Migrasi Pola: Berpindah dari v1 ke v2 AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Generasi pertama AI enterprise sudah menua. Tim yang men-deploy RAG Assistant pada 2022 membangunnya di atas text-embedding-ada-002. Tim yang men-deploy model scoring pada 2023 melatihnya pada infrastruktur data pra-GPT4. Tim yang membangun Workflow Copilot di awal 2024 merancang prompt untuk model yang sejak itu telah digantikan oleh dua generasi.
Sistem-sistem ini masih berjalan. Itulah masalahnya. Mereka berjalan diam-diam, mengakumulasi technical dan operational debt, sementara arsitektur yang lebih baik hanya satu migrasi jauhnya. Tim yang berjalan pada infrastruktur yang dihentikan tidak gagal. Mereka hanya meninggalkan kemampuan di meja sementara backlog migrasi mereka tumbuh.
Migrasi bukan opsional. Tetapi ini juga tidak setara dengan peningkatan versi perangkat lunak. Perilaku AI bersifat probabilistik. "Berfungsi sebagaimana dimaksud" bukan kondisi biner. Anda tidak dapat hanya menukar model, menjalankan test suite, dan menyebutnya selesai. Perubahan perilaku dari pembaruan model itu nyata, terkadang halus, dan terkadang signifikan. Dan pengguna yang telah membangun alur kerja di sekitar perilaku lama perlu mengetahui apa yang berubah.
Artikel ini ditujukan untuk tim yang membangun sesuatu pada 2022-2024 dan perlu meningkatkannya tanpa merusak produksi.
Apa yang memicu migrasi pola
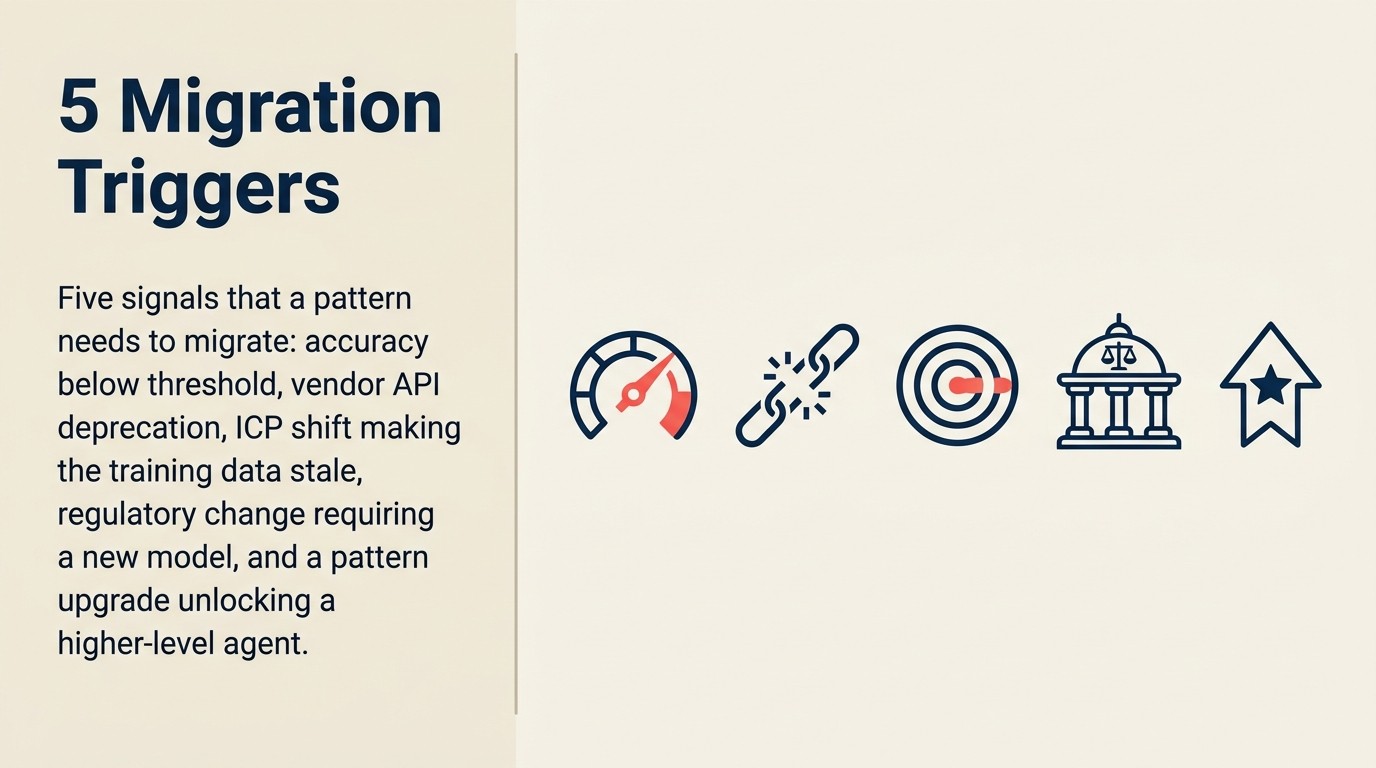
Lima skenario mendorong pola ke migrasi daripada pemeliharaan berkelanjutan:
Penghentian model oleh vendor. Pemicu paling jelas. OpenAI, Anthropic, Google, dan Azure semua menerbitkan timeline penghentian dengan tanggal end-of-life. Ketika model yang bergantung pada pola Anda mencapai EOL, Anda bermigrasi atau rusak. Sebagian besar tim AI enterprise telah mengalami ini setidaknya sekali: API mengembalikan pemberitahuan penghentian, dan tiba-tiba migrasi yang tidak ada di roadmap menjadi mendesak. Dokumentasi penghentian model Anthropic memberikan setidaknya 60 hari pemberitahuan sebelum penghentian, tetapi timeline tersebut mengasumsikan Anda memantau pemberitahuan. Permintaan API ke model yang dihentikan gagal secara sunyi dari perspektif pemanggil kecuali pemantauan ada.
