Personalization Engine: Relevancia a Escala
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
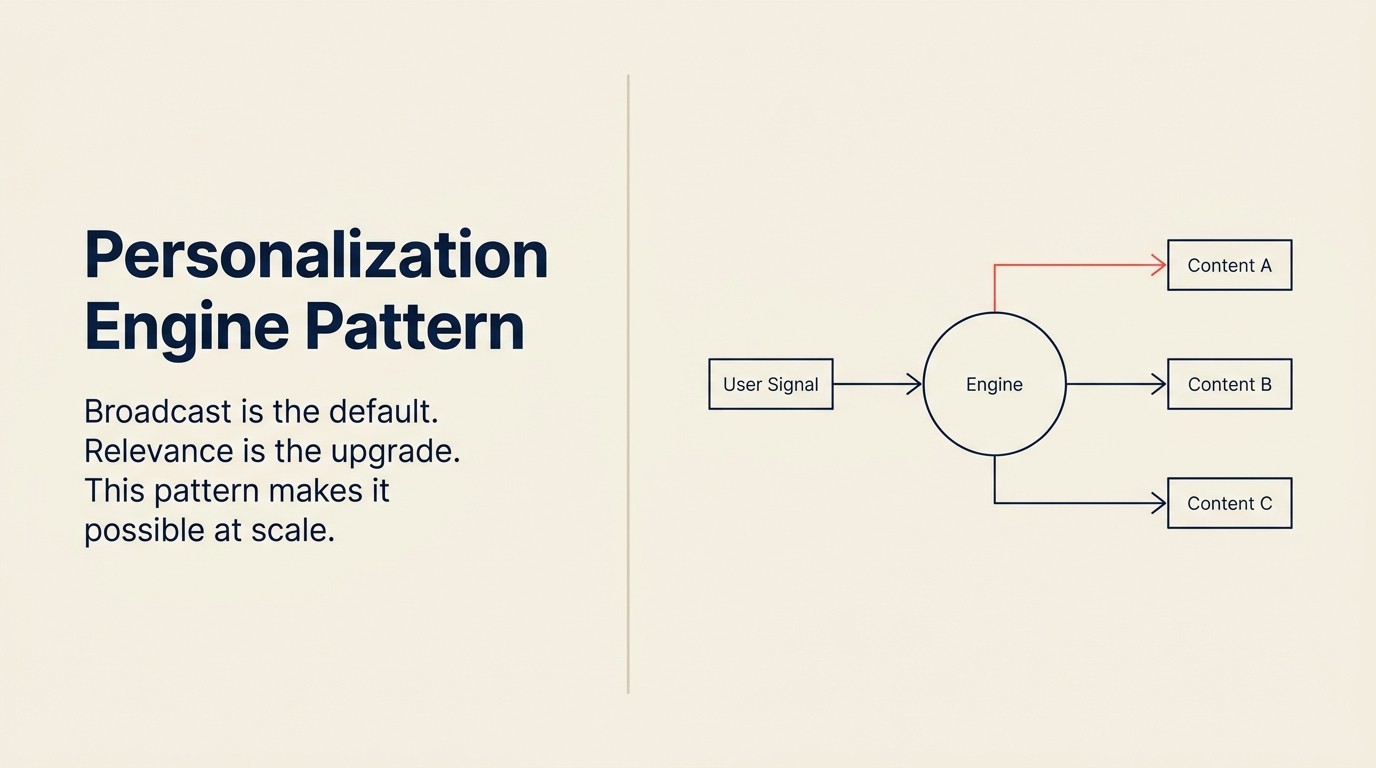
El broadcast es el valor predeterminado. La relevancia es la mejora.
El mismo correo enviado a 50,000 personas funciona con un 1% de click-through. Una versión ajustada a cada segmento, cada comportamiento, cada momento en el ciclo de vida del cliente funciona al 5 al 12%. No porque la redacción sea mejor. Porque el contenido correcto llegó a la persona correcta en el momento correcto.
