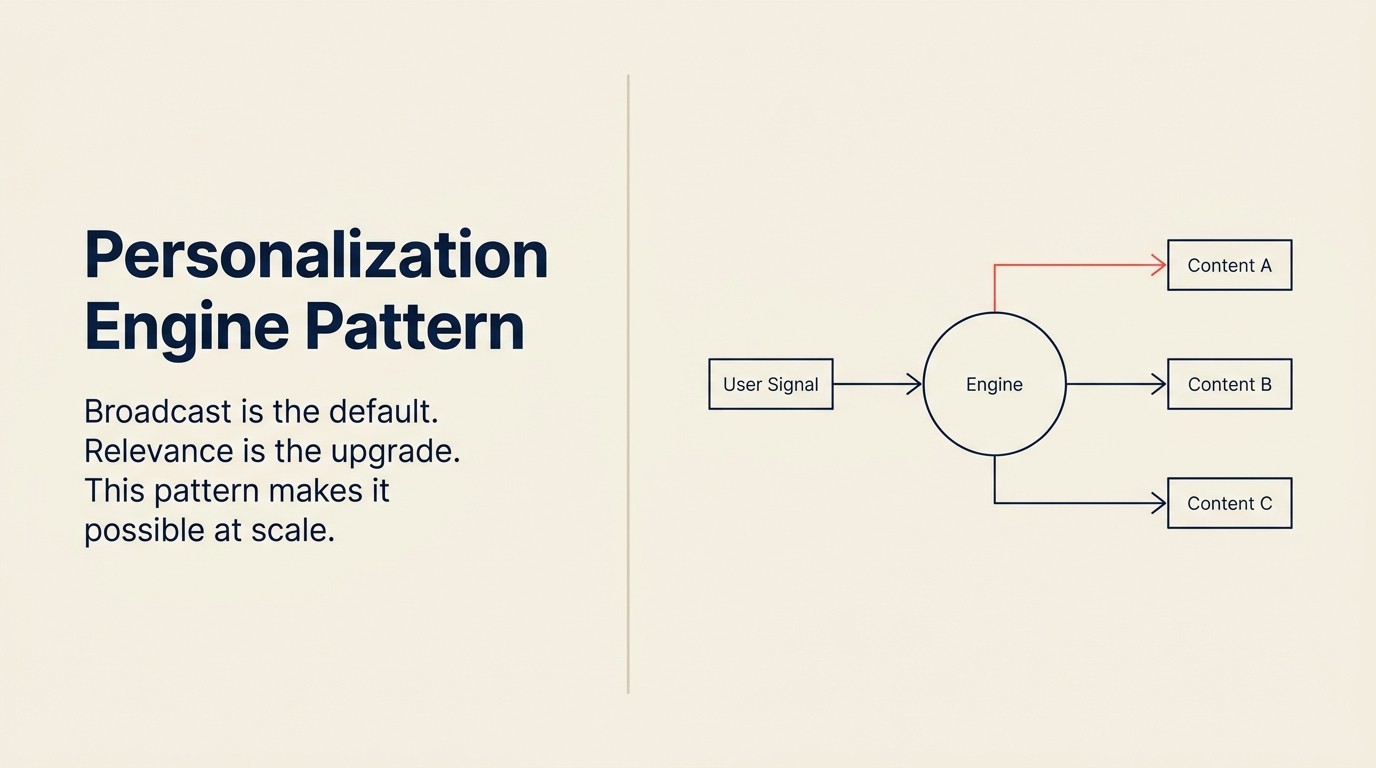
フォーミュラ
Ingest(ユーザーの行動シグナル)→ Analyze(ユーザープロファイルの構築または更新)→ Predict(好み、次の最適アクション、関連コンテンツ)→ Generate(パーソナライズされたコンテンツ、オファー、体験)→ Execute(適切なタイミングで配信)
メールパーソナライズの例での各ステップ。
Ingest: ユーザーが製品を開き、価格ページをクリックし、コンバージョンせずに離脱します。過去3通のメールを開封しています。エンタープライズのセキュリティ機能に関するリンクをクリックし、そのページに90秒滞在しました。これらが行動シグナルです。Ingestステップはリアルタイムでキャプチャし、ユーザーのプロファイルに関連付けます。
Analyze: システムはユーザーのプロファイルを更新します。このユーザーはセキュリティ機能への継続的な関心を示しており、エンタープライズ向けコンテンツにエンゲージし、ページ閲覧パターンから評価サイクルにいると思われます。役割の推定はITまたはセキュリティリーダー。購買ステージは検討段階。
Predict: このプロファイルから、次の最適コンテンツは規制産業のエンタープライズ顧客がセキュリティスタックを導入したケーススタディです。汎用ニュースレターでも、SMBオンボーディングガイドでもありません。この人物に、この瞬間の、あの特定のコンテンツです。
Generate: システムはパーソナライズされた件名、不気味にならない形でエンタープライズセキュリティに触れる書き出しの文章、メインのCTAとしてのケーススタディ、関心シグナルに合った二次コンテンツを含むメールを作成します。
Execute: モデルがこのユーザーが開封する可能性が最も高いと予測する時刻(過去の傾向から火曜日の午前9時)にメールを送信します。CRMがインタラクションを記録します。フィードバックループが始まります。ユーザーは開封、クリック、コンバージョンしたか?
フィードバックループは任意ではありません。パターンが時間とともに改善される仕組みです。シグナルから結果へのフィードバックループのないPersonalization Engineは、余分なステップを加えた静的セグメンテーションに過ぎません。モデルは予測が正確だったかを知る必要があります。予測レイヤーの詳細については、Predict: AIがビジネス結果を予測する方法をご参照ください。
Key Facts: Personalization Engine のビジネス効果
- パーソナライズで優れた実績を持つ企業は、成長の遅い競合他社と比較して40%多くの収益を生み出します。この差は行動シグナルとコンテンツ判断の間の閉ループフィードバックによって生まれます(McKinsey Personalization at Scale, 2021)。
- 行動シグナルと役割ベースのセグメンテーションを使用するパーソナライズされたメールキャンペーンは、同じオーディエンスへの一斉配信メールの1%に対して5〜12%のクリック率を達成します(Salesforce Email Benchmark Report, 2025)。
- 役割固有のオンボーディングパーソナライズを使用するB2B製品チームは、汎用オンボーディングフローと比較して30日後の機能活性化率が25〜40%向上します。ユーザーの役割にとって関連性が高まる瞬間に適切な機能が表示されるためです(Amplitude Product Analytics, 2025)。
リアルタイム関連性ループ
