ルールベースモデルを超えたAI Lead Scoring

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
現在デプロイされているほとんどの「Lead Scoring」は、Intelligenceのふりをした手動の重み付けです。
ロジックはこういうものです。フォーム送信は10点、VP肩書きは20点追加、200名以上の企業は15点追加、Pricingページ訪問は25点追加。合計して70以上はすべて「Hot Lead」。営業チームはHot Leadを優先的に取り組む。
問題は声に出すと明らかです。その重みを人間が決めたのです。おそらく営業チームの直感といくつかの逸話に基づいて判断を下し、静的なルールとしてエンコードしました。重みは市場が変化しても更新されません。Series Bを調達してICP(Ideal Customer Profile)が変わっても再調整されません。そしてシグナル間のInteractionを捉えることは確実にできません。
午前2時の土曜に50名規模企業からのVP肩書きと、火曜午前10時の300名規模企業からの同じ肩書きでは、Conversion Rateがまったく異なります。
機械学習(ML)のLead Scoringは、人間の代わりにデータが重みを選択します。それが概念的な違いのすべてです。ただしうまく実行するには、モデルがどのように機能するか、どのデータが必要か、デプロイがどこで失敗するかを理解する必要があります。これはAI Sales Operatorアーキテクチャのパターン1であり、他のすべてが構築される基盤です。
ルールベースScoringが見落とすもの
ルールはカテゴリ的です。MLモデルは確率的です。McKinseyのB2B営業におけるAIに関する調査は、Lead資格確認を営業チームにとって最も影響の大きいAI活用事例の一つとして特定しています。改善が複利で作用するからです。より良いScoringはRepがより良いLeadに取り組み、よりCloseし、次のモデル反復のためのより良いトレーニングデータを生成します。この区別はルールベースアプローチにおける系統的な盲点を生み出します。
フィールドのSparsity。 ほとんどのLeadフォームは4〜6フィールドをキャプチャします。ほとんどのCRMレコードには潜在的に関連するフィールドが数十あり、その多くは空です。ルールは空フィールドを中立として扱います。MLモデルは、特定の会社規模バンドでのLinkedIn URLの欠落が低いClose Rateと相関することを学習できます。それが過去のデータが示すことだからです。情報の欠如自体がシグナルです。
タイミングとSequence。 Day 1にPricingページを訪問し同日にDemoフォームを送信したLeadと、フォーム送信の3週間前にPricingページを訪問し、前日に再訪問したLeadでは異なるConversionをします。ルールは「Pricingページ訪問=25点」を検出できますが、Recency CurveやBehavioral Sequenceを捉えません。MLモデルは捉えます。
企業属性変化のシグナル。 VP of Salesを最近採用した企業は、6ヶ月前の同じ企業とは根本的に異なる見込み客です。最近の資金調達は購買力を変えます。新製品ローンチはテクノロジーニーズを生み出します。静的なルールはこれらの動的なシグナルを拾いません。最近の企業属性データ(LinkedIn、Clearbit、6senseなどのソースから)を供給されたMLモデルはそれらを考慮できます。