Personalization Engine es el patrón de IA que hace posible la relevancia a escala. Está integrado en cada plataforma de e-commerce importante, en cada stack de marketing automation que vale la pena usar y en una proporción creciente de experiencias de productos B2B. Pero la mayoría de los equipos lo despliegan sin entender la mecánica, que es como termina con un filter bubble que deja de mostrar nuevas categorías, o una sensación de "demasiado conocedor" que incomoda a los usuarios y genera desengagement.
Este artículo cubre el patrón completo: fórmula, ejemplos reales en cinco contextos de despliegue, failure modes, arquitectura de privacidad y señales de ROI.
La fórmula
Ingest (señales de comportamiento del usuario) → Analyze (construir o actualizar perfil de usuario) → Predict (preferencias, siguiente mejor acción, contenido relevante) → Generate (contenido personalizado, oferta o experiencia) → Execute (entregar en el momento correcto)
Cada paso en un ejemplo de personalización de correo:
Ingest: Un usuario abre su producto, hace clic en la página de precios, luego abandona sin convertir. Abrió sus últimos tres correos. Hizo clic en un enlace sobre funciones de seguridad empresarial y pasó 90 segundos en esa página. Estas son señales de comportamiento. El paso Ingest las captura en tiempo real y las asocia con el perfil del usuario.
Analyze: El sistema actualiza el perfil del usuario. Esta persona ha mostrado interés repetido en las funciones de seguridad, se ha involucrado con contenido de nivel empresarial y parece estar en un ciclo de evaluación según los patrones de visitas a páginas. Suposición de rol: líder de TI o seguridad. Etapa de compra: consideración.
Predict: Dado este perfil, el siguiente mejor contenido es un caso de estudio sobre clientes empresariales en industrias reguladas que implementaron el stack de seguridad. No un boletín genérico. No la guía de onboarding para PYMES. Ese contenido específico, para esta persona, en este momento.
Generate: El sistema construye un correo con un asunto personalizado, una oración de apertura que hace referencia a la seguridad empresarial sin resultar intrusiva, el caso de estudio como el principal call-to-action y contenido secundario que coincide con las señales de interés.
Execute: El correo se envía en el momento en que el modelo predice que es más probable que este usuario lo abra (históricamente el martes por la mañana, 9 a.m.). El CRM registra la interacción. El bucle de retroalimentación comienza: ¿abrió el usuario, hizo clic, convirtió?
El bucle de retroalimentación no es opcional. Es lo que hace que el patrón mejore con el tiempo. Un personalization engine sin un bucle de retroalimentación señal-a-resultado es una segmentación estática con pasos adicionales. El modelo necesita saber si sus predicciones fueron correctas para mejorar. Vea Predict: cómo la IA pronostica resultados de negocio para saber cómo funciona la capa de predicción en detalle.
Key Facts: Impacto de negocio del Personalization Engine
- Las empresas que sobresalen en personalización generan un 40% más de ingresos que sus pares de crecimiento más lento, con la brecha impulsada por la retroalimentación de bucle cerrado entre señales de comportamiento y decisiones de contenido (McKinsey Personalization at Scale, 2021)
- Las campañas de correo personalizadas que usan señales de comportamiento y segmentación basada en roles logran tasas de click-through del 5-12% versus el 1% para correos broadcast a la misma audiencia (Salesforce Email Benchmark Report, 2025)
- Los equipos de producto B2B que usan personalización de onboarding específica por rol ven una mejora del 25-40% en las tasas de activación de funciones a 30 días en comparación con los flujos de onboarding genéricos, porque la función correcta se muestra en el momento en que el rol del usuario la hace relevante (Amplitude Product Analytics, 2025)
El Bucle de Relevancia en Tiempo Real
El mecanismo central del Personalization Engine es un bucle de retroalimentación cerrado: las señales de comportamiento actualizan el perfil del usuario, el perfil actualizado impulsa una nueva predicción, la predicción genera contenido personalizado, el contenido se entrega y la respuesta del usuario (clic, salto, conversión, ignorar) se convierte en la siguiente señal de comportamiento. Este bucle es lo que distingue el Personalization Engine de la segmentación. La segmentación asigna usuarios a grupos estáticos y mantiene esa asignación hasta que alguien la actualiza manualmente. El Personalization Engine actualiza el perfil continuamente, de modo que la predicción refleja quién es el usuario hoy, no quién era al registrarse. Un modelo sin un bucle de retroalimentación cerrado es segmentación estática con etiquetado de IA. Un modelo con un bucle cerrado mejora la precisión de predicción con cada interacción.
