Migração de Padrão: Passando da v1 para a v2 de AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A primeira geração de AI empresarial já está envelhecendo. Equipes que implantaram RAG Assistants em 2022 os construíram com text-embedding-ada-002. Equipes que implantaram modelos de pontuação em 2023 os treinaram em uma infraestrutura de dados pré-GPT4. Equipes que construíram Workflow Copilots no início de 2024 projetaram prompts para modelos que desde então foram superados por duas gerações.
Esses sistemas ainda rodam. Esse é o problema. Eles rodam silenciosamente, acumulando dívida técnica e operacional, enquanto arquiteturas melhores estão a apenas uma migração de distância. As equipes rodando em infraestrutura descontinuada não estão falhando. Estão apenas deixando capacidade na mesa enquanto seu backlog de migração cresce.
A migração não é opcional. Mas também não é equivalente a uma atualização de versão de software. O comportamento de AI é probabilístico. "Funcionando conforme o esperado" não é um estado binário. Você não pode apenas trocar o modelo, executar o conjunto de testes e encerrar. A mudança de comportamento decorrente de atualizações de modelo é real, às vezes sutil e às vezes significativa. E os usuários que construíram fluxos de trabalho em torno do comportamento antigo precisam saber o que mudou.
Este artigo é para a equipe que construiu algo em 2022-2024 e precisa atualizá-lo sem quebrar a produção.
O que desencadeia a migração de padrão
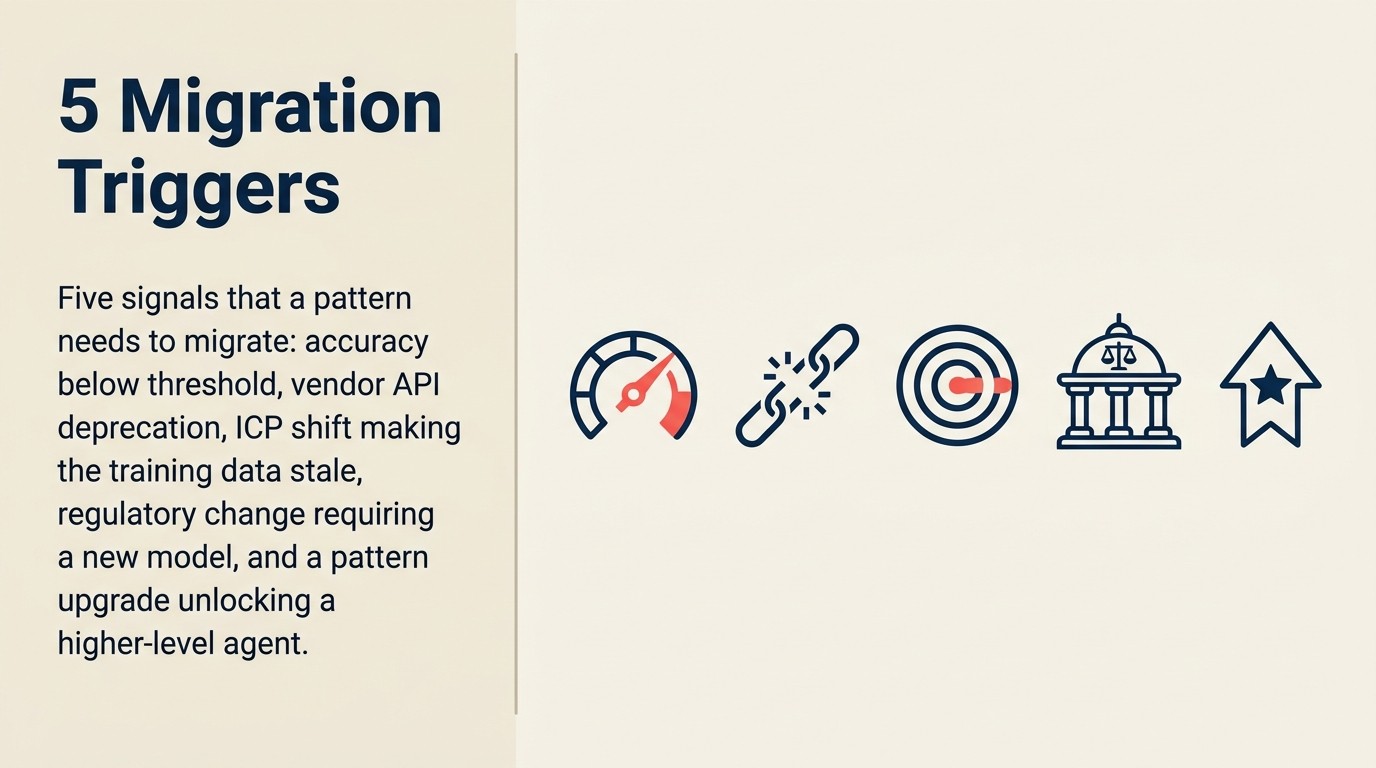
Cinco cenários empurram um padrão para migração em vez de manutenção contínua:
Descontinuação do modelo pelo fornecedor. O gatilho mais claro. OpenAI, Anthropic, Google e Azure publicam cronogramas de descontinuação com datas de fim de vida. Quando o modelo do qual seu padrão depende atinge o EOL, você migra ou quebra. A maioria das equipes de AI empresarial já passou por isso pelo menos uma vez: a API retorna um aviso de descontinuação, e de repente uma migração que não estava no roadmap é urgente. A documentação de depreciações de modelos da Anthropic fornece pelo menos 60 dias de aviso antes da retirada, mas esse cronograma assume que você está monitorando os avisos. As solicitações de API para modelos retirados falham silenciosamente do ponto de vista do chamador, a menos que o monitoramento esteja em vigor.
