Autonomous Agent: Objetivos de Múltiples Pasos con Uso de Herramientas
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Todos los demás patrones manejan una tarea única y definida. El Autonomous Agent maneja un objetivo.
Esa diferencia lo es todo.
Una tarea tiene una entrada definida y una salida definida. Resumir esta reunión. Puntuar este lead. Redactar este correo. El camino es claro. Una pasada por la cadena de capacidades, listo.
Un objetivo es diferente. "Investigar esta cuenta y conseguir una reunión reservada" requiere una serie de decisiones: qué fuentes leer, qué señales importan, cómo enmarcar el alcance, qué hacer cuando el prospecto rebota el correo, cuándo detenerse. El agente no puede conocer el camino de antemano porque el camino depende de lo que encuentre en el proceso.
Eso es lo que hace que los agentes autónomos sean poderosos. Y es exactamente lo que los hace peligrosos cuando el objetivo está mal especificado, las herramientas están mal configuradas o la detección de errores es débil.
Este artículo no exagera los agentes autónomos. Explica qué son, dónde funcionan, qué sale mal y cómo gobernarlos si decide desplegarlos. La guía práctica de OpenAI para construir agentes recomienda comenzar con un solo agente y evolucionar a sistemas multiagente solo cuando sea necesario, priorizando casos de uso con toma de decisiones complejas, datos no estructurados y reglas difíciles de mantener.
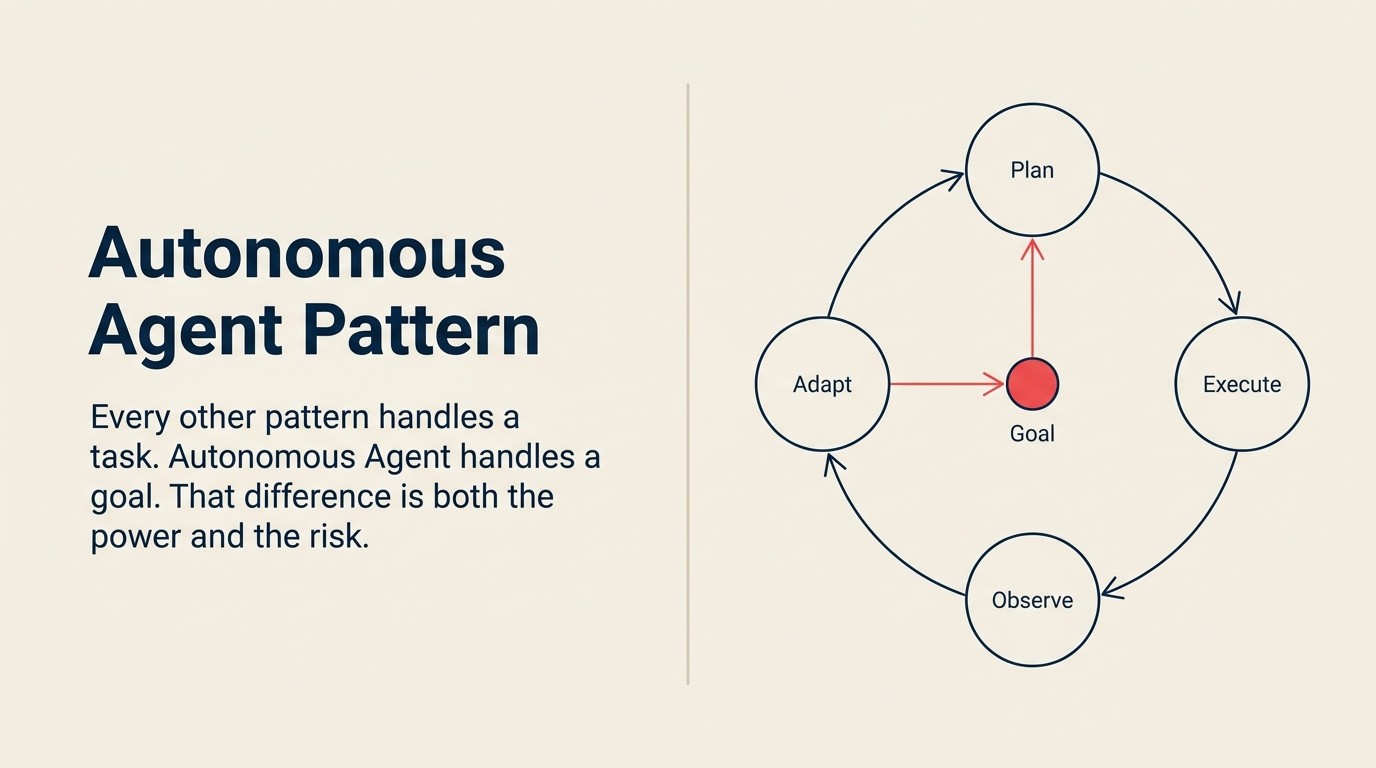
La fórmula
Autonomous Agent es el único patrón que usa las cinco capacidades ACE en un bucle:
Ingest (estado actual + herramientas disponibles) → Analyze (¿qué sé, qué necesito?) → Predict (¿qué acción tiene más probabilidad de avanzar hacia el objetivo?) → Generate (un plan o próxima acción) → Execute (tomar la acción, actualizar el estado) → repetir hasta que el objetivo se logre o se alcance el número máximo de pasos
Cada elemento del bucle tiene un significado específico:
Ingest no es solo leer la tarea inicial. En cada iteración del bucle, el agente ingesta el estado actual del mundo. ¿Qué produjo la última acción? ¿Qué herramientas están disponibles? ¿Qué ha aprendido el agente desde que comenzó el bucle? En un agente de investigación, Ingest en la iteración 3 incluye el contenido de las dos páginas ya leídas, las consultas que devolvieron resultados vacíos y el hecho de que la empresa objetivo cambió su nombre hace 8 meses.
Analyze determina qué sabe el agente y qué aún necesita para lograr el objetivo. Es un análisis de brechas continuo: aquí está lo que tengo, aquí está lo que necesito, aquí está lo que aún falta. Aquí es donde el agente decide si continuar hacia el sub-objetivo actual o pivotar a un camino diferente.
Predict selecciona la siguiente acción más probable para avanzar hacia el objetivo. No todas las acciones posibles. La que tiene más probabilidad de cerrar la brecha. En un agente de soporte que resuelve una disputa de facturación, Predict puede determinar que buscar el historial de transacciones en el sistema de pago es el siguiente paso de mayor valor, en lugar de leer el historial completo de tickets del cliente.