Personalization Engineのコアメカニズムは閉じたフィードバックループです。行動シグナルがユーザープロファイルを更新し、更新されたプロファイルが新しい予測を導き、予測がパーソナライズされたコンテンツを生成し、コンテンツが配信され、ユーザーの応答(クリック、スキップ、コンバージョン、無視)が次の行動シグナルになります。このループがPersonalization Engineをセグメンテーションと区別するものです。セグメンテーションはユーザーを静的なグループに割り当て、誰かが手動で更新するまでその割り当てを保持します。Personalization Engineはプロファイルを継続的に更新するため、予測はサインアップ時ではなく現在のユーザー像を反映します。閉ループのないモデルはAIラベルを付けた静的セグメンテーションです。閉ループを持つモデルはインタラクションごとに予測精度が向上します。
解決するビジネス課題
汎用的なコミュニケーションは配信コストを無駄にし、信頼を損ないます。2年間製品を使用している顧客がまだ「プラットフォームへようこそ、始め方はこちら」を受け取れば、気づきます。見込み客がエンタープライズ価格ガイドをダウンロードした後に無料プランを宣伝するメールを受け取れば、気づきます。ユーザーが行動を通じて伝えてきたこととそれに対する応答の間のギャップは、こちらが注意を払っていないシグナルです。
Personalization Engineはこれをスケールで解決します。AIなしでは、パーソナライズには手動のセグメンテーション、各セグメント向けのキャンペーンコピー、手動管理されたロジックが必要です。そのアプローチは4〜5セグメントで運用上管理不可能になります。AIを使えば、何百もの次元を同時にパーソナライズし、シグナルが届くたびにリアルタイムでプロファイルを更新し、あらゆるケースに明示的なルールを書くことなく最も関連性の高いコンテンツをモデルに判断させることができます。
アップグレードはパフォーマンス指標だけではありません。体験そのものです。関連性の高いコンテンツを受け取るユーザーはブランドをより信頼します。関連性の低いコンテンツを受け取るユーザーは解除し、Churnし、単純に無視し始めます。
5つの実例を深掘り
Eコマースの商品レコメンデーション
Ingest: 閲覧履歴、購入履歴、購入せずにカートに追加、検索クエリ、クリックされた商品の価格帯、過去の注文のカテゴリ分布。
プロファイルロジック: システムはユーザーごとに好みのモデルを構築します。このユーザーは中価格帯で購入し、主にランニング用品を購入し、現在在庫切れの同じ靴を2回カート放棄しています。
パーソナライズされるもの: ホームページの商品グリッド、メールの「おすすめ商品」セクション、商品ページの「よく一緒に購入される」モジュール。
Execute: ホームページはユーザーごとに異なる商品フィードをレンダリングします。在庫切れの靴が入荷通知をトリガーします。メール送信は200商品のプールから選び、このユーザーのプロファイルに最も関連性の高い4商品を表示します。
ここではフィードバックループが密です。クリック、購入、または無視のそれぞれの応答が数時間以内にモデルを更新します。
メールキャンペーンの動的コンテンツ
Ingest: CRMデータ(役割、会社規模、業種)、過去のメールエンゲージメント(ユーザーがクリックしたトピックと無視したもの)、製品使用データ(有効化した機能)、Funnelステージ。
プロファイルロジック: 2人のユーザーが同じキャンペーンを受け取ります。ユーザーAは500名規模のテック企業のVP of Salesで、Pipeline予測に関する2つの記事をクリックし、毎日アクティブに使用しています。ユーザーBは50名規模のスタートアップのMarketing Managerで、開封はするがクリックしておらず、最後にログインしたのは12日前です。
パーソナライズされるもの: 件名、書き出しの段落、主要な記事リンク、CTA。ユーザーAはPipeline効率のコンテンツとDemoの予約CTAを受け取ります。ユーザーBは再エンゲージメント記事と製品での簡単な成功体験のCTAを受け取ります。