El problema de negocio que resuelve
La comunicación genérica desperdicia el presupuesto de entrega y erosiona la confianza. Cuando un cliente lleva dos años usando su producto y sigue recibiendo "Bienvenido a la plataforma, aquí le mostramos cómo comenzar", lo nota. Cuando un prospecto descarga una guía de precios empresariales y luego recibe un correo que promueve su plan gratuito, lo nota. La desconexión entre lo que el usuario le ha dicho a través de su comportamiento y lo que usted le está diciendo en respuesta señala que no está prestando atención.
Personalization Engine resuelve esto a escala. Sin IA, la personalización requiere segmentación manual, copias de campaña para cada segmento y lógica gestionada manualmente. Ese enfoque llega a un tope de 4 o 5 segmentos antes de volverse inmanejable operativamente. Con IA, puede personalizar en cientos de dimensiones simultáneamente, actualizar el perfil en tiempo real a medida que llegan las señales y dejar que el modelo determine qué contenido es más relevante sin escribir reglas explícitas para cada caso.
La mejora no es solo métricas de rendimiento. Es la experiencia. Los usuarios que reciben contenido relevante confían más en la marca. Los usuarios que reciben contenido irrelevante se dan de baja, abandonan o simplemente empiezan a ignorarlo.
Cinco ejemplos reales en profundidad
Recomendaciones de productos en e-commerce
Ingest: Historial de navegación, historial de compras, añadir al carrito sin comprar, consultas de búsqueda, rango de precios de los artículos en los que se hizo clic, distribución de categorías de pedidos anteriores.
Lógica de perfil: El sistema construye un modelo de preferencias por usuario. Este usuario compra en el rango de precios medio, hace compras principalmente en equipamiento de running y ha abandonado el carrito dos veces en el mismo zapato que actualmente está agotado.
Qué se personaliza: La cuadrícula de productos de la página de inicio, la sección "también podría gustarle" del correo y el módulo "comprado frecuentemente junto" en las páginas de productos.
Execute: La página de inicio renderiza diferentes feeds de productos por usuario. El zapato agotado desencadena una notificación de vuelta en stock. El envío del correo elige de un pool de 200 productos y muestra los 4 más relevantes para el perfil de este usuario.
El bucle de retroalimentación es ajustado aquí. Clic, compra o ignorar, cada respuesta actualiza el modelo en cuestión de horas.
Contenido dinámico en campañas de correo
Ingest: Datos del CRM (rol, tamaño de empresa, industria), engagement de correo pasado (qué temas ha clicado el usuario, cuáles ha ignorado), datos de uso del producto (qué funciones ha activado) y etapa del funnel.
Lógica de perfil: Dos usuarios reciben la misma campaña. El usuario A es un VP de Ventas en una empresa de tecnología de 500 personas, hizo clic en dos artículos sobre pronóstico de pipeline y es un usuario activo diario. El usuario B es un Marketing Manager en una startup de 50 personas, abrió pero nunca hizo clic y se conectó por última vez hace 12 días.
Qué se personaliza: El asunto, el párrafo de apertura, el enlace del artículo principal y el call-to-action. El usuario A recibe contenido de eficiencia de pipeline y una invitación a reservar una demo. El usuario B recibe una pieza de re-engagement y una invitación a comenzar con un quick win en el producto.