Generate produce el plan de acción o la próxima acción específica. Puede ser una especificación de llamada a herramienta ("buscar en la web 'ronda de financiación de Acme Corp 2024'"), un borrador de mensaje ("aquí está la respuesta que enviaré para cerrar el ticket") o una descomposición de sub-objetivos ("necesito completar estas 3 cosas antes de poder lograr el objetivo principal").
Execute ejecuta la acción. Este es el paso que cambia el estado en el mundo. Envía una solicitud a una API de búsqueda. Crea un registro en el CRM. Emite un reembolso. Ejecuta una suite de pruebas. Cada paso Execute es una acción real con consecuencias reales. A diferencia de los patrones de tarea única donde Execute se activa una vez al final, los agentes autónomos ejecutan Execute múltiples veces por ejecución, potencialmente docenas de veces en objetivos complejos. La profundización en la capacidad Execute y el límite entre Generate y Execute son los artículos de referencia del Marco ACE más relevantes para entender por qué esto importa.
El bucle termina cuando se cumple una de tres condiciones: el objetivo se logra, se alcanza el número máximo de pasos, o un umbral de confianza cae por debajo de un mínimo definido y el sistema transfiere el trabajo a un humano.
El "número máximo de pasos" no es opcional. Es un límite de seguridad rígido. Los agentes sin un techo de pasos pueden hacer bucles indefinidamente en objetivos que no pueden lograr con las herramientas disponibles.
Key Facts: Adopción y Riesgo de los Autonomous Agents
- El 23% de las organizaciones está escalando activamente sistemas de IA agéntica, y el 39% ha comenzado a experimentar, pero menos del 10% de los que experimentan han escalado agentes para entregar valor de negocio tangible, principalmente debido a brechas en gobernanza y gestión de failure modes (McKinsey State of AI, 2025)
- El 80% de las organizaciones ha encontrado comportamiento riesgoso o inesperado de agentes de IA, con casi cada incidente rastreable a un paso Execute que se activó en un bucle sin validación adecuada o restricciones de alcance (McKinsey Agentic AI Risk Study, 2025)
- Los agentes autónomos que incluyen revisión previa a la ejecución, compuertas intermedias para acciones de alto riesgo y trazas de auditoría post-ejecución reducen las tasas de error de acciones irreversibles en un 73% en comparación con los agentes desplegados sin estos puntos de control (Anthropic Agent Safety Research, 2025)
El problema de negocio que resuelve
Autonomous Agent es el patrón correcto para un tipo específico de problema: un objetivo de múltiples pasos que requiere uso de herramientas, decisiones condicionales y retroceso, y donde la aprobación humana en cada paso intermedio dejaría sin sentido el propósito.