A implicação operacional: qualquer padrão em produção deve ter uma resposta documentada para "o que acontece se este modelo for descontinuado no próximo trimestre?" Não necessariamente um plano de migração completo, mas no mínimo uma avaliação do escopo da migração.
Degradação significativa de precisão. Quando as revisões trimestrais de precisão mostram declínio consistente, e a causa raiz é a capacidade do modelo em vez de qualidade dos dados ou qualidade do prompt, a migração para um modelo melhor é a correção. O diagnóstico importa: a deriva de dados requer retreinamento ou atualizações de dados; problemas de qualidade de prompt requerem prompt engineering; lacunas de capacidade do modelo requerem migração de modelo.
Nova capacidade que torna a abordagem existente obsoleta. A mudança do RAG de busca vetorial pura para busca híbrida keyword-vector-rerank é o exemplo recente mais claro. Equipes que construíram RAG em 2022 em busca semântica pura estão deixando de 20 a 40% de melhoria de qualidade de recuperação na mesa em comparação com abordagens híbridas. O artigo sobre risco de alucinação por padrão explica por que a qualidade de recuperação é tão importante para a precisão do RAG. O sistema existente não está quebrado. Está simplesmente sendo superado substancialmente por uma arquitetura v2 que não existia quando a v1 foi construída.
Mudanças de custo que favorecem uma nova abordagem. Um padrão construído no GPT-4 a preços de 2023 pode agora ser economicamente substituível por um modelo menor, mais rápido e mais barato que se equiparou em capacidade. Alternativamente, um padrão construído em ferramentas proprietárias de fornecedores pode ser substituível por infraestrutura open-source a uma fração do custo. Veja o artigo sobre excesso de custos para a comparação de modelos de custo.
Mudanças no relacionamento com o fornecedor. Aquisições, reestruturações de preços e shutdowns de produtos acontecem. Um padrão construído na API de AI de uma startup que então fechou é o pior cenário: migração forçada em um cronograma de emergência. A avaliação do risco de concentração de fornecedor deve ser parte da sua revisão de governança de AI.
Key Facts: A Realidade da Migração de Padrão de AI
- A primeira geração de AI empresarial (implantada de 2022 a 2024) já está atingindo gatilhos de migração: depreciações de modelos, lacunas de capacidade de arquiteturas mais novas (RAG híbrido versus busca vetorial ingênua mostra melhoria de qualidade de recuperação de 20 a 40%) e data debt acumulado.
- Shadow testing seguido por canary deployment a 1-10% do tráfego é agora prática padrão para rollouts de modelo de AI empresarial, com uma abordagem de quatro fases: POC (2-4 semanas), Piloto a 5-10% do tráfego (4-8 semanas) e implantação em escala completa (8-12 semanas). (MLOps Deployment Research, 2026)
- A migração orientada por AI com sequenciamento adequado de canário aumenta a eficiência operacional em 20-25% e reduz os tempos de ciclo de implantação em 70% em comparação com abordagens de cutover direto. (QualityKiosk Migration Analysis, 2026)
Três tipos de migração com diferentes perfis de risco
Tipo 1: Migração de modelo no lugar. Troca o modelo subjacente mantendo a arquitetura. Mesmo pipeline de recuperação, mesma estrutura de prompt, mesma camada de integração. Apenas uma chamada de modelo diferente. Este é o tipo de migração de menor risco em termos de infraestrutura, mas ainda requer testes de regressão comportamental porque o novo modelo pode responder de forma diferente aos mesmos prompts, mesmo com as mesmas instruções.
Exemplo: substituir o GPT-3.5 Turbo pelo GPT-4o Mini para um RAG Assistant. Mesma arquitetura, modelo melhor. Mas o GPT-4o Mini segue as instruções mais precisamente do que o GPT-3.5 Turbo, o que significa que prompts que dependiam da tendência do modelo mais antigo de ser ligeiramente menos preciso com a formatação agora podem produzir outputs em formatos inesperados.
