Personalization Engine: Relevância em Escala
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
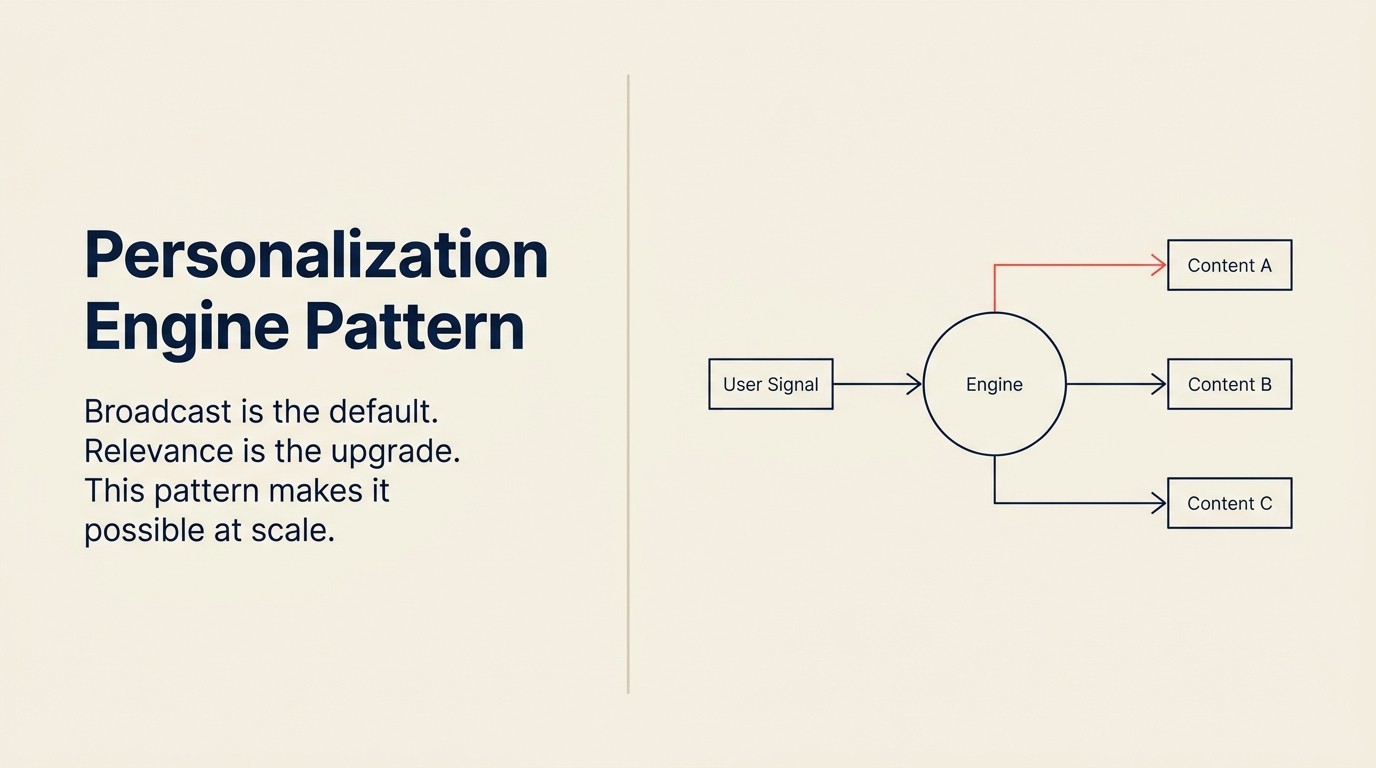
Broadcast é o padrão. Relevância é o upgrade.
O mesmo e-mail enviado para 50.000 pessoas tem desempenho de 1% de taxa de cliques. Uma versão ajustada para cada segmento, cada comportamento, cada momento no ciclo de vida do cliente tem desempenho de 5 a 12%. Não porque a redação é melhor. Porque o conteúdo certo chegou à pessoa certa no momento certo.
O Personalization Engine é o padrão de AI que torna a relevância em escala possível. Está integrado em todas as principais plataformas de e-commerce, em cada stack de automação de marketing que vale a pena usar, e em uma parte crescente de experiências de produto B2B. Mas a maioria das equipes o implanta sem entender os mecanismos, o que é como você acaba com uma bolha de filtro que para de mostrar novas categorias, ou uma sensação de "saber demais" que deixa os usuários desconfortáveis e impulsiona o desengajamento.