マルチタッチInteraction。 「VP肩書き + Pricingページ + リファーラルソース = Partnerチャネル」の組み合わせは40%でConversionするかもしれません。各要素単独では10%かもしれません。ルールはそれらを個別にScoringします。MLはInteraction Effectを捉えます。
Key Facts: AI Lead Scoring
- McKinseyはLead資格確認をB2B営業チームにとって最も影響の大きいAI活用事例の一つとして特定しています。より良いScoringが複利で作用するためです。より良いLeadはより多くCloseし、次のモデル反復のためのより良いトレーニングデータを生成します
- 信頼できるML Lead Scoring Modelには最低200件のClosed-Won Dealが必要です。100件未満では、ほとんどの商用ツールがランダムアサインと統計的に区別がつかない出力を生成します
- AI Assisted Lead ScoringはMadKuduと6senseの顧客データ(2022〜2024年)によると、静的ルールベースモデルと比較してLead-to-Opportunity Conversion Rateが10〜20%高いことが報告されています
ML Lead Scoringの仕組み(専門知識なしで理解する)
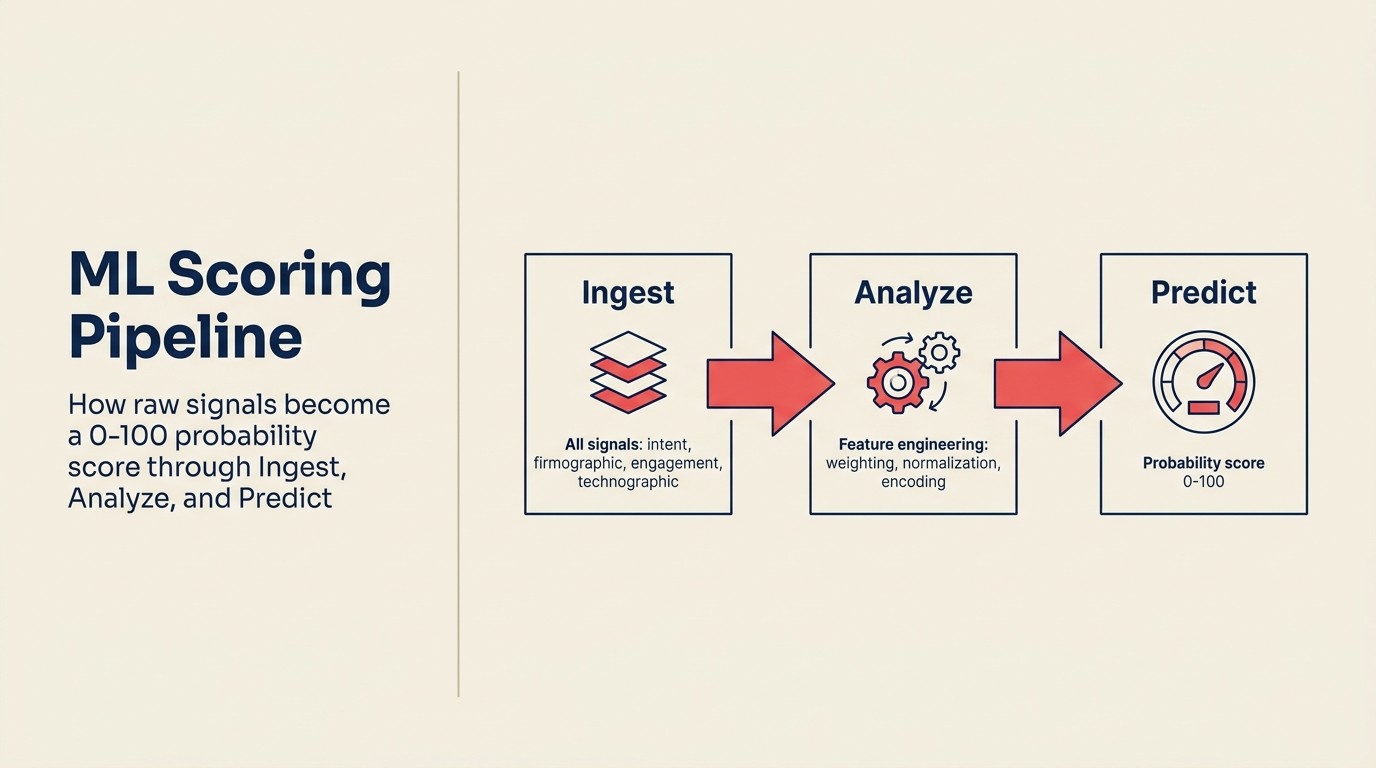
メカニクスはほとんどのベンダーが伝えるよりシンプルです。ACE Framework語彙を使った運用ロジックを示します。
Ingestは各Leadのすべての利用可能なシグナルを取り込みます。CRMフィールド(肩書き、会社規模、業界、ソース)、行動データ(訪問ページ、メール開封、ウェビナー参加)、企業属性エンリッチメント(収益バンド、ヘッドカウント、資金調達ステージ、テックスタック)、時間ベースのデータ(アクティビティがいつ起きたか、その間のギャップ)。
Analyzeはその生データからFeatureを抽出します。FeatureはモデルがActuallyトレーニングする入力変数です。一部は直接的です(肩書き = 「VP」→ バイナリFeature)。一部はEngineeredです(最初の訪問とフォーム送信の間の日数 → 数値Feature)。一部はInteractionタームです(会社規模 × Engagement頻度 → 複合シグナル)。Feature Engineeringがほとんどの作業が行われる場所であり、自社データを理解するOpsチームが汎用のOut-of-BoxモデルよりAdvantageを持つ場所です。
Predictはラベル付きの過去データでモデルをトレーニングします。CloseしたDeal(Won)とCloseしなかったDeal(Lost)、およびすべての上記Featuresです。内部では、ほとんどの商用Lead ScoringツールはLogistic RegressionまたはGradient Boostingを使用します。どちらも0〜1の確率を出力する理解された機械学習手法です。モデルは自社の特定の顧客ベースでどのFeatureの組み合わせがClosed-Won Outcomeと相関するかを学習し、その学習済み重みをすべての新しいLeadに適用します。確率の出力を生成します。このLeadはわかっていることに基づいて73%のConversion Probabilityがある。
それだけです。0〜100の確率値で、自社のWin/Loss履歴に基づいて、新しいDealがCloseするたびに更新されます。RecalibrationループがワーキングモデルとゆっくりDriftするモデルを分けるものです。
