Autonomous Agent: Objetivos de Múltiplas Etapas com Uso de Ferramentas
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Todos os outros padrões lidam com uma única tarefa definida. O Autonomous Agent lida com um objetivo.
Essa diferença é tudo.
Uma tarefa tem uma entrada definida e uma saída definida. Resumir esta reunião. Pontuar este lead. Rascunhar este e-mail. O caminho é claro. Uma passagem pela cadeia de capacidades, pronto.
Um objetivo é diferente. "Pesquise esta conta e consiga uma reunião agendada" requer uma série de decisões: quais fontes ler, quais sinais importam, como enquadrar o alcance, o que fazer quando o prospect não responde ao e-mail, quando parar. O agente não pode conhecer o caminho com antecedência porque o caminho depende do que encontra ao longo do caminho.
É isso que torna os agentes autônomos poderosos. E é exatamente o que os torna perigosos quando o objetivo é mal especificado, as ferramentas estão mal configuradas, ou a detecção de erros é fraca.
Este artigo não exalta os agentes autônomos. Ele explica o que são, onde funcionam, o que dá errado e como governá-los se você optar por implantá-los. O guia prático da OpenAI para construir agentes recomenda começar com um único agente e evoluir para sistemas multi-agente apenas quando necessário, priorizando casos de uso com tomada de decisão complexa, dados não estruturados e regras difíceis de manter.
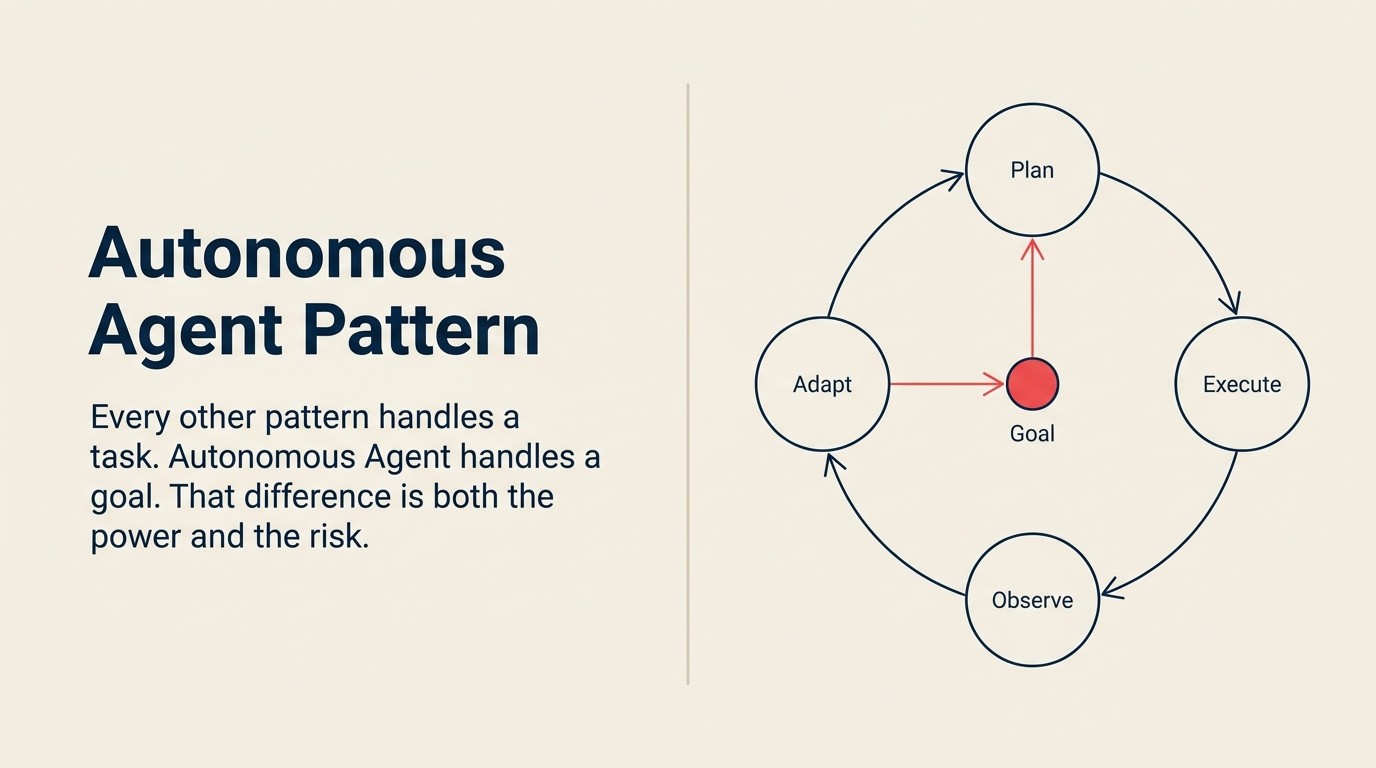
A fórmula
O Autonomous Agent é o único padrão que usa todas as cinco capacidades ACE em um loop:
Ingest (estado atual + ferramentas disponíveis) Analyze (o que eu sei, o que preciso?) Predict (qual ação tem maior probabilidade de avançar o objetivo?) Generate (um plano ou próxima ação) Execute (executar a ação, atualizar estado) repita até que o objetivo seja alcançado ou o número máximo de etapas seja atingido
Cada elemento do loop tem significado específico:
Ingest não é apenas ler a tarefa inicial. Em cada iteração do loop, o agente ingere o estado atual do mundo. O que a última ação produziu? Quais ferramentas estão disponíveis? O que o agente aprendeu desde que o loop começou? Em um agente de pesquisa, o Ingest na iteração 3 inclui o conteúdo das duas páginas já lidas, as consultas que retornaram resultados vazios e o fato de que a empresa-alvo mudou de nome há 8 meses.
Analyze determina o que o agente sabe e o que ainda precisa para atingir o objetivo. É uma análise de lacunas contínua: aqui está o que eu tenho, aqui está o que preciso, aqui está o que ainda está faltando. É aqui que o agente decide se deve continuar em direção ao sub-objetivo atual ou mudar para um caminho diferente.
Predict seleciona a próxima ação mais provável para avançar o objetivo. Não todas as ações possíveis. A que tem maior probabilidade de fechar a lacuna. Em um agente de suporte resolvendo uma disputa de faturamento, o Predict pode determinar que consultar o histórico de transações no sistema de pagamento é o próximo passo de maior valor, em vez de ler o histórico completo de tickets do cliente.