Este artigo abrange o padrão completo: fórmula, exemplos reais em cinco contextos de implantação, modos de falha, arquitetura de privacidade e sinais de ROI.
A fórmula
Ingest (sinais de comportamento do usuário) Analyze (construir ou atualizar perfil do usuário) Predict (preferências, próxima melhor ação, conteúdo relevante) Generate (conteúdo, oferta ou experiência personalizada) Execute (entregar no momento certo)
Cada etapa em um exemplo de personalização de e-mail:
Ingest: Um usuário abre seu produto, clica na página de preços e depois abandona sem converter. Abriu seus últimos três e-mails. Clicou em um link sobre recursos de segurança enterprise e passou 90 segundos nessa página. Esses são sinais de comportamento. A etapa Ingest os captura em tempo real e os associa ao perfil do usuário.
Analyze: O sistema atualiza o perfil do usuário. Esta pessoa mostrou interesse repetido em recursos de segurança, se engajou com conteúdo de nível enterprise e parece estar em um ciclo de avaliação com base nos padrões de visita às páginas. Suposição de função: líder de TI ou segurança. Etapa de compra: consideração.
Predict: Dado este perfil, o próximo melhor conteúdo é um case study sobre clientes enterprise em setores regulamentados que implementaram o stack de segurança. Não um newsletter genérico. Não o guia de onboarding para PMEs. Esse conteúdo específico, para esta pessoa, neste momento.
Generate: O sistema constrói um e-mail com uma linha de assunto personalizada, uma frase de abertura que referencia segurança enterprise sem ser invasiva, o case study como principal call-to-action e conteúdo secundário que corresponde aos sinais de interesse.
Execute: O e-mail é enviado no horário em que o modelo prevê que este usuário tem maior probabilidade de abrir (historicamente terça-feira de manhã, às 9h). O CRM registra a interação. O loop de feedback começa: o usuário abriu, clicou, converteu?
O loop de feedback não é opcional. É o que faz o padrão melhorar ao longo do tempo. Um Personalization Engine sem um loop de feedback de sinal para resultado é segmentação estática com etapas extras. O modelo precisa saber se suas previsões estavam certas para melhorar. Veja Predict: como a AI prevê resultados de negócios para como a camada de previsão funciona em detalhes.
Key Facts: Impacto de Negócio do Personalization Engine
- Empresas que se destacam em personalização geram 40% mais receita a partir dela do que pares de crescimento mais lento, com a lacuna impulsionada por feedback de loop fechado entre sinais de comportamento e decisões de conteúdo (McKinsey Personalization at Scale, 2021)
- Campanhas de e-mail personalizadas que usam sinais comportamentais e segmentação baseada em função alcançam taxas de cliques de 5-12% versus 1% para e-mails de broadcast para o mesmo público (Salesforce Email Benchmark Report, 2025)
- Equipes de produto B2B que usam personalização de onboarding específica para função veem melhoria de 25-40% nas taxas de ativação de funcionalidades em 30 dias em comparação com fluxos de onboarding genéricos, porque o recurso certo é mostrado no momento em que a função do usuário o torna relevante (Amplitude Product Analytics, 2025)
O Loop de Relevância em Tempo Real
O mecanismo central do Personalization Engine é um loop de feedback fechado: sinais comportamentais atualizam o perfil do usuário, o perfil atualizado impulsiona uma nova previsão, a previsão gera conteúdo personalizado, o conteúdo é entregue, e a resposta do usuário (clique, pular, converter, ignorar) se torna o próximo sinal comportamental. Este loop é o que distingue o Personalization Engine da segmentação. A segmentação atribui usuários a grupos estáticos e mantém essa atribuição até que alguém a atualize manualmente. O Personalization Engine atualiza o perfil continuamente, de modo que a previsão reflita quem o usuário é hoje, não quem era no momento do cadastro. Um modelo sem loop de feedback fechado é segmentação estática com rotulagem de AI. Um modelo com loop fechado melhora a precisão da previsão a cada interação.
O problema de negócio que resolve
Comunicação genérica desperdiça orçamento de entrega e corrói a confiança. Quando um cliente usa seu produto há dois anos e ainda recebe "Bem-vindo à plataforma, aqui está como começar," eles percebem. Quando um prospect baixa um guia de preços enterprise e depois recebe um e-mail promovendo seu plano gratuito, eles percebem. A desconexão entre o que o usuário disse a você por meio de seu comportamento e o que você está dizendo a ele em resposta sinaliza que você não está prestando atenção.