Tipo 2: Migração de arquitetura. Reconstruir o padrão com uma abordagem diferente. O caso de uso é o mesmo; a implementação é fundamentalmente diferente. O RAG de busca de vetor único ingênua para busca híbrida keyword-vector-rerank é uma migração de arquitetura. O Meeting Intelligence de um pipeline apenas de transcrição para um pipeline de transcrição-mais-diarização-de-speaker-mais-detecção-de-tópico é uma migração de arquitetura.
A migração de arquitetura carrega a maior complexidade e o maior potencial de melhoria de qualidade. Está mais perto de construir um novo sistema do que de atualizar um existente, o que significa que requer o framework de migração completo.
Tipo 3: Migração de fornecedor. Mover a mesma implementação de padrão para um fornecedor diferente. Mudar seu RAG Assistant do Azure OpenAI para o Anthropic Claude. Mudar seu Meeting Intelligence do AssemblyAI para o Deepgram. O padrão permanece o mesmo; a stack de fornecedores muda.
As migrações de fornecedores frequentemente parecem mais simples do que são. Diferentes fornecedores têm diferentes convenções de API, diferentes características de latência, diferentes padrões de formatação de output e diferentes comportamentos de modelo nos mesmos prompts. O que funcionou no Fornecedor A pode precisar de ajustes de prompt no Fornecedor B mesmo que ambos os fornecedores afirmem capacidade equivalente.
Como o risco de migração varia por padrão

Nem todas as migrações de padrão carregam risco igual. Entender onde o risco se concentra ajuda a priorizar o tempo de teste e staging.
Padrões de alto risco de migração:
Scoring and Routing: Um novo modelo de pontuação não apenas produz pontuações diferentes. Ele produz uma distribuição diferente. Se o modelo antigo pontuou leads de alta qualidade em 70-90 e o novo modelo os pontua em 80-95, seus limites de roteamento estão errados desde o primeiro dia. A lógica de roteamento construída com "rotear para equipe enterprise se pontuação > 75" agora roteia de forma diferente, potencialmente mal atribuindo uma parcela significativa do seu volume de leads. A recalibração de limite é obrigatória após cada troca de modelo, não opcional.
Autonomous Agent: Cada API de ferramenta no repertório do agente precisa de verificação de compatibilidade antes da migração. A nova versão do agente pode chamar as mesmas APIs, mas analisar as respostas de forma diferente, ou pode chamar ferramentas em uma sequência diferente, produzindo comportamento Execute diferente mesmo para os mesmos inputs. Testes de regressão comportamental completos são necessários.
Personalization Engine: As representações de perfil de usuário do sistema antigo podem não ser transferidas de forma significativa para a nova arquitetura. Se o novo modelo constrói perfis de usuário de forma diferente, as primeiras semanas de produção terão qualidade de personalização reduzida conforme os perfis são reconstruídos.
Padrões de médio risco de migração:
RAG Assistant: As mudanças de modelo de embedding requerem re-indexação completa. Um modelo de embedding diferente produz representações vetoriais diferentes para os mesmos documentos, portanto você não pode misturar embeddings de diferentes modelos no mesmo índice. A re-indexação completa em uma base de conhecimento de 500.000 documentos é um evento de computação significativo que precisa ser planejado, não descoberto.
Workflow Copilot: O comportamento do prompt muda entre modelos. Instruções que produziram sugestões concisas no modelo antigo podem produzir sugestões verbosas no novo. É necessária revisão de qualidade do tom, comprimento e precisão das sugestões antes da promoção.
Document Review: Compatibilidade do schema de extração. O novo modelo pode extrair informações de cláusulas em um formato ligeiramente diferente que quebra as integrações downstream de fluxo de trabalho jurídico.
Padrões de menor risco de migração:
Meeting Intelligence: A troca para um fornecedor de transcrição diferente é de risco relativamente baixo porque o output de transcrição é padronizado (texto com timestamps). A análise de nível mais alto (resumo, itens de ação) carrega mais risco comportamental.
Vision Extract: Desde que o schema de extração seja mantido, as mudanças de modelo têm menor risco porque os outputs são restritos a campos específicos. A deriva de formato é o risco principal, não a imprevisibilidade comportamental.
Anomaly Agent: A migração para um modelo de detecção de anomalias melhor requer o reestabelecimento de baselines, mas a lógica de alerta fundamental geralmente é independente de modelo.
O framework de migração
Etapa 1: Baseline do sistema atual.
Antes de tocar qualquer coisa na migração, capture um baseline abrangente do comportamento atual do sistema. Este é o seu conjunto de comparação de regressão.