Implikasi operasional: pola produksi mana pun harus memiliki jawaban terdokumentasi tentang "apa yang terjadi jika model ini dihentikan kuartal depan?" Tidak harus rencana migrasi lengkap, tetapi setidaknya penilaian tentang apa yang akan menjadi cakupan migrasi.
Degradasi akurasi yang signifikan. Ketika tinjauan akurasi triwulanan menunjukkan penurunan yang konsisten, dan akar penyebabnya adalah kemampuan model daripada kualitas data atau kualitas prompt, migrasi ke model yang lebih baik adalah solusinya. Diagnosisnya penting: data drift memerlukan retraining atau pembaruan data; masalah kualitas prompt memerlukan rekayasa prompt; kesenjangan kemampuan model memerlukan migrasi model.
Kemampuan baru yang membuat pendekatan yang ada menjadi usang. Perpindahan dari RAG pencarian vektor murni ke hybrid keyword-vector-rerank adalah contoh terbaru yang paling jelas. Tim yang membangun RAG pada 2022 dengan pencarian semantik murni meninggalkan peningkatan kualitas retrieval 20-40% dibandingkan pendekatan hybrid. Artikel risiko hallusinasi per pola menjelaskan mengapa kualitas retrieval sangat penting untuk akurasi RAG. Sistem yang ada tidak rusak. Ia hanya secara substansial diungguli oleh arsitektur v2 yang tidak ada saat v1 dibangun.
Perubahan biaya yang menguntungkan pendekatan baru. Pola yang dibangun di atas GPT-4 dengan harga 2023 mungkin sekarang dapat digantikan secara ekonomis dengan model yang lebih kecil, lebih cepat, lebih murah yang telah mengejar kemampuan. Atau, pola yang dibangun di atas tooling vendor proprietary mungkin dapat digantikan dengan infrastruktur open-source dengan sebagian kecil biaya. Lihat artikel cost overrun untuk perbandingan model biaya.
Perubahan hubungan vendor. Akuisisi, restrukturisasi harga, dan penutupan produk terjadi. Pola yang dibangun di atas API AI startup yang kemudian ditutup adalah skenario kasus terburuk: migrasi paksa pada timeline darurat. Penilaian risiko konsentrasi vendor harus menjadi bagian dari tinjauan governance AI Anda.
Key Facts: Realitas Migrasi Pola AI
- Generasi pertama AI enterprise (di-deploy 2022-2024) sudah mencapai pemicu migrasi: penghentian model, kesenjangan kemampuan dari arsitektur baru (hybrid RAG versus pencarian vektor naive menunjukkan peningkatan kualitas retrieval 20-40%), dan data debt yang terakumulasi.
- Shadow testing diikuti oleh canary deployment pada 1-10% traffic sekarang menjadi praktik standar untuk rollout model AI enterprise, dengan pendekatan empat fase: POC (2-4 minggu), Pilot pada traffic 5-10% (4-8 minggu), dan deployment skala penuh (8-12 minggu). (MLOps Deployment Research, 2026)
- Migrasi berbasis AI dengan sequencing canary yang tepat meningkatkan efisiensi operasional sebesar 20-25% dan mengurangi waktu siklus deployment sebesar 70% dibandingkan pendekatan direct cutover. (QualityKiosk Migration Analysis, 2026)
Tiga jenis migrasi dengan profil risiko yang berbeda
Tipe 1: Migrasi model-in-place. Ganti model yang mendasarinya sambil mempertahankan arsitektur. Pipeline retrieval yang sama, struktur prompt yang sama, lapisan integrasi yang sama. Hanya pemanggilan model yang berbeda. Ini adalah jenis migrasi dengan risiko infrastruktur terendah, tetapi masih memerlukan pengujian regresi perilaku karena model baru mungkin merespons prompt yang sama secara berbeda, bahkan dengan instruksi yang sama.
Contoh: mengganti GPT-3.5 Turbo dengan GPT-4o Mini untuk RAG Assistant. Arsitektur yang sama, model yang lebih baik. Tetapi GPT-4o Mini mengikuti instruksi lebih tepat daripada GPT-3.5 Turbo, yang berarti prompt yang mengandalkan kecenderungan model yang lebih lama untuk sedikit longgar dengan format mungkin sekarang menghasilkan output dalam format yang tidak terduga.