Los casos operativos que realmente justifican este patrón:
- Investigación y síntesis a través de múltiples fuentes donde el número de fuentes no es predecible de antemano
- Ejecución de procesos de extremo a extremo que abarcan múltiples sistemas (CRM + calendario + correo + procesador de pagos) y requieren decisiones basadas en lo que devuelve cada sistema
- Trabajo de refinamiento iterativo como código donde el bucle es: escribir, probar, leer el fallo, revisar, probar de nuevo
- Tareas estructuradas de alto volumen donde el human-in-the-loop en cada paso es operativamente imposible
Lo que este patrón no es: una forma de automatizar cualquier flujo de trabajo de múltiples pasos. Los flujos de trabajo con pasos fijos y predecibles no necesitan un agente autónomo. El patrón Scoring + Routing los maneja. Los flujos de trabajo donde el juicio humano importa en cada paso necesitan un Workflow Copilot. Los agentes autónomos son para el caso específico donde el camino es genuinamente impredecible y la participación humana en cada paso es impráctica.
Cuatro ejemplos reales en profundidad

Agente de investigación
Herramientas disponibles: API de búsqueda web, lector de URL, parser de documentos, extractor de citas.
Objetivo: "Producir un briefing sobre la posición competitiva de ACME Corp, incluyendo financiación reciente, lanzamientos de productos y cambios clave de ejecutivos, para una llamada de ventas el próximo jueves."
Mecánica del bucle: El agente busca noticias recientes (Ingest), identifica cuáles resultados son relevantes (Analyze), predice qué fuente leer a continuación según las brechas de información (Predict), llama al lector de URL en la fuente principal (Execute), extrae hechos relevantes (Ingest el resultado), actualiza su documento de trabajo (Generate + Execute) y repite hasta que tenga suficiente señal o se agoten las fuentes de alta confianza.
Cómo luce el éxito: Un documento de briefing estructurado con secciones, citas y puntos clave de conversación. El agente envía el documento y termina.
Cómo luce el fallo: El agente lee un comunicado de prensa que contiene información desactualizada (un CEO que salió hace 6 meses todavía aparece listado). El agente incluye esto en el briefing. El representante de ventas entra a la llamada dirigiéndose al contacto ejecutivo incorrecto. En un escenario solo de investigación, esto es un error de calidad. Si el agente también envió un correo personalizado a ese contacto (creep de alcance), se convierte en un error en la relación con el cliente.
Agente de soporte al cliente
Herramientas disponibles: Lector de tickets del helpdesk, búsqueda en CRM, API de historial de pedidos, API de reembolso del procesador de pagos, herramienta para cerrar tickets, herramienta para enviar correos.
Objetivo: "Resolver disputas de facturación abiertas por debajo de $200 de extremo a extremo sin participación humana."
Mecánica del bucle: El agente lee el ticket (Ingest), consulta el historial de pedidos para verificar el reclamo (Execute + Ingest), verifica el estado de la cuenta en el CRM y el historial previo de disputas (Execute + Ingest), determina el camino de resolución (Analyze + Predict), emite el reembolso (Execute) o marca para revisión humana si no se cumplen las condiciones de la política, cierra el ticket (Execute), envía un correo de confirmación (Execute).
Cómo luce el éxito: Disputa resuelta, reembolso emitido, ticket cerrado, confirmación enviada. El cliente recibe el resultado en minutos en lugar de días.
Cómo luce el fallo: Un actor malicioso envía 40 tickets de disputa casi idénticos durante 3 horas. Cada ticket cumple con el umbral de menos de $200. El agente procesa los 40 antes de que cualquier detección de patrones active una alerta humana. $8,000 salen de la cuenta. Este es un failure mode real en los despliegues de agentes de soporte en producción. La mitigación es una verificación de limitación de velocidad (máximo 5 resoluciones por cuenta por 24 horas) incorporada en las restricciones de alcance, no agregada como algo secundario.
Agente de desarrollo de ventas
Herramientas disponibles: Búsqueda web, lector de LinkedIn, lectura/escritura en CRM, compositor de correos, creador de tareas en calendario.