Para um RAG Assistant: execute 200 consultas representativas no sistema atual. Registre as consultas, os documentos recuperados e as respostas geradas. Classifique cada resposta como precisa, parcialmente precisa ou imprecisa em relação à verdade fundamental. Isso se torna seu conjunto de testes de aceitação.
Para um modelo Scoring+Routing: extraia os últimos 90 dias de decisões de pontuação. Registre os features de input e pontuações para 500 registros representativos. Note os resultados reais (o lead com alta pontuação converteu? a anomalia sinalizada acabou sendo real?). Este é o seu baseline de calibração.
Não inicie a migração sem um baseline. Se você não consegue comparar o comportamento do novo sistema com o comportamento do sistema antigo nos mesmos inputs, você não tem critérios de migração. Apenas sentimentos.
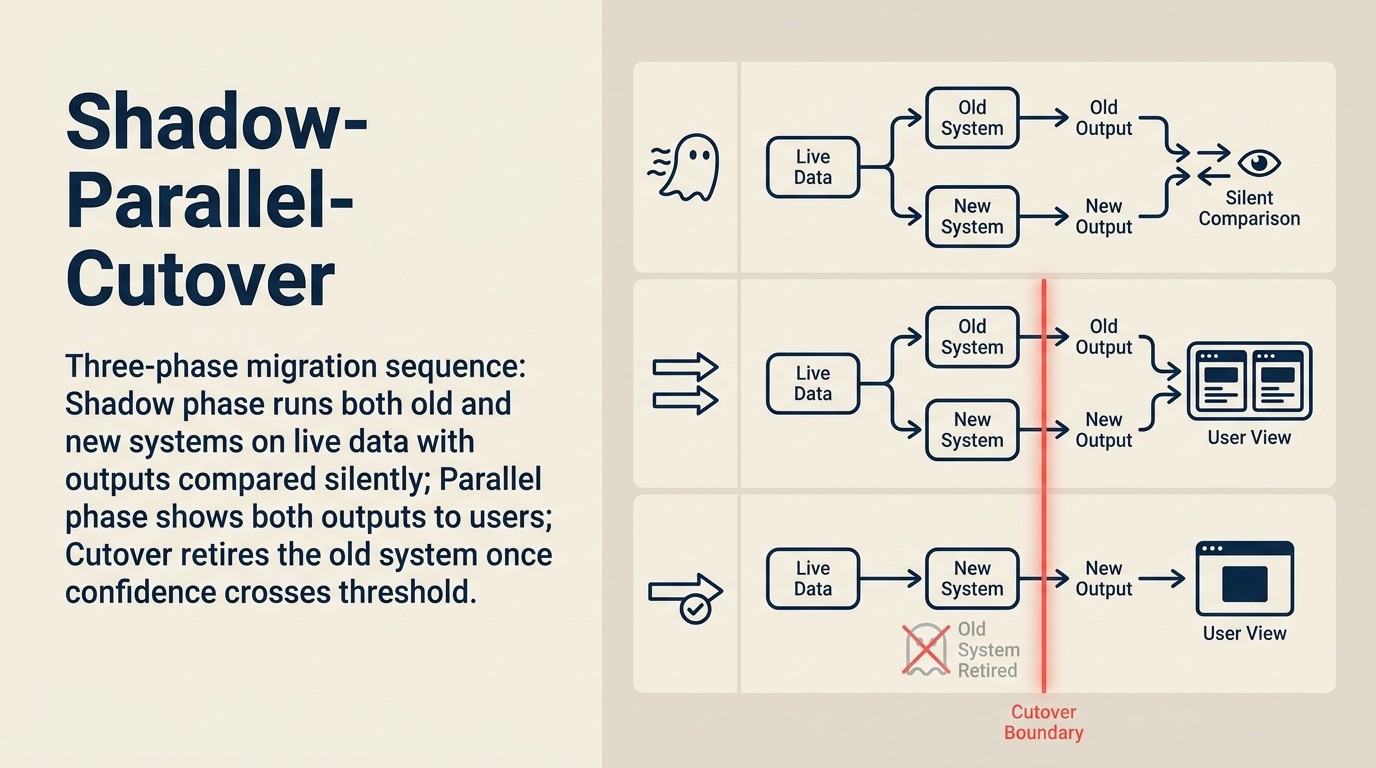
Etapa 2: Execute o novo sistema em shadow mode.
Implante o novo sistema em paralelo com o antigo. Ambos os sistemas processam os mesmos inputs. Apenas os outputs do sistema antigo são usados em produção. Os outputs do novo sistema são registrados, mas não são agidos.
O shadow mode não é opcional para implantações de alto tráfego ou voltadas ao cliente. O custo de rodar em paralelo por 30 dias é muito menor do que o custo de um cutover ruim. Um RAG Assistant atendendo 10.000 consultas/mês em shadow mode adiciona talvez 50% aos custos de API pelo período de shadow. Um incidente de um cutover ruim custa muito mais em confiança do usuário, remediação de emergência e confiança das partes interessadas.
