Migración de Patrones: Pasando de AI v1 a v2
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La primera generación de AI empresarial ya está envejeciendo. Los equipos que desplegaron RAG Assistants en 2022 los construyeron sobre text-embedding-ada-002. Los equipos que desplegaron modelos de Scoring en 2023 los entrenaron sobre una infraestructura de datos previa a GPT-4. Los equipos que construyeron Workflow Copilots a principios de 2024 diseñaron prompts para modelos que desde entonces han sido superados por dos generaciones.
Estos sistemas todavía funcionan. Ese es el problema. Funcionan en silencio, acumulando deuda técnica y operativa, mientras mejores arquitecturas esperan a una migración. Los equipos que trabajan con infraestructura obsoleta no están fallando. Solo están dejando capacidad sobre la mesa mientras su lista de migración pendiente crece.
La migración no es opcional. Pero tampoco es equivalente a una actualización de versión de software. El comportamiento de la AI es probabilístico. "Funciona según lo previsto" no es un estado binario. No puede simplemente cambiar el modelo, ejecutar la suite de pruebas y darlo por hecho. El cambio de comportamiento derivado de las actualizaciones del modelo es real, a veces sutil, y a veces significativo. Y los usuarios que han construido flujos de trabajo alrededor del comportamiento antiguo necesitan saber qué cambió.
Este artículo es para el equipo que construyó algo en 2022-2024 y necesita actualizarlo sin romper la producción.
Qué desencadena la migración de patrones
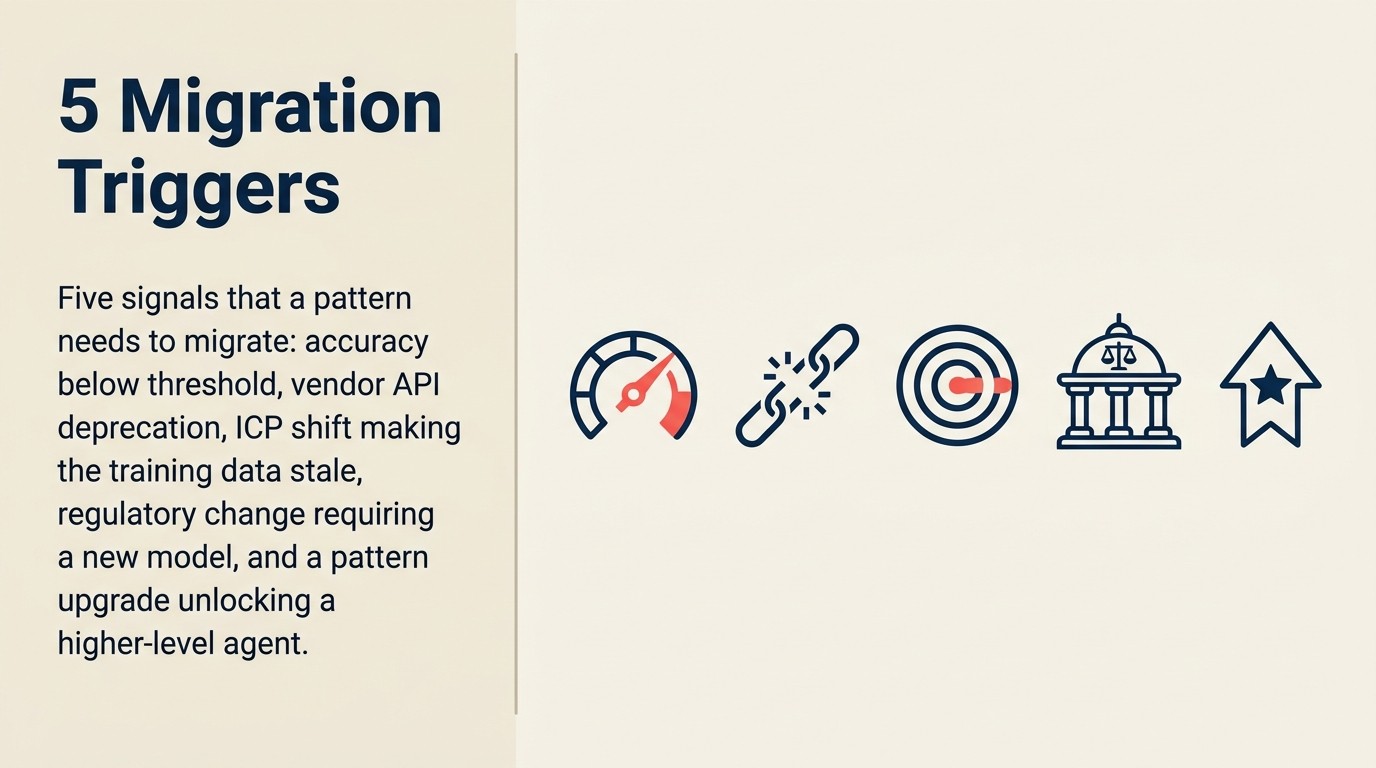
Cinco escenarios llevan un patrón a la migración en lugar del mantenimiento continuo:
Baja de servicio del modelo por el proveedor. El desencadenante más claro. OpenAI, Anthropic, Google y Azure todos publican cronogramas de baja con fechas de fin de vida. Cuando el modelo del que depende su patrón llega al EOL, migra o se rompe. La mayoría de los equipos de AI empresarial han experimentado esto al menos una vez: la API devuelve un aviso de baja y de repente una migración que no estaba en el Roadmap es urgente. La documentación de bajas de modelos de Anthropic proporciona al menos 60 días de aviso antes de la retirada, pero ese cronograma asume que está vigilando los avisos. Las solicitudes de API a modelos retirados fallan silenciosamente desde la perspectiva del llamante a menos que haya monitoreo establecido.