O Personalization Engine resolve isso em escala. Sem AI, a personalização requer segmentação manual, cópias de campanha para cada segmento e lógica gerenciada manualmente. Essa abordagem chega ao máximo em 4 ou 5 segmentos antes de se tornar operacionalmente ingerenciável. Com AI, você pode personalizar em centenas de dimensões simultaneamente, atualizar o perfil em tempo real à medida que os sinais chegam e deixar o modelo descobrir qual conteúdo é mais relevante sem escrever regras explícitas para cada caso.
O upgrade não é apenas métricas de desempenho. É a experiência. Usuários que recebem conteúdo relevante confiam mais na marca. Usuários que recebem conteúdo irrelevante cancelam a inscrição, fazem churn ou simplesmente começam a te ignorar.
Cinco exemplos reais em profundidade
Recomendações de produtos em e-commerce
Ingest: Histórico de navegação, histórico de compras, adição ao carrinho sem compra, consultas de pesquisa, faixa de preço dos itens clicados, distribuição de categorias de pedidos anteriores.
Lógica de perfil: O sistema constrói um modelo de preferência por usuário. Este usuário compra na faixa de preço médio, compra principalmente em equipamentos de corrida e abandonou o carrinho duas vezes no mesmo tênis que está atualmente fora de estoque.
O que é personalizado: A grade de produtos da página inicial, a seção "você também pode gostar" do e-mail e o módulo "frequentemente comprado juntos" nas páginas de produto.
Execute: A página inicial renderiza feeds de produtos diferentes por usuário. O tênis fora de estoque aciona uma notificação de volta ao estoque. O envio do e-mail seleciona de um pool de 200 produtos e mostra os 4 mais relevantes para o perfil deste usuário.
O loop de feedback é estreito aqui. Clicar, comprar ou ignorar: cada resposta atualiza o modelo dentro de horas.
Conteúdo dinâmico em campanhas de e-mail
Ingest: Dados do CRM (função, tamanho da empresa, setor), engajamento com e-mails anteriores (quais tópicos o usuário clicou, quais ignorou), dados de uso do produto (quais funcionalidades ativaram) e estágio no funil.
Lógica de perfil: Dois usuários recebem a mesma campanha. O Usuário A é VP de Vendas em uma empresa de tecnologia de 500 pessoas, clicou em dois artigos sobre previsão de pipeline e é um usuário ativo diário. O Usuário B é Gerente de Marketing em uma startup de 50 pessoas, abriu mas nunca clicou e fez último login há 12 dias.
O que é personalizado: A linha de assunto, o parágrafo de abertura, o link do artigo principal e a call-to-action. O Usuário A recebe conteúdo de eficiência de pipeline e uma chamada para agendar uma demo. O Usuário B recebe uma peça de re-engajamento e uma chamada para começar com uma vitória rápida no produto.
Execute: Mesma infraestrutura de campanha, duas experiências de e-mail diferentes construídas no momento do envio.
A distinção da segmentação simples: o sistema não está usando segmentos estáticos. Está construindo um perfil em tempo real por usuário e tomando decisões de conteúdo por envio. O modelo melhora a cada envio com base no que funcionou.
Nudges de onboarding no produto
Ingest: Função de trabalho do formulário de cadastro, tamanho da empresa, funcionalidades ativadas nos primeiros 7 dias, páginas visitadas no aplicativo e tickets de suporte enviados (que são sinais indiretos sobre onde o usuário está travado).
Lógica de perfil: Um usuário que se cadastrou como Account Executive e ativou a integração com CRM mas não conectou seu calendário de e-mail está perdendo um fluxo de trabalho de alto valor. O sistema anota isso.
O que é personalizado: A sequência de tooltips no produto, os itens da lista de verificação mostrados na barra lateral de onboarding e o acompanhamento por e-mail acionado no dia 3.
Execute: No dia 3, em vez do e-mail de onboarding genérico, o usuário recebe um e-mail de foco único: "Você conectou seu CRM. Veja como adicionar a sincronização de calendário em 90 segundos," com um deep-link diretamente para as configurações de calendário.
As equipes de produto B2B subestimam quanto valor está neste padrão. Fluxos de onboarding genéricos deixam taxas de ativação significativas na mesa. Fluxos específicos para cada função, construídos a partir de sinais comportamentais, convertem a taxas significativamente maiores.