Execute: La misma infraestructura de campaña, dos experiencias de correo diferentes construidas en el momento del envío.
La distinción respecto a la segmentación simple: el sistema no usa segmentos estáticos. Está construyendo un perfil en tiempo real por usuario y tomando decisiones de contenido por envío. El modelo mejora con cada envío basándose en lo que funcionó.
Nudges de onboarding en el producto
Ingest: Función de trabajo del formulario de registro, tamaño de empresa, funciones activadas en los primeros 7 días, páginas visitadas en la app y tickets de soporte enviados (que son señales indirectas sobre dónde está atascado el usuario).
Lógica de perfil: Un usuario que se registró como Account Executive y ha activado la integración de CRM pero no ha conectado su calendario de correo está perdiendo un flujo de trabajo de alto valor. El sistema lo nota.
Qué se personaliza: La secuencia de tooltips en el producto, los elementos de la lista de verificación mostrados en la barra lateral de onboarding y el seguimiento por correo activado en el día 3.
Execute: En el día 3, en lugar del correo de onboarding genérico, el usuario recibe un correo de enfoque único: "Ha conectado su CRM. Así es como puede agregar la sincronización de calendario en 90 segundos", con un deep-link directamente a la configuración del calendario.
Los equipos de producto B2B subestiman cuánto valor hay en este patrón. Los flujos de onboarding genéricos dejan tasas de activación significativas sobre la mesa. Los flujos específicos por rol, construidos a partir de señales de comportamiento, se convierten a tasas significativamente más altas.
Personalización de precios B2B
Ingest: Tamaño de cuenta (del CRM), vertical de industria, nivel de uso del producto (qué funciones usa más la cuenta), señales de expansión (usuarios añadidos, asientos solicitados, solicitudes de funciones enviadas) y puntuación NPS.
Lógica de perfil: Una cuenta de 200 asientos en servicios financieros está en el plan Starter pero usa la API de forma intensiva. Tres miembros del equipo han enviado solicitudes de funciones para registro de auditoría avanzado. Esta cuenta está lista para la expansión.
Qué se personaliza: El prompt de actualización en la app muestra un mensaje sobre las funciones de registro de auditoría y cumplimiento específicamente. El correo del Customer Success manager está pre-llenado con el caso de expansión específico para el patrón de uso de esta cuenta.
Execute: El prompt de actualización se activa después de la 500ª llamada a la API en un ciclo de facturación. El correo del CSM se pone en cola para revisión antes del envío (compuerta de aprobación humana para comunicaciones orientadas al cliente).
Aquí es donde la personalización B2B diverge del consumidor. El paso Execute para la comunicación de precios debe mantener a un humano en el bucle. La IA construye la relevancia. El humano es dueño de la relación.
Recomendaciones de rutas de aprendizaje en LMS
Ingest: Rol y departamento del sistema de RR.HH., completaciones de cursos anteriores, puntuaciones de cuestionarios por área temática, tiempo para completar por módulo (proxy del engagement) y brechas de habilidades auto-reportadas desde la evaluación inicial.
Lógica de perfil: Un gerente recién promovido completó dos cursos de liderazgo y tuvo buenas puntuaciones en los módulos de comunicación pero saltó el módulo de resolución de conflictos. El modelo marca la resolución de conflictos como la siguiente recomendación de mayor prioridad.
Qué se personaliza: El carrusel "recomendado para usted" en la página de inicio del LMS, el correo semanal de resumen de aprendizaje y los inputs del plan de coaching del gerente.
Execute: El plan de aprendizaje se actualiza automáticamente cada lunes. El resumen por correo construye la lista de 3 recomendaciones de cada usuario de forma dinámica.