La implicación operativa: cualquier patrón en producción debe tener una respuesta documentada para "¿qué sucede si este modelo es dado de baja el próximo trimestre?" No necesariamente un plan de migración completo, pero como mínimo una evaluación de cuál sería el alcance de la migración.
Degradación significativa de la precisión. Cuando las revisiones trimestrales de precisión muestran un declive consistente y la causa raíz es la capacidad del modelo en lugar de la calidad de los datos o del prompt, la migración a un mejor modelo es la solución. El diagnóstico importa: la deriva de datos requiere reentrenamiento o actualizaciones de datos; los problemas de calidad del prompt requieren ingeniería de prompts; las brechas de capacidad del modelo requieren migración del modelo.
Nueva capacidad que hace que el enfoque existente quede obsoleto. El paso de RAG de búsqueda vectorial pura a híbrida de búsqueda por palabras clave-vectores-reranking es el ejemplo más claro reciente. Los equipos que construyeron RAG en 2022 sobre búsqueda semántica pura están dejando entre un 20-40% de mejora de calidad de recuperación sobre la mesa en comparación con los enfoques híbridos. El artículo sobre riesgo de alucinación por patrón explica por qué la calidad de recuperación importa tanto para la precisión de RAG. El sistema existente no está roto. Simplemente está sustancialmente superado por una arquitectura v2 que no existía cuando se construyó la v1.
Cambios de costos que favorecen un nuevo enfoque. Un patrón construido sobre GPT-4 a los precios de 2023 puede ahora ser reemplazable económicamente por un modelo más pequeño, rápido y barato que se ha puesto al día en capacidades. Alternativamente, un patrón construido sobre herramientas propietarias del proveedor puede ser reemplazable con infraestructura de código abierto a una fracción del costo. Consulte el artículo sobre excesos de costos para la comparación del modelo de costos.
Cambios en la relación con el proveedor. Las adquisiciones, las reestructuraciones de precios y el cierre de productos ocurren. Un patrón construido sobre la API de AI de una startup que luego cerró es el peor escenario: migración forzada con un cronograma de emergencia. La evaluación del riesgo de concentración de proveedores debe ser parte de su revisión de gobernanza de AI.
Key Facts: Realidad de la Migración de Patrones de AI
- La primera generación de AI empresarial (desplegada 2022-2024) ya está alcanzando desencadenantes de migración: bajas de modelos, brechas de capacidad de arquitecturas más nuevas (RAG híbrido versus búsqueda vectorial ingenua muestra un 20-40% de mejora en la calidad de recuperación) y deuda de datos acumulada.
- Las pruebas en modo sombra seguidas de despliegue canario al 1-10% del tráfico son ahora práctica estándar para los lanzamientos de modelos de AI empresarial, con un enfoque de cuatro fases: POC (2-4 semanas), Piloto al 5-10% del tráfico (4-8 semanas) y despliegue a escala completa (8-12 semanas). (MLOps Deployment Research, 2026)
- La migración impulsada por AI con una secuenciación canaria adecuada aumenta la eficiencia operativa entre un 20-25% y reduce los tiempos del ciclo de despliegue en un 70% en comparación con los enfoques de corte directo. (QualityKiosk Migration Analysis, 2026)
Tres tipos de migración con diferentes perfiles de riesgo
Tipo 1: Migración del modelo en su lugar. Cambiar el modelo subyacente manteniendo la arquitectura. Mismo Pipeline de recuperación, misma estructura de prompts, misma capa de integración. Solo una llamada al modelo diferente. Este es el tipo de migración de menor riesgo en términos de infraestructura, pero aún requiere pruebas de regresión del comportamiento porque el nuevo modelo puede responder de manera diferente a los mismos prompts, incluso con las mismas instrucciones.
Ejemplo: reemplazar GPT-3.5 Turbo con GPT-4o Mini para un RAG Assistant. Misma arquitectura, mejor modelo. Pero GPT-4o Mini sigue las instrucciones más precisamente que GPT-3.5 Turbo, lo que significa que los prompts que dependían de la tendencia del modelo más antiguo a ser ligeramente flexible con el formato pueden ahora producir resultados en formatos inesperados.