Personalização de preços B2B
Ingest: Tamanho da conta (do CRM), vertical da indústria, nível de uso do produto (quais funcionalidades a conta usa mais), sinais de expansão (usuários adicionados, assentos solicitados, feature requests enviados) e pontuação NPS.
Lógica de perfil: Uma conta de 200 assentos em serviços financeiros está no plano Starter, mas usa a API intensamente. Três membros da equipe enviaram feature requests para registro de auditoria avançado. Esta conta está pronta para expansão.
O que é personalizado: O prompt de upgrade no aplicativo mostra uma mensagem sobre recursos de registro de auditoria e conformidade especificamente. O e-mail do Customer Success Manager é pré-preenchido com o caso de expansão específico para o padrão de uso desta conta.
Execute: O prompt de upgrade é acionado após a 500ª chamada de API em um ciclo de faturamento. O e-mail do CSM fica na fila para revisão antes do envio (portão de aprovação humana para comunicações voltadas ao cliente).
É aqui que a personalização B2B diverge do consumidor. A etapa Execute para comunicação de preços deve manter um humano no loop. A AI constrói a relevância. O humano é dono do relacionamento.
Recomendações de trilhas de aprendizado em LMS
Ingest: Função e departamento do sistema de RH, conclusões de cursos anteriores, pontuações de quizzes por área temática, tempo para completar por módulo (proxy para engajamento) e lacunas de habilidades autodeclaradas da avaliação inicial.
Lógica de perfil: Um gerente recém-promovido completou dois cursos de liderança e pontuou bem nos módulos de comunicação, mas pulou o módulo de resolução de conflitos. O modelo sinaliza a resolução de conflitos como a próxima recomendação de maior prioridade.
O que é personalizado: O carrossel "recomendado para você" na página inicial do LMS, o e-mail de resumo de aprendizado semanal e as entradas do plano de coaching do gestor.
Execute: O plano de aprendizado é atualizado automaticamente toda segunda-feira. O e-mail de resumo constrói a lista de 3 itens de recomendação de cada usuário dinamicamente.
O loop de feedback aqui são os dados de resultados de aprendizado: as pontuações de avaliação de desempenho do funcionário melhoraram nas áreas onde a AI recomendou desenvolvimento? Esse é um sinal de ciclo longo, mas é o sinal que valida se a personalização está funcionando no nível de resultado, não apenas no nível de engajamento.
Quando o Personalization Engine funciona bem
Três condições tornam o padrão eficaz:
Sinal de comportamento suficiente por usuário. O modelo precisa de algo com que trabalhar. Se os usuários interagem com seu produto com pouca frequência ou deixam um rastro comportamental mínimo, o perfil é fino. Perfis finos produzem recomendações genéricas. A maioria das plataformas de e-commerce precisa de 5-10 interações antes que a personalização supere o broadcast. Ferramentas B2B com fluxos de trabalho complexos e infrequentes precisam de coleta explícita de sinais (função, intenção, objetivo) para compensar dados comportamentais escassos.
Superfície de personalização que pode variar. O corpo do e-mail, o feed de produtos, o fluxo de onboarding ou a página de preços precisa realmente suportar variação. Se sua infraestrutura técnica entrega uma página estática para cada visitante, a personalização na camada de conteúdo é bloqueada pela infraestrutura, não pela capacidade de AI. Audite a superfície antes de se comprometer com o padrão.
Loop de feedback fechado. Você precisa medir se a personalização funcionou. Clique, compra, ativação, conversão, retenção. Se você não consegue conectar a intervenção personalizada a um sinal de resultado, não pode treinar o modelo para melhorar. Você está executando personalização às cegas.
Modos de falha
Cold start. Novos usuários sem sinal recebem saída genérica de qualquer maneira. Isso é inevitável, mas gerenciável. A mitigação é coleta explícita de sinal no cadastro: pergunte sobre função, caso de uso e objetivos. Use esses sinais declarados para inicializar o perfil antes que os dados comportamentais se acumulem. Sinais explícitos decaem com o tempo (as pessoas mudam de função, as empresas crescem), então o sistema deve ponderar sinais comportamentais recentes acima dos declarados mais antigos à medida que o perfil amadurece.
Filter bubble. O modelo traz à tona o que o usuário já demonstrou interesse, o que significa que ele para de ver coisas fora de seus padrões existentes.