Tipe 2: Migrasi arsitektur. Bangun ulang pola dengan pendekatan yang berbeda. Kasus penggunaan sama; implementasinya secara fundamental berbeda. RAG dari pencarian single-vektor naive ke hybrid keyword-vector-rerank adalah migrasi arsitektur. Meeting Intelligence dari pipeline transkripsi-saja ke pipeline transkripsi-plus-speaker-diarization-plus-deteksi-topik adalah migrasi arsitektur.
Migrasi arsitektur membawa kompleksitas tertinggi dan potensi peningkatan kualitas tertinggi. Ini lebih dekat ke membangun sistem baru daripada meningkatkan yang sudah ada, yang berarti memerlukan framework migrasi penuh.
Tipe 3: Migrasi vendor. Memindahkan implementasi pola yang sama ke vendor yang berbeda. Beralih RAG Assistant dari Azure OpenAI ke Anthropic Claude. Beralih Meeting Intelligence dari AssemblyAI ke Deepgram. Polanya tetap sama; tumpukan vendor berubah.
Migrasi vendor sering terlihat lebih sederhana dari yang sebenarnya. Vendor yang berbeda memiliki konvensi API yang berbeda, karakteristik latensi yang berbeda, default pemformatan output yang berbeda, dan perilaku model yang berbeda pada prompt yang sama. Apa yang berhasil di Vendor A mungkin memerlukan penyesuaian prompt di Vendor B bahkan jika kedua vendor mengklaim kemampuan setara.
Bagaimana risiko migrasi bervariasi per pola

Tidak semua migrasi pola membawa risiko yang sama. Memahami di mana risiko terkonsentrasi membantu Anda memprioritaskan waktu pengujian dan staging.
Pola dengan risiko migrasi tinggi:
Scoring dan Routing: Model scoring baru tidak hanya menghasilkan skor yang berbeda. Ini menghasilkan distribusi yang berbeda. Jika model lama menilai lead berkualitas tinggi pada 70-90 dan model baru menilainya pada 80-95, ambang routing Anda salah dari hari pertama. Logika routing yang dibangun di atas "arahkan ke tim enterprise jika skor > 75" sekarang merutekan secara berbeda, berpotensi salah menetapkan sebagian besar volume lead Anda. Rekalibrasi ambang diperlukan setelah setiap penggantian model, bukan opsional.
Autonomous Agent: Setiap API tool dalam repertoar agent perlu verifikasi kompatibilitas sebelum migrasi. Versi agent baru mungkin memanggil API yang sama tetapi mengurai respons secara berbeda, atau mungkin memanggil alat dalam urutan yang berbeda, menghasilkan perilaku Execute yang berbeda bahkan untuk input yang sama. Pengujian regresi perilaku penuh diperlukan.
Personalization Engine: Representasi profil pengguna dari sistem lama mungkin tidak ditransfer secara bermakna ke arsitektur baru. Jika model baru membangun profil pengguna secara berbeda, minggu-minggu pertama produksi akan memiliki kualitas personalisasi yang berkurang seiring profil dibangun ulang.
Pola dengan risiko migrasi sedang:
RAG Assistant: Perubahan model embedding memerlukan re-indexing penuh. Model embedding yang berbeda menghasilkan representasi vektor yang berbeda untuk dokumen yang sama, sehingga Anda tidak dapat mencampur embedding dari model yang berbeda dalam indeks yang sama. Re-indexing penuh pada knowledge base 500.000 dokumen adalah peristiwa komputasi yang signifikan yang perlu direncanakan, bukan ditemukan.
Workflow Copilot: Perilaku prompt berubah antar model. Instruksi yang menghasilkan saran ringkas pada model lama mungkin menghasilkan saran yang panjang pada model baru. Tinjauan kualitas nada saran, panjang, dan akurasi diperlukan sebelum promosi.
Document Review: Kompatibilitas skema ekstraksi. Model baru mungkin mengekstraksi informasi klausul dalam format yang sedikit berbeda yang merusak integrasi alur kerja hukum downstream.
Pola dengan risiko migrasi lebih rendah:
Meeting Intelligence: Beralih ke vendor transkripsi yang berbeda relatif berisiko rendah karena output transkripsi terstandarisasi (teks dengan timestamp). Analisis tingkat lebih tinggi (ringkasan, item tindakan) membawa lebih banyak risiko perilaku.
Vision Extract: Selama skema ekstraksi dipertahankan, perubahan model memiliki risiko lebih rendah karena output dibatasi pada field tertentu. Penyimpangan format adalah risiko utama, bukan ketidakpastian perilaku.
Anomaly Agent: Migrasi ke model deteksi anomali yang lebih baik memerlukan penetapan ulang baseline, tetapi logika alerting fundamental biasanya independen dari model.
Framework migrasi
Langkah 1: Buat baseline sistem saat ini.
Sebelum menyentuh apa pun dalam migrasi, tangkap baseline komprehensif dari perilaku sistem saat ini. Ini adalah set perbandingan regresi Anda.
Untuk RAG Assistant: jalankan 200 query representatif terhadap sistem saat ini. Catat query, dokumen yang diambil, dan respons yang dihasilkan. Klasifikasikan setiap respons sebagai akurat, sebagian akurat, atau tidak akurat terhadap ground truth. Ini menjadi test suite penerimaan Anda.