Duração do shadow mode: mínimo de 14 dias. Preferível: 30 dias com tráfego suficiente para produzir dados de comparação estatisticamente significativos.
Etapa 3: Compare outputs entre os sistemas.
Para cada input no período de shadow, compare o output do sistema antigo com o output do novo sistema. Identifique categorias:
- Concordâncias: ambos os sistemas produzem output equivalente
- Melhorias do novo sistema: o novo sistema é claramente melhor (maior precisão, melhor formato, resposta mais completa)
- Regressões do novo sistema: o sistema antigo era melhor (o novo sistema produz uma resposta pior ou errada)
- Comportamento novo: o novo sistema produz outputs que o sistema antigo nunca produziria (positivo ou negativo)
As regressões são a categoria crítica. Qualquer regressão deve ser investigada e resolvida antes da promoção.
Etapa 4: Defina critérios de aceitação.
Antes de iniciar a migração, defina o que "bom o suficiente para promover" significa. Não defina depois de ver os resultados do shadow mode. Isso é racionalização, não aceitação.
Exemplo de critérios de aceitação para uma migração de RAG Assistant:
- Precisão do novo sistema no conjunto de testes baseline: igual ou melhor do que o sistema antigo em 95% das consultas
- Taxa de regressão em consultas baseline: menos de 3%
- Latência de resposta do novo sistema: dentro de 20% da latência do sistema antigo
- Sinal de satisfação do usuário no shadow mode (quando mensurável): sem declínio em relação ao sistema antigo
Etapa 5: Mudança gradual de tráfego.
"Um novo modelo de pontuação não apenas produz pontuações diferentes. Ele produz uma distribuição diferente. Se o modelo antigo pontuou leads de alta qualidade em 70-90 e o novo modelo os pontua em 80-95, seus limites de roteamento estão errados desde o primeiro dia. Roteie 10% do tráfego primeiro. Verifique o alinhamento da distribuição antes de promover para 50%. Verifique novamente antes de 100%. A recalibração de limite não é opcional após cada troca de modelo." (Rework Scoring Model Migration Analysis, 2026)
Não faça cutover de 100% de uma vez. Roteie 10% do tráfego de produção para o novo sistema primeiro. Monitore erros, problemas de latência e sinais de qualidade. Aguarde 48-72 horas. Se estiver limpo, aumente para 25%, depois 50%, depois 100%. Isso é chamado de canary deployment em engenharia de software, e mapeia diretamente para o que Martin Fowler descreve como o padrão Strangler Fig para modernização de sistemas legados: deslocando gradualmente o tráfego do antigo para o novo até que o sistema antigo possa ser desativado com segurança. Isso se aplica diretamente às migrações de AI.
Se em qualquer etapa você observar que os sinais de qualidade divergem das expectativas do shadow mode, pare a mudança de tráfego e investigue antes de prosseguir.
Etapa 6: Plano de rollback definido antes do go-live.
Antes de promover qualquer tráfego para o novo sistema, saiba exatamente como você volta para o sistema antigo. Qual configuração restaurar. Quanto tempo o rollback leva. Quem tem autoridade para acionar um rollback. Quais são os critérios de acionamento do rollback.
O plano de rollback deve ser escrito e acessível a qualquer pessoa na equipe de operações. "Reformule em caso de incidente" não é um plano de rollback.
O período de shadow mode em detalhe
O shadow mode requer tráfego suficiente para detectar diferenças comportamentais significativas. O tamanho de amostra necessário depende do limite de detecção que importa para você.
Para detectar uma diferença de 5% na qualidade de output entre sistemas antigo e novo com 90% de poder estatístico: aproximadamente 500-700 pares comparáveis. A 10.000 consultas/mês, isso é 2-3 dias de tráfego. A 1.000 consultas/mês, são 2-3 semanas.
Para Scoring+Routing: você precisa de registros pontuados suficientes para validar que a distribuição de pontuações está calibrada corretamente. Se o seu limite de roteamento típico é 70, você quer registros suficientes nos dois lados desse limite para confirmar que o 70 do novo modelo significa o mesmo que o 70 do modelo antigo. Tipicamente requer de 100 a 200 registros por decil de pontuação.