Tipo 2: Migración de arquitectura. Reconstruir el patrón con un enfoque diferente. El caso de uso es el mismo; la implementación es fundamentalmente diferente. RAG de búsqueda vectorial única e ingenua a búsqueda híbrida de palabras clave-vectores-reranking es una migración de arquitectura. Meeting Intelligence de un Pipeline solo de transcripción a uno de transcripción-más-diarización de oradores-más-detección de temas es una migración de arquitectura.
La migración de arquitectura lleva la mayor complejidad y el mayor potencial de mejora de calidad. Se asemeja más a construir un nuevo sistema que a actualizar uno existente, lo que significa que requiere el marco de migración completo.
Tipo 3: Migración de proveedor. Mover la misma implementación del patrón a un proveedor diferente. Cambiar su RAG Assistant de Azure OpenAI a Anthropic Claude. Cambiar su Meeting Intelligence de AssemblyAI a Deepgram. El patrón permanece igual; el stack del proveedor cambia.
Las migraciones de proveedor a menudo parecen más simples de lo que son. Los diferentes proveedores tienen diferentes convenciones de API, diferentes características de latencia, diferentes valores predeterminados de formato de salida y diferentes comportamientos del modelo con los mismos prompts. Lo que funcionó con el Proveedor A puede necesitar ajustes de prompts con el Proveedor B incluso si ambos afirman tener capacidades equivalentes.
Cómo varía el riesgo de migración según el patrón

No todas las migraciones de patrones llevan el mismo riesgo. Entender dónde se concentra el riesgo le ayuda a priorizar el tiempo de prueba y de staging.
Patrones de alto riesgo de migración:
Scoring and Routing: Un nuevo modelo de Scoring no solo produce puntuaciones diferentes. Produce una distribución diferente. Si el modelo antiguo puntuaba los leads de alta calidad entre 70-90 y el nuevo los puntúa entre 80-95, sus umbrales de Routing están mal desde el primer día. La lógica de Routing construida sobre "asignar al equipo enterprise si la puntuación > 75" ahora asigna de manera diferente, potencialmente asignando incorrectamente una porción significativa de su volumen de leads. La recalibración del umbral es necesaria después de cada cambio de modelo, no opcional.
Autonomous Agent: Cada API de herramienta en el repertorio del agente necesita verificación de compatibilidad antes de la migración. La nueva versión del agente puede llamar a las mismas APIs pero analizar las respuestas de manera diferente, o puede llamar a las herramientas en una secuencia diferente, produciendo un comportamiento Execute diferente incluso para las mismas entradas. Se requieren pruebas de regresión del comportamiento completas.
Personalization Engine: Las representaciones de perfil de usuario del sistema antiguo pueden no transferirse significativamente a la nueva arquitectura. Si el nuevo modelo construye perfiles de usuario de manera diferente, las primeras semanas de producción tendrán una calidad de personalización reducida a medida que los perfiles se reconstruyan.
Patrones de riesgo de migración medio:
RAG Assistant: Los cambios del modelo de embeddings requieren re-indexación completa. Un modelo de embeddings diferente produce representaciones vectoriales diferentes para los mismos documentos, por lo que no puede mezclar embeddings de diferentes modelos en el mismo índice. La re-indexación completa de una base de conocimiento de 500.000 documentos es un evento de cómputo significativo que necesita planificarse, no descubrirse.
Workflow Copilot: El comportamiento de los prompts cambia entre modelos. Las instrucciones que producían sugerencias concisas con el modelo antiguo pueden producir sugerencias verbosas con el nuevo. Se requiere revisión de calidad del tono, la longitud y la precisión de las sugerencias antes de la promoción.
Document Review: Compatibilidad del esquema de extracción. El nuevo modelo puede extraer información de cláusulas en un formato ligeramente diferente que rompe las integraciones de flujo de trabajo legal downstream.
Patrones de menor riesgo de migración:
Meeting Intelligence: Cambiar a un proveedor de transcripción diferente es de relativo bajo riesgo porque el resultado de la transcripción está estandarizado (texto con marcas de tiempo). El análisis de nivel superior (resumen, acciones a tomar) lleva más riesgo de comportamiento.
Vision Extract: Siempre que se mantenga el esquema de extracción, los cambios de modelo tienen menor riesgo porque los resultados están restringidos a campos específicos. La deriva del formato es el principal riesgo, no la imprevisibilidad del comportamiento.
Anomaly Agent: La migración a un mejor modelo de detección de anomalías requiere re-establecer las referencias, pero la lógica de alertas fundamental es generalmente independiente del modelo.
El marco de migración
Paso 1: Establecer la referencia del sistema actual.
Antes de tocar nada en la migración, capture una referencia completa del comportamiento actual del sistema. Este es su conjunto de comparación de regresión.