Untuk model Scoring+Routing: tarik 90 hari terakhir keputusan scoring. Catat fitur input dan skor untuk 500 catatan representatif. Perhatikan outcome aktual (apakah lead berskor tinggi berkonversi? apakah anomali yang ditandai ternyata nyata?). Ini adalah baseline kalibrasi Anda.
Jangan mulai migrasi tanpa baseline. Jika Anda tidak dapat membandingkan perilaku sistem baru dengan perilaku sistem lama pada input yang sama, Anda tidak memiliki kriteria migrasi. Hanya perasaan.
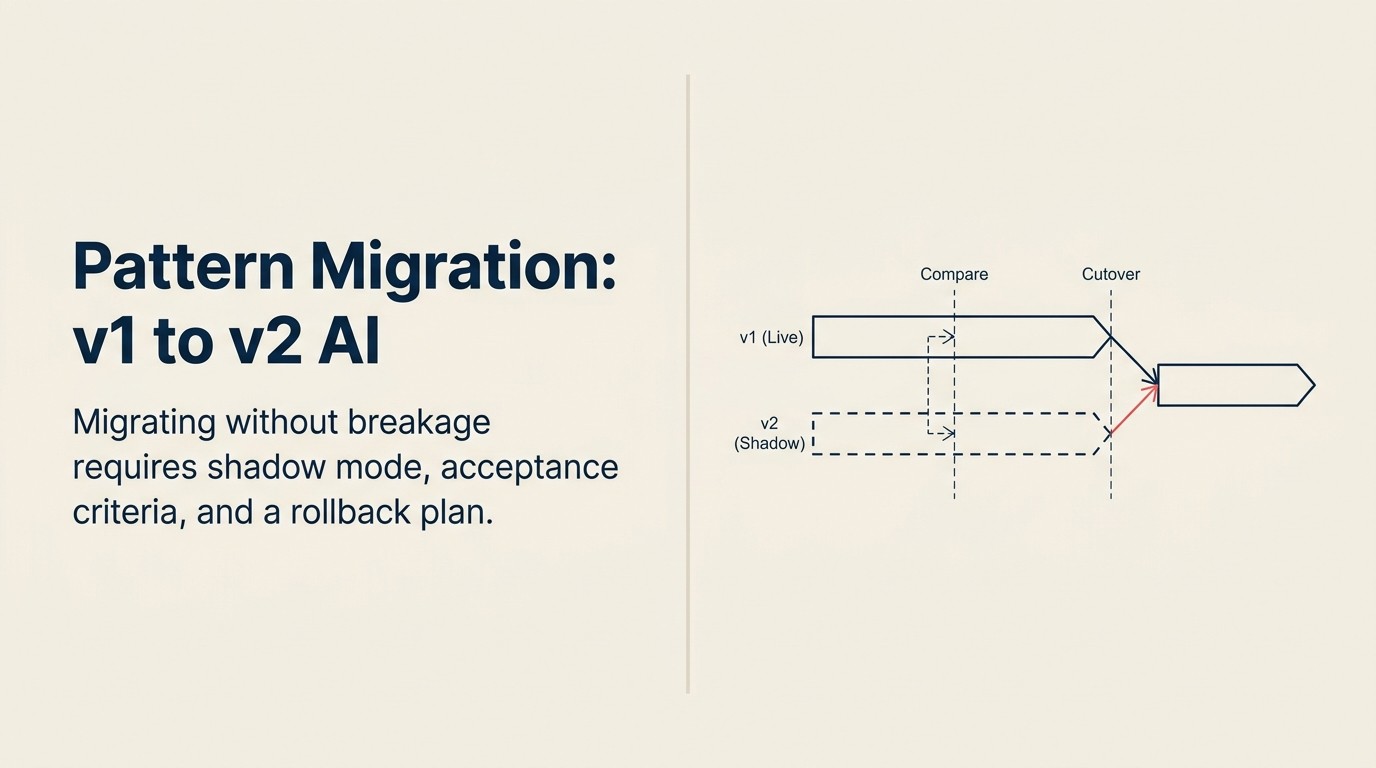
Langkah 2: Jalankan sistem baru dalam shadow mode.
Deploy sistem baru secara paralel dengan yang lama. Kedua sistem memproses input yang sama. Hanya output sistem lama yang digunakan dalam produksi. Output sistem baru dicatat tetapi tidak ditindaklanjuti.
Shadow mode bukan opsional untuk deployment bertraffic tinggi atau berhadapan dengan pelanggan. Biaya menjalankan secara paralel selama 30 hari jauh lebih rendah dari biaya cutover yang buruk. RAG Assistant yang melayani 10.000 query/bulan dalam shadow mode menambahkan sekitar 50% ke biaya API untuk periode shadow. Insiden dari cutover yang buruk jauh lebih mahal dalam kepercayaan pengguna, remediasi darurat, dan kepercayaan pemangku kepentingan.
Durasi shadow mode: minimum 14 hari. Disukai: 30 hari dengan traffic yang cukup untuk menghasilkan data perbandingan yang bermakna secara statistik.