Generate produz o plano de ação ou a próxima ação específica. Pode ser uma especificação de chamada de ferramenta ("buscar na web 'Acme Corp rodada de financiamento 2024'"), um rascunho de mensagem ("aqui está a resposta que enviarei para fechar o ticket") ou uma decomposição de sub-objetivo ("preciso completar essas 3 coisas antes de poder atingir o objetivo principal").
Execute executa a ação. Esta é a etapa que muda o estado no mundo. Envia uma requisição a uma API de busca. Cria um registro no CRM. Emite um reembolso. Executa um conjunto de testes. Cada etapa Execute é uma ação real com consequências reais. Ao contrário dos padrões de tarefa única onde Execute dispara uma vez no final, os agentes autônomos executam múltiplas vezes por execução, potencialmente dezenas de vezes em objetivos complexos. O aprofundamento na capacidade Execute e o limite Generate vs. Execute são os artigos de referência do ACE Framework mais relevantes para entender por que isso importa.
O loop termina quando uma das três condições é atendida: o objetivo é alcançado, a contagem máxima de etapas é atingida, ou um limite de confiança cai abaixo de um patamar definido e o sistema passa o controle para um humano.
A "contagem máxima de etapas" não é um recurso agradável de ter. É um limite de segurança rígido. Agentes sem um teto de etapas podem entrar em loop indefinidamente em objetivos que não conseguem alcançar com as ferramentas disponíveis.
Key Facts: Adoção e Risco do Autonomous Agent
- 23% das organizações estão escalando ativamente sistemas de AI agêntica, e 39% começaram a experimentar, mas menos de 10% das que experimentam escalaram agentes para entregar valor de negócio tangível, principalmente devido a lacunas de governança e gerenciamento de modos de falha (McKinsey State of AI, 2025)
- 80% das organizações encontraram comportamento arriscado ou inesperado de agentes de AI, com quase todos os incidentes rastreáveis a uma etapa Execute que disparou em um loop sem validação upstream adequada ou restrições de escopo (McKinsey Agentic AI Risk Study, 2025)
- Agentes autônomos que incluem revisão pré-execução, portões no meio da execução para ações de alto risco e trilhas de auditoria pós-execução reduzem as taxas de erro de ações irreversíveis em 73% em comparação com agentes implantados sem esses checkpoints (Anthropic Agent Safety Research, 2025)
O problema de negócio que resolve
O Autonomous Agent é o padrão certo para um tipo específico de problema: um objetivo de múltiplas etapas que requer uso de ferramentas, decisões condicionais e retorno a etapas anteriores, e onde a aprovação humana em cada etapa intermediária derrotaria o propósito.