El bucle de retroalimentación aquí son los datos de resultados de aprendizaje: ¿mejoraron las puntuaciones de revisión de desempeño del empleado en las áreas donde la IA recomendó desarrollo? Esa es una señal de ciclo largo, pero es la señal que valida si la personalización está funcionando al nivel de los resultados, no solo al nivel del engagement.
Cuándo funciona bien Personalization Engine
Tres condiciones hacen que el patrón sea efectivo:
Señal de comportamiento suficiente por usuario. El modelo necesita algo con qué trabajar. Si los usuarios interactúan con su producto con poca frecuencia o dejan un rastro de comportamiento mínimo, el perfil es delgado. Los perfiles delgados producen recomendaciones genéricas. La mayoría de las plataformas de e-commerce necesitan 5-10 interacciones antes de que la personalización supere al broadcast. Las herramientas B2B con flujos de trabajo complejos e infrecuentes necesitan recolección explícita de señales (rol, intención, objetivo) para compensar los datos de comportamiento escasos.
Superficie de personalización que puede variar. El cuerpo del correo, el feed de productos, el flujo de onboarding o la página de precios necesita realmente soportar la variación. Si su infraestructura técnica entrega una página estática a cada visitante, la personalización en la capa de contenido está bloqueada por la infraestructura, no por la capacidad de IA. Audite la superficie antes de comprometerse con el patrón.
Bucle de retroalimentación cerrado. Necesita medir si la personalización funcionó. Clic, compra, activación, conversión, retención. Si no puede conectar la intervención personalizada con una señal de resultado, no puede entrenar al modelo para mejorar. Está ejecutando personalización a ciegas.
Failure modes
Cold start. Los nuevos usuarios sin señal reciben salida genérica de todos modos. Esto es inevitable pero manejable. La mitigación es la recolección explícita de señales al registrarse: pregunte por el rol, el caso de uso y los objetivos. Use esas señales declaradas para arrancar el perfil antes de que se acumulen los datos de comportamiento. Las señales explícitas decaen con el tiempo (las personas cambian de rol, las empresas crecen), así que el sistema debe ponderar las señales de comportamiento recientes sobre las declaradas obsoletas a medida que madura el perfil.
Filter bubble. El modelo muestra lo que el usuario ya ha demostrado interés, lo que significa que deja de ver cosas fuera de sus patrones existentes.
La investigación de Netflix encontró que el 80% del contenido visto en la plataforma se descubre a través de su motor de recomendaciones, pero en los años en que la cuota de diversidad no se mantuvo activamente, el engagement con nuevos títulos cayó un 23% en 6 meses a medida que los usuarios caían en bucles de recomendaciones cada vez más estrechos (Netflix Technology Blog, 2022). La misma dinámica aparece en contextos B2B: los usuarios cuya personalización de onboarding solo muestra las funciones que ya han tocado se pierden las funciones adyacentes que entregarían valor adicional. Esto importa más en plataformas de contenido y mercados donde el descubrimiento es un valor central. Mitigación: inyectar una "cuota de diversidad" en la lógica de recomendación, una fracción de recomendaciones que deliberadamente extrae de categorías adyacentes en lugar de preferencias confirmadas. El 10 al 20% de diversidad es típicamente suficiente para mantener el descubrimiento sin socavar la relevancia.
Percepción de privacidad. Los usuarios que encuentran la personalización "demasiado conocedora" se desenganchan o se sienten vigilados. Esto es distinto del cumplimiento de la ley de privacidad (GDPR, CCPA). Una recomendación técnicamente legal puede seguir sintiéndose invasiva. La línea suele ser sobre combinar señales offline y online de maneras que se sienten sorprendentes. Mitigación: mantener la personalización anclada a lo que los usuarios han hecho dentro de su producto o con contenido con el que se comprometieron explícitamente. Comprar datos de terceros para personalizar una experiencia cruza una línea para muchos usuarios incluso si es legal.