Para un RAG Assistant: ejecute 200 consultas representativas contra el sistema actual. Registre las consultas, los documentos recuperados y las respuestas generadas. Clasifique cada respuesta como precisa, parcialmente precisa o imprecisa contra la verdad de fondo. Esto se convierte en su suite de pruebas de aceptación.
Para un modelo de Scoring+Routing: extraiga las últimas decisiones de Scoring de los 90 días. Registre los atributos de entrada y las puntuaciones para 500 registros representativos. Anote los resultados reales (¿cerró el lead con alta puntuación? ¿resultó ser real la anomalía señalada?). Esta es su referencia de calibración.
No comience la migración sin una referencia. Si no puede comparar el comportamiento del nuevo sistema con el del sistema antiguo para las mismas entradas, no tiene criterios de migración. Solo sentimientos.
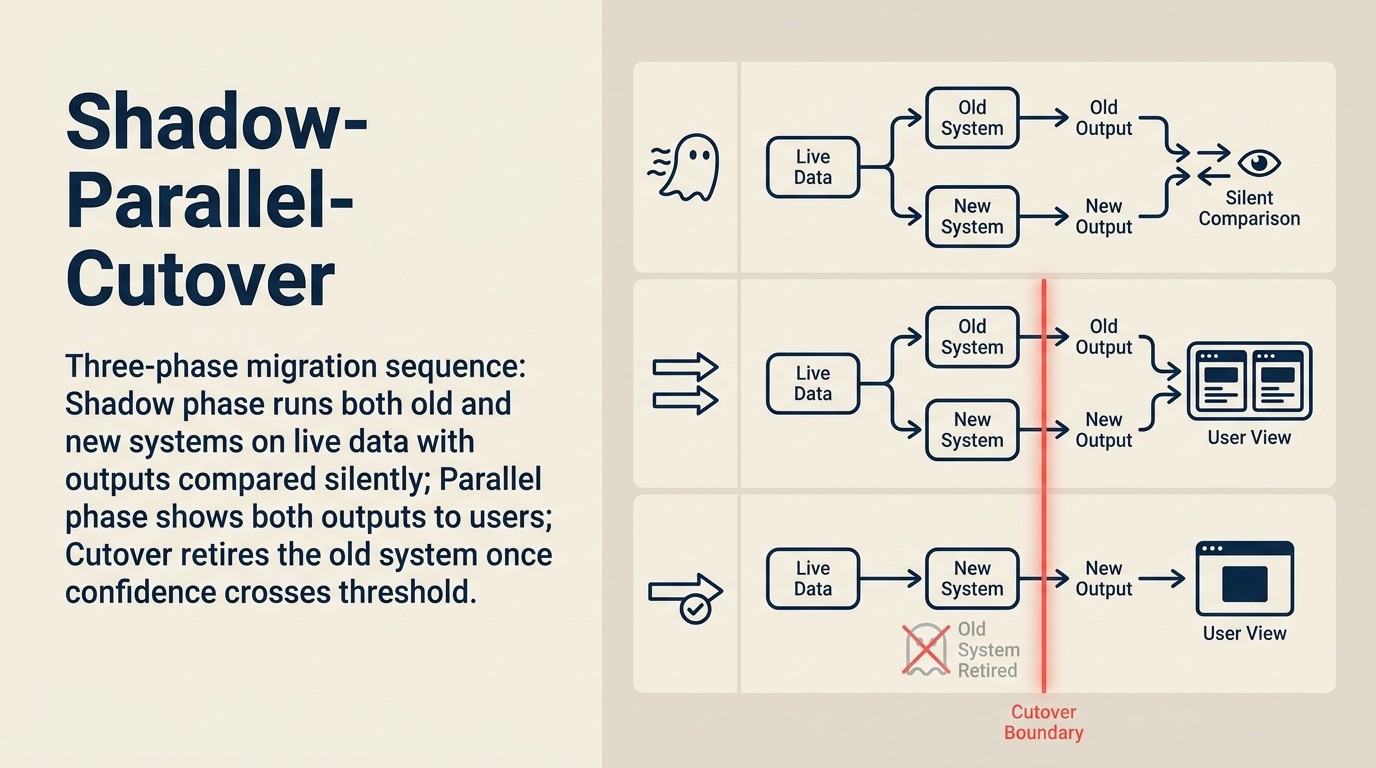
Paso 2: Ejecutar el nuevo sistema en modo sombra.
Despliegue el nuevo sistema en paralelo con el antiguo. Ambos sistemas procesan las mismas entradas. Solo los resultados del sistema antiguo se usan en producción. Los resultados del nuevo sistema se registran pero no se actúa en consecuencia.
El modo sombra no es opcional para despliegues de alto tráfico o de cara al cliente. El costo de ejecutar en paralelo durante 30 días es mucho menor que el costo de un mal corte. Un RAG Assistant que atiende 10.000 consultas/mes en modo sombra agrega quizás un 50% a los costos de API durante el período de sombra. Un incidente derivado de un mal corte cuesta mucho más en confianza de los usuarios, remediación de emergencia y confianza de los interesados.