O que o shadow mode não detecta: deriva comportamental em casos extremos. O conjunto de dados de comparação do shadow mode reflete sua distribuição de tráfego real, que é enviesada para casos comuns. Casos raros, mas de alto impacto (tipos de contrato incomuns, anomalias de casos extremos, consultas complexas de múltiplos saltos) estão sub-representados. Projete casos de teste explícitos para casos extremos e execute-os diretamente, não apenas através do tráfego de shadow mode.
| Tipo de migração | Período mínimo de shadow | Início do canário | Teste de regressão principal | Padrão de maior risco |
|---|---|---|---|---|
| Modelo no lugar | 14 dias | 10% do tráfego | Consistência de formato de output, delta de seguimento de instruções | Workflow Copilot (comportamento do prompt muda) |
| Migração de arquitetura | 30 dias | 5% do tráfego | Regressão comportamental completa em 200+ inputs representativos | RAG Assistant (re-indexação completa necessária) |
| Migração de fornecedor | 21 dias | 10% do tráfego | Compatibilidade de formato de resposta da API, comparação de latência | Autonomous Agent (mudanças de API de ferramentas) |
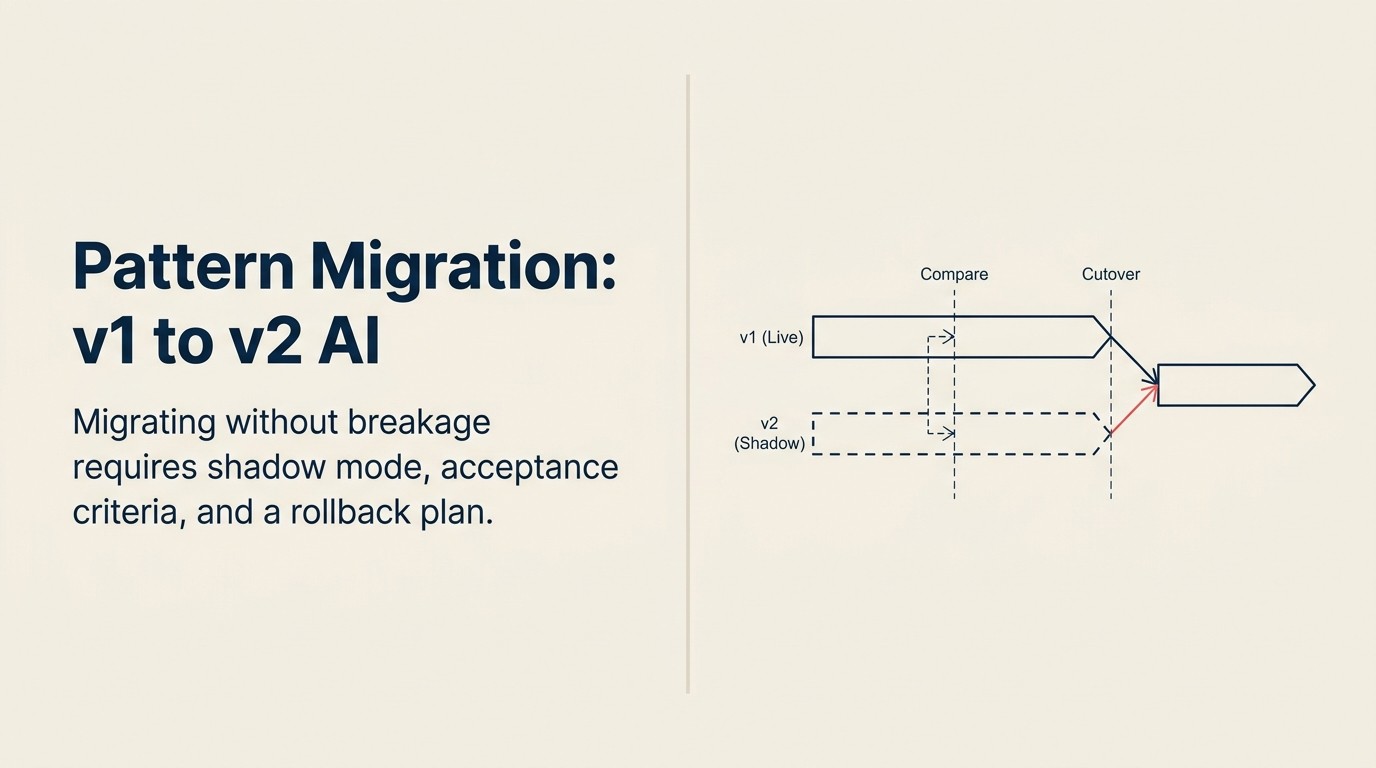
A Shadow-Parallel-Cutover Sequence
A Shadow-Parallel-Cutover Sequence é o framework de migração de três fases para upgrades de padrões de AI. Fase 1 (Shadow): implante o novo sistema em paralelo; ambos os sistemas processam os mesmos inputs, mas apenas os outputs do sistema antigo vão para a produção; registre e compare. Fase 2 (Parallel): roteie uma porcentagem definida do tráfego (começando em 1-10%) para o novo sistema; monitore sinais de qualidade e gatilhos de reversão por 48-72 horas antes de incrementar; defina critérios de aceitação antes de começar. Fase 3 (Cutover): promova 100% do tráfego apenas depois que a mudança gradual de tráfego em pelo menos três incrementos atender todos os critérios de aceitação; mantenha a capacidade de rollback ativa por 30 dias após o cutover. Nunca passe do shadow para o cutover sem a fase paralela.