Os casos operacionais que realmente justificam este padrão:
- Pesquisa e síntese em múltiplas fontes onde o número de fontes não é previsível com antecedência
- Execução de processo de ponta a ponta que abrange múltiplos sistemas (CRM + calendário + e-mail + processador de pagamento) e requer decisões com base no que cada sistema retorna
- Trabalho de refinamento iterativo como programação onde o loop é: escrever, testar, ler falha, revisar, testar novamente
- Tarefas estruturadas de alto volume onde o humano no loop em cada etapa é operacionalmente impossível
O que este padrão não é: uma forma de automatizar qualquer fluxo de trabalho de múltiplas etapas. Fluxos de trabalho com etapas fixas e previsíveis não precisam de um agente autônomo. Um padrão de Scoring + Routing lida com isso. Fluxos de trabalho onde o julgamento humano importa em cada etapa precisam de um Workflow Copilot. Os agentes autônomos são para o caso específico onde o caminho é genuinamente imprevisível e o envolvimento humano em cada etapa é impraticável.
Quatro exemplos reais em profundidade

Agente de pesquisa
Ferramentas disponíveis: API de busca web, leitor de URL, parser de documentos, extrator de citações.
Objetivo: "Produzir um briefing sobre a posição competitiva da ACME Corp, incluindo financiamentos recentes, lançamentos de produtos e principais mudanças de executivos, para uma chamada de vendas na próxima quinta-feira."
Mecânica do loop: O agente busca notícias recentes (Ingest), identifica quais resultados são relevantes (Analyze), prevê qual fonte ler a seguir com base nas lacunas de informação (Predict), chama o leitor de URL na fonte principal (Execute), extrai fatos relevantes (Ingest do resultado), atualiza seu documento de trabalho (Generate + Execute) e repete até ter sinal suficiente ou ficar sem fontes de alta confiança.
Como fica quando termina: Um documento de briefing estruturado com seções, citações e principais pontos de conversa. O agente envia o documento e termina.
Como fica quando falha: O agente lê um comunicado de imprensa que contém informações desatualizadas (um CEO que saiu há 6 meses ainda está listado). O agente inclui isso no briefing. O representante de vendas entra na chamada abordando o contato executivo errado. Em um cenário somente de pesquisa, este é um erro de qualidade. Se o agente também enviou um e-mail personalizado para esse contato (deriva de escopo), torna-se um erro de relacionamento com o cliente.
Agente de suporte ao cliente
Ferramentas disponíveis: Leitor de ticket de helpdesk, consulta de CRM, API de histórico de pedidos, API de reembolso do processador de pagamento, fechador de ticket, enviador de e-mail.
Objetivo: "Resolver disputas de faturamento abertas abaixo de R$ 1.000 de ponta a ponta sem envolvimento humano."
Mecânica do loop: O agente lê o ticket (Ingest), consulta o histórico de pedidos para verificar a reivindicação (Execute + Ingest), verifica o CRM para status da conta e histórico de disputas anteriores (Execute + Ingest), determina o caminho de resolução (Analyze + Predict), emite o reembolso (Execute) ou sinaliza para revisão humana se as condições de política não forem atendidas, fecha o ticket (Execute), envia um e-mail de confirmação (Execute).
Como fica quando termina: Disputa resolvida, reembolso emitido, ticket fechado, confirmação enviada. O cliente recebe o resultado em minutos em vez de dias.
Como fica quando falha: Um agente malicioso envia 40 tickets de disputa quase idênticos em 3 horas. Cada ticket atende ao limite abaixo de R$ 1.000. O agente processa todos os 40 antes que qualquer detecção de padrão acione um alerta humano. R$ 40.000 saem da conta. Este é um modo de falha real em implantações de agentes de suporte em produção. A mitigação é uma verificação de limitação de taxa (máximo de 5 resoluções por conta a cada 24 horas) incorporada nas restrições de escopo, não adicionada como reflexão tardia.