Langkah 3: Bandingkan output antar sistem.
Untuk setiap input dalam periode shadow, bandingkan output sistem lama dengan output sistem baru. Identifikasi kategori:
- Persetujuan: kedua sistem menghasilkan output yang setara
- Peningkatan sistem baru: sistem baru jelas lebih baik (akurasi lebih tinggi, format lebih baik, respons lebih lengkap)
- Regresi sistem baru: sistem lama lebih baik (sistem baru menghasilkan jawaban yang lebih buruk atau salah)
- Perilaku baru: sistem baru menghasilkan output yang tidak pernah dihasilkan sistem lama (positif atau negatif)
Regresi adalah kategori kritis. Setiap regresi harus diselidiki dan ditangani sebelum promosi.
Langkah 4: Tentukan kriteria penerimaan.
Sebelum memulai migrasi, tentukan apa arti "cukup baik untuk dipromosikan". Jangan menentukannya setelah Anda melihat hasil shadow mode. Itu adalah rasionalisasi, bukan penerimaan.
Contoh kriteria penerimaan untuk migrasi RAG Assistant:
- Akurasi sistem baru pada set pengujian baseline: sama dengan atau lebih baik dari sistem lama pada 95% query
- Tingkat regresi pada query baseline: kurang dari 3%
- Latensi respons sistem baru: dalam 20% latensi sistem lama
- Sinyal kepuasan pengguna shadow mode (ketika dapat diukur): tidak ada penurunan dibandingkan sistem lama
Langkah 5: Pergeseran traffic bertahap.
"Model scoring baru tidak hanya menghasilkan skor yang berbeda. Ini menghasilkan distribusi yang berbeda. Jika model lama menilai lead berkualitas tinggi pada 70-90 dan model baru menilainya pada 80-95, ambang routing Anda salah dari hari pertama. Rutekan 10% traffic terlebih dahulu. Periksa keselarasan distribusi sebelum mempromosikan ke 50%. Periksa lagi sebelum 100%. Rekalibrasi ambang bukan opsional setelah setiap penggantian model." (Rework Scoring Model Migration Analysis, 2026)
Jangan beralih 100% sekaligus. Rutekan 10% traffic produksi ke sistem baru terlebih dahulu. Pantau kesalahan, masalah latensi, dan sinyal kualitas. Tahan selama 48-72 jam. Jika bersih, tingkatkan ke 25%, kemudian 50%, kemudian 100%. Ini disebut canary deployment dalam rekayasa perangkat lunak, dan memetakan langsung ke apa yang Martin Fowler deskripsikan sebagai pola Strangler Fig untuk modernisasi legacy: secara bertahap mengalihkan traffic dari yang lama ke yang baru sampai sistem lama dapat dinonaktifkan dengan aman. Ini berlaku langsung untuk migrasi AI.
Jika pada tahap mana pun Anda melihat sinyal kualitas menyimpang dari ekspektasi shadow mode, hentikan pergeseran traffic dan selidiki sebelum melanjutkan.
Langkah 6: Rencana rollback didefinisikan sebelum go-live.
Sebelum Anda mempromosikan traffic apa pun ke sistem baru, ketahui persis cara Anda kembali ke sistem lama. Konfigurasi mana yang perlu dipulihkan. Berapa lama rollback berlangsung. Siapa yang memiliki wewenang untuk memicu rollback. Apa kriteria pemicu rollback.
Rencana rollback harus tertulis dan dapat diakses oleh siapa pun di tim operasi. "Reformulasikan jika terjadi insiden" bukan rencana rollback.
Periode shadow mode secara detail
Shadow mode memerlukan traffic yang cukup untuk mendeteksi perbedaan perilaku yang bermakna. Ukuran sampel yang diperlukan bergantung pada ambang deteksi yang Anda pedulikan.
Untuk mendeteksi perbedaan 5% dalam kualitas output antara sistem lama dan baru dengan kekuatan statistik 90%: sekitar 500-700 pasang yang sebanding. Dengan 10.000 query/bulan, itu 2-3 hari traffic. Dengan 1.000 query/bulan, itu 2-3 minggu.
Untuk Scoring+Routing: Anda memerlukan cukup catatan yang dinilai untuk memvalidasi bahwa distribusi skor dikalibrasi dengan benar. Jika ambang routing tipikal Anda adalah 70, Anda ingin cukup catatan di kedua sisi ambang tersebut untuk mengkonfirmasi bahwa 70 model baru berarti hal yang sama dengan 70 model lama. Biasanya memerlukan 100-200 catatan per desil skor.