Objetivo: "Investigar las 20 empresas en esta lista objetivo, puntuar cada una contra nuestros criterios de ICP, redactar alcance personalizado para las que estén sobre el umbral, agregarlas al CRM y programar tareas de seguimiento."
Mecánica del bucle: Para cada empresa, el agente busca datos firmográficos (Ingest), puntúa contra los criterios de ICP (Analyze + Predict), redacta alcance personalizado para las que están sobre el umbral (Generate), crea o actualiza el registro en el CRM (Execute), crea una tarea de seguimiento (Execute). El bucle se repite para las 20 empresas.
Cómo luce el éxito: CRM actualizado con 20 cuentas puntuadas y clasificadas. Las cuentas calificadas tienen borradores de alcance esperando la revisión del representante. Tareas programadas. Resumen de investigación adjunto a cada registro.
Cómo luce el fallo: El agente investiga una empresa y encuentra un anuncio de adquisición reciente. La empresa fue comprada por un competidor. El agente sigue puntuando a la empresa como un prospecto de alto ajuste y redacta un alcance dirigido al CEO original, quien ahora está en la empresa adquirente. El representante envía el correo redactado por IA sin revisarlo. Vergüenza como mínimo, daño reputacional si el adquirente lo nota.
El control correcto: el agente marca "cambio de propiedad detectado" como una condición que pausa el bucle y lo muestra a un humano para revisión, en lugar de proceder automáticamente.
Agente de código
Herramientas disponibles: Lector/escritor del sistema de archivos, ejecutor de pruebas, linter de código, creador de pull requests en GitHub.
Objetivo: "Corregir la prueba fallida en el módulo de checkout. La prueba es checkout_test.go:línea 78. No romper otras pruebas."
Mecánica del bucle: El agente lee la prueba fallida para entender qué espera (Ingest), lee el código fuente relevante (Ingest), analiza la brecha entre el comportamiento esperado y el real (Analyze), propone un cambio de código (Generate), escribe el cambio en el archivo (Execute), ejecuta la suite de pruebas (Execute + Ingest), lee el nuevo resultado de las pruebas (Analyze), decide si la corrección funcionó o requiere revisión (Predict). Hace bucles hasta que las pruebas pasan o se alcanzan los intentos máximos de revisión.
Cómo luce el éxito: La prueba pasa. Sin regresión en otras pruebas. PR abierto para revisión humana antes del merge.
Cómo luce el fallo: La corrección del agente hace que la prueba originalmente fallida pase, pero introduce una regresión sutil en las pruebas del flujo de pago, que están en un módulo separado que no verificó. Si el agente tiene permiso para hacer auto-merge en pruebas verdes, y la suite de pruebas no cubre la regresión de pago, el cambio va a producción.
El control correcto: el auto-merge no está en el alcance. El agente abre un PR. Un humano revisa y hace el merge. El agente maneja el bucle iterativo de corrección de código. El humano toma la decisión de despliegue.
La Regla Auditar-O-Bloquear
Cada despliegue de Autonomous Agent debe implementar dos controles innegociables antes de la primera ejecución en producción: una traza de auditoría que registre cada paso de Ingest, Analyze, Predict, Generate y Execute con marcas de tiempo y el razonamiento declarado del agente, y una condición de bloqueo que termine el bucle y escale a un humano cuando la confianza caiga por debajo de un umbral definido o cuando una acción irreversible de alto riesgo esté pendiente. La Regla Auditar-O-Bloquear establece que si un agente no puede producir una traza de decisión completa (auditoría) para cualquier acción que haya tomado, no debe tomar esa acción de forma autónoma (bloquear). Estos dos controles convierten un bucle autónomo potencialmente incontrolable en un sistema supervisado donde cada error es diagnosticable y la mayoría de los errores son prevenibles. Los agentes desplegados sin ambos controles deben clasificarse como experimentales, no como de producción.
Por qué los agentes autónomos son el patrón de mayor riesgo

Todos los demás patrones del Marco ACE ejecutan como máximo un paso Execute. Los agentes autónomos ejecutan múltiples pasos Execute en un bucle. Cada paso es un incidente potencial.
El riesgo se compone de maneras que importan:
Un error temprano de Analyze (malinterpretar el contexto en la iteración 1 del bucle) produce un error de Generate (acción siguiente incorrecta). Esa acción incorrecta se convierte en un paso Execute que cambia el estado en el mundo real. La siguiente iteración del bucle ahora comienza desde un estado corrupto. Las acciones posteriores del agente se optimizan todas desde una línea base incorrecta. Para cuando un humano revisa la salida o recibe una alerta, el daño es de múltiples pasos e interdependiente.