A pesquisa da Netflix descobriu que 80% do conteúdo assistido na plataforma é descoberto por meio de seu mecanismo de recomendação, mas nos anos em que a cota de diversidade não era ativamente mantida, o engajamento com novos títulos caiu 23% em 6 meses à medida que os usuários entravam em loops de recomendação cada vez mais estreitos (Netflix Technology Blog, 2022). A mesma dinâmica aparece em contextos B2B: usuários cujo onboarding personalizado mostra apenas as funcionalidades que já tocaram perdem funcionalidades adjacentes que entregariam valor adicional. Isso importa mais em plataformas de conteúdo e marketplaces onde a descoberta é um valor central. Mitigação: injete uma "cota de diversidade" na lógica de recomendação, uma fração de recomendações que deliberadamente puxam de categorias adjacentes em vez de preferências confirmadas. 10 a 20% de diversidade é tipicamente suficiente para manter a descoberta sem comprometer a relevância.
Percepção de privacidade. Usuários que acham a personalização "sabendo demais" se desengajam ou se sentem vigiados. Isso é distinto da conformidade com leis de privacidade (LGPD, GDPR, CCPA). Uma recomendação que é tecnicamente legal ainda pode parecer invasiva. A linha é geralmente sobre combinar sinais offline e online de maneiras que parecem surpreendentes. Mitigação: mantenha a personalização ancorada no que os usuários fizeram dentro do seu produto ou com conteúdo com o qual se engajaram explicitamente. Comprar dados de terceiros para personalizar uma experiência cruza uma linha para muitos usuários, mesmo que seja legal.
Decaimento de sinal. O histórico de compras de um cliente de 18 meses atrás não é mais um sinal confiável se mudaram de função, de empresa ou concluíram um projeto que criou o padrão de compra original. O modelo continua otimizando para um usuário que não existe mais. Mitigação: pondere os sinais pelo tempo de modo que o comportamento recente tenha mais influência do que o comportamento mais antigo. Defina um limite de decaimento: sinais com mais de 12 meses contribuem com peso reduzido; sinais com mais de 24 meses são arquivados e excluídos da construção ativa do perfil. O gradiente de risco entre os padrões de AI explica por que este padrão está no risco de Nível 3 quando a personalização impulsiona decisões automatizadas em escala.
Quando escolher o Personalization Engine versus alternativas
Vs. RAG Assistant: O RAG responde a consultas explícitas. O usuário faz uma pergunta; o sistema recupera conteúdo relevante e responde. O Personalization Engine é proativo. Ele ajusta o ambiente antes que o usuário pergunte. Use o RAG quando os usuários têm perguntas específicas e expressáveis. Use o Personalization Engine quando quiser moldar o que os usuários encontram antes de formarem uma consulta.
Vs. Workflow Copilot: O Workflow Copilot auxilia o usuário durante o trabalho ativo, sugerindo próximas ações dentro de uma tarefa. O Personalization Engine ajusta o ambiente ao redor do usuário, mudando que conteúdo, produtos ou opções são visíveis antes de o usuário começar a trabalhar em algo específico. A distinção é dentro da tarefa versus ao redor da tarefa.
Vs. Scoring + Routing: O Scoring and Routing faz a triagem de itens de entrada e os encaminha para o humano ou fila certos. Determina para onde algo vai. O Personalization Engine sintoniza o que o usuário vê, não para onde vai. Ambos podem usar os mesmos sinais comportamentais e de perfil, mas produzem saídas diferentes: uma decisão de encaminhamento versus uma seleção de conteúdo.
Arquitetura de privacidade e consentimento
Três categorias de sinais requerem consentimento explícito do usuário na maioria dos frameworks regulatórios (LGPD, GDPR, CCPA, PIPEDA):
- Rastreamento entre sites (cookies que seguem usuários em diferentes domínios)
- Dados de categorias sensíveis (saúde, financeiros, políticos, localização com precisão)
- Combinação de identificadores para criar um perfil que vincula comportamento online à identidade offline
Para ambientes sem cookies, sinais comportamentais dentro do seu produto (cliques, uso de funcionalidades, tempo na página, consultas de pesquisa no produto) não requerem mecanismos de consentimento de terceiros. São sinais de primeira parte de usuários que têm uma conta e concordaram com seus termos.