Yang tidak ditangkap shadow mode: behavioral drift pada edge case. Dataset perbandingan dari shadow mode mencerminkan distribusi traffic aktual Anda, yang condong ke kasus umum. Kasus langka tetapi berdampak tinggi (jenis kontrak yang tidak biasa, anomali edge-case, query multi-hop yang kompleks) kurang terwakili. Rancang kasus pengujian eksplisit untuk edge case dan jalankannya secara langsung, bukan hanya melalui traffic shadow mode.
| Jenis migrasi | Periode shadow minimum | Mulai canary | Pengujian regresi kunci | Pola dengan risiko tertinggi |
|---|---|---|---|---|
| Model-in-place | 14 hari | 10% traffic | Konsistensi format output, delta pengikutan instruksi | Workflow Copilot (perubahan perilaku prompt) |
| Migrasi arsitektur | 30 hari | 5% traffic | Regresi perilaku penuh pada 200+ input representatif | RAG Assistant (re-index penuh diperlukan) |
| Migrasi vendor | 21 hari | 10% traffic | Kompatibilitas format respons API, perbandingan latensi | Autonomous Agent (perubahan API tool) |
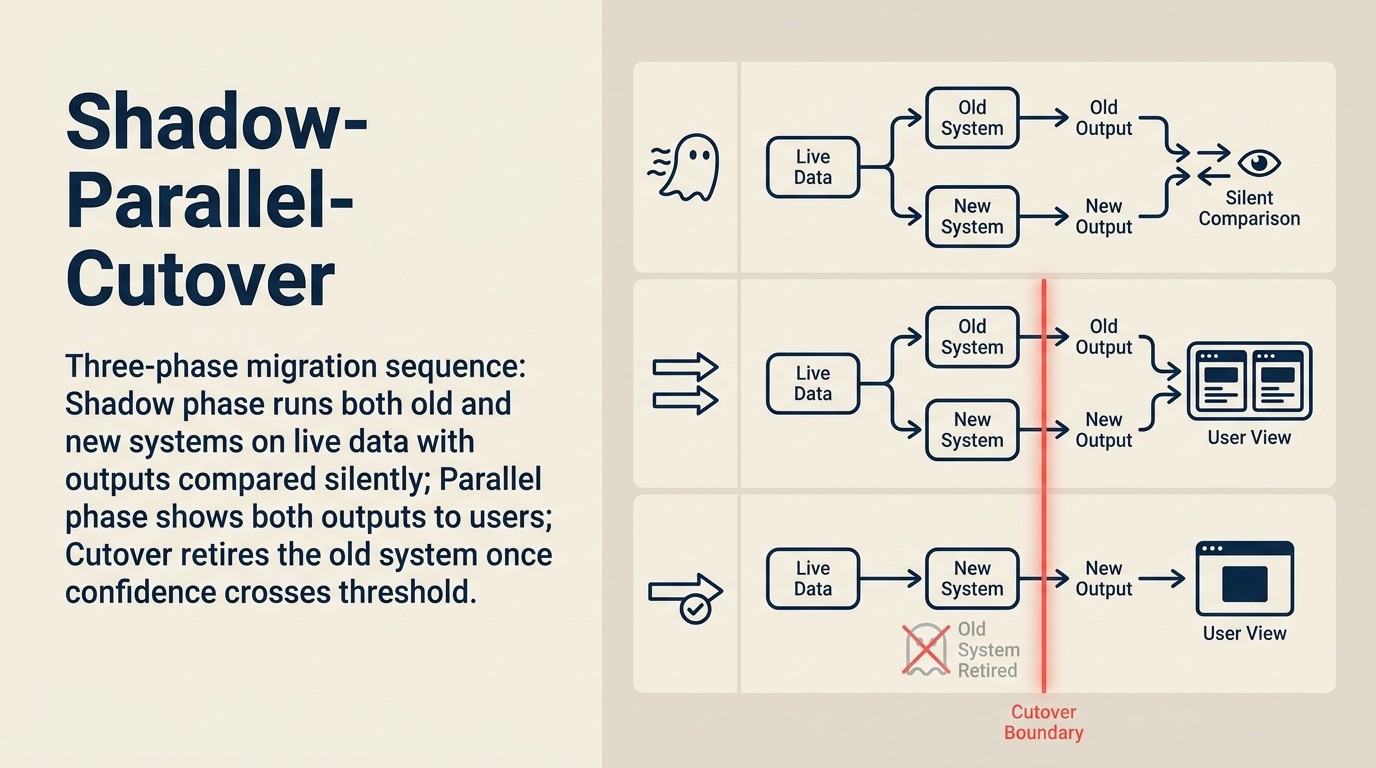
Shadow-Parallel-Cutover Sequence
Shadow-Parallel-Cutover Sequence adalah framework migrasi tiga fase untuk peningkatan pola AI. Fase 1 (Shadow): deploy sistem baru secara paralel; kedua sistem memproses input yang sama tetapi hanya output sistem lama yang digunakan dalam produksi; catat dan bandingkan. Fase 2 (Parallel): rutekan persentase traffic yang ditentukan (mulai dari 1-10%) ke sistem baru; pantau sinyal kualitas dan pemicu revert selama 48-72 jam sebelum menambah; tentukan kriteria penerimaan sebelum memulai. Fase 3 (Cutover): promosi traffic 100% hanya setelah pergeseran traffic bertahap di setidaknya tiga kenaikan memenuhi semua kriteria penerimaan; simpan kemampuan rollback aktif selama 30 hari setelah cutover. Jangan pernah melanjutkan dari shadow ke cutover tanpa fase paralel.