Esta dinámica de composición es por qué todos los problemas de gobernanza en el Marco ACE alcanzan su punto máximo en el patrón Autonomous Agent. Las trazas de auditoría, las restricciones de alcance, la limitación de velocidad, la capacidad de reversión y los puntos de control humanos no son sobrecarga burocrática. Son los requisitos arquitectónicos que hacen que el patrón sea desplegable en sistemas que importan.
La investigación de gobernanza de IA de Gartner de 2025 encontró que las empresas que ejecutan agentes autónomos sin restricciones de alcance tienen 8 veces más probabilidad de experimentar un incidente de IA significativo (definido como causar daño financiero, reputacional o al cliente medible) que las empresas que implementan la pila de gobernanza completa antes del lanzamiento en producción. La Política de Escala Responsable de Anthropic identifica los niveles intermedios de autonomía del modelo como puntos de control críticos que requieren evaluación adicional y salvaguardas más sólidas, precisamente el principio de diseño detrás de los niveles de gobernanza en este marco. Requisitos de gobernanza por patrón de IA proporciona la especificación completa para cada nivel.
Failure modes y mitigaciones
Especificación incorrecta del objetivo. El failure mode más común. El humano dio al agente un objetivo que era claro para el humano pero ambiguo para el sistema. "Cierra este ticket de soporte" significa resolver el problema del cliente para un humano, pero significa "establecer el estado del ticket como cerrado" para un agente sin contexto explícito sobre la calidad de la resolución. Solución: escribir los objetivos como descripciones de resultados con criterios de completación explícitos. No "cerrar el ticket" sino "cerrar el ticket solo después de confirmar que el problema original del cliente está resuelto, con evidencia del sistema de pago que confirme que el reembolso fue emitido". Use plantillas de objetivos estructuradas cuando sea posible.
Llamadas a herramientas alucinadas. El agente llama a una herramienta que no existe, usa una herramienta con tipos de parámetros incorrectos o interpreta las capacidades de una herramienta más allá de lo que realmente puede hacer. En los despliegues de producción, esto aparece como errores de API que el agente no sabe cómo manejar. Solución: mantener un registro estricto de herramientas con descripciones de esquema explícitas para cada herramienta. Probar el agente contra cada herramienta de forma aislada antes de desplegar el bucle completo. Construir una rama de manejo de errores que muestre los fallos inesperados de herramientas a un humano en lugar de dejar que el agente reintente indefinidamente.
Bucles infinitos. El agente persigue un objetivo que es inalcanzable con las herramientas disponibles, y reintenta en un bucle en lugar de reconocer el callejón sin salida. Un agente de búsqueda al que se le pide encontrar documentos internos que no existen seguirá reformulando consultas de búsqueda sin converger. Solución: techo de pasos rígido con escalación obligatoria. Si el agente no ha logrado un progreso medible hacia el objetivo dentro de N pasos, la ejecución termina y el trabajo se transfiere a un humano con un resumen de lo que intentó el agente. Establezca N de forma conservadora según la complejidad de la tarea.
Creep de alcance. El agente toma acciones fuera del alcance previsto porque parecían útiles para el objetivo. Un agente de investigación con acceso a un escritor de archivos podría decidir crear una versión "mejor organizada" de los archivos de investigación existentes en el camino a completar su tarea principal. Parecía eficiente. El usuario no lo autorizó. Solución: restricciones de alcance explícitas como parte de cada configuración de agente. Herramientas autorizadas. Tipos de acción autorizados dentro de cada herramienta. Sin permiso implícito para actuar en tareas adyacentes. Las violaciones de alcance deben terminar la ejecución y alertar al usuario configurador, no continuar.
Errores en cascada. Un paso incorrecto temprano corrompe el estado del que dependen todos los pasos posteriores. El agente investiga una empresa e identifica la subsidiaria incorrecta. Cada acción posterior (alcance redactado, registro de CRM creado, seguimiento programado) es ahora para la entidad incorrecta. Solución: construir puntos de control de verificación para acciones que cambian el estado. Antes de escribir un registro en el CRM, confirme la coincidencia de la empresa contra al menos dos fuentes. Antes de ejecutar una acción irreversible (enviar correo, emitir reembolso), registre la traza de razonamiento y marque para revisión humana si la confianza está por debajo del umbral.