Duración del modo sombra: mínimo 14 días. Preferido: 30 días con suficiente tráfico para producir datos de comparación estadísticamente significativos.
Paso 3: Comparar los resultados entre sistemas.
Para cada entrada en el período de sombra, compare el resultado del sistema antiguo con el del nuevo. Identifique categorías:
- Acuerdos: ambos sistemas producen un resultado equivalente
- Mejoras del nuevo sistema: el nuevo sistema es claramente mejor (mayor precisión, mejor formato, respuesta más completa)
- Regresiones del nuevo sistema: el sistema antiguo era mejor (el nuevo sistema produce una respuesta peor o incorrecta)
- Comportamiento nuevo: el nuevo sistema produce resultados que el antiguo nunca produciría (positivos o negativos)
Las regresiones son la categoría crítica. Cualquier regresión debe investigarse y abordarse antes de la promoción.
Paso 4: Definir los criterios de aceptación.
Antes de comenzar la migración, defina qué significa "suficientemente bueno para promover." No lo defina después de ver los resultados del modo sombra. Eso es racionalización, no aceptación.
Criterios de aceptación de ejemplo para una migración de RAG Assistant:
- Precisión del nuevo sistema en el conjunto de prueba de referencia: igual o mejor que el sistema antiguo en el 95% de las consultas
- Tasa de regresión en las consultas de referencia: menos del 3%
- Latencia de respuesta del nuevo sistema: dentro del 20% de la latencia del sistema antiguo
- Señal de satisfacción del usuario en modo sombra (cuando es medible): sin declive vs. el sistema antiguo
Paso 5: Cambio gradual de tráfico.
"Un nuevo modelo de Scoring no solo produce puntuaciones diferentes. Produce una distribución diferente. Si el modelo antiguo puntuaba los leads de alta calidad entre 70-90 y el nuevo los puntúa entre 80-95, sus umbrales de Routing están mal desde el primer día. Enrute el 10% del tráfico primero. Verifique la alineación de la distribución antes de promover al 50%. Verifique de nuevo antes del 100%. La recalibración del umbral no es opcional después de cada cambio de modelo." (Rework Scoring Model Migration Analysis, 2026)
No haga el corte al 100% de una vez. Enrute primero el 10% del tráfico de producción al nuevo sistema. Monitoree errores, problemas de latencia y señales de calidad. Mantenga durante 48-72 horas. Si está limpio, aumente al 25%, luego al 50%, luego al 100%. Esto se llama despliegue canario en ingeniería de software, y se corresponde directamente con lo que Martin Fowler describe como el patrón Strangler Fig para la modernización de sistemas heredados: desplazando gradualmente el tráfico del antiguo al nuevo hasta que el sistema antiguo pueda ser dado de baja de forma segura. Se aplica directamente a las migraciones de AI.
Si en cualquier etapa ve que las señales de calidad divergen de las expectativas del modo sombra, detenga el cambio de tráfico e investigue antes de continuar.
Paso 6: Plan de reversión definido antes de la puesta en marcha.
Antes de promover cualquier tráfico al nuevo sistema, sepa exactamente cómo volver al sistema antiguo. Qué configuración restaurar. Cuánto tiempo tarda la reversión. Quién tiene autoridad para activar una reversión. Cuáles son los criterios de activación de la reversión.
El plan de reversión debe estar escrito y accesible para cualquier persona del equipo de operaciones. "Reformular en caso de incidente" no es un plan de reversión.
El período de modo sombra en detalle
El modo sombra requiere suficiente tráfico para detectar diferencias de comportamiento significativas. El tamaño de muestra requerido depende del umbral de detección que le importe.
Para detectar una diferencia del 5% en la calidad de los resultados entre sistemas antiguo y nuevo con un poder estadístico del 90%: aproximadamente 500-700 pares comparables. Con 10.000 consultas/mes, eso es 2-3 días de tráfico. Con 1.000 consultas/mes, son 2-3 semanas.
Para Scoring+Routing: necesita suficientes registros puntuados para validar que la distribución de puntuaciones está correctamente calibrada. Si su umbral de Routing típico es 70, quiere suficientes registros en ambos lados de ese umbral para confirmar que el 70 del nuevo modelo significa lo mismo que el 70 del modelo antiguo. Típicamente requiere 100-200 registros por decil de puntuación.