Probabilistic Lead Score Standard
Probabilistic Lead Score Standardは、防御可能なAI Lead Scoreに必要なものを定義します。会社自身のWin/Loss履歴に基づいた0〜1の確率出力、少なくとも200件のClosed-Won Outcomeでのトレーニング、新しいDeal Outcomeに対して最低四半期ごとのRecalibration、Feature Attribution(どのシグナルがこのスコアを駆動したか)をRepに公開すること。この4つの基準のいずれか一つでも失敗するScoringシステムは、真のML Scoringよりも強化ルールベースScoringとして分類する方が適切です。出力が測定されたConversionパターンに統計的に基づいていないためです。
ConversionリフトでランクされたSignalタイプ

すべてのシグナルが等しく有用ではありません。MadKuduのリサーチと2022〜2024年に公開された6senseのBuyer Intent Dataに基づいたパターンで、B2B SaaSのLift Contributionのシグナルカテゴリ一般ランキングを示します。
| Signal Type | 例 | Lift Contribution | 備考 |
|---|---|---|---|
| Intentシグナル | Pricingページ訪問、競合比較ページ、G2カテゴリ閲覧 | 非常に高い | Late-Stage購買シグナル。Recencyが重要(過去7日 >> 過去30日) |
| Engagementの新鮮さ | 過去14日間のメール開封、Web訪問、ウェビナー参加 | 高い | Recency Curveが重要。過去30日以降は指数関数的に減衰 |
| 企業属性Fit | 会社規模、業界垂直市場、資金調達ステージ | 高い | 数学的にエンコードされたICP定義 |
| 技術スタックFit | CRMタイプ(Salesforce vs HubSpot)、既知の統合、現在のテックスタック | 中〜高い | 製品が特定ツールを置き換えるまたは補完する場合に最も強いLift |
| ニューストリガー | 最近の資金調達、新規採用発表、製品ローンチ | 中程度 | コールドアウトバウンドへの強いシグナル。インバウンドへの予測力は低い |
| コンタクトレベルFit | 肩書き、シニアリティ、部署 | 中程度 | 会社レベルFitとの組み合わせで最も強い。単独では弱い |
| Leadソース | オーガニック検索、パートナーリファーラル、コンテンツダウンロード | 低〜中程度 | 会社によって大幅に異なる。仮定するのではなく常にテスト |
| フォーム行動 | フォームの時間、入力フィールド数、デバイスタイプ | 低い | Tiebreaker として有用。主要シグナルではない |
製品と市場によって順序は変わります。開発者ツールの場合、技術スタックFitが最も強いシグナルかもしれません。金融サービス製品の場合、企業属性バンドと規制コンテキストが支配するかもしれません。モデルはデータから会社の実際のランキングを学習します。上記の表は開始点のHypothesisです。
デプロイ前のデータ準備チェックリスト
これがほとんどの企業がスキップするステップです。AI Lead Scoringは悪いデータでは良い結果を生みません。MLScoringツールを購入または設定する前に、このチェックリストを確認してください。
最低要件:
- 一貫したWon/LostラベリングによるClosedDealが少なくとも6ヶ月分(12ヶ月推奨)