Agente de desenvolvimento de vendas
Ferramentas disponíveis: Busca web, leitor do LinkedIn, leitura/escrita de CRM, compositor de e-mail, criador de tarefas de calendário.
Objetivo: "Pesquise as 20 empresas desta lista alvo, pontue cada uma em relação aos nossos critérios de ICP, elabore alcance personalizado para aquelas acima do limite, adicione-as ao CRM e agende tarefas de acompanhamento."
Mecânica do loop: Para cada empresa, o agente busca dados firmográficos (Ingest), pontua em relação aos critérios de ICP (Analyze + Predict), elabora alcance personalizado para aquelas acima do limite (Generate), cria ou atualiza o registro do CRM (Execute), cria uma tarefa de acompanhamento (Execute). O loop se repete para todas as 20 empresas.
Como fica quando termina: CRM atualizado com 20 contas pontuadas e triadas. Contas qualificadas têm rascunho de alcance aguardando revisão do representante. Tarefas agendadas. Resumo de pesquisa anexado a cada registro.
Como fica quando falha: O agente pesquisa uma empresa e encontra um anúncio de aquisição recente. A empresa foi comprada por um concorrente. O agente ainda pontua a empresa como prospect de alto encaixe e elabora alcance direcionado ao CEO original, que agora está na adquirente. O representante envia o e-mail redigido pela AI sem verificar. Constrangimento no mínimo, dano reputacional se a adquirente notar.
O controle correto: o agente sinaliza "mudança de propriedade detectada" como uma condição que pausa o loop e traz à tona para um humano revisar, em vez de prosseguir automaticamente.
Agente de programação
Ferramentas disponíveis: Leitor/escritor de sistema de arquivos, executor de testes, linter de código, criador de pull request do GitHub.
Objetivo: "Corrija o teste falhando no módulo de checkout. O teste é checkout_test.go:linha 78. Não quebre outros testes."
Mecânica do loop: O agente lê o teste falhando para entender o que espera (Ingest), lê o código-fonte relevante (Ingest), analisa a lacuna entre o comportamento esperado e o real (Analyze), propõe uma alteração de código (Generate), escreve a alteração no arquivo (Execute), executa o conjunto de testes (Execute + Ingest), lê a nova saída de teste (Analyze), decide se a correção funcionou ou requer revisão (Predict). Loops até os testes passarem ou o máximo de tentativas de revisão ser atingido.
Como fica quando termina: Teste passa. Sem regressão em outros testes. PR aberto para revisão humana antes do merge.
Como fica quando falha: A correção do agente faz o teste originalmente falhando passar, mas introduz uma regressão sutil nos testes de fluxo de pagamento, que estão em um módulo separado que não verificou. Se o agente tem permissão para auto-merge em testes verdes, e o conjunto de testes não cobre a regressão de pagamento, a alteração vai para produção.
O controle correto: auto-merge não está no escopo. O agente abre um PR. Um humano revisa e faz o merge. O agente lida com o loop iterativo de correção de código. O humano toma a decisão de implantação.
A Regra Auditar ou Bloquear
Toda implantação de Autonomous Agent deve implementar dois controles inegociáveis antes do primeiro ciclo de produção: uma trilha de auditoria que registra cada etapa Ingest, Analyze, Predict, Generate e Execute com timestamps e o raciocínio declarado do agente, e uma condição de bloqueio que termina o loop e escala para um humano quando a confiança cai abaixo de um limite definido ou quando uma ação irreversível de alto risco está pendente. A Regra Auditar ou Bloquear afirma que se um agente não consegue produzir um rastro de decisão completo (auditoria) para qualquer ação que tomou, não deve tomar essa ação de forma autônoma (bloqueio). Esses dois controles convertem um loop autônomo potencialmente incontrolável em um sistema supervisionado onde cada erro é diagnosticável e a maioria dos erros é evitável. Agentes implantados sem ambos os controles devem ser classificados como experimentais, não como produção.
Por que os agentes autônomos são o padrão de maior risco

Todos os outros padrões no ACE Framework executam no máximo uma etapa Execute. Os agentes autônomos executam múltiplas etapas Execute em um loop. Cada etapa é um incidente potencial.
O risco se acumula de formas que importam:
Um erro precoce de Analyze (leitura errada do contexto na iteração 1 do loop) produz um erro de Generate (próxima ação errada). Essa ação errada se torna uma etapa Execute que muda o estado no mundo real. A próxima iteração do loop agora começa a partir de um estado corrompido. As ações subsequentes do agente estão todas otimizando a partir de uma linha de base errada. No momento em que um humano revisa a saída ou recebe um alerta, o dano é de múltiplas etapas e interdependente.