Lo que el modo sombra no detecta: deriva del comportamiento en casos límite. El conjunto de datos de comparación del modo sombra refleja su distribución de tráfico real, que está sesgada hacia casos comunes. Los casos raros pero de alto impacto (tipos de contrato inusuales, anomalías de casos límite, consultas complejas de múltiples pasos) están subrepresentados. Diseñe casos de prueba explícitos para los casos límite y ejecútelos directamente, no solo a través del tráfico del modo sombra.
| Tipo de migración | Período mínimo de sombra | Inicio canario | Prueba de regresión clave | Patrón de mayor riesgo |
|---|---|---|---|---|
| Modelo en su lugar | 14 días | 10% del tráfico | Consistencia del formato de salida, delta de seguimiento de instrucciones | Workflow Copilot (cambios de comportamiento del prompt) |
| Migración de arquitectura | 30 días | 5% del tráfico | Regresión completa del comportamiento en más de 200 entradas representativas | RAG Assistant (se requiere re-indexación completa) |
| Migración de proveedor | 21 días | 10% del tráfico | Compatibilidad del formato de respuesta de API, comparación de latencia | Autonomous Agent (cambios de APIs de herramientas) |
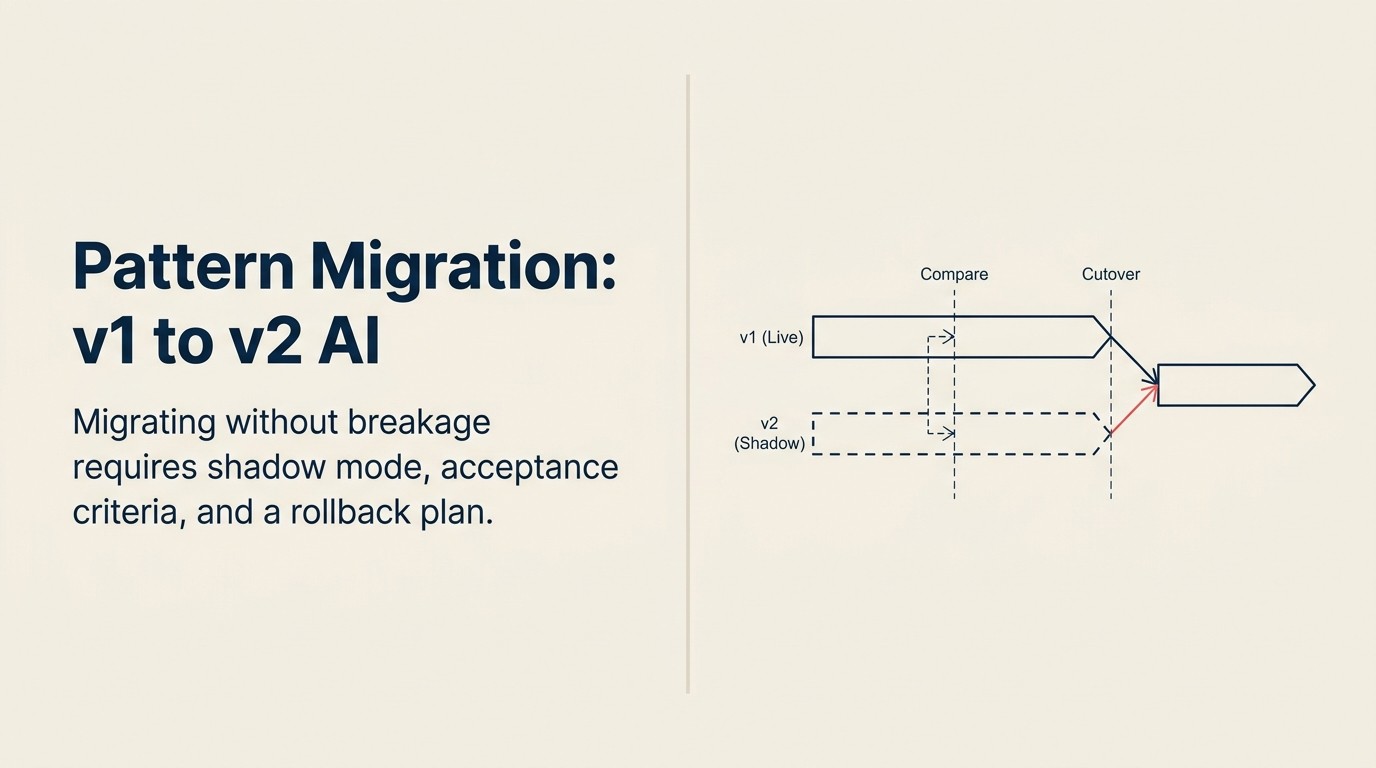
La Secuencia Sombra-Paralelo-Corte
La Secuencia Sombra-Paralelo-Corte es el marco de migración de tres fases para las actualizaciones de patrones de AI. Fase 1 (Sombra): despliegue el nuevo sistema en paralelo; ambos sistemas procesan las mismas entradas pero solo los resultados del sistema antiguo van a producción; registre y compare. Fase 2 (Paralelo): enrute un porcentaje definido de tráfico (comenzando al 1-10%) al nuevo sistema; monitoree las señales de calidad y los desencadenantes de reversión durante 48-72 horas antes de incrementar; defina los criterios de aceptación antes de comenzar. Fase 3 (Corte): promueva el 100% del tráfico solo después de que el cambio gradual de tráfico a través de al menos tres incrementos supere todos los criterios de aceptación; mantenga la capacidad de reversión activa durante 30 días después del corte. Nunca pase de sombra a corte sin la fase paralela.