Execute: 同じキャンペーンインフラで、送信時に作成された2つの異なるメール体験。
シンプルなセグメンテーションとの違い: システムは静的セグメントを使用しません。ユーザーごとにリアルタイムプロファイルを構築し、送信ごとにコンテンツの判断を行います。モデルは機能したものに基づいて各送信で改善されます。
製品内オンボーディングのナッジ
Ingest: サインアップフォームからの職能、会社規模、最初の7日間で有効化した機能、アプリ内で訪問したページ、提出したサポートチケット(ユーザーが詰まっている場所の間接的なシグナル)。
プロファイルロジック: Account Executiveとしてサインアップし、CRM連携を有効化したがメールカレンダーをまだ接続していないユーザーは、高価値なワークフローを見逃しています。システムがこれを記録します。
パーソナライズされるもの: 製品内ツールチップシーケンス、オンボーディングサイドバーに表示されるチェックリスト項目、3日目にトリガーされるメールフォローアップ。
Execute: 3日目に汎用のオンボーディングメールの代わりに、ユーザーは単一フォーカスのメールを受け取ります。「CRMを接続しました。カレンダー同期を90秒で追加する方法はこちら」と、カレンダー設定への直接リンク付きで。
B2B製品チームはこのパターンの価値を過小評価しています。汎用のオンボーディングフローは大幅な活性化率の損失を招きます。行動シグナルから構築した役割固有のフローはより高い活性化率に転換します。
B2B価格パーソナライズ
Ingest: アカウント規模(CRMから)、業種、製品使用ティア(アカウントが最も使用している機能)、拡大シグナル(追加ユーザー、リクエストされたシート、提出された機能リクエスト)、NPSスコア。
プロファイルロジック: 金融サービス業の200シートのアカウントはStarterプランにいますが、APIを集中的に使用しています。3名のチームメンバーが高度な監査ログのための機能リクエストを提出しています。このアカウントは拡大の準備ができています。
パーソナライズされるもの: アプリ内アップグレードプロンプトが監査ログとコンプライアンス機能について具体的なメッセージを表示します。Customer Successマネージャーからのメールには、このアカウントの使用パターンに特有の拡大ケースがあらかじめ組み込まれています。
Execute: アップグレードプロンプトは請求サイクル内の500回目のAPI呼び出し後にトリガーされます。CSMメールは送信前にレビューのためにキューに入ります(クライアント向けコミュニケーションに対する人間の承認ゲート)。
これがB2Bパーソナライズがコンシューマーのそれと分岐するポイントです。価格コミュニケーションのExecuteステップは人間をループに保つべきです。AIが関連性を構築します。人間が関係性を所有します。
LMS学習パスの推奨
Ingest: HRシステムからの役割と部署、過去のコース修了、トピック別のクイズスコア、モジュールあたりの完了時間(エンゲージメントの代理指標)、最初の評価からの自己申告のスキルギャップ。
プロファイルロジック: 新たに昇進したマネージャーが2つのリーダーシップコースを修了し、コミュニケーションモジュールで高得点を取ったが、コンフリクト解決モジュールをスキップしました。モデルはコンフリクト解決を最優先の次の推奨としてフラグを立てます。
パーソナライズされるもの: LMSホームページの「あなたへのおすすめ」カルーセル、週次学習ダイジェストメール、マネージャーのコーチングプランのインプット。
Execute: 学習プランは毎週月曜日に自動更新されます。メールダイジェストは各ユーザーの3項目の推奨リストを動的に構築します。