Escalación de permisos. El agente solicita acceso a herramientas o fuentes de datos adicionales que no estaban en su alcance original porque las herramientas actuales son insuficientes para lograr el objetivo. En sistemas mal configurados, un agente podría adquirir con éxito estos permisos. Solución: las herramientas disponibles para un agente son estáticas y revisadas antes del despliegue. Sin expansión de permisos en tiempo de ejecución. Si el agente necesita herramientas adicionales, la ejecución debe terminar con una señal de "herramientas insuficientes" y un humano toma la decisión de configuración.
Cuándo elegir Autonomous Agent vs. alternativas
La mayoría de las tareas que parecen problemas de agente autónomo son en realidad patrones más simples disfrazados. Vale la pena hacerse esta pregunta honestamente antes de comprometerse con la complejidad y la inversión en gobernanza.
Cuándo Workflow Copilot es suficiente: Si un humano puede estar en el bucle en cada punto de decisión significativo sin un retraso inaceptable, use Workflow Copilot en su lugar. Copilot es más rápido de desplegar, más fácil de gobernar y tiene una superficie de fallo mucho menor. El usuario sigue siendo responsable. La IA proporciona apalancamiento sin eliminar el juicio humano del bucle.
Cuándo Scoring + Routing es suficiente: Si la tarea tiene un solo punto de decisión (clasificar un elemento entrante y enrutarlo), no muchos, Scoring + Routing lo maneja. Muchos casos de uso de "agente" para soporte al cliente son en realidad patrones de Scoring + Routing: clasificar el ticket, asignarlo a la cola correcta, mostrar los artículos relevantes de la base de conocimiento. Son tres pasos de capacidad, no un bucle dirigido por objetivos.
Cuándo Generative Research es suficiente: Si la salida es un documento en lugar de una serie de acciones, Generative Research es el patrón correcto. La síntesis de múltiples fuentes en un informe no requiere pasos Execute en cada iteración del bucle. Requiere Ingest de muchas fuentes, Analyze a través de ellas y Generate para la salida.
La señal de que genuinamente necesita Autonomous Agent: el objetivo requiere más de 3 pasos Execute secuenciales, y la aprobación humana en cada paso no es operativamente práctica, y la tarea tiene una ramificación condicional genuina donde el camino depende de lo que producen los pasos anteriores.
Diseño del human-in-the-loop a nivel de agente

Los puntos de control no son una concesión a la precaución. Son un requisito arquitectónico para cualquier agente autónomo que toque sistemas orientados al cliente, acciones irreversibles o decisiones de alto valor.
Cómo luce un buen diseño de puntos de control:
Revisión previa a la ejecución: Antes de que el agente comience, un humano revisa la especificación del objetivo, las herramientas autorizadas y las restricciones de alcance. Este es el momento de detectar objetivos mal especificados antes de que se tomen acciones.
Compuertas intermedias para Execute de alto riesgo: Defina categorías de acción que paausen el bucle y lo muestren a un humano antes de proceder. Enviar comunicaciones orientadas al cliente. Emitir transacciones financieras por encima de un umbral. Eliminar registros. Actualizar registros que afecten deals activos. El bucle continúa después de la aprobación; no se reinicia.
Transferencia por mínimo de confianza: Cuando la confianza del agente en su próxima acción cae por debajo de un umbral definido (por ejemplo, señales en conflicto de dos fuentes que no se pueden reconciliar automáticamente), la ejecución se pausa y el agente escribe una nota de transferencia: "He llegado hasta aquí, esto es lo que encontré, aquí está por qué estoy incierto, esto es lo que necesita decidir". El humano resuelve la incertidumbre y el agente puede continuar o el humano completa la tarea.
Auditoría post-ejecución: Cada ejecución de un agente autónomo debe producir una traza de decisión completa: qué ingesto el agente en cada paso, qué analizó, qué generó, qué ejecutó, con marcas de tiempo. Esa traza es la única manera de entender qué sucedió cuando algo sale mal. Retención mínima de 90 días. Interfaz de auditoría accesible por humanos.
El requisito de gobernanza no es opcional. Cualquier agente autónomo desplegado sin trazas de auditoría, restricciones de alcance y rutas de escalación es una responsabilidad esperando surgir. La infraestructura de auditoría es parte del despliegue, no una mejora agregada después. El Marco de Gestión de Riesgos de IA del NIST identifica la gobernanza, el mapeo, la medición y la gestión como las cuatro funciones centrales del despliegue responsable de IA, todas las cuales aplican en cada punto de control en el bucle de ejecución de un agente autónomo.