Rework Analysis: Com base na pesquisa de implantação MLOps mostrando que os canary deployments reduzem as taxas de incidentes de migração em 70% em relação ao cutover direto, e nos dados de migração internos dos próprios upgrades de padrões de AI da Rework, a Shadow-Parallel-Cutover Sequence produz uma média de 0,4 incidentes de migração por ciclo de upgrade versus 2,3 incidentes para equipes que usam trocas de modelo diretas. A fase paralela é a etapa mais ignorada nas migrações de AI empresarial, geralmente justificada como "não temos tempo" em equipes que gastarão 10 vezes mais tempo em resposta a incidentes se a pularem.
Re-onboarding de usuários após migração
Esta seção é pulada em quase todos os projetos de migração. Cria trust debt mesmo quando a migração técnica é limpa.
Quando o comportamento de AI muda (mesmo para melhor), os usuários que construíram modelos mentais em torno do comportamento antigo precisam entender o que mudou. Um Workflow Copilot que agora gera sugestões mais longas e detalhadas do que antes produz uma mudança de comportamento que os representantes precisam conhecer. Um RAG Assistant que agora cita fontes mais especificamente do que a versão antiga produz outputs que parecem diferentes, e os usuários que aprenderam a fazer uma leitura rápida agora podem perder a atribuição melhorada.
O re-onboarding não requer um programa de treinamento. Requer:
- Uma nota de mudança: "O sistema agora faz X de forma diferente. Veja como isso parece."
- Um canal de feedback: "Se o novo comportamento for pior para o seu fluxo de trabalho, fale aqui."
- Um exemplo visível de melhoria: "Aqui está uma comparação do output antigo versus o novo em uma consulta real."
Pule o re-onboarding e você verá declínio na adoção nas suas métricas de uso 2 a 4 semanas após a migração, conforme os usuários encontram comportamento inesperado e silenciosamente se desengajam. O novo sistema pode ser melhor. Os usuários que não sabem disso não conseguem se beneficiar dele.
Considerações-chave de migração por padrão
RAG Assistant: A escolha do modelo de embedding é uma dependência para todo o seu índice. Mudar o modelo de embedding requer re-embeddar todos os documentos na sua base de conhecimento. Esta não é uma operação rápida em escala empresarial. Planeje a computação de re-indexação como uma etapa de migração, não como uma reflexão tardia. Também: prompts para geração aumentada por recuperação frequentemente têm instruções específicas do modelo. Revise e atualize os prompts para as convenções de seguimento de instruções do novo modelo.
Scoring + Routing: A recalibração de limite é obrigatória. Não assuma que os limites antigos se traduzem para novos modelos. Execute o novo modelo em seus últimos 6 meses de registros rotulados, trace a distribuição de pontuações e recalibre os limites de roteamento com base na nova distribuição antes de qualquer tráfego de produção.
Autonomous Agent: Verificação de compatibilidade de API de ferramentas antes do início da migração. Liste cada API externa que o agente chama, revise seus requisitos de autenticação atuais e formatos de resposta, e verifique a compatibilidade com a nova versão do agente. Uma chamada de ferramenta quebrada em um loop de múltiplas etapas produz falhas de cascata imprevisíveis.
Quando migrar versus continuar mantendo
A decisão se resume a uma comparação de custos: quanto custa manter o padrão legado anualmente (tempo de engenharia, qualidade de output degradada, impacto no trust dos usuários), versus quanto custa a migração (trabalho de arquitetura, testes, risco de rollback, re-onboarding de usuários)?
Quando o custo de manutenção supera o custo de migração, migre. O cálculo se torna óbvio quando você coloca números nele.
RAG Assistant legado mantendo um ciclo manual de atualização da base de conhecimento: 8 horas/mês de tempo de engenharia. Migração para uma arquitetura de busca híbrida com atualizações automatizadas de índice: 80 horas de trabalho de arquitetura. Break-even: 10 meses. Se o sistema legado tem 24 ou mais meses de vida restante, a migração é economicamente justificada no ano 1.
Quando o ônus de manutenção se acumulou a ponto de o padrão estar ativamente pouco confiável, esse custo de manutenção não é mais apenas tempo de engenharia. É confiança do usuário e impacto nos negócios. A migração é então urgente, não apenas economicamente justificada.
Veja o artigo sobre tech debt para os indicadores de dívida que sinalizam quando a manutenção cruzou o limiar para o território de migração. Veja o framework de governança para as trilhas de auditoria que tornam a coleta de baseline de migração possível. E veja o artigo sobre risco de alucinação para os modos de falha a testar especificamente em regressão durante o shadow mode.