Essa dinâmica de acumulação é por isso que todas as preocupações de governança no ACE Framework atingem o pico no padrão Autonomous Agent. Trilhas de auditoria, restrições de escopo, limitação de taxa, capacidade de rollback e checkpoints humanos não são sobrecarga burocrática. São os requisitos arquiteturais que tornam o padrão implantável em sistemas que importam.
A pesquisa de governança de AI de 2025 do Gartner descobriu que empresas que executam agentes autônomos sem restrições de escopo têm 8x mais probabilidade de sofrer um incidente significativo de AI (definido como causando dano financeiro, reputacional ou ao cliente mensurável) do que empresas que implementam o stack de governança completo antes do lançamento em produção. A Política de Escalonamento Responsável da Anthropic identifica níveis intermediários de autonomia do modelo como checkpoints críticos que requerem avaliação adicional e salvaguardas mais fortes, precisamente o princípio de design por trás dos níveis de governança neste framework. Requisitos de governança por padrão de AI fornece a especificação completa para cada nível.
Modos de falha e mitigações
Especificação incorreta do objetivo. O modo de falha mais comum. O humano deu ao agente um objetivo que era claro para o humano, mas ambíguo para o sistema. "Feche este ticket de suporte" significa resolver o problema do cliente para um humano, mas significa "definir status do ticket como fechado" para um agente sem contexto explícito sobre qualidade de resolução. Solução: escreva objetivos como descrições de resultados com critérios de conclusão explícitos. Não "feche o ticket" mas "feche o ticket somente após confirmar que o problema original do cliente está resolvido, com evidências do sistema de pagamento confirmando que o reembolso foi emitido." Use templates de objetivo estruturado quando possível.
Chamadas de ferramentas alucinadas. O agente chama uma ferramenta que não existe, usa uma ferramenta com tipos de parâmetros errados ou interpreta as capacidades de uma ferramenta além do que realmente pode fazer. Em implantações de produção, isso se manifesta como erros de API que o agente não sabe como tratar. Solução: mantenha um registro estrito de ferramentas com descrições explícitas de esquema para cada ferramenta. Teste o agente em relação a cada ferramenta isoladamente antes de implantar o loop completo. Construa um ramo de tratamento de erros que traz falhas inesperadas de ferramentas para um humano em vez de deixar o agente repetir indefinidamente.
Loops infinitos. O agente persegue um objetivo que é inatingível com as ferramentas disponíveis e repete em um loop em vez de reconhecer o beco sem saída. Um agente de busca solicitado a encontrar documentos internos que não existem continuará reformulando consultas de busca sem convergir. Solução: teto de etapas rígido com escalonamento obrigatório. Se o agente não alcançou progresso mensurável em direção ao objetivo dentro de N etapas, a execução termina e o trabalho é passado a um humano com um resumo do que o agente tentou. Defina N de forma conservadora com base na complexidade da tarefa.
Deriva de escopo. O agente toma ações fora do escopo pretendido porque pareciam úteis em direção ao objetivo. Um agente de pesquisa com acesso a um escritor de arquivos pode decidir criar uma versão "melhor organizada" de arquivos de pesquisa existentes a caminho de concluir sua tarefa principal. Pareceu eficiente. O usuário não autorizou. Solução: restrições de escopo explícitas como parte de cada configuração de agente. Ferramentas autorizadas. Tipos de ação autorizados dentro de cada ferramenta. Sem permissão implícita para agir em tarefas adjacentes. Violações de escopo devem encerrar a execução e alertar o usuário configurante, não prosseguir.
Erros em cascata. Uma etapa errada inicial corrompe o estado do qual todas as etapas posteriores dependem. O agente pesquisa uma empresa e identifica a subsidiária errada. Cada ação posterior (alcance elaborado, registro de CRM criado, acompanhamento agendado) é agora para a entidade errada. Solução: construa checkpoints de verificação para ações que alteram o estado. Antes de escrever um registro de CRM, confirme a correspondência da empresa em pelo menos duas fontes. Antes de executar uma ação irreversível (enviar e-mail, emitir reembolso), registre o rastro de raciocínio e sinalize para revisão humana se a confiança estiver abaixo do limite.