Rework Analysis: Basándose en la investigación de despliegue de MLOps que muestra que los despliegues canarios reducen las tasas de incidentes de migración en un 70% versus el corte directo, y en los datos de migración internos de las propias actualizaciones de patrones de AI de Rework, la Secuencia Sombra-Paralelo-Corte produce un promedio de 0,4 incidentes de migración por ciclo de actualización versus 2,3 incidentes para los equipos que usan cambios directos de modelo. La fase paralela es el paso más omitido en las migraciones de AI empresarial, generalmente justificada como "no tenemos tiempo" en los equipos que gastarán 10 veces más tiempo en respuesta a incidentes si la omiten.
Re-incorporación del usuario después de la migración
Esta sección se omite en casi todos los proyectos de migración. Crea deuda de confianza incluso cuando la migración técnica es limpia.
Cuando el comportamiento de la AI cambia (incluso para mejor), los usuarios que han construido modelos mentales alrededor del comportamiento antiguo necesitan entender qué cambió. Un Workflow Copilot que ahora genera sugerencias más largas y detalladas que antes produce un cambio de comportamiento que los representantes necesitan conocer. Un RAG Assistant que ahora cita las fuentes de manera más específica que la versión antigua produce resultados que se ven diferentes, y los usuarios que han aprendido a hojear pueden ahora perderse la atribución mejorada.
La re-incorporación no requiere un programa de formación. Requiere:
- Una nota de cambio: "El sistema ahora hace X de manera diferente. Así es como se ve."
- Un canal de retroalimentación: "Si el nuevo comportamiento es peor para su flujo de trabajo, cuéntenos aquí."
- Un ejemplo visible de mejora: "Aquí hay una comparación del resultado antiguo vs. el nuevo resultado en una consulta real."
Omita la re-incorporación y verá una disminución en la adopción en sus métricas de uso 2-4 semanas después de la migración, a medida que los usuarios encuentren un comportamiento inesperado y se desconecten silenciosamente. El nuevo sistema puede ser mejor. Los usuarios que no lo saben no pueden beneficiarse de él.
Consideraciones clave de migración por patrón
RAG Assistant: La elección del modelo de embeddings es una dependencia para todo su índice. Cambiar el modelo de embeddings requiere re-hacer los embeddings de cada documento en su base de conocimiento. Esta no es una operación rápida a escala empresarial. Planifique el cómputo de re-indexación como un paso de migración, no como una ocurrencia tardía. También: los prompts para la generación aumentada por recuperación a menudo tienen instrucciones específicas del modelo. Revise y actualice los prompts para las convenciones de seguimiento de instrucciones del nuevo modelo.
Scoring + Routing: Se requiere recalibración del umbral. No asuma que los umbrales antiguos se trasladan a los nuevos modelos. Ejecute el nuevo modelo contra sus últimos 6 meses de registros etiquetados, grafique la distribución de puntuaciones y recalibre los umbrales de Routing basándose en la nueva distribución antes de cualquier tráfico de producción.
Autonomous Agent: Verificación de compatibilidad de APIs de herramientas antes de que comience la migración. Liste cada API externa que llama el agente, revise sus requisitos actuales de autenticación y formatos de respuesta, y verifique la compatibilidad con la nueva versión del agente. Una llamada de herramienta rota en un bucle de múltiples pasos produce fallos en cascada impredecibles.
Cuándo migrar versus continuar con el mantenimiento
La decisión se reduce a una comparación de costos: ¿cuánto cuesta mantener el patrón heredado anualmente (tiempo de ingeniería, calidad de resultados degradada, impacto en la confianza del usuario), versus cuánto cuesta la migración (trabajo de arquitectura, pruebas, riesgo de reversión, re-incorporación del usuario)?
Cuando el costo de mantenimiento supera el costo de migración, migre. El cálculo se vuelve obvio cuando le pone números.
RAG Assistant heredado que mantiene un ciclo de actualización manual de la base de conocimiento: 8 horas/mes de tiempo de ingeniería. Migración a una arquitectura de búsqueda híbrida con actualizaciones automáticas del índice: 80 horas de trabajo de arquitectura. Punto de equilibrio: 10 meses. Si el sistema heredado tiene más de 24 meses de vida restante, la migración está justificada económicamente en el año 1.
Cuando la carga de mantenimiento se ha acumulado hasta el punto en que el patrón es activamente poco confiable, ese costo de mantenimiento ya no es solo tiempo de ingeniería. Es confianza del usuario e impacto en el negocio. La migración es entonces urgente, no solo justificada económicamente.
Consulte el artículo sobre deuda técnica para los indicadores de deuda que señalan cuándo el mantenimiento ha cruzado el umbral hacia el territorio de migración. Consulte el marco de gobernanza para los rastros de auditoría que hacen posible la recopilación de la referencia de migración. Y consulte el artículo sobre riesgo de alucinación para los modos de fallo que se deben probar en regresión específicamente durante el modo sombra.