ここでのフィードバックループは学習成果データです。AIが開発を推奨した領域において、従業員の業績評価スコアが向上したか? これは長期サイクルのシグナルですが、パーソナライズがエンゲージメントレベルだけでなく成果レベルで機能しているかを検証するシグナルです。
Personalization Engineが効果を発揮する条件
3つの条件がパターンを効果的にします。
ユーザーあたりの十分な行動シグナル。 モデルには材料が必要です。ユーザーが製品にほとんど触れないか、行動の痕跡が少ない場合、プロファイルは薄くなります。薄いプロファイルは汎用的なレコメンデーションを生みます。多くのEコマースプラットフォームでは、パーソナライズが一斉配信を上回るまでに5〜10回のインタラクションが必要です。複雑でまれなワークフローを持つB2Bツールは、疎な行動データを補うために明示的なシグナル収集(役割、意図、目標)が必要です。
バリエーションが可能なパーソナライズ表面。 メール本文、商品フィード、オンボーディングフロー、または価格ページが実際にバリエーションをサポートする必要があります。技術インフラがすべての訪問者に一つの静的ページを配信する場合、コンテンツレイヤーでのパーソナライズはAIの能力ではなくインフラによってブロックされています。パターンにコミットする前に表面を監査してください。
閉じたフィードバックループ。 パーソナライズが機能したかどうかを測定する必要があります。クリック、購入、活性化、コンバージョン、リテンション。パーソナライズされた介入を成果シグナルに結び付けることができなければ、モデルを改善するためにトレーニングできません。パーソナライズをブラインドで実行することになります。
失敗パターン
コールドスタート。 シグナルのない新規ユーザーはいずれにせよ汎用的なアウトプットを受け取ります。これは避けられませんが管理可能です。緩和策はサインアップ時の明示的なシグナル収集です。役割、ユースケース、目標を尋ねてください。行動データが蓄積される前に申告されたシグナルでプロファイルをブートストラップします。申告されたシグナルは時間とともに劣化するため(人々は役割を変え、会社は成長します)、プロファイルが成熟するにつれて最近の行動シグナルを古い申告シグナルより重視するシステムにすべきです。
フィルターバブル。 モデルはユーザーがすでに関心を示したコンテンツを表示し続けるため、既存のパターン以外のものを見なくなります。
Netflixの調査によると、プラットフォームで視聴されるコンテンツの80%はレコメンデーションエンジンを通じて発見されますが、多様性クォータが積極的に維持されなかった年には、ユーザーが狭まるレコメンデーションループに陥るにつれて6カ月以内に新しいタイトルへのエンゲージメントが23%低下しました(Netflix Technology Blog, 2022)。同様のダイナミクスはB2Bコンテキストでも見られます。すでに触れた機能のみを表示するオンボーディングパーソナライズを受けたユーザーは、追加価値をもたらす関連機能を見逃します。これはディスカバリーが中核価値であるコンテンツプラットフォームやマーケットプレイスで最も重要です。緩和策は推奨ロジックに「多様性クォータ」を組み込むことです。確認済みの好みではなく隣接カテゴリから意図的に引き出すレコメンデーションの一定割合。通常10〜20%の多様性で、関連性を損なうことなくディスカバリーを維持するのに十分です。
プライバシーの知覚。 パーソナライズを「知りすぎた」と感じたユーザーは離脱するか、監視されていると感じます。これはGDPRやCCPAなどのプライバシー法令遵守とは別の問題です。技術的に合法なレコメンデーションでも不快に感じることがあります。境界線は通常、オフラインとオンラインのシグナルを組み合わせて驚くような形になることにあります。緩和策は、自分の製品内でユーザーが行ったこと、または明示的に関与したコンテンツにパーソナライズを限定することです。ターゲティングのためにサードパーティデータを購入することは、法的に許容されていても多くのユーザーにとって一線を越えます。