Rework Analysis: Berdasarkan riset deployment MLOps yang menunjukkan canary deployment mengurangi tingkat insiden migrasi sebesar 70% versus direct cutover, dan data migrasi internal dari peningkatan pola AI Rework sendiri, Shadow-Parallel-Cutover Sequence menghasilkan rata-rata 0,4 insiden migrasi per siklus peningkatan versus 2,3 insiden untuk tim yang menggunakan penggantian model langsung. Fase paralel adalah langkah yang paling sering dilewati dalam migrasi AI enterprise, biasanya dibenarkan sebagai "kami tidak punya waktu" di tim yang akan menghabiskan 10x lebih banyak waktu untuk respons insiden jika melewatinya.
Re-onboarding pengguna setelah migrasi
Bagian ini dilewatkan di hampir setiap proyek migrasi. Ini menciptakan trust debt bahkan ketika migrasi teknis bersih.
Ketika perilaku AI berubah (bahkan menjadi lebih baik), pengguna yang telah membangun model mental di sekitar perilaku lama perlu memahami apa yang berubah. Workflow Copilot yang sekarang menghasilkan saran yang lebih panjang dan lebih detail dari sebelumnya menghasilkan perubahan perilaku yang perlu diketahui rep. RAG Assistant yang sekarang mengutip sumber lebih spesifik dari versi lama menghasilkan output yang terlihat berbeda, dan pengguna yang terbiasa membaca sekilas mungkin sekarang melewatkan atribusi yang ditingkatkan.
Re-onboarding tidak memerlukan program pelatihan. Ini memerlukan:
- Catatan perubahan: "Sistem sekarang melakukan X secara berbeda. Ini tampilannya."
- Saluran umpan balik: "Jika perilaku baru lebih buruk untuk alur kerja Anda, beri tahu kami di sini."
- Contoh peningkatan yang terlihat: "Ini adalah perbandingan output lama vs. baru pada query nyata."
Lewatkan re-onboarding dan Anda akan melihat penurunan adopsi dalam metrik penggunaan Anda 2-4 minggu setelah migrasi, karena pengguna menghadapi perilaku yang tidak terduga dan secara diam-diam berhenti berinteraksi. Sistem baru mungkin lebih baik. Pengguna yang tidak tahu itu tidak dapat memanfaatkannya.
Pertimbangan utama migrasi per pola
RAG Assistant: Pilihan model embedding adalah ketergantungan untuk seluruh indeks Anda. Mengubah model embedding memerlukan re-embedding setiap dokumen dalam knowledge base Anda. Ini bukan operasi cepat pada skala enterprise. Rencanakan komputasi re-indexing sebagai langkah migrasi, bukan sebagai renungan. Juga: prompt untuk retrieval-augmented generation sering memiliki instruksi spesifik model. Tinjau dan perbarui prompt untuk konvensi pengikutan instruksi model baru.
Scoring + Routing: Rekalibrasi ambang diperlukan. Jangan asumsikan ambang lama diterjemahkan ke model baru. Jalankan model baru terhadap 6 bulan terakhir catatan berlabel Anda, plot distribusi skor, dan kalibrasi ulang ambang routing berdasarkan distribusi baru sebelum traffic produksi apa pun.
Autonomous Agent: Pemeriksaan kompatibilitas API tool sebelum migrasi dimulai. Daftarkan setiap API eksternal yang dipanggil agent, tinjau persyaratan autentikasi dan format respons saat ini, dan verifikasi kompatibilitas dengan versi agent baru. Satu pemanggilan tool yang rusak dalam loop multi-langkah menghasilkan kegagalan kaskade yang tidak dapat diprediksi.
Kapan bermigrasi vs. terus memelihara
Keputusan bergantung pada perbandingan biaya: berapa biaya memelihara pola legacy setiap tahun (waktu rekayasa, kualitas output yang menurun, dampak kepercayaan pengguna), versus berapa biaya migrasi (pekerjaan arsitektur, pengujian, risiko rollback, re-onboarding pengguna)?
Ketika biaya pemeliharaan melebihi biaya migrasi, bermigrasi. Perhitungan menjadi jelas ketika Anda memasukkan angka.
RAG Assistant legacy yang mempertahankan siklus pembaruan knowledge base manual: 8 jam/bulan waktu rekayasa. Migrasi ke arsitektur pencarian hybrid dengan pembaruan indeks otomatis: 80 jam kerja arsitektur. Break-even: 10 bulan. Jika sistem legacy memiliki masa hidup tersisa 24+ bulan, migrasi dibenarkan secara ekonomis di tahun 1.
Ketika beban pemeliharaan telah menumpuk ke titik di mana pola secara aktif tidak andal, biaya pemeliharaan tersebut bukan lagi hanya waktu rekayasa. Ini adalah kepercayaan pengguna dan dampak bisnis. Migrasi kemudian mendesak, bukan hanya dibenarkan secara ekonomis.
Lihat artikel tech debt untuk indikator debt yang menandai kapan pemeliharaan telah melewati ambang ke wilayah migrasi. Lihat framework governance untuk audit trail yang membuat pengumpulan baseline migrasi menjadi mungkin. Dan lihat artikel risiko hallusinasi untuk mode kegagalan yang perlu diuji regresi secara khusus selama shadow mode.