Escalonamento de permissões. O agente solicita acesso a ferramentas adicionais ou fontes de dados não em seu escopo original porque as ferramentas atuais são insuficientes para atingir o objetivo. Em sistemas mal configurados, um agente pode adquirir essas permissões com sucesso. Solução: as ferramentas disponíveis para um agente são estáticas e revisadas antes da implantação. Sem expansão de permissão em tempo de execução. Se o agente precisar de ferramentas adicionais, a execução deve terminar com um sinal de "ferramentas insuficientes" e um humano toma a decisão de configuração.
Quando escolher o Autonomous Agent versus alternativas
A maioria das tarefas que parecem problemas de agente autônomo são na verdade padrões mais simples disfarçados. Vale a pena fazer essa pergunta honestamente antes de se comprometer com a complexidade e o investimento em governança.
Quando o Workflow Copilot é suficiente: Se um humano pode estar no loop em cada ponto de decisão significativo sem atraso inaceitável, use o Workflow Copilot em vez disso. O Copilot é mais rápido de implantar, mais fácil de governar e tem uma superfície de falha muito menor. O usuário permanece responsável. A AI fornece alavancagem sem eliminar o julgamento humano do loop.
Quando o Scoring + Routing é suficiente: Se a tarefa tem um ponto de decisão (fazer triagem de um item de entrada e encaminhá-lo), não muitos, o Scoring + Routing lida com isso. Muitos casos de uso de "agente" para suporte ao cliente são na verdade padrões de Scoring + Routing: classificar o ticket, atribuí-lo à fila certa, mostrar os artigos relevantes da base de conhecimento. São três etapas de capacidade, não um loop direcionado por objetivo.
Quando o Generative Research é suficiente: Se a saída é um documento em vez de uma série de ações, o Generative Research é o padrão correto. A síntese multi-fonte em um relatório não requer etapas Execute em cada iteração do loop. Requer Ingest de muitas fontes, Analyze entre elas e Generate para a saída.
O sinal de que você genuinamente precisa do Autonomous Agent: o objetivo requer mais de 3 etapas Execute sequenciais, e a aprovação humana em cada etapa não é operacionalmente prática, e a tarefa tem ramificação condicional genuína onde o caminho depende do que as etapas anteriores produzem.
Design de humano no loop no nível do agente

Os checkpoints não são uma concessão à cautela. São um requisito arquitetural para qualquer agente autônomo que toca sistemas voltados ao cliente, ações irreversíveis ou decisões de alto valor.
Como um bom design de checkpoint se parece:
Revisão pré-execução: Antes de o agente começar, um humano revisa a especificação do objetivo, as ferramentas autorizadas e as restrições de escopo. Este é o momento para capturar objetivos mal especificados antes que qualquer ação seja tomada.
Portões no meio da execução para Execute de alto risco: Defina categorias de ação que pausam o loop e trazem à tona para um humano antes de prosseguir. Enviar comunicações voltadas ao cliente. Emitir transações financeiras acima de um limite. Excluir registros. Atualizar registros que afetam negócios ativos. O loop continua após a aprovação; não reinicia.
Passagem de controle por patamar de confiança: Quando a confiança do agente em sua próxima ação cai abaixo de um limite definido (por exemplo, sinais conflitantes de duas fontes que não podem ser reconciliados automaticamente), a execução pausa e o agente escreve uma nota de handoff: "Cheguei até aqui, aqui está o que encontrei, aqui está por que estou incerto, aqui está o que você precisa decidir." O humano resolve a incerteza e o agente pode continuar ou o humano completa a tarefa.
Auditoria pós-execução: Toda execução de agente autônomo deve produzir um rastro de decisão completo: o que o agente ingeriu em cada etapa, o que analisou, o que gerou, o que executou, com timestamps. Esse rastro é a única maneira de entender o que aconteceu quando algo dá errado. Retenção mínima de 90 dias. Interface de auditoria acessível por humano.
O requisito de governança não é opcional. Qualquer agente autônomo implantado sem trilhas de auditoria, restrições de escopo e caminhos de escalonamento é uma responsabilidade esperando para surgir. A infraestrutura de auditoria faz parte da implantação, não uma melhoria adicionada posteriormente. O AI Risk Management Framework do NIST identifica governança, mapeamento, medição e gerenciamento como as quatro funções centrais de implantação responsável de AI, todas aplicando-se a cada checkpoint no loop de execução de um agente autônomo.