- Closed-Won Dealが合計最低200件(多ければ多いほど良い。100件未満では信頼性の低いモデルを生成)
- CRM Dealステージがチーム全体で一貫している(「Closed Won」vs「Won」vs「Closed」の変異がない)
- First-Touchソースが70%以上のレコードでキャプチャされている
- 80%以上のレコードで会社名とドメインが入力されている
あれば良い(モデル品質を大幅に改善):
- コンタクトの肩書きとシニアリティが少なくとも60%のLeadでキャプチャされている
- 会社規模(従業員数)が70%以上のレコードでキャプチャまたはエンリッチ可能
- WebサイトBehavioral Data(HubSpot Tracking、Segment、または同等品)がCRMにイベントを送信
- CRMに供給する企業属性エンリッチメントソースが少なくとも1つある(Clearbit、Apollo、ZoomInfo)
Scoringの前にデータ作業が必要であることを示すWarning Signs:
- 結果ラベルなしにCloseしたDealが20%以上
- 同じライフサイクル位置に対して3つ以上の異なるステージ名
- CRM移行後のDeal履歴が6ヶ月未満(移行前データは信頼性が低いことが多い)
- Behavioralトラッキングデータがゼロ(ページ訪問履歴なし、メール開封トラッキングなし)
最低限リストの複数の項目が欠けている場合は、Scoringをデプロイする前に4〜6週間データのCleaningに費やしてください。モデルは与えられたものに基づいて構築されます。
Model OutputからRouting Thresholdへ
モデルはProbabilityを提供します。それをどう扱うかはまだ決める必要があります。
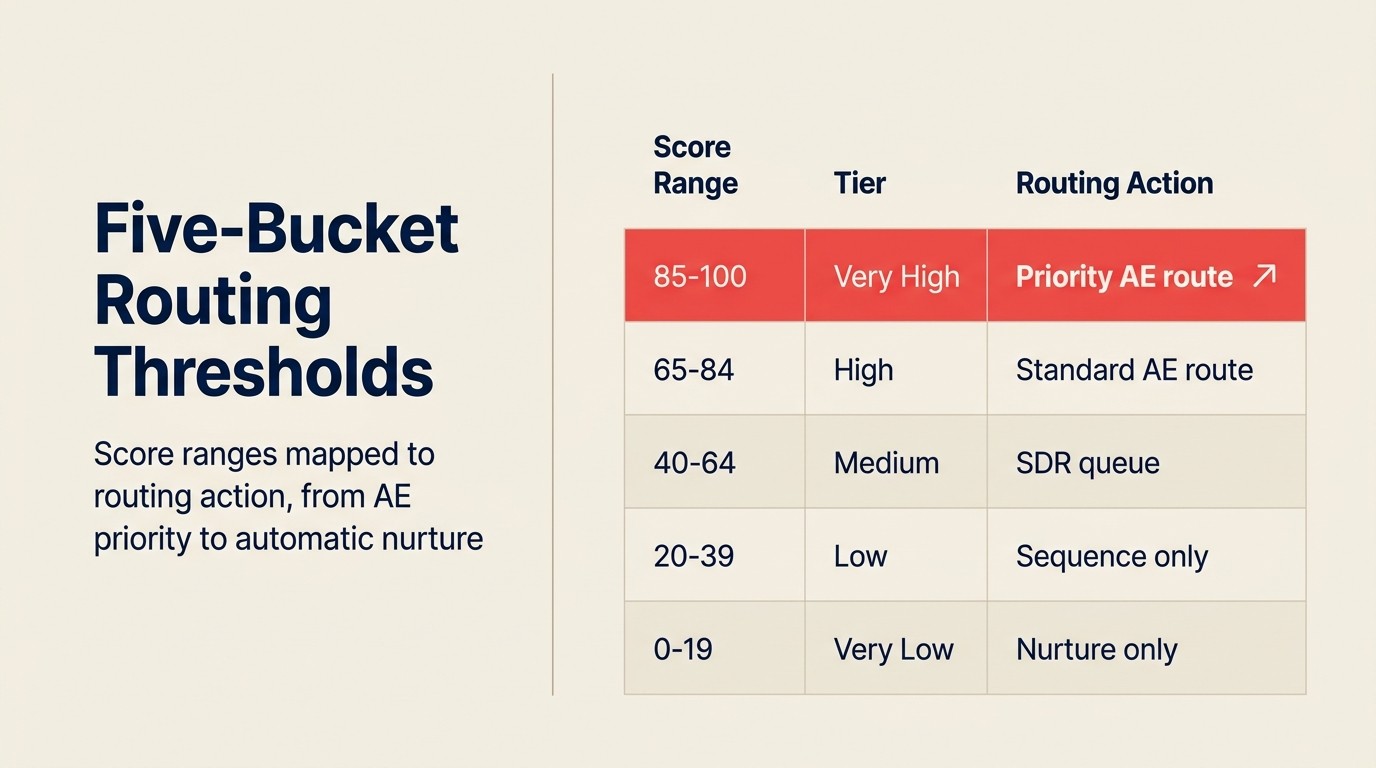
ほとんどのデプロイでは、Routing Logicが付いた3〜5つのBucketを定義します。
| スコア範囲 | ラベル | Routing Action |
|---|---|---|
| 85〜100% | 非常に高い | シニアAEにRouting、即時Slack通知、SDRフィルターなし |
| 65〜84% | 高い | AEキューにRouting、SLA: 2時間以内にコンタクト |
| 40〜64% | 中程度 | SDRに資格確認のためにRouting、Mid-TouchSequenceにEnroll |
| 20〜39% | 低い | Nurtureシーケンスへの自動Enroll、担当者アサインなし |
| 0〜19% | 非常に低い | Actionなし。ニュースレターリストにのみ追加 |
閾値の数値はベンダーではなく自分たちで設定するものです。担当者キャパシティ(担当者が多い = 直接アサインのための低い閾値)、False Positiveをどのくらい許容できるか(スコアが高いが間違っていたLead = 担当者の時間の浪費)、現在のコンタクトSLAコミットメントを反映すべきです。
閾値を正しく設定することはCalibrationの演習であり、一度限りの設定ではありません。初期閾値で60日間動かし、その後比較してください。各Bucketで実際のConversion Rateはどうだったか?「High」BucketがConversion Rate 8%で「Medium」BucketがConversion Rate 12%であれば、閾値のCalibrationが間違っています。調整して再び観察します。そして常にキュー量に注意してください。突然Leadの40%が「High」Bucketに送られる閾値のDriftは、数週間以内に担当者の信頼を破壊します。