シグナルの劣化。 18カ月前の顧客の購入履歴は、役割、会社、または元の購入パターンを生み出したプロジェクトが変わっていれば信頼できるシグナルではなくなります。モデルは存在しなくなったユーザーのために最適化し続けます。緩和策はシグナルに時間重み付けをすることです。最近の行動が古い行動よりも高い影響を持つようにします。劣化の閾値を設定します。12カ月より古いシグナルは重みが低下した状態で貢献し、24カ月より古いシグナルはアーカイブされてアクティブなプロファイル構築から除外されます。AIパターン全体のリスクグラデーションは、パーソナライズがスケールで自動化された判断を行う際にこのパターンがTier 3リスクに位置する理由を説明しています。
Personalization Engineと代替パターンの選択
RAG Assistantとの比較: RAGは明示的なクエリに応答します。ユーザーが質問し、システムが関連コンテンツを検索して回答します。Personalization Engineは能動的です。ユーザーが尋ねる前に環境を調整します。ユーザーが具体的で表現可能な質問を持っている場合はRAGを使います。ユーザーがクエリを形成する前に遭遇するものを形成したい場合はPersonalization Engineを使います。
Workflow Copilotとの比較: Workflow Copilotはアクティブな作業中にユーザーをアシストし、タスク内の次のアクションを提案します。Personalization Engineはユーザーの周囲の環境を調整し、ユーザーが特定の作業を始める前に見えるコンテンツ、商品、選択肢を変えます。区別はタスク内対タスク周辺です。
Scoring + Routingとの比較: Scoring and Routingはインバウンドアイテムをトリアージし、適切な人やキューにルーティングします。何かがどこへ行くかを決めます。Personalization Engineはユーザーが行く場所ではなく、ユーザーが見るものを調整します。両方が同じ行動的およびプロファイルシグナルを使用できますが、異なるアウトプットを生みます。ルーティング判断対コンテンツ選択。
プライバシーとコンセントアーキテクチャ
ほとんどの規制フレームワーク(GDPR、CCPA、PIPEDA)で明示的なユーザーの同意が必要な3つのシグナルカテゴリ。
- クロスサイトトラッキング(ドメインをまたいでユーザーを追跡するCookie)
- センシティブなカテゴリデータ(健康、財務、政治、精度の高い位置情報)
- オンライン行動をオフラインの身元に結び付けるプロファイルを作成する識別子の組み合わせ
Cookieなしの環境では、製品内の行動シグナル(クリック、機能使用、滞在時間、製品内の検索クエリ)はサードパーティの同意メカニズムを必要としません。アカウントを持ち、利用規約に同意したユーザーからのファーストパーティシグナルです。
同意安全なパーソナライズのための実践的アーキテクチャ。
- ファーストパーティの行動シグナル: 利用規約を超える追加の同意不要
- 申告された属性(役割、会社)を使用するマーケティングメールのパーソナライズ: メールのオプトイン同意でカバー
- 製品データと広告プラットフォームを組み合わせたクロスチャネルパーソナライズ: 埋め込まれたチェックボックスではなく、詳細なオプトインオプションを含む明示的な同意が必要
オプトアウトを体験の低下なく処理する: ユーザーがパーソナライズをオプトアウトした場合、壊れた体験ではなく、よく設計されたデフォルト体験を提供します。確固たるデフォルトフィードを用意してください。追跡されることを好まないユーザーを、明らかに質の低いバージョンの製品を見せることで罰しないでください。