Migrasi adalah obat untuk debt yang terakumulasi. Dilakukan dengan baik, dengan shadow mode, kriteria penerimaan, dan rollout bertahap, ini adalah operasi rutin. Dilakukan dengan buruk (cutover penuh, tanpa rencana rollback, tanpa komunikasi pengguna), ini adalah insiden yang menunggu untuk terjadi.
Tim yang bermigrasi dengan baik adalah tim yang memperlakukan deployment pertama mereka sebagai v1, bukan jawaban akhir.
Pertanyaan yang Sering Diajukan
Apa itu Shadow-Parallel-Cutover Sequence?
Shadow-Parallel-Cutover Sequence adalah framework migrasi tiga fase. Fase 1 (Shadow): kedua sistem memproses input yang sama tetapi hanya output sistem lama yang masuk ke produksi; output sistem baru dicatat dan dibandingkan. Fase 2 (Parallel): persentase traffic yang ditentukan (mulai dari 1-10%) diarahkan ke sistem baru dengan pemicu revert yang terdefinisi. Fase 3 (Cutover): promosi traffic 100% hanya setelah pergeseran traffic bertahap di setidaknya tiga kenaikan memenuhi kriteria penerimaan. Kemampuan rollback tetap aktif selama 30 hari setelah cutover.
Apa yang memicu migrasi pola daripada pemeliharaan berkelanjutan?
Lima skenario memicu migrasi: penghentian model oleh vendor (pemicu paling jelas, dengan penyedia AI menerbitkan timeline penghentian), degradasi akurasi yang signifikan di mana akar penyebabnya adalah kemampuan model daripada kualitas data, kemampuan arsitektur baru yang secara substansial mengungguli pendekatan yang ada (hybrid RAG versus pencarian vektor naive menunjukkan peningkatan kualitas retrieval 20-40%), perubahan biaya yang menguntungkan pendekatan baru, dan perubahan hubungan vendor termasuk akuisisi, restrukturisasi harga, dan penutupan.
Pola AI mana yang membawa risiko migrasi tertinggi?
Scoring dan Routing memiliki risiko migrasi tinggi karena model baru menghasilkan distribusi skor yang berbeda, memerlukan rekalibrasi ambang routing sebelum traffic produksi apa pun. Autonomous Agent memiliki risiko migrasi tinggi karena setiap API tool dalam repertoar agent perlu verifikasi kompatibilitas, dan versi agent baru mungkin memanggil API yang sama dengan parsing yang berbeda, menghasilkan perilaku Execute yang tidak terduga. Personalization Engine memiliki risiko migrasi tinggi karena representasi profil pengguna dari sistem lama mungkin tidak ditransfer ke arsitektur baru.
Berapa lama shadow mode harus berjalan sebelum cutover?
Minimum 14 hari untuk migrasi model-in-place. Minimum 30 hari untuk migrasi arsitektur. Ukuran sampel yang diperlukan bergantung pada ambang deteksi: untuk mendeteksi perbedaan kualitas 5% dengan kekuatan statistik 90% memerlukan 500-700 pasang yang sebanding. Dengan 1.000 query per bulan, 30 hari menghasilkan data yang bermakna secara statistik. Dengan 10.000 query per bulan, 3 hari cukup untuk persyaratan statistik tetapi 14 hari masih merupakan minimum untuk menangkap edge case dan behavioral drift.
Mengapa perubahan model embedding memerlukan re-indexing penuh?
Model embedding yang berbeda menghasilkan representasi vektor yang berbeda untuk dokumen yang sama. Vektor dari satu model embedding tidak dapat dibandingkan dengan vektor dari model yang berbeda dalam indeks yang sama. Mengubah model embedding memerlukan re-embedding setiap dokumen dalam knowledge base sebelum model baru dapat digunakan dalam produksi. Untuk knowledge base 500.000 dokumen, re-indexing penuh adalah peristiwa komputasi yang signifikan yang harus direncanakan sebagai langkah migrasi eksplisit, bukan ditemukan di tengah migrasi.
Apa kesalahan re-onboarding pengguna yang paling umum setelah migrasi AI?
Melewatinya sepenuhnya. Ketika perilaku AI berubah bahkan menjadi lebih baik, pengguna yang telah membangun alur kerja di sekitar perilaku lama perlu memahami apa yang berubah. Tim yang melewatkan re-onboarding melihat penurunan adopsi 2-4 minggu setelah migrasi karena pengguna menghadapi perilaku yang tidak terduga dan secara diam-diam berhenti berinteraksi. Re-onboarding tidak memerlukan program pelatihan. Ini memerlukan catatan perubahan yang menjelaskan apa yang berubah, saluran umpan balik, dan perbandingan yang terlihat dari output lama versus baru pada query nyata.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Apa yang memicu migrasi pola
- Tiga jenis migrasi dengan profil risiko yang berbeda
- Bagaimana risiko migrasi bervariasi per pola
- Framework migrasi
- Periode shadow mode secara detail
- Shadow-Parallel-Cutover Sequence
- Re-onboarding pengguna setelah migrasi
- Pertimbangan utama migrasi per pola
- Kapan bermigrasi vs. terus memelihara
- Pelajari lebih lanjut