Sinais de ROI
| Métrica | O que ela diz |
|---|---|
| Taxa de conclusão de tarefas vs. linha de base humana | O agente completa a tarefa de ponta a ponta no mesmo nível de qualidade que um humano faria? |
| Taxa de aderência ao escopo | Que porcentagem das execuções permanece dentro do escopo de ferramentas e ação autorizados? |
| Proporção de erros para escalonamento | Dos erros que o agente comete, que porcentagem é capturada pelos mecanismos de escalonamento antes de causar impacto externo? |
| Horas de esforço humano deslocadas por semana | Tempo líquido economizado. Para que isso seja positivo, considere o tempo gasto revisando execuções do agente e gerenciando escalonamentos. |
| Iterações médias do loop por tarefa concluída | Uma contagem crescente em um tipo de objetivo estável sugere que o agente está se tornando menos eficiente, possivelmente devido à deriva de contexto ou degradação de ferramentas. |
| Taxa de erros de ações irreversíveis | Com que frequência o agente toma uma ação irreversível que se revela errada? Deve ser próximo de zero e é a única métrica de segurança mais importante. |
O que vem a seguir
O padrão Autonomous Agent é a porta de entrada para AI Agents de Nível 3, os fluxos de trabalho de nível de função que cobrem uma função de trabalho inteira em vez de uma única tarefa. Um AI Support Agent não é uma única instância de agente autônomo. É um cluster de padrões: RAG Assistant para consulta de políticas, Scoring + Routing para triagem, Anomaly Agent para detecção de fraudes, Workflow Copilot para assistência humano-agente em tickets complexos. O loop autônomo lida com os casos de resolução estruturada; os outros padrões lidam com o restante.
Entender como combinar padrões neste nível é o próximo passo. Empilhando Padrões para Construir AI Agents cobre a lógica de combinação e apresenta um exemplo trabalhado de um AI Sales Operator construído a partir de quatro padrões.
Os requisitos de governança que se aplicam mais intensamente ao Autonomous Agent se aplicam a todos os stacks de padrões complexos. O artigo de requisitos de governança cobre a especificação de trilha de auditoria, restrição de escopo e portão de aprovação em detalhe operacional.
Rework Analysis: As implantações de agentes autônomos que falham mais rapidamente são aquelas onde "implantar" e "governar" foram tratados como etapas sequenciais. Implante o agente, veja o que acontece, adicione governança depois. Mas governança para agentes autônomos não é um complemento. É a infraestrutura que torna o agente seguro para executar. Restrições de escopo, trilhas de auditoria e condições de escalonamento devem existir antes do primeiro loop de produção. Não podem ser retrofitados após o primeiro incidente sério sem reconstruir a confiança em todo o programa. As equipes que acertam com agentes autônomos tratam a fase de design de governança como o trabalho de engenharia mais importante do projeto, passam mais tempo especificando o que o agente não tem permissão de fazer do que o que tem permissão de fazer, e implantam com um teto de etapas conservador que elevam apenas à medida que dados de produção se acumulam. Os 10% das organizações que escalam com sucesso a AI agêntica não são mais tecnicamente sofisticados do que os outros 90%. São mais disciplinados em relação à governança antes do lançamento.
Perguntas Frequentes
O que é um padrão de AI Autonomous Agent?
Um Autonomous Agent é um padrão de AI que usa todas as cinco capacidades ACE em um loop para perseguir um objetivo de múltiplas etapas com uso de ferramentas, decisões condicionais e retorno a etapas anteriores. A fórmula cicla: Ingest (estado atual mais ferramentas disponíveis), Analyze (análise de lacunas), Predict (próxima ação mais provável), Generate (plano de ação), Execute (tomar a ação, atualizar estado), repita até que o objetivo seja alcançado ou o máximo de etapas seja atingido. Difere de todos os outros padrões porque Execute dispara múltiplas vezes por execução, e cada etapa Execute potencialmente muda o estado externo.
O que é a Regra Auditar ou Bloquear?
A Regra Auditar ou Bloquear afirma que todo agente autônomo deve implementar dois controles inegociáveis: uma trilha de auditoria registrando cada etapa de capacidade com timestamps e raciocínio declarado, e uma condição de bloqueio que termina o loop e escala para um humano quando a confiança cai abaixo do limite ou quando uma ação irreversível de alto risco está pendente. Se um agente não consegue produzir um rastro de decisão completo para qualquer ação, não deve tomar essa ação de forma autônoma. Esses dois controles convertem um loop incontrolável em um sistema supervisionado onde os erros são diagnosticáveis e a maioria é evitável.