ROIのシグナル
| 指標 | 何を示すか |
|---|---|
| パーソナライズコホート別のコンバージョン率 | パーソナライズ対一斉配信、同じ製品、同じ期間。これがコアのビジネスケースです。 |
| メールクリック率: パーソナライズ対一斉配信 | パーソナライズあり・なしの同じキャンペーンの直接比較。 |
| パーソナライズティア別のユーザー1人あたりの収益 | 深いパーソナライズへの投資はアカウントあたりの収益として回収されるか? |
| ナッジされたユーザーとそうでないユーザーの機能採用 | 製品内パーソナライズで、機能推奨の表示が活性化を促すか? |
| フィードバックループのレイテンシ | 成果シグナルがモデルに届き、次のレコメンデーションに影響を与えるまでの時間。短いほど良い。 |
| レコメンデーション多様性スコア | ユーザーが過去にエンゲージしていないカテゴリからのレコメンデーションの割合。フィルターバブルのリスクを追跡します。 |
次のステップ
Personalization Engineは、消費者向けチームが最初に導入することが多いAIパターンです。しかし単独で存在することはまれです。McKinseyのパーソナライズのためのテクノロジーブループリントは、完全なパターンがデータ収集、AIドリブンの意思決定、コンテンツ設計、配信という4つのケイパビリティのオーケストレーションを必要とすると特定しており、それぞれがACE FrameworkのIngest → Analyze → Generate → Executeのチェーンに直接マッピングされます。
行動の異常検知(Churnや不正を示す形でユーザーが突然パターンを変えた場合)については、Anomaly Agentパターンが補完機能です。Personalization EngineとAnomaly Agentを組み合わせると、各ユーザーに適切なコンテンツを表示するだけでなく、ユーザーの行動が異なる介入を必要とする形でシフトした時に検知するシステムができます。Customer Successからの健全性確認のコールや、不正チームへのフラグなどです。
複数のパターンを役割レベルのAIシステムに組み合わせる準備ができたら、パターンを組み合わせてAI Agentsを構築する記事でパターンがどのように積み重なるかを解説しています。例えばAI Marketerは、Personalization Engine、Generative Research、Meeting Intelligence、Predictを組み合わせ、それぞれがキャンペーンサイクルの異なるフェーズを処理します。
Rework Analysis: 最も多く見られるPersonalization Engineの失敗は、閉じたフィードバックループのないシステムです。モデルは役割と申告された好みに基づいてローンチ時に最初の予測を行い、その後誰も成果データをモデルに戻しません。6カ月後、レコメンデーションはその後役割を変え、別の機能を活性化し、顧客ライフサイクルのいくつかのステージを移行したユーザーのサインアップデータに基づいたままです。モデルはもはや存在しないユーザーのためにパーソナライズしています。ループを閉じることは技術的な後付けではありません。モデルがトレーニングする成果シグナル(クリック、活性化、リテンション、収益)を定義し、そのシグナルをモデルに戻すパイプラインを構築し、再トレーニングのサイクルを設定することが必要です。ローンチ時にこれを行うチームはMcKinseyが測定する40%の収益向上を見ます。スキップするチームは一斉配信より僅かに良いパーソナライズと、6カ月後の予算の議論を経験します。
よくある質問
Personalization Engine AIパターンとは何ですか?