Señales de ROI
| Métrica | Qué le dice |
|---|---|
| Tasa de completación de tareas vs. baseline humano | ¿Completa el agente la tarea de extremo a extremo al mismo nivel de calidad que lo haría un humano? |
| Tasa de adherencia al alcance | ¿Qué porcentaje de ejecuciones permanece dentro del alcance autorizado de herramientas y acciones? |
| Ratio error-a-escalación | De los errores que comete el agente, ¿qué porcentaje es detectado por los mecanismos de escalación antes de causar impacto externo? |
| Horas de esfuerzo humano desplazadas por semana | Tiempo neto ahorrado. Para que esto sea positivo, tenga en cuenta el tiempo dedicado a revisar ejecuciones del agente y gestionar escalaciones. |
| Iteraciones de bucle promedio por tarea completada | Un número creciente en un tipo de objetivo estable sugiere que el agente se está volviendo menos eficiente, posiblemente debido a deriva del contexto o degradación de herramientas. |
| Tasa de error en acciones irreversibles | ¿Con qué frecuencia toma el agente una acción irreversible que resulta ser incorrecta? Esto debería estar cerca de cero y es la métrica de seguridad más importante. |
Qué viene después
El patrón Autonomous Agent es la puerta de entrada a los AI Agents de Nivel 3, los flujos de trabajo a nivel de rol que cubren una función de trabajo completa en lugar de una sola tarea. Un AI Support Agent no es una única instancia de agente autónomo. Es un clúster de patrones: RAG Assistant para la búsqueda de políticas, Scoring + Routing para el triaje, Anomaly Agent para la detección de fraude, Workflow Copilot para la asistencia humano-agente en tickets complejos. El bucle autónomo maneja los casos de resolución estructurada; los otros patrones manejan el resto.
Entender cómo combinar patrones a este nivel es el siguiente paso. Combinando Patrones para Construir AI Agents cubre la lógica de combinación y recorre un ejemplo trabajado de un AI Sales Operator construido a partir de cuatro patrones.
Los requisitos de gobernanza que aplican con más intensidad al Autonomous Agent aplican a todas las pilas de patrones complejos. El artículo de requisitos de gobernanza cubre las especificaciones de trazas de auditoría, restricciones de alcance y compuertas de aprobación con detalle operativo.
Rework Analysis: Los despliegues de agentes autónomos que fracasan más rápido son los que trataron "desplegar" y "gobernar" como pasos secuenciales. Desplegar el agente, ver qué sucede, agregar gobernanza después. Pero la gobernanza para los agentes autónomos no es un complemento. Es la infraestructura que hace que el agente sea seguro de ejecutar. Las restricciones de alcance, las trazas de auditoría y las condiciones de escalación deben existir antes del primer bucle en producción. No se pueden retroalimentar después del primer incidente grave sin reconstruir la confianza en todo el programa. Los equipos que aciertan con los agentes autónomos tratan la fase de diseño de gobernanza como el trabajo de ingeniería más importante del proyecto, pasan más tiempo especificando lo que el agente no tiene permitido hacer que lo que sí tiene permitido hacer, y despliegan con un techo de pasos conservador que solo elevan a medida que se acumulan datos de producción. El 10% de las organizaciones que escalan exitosamente la IA agéntica no son técnicamente más sofisticadas que el otro 90%. Son más disciplinadas con la gobernanza antes del lanzamiento.
Preguntas Frecuentes
¿Qué es el patrón de IA Autonomous Agent?
Un Autonomous Agent es un patrón de IA que usa las cinco capacidades ACE en un bucle para perseguir un objetivo de múltiples pasos con uso de herramientas, decisiones condicionales y retroceso. La fórmula cicla: Ingest (estado actual más herramientas disponibles), Analyze (análisis de brechas), Predict (acción siguiente más probable), Generate (plan de acción), Execute (tomar la acción, actualizar el estado), repetir hasta que el objetivo se logre o se alcancen los pasos máximos. Se diferencia de todos los demás patrones en que Execute se activa múltiples veces por ejecución, y cada paso Execute potencialmente cambia el estado externo.
¿Qué es la Regla Auditar-O-Bloquear?
La Regla Auditar-O-Bloquear establece que cada agente autónomo debe implementar dos controles innegociables: una traza de auditoría que registre cada paso de capacidad con marcas de tiempo y razonamiento declarado, y una condición de bloqueo que termine el bucle y escale a un humano cuando la confianza cae por debajo del umbral o cuando una acción irreversible de alto riesgo está pendiente. Si un agente no puede producir una traza de decisión completa para cualquier acción, no debe tomar esa acción de forma autónoma. Estos dos controles convierten un bucle incontrolable en un sistema supervisado donde los errores son diagnosticables y la mayoría son prevenibles.