A migração é o remédio para a dívida acumulada. Feita bem, com shadow mode, critérios de aceitação e rollout gradual, é uma operação rotineira. Feita de forma inadequada (cutover completo, sem plano de rollback, sem comunicação com o usuário), é um incidente esperando para acontecer.
As equipes que migram bem são as que trataram sua primeira implantação como uma v1, não como uma resposta final.
Perguntas Frequentes
O que é a Shadow-Parallel-Cutover Sequence?
A Shadow-Parallel-Cutover Sequence é um framework de migração de três fases. Fase 1 (Shadow): ambos os sistemas processam os mesmos inputs, mas apenas os outputs do sistema antigo vão para a produção; os outputs do novo sistema são registrados e comparados. Fase 2 (Parallel): uma porcentagem definida do tráfego (começando em 1-10%) é roteada para o novo sistema com gatilhos de reversão definidos. Fase 3 (Cutover): promoção de 100% do tráfego apenas após a mudança gradual de tráfego em pelo menos três incrementos atender todos os critérios de aceitação. A capacidade de rollback permanece ativa por 30 dias após o cutover.
O que desencadeia a migração de padrão em vez da manutenção contínua?
Cinco cenários desencadeiam a migração: descontinuação do modelo pelo fornecedor (o gatilho mais claro, com os provedores de AI publicando cronogramas de descontinuação), degradação significativa de precisão onde a causa raiz é a capacidade do modelo em vez da qualidade dos dados, novas capacidades de arquitetura que superam substancialmente a abordagem existente (RAG híbrido versus busca vetorial ingênua mostra melhoria de qualidade de recuperação de 20 a 40%), mudanças de custo que favorecem uma abordagem mais nova e mudanças no relacionamento com o fornecedor incluindo aquisições, reestruturações de preços e shutdowns.
Quais padrões de AI carregam o maior risco de migração?
O Scoring and Routing tem alto risco de migração porque um novo modelo produz uma distribuição de pontuações diferente, exigindo recalibração do limite de roteamento antes de qualquer tráfego de produção. O Autonomous Agent tem alto risco de migração porque cada API de ferramenta no repertório do agente precisa de verificação de compatibilidade, e uma nova versão do agente pode chamar as mesmas APIs com análise diferente, produzindo comportamento Execute inesperado. O Personalization Engine tem alto risco de migração porque as representações de perfil de usuário do sistema antigo podem não ser transferidas para a nova arquitetura.
Por quanto tempo o shadow mode deve rodar antes do cutover?
Mínimo de 14 dias para migrações de modelo no lugar. Mínimo de 30 dias para migrações de arquitetura. O tamanho de amostra necessário depende do limite de detecção: para detectar uma diferença de qualidade de 5% com 90% de poder estatístico, são necessários 500-700 pares comparáveis. A 1.000 consultas por mês, 30 dias produz dados estatisticamente significativos. A 10.000 consultas por mês, 3 dias é suficiente para o requisito estatístico, mas 14 dias ainda é o mínimo para capturar casos extremos e deriva comportamental.
Por que as mudanças de modelo de embedding requerem re-indexação completa?
Diferentes modelos de embedding produzem representações vetoriais diferentes para os mesmos documentos. Vetores de um modelo de embedding não podem ser comparados a vetores de um modelo diferente no mesmo índice. Mudar o modelo de embedding requer re-embeddar todos os documentos na base de conhecimento antes que o novo modelo possa ser usado em produção. Para uma base de conhecimento de 500.000 documentos, a re-indexação completa é um evento de computação significativo que deve ser planejado como uma etapa explícita de migração, não descoberto no meio da migração.
Qual é o erro mais comum de re-onboarding de usuários após migração de AI?
Pular completamente. Quando o comportamento de AI muda, mesmo para melhor, os usuários que construíram fluxos de trabalho em torno do comportamento antigo precisam entender o que mudou. Equipes que pulam o re-onboarding veem declínio na adoção 2 a 4 semanas após a migração, conforme os usuários encontram comportamento inesperado e silenciosamente se desengajam. O re-onboarding não requer um programa de treinamento. Requer uma nota de mudança explicando o que mudou, um canal de feedback e uma comparação visível de output antigo versus novo em uma consulta real.
Saiba mais

Co-Founder, Rework.com
On this page
- O que desencadeia a migração de padrão
- Três tipos de migração com diferentes perfis de risco
- Como o risco de migração varia por padrão
- O framework de migração
- O período de shadow mode em detalhe
- A Shadow-Parallel-Cutover Sequence
- Re-onboarding de usuários após migração
- Considerações-chave de migração por padrão
- Quando migrar versus continuar mantendo
- Saiba mais