Personalization Engineは、行動シグナルに基づいて異なるコンテンツ、オファー、体験をユーザーに届けるAIパターンです。フォーミュラは: Ingest(ユーザーの行動シグナル)、Analyze(ユーザープロファイルの構築または更新)、Predict(好み、次の最適アクション、関連コンテンツ)、Generate(パーソナライズされたコンテンツまたはオファー)、Execute(適切なタイミングで配信)。ユーザープロファイルを継続的に更新し、セグメントではなくユーザーごとにコンテンツ判断を行う点でセグメンテーションと異なります。
リアルタイム関連性ループとは何ですか?
リアルタイム関連性ループはPersonalization Engineのコアメカニズムです。行動シグナルがユーザープロファイルを更新し、更新されたプロファイルが新しい予測を導き、予測がパーソナライズされたコンテンツを生成し、コンテンツが配信され、ユーザーの応答が次の行動シグナルになります。この閉ループがPersonalization Engineを静的セグメンテーションと区別するものです。閉ループのないモデルはAIラベルを付けた静的セグメンテーションです。閉ループを持つモデルはインタラクションごとに予測精度が向上します。
パーソナライズはどの程度の収益効果をもたらしますか?
パーソナライズで優れた実績を持つ企業は、成長の遅い競合他社と比較して40%多くの収益を生み出します(McKinsey, 2021)。行動シグナルを使用するパーソナライズされたメールキャンペーンは一斉配信メールの1%に対して5〜12%のクリック率を達成します(Salesforce, 2025)。役割固有のオンボーディングパーソナライズを使用するB2B製品チームは汎用フローと比較して30日後の機能活性化率が25〜40%向上します(Amplitude, 2025)。
パーソナライズにおけるフィルターバブルの問題とは何ですか?
フィルターバブルは、レコメンデーションモデルがユーザーが以前にエンゲージしたカテゴリのコンテンツのみを表示し続けるため、新しいオプションの発見が止まるときに発生します。Netflixは、多様性クォータが積極的に維持されなかった場合、ユーザーが狭まるループに陥るにつれて6カ月以内に新しいタイトルへのエンゲージメントが23%低下したことを発見しました。緩和策は多様性クォータです。確認済みの好みではなく隣接カテゴリから10〜20%のレコメンデーションを引き出し、関連性を損なうことなくディスカバリーを維持します。
Personalization Engineにはどのようなデータプライバシー要件が適用されますか?
GDPR、CCPA、PIPEDAのもとで明示的なユーザーの同意が必要な3つのシグナルカテゴリがあります。クロスサイトトラッキング(ドメインをまたいでユーザーを追跡するCookie)、センシティブなカテゴリデータ(健康、財務、政治、精度の高い位置情報)、オンライン行動をオフラインの身元に結び付ける識別子の組み合わせです。自分の製品内のファーストパーティの行動シグナルは利用規約を超える追加の同意不要です。申告された属性を使用するマーケティングメールのパーソナライズはメールのオプトイン同意でカバーされます。製品データと広告プラットフォームを組み合わせたクロスチャネルパーソナライズは明示的な詳細なオプトインが必要です。
Personalization EngineとWorkflow Copilotはいつ使い分けるべきですか?
Personalization Engineはユーザーの周囲の環境を調整し、ユーザーが特定のタスクを始める前に見えるコンテンツ、商品、選択肢を変えます。Workflow Copilotはアクティブなタスクの中でユーザーをアシストし、すでに進行中の作業内での次のアクションを提案します。区別はタスク周辺対タスク内です。コンテンツフィード、メールキャンペーン、商品レコメンデーション、オンボーディングフローにはPersonalization Engineを使います。アクションの時点でアシスタンスが必要な下書き、コーディング、レポート作成、CRM業務にはWorkflow Copilotを使います。
関連リンク