¿Por qué se consideran los agentes autónomos el patrón de IA de mayor riesgo?
Porque Execute se activa múltiples veces por ejecución en un bucle, y los errores se componen a través de los pasos. Un error temprano de Analyze produce una salida incorrecta de Generate, que se convierte en un paso Execute que corrompe el estado. Todas las iteraciones posteriores del bucle se optimizan desde una línea base incorrecta. Para cuando un humano revisa la salida, el daño es de múltiples pasos e interdependiente. McKinsey encontró que el 80% de las organizaciones han encontrado comportamiento riesgoso de agentes, casi todo rastreable a pasos Execute en bucles sin validación adecuada. Gartner encontró que las empresas sin restricciones de alcance tienen 8 veces más probabilidad de experimentar un incidente de IA significativo.
¿Qué controles de gobernanza se requieren para los agentes autónomos?
Se requieren cuatro controles antes del lanzamiento en producción: revisión previa a la ejecución (el humano revisa la especificación del objetivo, las herramientas autorizadas y las restricciones de alcance antes de la primera ejecución), compuertas intermedias para pasos Execute de alto riesgo (el bucle se pausa antes de enviar comunicaciones orientadas al cliente, emitir transacciones financieras o eliminar registros), transferencia por mínimo de confianza (el bucle se pausa cuando la confianza del agente cae por debajo del umbral y produce una nota de transferencia) y auditoría post-ejecución (traza de decisión completa con retención mínima de 90 días). Las organizaciones que implementan los cuatro reducen las tasas de error de acciones irreversibles en un 73% versus los agentes sin estos puntos de control (Anthropic, 2025).
¿Cuándo debería usar Autonomous Agent en lugar de Workflow Copilot?
Use Autonomous Agent solo cuando el objetivo requiera más de tres pasos Execute secuenciales, la aprobación humana en cada paso sea operativamente impráctica y la tarea tenga una ramificación condicional genuina donde el camino depende de lo que producen los pasos anteriores. Si un humano puede estar en el bucle en cada punto de decisión significativo sin un retraso inaceptable, Workflow Copilot es más seguro, más rápido de desplegar y tiene una superficie de fallo mucho menor. La mayoría de las tareas que parecen problemas de agente autónomo son en realidad patrones más simples: Scoring + Routing para triaje de decisión única, Generative Research para síntesis de múltiples fuentes, Workflow Copilot para trabajo del conocimiento que requiere juicio.
¿Cuál es el failure mode más común de los agentes autónomos?
La especificación incorrecta del objetivo es el failure mode más común. La intención del humano era clara para el humano pero ambigua para el sistema. "Cierra este ticket" significa "confirmar que el problema está resuelto" para un humano, pero puede significar "establecer el estado como cerrado" para un agente. La mitigación es escribir objetivos como descripciones de resultados con criterios de completación explícitos: "cerrar el ticket solo después de confirmar que el problema original del cliente está resuelto, con evidencia del sistema de pago que confirme que el reembolso fue emitido". Las plantillas de objetivos estructuradas que requieren condiciones de completación nombradas y límites de alcance reducen dramáticamente la especificación incorrecta de objetivos.
Más información
- Combinando Patrones para Construir AI Agents
- El Gradiente de Riesgo en los Patrones de IA
- Requisitos de Gobernanza por Patrón de IA
- Workflow Copilot: IA como Asistente de Nivel Par
- Execute: Cuando la IA Cambia el Estado Externo (y Por Qué es Riesgoso)
- Generative Research: De Fuentes a Síntesis
- ¿Qué es un Patrón de IA?
- OpenAI: A Practical Guide to Building AI Agents
- Anthropic Responsible Scaling Policy
- NIST AI Risk Management Framework

Co-Founder, Rework.com
On this page
- La fórmula
- El problema de negocio que resuelve
- Cuatro ejemplos reales en profundidad
- Agente de investigación
- Agente de soporte al cliente
- Agente de desarrollo de ventas
- Agente de código
- La Regla Auditar-O-Bloquear
- Por qué los agentes autónomos son el patrón de mayor riesgo
- Failure modes y mitigaciones
- Cuándo elegir Autonomous Agent vs. alternativas
- Diseño del human-in-the-loop a nivel de agente
- Señales de ROI
- Qué viene después
- Más información