Decaimiento de señales. El historial de compras de un cliente de hace 18 meses ya no es una señal confiable si ha cambiado de roles, de empresa o ha completado un proyecto que creó el patrón de compra original. El modelo sigue optimizando para un usuario que ya no existe. Mitigación: ponderar las señales en el tiempo para que el comportamiento reciente tenga mayor influencia que el comportamiento antiguo. Establecer un umbral de decaimiento: las señales de más de 12 meses contribuyen con peso reducido; las señales de más de 24 meses se archivan y se excluyen de la construcción activa del perfil. El gradiente de riesgo en los patrones de IA explica por qué este patrón se ubica en el riesgo de Nivel 3 cuando la personalización impulsa decisiones automatizadas a escala.
Cuándo elegir Personalization Engine vs. alternativas
Vs. RAG Assistant: RAG responde a consultas explícitas. El usuario hace una pregunta; el sistema recupera contenido relevante y responde. Personalization Engine es proactivo. Ajusta el entorno antes de que el usuario pregunte. Use RAG cuando los usuarios tengan preguntas específicas y expresables. Use Personalization Engine cuando quiera moldear lo que los usuarios encuentran antes de que formen una consulta.
Vs. Workflow Copilot: Workflow Copilot asiste al usuario durante el trabajo activo, sugiriendo próximas acciones dentro de una tarea. Personalization Engine ajusta el entorno alrededor del usuario, cambiando qué contenido, productos u opciones son visibles antes de que el usuario comience a trabajar en algo específico. La distinción es dentro de la tarea vs. alrededor de la tarea.
Vs. Scoring + Routing: Scoring and Routing clasifica los elementos entrantes y los enruta al humano o cola correcta. Determina a dónde va algo. Personalization Engine ajusta lo que el usuario ve, no a dónde va. Ambos pueden usar las mismas señales de comportamiento y perfil, pero producen salidas diferentes: una decisión de enrutamiento vs. una selección de contenido.
Arquitectura de privacidad y consentimiento
Tres categorías de señales requieren consentimiento explícito del usuario en la mayoría de los marcos regulatorios (GDPR, CCPA, PIPEDA):
- Seguimiento entre sitios (cookies que siguen a los usuarios entre dominios)
- Datos de categorías sensibles (salud, financiero, político, ubicación con precisión)
- Combinar identificadores para crear un perfil que vincule el comportamiento en línea con la identidad fuera de línea
Para entornos sin cookies, las señales de comportamiento dentro de su producto (clics, uso de funciones, tiempo en página, consultas de búsqueda en el producto) no requieren mecanismos de consentimiento de terceros. Son señales de primera parte de usuarios que tienen una cuenta y han aceptado sus términos.
Arquitectura práctica para personalización con consentimiento seguro:
- Señales de comportamiento de primera parte: no se necesita consentimiento adicional más allá de sus términos de servicio
- Personalización de correo de marketing usando atributos declarados (rol, empresa): cubierta por el consentimiento de opt-in de correo
- Personalización entre canales que combina datos del producto con plataformas publicitarias: requiere consentimiento explícito con opciones de opt-in granulares, no una casilla de verificación enterrada
Manejar el opt-out sin degradar la experiencia: cuando un usuario opta por no participar en la personalización, sirva una experiencia predeterminada bien diseñada, no una que esté rota. Organice un feed predeterminado sólido. No penalice a los usuarios que prefieren no ser rastreados mostrándoles una versión obviamente inferior del producto.