Arquitetura prática para personalização segura em termos de consentimento:
- Sinais comportamentais de primeira parte: nenhum consentimento adicional necessário além dos seus termos de serviço
- Personalização de e-mail de marketing usando atributos declarados (função, empresa): coberto pelo consentimento de opt-in de e-mail
- Personalização entre canais combinando dados de produto com plataformas de publicidade: requer consentimento explícito com opções granulares de opt-in, não uma caixa de seleção enterrada
Tratar opt-out sem degradar a experiência: quando um usuário opta por não receber personalização, sirva-lhes uma experiência padrão bem projetada, não uma quebrada. Cuide de um feed padrão sólido. Não puna usuários que preferem não ser rastreados mostrando-lhes uma versão obviamente inferior do produto.
Sinais de ROI
| Métrica | O que ela diz |
|---|---|
| Taxa de conversão por coorte de personalização | Personalizado versus broadcast, mesmo produto, mesmo período de tempo. Este é o caso de negócio central. |
| Cliques de e-mail: personalizado versus broadcast | Comparação direta da mesma campanha com e sem personalização. |
| Receita por usuário por nível de personalização | O investimento do modelo em personalização profunda se paga em receita por conta? |
| Adoção de funcionalidades para usuários nudgeados versus não nudgeados | Para personalização no produto, a exibição de uma recomendação de funcionalidade impulsiona a ativação? |
| Latência do loop de feedback | Quanto tempo leva para um sinal de resultado chegar ao modelo e influenciar a próxima recomendação? Menor é melhor. |
| Pontuação de diversidade de recomendações | Que porcentagem de recomendações vem de categorias com as quais o usuário ainda não se engajou? Rastreia o risco de filter bubble. |
O que vem a seguir
O Personalization Engine é frequentemente o primeiro padrão de AI que equipes voltadas ao consumidor implantam. Mas raramente funciona isolado. O blueprint de tecnologia de personalização da McKinsey identifica que o padrão completo requer orquestrar quatro capacidades: coleta de dados, tomada de decisão impulsionada por AI, design de conteúdo e distribuição, cada uma das quais mapeia diretamente para a cadeia Ingest Analyze Generate Execute no ACE Framework.
Para detecção de anomalias comportamentais (o usuário que de repente muda de padrões de uma forma que indica churn ou fraude), o padrão Anomaly Agent é o complemento. Combine o Personalization Engine com o Anomaly Agent e você tem um sistema que não apenas mostra o conteúdo certo para cada usuário, mas também captura quando o comportamento de um usuário muda de formas que requerem intervenção diferente: uma ligação de verificação de saúde do customer success, ou uma sinalização para a equipe de fraude.
Quando estiver pronto para combinar múltiplos padrões em um sistema de AI de nível de função, o artigo Empilhando Padrões para Construir AI Agents aborda como os padrões se somam. Um AI Marketer, por exemplo, combina o Personalization Engine com o Generative Research, o Meeting Intelligence e o Predict, cada um tratando de uma fase diferente do ciclo da campanha.
Rework Analysis: A falha do Personalization Engine que vemos com mais frequência é um sistema sem loop de feedback fechado. O modelo executa suas primeiras previsões no lançamento com base em função e preferências declaradas, e então ninguém conecta dados de resultado de volta ao modelo. Seis meses depois, as recomendações ainda são baseadas em dados de cadastro de usuários que desde então mudaram de função, ativaram funcionalidades diferentes e passaram por vários estágios de seu ciclo de vida como clientes. O modelo está personalizando para usuários que não existem mais. Fechar o loop não é uma reflexão técnica tardia: requer definir qual sinal de resultado o modelo treina (clique, ativação, retenção, receita), construir o pipeline que rota esse sinal de volta ao modelo e definir uma cadência de retreinamento. Equipes que fazem isso no lançamento veem a elevação de receita de 40% que a McKinsey mede. Equipes que pulam isso veem personalização que tem desempenho marginalmente melhor do que broadcast e uma conversa de orçamento seis meses depois.
Perguntas Frequentes
O que é um padrão de AI Personalization Engine?
O Personalization Engine é um padrão de AI que entrega conteúdo, ofertas ou experiências diferentes para usuários diferentes com base em sinais comportamentais. A fórmula é: Ingest (sinais de comportamento do usuário), Analyze (construir ou atualizar perfil do usuário), Predict (preferências, próxima melhor ação ou conteúdo relevante), Generate (conteúdo ou oferta personalizada), Execute (entregar no momento certo). Difere da segmentação porque atualiza perfis de usuário continuamente e toma decisões de conteúdo por usuário em vez de por segmento.