よくある失敗パターン
バイアスがかかった過去データでトレーニングされたモデル。 過去のWinが特定のチャネルに偏っている場合(例: Closed Dealの70%がPartnerリファーラルから)、モデルはPartnerソースのLeadを高くScoringするよう学習します。新しいチャネルに展開すると、モデルはそれらのLeadを低くScoringします。悪いLeadだからではなく、そのパターンのトレーニングデータがないためです。修正: より広いデータでRetrain、またはソースでモデルをSegment。
RepのワークフローにScoreが表示されない。 モデルは良い出力を生成しているが、CRMフィールドに存在しているだけで誰もそれを見ていない。RepはLeadを到着順に取り組み続けます。これはモデルの失敗ではなくAdoptionの失敗です。修正: RepのDaily Workflow(Slackの通知、スコアで並び替えられたCRMキュー)でスコアを表示し、Go-Live前にRepにスコアの意味をトレーニング。
Retrainのためのフィードバックループがない。 モデルは1月に設定されて二度と触れられない。12ヶ月後、市場は変化し、ICPは進化し、モデルは依然として18ヶ月前のパターンに最適化しています。修正: 四半期Recalibrationプロセスを構築。RevOpsリードがモデルパフォーマンス指標(精度、Bucket別Precision・Recall)をレビューし、精度が5パーセントポイント以上低下したときにRetrainをトリガー。
閾値の設定放置。 初期閾値はGo-Liveに設定され、二度とレビューされない。90日後、モデルが広すぎる学習をしたため、すべてのLeadの40%が「High」にScoringされる。「High」キューが担当者を圧倒し、信頼が崩壊する。修正: 閾値Distributionを月次でレビューし、担当者キャパシティに合った適切なキュー量を維持するよう調整。
一般的なAI Lead Scoringの落とし穴の詳細はこちら。
ベンダーSnapshot
Salesforce Einstein Lead ScoringはSales Cloud Enterprise以上に含まれています。SalesforceデータをエクスポートしたりThird-Partyツールに接続したりすることなく、直接Salesforceデータでトレーニングします。モデルは定期的なスケジュールで自動Recalibrateします。CleanなSalesforceデータと12ヶ月以上の履歴を持つ企業では品質が高いです。高度なFeature EngineeringやカスタムデータソースのConfigurationが制限されています。
HubSpot Predictive Lead ScoringはMarketing Hub Professional/EnterpriseとSales Hub Enterpriseで利用可能です。Einsteinと同様のアーキテクチャ: HubSpotデータでトレーニングし、HubSpot Pipeline内で表示されるスコアを生成します。HubSpot外で大量のBehavioral Dataがあるまたは複雑な企業属性Segmentationニーズがある企業では弱いです。
MadKuduはSalesforce、HubSpot、複数のデータエンリッチメントソースに接続するPurpose-Built B2B Scoring Platformです。Feature Importance(特定のスコアをどのシグナルが駆動したか)を表示し、RevOpsがAuditとCalibrationをしやすくします。モデルロジックへのTransparencyを求めていて、データ統合作業を惜しまない企業に最適です。