Señales de ROI
| Métrica | Qué le dice |
|---|---|
| Tasa de conversión por cohorte de personalización | Personalizado vs. broadcast, mismo producto, mismo período de tiempo. Este es el caso de negocio central. |
| Click-through de correo: personalizado vs. broadcast | Comparación directa de la misma campaña con y sin personalización. |
| Ingresos por usuario por nivel de personalización | ¿La inversión del modelo en personalización profunda se paga en ingresos por cuenta? |
| Adopción de funciones para usuarios con nudges vs. sin nudges | Para la personalización en el producto, ¿mostrar una recomendación de función impulsa la activación? |
| Latencia del bucle de retroalimentación | ¿Cuánto tiempo tarda una señal de resultado en llegar al modelo e influir en la siguiente recomendación? Cuanto más corto, mejor. |
| Puntuación de diversidad de recomendaciones | ¿Qué porcentaje de recomendaciones proviene de categorías con las que el usuario no ha interactuado previamente? Rastrear el riesgo de filter bubble. |
Qué viene después
Personalization Engine es a menudo el primer patrón de IA que despliegan los equipos orientados al consumidor. Pero rara vez funciona solo. El plan de tecnología de personalización de McKinsey identifica que el patrón completo requiere orquestar cuatro capacidades: recolección de datos, toma de decisiones impulsada por IA, diseño de contenido y distribución, cada una de las cuales se corresponde directamente con la cadena Ingest → Analyze → Generate → Execute en el Marco ACE.
Para la detección de anomalías de comportamiento (el usuario que de repente cambia de patrones de una manera que indica churn o fraude), el patrón Anomaly Agent es el complemento. Combine Personalization Engine con Anomaly Agent y tiene un sistema que no solo muestra el contenido correcto para cada usuario, sino que también detecta cuando el comportamiento de un usuario cambia de maneras que requieren una intervención diferente: una llamada de revisión de salud del customer success, o una marca para el equipo de fraude.
Cuando esté listo para combinar múltiples patrones en un sistema de IA a nivel de rol, el artículo Combinando Patrones para Construir AI Agents cubre cómo se suman los patrones. Un AI Marketer, por ejemplo, combina Personalization Engine con Generative Research, Meeting Intelligence y Predict, cada uno manejando una fase diferente del ciclo de campaña.
Rework Analysis: El fallo de Personalization Engine que vemos con más frecuencia es un sistema sin bucle de retroalimentación cerrado. El modelo ejecuta sus primeras predicciones en el lanzamiento basándose en el rol y las preferencias declaradas, y luego nadie conecta los datos de resultado de vuelta al modelo. Seis meses después, las recomendaciones siguen basándose en datos de registro de usuarios que desde entonces han cambiado de roles, activado diferentes funciones y avanzado por varias etapas de su ciclo de vida de cliente. El modelo está personalizando para usuarios que ya no existen. Cerrar el bucle no es una reflexión técnica tardía: requiere definir qué señal de resultado entrena el modelo (clic, activación, retención, ingresos), construir el pipeline que enruta esa señal de vuelta al modelo y establecer una cadencia de reentrenamiento. Los equipos que hacen esto en el lanzamiento ven el incremento de ingresos del 40% que mide McKinsey. Los que lo omiten ven una personalización que funciona marginalmente mejor que el broadcast y una conversación de presupuesto seis meses después.
Preguntas Frecuentes
¿Qué es el patrón de IA Personalization Engine?
Personalization Engine es un patrón de IA que entrega contenido, ofertas o experiencias diferentes a distintos usuarios según señales de comportamiento. La fórmula es: Ingest (señales de comportamiento del usuario), Analyze (construir o actualizar el perfil del usuario), Predict (preferencias, siguiente mejor acción o contenido relevante), Generate (contenido u oferta personalizada), Execute (entregar en el momento correcto). Se diferencia de la segmentación en que actualiza los perfiles de usuario continuamente y toma decisiones de contenido por usuario en lugar de por segmento.
¿Qué es el Bucle de Relevancia en Tiempo Real?
El Bucle de Relevancia en Tiempo Real es el mecanismo central del Personalization Engine: las señales de comportamiento actualizan el perfil del usuario, el perfil actualizado impulsa una nueva predicción, la predicción genera contenido personalizado, el contenido se entrega y la respuesta del usuario se convierte en la siguiente señal de comportamiento. Este bucle cerrado es lo que distingue al Personalization Engine de la segmentación estática. Un modelo sin un bucle cerrado es segmentación estática con etiquetado de IA. Un modelo con un bucle cerrado mejora la precisión de predicción con cada interacción.