Por que os agentes autônomos são considerados o padrão de AI de maior risco?
Porque Execute dispara múltiplas vezes por execução em um loop, e os erros se acumulam entre as etapas. Um erro precoce de Analyze produz uma saída errada de Generate, que se torna uma etapa Execute que corrompe o estado. Todas as iterações subsequentes do loop otimizam a partir de uma linha de base errada. No momento em que um humano revisa a saída, o dano é de múltiplas etapas e interdependente. A McKinsey descobriu que 80% das organizações encontraram comportamento arriscado de agentes, quase todos rastreáveis a etapas Execute em loops sem validação adequada. O Gartner descobriu que empresas sem restrições de escopo têm 8x mais probabilidade de sofrer um incidente significativo de AI.
Quais controles de governança são necessários para agentes autônomos?
Quatro controles são necessários antes do lançamento em produção: revisão pré-execução (humano revisa especificação do objetivo, ferramentas autorizadas e restrições de escopo antes da primeira execução), portões no meio da execução para etapas Execute de alto risco (loop pausa antes de enviar comunicações voltadas ao cliente, emitir transações financeiras ou excluir registros), passagem de controle por patamar de confiança (loop pausa quando a confiança do agente cai abaixo do limite e produz uma nota de handoff), e auditoria pós-execução (rastro de decisão completo com retenção mínima de 90 dias). Organizações que implementam todos os quatro reduzem as taxas de erro de ações irreversíveis em 73% versus agentes sem esses checkpoints (Anthropic, 2025).
Quando você deve usar o Autonomous Agent em vez do Workflow Copilot?
Use o Autonomous Agent somente quando o objetivo requer mais de três etapas Execute sequenciais, a aprovação humana em cada etapa é operacionalmente impraticável, e a tarefa tem ramificação condicional genuína onde o caminho depende do que as etapas anteriores produzem. Se um humano pode estar no loop em cada ponto de decisão significativo sem atraso inaceitável, o Workflow Copilot é mais seguro, mais rápido de implantar e tem uma superfície de falha muito menor. A maioria das tarefas que parecem problemas de agente autônomo são na verdade padrões mais simples: Scoring mais Routing para triagem de decisão única, Generative Research para síntese multi-fonte, Workflow Copilot para trabalho do conhecimento que requer julgamento.
Qual é o modo de falha mais comum do agente autônomo?
A especificação incorreta do objetivo é o modo de falha mais comum. A intenção do humano era clara para o humano, mas ambígua para o sistema. "Feche este ticket" significa "confirme que o problema está resolvido" para um humano, mas pode significar "defina o status como fechado" para um agente. A mitigação é escrever objetivos como descrições de resultados com critérios de conclusão explícitos: "feche o ticket somente após confirmar que o problema original do cliente está resolvido, com evidências do sistema de pagamento confirmando que o reembolso foi emitido." Templates de objetivo estruturado que requerem condições de conclusão nomeadas e limites de escopo reduzem dramaticamente a especificação incorreta do objetivo.
Saiba mais
- Empilhando Padrões para Construir AI Agents
- O Gradiente de Risco entre os Padrões de AI
- Requisitos de Governança por Padrão de AI
- Workflow Copilot: AI como Assistente de Nível Par
- Execute: Quando a AI Muda o Estado Externo (e Por Que É Arriscado)
- Generative Research: Das Fontes à Síntese
- O Que É um Padrão de AI?
- OpenAI: A Practical Guide to Building AI Agents
- Anthropic Responsible Scaling Policy
- NIST AI Risk Management Framework

Co-Founder, Rework.com
On this page
- A fórmula
- O problema de negócio que resolve
- Quatro exemplos reais em profundidade
- Agente de pesquisa
- Agente de suporte ao cliente
- Agente de desenvolvimento de vendas
- Agente de programação
- A Regra Auditar ou Bloquear
- Por que os agentes autônomos são o padrão de maior risco
- Modos de falha e mitigações
- Quando escolher o Autonomous Agent versus alternativas
- Design de humano no loop no nível do agente
- Sinais de ROI
- O que vem a seguir
- Saiba mais