6senseはConversion ProbabilityよりもIntentシグナル(Buying Committee識別、匿名訪問者トラッキング)にフォーカスしています。Mid-FunnelのAccount Prioritization、特にAccount-Based Sellingで強みがあります。CRMネイティブのScoringモデルを置き換えるのではなく、その上にLayerするケースが多いです。
Rework Sales AIはフルAI Sales Operatorアーキテクチャの一部としてCRMにScoring+Routingが組み込まれています。ScoreはDeal OutcomeからRecalibrateし、自動的にRepキューにRoutingし、Workflow CopilotにDirect Feedして下書きフォローアップを生成します。別のベンダー関係を管理せずに統合Scoringを求めるチームに最適です。
Rework Analysis: 私たちが見る最もよくあるML Lead Scoringの失敗は、悪いモデルではありません。誰もRecalibrateしない良いモデルです。チームはQ1にデプロイし、Q2に強い結果を見て、Q4には「Hot」Leadがもうクローズしない理由を疑問に思っています。モデルは9ヶ月前に存在した市場でトレーニングされていました。価格変更後にICPがShiftし、新しい競合が参入し、新しいUse Caseが出てきました。四半期Recalibrationはオプションのメンテナンスではありません。Probability Outputを現在の現実と接続し続けるメカニズムです。最初からOpsカレンダーにRecalibrationレビューを組み込んだチームは12〜18ヶ月間ROIを持続させます。モデルを一度限りのインストールとして扱うチームは通常6ヶ月以内にパフォーマンスがプラトーになります。
フィードバックループがすべて
ルールベースScoringはHypothesisです。これらの属性はConversionを予測するはずだ。一度設定して古くなっても大丈夫を願います。
ML Scoringは測定です。これらの属性は実際のOutcomeに基づいてConversionを予測しました。新しいOutcomeが届くたびに更新されます。
しかし「ML Scoringは測定である」は、測定システムにフィードバックループがある場合にのみ成立します。Recalibrationなしでは、モデルもHypothesisです。直感ではなくデータでトレーニングされたに過ぎない。市場状況が変化するにつれてDriftするHypothesisです。
持続的なROIをもたらすデプロイは、RevOpsがフィードバックループをOwnしているものです。四半期ごとにモデルの精度を追跡します。精度が低下したときにRetrainします。閾値パフォーマンスを月次でAuditします。Scoringモデルを一度限りのプロジェクトではなくInfrastructureとして扱います。
その運用上のOwnershipが、改善し続けるAI Lead ScoringデプロイとGoLive後3ヶ月は良い結果を出してその後BackgroundNoiseになるものを分けます。ScoringモデルがCalibrationされて正しいLeadを正しいRepにFeedするようになると、次の問いはそれらのLeadが到着したときに何が起きるかです。
よくある質問
AI Lead Scoringとは何ですか?