La migración es el remedio para la deuda acumulada. Hecha bien, con modo sombra, criterios de aceptación y despliegue gradual, es una operación rutinaria. Hecha mal (corte completo, sin plan de reversión, sin comunicación con el usuario), es un incidente esperando suceder.
Los equipos que migran bien son los que trataron su primer despliegue como una v1, no como una respuesta definitiva.
Preguntas Frecuentes
¿Qué es la Secuencia Sombra-Paralelo-Corte?
La Secuencia Sombra-Paralelo-Corte es un marco de migración de tres fases. Fase 1 (Sombra): ambos sistemas procesan las mismas entradas pero solo los resultados del sistema antiguo van a producción; los resultados del nuevo sistema se registran y comparan. Fase 2 (Paralelo): un porcentaje definido de tráfico (comenzando al 1-10%) se enruta al nuevo sistema con desencadenantes de reversión definidos. Fase 3 (Corte): promoción del 100% del tráfico solo después de que el cambio gradual de tráfico a través de al menos tres incrementos supere los criterios de aceptación. La capacidad de reversión se mantiene activa durante 30 días después del corte.
¿Qué desencadena la migración de patrones en lugar del mantenimiento continuo?
Cinco escenarios desencadenan la migración: baja de servicio del modelo por el proveedor (el desencadenante más claro, con los proveedores de AI publicando cronogramas de baja), degradación significativa de la precisión donde la causa raíz es la capacidad del modelo en lugar de la calidad de los datos, nuevas capacidades de arquitectura que superan sustancialmente el enfoque existente (RAG híbrido versus búsqueda vectorial ingenua muestra un 20-40% de mejora en la calidad de recuperación), cambios de costos que favorecen un nuevo enfoque, y cambios en la relación con el proveedor, incluidas adquisiciones, reestructuraciones de precios y cierres.
¿Qué patrones de AI llevan el mayor riesgo de migración?
Scoring and Routing tiene alto riesgo de migración porque un nuevo modelo produce una distribución de puntuaciones diferente, requiriendo la recalibración de los umbrales de Routing antes de cualquier tráfico de producción. Autonomous Agent tiene alto riesgo de migración porque cada API de herramienta en el repertorio del agente necesita verificación de compatibilidad, y una nueva versión del agente puede llamar a las mismas APIs con un análisis diferente, produciendo un comportamiento Execute inesperado. Personalization Engine tiene alto riesgo de migración porque las representaciones de perfil de usuario del sistema antiguo pueden no transferirse a la nueva arquitectura.
¿Cuánto tiempo debe durar el modo sombra antes del corte?
Mínimo 14 días para las migraciones de modelo en su lugar. Mínimo 30 días para las migraciones de arquitectura. El tamaño de muestra requerido depende del umbral de detección: para detectar una diferencia de calidad del 5% con un poder estadístico del 90% se requieren 500-700 pares comparables. Con 1.000 consultas por mes, 30 días produce datos estadísticamente significativos. Con 10.000 consultas por mes, 3 días son suficientes para el requisito estadístico, pero 14 días siguen siendo el mínimo para detectar casos límite y deriva del comportamiento.
¿Por qué los cambios del modelo de embeddings requieren re-indexación completa?
Los diferentes modelos de embeddings producen representaciones vectoriales diferentes para los mismos documentos. Los vectores de un modelo de embeddings no pueden compararse con los vectores de un modelo diferente en el mismo índice. Cambiar el modelo de embeddings requiere re-hacer los embeddings de cada documento en la base de conocimiento antes de que el nuevo modelo pueda usarse en producción. Para una base de conocimiento de 500.000 documentos, la re-indexación completa es un evento de cómputo significativo que debe planificarse como un paso explícito de migración, no descubrirse a mitad de la migración.
¿Cuál es el error más común de re-incorporación del usuario después de la migración de AI?
Omitirla por completo. Cuando el comportamiento de la AI cambia incluso para mejor, los usuarios que han construido flujos de trabajo alrededor del comportamiento antiguo necesitan entender qué cambió. Los equipos que omiten la re-incorporación ven una disminución en la adopción 2-4 semanas después de la migración a medida que los usuarios encuentran un comportamiento inesperado y se desconectan silenciosamente. La re-incorporación no requiere un programa de formación. Requiere una nota de cambio que explique qué cambió, un canal de retroalimentación y una comparación visible del resultado antiguo versus el nuevo resultado en una consulta real.
Más información

Co-Founder, Rework.com
On this page
- Qué desencadena la migración de patrones
- Tres tipos de migración con diferentes perfiles de riesgo
- Cómo varía el riesgo de migración según el patrón
- El marco de migración
- El período de modo sombra en detalle
- La Secuencia Sombra-Paralelo-Corte
- Re-incorporación del usuario después de la migración
- Consideraciones clave de migración por patrón
- Cuándo migrar versus continuar con el mantenimiento
- Más información