¿Qué impacto de ingresos entrega la personalización?
Las empresas que sobresalen en personalización generan un 40% más de ingresos que sus pares de crecimiento más lento, con la brecha impulsada por la retroalimentación de bucle cerrado (McKinsey, 2021). Las campañas de correo personalizadas que usan señales de comportamiento logran tasas de click-through del 5-12% versus el 1% para correos broadcast (Salesforce, 2025). Los equipos de producto B2B que usan personalización de onboarding específica por rol ven una mejora del 25-40% en las tasas de activación de funciones a 30 días versus flujos genéricos (Amplitude, 2025).
¿Qué es el problema del filter bubble en la personalización?
Filter bubble ocurre cuando el modelo de recomendación solo muestra contenido de las categorías con las que el usuario ya ha interactuado, haciendo que dejen de descubrir nuevas opciones. Netflix encontró que cuando la cuota de diversidad no se mantuvo activamente, el engagement con nuevos títulos cayó un 23% en 6 meses a medida que los usuarios caían en bucles cada vez más estrechos. La mitigación es una cuota de diversidad: el 10-20% de las recomendaciones extraídas de categorías adyacentes en lugar de preferencias confirmadas, manteniendo el descubrimiento sin socavar la relevancia.
¿Qué requisitos de privacidad de datos aplican al Personalization Engine?
Tres categorías de señales requieren consentimiento explícito del usuario bajo GDPR, CCPA y PIPEDA: seguimiento entre sitios (cookies que siguen a los usuarios entre dominios), datos de categorías sensibles (salud, financiero, político, ubicación con precisión) y combinar identificadores para vincular el comportamiento en línea con la identidad fuera de línea. Las señales de comportamiento de primera parte dentro de su propio producto no requieren consentimiento adicional más allá de los términos de servicio. La personalización de correo de marketing usando atributos declarados está cubierta por el consentimiento de opt-in de correo. La personalización entre canales que combina datos del producto con plataformas publicitarias requiere opt-in explícito y granular.
¿Cuándo debería usar Personalization Engine versus Workflow Copilot?
Personalization Engine ajusta el entorno alrededor del usuario, cambiando qué contenido, productos u opciones son visibles antes de que el usuario comience una tarea específica. Workflow Copilot asiste al usuario dentro de una tarea activa, sugiriendo próximas acciones dentro del trabajo ya en progreso. La distinción es alrededor de la tarea versus dentro de la tarea. Use Personalization Engine para feeds de contenido, campañas de correo, recomendaciones de productos y flujos de onboarding. Use Workflow Copilot para redacción, código, informes y trabajo de CRM donde el usuario necesita asistencia en el punto de acción.
Más información
- Anomaly Agent: Detectando lo Inesperado
- Combinando Patrones para Construir AI Agents
- El Gradiente de Riesgo en los Patrones de IA
- Elegir el Patrón de IA Correcto para su Problema
- Scoring and Routing: Clasificación a Escala
- ¿Qué es la IA de Negocio? Una Definición Práctica para Operadores
- McKinsey: The Value of Getting Personalization Right
- McKinsey: A Technology Blueprint for Personalization at Scale

Co-Founder, Rework.com
On this page
- La fórmula
- El Bucle de Relevancia en Tiempo Real
- El problema de negocio que resuelve
- Cinco ejemplos reales en profundidad
- Recomendaciones de productos en e-commerce
- Contenido dinámico en campañas de correo
- Nudges de onboarding en el producto
- Personalización de precios B2B
- Recomendaciones de rutas de aprendizaje en LMS
- Cuándo funciona bien Personalization Engine
- Failure modes
- Cuándo elegir Personalization Engine vs. alternativas
- Arquitectura de privacidad y consentimiento
- Señales de ROI
- Qué viene después
- Más información