AI Lead ScoringはCRMの過去データでトレーニングされた機械学習モデルを使用して、各インバウンドLeadに0〜100のProbability Scoreを割り当てます。人間が割り当てたポイント重み(ルールベースScoring)の代わりに、モデルは自社の特定の顧客ベースでどのシグナルの組み合わせが実際にClosed-Won Outcomeと相関するかを学習し、すべての新しいLeadにその学習済み重みを適用します。新しいDealがCloseするたびにスコアが更新され、静的ではなく自己Calibratingになります。
AI Lead Scoringはルールベースのそれとどう違いますか?
ルールベースScoringはHypothesisをエンコードします。「VP肩書きは20点追加、Pricingページ訪問は25点追加」。AI Scoringは実際にConversionしたものを測定します。モデルは過去のデータでWon Dealと相関するシグナルの組み合わせを見つけ、それに応じて重みを付けます。実際の違いは、ルールはICPが変わっても適応せず、シグナル間のInteraction Effectを捉えず、時間とともに改善しないことです。AIモデルは適切にRecalibrateされると3つすべてを行います。
AI Lead Scoring ModelにはどのようなDataが必要ですか?
最低要件は一貫したWon/LostラベリングによるClosedDealが少なくとも6ヶ月分(12ヶ月推奨)、Closed-Won Dealが合計最低200件、一貫したCRMステージ定義、70%以上のレコードでキャプチャされたFirst-Touchソース、80%以上のレコードで入力された会社名/ドメインです。Won Dealが100件未満でトレーニングされたモデルはランダムアサインと統計的に区別がつかない出力を生成します。
B2B Lead ScoringにはどのシグナルがMost Importantですか?
Intentシグナル(Pricingページ訪問、競合比較ページ、G2カテゴリ閲覧)がLate-Stage購買行動を示すため最も高いConversionリフトを持ちます。EngagementのRecencyが続き、過去30日以降は指数関数的に減衰します。企業属性Fit(会社規模、業界、資金調達ステージ)はほとんどのB2B SaaS製品にとって3番目に予測力の高いカテゴリです。具体的なランキングは製品によって異なります。モデルはデータから自社の実際の順序を学習します。
AI Lead Scoring Modelはどのくらいの頻度でRecalibrateすべきですか?
四半期Recalibrationが最低標準です。RevOps Ownerは毎四半期モデルの精度(Score Bucket別のPrecisionとRecall)をレビューし、精度がBaselineから5パーセントポイント以上低下したときにRetrainをトリガーする必要があります。ICPはShiftし、新しいチャネルが出現し、価格変更はどのLeadがConversionするかを変えます。9〜12ヶ月前にRecalibrationなしでトレーニングされたモデルは、現在の購買者を反映していないパターンに最適化している可能性があります。
AI Lead Scoringの最もよくある失敗パターンとは何ですか?
4つの最もよくある失敗は: (1) バイアスがかかった過去データでトレーニングされたモデル(例: Winの70%が1つのチャネルから、モデルが他のチャネルのScoringが苦手になる)、(2) RepのDaily WorkflowにScoreが表示されず無視される、(3) Recalibrationプロセスがなく市場が変化するにつれて精度がDrift、(4) 閾値のMiscalibrationで「High」Bucketにあまりにも多くのLeadが入りRepキャパシティを圧迫して信頼が崩壊。
異なるスコア範囲はどのようなRoutingActionをトリガーすべきですか?
標準の5 Bucket Routingモデルは: 85〜100%(シニアAEへの直接Routing、即時Slack通知)、65〜84%(AEキュー、2時間コンタクトSLA)、40〜64%(SDR資格確認、Mid-TouchSequenceにEnroll)、20〜39%(自動Nurture、担当者アサインなし)、0〜19%(ニュースレターのみ)にマッピングされます。具体的な閾値はチームの担当者キャパシティに合わせてCalibrationし、現在のヘッドカウントに適したキュー量を維持するため月次でレビューすべきです。
関連記事