O que é o Loop de Relevância em Tempo Real?
O Loop de Relevância em Tempo Real é o mecanismo central do Personalization Engine: sinais comportamentais atualizam o perfil do usuário, o perfil atualizado impulsiona uma nova previsão, a previsão gera conteúdo personalizado, o conteúdo é entregue e a resposta do usuário se torna o próximo sinal comportamental. Este loop fechado é o que distingue o Personalization Engine da segmentação estática. Um modelo sem loop fechado é segmentação estática com rotulagem de AI. Um modelo com loop fechado melhora a precisão da previsão a cada interação.
Qual impacto de receita a personalização entrega?
Empresas que se destacam em personalização geram 40% mais receita a partir dela do que pares de crescimento mais lento, com a lacuna impulsionada por feedback de loop fechado (McKinsey, 2021). Campanhas de e-mail personalizadas que usam sinais comportamentais alcançam taxas de cliques de 5-12% versus 1% para e-mails de broadcast (Salesforce, 2025). Equipes de produto B2B que usam personalização de onboarding específica para função veem melhoria de 25-40% nas taxas de ativação de funcionalidades em 30 dias versus fluxos genéricos (Amplitude, 2025).
O que é o problema de filter bubble na personalização?
O filter bubble ocorre quando o modelo de recomendação mostra apenas conteúdo de categorias com as quais o usuário já se engajou, fazendo-o parar de descobrir novas opções. A Netflix descobriu que quando a cota de diversidade não era ativamente mantida, o engajamento com novos títulos caiu 23% em 6 meses à medida que os usuários entravam em loops cada vez mais estreitos. A mitigação é uma cota de diversidade: 10-20% das recomendações retiradas de categorias adjacentes em vez de preferências confirmadas, mantendo a descoberta sem comprometer a relevância.
Quais requisitos de privacidade de dados se aplicam ao Personalization Engine?
Três categorias de sinais requerem consentimento explícito do usuário sob LGPD, GDPR, CCPA e PIPEDA: rastreamento entre sites (cookies seguindo usuários em domínios diferentes), dados de categorias sensíveis (saúde, financeiros, políticos, localização com precisão) e combinação de identificadores para vincular comportamento online à identidade offline. Sinais comportamentais de primeira parte dentro do seu próprio produto não requerem consentimento adicional além dos termos de serviço. Personalização de e-mail de marketing usando atributos declarados é coberta pelo consentimento de opt-in de e-mail. Personalização entre canais combinando dados de produto com plataformas de publicidade requer opt-in explícito e granular.
Quando você deve usar o Personalization Engine versus o Workflow Copilot?
O Personalization Engine ajusta o ambiente ao redor do usuário, mudando que conteúdo, produtos ou opções são visíveis antes de o usuário iniciar uma tarefa específica. O Workflow Copilot auxilia o usuário dentro de uma tarefa ativa, sugerindo próximas ações dentro do trabalho já em andamento. A distinção é ao redor da tarefa versus dentro da tarefa. Use o Personalization Engine para feeds de conteúdo, campanhas de e-mail, recomendações de produto e fluxos de onboarding. Use o Workflow Copilot para rascunho, programação, relatórios e trabalho de CRM onde o usuário precisa de assistência no ponto de ação.
Saiba mais
- Anomaly Agent: Detectando o Inesperado
- Empilhando Padrões para Construir AI Agents
- O Gradiente de Risco entre os Padrões de AI
- Escolhendo o Padrão de AI Certo para Seu Problema
- Scoring and Routing: Triagem em Escala
- O Que é AI para Negócios? Uma Definição Prática para Operadores
- McKinsey: The Value of Getting Personalization Right
- McKinsey: A Technology Blueprint for Personalization at Scale

Co-Founder, Rework.com
On this page
- A fórmula
- O Loop de Relevância em Tempo Real
- O problema de negócio que resolve
- Cinco exemplos reais em profundidade
- Recomendações de produtos em e-commerce
- Conteúdo dinâmico em campanhas de e-mail
- Nudges de onboarding no produto
- Personalização de preços B2B
- Recomendações de trilhas de aprendizado em LMS
- Quando o Personalization Engine funciona bem
- Modos de falha
- Quando escolher o Personalization Engine versus alternativas
- Arquitetura de privacidade e consentimento
- Sinais de ROI
- O que vem a seguir
- Saiba mais